Abstract
In this paper, a new method of measurement matrix optimization for compressed sensing based on alternating minimization is introduced. The optimal measurement matrix is formulated in terms of minimizing the Frobenius norm of the difference between the Gram matrix of sensing matrix and the target one. The method considers the simultaneous minimization of the mutual coherence indexes including maximum mutual coherence , t-averaged mutual coherence and global mutual coherence , and solves the problem that minimizing a single index usually results in the deterioration of the others. Firstly, the threshold of the shrinkage function is raised to be higher than the Welch bound and the relaxed Equiangular Tight Frame obtained by applying the new function to the Gram matrix is taken as the initial target Gram matrix, which reduces and solves the problem that would be larger caused by the lower threshold in the known shrinkage function. Then a new target Gram matrix is obtained by sequentially applying rank reduction and eigenvalue averaging to the initial one, leading to lower. The analytical solutions of measurement matrix are derived by SVD and an alternating scheme is adopted in the method. Simulation results show that the proposed method simultaneously reduces the above three indexes and outperforms the known algorithms in terms of reconstruction performance.
1. Introduction
Compressed sensing (CS) [1] can sample the sparse or compressible signals at a sub-Nyquist rate, which brings great convenience for data storage, transmission, and processing. By adopting the reconstruction algorithms, the signal can be exactly reconstructed from the sampled data. As a marvel way of signal processing, CS is applied in different fields such as image encryption [2], wideband spectrum sensing [3], wireless sensor network data processing [4], etc.
The original signal is assumed to have a sparse representation in a known domain () as where is the dictionary matrix and is a -sparse signal. The incomplete measurement is obtained through the linear model
where () is called the measurement matrix and is the sensing matrix.
Some specific properties of have great impacts on the reconstruction performance. In [5,6], spark and restricted isometric property (RIP) are respectively proposed as the sufficient conditions on to recovery guarantee. However, computing the spark of a matrix has combinatorial complexity and certifying RIP for a matrix requires combinatorial search, that is to say, these tasks are NP-hard and difficult to accomplish. To a large extent, the coherence between and reflects the performance of meeting the above conditions. Actually, the coherence is equivalent to the mutual coherence of . Since the mutual coherence can be easily manipulated to provide recovery guarantees, it is commonly used to measure the performance of . The frequently-used mutual coherence indexes include the maximum mutual coherence [7], t-averaged mutual coherence [8] and global mutual coherence [9], which respectively represent the maximum, the average and the sum of squares of the correlation between any distinct pair of columns in .
The first attempt to consider the optimal design of is given in [8]. The simulation results carried out in [8] show that the optimized leads to smaller and a substantially better CS reconstruction performance is obtained. Then the optimization of becomes an important issue in CS. The recent works try to find the optimal which has excellent performance in reducing the mutual correlation by minimizing the Frobenius norm of the difference between the Gram matrix and the target Gram matrix . The main work focuses on designing and finding the best .
In [8], is obtained by shrinking the off-diagonal entries in . The shrinkage technique reduces but it is time-consuming. Furthermore, is still large, which ruins the worst-case guarantees of the reconstruction algorithms. A suitable point between the current solution and the one obtained using a new shrinkage function is chosen to design the in [10]. It is of very strong competitiveness in and . However, the optimal point is hard to determine and the unsuitable point may seriously degrade the algorithm’s performance. In [9], is obtained by averaging the eigenvalues of . Simulation results show that is reduced effectively but reducing and is hard to be guaranteed, which means and may maintain large values. Duarte-Carajalino and Sapiro [11] set as an identity matrix. Since is overcomplete and cannot be an identity matrix, simply minimizing the difference between and does not imply low [12]. In [13,14,15,16,17], is chosen from a set of relaxed Equiangular Tight Frames (ETF) [18]. The set can be formulated as where denotes the Welch bound [19] and denotes the th entry of . However, the maximum absolute value of off-diagonal entries in is almost always greater than . In this case, the optimization usually implies a solution with low but high . In summary, the target Gram matrices mentioned above only focus on a certain mutual coherence index, and fail to take into account , and simultaneously. When a certain index is targeted, the other indexes may not decrease significantly or even increase. Therefore, is not ‘good’ enough and the reconstruction performance is well below par.
