Abstract
Randomized response (RR) techniques are widely used in research involving sensitive variables, such as drugs, violence or crime, especially when a population mean or prevalence must be estimated. However, they are not generally applied to examine relationships between a sensitive variable and other characteristics. This type of technique was initially applied to qualitative variables, and studies later showed that a logistic regression may be performed with RR data. Since many of the variables considered in this context are quantitative, RR techniques were extended to these cases to estimate the values required. Regression analysis is a valuable statistical tool for exploring relationships among variables and for establishing associations between responses and covariates. In this article, we propose a design-based regression analysis for complex sample designs based on the unified RR approach. We present estimators of the regression coefficients, study their theoretical properties and consider different ways to estimate their variance. The properties of these estimation techniques were simulated using various quantitative randomized models. The method proposed was also used to analyse the findings from a real-world survey.
1. Introduction
Standard randomized response (RR) methods are mainly used in surveys that elicit a binary response to a sensitive question in order to estimate the proportion of the study population presenting a given (sensitive) characteristic. Warner’s study generated a rapidly expanding body of research literature on alternative techniques for eliciting suitable RR schemes in order to estimate such a population proportion ([1,2,3,4,5,6]).
Some studies addressed situations in which the response to a sensitive question results in a quantitative variable and when the researcher wishes to estimate a linear parameter as the mean or the total of the sensitive variable under study. In the method proposed by [7], the interviewee was asked to choose, by means of a randomization device, from two questions; one concerned the sensitive variable and the other was unrelated (both were of the same order of magnitude). Other important papers in this regard include [8,9,10,11,12,13,14,15,16,17,18,19,20,21], together with the contributions compiled by [22,23,24,25,26]. When dealing with quantitative sensitive variables, the idea is that respondents should not disclose the true value of the sensitive variable but rather provide a scrambled value, which is obtained by algebraically perturbing the true response. This is done by applying one or more scrambling random variables, independent from each other and from the sensitive variable, the distributions of which are fully known to the researcher.
RR methods were also been applied to examine relationships between a qualitative sensitive variable and other variables. Thus, reference [27] showed that logistic regression may be performed with RR data, and [28] developed multivariate regression logistic techniques for four RR designs. In addition, reference [29] considered the univariate logistic regression model for binary RR response variables and presented this model as a generalized linear model. The same research group also developed a multivariate logistic regression model for RR response variables. Under simple random sampling, reference [30] considered a generalized linear model and generalized linear mixed models for RR designs where the probability of obtaining a positive response can be written as a linear equation of the answer to the sensitive question. Finally, reference [31] presented a logistic regression model on RR data when the covariates for some subjects were randomly missing.
However, few prior studies were made of regression techniques for quantitative randomized response variables. reference [32] performed a linear regression analysis using the model presented in [10] for the simple random sampling case, from which the variance of the estimate was calculated. In a related paper, reference [33] discussed the maximum likelihood estimation of an independently and identically distributed normal linear regression model when some of the covariates are subject to RR.
In this paper, we address the question of regression techniques for quantitative RR data under a general sampling design. Specifically, we consider a general class of RR methods ([34]) for quantitative variables and show how the RR can be used as the outcome in regression models.
The rest of this paper is organized as follows. First, we review the unified RRT approach described by [21] to establish the framework, and clarify the notation used (Section 2). We then show how RR can be used as the outcome in regression models, present estimators for the regression coefficients and investigate their theoretical properties in Section 3. Based on the asymptotic variance, we propose an estimator for the variance and discuss two interesting resampling methods, jackknife and bootstrap. Simulation experiments were carried out to confirm the finite size sample properties of the proposed estimators. These simulations are discussed in Section 4, after which the method described is applied to a real-world situation, that of a survey focused on sensitive characteristics. Finally, in Section 6, we summarize the main findings obtained and the conclusions drawn.
2. Randomized Response Survey Designs for Quantitative Variables
Let be a finite population consisting of N different elements. Let be the value of the sensitive aspect under study for the i-th population element.
In this case, y is a sensitive variable that cannot be observed directly. We consider the unified approach given by [21] because some important RR techniques [8,10,11,13] can be viewed as particular cases of this approach.
