Abstract
A significant amount of digital cultural contents is shared online, but learners do not know where subject matter content is or how to find it. Therefore, there is a need for a service to improve educational quality by effectively providing relevant information in response to searches for content that is useful to learners. This study developed and tested the usability and utility of an intelligent information system that effectively searches and visualizes digital cultural contents. The system collects data on digital cultural contents, automatically classifies them, and creates content triple data to automatically display the results with a 3D timeline, knowledge network map, and keyword relation network map through content search, triple search, and keyword search. We also conducted a survey and in-depth interviews to verify users’ satisfaction with respect to the use and utility of the system. For the experiment, we developed survey questions to measure user satisfaction and conducted in-depth interviews regarding the system’s utility with a total of 65 subjects. The results show that the response for satisfaction with regard to the use and utility was generally “satisfied”. In addition, the system stability was evaluated as “high”.
1. Introduction
With the recent development of online education, humans interact with others through various media to learn and interact. In particular, digital cultural content for cultural education is desperately needed to help people learn about their ethnicity or race. Culture encompasses the general way in which people of a country, race, or mankind, lived in the past, along with ideas, costumes, languages, religions, rituals, laws, morals, regulations, values, etc. [1].
However, despite the development of information technology, systems or visual services that provide systematic classification and search functions for cultural resources have not yet been developed [2]. Search services are used to search for information on certain content. These search services basically receive search keywords from users and provide highly relevant information. However, existing search services simply provide one-dimensional and fragmentary information related to the search keywords. For example, if we search “Joseon”, the current search service simply provides all the information that includes “Joseon” in the sentence. If we want to see the relationship between “Joseon” and “Gyeongbokgung Palace”, we need to search for “Joseon” and “Gyeongbokgung Palace” separately and combine simple information from the two sets of results. Thus, it takes a considerable amount of time to deduce the relationship between search keywords because of the difficulty involved in the search.
This study developed an intelligent information system for digital cultural contents and verified its usability to improve the quality of education. Through this system, a 3D timeline can be automatically generated by establishing a digital cultural content classification system, for which a systematic classification and search function can be provided. In addition, by visualizing search keywords, learners can grasp the relationship between history and culture and broaden social and cultural knowledge. We developed an automatically generated triple model to visualize the relationship between data and provide a knowledge network map search to grasp complex relationships more easily and quickly. Through this, we dramatically shortened the analysis time by visualizing the relationships between search keywords and data and enabling users to grasp the information easily. We also conducted an expert advisory evaluation to verify the usability. In addition, we drew evaluation criteria and factors so that the feasibility assessment could be considered in terms of users, experts, and system developers.
2. Related Work
2.1. The Concept of a Chronological Table
A chronological table arranges historical facts and ideas over time. The time of occurrence, consecutive times, or relationships between events can be marked on this table [3]. The simplest and best way to understand history is to compare the associations between events by using a chronological table as a visual tool. However, the tables are static in books and certain web pages, and space limitations often make it difficult to visualize the information. Existing historical tables are divided into text formats that list text horizontally or vertically in the order of the historical events and image formats that visualize and represent the relationship between the events. The text format can record considerable content in chronological order, but its simple structure makes it difficult to represent the context between events. The image format can represent the relationship between events, but there is a space limitation. As such, both the text and image formats of the current chronological table represent the events in one axis and time on the other axis in a limited 2D space [4].
2.2. Semantic Web
The Semantic Web is a framework technology that represents the meaning of the relationship between resources (web documents, services, various files, etc.) in an ontological format so that a computer can process it. In other words, it is an extended new web that defines the meaning of information on the web in a format that a computer can understand so that information on the web can be automatically processed without direct human intervention. The ultimate purpose of the Semantic Web is to develop technology and standards that help computers quickly understand the information on the web to support semantic search or data integration [5].
Meanwhile, as the Internet becomes more common and digital content increases, a semantic search method is needed to draw on users’ more sophisticated and unexpressed search intentions, more than the simple keyword-oriented search method. In contrast to existing search methods that match keywords in texts or documents, the principal of semantic search is the object search method. Search results using semantic algorithms provide more advanced information that includes the concept, relations, properties, and instances of the object, not just simple URLs [6]. Therefore, semantic search is useful when users want to search one or more relevant concepts that the keywords mean in a document [7]. Also, a semantic search algorithm can provide a more sophisticated search if meta-data connected to keywords or documents is properly assigned. To support these functions on the Semantic Web, the relationship between ontology and knowledge or concepts for knowledge representation should be built in the web document and inference rules should be included [8].
