1. Introduction
Market forces cause stock prices to change every day. Influencing the stock market are uncertain factors caused most notably by political issues and the government. Such uncertainty complicates the determination of appropriate trading strategies for selling or buying stock. Stock market analysis includes portfolio optimization [
1], investment strategy determination [
2], and market risk analysis [
3]. Stock price trend prediction has attracted researchers and participants from various disciplines, such as economics, financial engineering, statistics, operations research, and machine learning [
4,
5,
6].
Traditional studies have proposed algorithms to predict stock trends based on machine learning techniques, such as artificial neural networks (ANNs) and support vector machines (SVMs) [
5,
6,
7,
8]. Recently, scholars have begun to adopt well-known deep learning techniques, such as recurrent neural networks (RNNs) and long short-term memory (LSTM) networks [
9,
10], for stock price prediction. Designing a profitable stock trading strategy is a challenging issue in financial market research, as financial time series data is highly volatile and noisy. Traditional traders must analyze large amounts of data to decide whether to place empty orders, multiple orders, or no transactions. In addition, after deciding to make a single order, to maximize profits, they must decide the size of the transaction. Recently, some researchers have proposed trading algorithms to maximize profits [
3].
Reinforcement learning and Q-learning are machine learning algorithms for automating goal-directed learning and decision making [
11]. Moody and Saffell [
12] optimized portfolios and trading stocks using direct reinforcement learning. Using reinforcement learning, Deepmind learned to play seven Atari video games, even achieving human-expert level on three of them. The system later achieved a human-expert level in over 20 different Atari games [
13]. AlphaGo, that combines neural networks and reinforcement learning, beat the best Go player in the world, boosting the popularity of reinforcement learning applied in deep learning as a topic of research.
In this study, we propose a novel automatic trading system which combines deep learning and reinforcement learning to determine the trading signal and the size of the trading position. The system is constructed from an LSTM network combined with deep Q-learning, which is an off-policy reinforcement learning algorithm that seeks to find the best action to take given the current state. It is considered off-policy because the Q-learning function learns from actions that are outside the current policy, such as random actions, and therefore no policy is needed. More specifically, Q-learning seeks to learn a policy that maximizes the total reward. Our system is based on the deep Q-network [
14]. We verify this system with five different financial products and three different states. The paper is organized as follows. In
Section 2, we review related work, and in
Section 3 we introduce our methodology. Our experimental data and results are presented in
Section 4. We conclude in
Section 5.
2. Literature Review
Stock market prediction had been proposed by many researchers using several machine learning techniques [
15,
16,
17,
18,
19]. Recently, deep learning models have been a popular research issue [
20,
21,
22] and we briefly discuss previous applications of deep learning to financial trading. Ding et al. [
23] proposed a deep convolutional neural network using event embedding which combined the influence of long-term events and short-term events to predict stock prices. Their events included stock price changes over months, weeks, and days. They demonstrated that combining event embedding with deep convolutional networks is useful for stock price prediction.
Akita et al. [
24] built an LSTM model using textual and numerical information to predict ten company’s closing stock prices. The experimental results showed that combining textual and numerical information was better than methods that use only textual data or only numerical data. Nelson, Pereira, and de Oliveira [
25] proposed a model based on LSTM using five historic price measures (open, close, low, high, and volume) and 175 technical indicators to predict stock price movement.
Liu et al. [
26] predicted stock price movements using a novel end-to-end attention-based event model. They proposed the ATT-ERNN model to exploit implicit correlations between world events, including the effect of event counts and short-term, medium-term, and long-term influence, as well as the movement of stock prices. Qin [
27] forecasted time series using a novel dual-stage attention-based recurrent neural network (DA-RNN) which consisted of an encoder with an input attention mechanism and a decoder with a temporal attention mechanism.
Fischer and Krauss [
9] applied an LSTM model to a large-scale financial market prediction task on S&P 500 data from December 1992 to October 2015. They showed that the LSTM model outperformed standard deep net and traditional machine learning methods. Zhao et al. [
28] captured market dynamics from multimodal information (fundamental indicators, technical indicators, and market structure) for stock return prediction by using an end-to-end market-aware system. Their market awareness system led to reduced error, and temporal awareness across stacks of market images led to further error reductions.
