A statistical study of the correlation between consecutive staying times in states has been carried out. We have detected that the correlations are not significant in some cases, and, in the others, it is weak, with a significance level. The evolution of the system is governed by a stochastic process , with denoting the state of the system at time t, state-space , and initial state 0, .
3.1. Fitting PH Distributions
The staying times in transient states are known for every patient, and a resume of these is given in
Table 1. The application of the state-space model initiates fitting a distribution to the times in states. An exhaustive study has been carried out fitting known distributions to the data and measuring the goodness-of-fit to a
significance level. By using the computational program R, the more frequent distributions have been fitted (exponential, Weibull, lognormal, and others). There is no distribution appropriate for states
, and they are rejected. For states
, the lognormal distribution is not rejected, but this distribution is not easy to manage in calculations. For getting an applicable model, it is convenient to consider the PH distributions as the ones for being fitted to the staying times.
The following are the representations of the
distributions fitted to the transient states, using the EMpht algorithm of Asmussen, Nerman, and Olsson [
27]. We denote by
the initial vector,
the transition rate matrix between transient phases, and
the absorption vector for state
. The numbers are approximated until
.
The Kolmogorov-Smirnov test is applied to the fittings, and they are not rejected with a significance level. In the application of the EMpht algorithm, the number of phases for the fitted distribution is previously selected, and we proceed from the lower number of phases: if the fit is good, it finishes; if not, a new phase is added, and so on, until we get a good fit.
3.2. The Markov Process
The Markov process
with state-space
is a multidimensional process, the generator is denoted by
Q, and it is calculated from the representations of the PH distributions and the proportions in
Table 2. It is constructed by blocks, corresponding to the phases of the states. The expression of generator
Q takes the form:
The subindices in the blocks are the order of the matrices. Block
A indicates the rate transitions among transient states and block
B the ones among the transient and absorbent states. Block 0 is a matrix in which entries are null. Blocks
are, in turn, block matrices:
Matrix
A is formed by blocks of different orders. The transition probability matrix
is calculated solving the matrix equation
under the initial condition
(identity matrix), and the final expression is
,
. This equation is solved by computational calculations, and it can also be written by blocks:
being
Once the initial vector is determined, the components of probability vector are the transition probabilities at time t among the phases of the involved PH distributions. Then, the transition probability function between states is obtained adding the components 3rd and 4th of vector ; adding components 5th to 8th the rate between states is obtained, and so with the other transitions.
The entries of the block , in matrix are the transition probability functions among the phases of the states at time t, and, similarly, the entries of matrix are the transition probability functions among the phases of the transient states and the absorbent states at time t.
Vector
is formed by the occupancy probability at time
t of the phases corresponding to the transient states. These probabilities are calculated as we have said above. The components of vector
are the occupancy probabilities of the states
, respectively, at time
t. Given that the process initiates in state 0, and the initial vector of the staying time is
, the process initiates in phase 1 of state 0, and the initial vector is
3.3. Survival Probability
In
Section 2.2, the empirical survival function has been calculated, and now the survival function
associated with the state-space model is calculated and compared with the empirical one.
Considering the progression as the fatal state, a patient has survived at time
t if, until this time, it has not visited state
P. The survival probability at time
t, denoted by
, is the
The numerical values of this function are calculated by using computational programs. In order to compare the empirical and estimated functions, a partition in the observation period is selected (
), the following up of the patients will be performed in these points. They are selected for
in the equidistant points
,
. The functions
and
are plotted in
Figure 2. The Kolmogorov-Smirnov statistics is
, and the fitting is not rejected with a
significance level.
In
Table 3, the estimated survival times in the states and in the system in the partition points are given. The last column indicates the survival times for the cohort, and it is very high; after 4000 days, more than
have survived. In columns 2 to 5, the survival values in states are given. In state 0, nearly
of the patients survive the first 800 days; from then on, the decreasing is fast. In state 1, nearly
of the patients survive the first 800 days; in state 2, the numbers are shorter than in state 1, but, in state 3, the survival is greater than in the previous states. From
in advance, the differences among the numbers are minor and tend to be similar. The duration of the staying times in states can be due to different causes that are not analyzed in the present study, but we have observed that the survival in state 3 is greater than in the previous ones, maybe due to the effectiveness of the treatments.