2.3. Resource Description Framework Triple
Unlike in the existing World Wide Web, the meaning of information resources is defined and their semantic connections are supported in the Semantic Web. The emergence of the Semantic Web, which is a next-generation intelligent web that can be understood even by machines, has led to the emergence of resource description framework (RDF) data, a new kind of structured data [9]. RDF is a language that describes information or properties of a resource through a graph structure that a computer can understand. Resource here means any object or concept to which uniform resource identifiers (URIs) can be granted. In other words, resources refer to web pages, documents, databases, or various identifiable objects. Everything that exists in the world, everything that humans have created, and everything that can be conceptually thought can be resources. The description characterizes resources in detail and the framework can be understood as a way of representation.
Basically, the RDF is represented in the triple structure of subject, predicate, and object. The object can also have a literal, which refers to the literal itself, to which a URI cannot be granted. Subject refers to the data to be represented, and the predicate describes the subject or the relation between subject and object. Object refers to the contents or value of the predicate. The subject-predicate-object triple is defined as the RDF triple and is the minimum unit that represents information in the RDF data model. When modeling knowledge on a certain domain, even complex knowledge should be represented in multiple RDF triples. In addition, each item of content can be described through the URI [10].
RDF represents information by describing the triple consecutively. It can also describe actual data and represent the types of terms used in the data and their relations. Recently, various studies have been performed on the representation of results of SPARQL inquiries on the web using the Daum Map API and Highcharts API, a study that proposes an interface to build the Record In Context concept model and ontology search [11], a study on user-centered search systems with RDF representation [12], and a study on automatic building of ontologies using topic modeling that automatically extracts the relations between documents and topic keywords and relations between documents [13].
This paper analyzes each sentence without extracting the relation at the global-level to automatically generate contents triple data, and then attempts to extract the relation at the global-level by collecting and analyzing fragmentary relations extracted within the sentence at once. The global-level relationship extraction was attempted only in a limited area by using temporal notation in the text [14], or attempted to overcome the limitation through detailed training data, but did not show good performance [15]. However, this paper applied a new method by using an external memory model that infers global relations in parallel with the relation extractor model that processes sentences. The external memory uses a memory-enhanced neural network to extract global relations. Relationships extracted from sentence units were separately stored in external memory as samples, and the relationships were analyzed and combined through training to extract relationships at the global level.
3. Intelligent Information System
This system consists of models that collect digital cultural contents, classify and save the collected digital cultural contents, and automatically create and save the contents’ triple data. Users can perform digital cultural content searches, triple searches, and keyword searches based on saved digital cultural contents. Search results are automatically created with a 3D timeline, knowledge network map, and keyword relation network map to provide the results. Figure 1 shows the overall structure of the system.
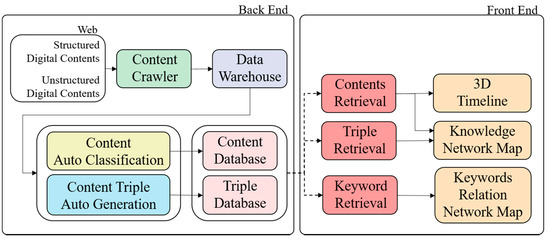
Figure 1.
Structure of Intelligent Information System.
This system collects structured and unstructured data through each digital culture site and saves collected content in the digital cultural content data warehouse so that it can be mapped. After that, it extracts the time data from the features of digital cultural contents, creates a basic digital chronological table based on the extracted time data, and performs digital chronological table and content mapping according to the time data and analysis of the content network. Then, it visualizes a digital chronological table and maps content in 3D and displays them.
Timelines that represent era and other time periods are placed on the Y axis and categories are placed on the X axis in the digital chronological table visualized in 3D. The content corresponding to each category is placed on the Y axis so that they are mapped in the timeline. The data warehouse (DW) structures the unstructured content of the digital culture-related video, image, and text content, and it integrates and saves the structured content with existing structured content.
