
Techniques to Deal with Off-Diagonal Elements in Confusion Matrices


Abstract
:1. Introduction
- 1.
- The classification bias can be due to deficiencies in the method of classification. For instance, it is well known [1] that an inappropriate choice of k in the k-nearest neighbor (k-nn) classifier may produce this effect. In case of being detected, the method of selection of k must be revised;
- 2.
- On the other hand, the classification bias may be caused by the existence of a unidirectional confusion between two or more categories, that is, the classes under consideration are not well separated. In case of being detected, maybe additional predictors related to distinguish between these specific classes must be incorporated in the process of classification. Think, for instance, of a problem of classification related to the use of land, and two given categories, such as water and rice; the probability of confusing water with rice is not the same as that of confusing rice with water.
2. Materials and Methods
3. Marginal Homogeneity
3.1. 2 × 2 Table
3.2. General Case
3.3. Post-Hoc Analysis
4. Bayesian Methodology
- 1.
- The marginal distributions are binomials, , .
- 2.
- and , .
- 3.
- .
- 1.
- The marginal distributions are Beta distributed,
- 2.
- The mean and variance marginals are
5. Applications
5.1. Application 1
5.1.1. Marginal Homogeneity
5.1.2. Bayesian Approach
Conclusions
5.2. Application 2
5.2.1. Marginal Homogeneity
5.2.2. Bayesian Approach
5.3. Application 3
5.3.1. Homogeneity
- 1.
- For the control group, nonnIBD, there does not exist evidence to reject the null hypothesis of marginal homogeneity. Therefore we do not detect any systematic errors in this category;
- 2.
- For UC, the test,with . It is obtained p-value , and therefore the null hypothesis is rejected, which suggests underprediction of the UC category.
- 3.
- For CD, the test,with , is obtained, which suggests overprediction of CD disease.
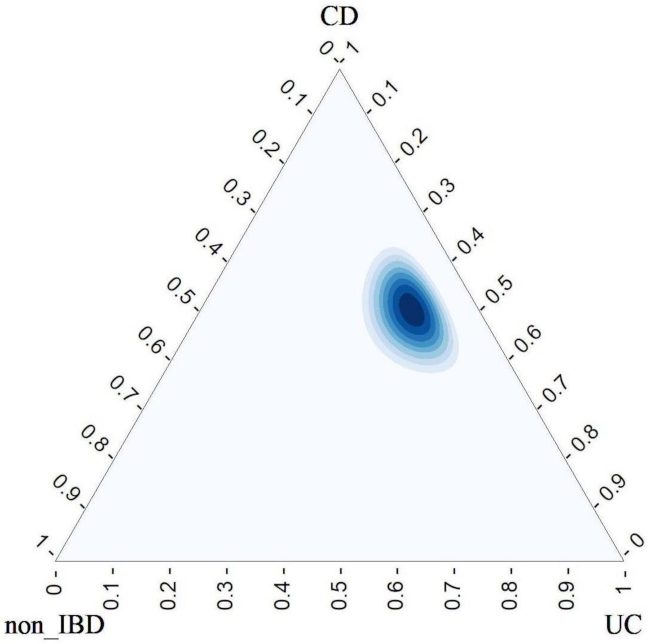
5.3.2. Bayesian Approach
Noninformative Prior Distributions
5.3.3. Sequential Use of Bayes Theorem
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Application 3

{kind=link}
{kind=link}
{kind=link}
| P_nonIBD | 0.5518703 | 0.7931919 | 0.5564379 | 0.7971693 |
| P_UC | 0.0044345 | 0.0971910 | 0.0008478 | 0.0837975 |
| P_CD | 0.1762997 | 0.4096195 | 0.1716235 | 0.4040643 |
| P_nonIBD | 0.0547901 | 0.2302899 | 0.0477798 | 0.2195273 |
| P_UC | 0.2478722 | 0.5019668 | 0.2448073 | 0.4985839 |
| P_CD | 0.3683954 | 0.6316046 | 0.3683954 | 0.6316046 |
| P_nonIBD | 0.0973247 | 0.2421973 | 0.0933429 | 0.2370862 |
| P_UC | 0.0113483 | 0.0877318 | 0.0076403 | 0.0800716 |
| P_CD | 0.7111385 | 0.8692713 | 0.7155517 | 0.8728854 |
| A_nonIBD | A_UC | A_CD | |
|---|---|---|---|
| P_nonIBD | 0.691 | 0.122 | 0.16 |
| P_UC | 0.025 | 0.372 | 0.035 |
| P_CD | 0.284 | 0.506 | 0.806 |
References
- Goin, J.E. Classification Bias of the k-Nearest Neighbor Algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 1984, PAMI-6, 379–381. [Google Scholar] [CrossRef] [PubMed]
- Black, S.; Gonen, M. A Generalization of the Stuart-Maxwell Test. In SAS Conference Proceedings: South-Central SAS Users Group 1997; Applied Logic Associates, Inc.: Houston, TX, USA, 1997. [Google Scholar]