The respondent performs a random experiment with three possible outcomes. If the first result is obtained, the respondent reports the real value of variable; with the second result, the respondent reports the scrambled response , and otherwise the respondent reports a value of a variable where , and are scramble variables whose distributions are known. In this randomization device, the distribution of the response given by person i is
and denote the mean and the variance, respectively, of the variable ().
The sample s of individuals is chosen according to a sampling design . and where are the first- and second-order inclusion probabilities. We assume that the sampling design and the randomization stage are independent of each other and that the randomization stage is performed on each selected individual independently ([35]).
The main study goal is usually to estimate . A design-unbiased estimator of the population mean is given by the Horvitz-Thompson (HT) estimator:
where is the sampling weight and
The variance of this estimator and an estimator of this variance are given in [21]. In cases where the population size N is unknown, is usual to consider the Hájek estimator (see [36,37]). The Hájek estimator is generally preferred to the Horvitz-Thompson estimator for the mean, although it is not considered in this paper.
3. Regression for RR Models
Consider a regression problem, in which the data that are collected on the i-th subject are the outcome variable and a vector of K covariates. Under this scenario, we can consider superpopulation models, in which it is assumed that the population under study constitutes a realization of superpopulation random variables under a superpopulation model M. The value of the variable of interest, associated with the i-th unit of the population, has two terms: a deterministic element and a random element:
where is a specific function and the random vector is assumed to have a zero mean and independent components.
Now, our aim is to estimate the regression coefficients . To do so, let denote the expectation under the model of given the covariates and .
Because the values of cannot be observed directly we need to relate the randomized response to the linear predictor of the sensitive question. This relation is given by:
where denotes the expectation under the RR mechanism.
A linear transformation of the observed values can then be performed:
which can be considered a realization of the variables
Thus, we consider the new regression model . The components of random vector are supposed to be independent with a zero mean and a positive definite covariance matrix which is diagonal, . The are known constants depending on . This model verifies that .
3.1. Estimation of the Regression Coefficients
Consider the population function:
where .
The population regression coefficient is obtained as the solution of the estimating equations . is an estimate of the model parameter if the census data set is known and defines a parameter for the survey population if it is unknown.
Given the values observed in the sample we consider the weighted estimation function
Let be a solution to . We study the properties of as an estimator of .
The usual asymptotic framework in survey sampling is adopted: the finite population U and the sampling design are embedded within a sequence of populations and designs indexed by , , with . Stochastic order is with respect to the above sequence of designs. To confirm our results, the following technical assumptions are made:
- A.1. The survey design satisfies for any .
- A.2. The survey design ensures that is asymptotically normally distributed with mean and entries of the variance-covariance matrix at the order for any .
- A.3. The survey design satisfies and for any .
Theorem 1.
Under assumptions A.1 and A.3, the solution to provides a consistent estimator for the parameter . If condition A.2 is also met, the weighted quasi-likelihood estimator is asymptotically normally distributed with mean and variance-covariance matrix
where is the design variance-covariance matrix and.
Proof.
The estimating function is twice differentiable with respect to . [38] showed that, under these conditions, a general parameter given by the solution of the population equation is consistently estimated by the solution to . In our case and .
Consider the following Taylor series expansion
Thus, is asymptotically normally distributed because is asymptotically normally distributed under assumption A.2. The asymptotic variance-covariance matrix of is easily derived:
and thus expression (2) is obtained. □
Remark 1.
Please note that in the RR setting there are two sources of randomness (if we do not account for the model variability), due to the sampling design, and to the randomization device that scrambles the variable of interest. Thus, the variances in are composed of two terms.
Let and denote the expectation and variance operators for any sampling design d. Taking into account the two sources of variability induced by the sampling design and the randomization device, we have the variance decomposition formula:
where and are the expectation–variance operators over the RR device. A detailed expression of can be seen in ([21], formulae 3).
The expressions of the covariances are simpler since the randomization stage is performed on each selected individual independently ( ).
Remark 2.
Software packages such as survey [39] in R with the function svyglm can be used to fit linear and generalized linear models incorporating the design weights and thus to calculate from the randomized values , but the reported variances and covariances are incorrect. Accordingly, the standard significance test based on these values is invalid and can lead to grossly misleading conclusions being drawn.