After designing , the next step is to find the ‘best’ by approaching to . In [8,9,10,11,17], is obtained by applying SVD to primarily and then the square root of is built as . At last, is obtained by where denotes the Moore Penrose pseudoinverse. This kind of method is intuitive, but the generalized pseudoinverse poses problems of calculation accuracy and robustness [15]. In [14,15], gradient algorithm and quasi-Newtonian algorithm are respectively utilized to attain . Firstly, the cost function with as the variable is constructed. Then the search direction is determined by the derivative of . Finally, is obtained with a fixed step size. However, choosing a suitable step size which has a great influence on the accuracy of the solution requires a lot of comparison work. Moreover, the gradient algorithm and quasi-Newtonian algorithm cannot converge until a certain number of iterations is accomplished, resulting in high computational cost. In [11,16], the method for designing shares the same concept as K-SVD [20], that is to update a matrix row by row. Eigenvalue decomposition is required to find the square root of the maximum eigenvalue for each row, which results in a significant increase in the calculation. For solving this problem, Hong et al. [16] utilize the power method instead of eigenvalue decomposition. However, the eigenvalue obtained by power method is the one with the largest absolute value. When the eigenvalue is negative, eigenvalue decomposition is still necessary.
The primary contributions of this paper are threefold:
- The new target Gram matrix targets , , and of simultaneously is designed. Firstly, a new shrinkage function whose threshold exceeds is utilized to determine the initial target Gram matrix. Then is obtained by sequentially applying rank reduction and eigenvalue averaging to the initial matrix.
- Analytical solutions of the measurement matrix to minimize the difference between and are derived by SVD.
- Based on alternating minimization, an iterative method is proposed to optimize the measurement matrix. The simulation results confirm the effectiveness of the proposed method in decreasing the mutual coherence indexes and improving reconstruction performance.
The remainder of this paper is organized as follows. Some basic definitions related to mutual coherence indexes and frames are described in the next section. The main results are presented in Section 3, where the solutions to the design are characterized and a class of the solutions to the optimal is derived in detail. The procedure of our method and the discussion can be also found in Section 3. In Section 4, simulations are carried out to confirm the effectiveness of the proposed method. In the end, the conclusion is drawn.
2. Mutual Coherence Indexes and ETFs
2.1. Mutual Coherence Indexes
Rewrite where and . Denote the entry at the position of row and column in , where . Here, we quote the definitions of the mutual coherence indexes as that presented by Donoho [7], Elad [8], and Zhao [9].
Definition 1.
For a matrix, the maximum mutual coherenceis defined as the largest absolute and normalized inner product between all columns inthat can be described as
Definition 2.
For a matrix, the t-averaged mutual coherenceis defined as the average of all absolute and normalized inner products between different columns inthat are above t and can be described as
Definition 3.
For a matrix, the global mutual coherenceis defined as the sum of squares of normalized inner products between all columns inthat can be described as
As shown in [5], the original signal can be exactly reconstructed as long as . The conclusion is true from a worst-case standpoint which means that does not do justice to the actual behavior of sparse representations. Therefore, Elad considers that an “average” measure of mutual coherence, namely , is more likely to describe its true behavior. Different from the previous two indexes, reflects the overall property of .
In fact, the purpose of reducing the mutual coherence indexes of is to attain that meets the following requirements: (1) The maximum absolute value of off-diagonal entries in is sufficiently small; (2) The number of off-diagonal entries with large absolute value is minimized; (3) The average of off-diagonal entries with large absolute value is as small as possible. However, when a certain mutual coherence index is targeted solely, we cannot guarantee that the obtained will fully meet the requirements. Therefore, the decrease of a certain index does not always mean better and improved reconstruction performance. When the three indexes are reduced simultaneously, the requirements are better satisfied and better performance is obtained.
2.2. ETFs
It is shown in [19] that of is lower bounded by
The bound is achievable for ETF. Here, we recall the definition of ETF [18].
Definition 4.
Letbe amatrix whose columns are. The matrixis called an equiangular tight frame if it satisfies three conditions
- (1)
- Each column has a unit norm:for.
- (2)
- The columns are equiangular. For some nonnegative, we havewhenand.
- (3)
- The columns form a tight frame. That is,whereis anidentity matrix.
Sustik et al. [18] show that a real () ETF exists on if holds. Furthermore, and must be odd integers when , , and must be an odd number and the sum of two squares respectively when . Fickus et al. [21] surveys some known construction of ETFs and tabulates existence for sufficiently small dimensions. The above studies show that and must meet some exacting requirements when an ETF is available for . However, it is really difficult to meet the requirements in practice, which means the maximum absolute value of the off-diagonal entries in is usually significantly larger than .