- Sun, X.; Yang, Z. Generalized McNemar’s Test for Homogeneity of the Marginal Distributions. In Proceedings of the SAS Global Forum Proceedings, Statistics and Data Analysis, San Antonio, TX, USA, 16–19 March 2008; Volume 382, pp. 1–10. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed.; Springer: New York, NY, USA, 2009. [Google Scholar]
- Barranco-Chamorro, I.; Luque-Calvo, P.; Jiménez-Gamero, M.; Alba-Fernández, M. A study of risks of Bayes estimators in the generalized half-logistic distribution for progressively type-II censored samples. Math. Comput. Simul. 2017, 137, 130–147. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data. Principles and Practices, 3rd ed.; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Carrillo-García, R.M. Text Mining: Principios Básicos, Aplicaciones, Técnicas y Casos Prácticos. Master’s Thesis, Universidad de Sevilla, Sevilla, Spain, 2021. [Google Scholar]
- Carrillo-García, R.M. Algorithms and Applications in Statistical Data Mining; PI3: Programa IMUS de Iniciación a la Investigación; Instituto de Matemáticas de la Universidad de Sevilla: Sevilla, Spain, 2021. [Google Scholar]
- Huang, Q.; Zhang, X.; Hu, Z. Application of Artificial Intelligence Modeling Technology Based on Multi-Omics in Noninvasive Diagnosis of Inflammatory Bowel Disease. J. Inflamm. Res. 2021, 14, 1933–1943. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Frazier, P.; Kumar, L. Comparative Assessment of the Measures of Thematic Classification Accuracy. Remote Sens. Environ. 2007, 107, 606–616. [Google Scholar] [CrossRef]
- Pontius, R.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Lance, R.F.; Kennedy, M.L.; Leberg, P.L. Classification Bias in Discriminant Function Analyses used to Evaluate Putatively Different Taxa. J. Mammal. 2000, 81, 245–249. [Google Scholar] [CrossRef] [Green Version]
- Schmidt, R.L.; Walker, B.S.; Cohen, M.B. Verification and classification bias interactions in diagnostic test accuracy studies for fine-needle aspiration biopsy. Cancer Cytopathol. 2015, 123, 193–201. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rivas-Ruiz, F.; Pérez-Vicente, S.; González-Ramírez, A. Bias in clinical epidemiological study designs. Allergol. Immunopathol. 2013, 41, 54–59. [Google Scholar] [CrossRef] [PubMed]
- Barranco-Chamorro, I.; Muñoz Armayones, S.; Romero-Losada, A.; Romero-Campero, F. Multivariate Projection Techniques to Reduce Dimensionality in Large Datasets. In Smart Data. State-of-the-Art Perspectives in Computing and Applications; CRC Press, Taylor & Francis Group: Boca Raton, FL, USA, 2019. [Google Scholar]
- Tsendbazar, N.; de Bruin, S.; Mora, B.; Schouten, L.; Herold, M. Comparative assessment of thematic accuracy of GLC maps for specific applications using existing reference data. Int. J. Appl. Earth Obs. Geoinf. 2016, 44, 124–135. [Google Scholar] [CrossRef]
- Pérez, C.J.; Girón, F.J.; Martín, J.; Ruiz, M.; Rojano, C. Misclassified multinomial data: A Bayesian approach. Rev. Real Acad. Cienc. Exactas Fís. Nat. Ser. A Mat. (RACSAM) 2007, 101, 71–80. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Meredith, M.; Kruschke, J. HDInterval: Highest (Posterior) Density Intervals. R Package Version 0.2.2. 2020. Available online: https://cran.r-project.org/web/packages/HDInterval/index.html (accessed on 12 July 2021).