In reinforcement learning (RL), the model learns to map situations to actions to maximize the reward [
29]. The RL agent is not instructed explicitly about how to improve its learning [
14]; instead, the agent only observes state information from its environment. The agent then learns by itself to select actions given this state and the reward obtained.
A reinforcement learning system includes a policy, a reward, a value function, and an environment. At each time step t = 0, 1, 2, 3, …, the agent and environment interact with each other; the agent observes st ∈ S, where S is the set of possible states from the environment, and then selects an action, at ∈ A(st), where A(st) is the set of actions that may be executed in state st. In the next time step, the agent receives a reward, rt + 1 ∈ ℜ, and observes a new state, st + 1. The agent’s policy is its mapping from states to actions at each time step. A policy is denoted πt, where πt (s, a) is the probability that at = a if st = s. Reinforcement learning is how the agent improves its policy given its experience. The agent’s goal is the maximum reward over the long term.
Moody and Saffell [
12] introduced recurrent reinforcement learning (RRL), a direct reinforcement approach that outperformed a Q-learning implementation. Their RRL trader uses a one-layer NN to maximize a function of risk-adjusted profit, which takes as input the past eight returns and its previous output. The trader was tested on USD/GBP currency pair data, half-hourly from January 1996 to August 1996, achieving an annualized profit of 15%. Gold [
30] further tested RRL on other currency markets with half-hourly data for the entire year of 1996, achieving a varied profit from −82.1% to 49.3%, with an average of 4.2% over ten different currency pairs. Duerson et al. [
31] used two techniques based on recurrent reinforcement learning (RLL) and two based on Q-learning for the problem of investment strategy determination. They combined reinforcement learning and a trading system. Traditionally, stock prediction and transactions are separated into independent systems as forecaster and trader systems. They demonstrated strong performance for the Q-learning approach: on some data series, the results were twice as good as the buy-and-hold strategy. Nevmyvaka et al. [
32] reported on the first extensive empirical application of reinforcement learning (RL) to the problem of optimized execution using large-scale NASDAQ market microstructure datasets. They used historical INET records and conducted experiments on three stocks—Amazon (AMZN), Qualcomm (QCOM), and NVIDIA (NVDA)—showing that RL beat the submit and leave (S&L) policy, which was already an improvement over a simple market order.
Dempster and Leemans [
33] used adaptive reinforcement learning (ARL) on the currency market. In their system, they added a risk management layer and a dynamic hyper-parameter optimization layer. They tested the system on two years of EUR/USD historical data, from January 2000 to January 2002, with 1-min granularity, achieving an average 26% annual return. Lee et al. [
34] proposed a new stock trading system based on reinforcement learning. MQ-trader, the proposed framework, consists of four cooperative Q-learning agents: buy and sell signal agents, which use global trend prediction to determine when to buy or sell stock shares, and buy and sell order agents, which decide the best buy price (BP) and sell price (SP) to execute intraday orders. Lee applied the four-agent approach to KOSPI 200, which includes 200 major Korean stocks. When using stock data from the Korean stock market, they found that their systems yielded better performance than other baseline systems.
Cumming et al. [
35] introduced an RL trading algorithm based on least-squares temporal difference (LSTD). Their state signal consisted of the open, highest, lowest, and close prices (bid only) from the last 8 periods, where each period covers a minute. The reward was defined as the profit from each transaction. In experiments, their method achieved a 1.64% annualized profit on the EUR/USD pair market. Deep reinforcement learning methods combined with different trading strategies have become popular [
36,
37] and been evaluated for their robustness and effectiveness on different countries’ stock markets. The proposed three-layered multi-ensemble approach performed better than a conventional buy-and-hold strategy [
38]. The three layer-stock framework, including a stacking layer, reinforcement meta learner, and ensembling layer, was evaluated with the experimental dataset containing S&P500, J.P. Morgan and Microsoft stocks between 1 January 2012 and 31 December 2019. The proposed ensemble method led to better trading results and less overfitting. The final return was better than the benchmark. Recently, a novel multi-agent deep reinforcement learning approach for stock trading was proposed and evaluated with an S&P500 dataset using walk-forward methodology. The experiment results showed that the multi-agent deep reinforcement learning approach performed better than a conventional buy-and-hold strategy [
39]. This study will use this method as the base line.