3. The Proposed Method
The off-diagonal entries in actually are the inner products between different columns in . Reducing those entries is likely to lead to lower mutual coherence indexes and better performance. The most straightforward approach is to replace large off-diagonal values with small ones. However, it is impossible to solve from a certain because of the inequality of rank between and when the approach is adopted. Therefore, a feasible approach is to minimize the difference between and that can be formulated as
where . This problem can be solved by alternating minimization strategy [14,16], which iteratively minimizes (5) to find the desired . The idea is to update and alternatively and repeat this proceeding until a stop criterion is reached. In this section, we design firstly and then derive the analytical solutions of . Finally, an iterative method is proposed to optimize the measurement matrix based on alternating minimization.
3.1. The Design of
It can be seen from (5) that plays an important role in measurement matrix optimization. In recent works, is frequently set as the relaxed ETF matrix, which is obtained by applying the following shrinkage function
where for and . Such a scheme in designing guarantees that the off-diagonal entries with large value of will be intensively constrained, which means lower and .
Recall from Section 2.2 that the Welch bound is not achievable for in most cases. As shown in [14,16], different yields different results and is not the optimal value. Li [22] et al. found that a smaller is available when is slightly larger than . Inspired by [22], we propose an improved shrinkage function which divides the entries in into three segments through two thresholds. One of the thresholds is and the other is larger than . The function is as follows
where and . As can be seen from Equation (7), the maximum absolute value of off-diagonal entries in is raised from to . According to the previous analysis, the new function is likely to lead to a further reduction in while maintaining the advantage of Equation (6) with respect to .
After shrinkage, becomes full rank generally [8], that is . However, the rank of is identically equal to . Thus, we consider mending this by forcing a rank . A new target Gram matrix, denoted as , is obtained by solving
The solutions to this problem are given by Theorem 1 below.
Theorem 1.
Letbe the matrix obtained by applying the shrinkage operation shown as Equation (7) toandbe the eigendecomposition of.is orthonormal with dimensionandwith. The solutions of the minimization problem defined by (8) are characterized by
where.
Proof.
Denote where . Let be an SVD of , where and are unitary. Then can be rewritten as
Denote . By substituting with , can be rewritten as a function of matrix . Let be the derivative of with respect to . The optimal should satisfy . Equivalently, we have
It then follows from that
Substituting Equation (12) into Equation (10), we obtain
It turns out from the unitary invariance with Equation (13) that
With a few manipulations, we conclude that the solution of (8) is equivalent to solving
where denotes the matrix trace operation. Noting that and , the problem in (15) is equivalent to
Denote and rewrite as where for . Rewrite as , where denotes a unit vector with the ith entry is equal to 1 for . Then, it is easy to obtain that
Let be the jth entry of . It can be shown with some manipulations that the problem in (16) is equivalent to
With and , it is straightforward that reaches the maximum value only if for . In this case, and hold for . Rewrite as where . Accordingly, all of the entries in both and are zero. Noting that is unitary, it can be shown that and are unitary. Hence, we have
As can be seen, the rank of is equal to . The proof is then completed. □
After the operation of rank reduction, the rank of is equal to that of . Additionally, is most similar to in terms of Frobenius norm. Inspired by [9], we reduce the sum of squares of all off-diagonal values of , namely , by eigenvalue averaging. When minimizing the difference between and , a smaller is more likely to lead to a smaller . can be formulated as
where denotes the th entry of and holds for .
Noting that and where , can be rewritten as
Assuming that is invariable, it then follows from the Cauchy BuniakowskySchwarz Inequality that takes the minimum value only if for . Let and , a new target Gram matrix denoted as with equal all non-zero eigenvalues is given by
Recall that is most similar to in terms of Frobenius norm, it means that is of good competitiveness in and . Furthermore, as a variant of , reduces the sum of squares of all off-diagonal values of , leading to a better performance in minimizing . Therefore, is more likely to be an ideal solution of target Gram matrix which leads to better , , and simultaneously.
3.2. The Analytical Solutions of
After obtaining the target Gram matrix , the next step of the optimization is to find the best . To handle the problem, we try to find the optimal solution by minimizing the difference between and as
Let be an SVD of , where and are unitary. Similarly, Let be an SVD of , where and are unitary. The solutions to this problem are given by Theorem 2 below.
Theorem 2.
Letbe the matrix shown as Equation (21) andbe theth principal submatrix of. Then the solutions of the minimization problem defined by (22) are characterized by
whereis an arbitrary unitary matrix.
Proof.