3.1. Content Auto Classification
The content auto classification model consists of a classification system that automatically performs category determination, object recognition, and unstructured auto-tagging. Classification systems classify structured data such as content title, description, and content ID and unstructured data such as videos, audios, and images. As shown in Figure 2, the content auto classification classifies the newly registered content into categories by extracting qualities (nouns) from the collected content. It excludes letter symbols in processing the text of collected content and extracts nouns through the analysis of morphemes. Morpheme analysis identifies the structure of various linguistic properties such as root, prefix/suffix, and part of speech (POS). The process of extracting nouns refers to the process of classifying morphemes from each sentence and creating a list by extracting the nouns. It creates a list of future categories by using extracted nouns. A core category list of high-frequency categories is created using the Term Frequency–Inverse Document Frequency (TF-IDF). The TF-IDF value is a statistical figure used to evaluate the importance of certain words in certain documents. Equation (1) shows the formula for calculating TF-IDF:
where wij indicates the value of the i-th word that appears in content, j and tfij is the value-structured frequency of the i-th word in content j at the maximum frequency shown in content j and has a real value between 0 and 1, N is the total number of contents, and ni is the number of data points represented by the i-th quality. Text vectors are created for each core category in the classification model learned by the SVM algorithm. If new digital cultural content data is registered through the learned classification model, categories are automatically classified.
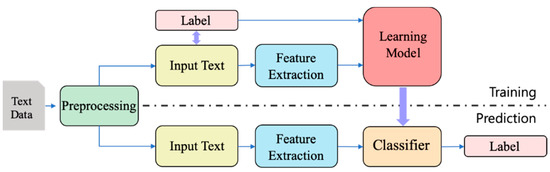
Figure 2.
Structure of Content Auto Classification.
Object recognition for proper nouns in digital cultural content is divided into text, image, and video formats, and it recognizes proper nouns in newly registered contents to classify the contents automatically. Object recognition for proper nouns in text is classified through the cross-validation of extracted text and saved data by applying a text search algorithm. Object recognition for proper nouns in images extracts text from the image by applying an image captioning algorithm. It uses the extracted text and classifies objects of images of proper nouns by applying the same algorithm as for recognition of proper nouns in text. Recognition for proper nouns in video extracts key frame images by an algorithm that extracts certain key frames from the video and classifies them through object recognition of proper nouns in images and text [16].
3.2. Content Triple Auto Generation
The ontology for the content triple auto generation model was manually built, but its tasks can be changed to auto, in order to save manpower, time, and costs. This model identifies the keywords for each sentence to extract its relations and analyzes and identifies relations for several sentences to extract their relations. To extract the relations, it searches whether keywords corresponding to each subject and object exist and then interprets their relations according to the verb. Relations across several sentences in the document are analyzed using two modules—an individual object recognition module and a knowledge graph–building module [17]. Figure 3 shows the structure of the contents of the triple auto generation model.
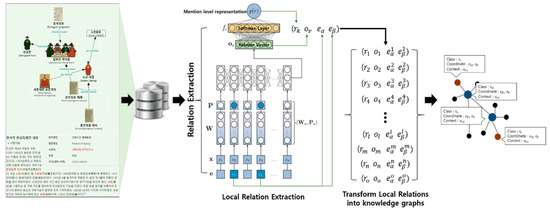
Figure 3.
Structure of Content Triple Auto Generation.
The individual object recognition module divides digital cultural contents by sentence through input, identifies relations between major objects and each object in the input received by each sentence, and displays the results of analysis and classification in triple format (object 1, relation, object 2). In the entered sentence, special symbols and Chinese characters are removed through preprocessing and tagged to each object through POS tagging. We also used word-embedding qualities for object recognition to solve the lack of quality of object recognition for the Korean language. The major words in the sentence are entered into the Bi-LSTM model, which is trained in advance to analyze sentences bi-directionally—forward from the beginning to the end of the sentence and reverse from the end to the beginning—to identify the object names in the sentences and classify the object names found. In this way, relations at the regional level that exist in all sentences of a document can be extracted. In addition, sentence structures are analyzed with emphasis on the dependency relations of words and other words according to the components of dependency analysis. This study used the Latent Semantic Analysis technique, which analyzes the meaning by using co-occurrence information between words that organize the sentences as an analysis process for synonyms, antonyms, and semantic similarity.
A knowledge graph–building model for entire relations is trained to extract all regional-level sentence relations that exist in the document and generate a knowledge graph through those relations. Then, relation information on each object is extracted from the knowledge graph and used to classify the semantic distance and final relations. This allows the extraction of not only fragmentary regional-level relations in the sentence but also relations represented across multiple sentences. A synchronization phase is required for both modules to perform this work, but it can be overcome by training two modules alternately.