- Signorell, A.; Aho, K.; Alfons, A.; Anderegg, N.; Aragon, T.; Arachchige, C.; Arppe, A.; Baddeley, A.; Barton, K.; Bolker, B.; et al. DescTools: Tools for Descriptive Statistics. R Package Version 0.99.44. 2021. Available online: https://cran.r-project.org/web/packages/DescTools/index.html (accessed on 12 December 2021).
- Tsagris, M.; Athineou, G. Compositional: Compositional Data Analysis. R Package Version 4.8. 2021. Available online: https://cran.r-project.org/web/packages/Compositional/index.html (accessed on 10 August 2021).
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- McNemar, Q. Note on the sampling error of the difference between correlated proportions or percentages. Psychometrika 1947, 12, 153–157. [Google Scholar] [CrossRef] [PubMed]
- Edwards, A. Note on the “correction for continuity” in testing the significance of the difference between correlated proportions. Psychometrika 1948, 13, 185–187. [Google Scholar] [CrossRef] [PubMed]
- Balakrishnan, N.; Johnson, N.L.; Kotz, S. Multinominal Distributions. In Discrete Multivariate Distributions; Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 1997; Chapter 2. [Google Scholar]
- Kotz, S.; Balakrishnan, N.; Johnson, N.L. Dirichlet and Inverted Dirichlet Distributions. In Continuous Multivariate Distributions: Models and Applications; Series in Probability and Statistics; Wiley: Hoboken, NJ, USA, 2000; Volume 1, Chapter 49; pp. 458–527. [Google Scholar] [CrossRef]


| Z | |||||
|---|---|---|---|---|---|
| Y | 1 | 2 | ⋯ | r | |
| 1 | ⋯ | ||||
| 2 | ⋯ | ||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ |
| ⋯ | |||||
| r | ⋯ |
| P_FallenLeaf | P_Conifiers | P_Agricultural | P_Scrub | |
|---|---|---|---|---|
| A_FallenLeaf | 65 | 6 | 0 | 4 |
| A_Conifiers | 4 | 81 | 11 | 7 |
| A_Agricultural | 22 | 5 | 85 | 3 |
| A_Scrub | 24 | 8 | 19 | 90 |
| df | p-Value | ||
|---|---|---|---|
| Stuart-Maxwell | 11.202 | 3 | 0.010680 |
| Bhapkar | 11.654 | 3 | 0.008667 |
| P_FallenLeaf | P_Others | |
|---|---|---|
| A_FallenLeaf | 65 | 10 |
| A_Others | 50 | 309 |
| P_Conifers | P_Others | |
|---|---|---|
| A_Conifers | 81 | 22 |
| A_Others | 19 | 312 |
| P_Agricultural | P_Others | |
|---|---|---|
| A_Agricultural | 85 | 30 |
| A_Others | 30 | 289 |
| P_Scrub | P_Others | |
|---|---|---|
| A_Scrub | 90 | 51 |