Assume that the off-diagonal values of and are non-zero, can be written as
By substituting in (22) with Equation (24), it can be shown with some manipulations that the solutions of the problem in (22) are equivalent to the solutions of
Let and be the ith diagonal entry of . Denote . With further manipulations, we simplify (25) to
Obviously, the minima are achievable only if holds and takes the maximum value. Let and be the th entry of where . Noting that the top diagonal entries of are all equal to , we have
It is worth noting that and where . Hence, it is clear that the maxima of are reached when takes the maximum value for . Rewrite as where . Since holds for , we have and , accordingly. As is a unitary matrix, it is easy to verify that and are both unitary matrices. Then it follows that
Substituting Equation (28) into Equation (24), the optimal solution is obtained by
The proof is then completed. □
3.3. Comments
According to Section 3.1 and Section 3.2, the procedure for measurement matrix optimization has been summarized in Algorithm 1.
| Algorithm 1. The proposed optimization method. |
| Input: Dictionary matrix which has an SVD form of , number of iterations Iter, constant , Welch bound . Output: Measurement matrix . Initialization: Initialize to a random matrix, initial to a unitary matrix. For to do
return |
Noting that plays an important role in measurement matrix optimization, Algorithm 1 takes , and into consideration simultaneously when designing the . By minimizing (5), the Gram matrix is most similar to in terms of Frobenius norm, leading to maintain the advantage of in reducing the mutual coherence indexes. Therefore, Algorithm 1 is effective in reducing , , and .
In the shrinkage function, a different threshold yields different results. Inspired by [22], we propose a shrinkage function shown as (7) which has a new threshold . We have not derived the optimal value of in theory, but setting to a proper value can also lead to a moderate result.
After averaging the eigenvalues of , the first term on the right part of (20) is minimized. However, the diagonal entries of change accordingly. Hence, we can’t assure that reaches the minima, that is to say, may not be the optimal solution in terms of . Fortunately, we find that the change of is much greater than that of in (20), which means our approach is effective in reducing .
The proposed algorithm is an iterative one. The main complexity of Algorithm 1 for each iteration is located at steps 1, 2, 4, and 7. For those steps, the flops required are , , , and respectively. Hence, the complexity of Algorithm 1 is approximate to be . Since the complexity for similar algorithms in [8,16,17] which apply eigenvalue decomposition or SVD is no less than , the proposed algorithm has not increased the complexity significantly.
4. Simulation Results and Discussion
In this section, we conduct simulations to predetermine a suitable firstly. Then, we examine the mutual coherence indexes and reconstruction performance of the proposed method and compare them with the well-established similar algorithms given in [8,16,17] by presenting the empirical results. Last, we verify the effectiveness of our method with various measurement matrices and dictionary matrices. The iteration number Iter is set to 100 and t is set to . For a given dictionary matrix , has a sparse representation as where is -sparse and each non-zero entry is randomly positioned with a Gaussian distribution of i.i.d. zero-mean and unit variance. Orthogonal Matching Pursuit (OMP) [23] algorithm is employed in signal reconstruction. Denote the reconstruction error where is the reconstructed signal. The reconstruction is identified as a success, called exact reconstruction, provided . Denote the percentage of successful reconstruction. In Section 4.1, Section 4.2 and Section 4.3, and are both Gaussian random matrices.
4.1. The Choice of
Since the analytical solution of is extremely difficult, here, we conduct a serious of simulations to find a suitable . Figure 1 illustrates the change tendency of mutual coherence indexes and with argument . We fix the row number of to 28, the sparsity to 8, and varies from 0 to 0.16. The experiment is performed for 1000 random sparse ensembles and the results are recorded.
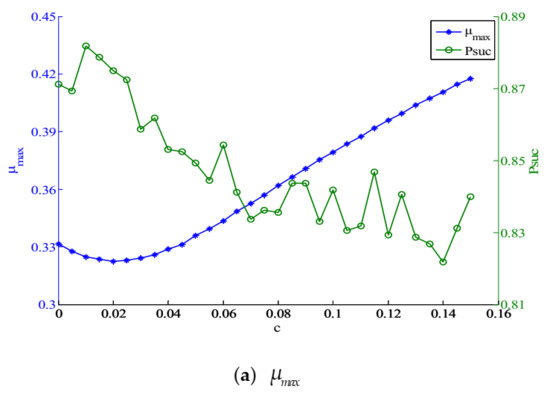
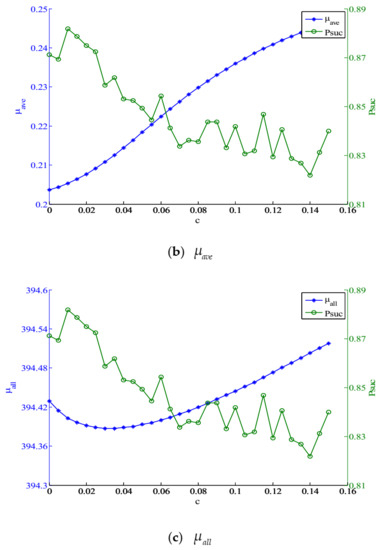
Figure 1.