3.3. 3D Timeline and Knowledge Network Map
The 3D timeline collects digital cultural contents, maps the collected contents to the Data Warehouse (DW), generates a chronological table by extracting time data, maps the generated chronological table to content in the DW, and generates a digital chronological table by visualizing it. To generate a digital chronological table automatically, it extracts time data from features of digital cultural contents and then generates a digital chronological table based on the extracted time data. For example, a chronological table is generated by extracting chronological table data through day or week base placement. In addition, a digital chronological table can be generated in a horizontally or vertically arranged table according to the criteria of period, era, country, and events. Digital chronological table and content mapping is performed according to the analysis of the time data and content network. Content mapping can be performed by automatic mapping. Alternatively, the generation of a digital chronological table can be set up to allow modification of content mapping through the participation of experts or users. Finally, the mapped contents are visualized in the timeline and displayed by the users.
The Y axis (the vertical direction) indicates the era or other time measurement, and the X axis (the horizontal direction) indicates categories in the 3D Timeline. The Y axis is arranged so that content corresponding to each category can be mapped in the timeline. An optional menu that allows users to set categories can be placed in some areas of the 3D timeline. This optional menu is placed on the upper right side of the 3D Timeline and can include features to add and delete designated categories. A category selected in the optional menu can be arranged or generated in the direction of the X axis at the bottom of the 3D timeline. Categories may include figures and content regarding figures, and the selected category can be placed so that it is the central axis of the 3D Timeline. An era-moving menu, by which users can move the timeline to a designated era, can be also placed in some areas of the 3D timeline. The era-moving menu may include designated eras such as the prehistoric age, period of the Three States, unified Silla period, Koryo Dynasty, Joseon Dynasty, Japanese colonial era, and modern and contemporary period. When the user selects one of the above designated eras, the timeline is moved to that era and displayed. When the user scrolls up and down using a mouse or touch input, the selected era is displayed. When the user scrolls up, the 3D digital chronological table moves forward in the 3D space and the timeline is changed to the past. When the user scrolls down, the 3D timeline moves backward in the 3D space and the timeline is changed to the future. A search window at the top of the era-moving menu in the area of the 3D timeline can be used to search a chronological table with that keyword.
Contents are arranged and mapped in the node format in the timeline. When users select a node, a pop-up window describes the contents corresponding to the node. In addition, the pop-up window may include a figure content pop-up to describe the figure content.
The content pop-up may include knowledge relation icons to open knowledge relation meta-information in addition to content corresponding to the node. When users select the knowledge relation icon in the content pop-up, the 3D timeline displays the knowledge network map. In addition, a knowledge network map can be generated by overlapping the 3D timeline, and the size and position of the knowledge network map can be adjusted according to the user’s input. The content pop-up also may include multimedia icons to open multimedia materials in addition to the description of the content corresponding to the node. Figure 4 shows the knowledge network map.
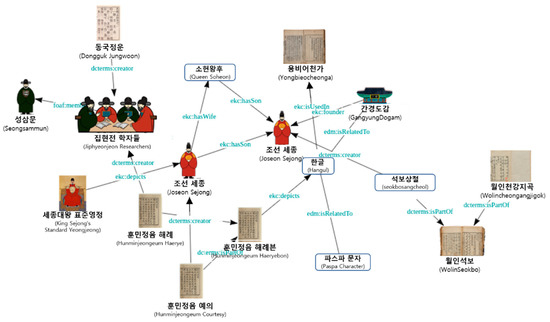
Figure 4.
Knowledge Network Map.
3.4. Triple and Keyword Retrieval
The triple search module searches the data in the triple database with search keywords entered by users as the subject. In addition, the module can search for keywords as well as objects and predicates. For example, if the search keyword is “Steven Spielberg”, the triple search module can find “Steven Spielberg is a producer of A.I.”, which is a triple data point with “Steven Spielberg” as the subject, and “Producer of Ready Player One is Steven Spielberg”, which is a triple data point with ”Steven Spielberg” as the object. In addition, the triple search module can validly find “The Last Gun is a movie by Steven Spielberg”, which is a triple data point with “Steven Spielberg” as the predicate. That is, the triple search module can search all triple data that include the users’ search keywords as valid data. It generates a triple data list searched in the form of a node and edge, as shown in Figure 5. The edge corresponds to the predicate, and the node corresponds to the subject and object. The node is represented by images that symbolize the subject and object in the network graph, and the edge is shown as a line connecting nodes. The predicate, the relation between the connected nodes, is represented as text.