| A_Others | 14 | 279 |
| FallenLeaf | Conifiers | Agricultural | Scrub | |
|---|---|---|---|---|
| Less | 0.7336454 | 0.5512891 | 0.9999994 | |
| Greater | 1.0000 | 0.3776143 | 0.5512891 | 0.0000022 |
| Two_Sided | 0.7552287 | 1.0000000 | 0.0000045 |
| P_FallenLeaf | 65 | 1 | 66 | 0.8354430 | 0.0017185 | 0.0414545 |
| P_Conifers | 6 | 1 | 7 | 0.0886076 | 0.0010095 | 0.0317719 |
| P_Agricultural | 0 | 1 | 1 | 0.0126582 | 0.0001562 | 0.0124990 |
| P_Scrub | 4 | 1 | 5 | 0.0632911 | 0.0007411 | 0.0272225 |
| P_FallenLeaf | 4 | 1 | 5 | 0.0467290 | 0.0004125 | 0.0203090 |
| P_Conifiers | 81 | 1 | 82 | 0.7663551 | 0.0016579 | 0.0407175 |
| P_Agricultural | 11 | 1 | 12 | 0.1121495 | 0.0009220 | 0.0303638 |
| P_Scrub | 7 | 1 | 8 | 0.0747664 | 0.0006405 | 0.0253085 |
| P_FallenLeaf | 22 | 1 | 23 | 0.1932773 | 0.0012993 | 0.0360464 |
| P_Conifiers | 5 | 1 | 6 | 0.0504202 | 0.0003990 | 0.0199746 |
| P_Agricultural | 85 | 1 | 86 | 0.7226891 | 0.0016701 | 0.0408666 |
| P_Scrub | 3 | 1 | 4 | 0.0336134 | 0.0002707 | 0.0164529 |
| P_FallenLeaf | 24 | 1 | 25 | 0.1724138 | 0.0009773 | 0.0312620 |
| P_Conifers | 8 | 1 | 9 | 0.0620690 | 0.0003987 | 0.0199685 |
| P_Agricultural | 19 | 1 | 20 | 0.1379310 | 0.0008144 | 0.0285381 |
| P_Scrub | 90 | 1 | 91 | 0.6275862 | 0.0016008 | 0.0400104 |
| A_FallenLeaf | A_Conifiers | A_Agricultural | A_Scrub | |
|---|---|---|---|---|
| P_FallenLeaf | 0.835 | 0.047 | 0.193 | 0.172 |
| P_Conifers | 0.089 | 0.766 | 0.05 | 0.062 |
| P_Agricultural | 0.013 | 0.112 | 0.723 | 0.138 |
| P_Scrub | 0.063 | 0.075 | 0.034 | 0.628 |
| P_FallenLeaf | 0.7466787 | 0.9081616 | 0.7530619 | 0.9129924 |
| P_Conifiers | 0.0368469 | 0.1599464 | 0.0316868 | 0.1517275 |
| P_Agricultural | 0.0003245 | 0.0461924 | 0.0000000 | 0.0376786 |
| P_Scrub | 0.0211397 | 0.1261276 | 0.0162449 | 0.1172020 |
| P_FallenLeaf | 0.0154910 | 0.0938056 | 0.0118001 | 0.0869559 |
| P_Conifiers | 0.6820994 | 0.8411858 | 0.6856855 | 0.8442327 |
| P_Agricultural | 0.0598832 | 0.1780965 | 0.0559003 | 0.1725756 |
| P_Scrub | 0.0331458 | 0.1313375 | 0.0291373 | 0.1251047 |
| P_FallenLeaf | 0.1277553 | 0.2685539 | 0.1246560 | 0.2648023 |
| P_Conifiers | 0.0188861 | 0.0961158 | 0.0153899 | 0.0900707 |
| P_Agricultural | 0.6392494 | 0.7990403 | 0.6418989 | 0.8013868 |
| P_Scrub | 0.0093120 | 0.0725024 | 0.0062365 | 0.0660927 |