3.4. Mean Time in States
The empirical mean time in states is calculated following up the trajectory of the patients and measuring the time in the successive occupied states until the final of the observation, when one of the absorbent states is reached. Every patient
u initiates the trajectory at time
in state
, and, after a time, it occupies a state
(or it is absorbed) and stays in it at an interval of time
. The initial state 0 is common in every patient, so index
i is suppressed, and the staying time in state
j for patient
u until
(partition point) is denoted
and defined as follows:
Using this expression, the observed times in states and in the system until time
are calculated using computational calculations for all patients, and then, the corresponding mean times; these values are in columns 2 to 6 in
Table 4. This calculation of the times in states is the discrete approximation to the way in which these ones are calculated in an absorbent Markov process.
The estimated expected time that the process stays in phase
j at time
t, given that the initial phase is
i, is the entry
in the matrix
The entry
in matrix
is the mean time in phase
j starting from phase
i, and in matrix
is the expected absorption time for phase
j starting from phase
i. The algebraic expression of the fundamental matrix of the process
is:
The entries of matrices
can be grouped by blocks according to the phases of the corresponding states; in terms of the blocks, the orders of
are
and
, respectively. Given that the staying times in states follow PH distributions, the previous expression gives the staying mean times in the virtual phases, that do not have any physical significance, so, for calculating the mean times in states, it is necessary to operate with the phases. The initial vector is
, of order 12; then, for calculating the mean times in states, it is sufficient to consider the first row in matrix
. We illustrate how the mean time in states are calculated for state 1, starting from 0. This is performed introducing several random variables related to the staying time in the transient phases of the states starting from the initial phases of the system. Let
, be the random variable indicating the staying time in phase
v in state 1 at time
t given that the process initiates in any phase in state 0. Let
Y be the discrete random variable indicating the initial phase, and it takes the values
. The first six elements of the first line in matrix
are:
where the two first components correspond to state 0, and the last four to state 1. Given the initial conditions, the mean time at time
t in state 1 is:
Denoting by
the random variable “time in state 1 at time
t starting from state 0”, can be written as:
and the mean value is:
The mean times in states until time
t in state
j are denoted by
,
, and they are calculated in the same way as
. The mean time in the system until time
t is:
These estimated values
in the partition points form column 7 in
Table 4. The calculations for obtaining the values
have been simplified due to the form of the initial value. If it is not the case, and the initial vector is, for example,
,
, the mean time in state
is calculated using the above expressions, and it depends on the two first rows in matrix
.
The empirical mean time in states and in the system for the total of patients during the observation period, and the mean time in the system according to the model, are given in the last row of
Table 4. The mean time in state 0 is more than two years and a half. The mean times in states
decrease. In state 3, the mean time in the system is greater than in the previous ones, maybe due to the effect of the treatments.