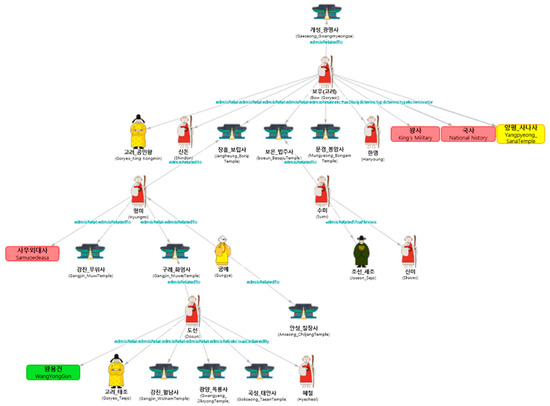
Figure 5.
Keyword Relation Network Map.
The keyword search module represents the list of nodes and edges generated from the triple search module or the list of edges generated from the relation search module between keywords in the keyword relation network map. When search keywords are received from users through a keyword input window, the triple search module searches the triple data list on that keyword in the triple database, and the keyword search module represents them as a keyword relation network map based on the list of nodes and edges generated from the triple data. Evidently, when multiple search keywords and the order for searching these relations are registered from users, the keyword search module can represent them as a keyword relation network map based on the list of nodes and edges and their relation edge lists.
When a keyword relation network map based on search keywords is displayed, double-clicking displays a network map based on new search keywords. In addition, the option is provided to remove and filter duplicate predicates among triple data on search keywords. If the user selects a particular predicate, they can reorganize the keyword relation network map by filtering the corresponding predicates and related nodes. For example, figures may include producers or main subjects for description, who are recognized as lineal relatives, siblings, father and daughter, mother and son, and creator/author. In addition, the network map can be expanded or reduced using a moving button, and the size can be adjusted according to the size of the area through automatic size adjustment.
4. Experiments and Results
4.1. Methods
This paper proposes and develops an intelligent information system for digital cultural contents that did not exist before. Accordingly, we verified its utility through evaluation of system satisfaction and in-depth interviews with experts. We selected college students as subjects for the survey, but we did not divide them into region, school, or grade by randomizing [18] the samples to offset the involvement of external factors in the sample. Participants in the survey included a total of 58 students, consisting of 31 male students and 27 female students aged 20–26 years. We also verified the system utility by having an expert group for the in-depth interview. Table 1 shows information on all participants in the experiment.

Table 1.
Participant Information.
We invited participation in the experiment from experts who could satisfy three conditions. Of the experts invited, seven out of 18 participated in the experiment. And the expert’s criteria includes the following three conditions:
- (1)
- More than three years relevant work or career experience,
- (2)
- Doctoral degree in a relevant field, and
- (3)
- More than three times experiences on creating relevant field.
A questionnaire survey was developed based on the existing study, and a total of 10 questions were developed using a Likert five-point scale to evaluate user satisfaction. The Content Validity Ratio (CVR) test was performed to evaluate the feasibility of each survey question. The CVR test is one of the most frequently used in academic and vocational testing. Specialized knowledge of each subject was required to perform the test, which was developed by Lawshe [19]. The CVR is calculated using Equation (2):
where ne is the number of respondents who checked “important” or “very important”, and N is the total number of respondents.
The CVR test for verifying the feasibility of the questions was conducted online twice with nine researchers. The final CVR score was >0.77 for all questions, which was greater than necessary for feasibility (0.75) [20]. The survey items developed are shown in Table 2.
Table 2.
Questionnaire for System Satisfaction.
Questions used for in-depth interviews were developed to fit the purpose of this study and the experimental environment using four-step questions (introduction—conversion—major—finishing questions) proposed by Krueger and Casey [30] and Behavioral Event Interview nine-step questions (describing the purpose of interview—checking personal details of the subjects—tasks and job—grasping work flow—knowledge and technology—questions on acquisition methods for work—who to contact to overcome problems—description of major events—finishing) proposed by Spencer [31]. The questionnaire developed consisted of a total of four steps: introduction, conversion, major, and finishing. The introduction step included explaining the interview purpose, obtaining consent for interview recording, verifying the information of participants, and simple questions on the interview subjects. The conversion step included items on feelings about using the proposed system, comparisons with the existing system environment, evaluation methods, etc. The major step included various items on the core use experience of the proposed system. The finishing step included items on the advantages and disadvantages, improvement, satisfaction, etc., about the proposed system. Additionally, evaluation criteria and factors were drawn to not only evaluate utility such as system functions, contents, and satisfaction, but also to consider feasibility evaluation by system experts and developers, including system design and screen UI/UX.