(a) and versus ; (b) and versus ; (c) and versus , both with and .
When , the shrinkage function shown as (7) is the same as (6). As can be seen from the graphs, when increases, increases, and decrease first and then increase, increases firstly and then decreases. and reach the minima when and respectively. It is worth noting that appropriate increase of leads to decrease of and but increase of . When , better and are obtained and the loss in is tolerable. Moreover, reaches the maxima. Therefore, 0.01 may be a moderate value for and is set to 0.01 in the simulations in Section 4.2, Section 4.3 and Section 4.4.
4.2. Comparing the Mutual Coherence Indexes
This section presents a series of simulations to compare our method with algorithms given in [8,16,17] on the three mutual coherence indexes of obtained by where is the optimized measurement matrix. For convenience, each method is denoted as Propose, Elad, Hong, and Entezari. The down-scaling factor for Elad is set to 0.95. The inner iteration number for Hong is set to 2, which means K-SVD is applied twice in every updating of . The point is set to 0.5 to update the in Entezari.
Figure 2 illustrates the change tendency of mutual coherence indexes with iteration number for . As can be seen from the figure, the indexes corresponding to different algorithms all change monotonously with the iteration number. When and converge, the number of iterations required by our method is almost equal to that of Hong and significantly less than that of Elad. When converges, the number of iterations required by our method is equivalent to that of Entezari and significantly less than that of Hong and Elad.
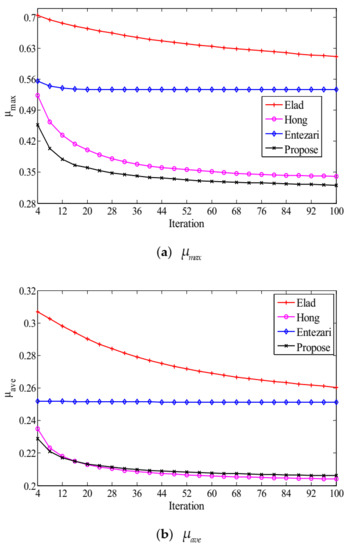
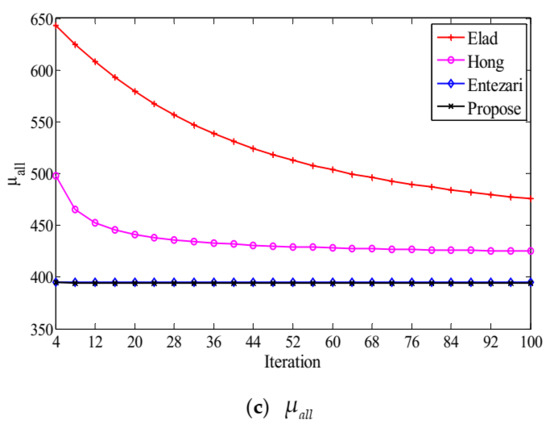
Figure 2.
The convergence results: (a) evolution of , (b) and (c) the evolution of , all versus iteration number, where .
Figure 3 presents the histogram of the absolute off-diagonal values of for . It is seen from the figure that Elad and Entezari have long tails, showing that the number of off-diagonal values that exceed 0.34 is relatively large. The tail of Hong is shorter than that of Elad and Entezari, and reaches the maximum of 0.34. Compared with Hong, our method has a shorter tail which reaches the maximum of 0.32 and has more off-diagonal values below the (0.1662).
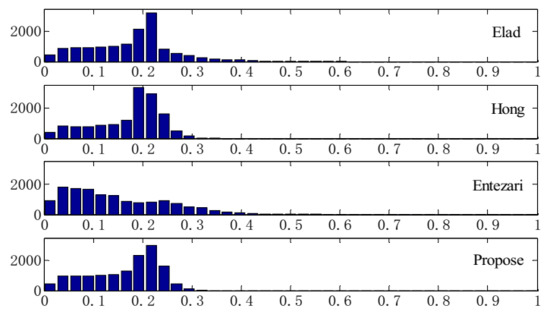
Figure 3.
Histogram of the absolute off-diagonal values of for .
Table 1, Table 2 and Table 3 present , , and by Elad, Hong, Entezari, and our method versus measurement dimension respectively. From Table 1, it can be observed that the of our method is significantly less than that of Elad and Entezari, and less than Hong, which means our method is effective in reducing the maximum mutual coherence. In Table 2, we see that the of our method is significantly less than that of Elad and Entezari, with an advantage of more than 0.03. It is worth noting that the of our method is slightly larger than Hong. In Table 3, the of our method is significantly less than that of Elad and Hong, with an advantage of more than 70 and 20 respectively. On the other hand, the of our method is almost the same as Entezari.