| P_FallenLeaf | 0.1156159 | 0.2377609 | 0.1129042 | 0.2344728 |
| P_Conifiers | 0.0289745 | 0.1065309 | 0.0258846 | 0.1018195 |
| P_Agricultural | 0.0869472 | 0.1983572 | 0.0840294 | 0.1946674 |
| P_Scrub | 0.5476286 | 0.7042094 | 0.5488392 | 0.7053518 |
| P_Rom | P_Mys | P_Hor | P_His | P_Fic | P_Fan | P_Com | P_Chi | P_Bio | P_Adv | |
|---|---|---|---|---|---|---|---|---|---|---|
| A_Rom | 10 | 4 | 3 | 7 | 1 | 2 | 0 | 11 | 11 | 1 |
| A_Mys | 0 | 39 | 2 | 1 | 1 | 0 | 1 | 4 | 2 | 0 |
| A_Hor | 0 | 8 | 23 | 1 | 4 | 6 | 1 | 7 | 0 | 0 |
| A_His | 0 | 1 | 0 | 18 | 8 | 7 | 1 | 2 | 11 | 2 |
| A_Fic | 3 | 8 | 2 | 0 | 11 | 4 | 1 | 9 | 11 | 1 |
| A_Fan | 2 | 0 | 3 | 0 | 3 | 36 | 1 | 5 | 0 | 0 |
| A_Com | 2 | 11 | 7 | 2 | 5 | 3 | 4 | 12 | 3 | 1 |
| A_Chi | 1 | 4 | 1 | 3 | 1 | 3 | 0 | 36 | 0 | 1 |
| A_Bio | 2 | 4 | 3 | 2 | 4 | 2 | 1 | 10 | 22 | 0 |
| A_Adv | 0 | 9 | 6 | 2 | 2 | 8 | 0 | 9 | 2 | 12 |
| df | p-value | ||
|---|---|---|---|
| Stuart–Maxwell | 94.19 | 9 | |
| Bhapkar | 121.17 | 9 | < |
| Mystery | Fantasy | Children | Biographical | |
|---|---|---|---|---|
| Less | 0.001900827 | 0.09090503 |
| Romance | History | Comedy | Adventure | |
|---|---|---|---|---|
| Greater | 0.03245432 |
| A_Rom | A_Mys | A_Hor | A_His | A_Fic | A_Fan | A_Com | A_Chi | A_Bio | A_Adv | |
|---|---|---|---|---|---|---|---|---|---|---|
| P_Rom | 0.183 | 0.017 | 0.017 | 0.017 | 0.067 | 0.05 | 0.05 | 0.033 | 0.05 | 0.017 |
| P_Mys | 0.083 | 0.667 | 0.15 | 0.033 | 0.15 | 0.017 | 0.2 | 0.083 | 0.083 | 0.167 |
| P_Hor | 0.067 | 0.05 | 0.4 | 0.017 | 0.05 | 0.067 | 0.133 | 0.033 | 0.067 | 0.117 |
| P_His | 0.133 | 0.033 | 0.033 | 0.317 | 0.017 | 0.017 | 0.05 | 0.067 | 0.05 | 0.05 |
| P_Fic | 0.033 | 0.033 | 0.083 | 0.15 | 0.2 | 0.067 | 0.1 | 0.033 | 0.083 | 0.05 |
| P_Fan | 0.05 | 0.017 | 0.117 | 0.133 | 0.083 | 0.617 | 0.067 | 0.067 | 0.05 | 0.15 |
| P_Com | 0.017 | 0.033 | 0.033 | 0.033 | 0.033 | 0.033 | 0.083 | 0.017 | 0.033 | 0.017 |
| P_Chi | 0.2 | 0.083 | 0.133 | 0.05 | 0.167 | 0.1 | 0.217 | 0.617 | 0.183 | 0.167 |
| P_Bio | 0.2 | 0.05 | 0.017 | 0.2 | 0.2 | 0.017 | 0.067 | 0.017 | 0.383 | 0.05 |
| P_Adv | 0.033 | 0.017 | 0.017 | 0.05 | 0.033 | 0.017 | 0.033 | 0.033 | 0.017 | 0.217 |
| P_nonIBD | P_UC | P_CD | |
|---|---|---|---|
| A_nonIBD | 37 | 1 | 15 |
| A_UC | 6 | 19 | 26 |
| A_CD | 15 | 3 | 77 |