The conclusions drawn are as follows. First, an intelligent information system for digital content should be operated in accordance with generally expected methods of operation. Second, it should effectively deliver meaningful information to users and allow intelligent searches on digital culture, beyond simply delivering simple keyword-centered results. Therefore, it should provide relations between each keyword and visualizations of related information. Third, it should be technically stable. Even a platform that provides easy-to-use UI/UX and intelligent search results can suffer significant usability disruption if technical features do not operate properly [32]. Table 3 shows the in-depth interview questionnaire.
Table 3.
Questionnaire for In-Depth Interview.
4.2. Results
We introduced the development purpose of the system and how to use it for 30 min to evaluate the usability satisfaction, and we allowed the subjects to use the system freely for 30 min. Subsequently, we conducted a survey on usability satisfaction. Data from a total of 55 surveys were analyzed, excluding three with bad responses (selecting the same scale for all questions, items with no more than one response) out of 58 participants. All 55 participants were considered to be familiar with the digital environment and good at handling digital devices. For system satisfaction, all questions were answered as “satisfied” on average except question 1, which asked for the ease of use. This question was answered as “normal”, which may imply that the system is somewhat complicated because of the large amount of content and features displayed. Therefore, it is deemed necessary to improve the UI/UX to make it intuitively easy to use. Table 4 shows the technical statistics for the analysis results.
Table 4.
Results of Questionnaire for System Satisfaction (N = 55).
We conducted in-depth interviews with experts to evaluate the utility of the intelligent information system proposed in this study. Through this, we verified the usability and utility of the system. We received positive responses from the interview results, and we determined that the utility of this system is sufficient based on the in-depth interviews. In particular, it was highly evaluated that searches can be performed within digital-only cultural contents, search results can be checked visually through a knowledge network map, and relations between contents can be searched and visualized. Table 5 shows a summary of some of the interviews.
Table 5.
Summary of some interviews.
In addition, it was found that users can effectively search things conveniently via the platform use as they can move the pages easily at will and have significant control over the operation of functions such as searching, modifying, saving, and filtering. It was also indicated that visual, functional, and cognitive factors, including screen layout, generality of icons, styles, and text visibility, were properly designed. In terms of technology, the users indicated that it was good to see the search results with a knowledge network map while differentiating it from the existing method. It was also indicated that it was good to see a more accurate and wider range of connecting links because this represented a figure-relation network that the creators usually performed manually based on collected materials in the process of creation as a knowledge network map and keyword relation network map. They said that it could also be used as a platform for education with sufficient value. In terms of platform stability, they evaluated the stability of the response time between page movement, response time for search results, buttons functions, compatibility of various web browsers, and function/system errors to be extremely high. However, the opinion was that descriptions of system errors or functions should be added because these did not exist.
5. Conclusions
As artificial intelligence progresses, it improves the quality of education by providing a greater variety. In particular, a significant amount of domestic content is available on cultural history and traditions, but it is difficult for students to learn about them. Therefore, a support service that enables users to effectively search or create useful materials is required. This study developed an intelligent information system that can help in the effective search of digital convergence materials related to culture, history, and traditions and is helpful for creation, and its usability and feasibility were verified.
The proposed intelligent information system collects digital cultural content data, automatically classifies collected content, generates content triple data, and represents the search results as a 3D timeline, knowledge network map, and keyword relation network map through content search, triple search, and keyword search. The features of this system are as follows: First, it collects structured and unstructured data from digital culture sites and uploads the collected content in the DW (Data Warehouse) so that it can be mapped. Second, it extracts time data from the characteristics of digital cultural contents and generates a basic chronological table based on the extracted time data. Third, it performs a digital chronological table and content mapping according to the analysis of time data and the content network. Fourth, it visualizes a basic digital chronological table, maps the contents, and displays them in a 3D timeline. This system is expected to provide systematic classification and search functions as well as an intelligent digital culture information service for those who use digital cultural content. This has significantly reduced the search time and the time required to analyze complex relations between content.
Surveys and in-depth interviews were conducted to verify the satisfaction with use and system utility of this system. For this experiment, 10 questions for the usage satisfaction survey and 17 questions for the in-depth interviews regarding system utility were developed. A total of 65 people, including 58 students for the survey and 7 experts for the in-depth interviews, participated in the experiment to evaluate the satisfaction with the use and utility of the system. The results showed that the response with use was generally “satisfied.” However, question 1, which enquired about difficulties with use, had somewhat low scores. This may imply that the system is complicated owing to the large amount of content and features displayed. Therefore, it is deemed necessary to improve the UI/UX to make it intuitively easy to use.