3. Methodology
Reinforcement learning (RL) is learning what to do, i.e., how to map situations to actions, to maximize a numerical reward signal. Unlike supervised learning, the RL agent never receives examples of correct or incorrect performance to boost learning [
24]. Instead, the agent is only provided with state information from its environment. The agent then learns to act through state. It learns what action is the best from rewards obtained for trying different actions by itself. The agent’s only goal is to maximize the rewards it gets.
We propose a framework to determine trading signals to maximize the total profit depending on the Q-value at each moment. In our framework, we modify the deep Q-learning algorithm on the stock market proposed by Mnih [
24]. They combined deep neural networks and Q-learning to master difficult control policies for Atari 2600 computer games.
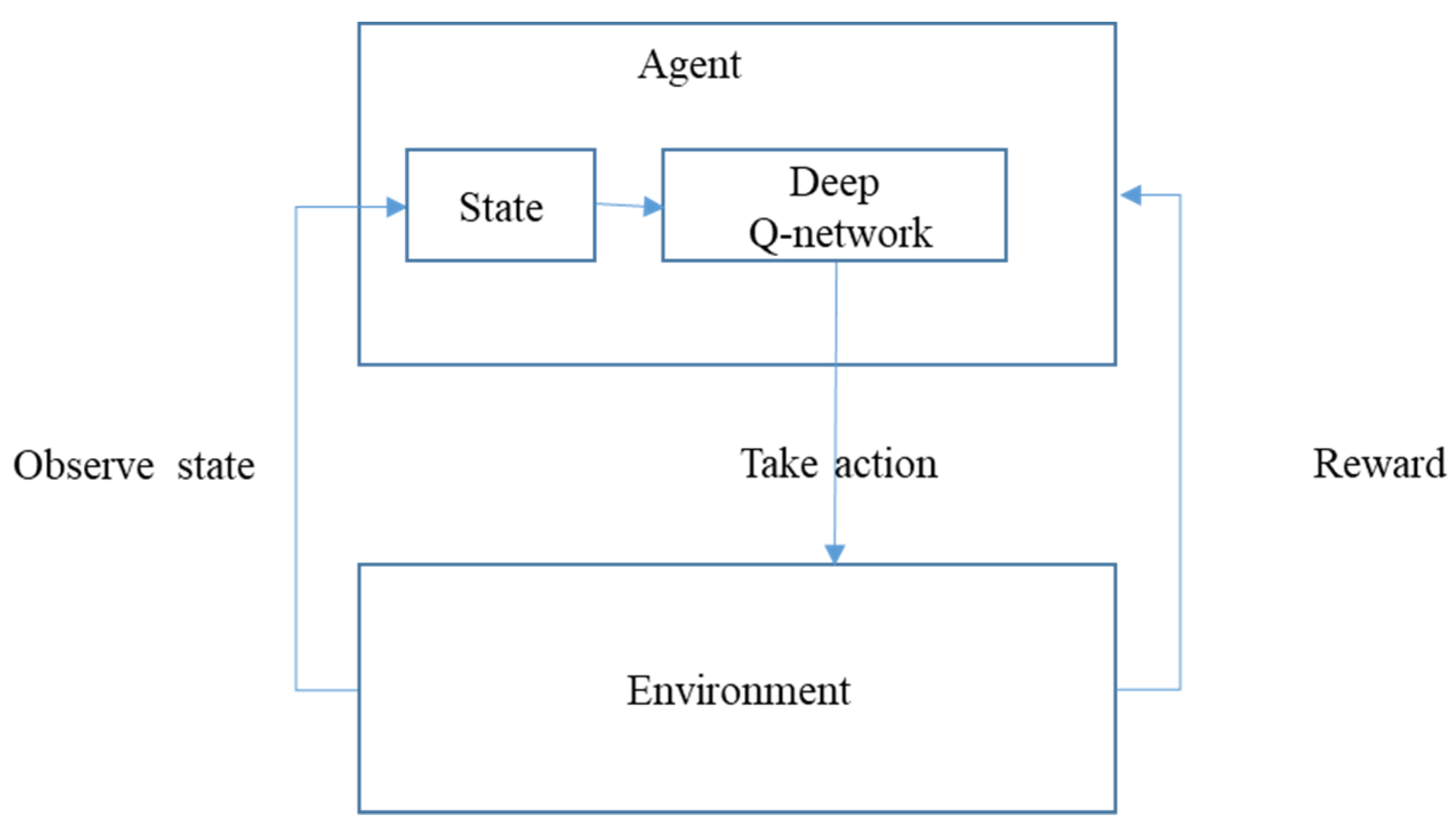
Figure 1 shows our proposed framework. A reinforcement learning system includes four main elements: a policy, a reward signal, a value function, and, optionally, a model of the environment. More specifically, the agent and environment interact at each of a sequence of discrete time steps,
t = 0, 1, 2, 3, … At each time step
t, the agent receives some representation of the environment’s state,
st ∈
S where
S is the set of possible states, and on that basis selects an action,
at ∈ A(
st), where A(
st) is the set of actions available in state
st. One time step later, in part as a result of its action, the agent receives a numerical reward,
rt+1 ∈ ℜ, and finds itself in a new state,
st+1. At each time step, the agent implements a mapping from states to probabilities of selecting each possible action. This mapping is called the agent’s policy and is denoted π
t where π
t (s, a) is the probability that a
t = a if
st = s. Reinforcement learning methods specify how the agent changes its policy as a result of its experience. The agent’s goal, broadly speaking, is to maximize the total amount of reward it receives over the long run.
At each moment, the agent observes the state from the environment and then decides what action to take using the deep Q-network. After taking an action, the agent receives a reward. Detailed definitions of the states, actions, and reward of each agent and the deep Q-network are provided in the following sections.