Table 1.
by Elad, Hong, Entezari, and proposed method versus measurement dimension .
Table 2.
by Elad, Hong, Entezari, and proposed method versus measurement dimension .
Table 3.
by Elad, Hong, Entezari, and proposed method versus measurement dimension .
In conclusion, while effectively reducing and , our method can maintain a small at the same time. Additionally, the number of iterations required for the convergence of each index of our method is significantly less than that of Elad. Therefore, from the view of mutual coherence indexes, the measurement matrix obtained by our method has better properties than the other three methods. This coincides with the theoretical results obtained in the Section 3.
4.3. Comparing the Reconstruction Performance
Case 1.
Comparison of thein the noiseless case.
In this case, we conduct two separate CS experiments, first by fixing and varying from 12 to 44 and second by fixing and varying from 4 to 20. Each experiment is performed for 1000 random sparse ensembles and the number of exact reconstruction is recorded.
Figure 4 and Figure 5 reveal that the of our method is the highest, which indicates its superiority over the other three methods.
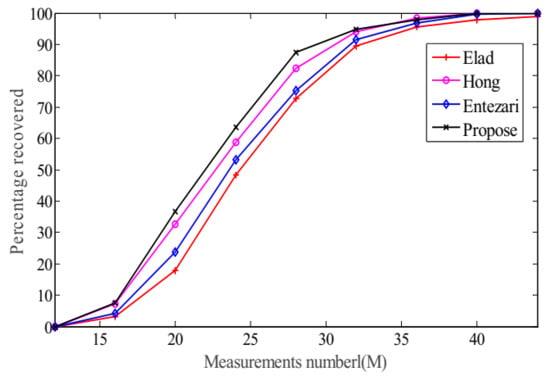
Figure 4.
The change tendency of with while in the noiseless case.
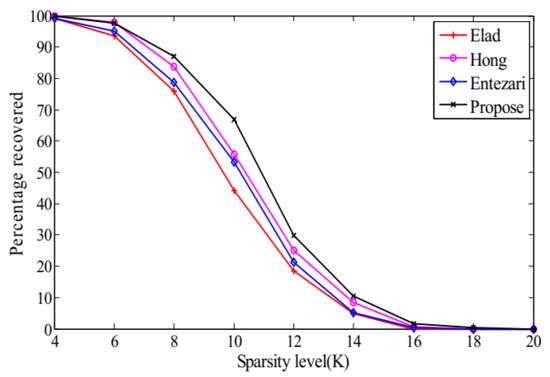
Figure 5.
The change tendency of with while in the noiseless case.
Case 2.
Comparison of thein the noisy case.
To show the robustness of the proposed method in noisy cases we consider the noisy model where is the vector of additive Gaussian noise with zero means. We conduct the experiment by fixing , , and varying SNR from 10 to 50 dB. The experiment is performed for 1000 random sparse ensembles and the average reconstruction error is recorded. From Figure 6, we can see that the reconstruction errors decrease with the increase of SNR, and the error of the proposed method is smaller than that of the others.
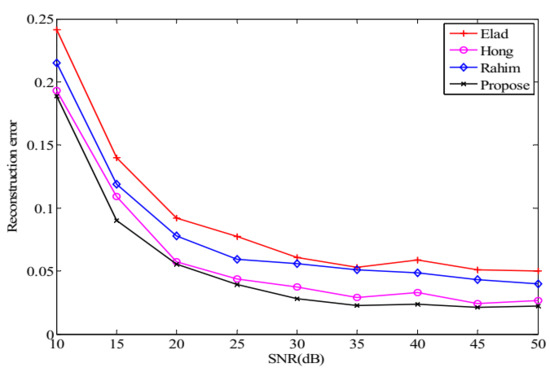
Figure 6.
The change tendency of with SNR while and .
Table 3 presents that of the Entezari is slightly larger than that of our method. It is interesting to note that the number of off-diagonal entries with smaller absolute values in the Entezari is significantly larger than that of our method from Figure 3. Moreover, it can be seen from Table 2 that of Hong is slightly lower than that of our method. However, the simulation results show that our method outperforms the others in terms of reconstruction performance. It is also worthy noting that our method reduces , , and simultaneously, leading to better reconstruction performance in CS. This implies that a single mutual coherence index cannot accurately reflect the actual performance of the methods, and verifies the necessity of using multiple indexes simultaneously in measurement matrix optimization.