From (2) we can construct a design-based estimator for the variance-covariance matrix of through the plug-in method:
where
and
with and where is an estimator of .
This variance estimator is not unbiased because it does not include the terms of variability induced by the randomization device; moreover, it is difficult to obtain because on many occasions it does not have an estimator of . Furthermore, the estimator requires knowledge of second-order inclusion probabilities, which are often impossible to compute or are not available for complex sampling designs.
From a practical viewpoint therefore, it is better to use the jackknife ([40]) and bootstrap techniques ([41]), which are readily applicable under diverse conditions.
The application of the jackknife method to the regression coefficient under simple random sampling is given in Section 4.4 and its use in stratified sampling is given in Section 4.5 of [42]. We apply these methods to rather than .
The jackknife estimation of variance of an estimator of the population mean based on a RR survey data is considered in [43,44]. The authors show that the jackknife estimator underestimates the variance of the Horvitz-Thompson estimator of the population mean and propose modifications of the conventional jackknife estimator. These modifications include an additional term that adds an estimate of the variance due to the randomization device that scrambles the variable of interest.
The bootstrap method developed by [41] has been adjusted for survey sampling and its sampling design is incorporated in several studies (see e.g., [45,46,47]). Direct applications of bootstrap methods for estimating the variance-covariance matrix (2) involve solving the equation repeatedly for each bootstrap sample. Multiplier bootstrap with estimating functions was proposed by [48]. We use this method with the values to estimate the variance of the proposed estimator. See [49] for a detailed description of this bootstrap method, Section 10.3.1.
Obtaining jackknife and bootstrap estimators for the variance of that takes into account the randomness due to the RR process is a lot more complex than in the case of estimating means. Measuring the influence of the randomization mechanism on the variance estimation using jackknife or bootstrap is an open problem that requires further investigation.
3.2. The Homoscedastic Linear Model
Let us now consider the case of the homoscedastic linear model: and . In this case the weighted quasi-likelihood estimate reduces to the weighted least squared estimator that is the solution to the equation:
The solution is given by the design-weighted estimator:
This estimator is model-unbiased and design-consistent.
For this linear model, matrix is simplified, and takes the simple expression
Thus, an estimator of the asymptotic variance of is given by:
with and where is the estimated HT variance.
3.3. The Ratio Model
We now consider the case of a single auxiliary variable, x, and the following ratio model ([37])
The weighted quasi-likelihood estimate can be reduced to the solution of the simple equation:
This solution is given by the design-weighted ratio estimator:
where is the HT estimator of the population mean . The estimator of the variance of a ratio estimator is straightforwardly obtained by Taylor linearization (see e.g., [42]):
where
and where (see ([21]) and
Since
an estimator for this covariance can be obtained as follows:
4. Simulation Study
This section describes an extensive simulation study, which was implemented in R. In the first study, the variables were simulated using the R-package simstudy ([50]) and the samples were selected with sampling package discussed in ([51]).
The population size was . The main variable y and two auxiliary variables and were generated using the genCorData function. The means, the standard deviations and the correlation matrix were:
We use as sampling design stratified simple random sampling from a stratified population with six strata of sizes 1000, 500, 150, 250, 150 and 300. Three different combinations of sample sizes were drawn for the population, corresponding to the following number of units per stratum:
.
.
.
Point estimators of the coefficient of regression were computed using the Eichhorn and Hayre (EH) and the Bar-Lev, Bobovitch and Boukai (BBB) models. For both models we let S as an innocuous quantitative variable unrelated to the sensitive variable and assume that its distribution is known. In Eichhorn and Hayre model the i-th respondent answer the truth multiplied by a generated number from S. In BBB model, the procedure is as follows, the i-th respondent is asked to answer the truth about the sensible variable with probability p and answer the truth multiplied by a generated number from S with probability . In this study a distribution was used for the scramble variable S, and in the BBB model was assumed. The use of the distribution as a scrambling distribution is justified by [10], who highlighted the protection it gives the respondent. For this reason, it is commonly used as a scramble variable in RRT simulation studies, see e.g., [17,21].
For each estimator of the population coefficient of regression , we computed the relative bias % (in percent) and the relative mean squared error % (in percent), where denotes the average based on 1000 simulation runs.