3.1. State Signal
Consider the stocks in time interval . Denote ,,, as the open price, highest price, lowest price, close price, and volume of stock at time , respectively. Note that the time interval between and represents one day, one week, or one month. In this paper, we consider the gross returns of these five features as the input of Q-learning. The symbols of gross returns are defined as , , , , , respectively.
Let
be the collection of state signals, where
,
, and
represent.
, , and , respectively.
The main components of the state signal
St ∈
S, where
S is a set of states {
s1,
s2,
s3, …}, are features extracted from market data, including open price, highest price, close price, lowest price, and volume. Each state
St includes
k ∈ {5, 10, 20} days of stock data. Each feature is normalized to the range [−1, 1]:
where
where
OPt is the open price at time
t,
HPt is the highest price at time
t,
CPt is the close price at time
t,
Lt is the lowest price at time
t, and
Vt is the volume at time
t.
3.2. Trading Strategy
There are five actions, denoted as for agents in the proposed model. These actions represent long large size (), long small size (), sit (), short small size (), and short large size (), respectively. The input of our training model at time is the state . According to the state the model determines the one action in at time .
The proposed agent can take only five different actions: long large size, long small size, sit, short small size, and short large size. The action signal can be simplified to A(s) =
] ∀s ∈ S, where
] are interpreted by the environment as desired in
Table 1. If the action signal is a0 or a1, we open a long position. If the action signal is a2, we do nothing (sit). If the action signal is a3 or a4, we open a short position.
Our trading strategy is long (short) stock at the moment before the market closes and clean the position at the moment the market opens on the next day. For example, if we long the stock with closed price on day , we clean (short) the stock the next day at the price . The profit and loss on day is calculated as . In this study, we represent the five actions about the positions with different sizes, where represents two long units of stock, represents one long unit of stock, represents do nothing, represents one short unit of stock, and represents two short units of stock.