4.4. Different Kinds of and Optimized by the Proposed Methods
To analyze the performance of our method with various measurement matrices and dictionary matrices, a serious of simulations are carried out in this section. We choose the measurement matrix as a Gaussian random matrix and a Bernoulli random matrix, and choose the dictionary matrix as a Gaussian random matrix and the DCT matrix, respectively. We compare the mutual coherence indexes and the reconstruction performance before and after optimization. When is the Gaussian random matrix, belongs to and belongs to . When is the DCT matrix, belongs to and belongs to . Each experiment is performed for 1000 random sparse ensembles.
The mutual coherence indexes of different measurement matrices with different dictionary matrices are shown in Figure 7. As seen from the simulations, all the optimized measurement matrices produce smaller , , and than the random ones.
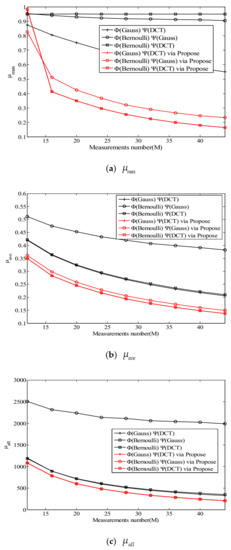
Figure 7.
The evolution of (a) , (b) and (c) , all versus measurements number with different .
Figure 8 and Figure 9 present the reconstruction performance of OMP with the optimized measurement matrices and the random ones. It is seen from the graphs in these figures that all the optimized matrices outperform the random ones in terms of the percentage of exact reconstruction.
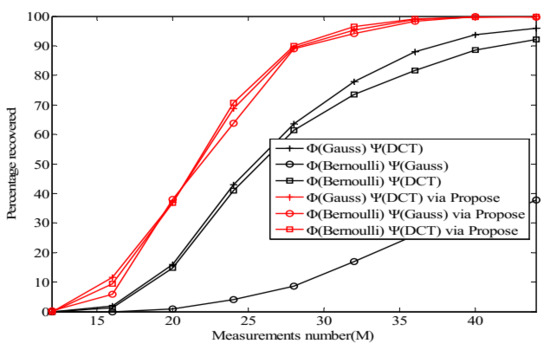
Figure 8.
The change tendency of with while in the noiseless case.
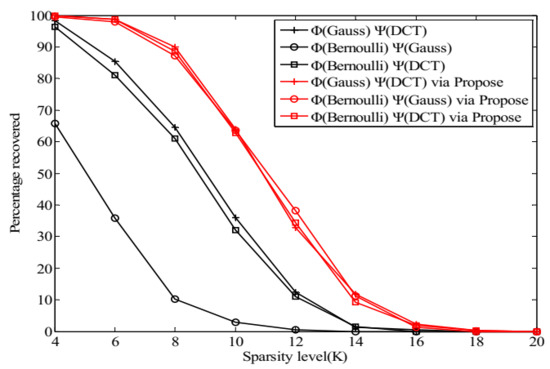
Figure 9.
The change tendency of with while in the noiseless case.
5. Conclusions
This paper focused on the optimization of measurement matrix for compressed sensing. To decrease , , and simultaneously, we designed a new target Gram matrix which was obtained by applying a new shrinkage function to the Gram matrix and updated by performing rank reduction and eigenvalue averaging. Then, we characterized the analytical solutions of the measurement matrix by SVD. Based on alternating minimization, we proposed an iterative method to optimize the measurement matrix. The simulation results show that the proposed method reduces , , and simultaneously and outperforms the existing algorithms in terms of reconstruction performance. In addition, the proposed method is computationally less expensive than some existing algorithms in the literature.
As detailed, we gave the optimal value of under a fixed matrix scale through simulation. When the scale changes, the value of in Section 4.1 may no longer be applicable. Therefore, it is meaningful to find the theoretical ‘optimal value’ of . Furthermore, noting that lower mutual coherence indexes mean potentially higher reconstruction performance, further efforts are needed to decrease the indexes simultaneously.
Author Contributions
Conceptualization: R.Y.; Methodology: C.C.; Software: R.Y.; Validation: B.W. and Y.G.; Formal analysis: C.C.; Data curation: R.Y.; Writing—original draft preparation: R.Y. and B.W.; Writing—review and editing: C.C. and Y.G. All authors have read and agreed to the published version of the manuscript.