The results for every possible combination are shown in Table 1.

Table 1.
Absolute relative bias and relative mean squared error in percent for and in SRSS for the BBB and EH models.
The RMSE values in this table confirm that the estimators and obtained using the EH method are less efficient than with BBB method. Moreover, on comparing the estimator for and for the estimates for the first parameter are worse.
The second simulation study examines the behaviour of variance estimators. In this study, we obtained the plug-in method based on the asymptotic variance formulae AV (described in Section 3.1), the jackknife JK and the bootstrap BS variance estimators. Table 2 shows the average length (L) of the confidence intervals based on a normal distribution, the simulated coverage (Cov) probability for each method, the absolute relative bias (|RB|) and the relative mean squared error (RMSE) in percent. In this case, and for each variance estimator, AV, JK, BS, RB and RMSE are calculated based on a simulated variance obtained as the average of 1000 independent runs.
Table 2.
Average length and coverage, relative bias and relative mean squared error for AV, JK and BS variances of and in SRSS for the BBB and EH models.
The most important observation is that, in general, all the variance estimators and the associated confidence intervals present good levels of performance. The lengths of the confidence intervals are small and the coverage probabilities of the 95% confidence interval are close to the nominal coverage.
The jackknife variance estimator has the smallest length, which means there is under-coverage for the confidence interval for some sample sizes. The bootstrap variance estimator provides a short length and the resulting coverage is very close to the nominal value.
We start by noting that the percent relative bias of all variance estimators were small, (less than 0.667% in absolute value for estimator AV, less than 0.233% in absolute value for estimator JK and less than 0.141% in absolute value for estimator BS). The model used to randomize the response has a low impact on the relative bias. For all models and sample sizes, we observed that JK and BS estimators are similar in terms of relative mean squared error.
This study was then repeated with a sample size and considering also a distribution of the distribution of scramble variable S. The dispersion of the and values obtained for each randomization method and degrees of freedom are represented by boxplot graphics (Figure 1).
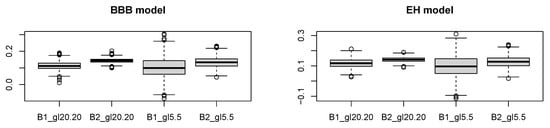
Figure 1.
Boxplot for and in SRSS in the BBB model (left) and EH model (right).
The figure shows that the values of are higher and the dispersion is lower than with for all randomization methods. Moreover, the variance of the scramble variable increases in line with the dispersion.
Following this example, the value of the plug-in method based on the asymptotic variance, the jackknife and bootstrap variances and the dispersion obtained for each randomization method and degrees of freedom considered are represented by boxplot graphics (Figure 2).
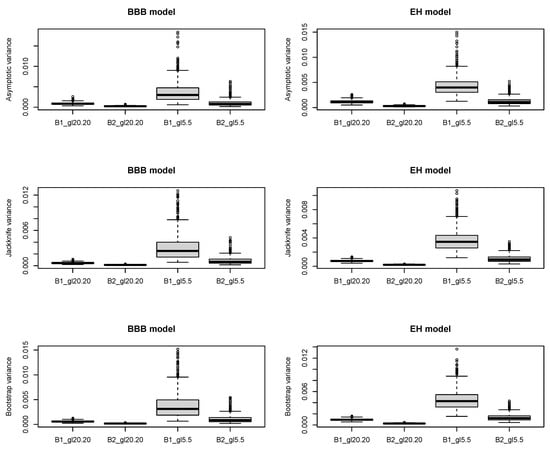
Figure 2.
Boxplot for AV, JK and BS variances of and in SRSS in the BBB and EH models.
For each randomization method, we note that the greater the variance of the scramble variable S, the greater the dispersion. This behaviour is especially noticeable in the estimation of parameter . This result is expected, since adding more noise makes the dispersion increase, but in practice it is not possible to use scramble variables with little variance, as this reduces the privacy protection obtained.
To compare regression-based RR model and ratio-based RR model, we conducted the third simulation study in which both models are included. We use as sampling design the simple random sampling under a population of size . Three different combinations of sample sizes were drawn from the population, . As in the previous study, point estimators of the coefficient of regression were computed using the Eichhorn and Hayre (EH) and the Bar-Lev, Bobovitch and Boukai (BBB) models. A distribution was used for the scramble variable S, and in the BBB model was assumed. The main variable y and an auxiliary variables x were generated using the model with , in this case , , and .