In terms of system utility, the interview results showed a positive evaluation. Therefore, the utility of this system was judged to be sufficient based on the in-depth interviews. In particular, it was highly evaluated that search results can be visually checked through knowledge network map and relations between contents can be search and visualized. In addition, interviewees responded that the system provided more accurate and a wider range of connecting links by representing the figure-relation network as a knowledge network map and keyword relation network map, and they said it can be used as a platform for education with sufficient value. Finally, the interviewees rated the system to be high on system stability, page movement response time, search results response time, matching of buttons or menu functions, compatibility with various web browsers, and function/system errors.
However, as this verification was conducted by seven experts and 58 general users and the results of the study are focused on system development, it is necessary to conduct follow-up research to analyze system effectiveness and reliability from a number of users (people from cultural studies and the general public), including a comparison of model algorithm performance and methods to provide service and technical support. In addition, this study was conducted using only digital culture data. Therefore, it is necessary to conduct follow-up research on scalability to apply various digital content other than digital cultural contents in the future.
Author Contributions
Conceptualization, Y.H. and J.J.; methodology, J.J.; software, Y.H.; validation, J.J.; formal analysis, Y.H.; investigation, Y.H. and J.J.; resources, Y.H. and J.J.; data curation, Y.H.; writing—original draft preparation, Y.H. and J.J.; writing—review and editing, Y.H. and J.J.; visualization, Y.H.; supervision, J.J.; project administration, J.J.; funding acquisition, J.J. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the MSIT (Ministry of Science and ICT), Korea, under the ITRC (Information Technology Research Center) support program (IITP-2020-2018-0-01405) supervised by the IITP (Institute for Information & Communications Technology Planning & Evaluation). Additionally, it was also supported by Institute for Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korean government (MSIT) (No. 2020-0-00368, A Neural-Symbolic Model for Knowledge Acquisition and Inference Techniques).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kang, H.; Pang, S.S.; Choi, S.M. Investigating the use of multiple social networking services: A cross-cultural perspective in the United States and Korea. KSII Trans. Internet Inf. Syst. 2015, 9, 3258–3275. [Google Scholar] [CrossRef]
- Kwak, J.H.; Lee, J.J.; Lee, H.-J.; Lee, B.G. Estimation of the Demand Function of the Information and Communication Construction Business. KSII Trans. Internet Inf. Syst. 2015, 9, 3249–3257. [Google Scholar] [CrossRef][Green Version]
- Kim, H.J. The Content and Method of History Education; With a Book: Seoul, Korea, 2007. [Google Scholar]
- Kim, Y.C. Development of 3D Design History Chronological Table by Study of Design History Theory: Based on Concept of Structure of form and Action. Ph.D. Thesis, Hanyang University, Seoul, Korea, 2011. [Google Scholar]
- Choi, Y.M. Overview and Research Trends of the Semantic Web. Commun. Korean Inst. Inf. Sci. Eng. 2003, 21, 4–10. [Google Scholar]
- Guha, R.; McCool, R.; Miller, E. Semantic Search. In Proceedings of the WWW 2003 Conference, Budapest, Hungary, 20–24 May 2003; ACM Press: New York, NY, USA, 2003. [Google Scholar]
- Rocha, C.; Schwabe, D.; Aragao, M.P. A hybrid approach for searching in the semantic web. In Proceedings of the 13th conference on World Wide Web—WWW ’04, New York, NY, USA, 17–22 May 2004; ACM Press: New York, NY, USA, 2004; pp. 374–383. [Google Scholar]
- Melnik, S.; Mitra, P.; Decker, S. Framework for the semantic Web: An RDF tutorial. IEEE Internet Comput. 2000, 4, 68–73. [Google Scholar] [CrossRef]
- Lassila, O.; Swick, R. Resource Description Framework (RDF) Model and Syntax Specification, W3C Recommendation. Available online: https://www.w3.org/TR/1998/WD-rdf-syntax-19980720/ (accessed on 20 July 1998).