Funding
No funding was received for conducting this study.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Xie, Y.; Yu, J.; Guo, S.; Ding, Q.; Wang, E. Image Encryption Scheme with Compressed Sensing Based on New Three-Dimensional Chaotic System. Entropy 2019, 21, 819. [Google Scholar] [CrossRef]
- Fang, Y.; Li, L.; Li, Y.; Peng, H.; Yang, Y. Low Energy Consumption Compressed Spectrum Sensing Based on Channel Energy Reconstruction in Cognitive Radio Network. Sensors 2020, 20, 1264. [Google Scholar] [CrossRef]
- Martinez, J.A.; Ruiz, P.M.; Skarmeta, A.F. Evaluation of the Use of Compressed Sensing in Data Harvesting for Vehicular Sensor Networks. Sensors 2020, 20, 1434. [Google Scholar] [CrossRef]
- Donoho, D.L.; Elad, M. Optimally sparse representation in general (nonorthogonal) dictionaries via 1 minimization. Proc. Natl. Acad. Sci. USA 2003, 100, 2197–2202. [Google Scholar] [CrossRef]
- Candes, E.J.; Tao, T. Decoding by linear programming. IEEE Trans. Inf. Theory 2005, 51, 4203–4215. [Google Scholar] [CrossRef]
- Stark, D.P.B. Uncertainty Principles and Signal Recovery. SIAM J. Appl. Math. 1989, 49, 906–931. [Google Scholar]
- Elad, M. Optimized Projections for Compressed Sensing. IEEE Trans. Signal Process. 2007, 55, 5695–5702. [Google Scholar] [CrossRef]
- Shaohai, H.U. An Optimization Method for Measurement Matrix Based on Eigenvalue Decomposition. Signal Process. 2012. [Google Scholar] [CrossRef]
- Yan, W.; Wang, Q.; Shen, Y. Shrinkage-Based Alternating Projection Algorithm for Efficient Measurement Matrix Construction in Compressive Sensing. IEEE Trans. Instrum. Meas. 2014, 63, 1073–1084. [Google Scholar] [CrossRef]
- Duartecarvajalino, J.M.; Sapiro, G. Learning to Sense Sparse Signals: Simultaneous Sensing Matrix and Sparsifying Dictionary Optimization. IEEE Trans. Image Process. 2009, 18, 1395–1408. [Google Scholar] [CrossRef]
- Lu, C.; Li, H.; Lin, Z. Optimized Projections for Compressed Sensing via Direct Mutual Coherence Minimization. Signal Process. 2018, 151, 45–55. [Google Scholar] [CrossRef]
- Xu, J.; Pi, Y.; Cao, Z. Optimized projection matrix for compressive sensing. EURASIP J. Adv. Signal Process. 2010, 2010, 560349. [Google Scholar] [CrossRef]
- Abolghasemi, V.; Ferdowsi, S.; Sanei, S. A gradient-based alternating minimization approach for optimization of the measurement matrix in compressive sensing. Signal Process. 2012, 92, 999–1009. [Google Scholar] [CrossRef]
- Zheng, H.; Li, Z.; Huang, Y. An Optimization Method for CS Projection Matrix Based on Quasi-Newton Method. Acta Electron. Sin. 2014, 42, 1977–1982. [Google Scholar]
- Hong, T.; Bai, H.; Li, S.; Zhu, Z. An efficient algorithm for designing projection matrix in compressive sensing based on alternating optimization. Signal Process. 2016, 125, 9–20. [Google Scholar] [CrossRef]
- Entezari, R.; Rashidi, A. Measurement matrix optimization based on incoherent unit norm tight frame. AEU Int. J. Electron. Commun. 2017, 82, 321–326. [Google Scholar] [CrossRef]
- Sustik, M.A.; Tropp, J.A.; Dhillon, I.S.; Heath, R.W. On the existence of equiangular tight frames. Linear Algebra Its Appl. 2007, 426, 619–635. [Google Scholar] [CrossRef]
- Welch, L. Lower bounds on the maximum cross correlation of signals (Corresp.). IEEE Trans. Inf. Theory 1974, 20, 397–399. [Google Scholar] [CrossRef]
- Aharon, M.; Elad, M.; Bruckstein, A.M. K-SVD: An Algorithm for Designing Overcomplete Dictionaries for Sparse Representation. IEEE Trans. Signal Process. 2006, 54, 4311–4322. [Google Scholar] [CrossRef]
- Fickus, M.; Mixon, D.G. Tables of the existence of equiangular tight frames. arXiv 2015, arXiv:1504.00253. [Google Scholar]
- Li, G.; Zhu, Z.; Yang, D.; Chang, L.; Bai, H. On Projection Matrix Optimization for Compressive Sensing Systems. IEEE Trans. Signal Process. 2013, 61, 2887–2898. [Google Scholar] [CrossRef]
- Tropp, J.A.; Gilbert, A.C. Signal Recovery from Random Measurements Via Orthogonal Matching Pursuit. IEEE Trans. Inf. Theory 2007, 53, 4655–4666. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).