For all randomization methods and in both models, regression and ratio, we can see (Table 3) how the values obtained from the relative bias and the relative mean squared error are small. Focusing on the RMSE, we observe that the value decreases as the sample size increases, as we expected, and we obtain a slightly better behavior of the ratio model compared to the regression model.
Table 3.
Absolute relative bias and relative mean squared error in percent for and in SRS for the BBB and EH models.
5. Real Application
As a real application of the methods described above, we conducted a survey by stratified random sampling at the University of *** to investigate the consumption of alcohol and drugs among the university population (in a sample of 754 students).
The sensitive question in this case was, “Indicates the age at which you started drinking alcohol and using drugs” and the RR technique used was the model proposed by [11]. To apply this model, each student was asked to use used as a randomizing device the app “Baraja Española” (a deck of cards, composed of 40 cards, divided into four families or suits, each numbered one to seven plus three face cards). When the user touches the screen, a card is shown. When it is a face card, the sensitive question should be answered; otherwise, the real number should be given, multiplied by the number shown on the card. Thus, the design parameter of the BarLev model was 3/10.
After the study data was compiled, a regression model was performed, in which the sensitive variable was taken as the dependent variable and the variable “Indicate on a scale of 0 (very bad) to 10 (optimal), how would you rate your relationship with your parents?” was an independent variable. After obtaining the value of the parameter, the estimate of the variance was obtained by the jackknife technique and the corresponding 95% confidence interval. This approach produced the following results:
In other words, the better the relationship with their parents, the higher the age at which these students began to consume alcohol and drugs.
6. Conclusions
Indirect interview techniques effectively reduce voluntary bias in surveys referring to sensitive questions. In recent years, many new techniques emerged for the estimation of proportions, means or totals of sensitive variables, but few studies addressed the question of dependency parameters.
In this paper, we propose a general scheme for a randomized response (RR) technique, under a general sampling design for estimating regression coefficients. We study the theoretical properties of the proposed estimators and we derive several estimators for their variances.
To assess the accuracy of the proposed estimators, a simulation study was conducted using two RR techniques. In this simulation study, the proposed estimators obtained good results in terms of relative bias and relative mean squared error.
The application of the proposed technique to a real survey enabled us to relate the age at which young people begin to consume alcohol and drugs with the perceived quality of the relationship with their parents.
Author Contributions
Conceptualization, M.d.M.R.; Data curation, B.C.; Formal analysis, A.A.; Funding acquisition, M.d.M.R.; Investigation, M.d.M.R.; Methodology, A.A.; Software, B.C.; Writing—original draft, M.d.M.R.; Writing—review & editing, B.C.. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by Ministerio de Ciencia e Innovación of Spain [grant PID2019-106861RB-I00].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Arnab, R. Randomized response trials: A unified approach for qualitative data. Commun. Stat. Theory Methods 1996, 25, 1173–1183. [Google Scholar] [CrossRef]
- Barabesi, L.; Marcheselli, M. A practical implementation and Bayesian estimation in Franklin’s randomized response procedure. Commun. Stat. Simul. Comput. 2006, 35, 563–573. [Google Scholar] [CrossRef]
- Barabesi, L. A design-based randomized response procedure for the estimation of population proportion and sensitivity level. J. Stat. Plan. Inference 2008, 138, 2398–2408. [Google Scholar] [CrossRef]