- Lassila, O. Web metadata: A matter of semantics. IEEE Internet Comput. 1998, 2, 30–37. [Google Scholar] [CrossRef]
- Lee, Y.-B.; Rieh, H.-Y. A Suggestion of Interface for Ontology-Based Record Retrieval System. J. Rec. Manag. Arch. Soc. Korea 2017, 17, 217–244. [Google Scholar] [CrossRef][Green Version]
- Kim, C.-S.; Lee, J.-W.; Jung, H.-K. A Study on Semantic Web based User Oriented Retrieval System. J. Korea Inst. Inf. Commun. Eng. 2015, 19, 871–876. [Google Scholar] [CrossRef][Green Version]
- Jeong, H. A Study on Ontology and Topic Modeling-based Multi-dimensional Knowledge Map Services. J. Intell. Inf. Syst. 2015, 21, 79–92. [Google Scholar] [CrossRef][Green Version]
- Moschitti, A.; Patwardhan, S.; Welty, C. Long-distance time-event relation extraction. In Proceedings of the Sixth International Joint Conference on Natural Language Processing, Nagoya, Japan, 14–18 October 2013; pp. 1330–1338. [Google Scholar]
- Zeng, X.; He, S.; Liu, K.; Zhao, J. Large scaled relation extraction with reinforcement learning. Relation 2018, 2, 3. [Google Scholar]
- Hur, Y.A.; Lee, D.Y.; Kim, K.K.; Yu, W.H.; Lim, H.S. A System for Automatic Classification of Traditional Culture Texts. J. Korea Converg. Soc. 2017, 8, 39–47. [Google Scholar]
- Kim, K.; Hur, Y.; Kim, G.; Lim, H. GREG: A Global Level Relation Extraction with Knowledge Graph Embedding. Appl. Sci. 2020, 10, 1181. [Google Scholar] [CrossRef]
- Park, D.K. Analysis of ANOVA and Iterative Measurement; Min Youngsa: Seoul, Korea, 2002. [Google Scholar]
- Lawshe, C.H. A quantitative approach to content validity. Pers. Psychol. 1975, 28, 563–575. [Google Scholar] [CrossRef]
- Wilson, F.; Robert, P.; Wei, S.; Donald, A. Recalculation of the critical values for Lawshe’s content validity ra-tio. Meas. Eval. Couns. Dev. 2012, 45, 197–210. [Google Scholar] [CrossRef]
- Min, M.S.; Lee, J.H. Analysis of Educational and Occupational Experiences of Women Studying Engineering. Korean J. Sociol. Educ. 2005, 15, 2. [Google Scholar]
- Good, J.J.; Woodzicka, J.A.; Wingfield, L.C. The Effects of Gender Stereotypic and Counter-Stereotypic Textbook Images on Science Performance. J. Soc. Psychol. 2010, 150, 132–147. [Google Scholar] [CrossRef] [PubMed]
- Hafkin, N.J.; Huyer, S. Women and Gender in ICT Statistics and Indicators for Development. Inf. Technol. Int. Dev. 2008, 4, 25–41. [Google Scholar] [CrossRef]
- Jang, H.J.; Kim, J.M.; Lee, W.G. Analysis of the recognition of Information subjects related to future profession of high school girls. J. Korean Assoc. Comput. Educ. 2018, 21, 21–29. [Google Scholar]
- Kim, E.M. Is Internet literacy inherited from parent to children? Korean J. Journal. Commun. Stud. 2011, 55, 155–177. [Google Scholar]
- Nam, C.W.; Ahn, S.H. The Effects of Elementary and Middle School Students’ Computer Use and Infor-mation(Computer) Educational Experiences on their ICT Literacy Levels. Korea Contents Soc. 2016, 16, 18–32. [Google Scholar] [CrossRef]
- Lee, S.J.; Youk, E.H. Digital Capability Divide and Digital Outcome Divide: Gaps in the Digital Capability and its Ef-fects on Informational Support. Korean J. Journal. Commun. Stud. 2014, 58, 206–232. [Google Scholar]
- Sung, W.J. A Study on Digital Literacy and Digital in the Smart Society. Korean Soc. Public Adm. 2014, 25, 53–75. [Google Scholar]
- Choi, Y.J.; Chung, H.S.; Ban, G.W.; Kim, S.M. Competencies of Korean Women and Its Implications: Comparative Analysis Based on OECD PIAAC. Korean Women’s Dev. Inst. 2016, 1, 1–318. [Google Scholar]
- Krueger, R.; Casey, A.; Mary, A. Focus Groups: A Practical Guide for Applied Research; Sage Publications: Thousand Oaks, CA, USA, 2014. [Google Scholar]
- Spencer, L.M.; Spencer, Y.; Spencer, S. Competence at work. In Models for Superior Performance; John Wiley & Sons: New York, NY, USA, 2011. [Google Scholar]
- Song, H.D.; Lim, C.; Lee, Y. Development and Implementation of a Digital Textbook Platform Usability Assess-ment Instrument. J. Educ. Technol. 2009, 25, 125–155. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).