Our trading strategy is day trading within two days. We open the position with trading price , closed price at time t, and then close the position at time t + 1 with trading price , open price at time t + 1. We observe k ∈ {5, 10, 20} days of open price, highest price, close price, lowest price, and volume and then decide to open a long position or open a short position at time t. Further, we close the position at time t + 1. In addition to the trading signal, our deep Q-network also determines the position size, that is, either small or large. In other words, the agent decides what action to take using the deep Q-network after knowing the state and then executes the transaction at time t. The environment returns a reward at time t + 1.
In the classical Q learning approach, we must give the state and action as an input resulting in a Q value for that state and action. Replicating this approach in neural networks is problematic as one must give the model the state and action for each possible action of the agent, leading to many forward passes in the same model. Instead, the model is designed in such a way that it predicts Q values for each action for a given state. As a result, only one forward pass is required. The implementation of DQN for our model is similar to the Q learning method. To start, instead of initializing the Q matrix, the model is initialized. In the ϵ greedy policy, instead of choosing the action based on policy π, Q values are calculated according to the model. At the end of every episode, the model is trained using random mini batches of experience.
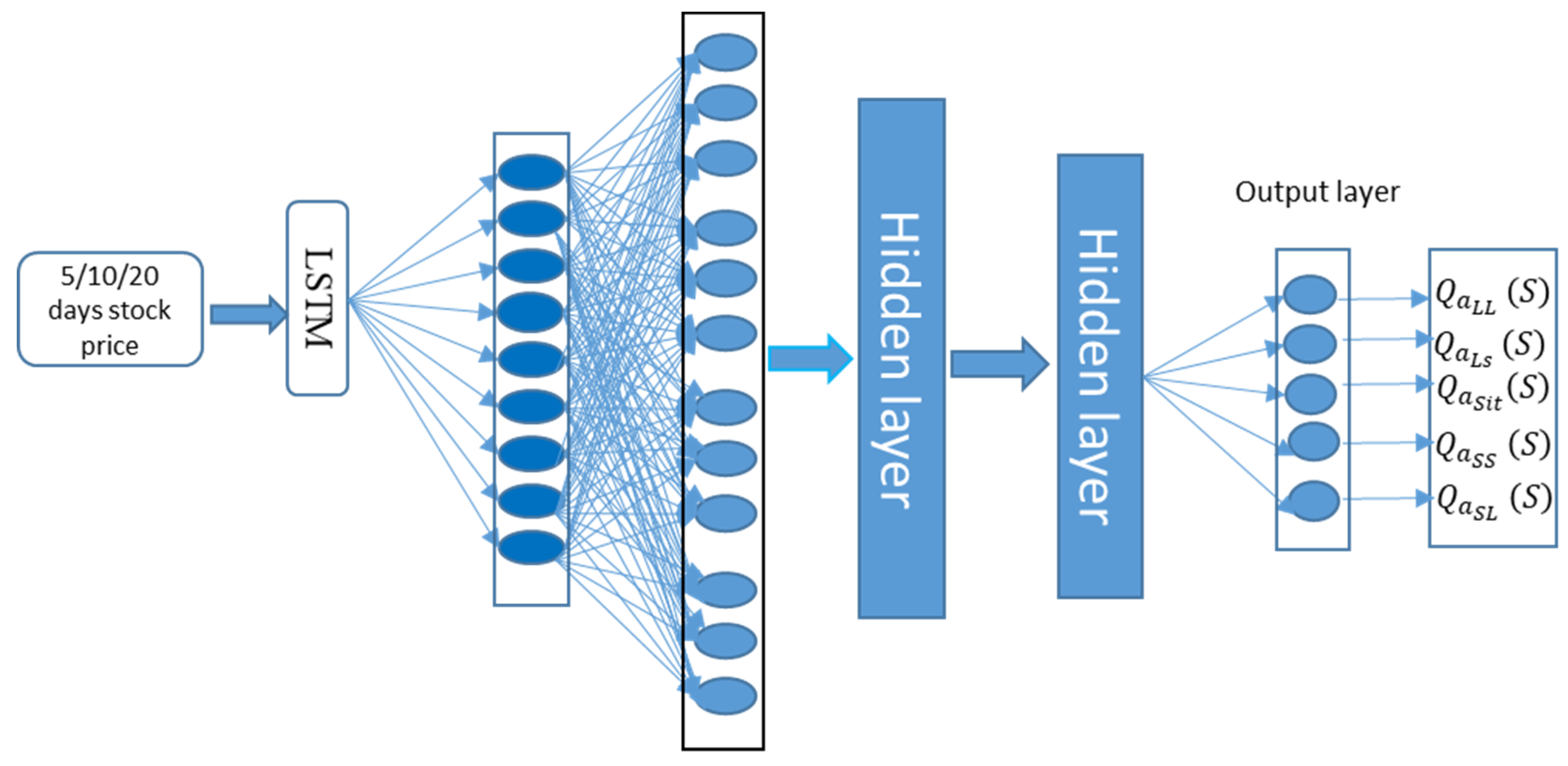
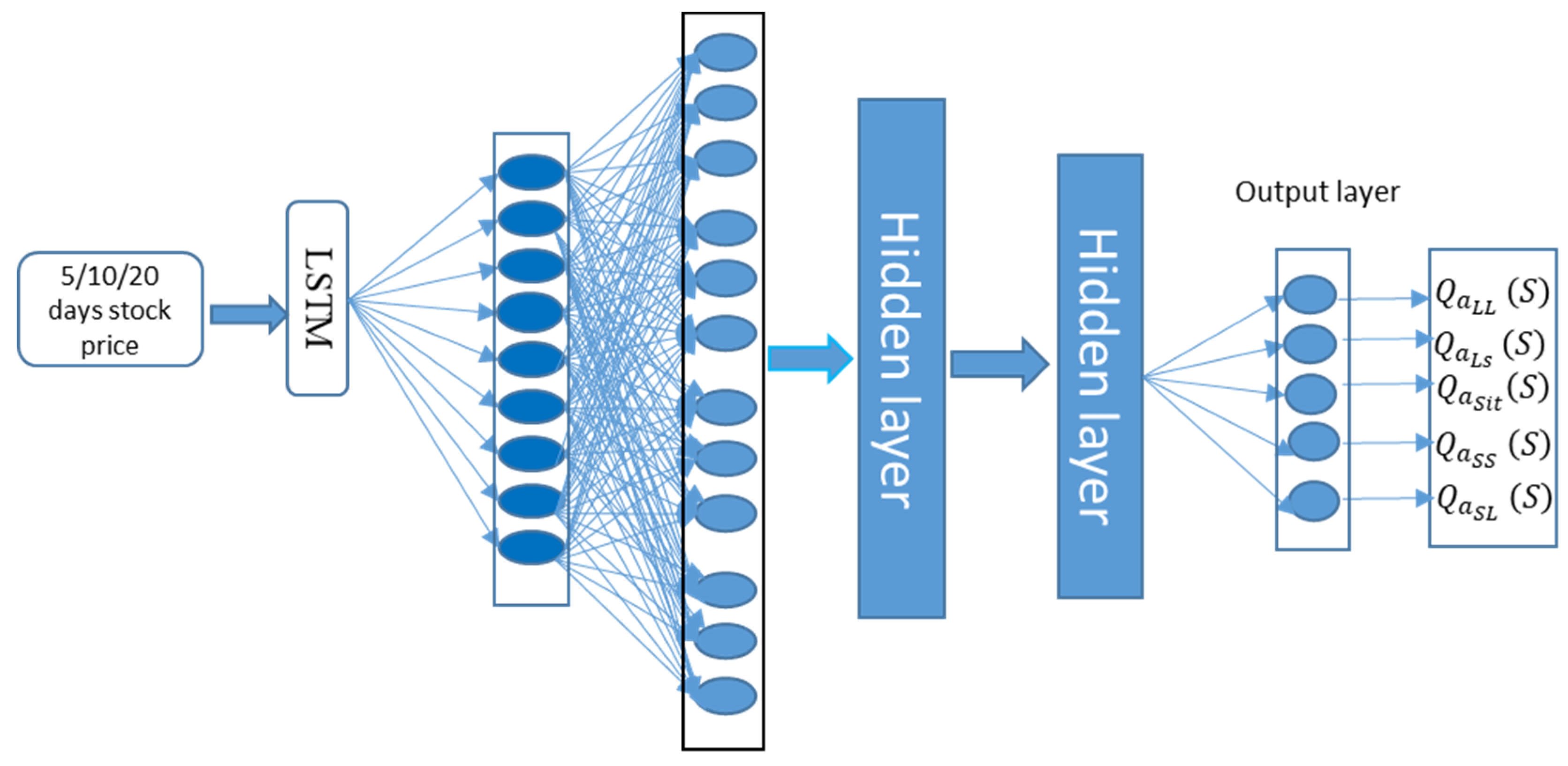
The core of the framework is a deep neural network, schematically depicted in
Figure 2. This network is tasked with computing the action value for the market environment. The input layer has a number of neurons defined by the elements in our state signal, which includes
k ∈ {5,10,20} [
6] days of normalized open price, highest price, close price, lowest price, and volume. This input layer is followed by five hidden layers.