- Perri, P. Modified randomized devices for Simmons’ model. Model Assist. Stat. Appl. 2008, 3, 233–239. [Google Scholar] [CrossRef]
- Lee, C.; Sedory, S.; Singh, S. Estimating at least seven measures of qualitative variables from a single sample using randomized response technique. Stat. Probab. Lett. 2013, 83, 399–409. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, G. Multi-category parallel models in the design of surveys with sensitive questions. Stat. Interface 2013, 6, 137–142. [Google Scholar] [CrossRef]
- Greenberg, B.; Kuebler, R.; Abernathy, J.; Horvitz, D. Application of the randomized response technique in obtaining quantitative data. J. Am. Stat. Assoc. 1971, 66, 243–250. [Google Scholar] [CrossRef]
- Eriksson, S. A new model for randomized response. Int. Stat. Rev. 1973, 41, 40–43. [Google Scholar] [CrossRef]
- Pollock, K.; Bek, Y. A comparison of three randomized response models for quantitative data. J. Am. Stat. Assoc. 1976, 71, 884–886. [Google Scholar] [CrossRef]
- Eichhorn, B.; Hayre, L. Scrambled randomized response methods for obtaining sensitive quantitative data. J. Stat. Plan. Inference 1983, 7, 307–316. [Google Scholar] [CrossRef]
- Bar-Lev, S.; Bobovitch, E.; Boukai, B. A note on randomized response models for quantitative data. Metrika 2004, 60, 255–260. [Google Scholar] [CrossRef]
- Gjestvang, R.; Singh, S. A new randomized response model. J. R. Stat. Soc. B 2006, 68, 523–530. [Google Scholar] [CrossRef]
- Saha, A. A simple randomized response technique in complex surveys. Metron 2007, LXV, 59–66. [Google Scholar]
- Singh, S.; Kim, J. A pseudo-empirical log-likelihood estimator using scrambled responses. Statist. Probab. Lett. 2007, 81, 345–351. [Google Scholar] [CrossRef]
- Huang, K. Estimation for sensitive characteristics using optional randomized response technique. Qual. Quant. 2008, 42, 679–686. [Google Scholar] [CrossRef]
- Bouza, C. Ranked set sampling and randomized response procedures for estimating the mean of a sensitive quantitative character. Metrika 2009, 70, 267–277. [Google Scholar] [CrossRef]
- Diana, G.; Perri, P. A new scrambled response models for estimating the mean of a sensitive quantitative character. J. Appl. Stat. 2010, 37, 1875–1890. [Google Scholar] [CrossRef]
- Diana, G.; Perri, P. Calibration-based approach to sensitive data: A simulation study. J. Appl. Stat. 2012, 39, 53–65. [Google Scholar] [CrossRef]
- Gupta, S.; Shabbir, J.; Sehra, S. Mean and sensitivity estimation in optional randomized response models. J. Stat. Plan. Inference 2010, 140, 2870–2874. [Google Scholar] [CrossRef]
- Odumade, O.; Singh, S. An alternative to the Bar-Lev, Bobovitch, and Boukai randomized response model. Sociol. Methods Res. 2010, 20, 1–16. [Google Scholar] [CrossRef]
- Arcos, A.; Rueda, M.; Singh, S. A generalized approach to randomised response for quantitative variables. Qual. Quant. 2015, 49, 1239–1256. [Google Scholar] [CrossRef]
- Fox, J.; Tracy, P. Randomized Response: A Method for Sensitive Survey; Sage Publication, Inc.: Thousand Oaks, CA, USA, 1986. [Google Scholar]
- Chaudhuri, A.; Mukerjee, R. Randomized Response: Theory and Techniques; Marcel Dekker, Inc.: New York, NY, USA, 1988. [Google Scholar]
- Chaudhuri, A. Randomized Response and Indirect Questioning Techniques in Surveys; Chapman & Hall: London, UK, 2011. [Google Scholar]
- Chaudhuri, A.; Christofides, T. Indirect Questioning in Sample Surveys; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Chaudhuri, A.; Christofides, T.; Rao, C. Data Gathering, Analysis and Protection of Privacy through Randomized Response Techniques: Qualitative and Quantitative Human Traits; Elsevier: Amsterdam, The Netherlands, 2016; Volume 34. [Google Scholar]
- Scheers, N.; Dayton, C. Improved estimation of academic cheating behavior using the randomized response technique. Res. High. Educ. 1987, 26, 61–69. [Google Scholar] [CrossRef]