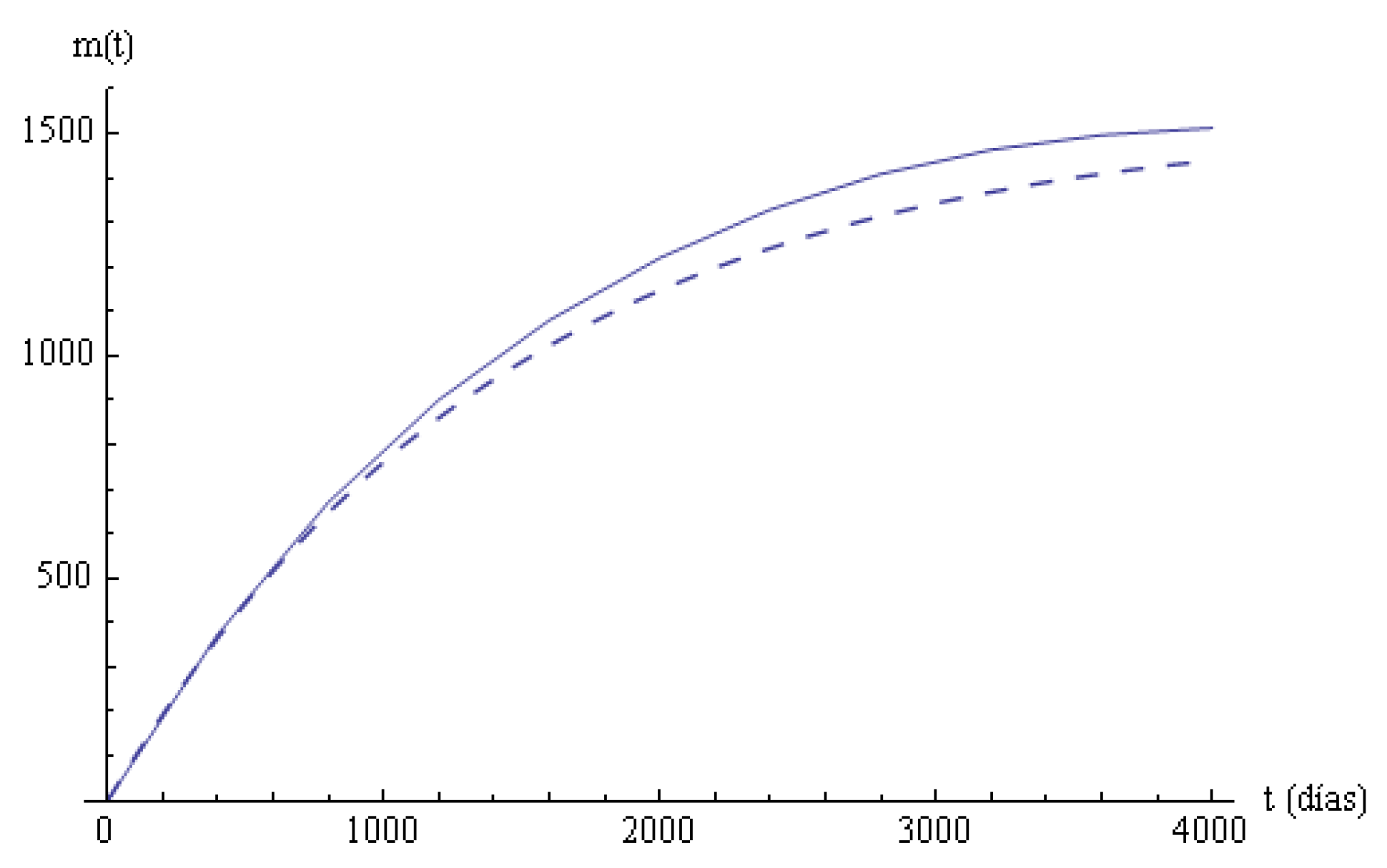
Columns 6, 7 in
Table 4 are the empirical and estimated mean times until time
t in the system. A linear regression model
is applied to compare these mean values, with
Y representing the estimated variable
and
X the empirical variable
. Parameter
b is 0 since the initial point is
for
X and
Y, and parameter
a with an adjusted determination coefficient
; the
p-value of the corresponding test is much smaller than
, and the fit cannot be rejected. In
Figure 3, the two mean times in the systems are plotted.
The longitudinal study of the survival times in states and in the system for the total of patients under bladder cancer considering a Markovian state-space model has been performed, the staying times are estimated and compared with the corresponding empirical values, and the fittings are acceptable in statistical terms. The survival function (
Figure 2) and the mean times in states (
Figure 3) illustrate the good fitting of these measures. A more detailed study, based on
Figure 1, can be performed considering the well-differenced trajectories of the patients to the two absorbent states, and these present different characteristics that will be studied in the following sections. The notation of the present section is preserved. The diagram of transition among states presenting clearly the two trajectories in the disease is shown in
Figure 1.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}