| g.l. | p-value | ||
|---|---|---|---|
| Stuart-Maxwell | 21.783 | 2 | |
| Bhapkar | 24.461 | 2 |
| nonIBD | UC | CD | |
|---|---|---|---|
| Less | 0.2556879 | 0.9999998864 | 0.001896853 |
| Greater | 0.8379957 | 0.0000009708 | 0.999226416 |
| Two_Sided | 0.5113758 | 0.0000019416 | 0.003793706 |
| P_nonIBD | 37 | 1 | 38 | 0.6785714 | 0.0038265 | 0.0618590 |
| P_UC | 1 | 1 | 2 | 0.0357143 | 0.0006042 | 0.0245803 |
| P_CD | 15 | 1 | 16 | 0.2857143 | 0.0035804 | 0.0598363 |
| P_nonIBD | 6 | 1 | 7 | 0.1296296 | 0.0020514 | 0.0452921 |
| P_UC | 19 | 1 | 20 | 0.3703704 | 0.0042399 | 0.0651147 |
| P_CD | 26 | 1 | 27 | 0.5000000 | 0.0045455 | 0.0674200 |
| P_nonIBD | 15 | 1 | 16 | 0.1632653 | 0.0013799 | 0.0371470 |
| P_UC | 3 | 1 | 4 | 0.0408163 | 0.0003955 | 0.0198861 |
| P_CD | 77 | 1 | 78 | 0.7959184 | 0.0016407 | 0.0405059 |
| P_nonIBD | P_UC | P_CD | |
|---|---|---|---|
| A_nonIBD | 42 | 1 | 10 |
| A_UC | 22 | 22 | 7 |
| A_CD | 34 | 10 | 51 |
| P_nonIBD | 42 | 38 | 80 | 0.7339450 | 0.0017752 | 0.0421329 |
| P_UC | 1 | 2 | 3 | 0.0275229 | 0.0002433 | 0.0155988 |
| P_CD | 10 | 16 | 26 | 0.2385321 | 0.0016512 | 0.0406352 |
| P_nonIBD | 22 | 7 | 29 | 0.2761905 | 0.0018859 | 0.0434274 |
| P_UC | 22 | 20 | 42 | 0.4000000 | 0.0022642 | 0.0475831 |
| P_CD | 7 | 27 | 34 | 0.3238095 | 0.0020656 | 0.0454492 |
| P_nonIBD | 34 | 16 | 50 | 0.2590674 | 0.0009894 | 0.0314554 |
| P_UC | 10 | 4 | 14 | 0.0725389 | 0.0003468 | 0.0186223 |
| P_CD | 51 | 78 | 129 | 0.6683938 | 0.0011425 | 0.0338008 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Barranco-Chamorro, I.; Carrillo-García, R.M. Techniques to Deal with Off-Diagonal Elements in Confusion Matrices. Mathematics 2021, 9, 3233. https://doi.org/10.3390/math9243233
Barranco-Chamorro I, Carrillo-García RM. Techniques to Deal with Off-Diagonal Elements in Confusion Matrices. Mathematics. 2021; 9(24):3233. https://doi.org/10.3390/math9243233
Chicago/Turabian StyleBarranco-Chamorro, Inmaculada, and Rosa M. Carrillo-García. 2021. "Techniques to Deal with Off-Diagonal Elements in Confusion Matrices" Mathematics 9, no. 24: 3233. https://doi.org/10.3390/math9243233
APA StyleBarranco-Chamorro, I., & Carrillo-García, R. M. (2021). Techniques to Deal with Off-Diagonal Elements in Confusion Matrices. Mathematics, 9(24), 3233. https://doi.org/10.3390/math9243233