- Blair, G.; Imai, K.; Zhou, Y. Design and Analysis of randomized response technique. J. Am. Stat. Assoc. 2005, 110, 1304–1319. [Google Scholar] [CrossRef]
- Van den Hout, A.; van der Heijden, P.; Gilchrist, R. The logistic regression model with response variables subject to randomized response. Comput. Stat. Data Anal. 2007, 51, 6060–6069. [Google Scholar] [CrossRef]
- Fox, J.; Veen, D.; Klotzke, K. Generalized Linear Mixed Models for Randomized Responses. Methodology 2019, 15, 1–18. [Google Scholar] [CrossRef]
- Hsieh, S.; Lee, S.; Shen, P. Logistic regression analysis of randomized response data with missing covariates. J. Stat. Plan. Inference 2010, 140, 927–940. [Google Scholar] [CrossRef]
- Singh, S.; Joarder, A.; King, M. Regression analysis using scrambled response. Aust. N. Z. J. Stat. 1996, 38, 201–211. [Google Scholar] [CrossRef]
- Van der Hout, A.; Kooiman, P. Estimating the linear regression model with categorical covariates subject to randomized response. Comput. Stat. Data Anal. 2006, 50, 3311–3323. [Google Scholar] [CrossRef]
- Arnab, R. Non-negative variance estimator in randomized response surveys. Commun. Stat. Theory Method 1994, 23, 1743–1752. [Google Scholar] [CrossRef]
- Barabesi, L.; Diana, G.; Perri, P. Design-based distribution function estimation for stigmatized populations. Metrika 2013, 76, 919–935. [Google Scholar] [CrossRef]
- Hájek, J. Comment on An essay on the logical foundations of survey sampling by Basu, D. In Foundations of Statistical Inference; Godambe, V.P., Sprott, D.A., Eds.; Springer: Berlin/Heidelberg, Germany, 1971. [Google Scholar]
- Särndal, C.E.; Swensson, B.; Wretman, J. Model Assisted Survey Sampling (Springer Series in Statistics); Springer: Berlin/Heidelberg, Germany, 1992. [Google Scholar]
- Binder, D. On the Variances of Asymptotically Normal Estimators from Complex Surveys. Int. Stat. Rev. Rev. Int. Stat. 1983, 51, 279–292. [Google Scholar] [CrossRef]
- Lumley, T. Package ‘survey’: Analysis of Complex Survey Samples. Available online: https://cran.r-project.org/web/packages/survey/index.html (accessed on 15 December 2020).
- Tukey, J. Bias and confidence in not-quite large samples. Ann. Math. Stat. 1958, 29, 614. [Google Scholar]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Wolter, K. Introduction to Variance Estimation; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Arnab, R.; Cobo, B. Variance jackknife estimation for randomized response surveys: A simulation study and an application to explore cheating in exams and bullying. Comput. Math. Methods 2020, 2, e1073. [Google Scholar] [CrossRef]
- Rueda, M.; Cobo, B.; Perri, P.F. Randomized response estimation in multiple frame surveys. Int. J. Comput. Math. 2020, 97, 189–206. [Google Scholar] [CrossRef]
- Booth, J.; Butler, R.; Hall, P. Bootstrap methods for finite populations. J. Am. Stat. Assoc. 1994, 89, 1282–1289. [Google Scholar] [CrossRef]
- Antal, E.; Tillé, Y. A direct bootstrap method for complex sampling designs from a finite population. J. Am. Stat. Assoc. 2011, 106, 534–543. [Google Scholar] [CrossRef]
- Antal, E.; Tillé, Y. A new resampling method for sampling designs without replacement: The doubled half bootstrap. Comput. Stat. 2014, 29, 1345–1363. [Google Scholar] [CrossRef]
- Zhao, P.; Haziza, D.; Wu, C. Survey weighted estimating equation inference with nuisance functionals. J. Econom. 2020, 216, 516–536. [Google Scholar] [CrossRef]
- Wu, C.; Thompson, M.E. Resampling and Replication Methods. In Sampling Theory and Practice. ICSA Book Series in Statistics; Springer: Berlin/Heidelberg, Germany, 2020. [Google Scholar] [CrossRef]
- Goldfeld, K. Package ‘simstudy’: Simulation of Study Data. Available online: https://cran.r-project.org/web/packages/simstudy/index.html (accessed on 15 December 2020).
- Tillé, Y.; Matei, A. Package ‘sampling’: Survey Sampling. Available online: https://cran.r-project.org/web/packages/sampling/index.html (accessed on 15 December 2020).


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).