The first hidden layer is a long short-term memory (LSTM) layer. LSTM is chosen because it is one of the most advanced deep learning architectures for financial tasks (Fischer & C. Krauss, 2018). The remaining hidden layers are fully connected deep neural network (DNN) layers.
The output layer has five neurons to represent action values (), where represents the prediction Q-value based on state and action , that for state and action , that for state and action , that for state and action , and that for state and action .
We choose the maximize action value as our action. The deep Q-network is initialized with a random set. As the network interacts with the market environment in a training process, it collects and stores state, action, and reward in memory. After a fixed period, we update the deep Q-network using the mean squared error (MSE) between the reward and action value received from the neural network.
4. Experiment
We collected two different types of financial data to verify the proposed system. Data descriptions are shown in
Table 2. These six financial products can have different patterns during the same period. The accumulated profit of these products are shown in
Figure 3,
Figure 4,
Figure 5,
Figure 6,
Figure 7 and
Figure 8. Code 0050 and TSMC have the same pattern because 0050 holds 18.78% of TSMC stock. Although 1101 does not show an increasing or decreasing trend, it is more volatile than 0050 and TSMC.
Codes 00655L and 00672L are leveraged ETFs, which is a security that seeks to multiply or invert the daily return of financial derivatives or debts. Code 00655L tracks the twice-daily performance of the FTSE China A50 index, and 00672L tracks the performance of the S&P GSCI Crude Oil 2× Leveraged Index ER.
We chose 0050 because the fund’s constituents are selected from the top 50 listed stocks on the Taiwan Stock Exchange by market weight, including 1101, 2330 and 2881. We also chose 00655L and 00672L because leveraged ETFs have high volatility.
4.1. Results and Discussion
Our results are presented in two stages. First, we compared the performance of the LSTM network with the deep neural network and the RNN network, and then we chose the best-performing network to construct the proposed framework. Second, we conducted various experiments to verify the proposed framework. In this experiment, we used a rolling window to evaluate the proposed approach. Each window included a three-month training period and a one-month testing period (3 months/1 month).
The key task of the proposed framework is to accurately predict stock and to determine the action to take. In this section, we used different neural networks to predict stock price movement. The input layer of the neural networks matches our state, such that the input data includes the open price, highest price, close price, lowest price, and volume. The output layer is a classification layer. As shown in
Table 3, we achieved at least 77% accuracy in all models. LSTM outperformed other models in four of five different stocks. Hence, we used LSTM to construct the deep Q-network.
4.2. Analysis of Deep Q-Learning Performance
We conducted various experiments to verify the proposed systems using five different stocks and three different states (5, 10, and 20 days of OHCLV). We assumed initial investment funds of 100,000. We used our framework to trade 0050, 2330, and 1101 from April 2016 to December 2018, 00655L from July 2016 to December 2018, and 00672L from January 2017 to December 2018.
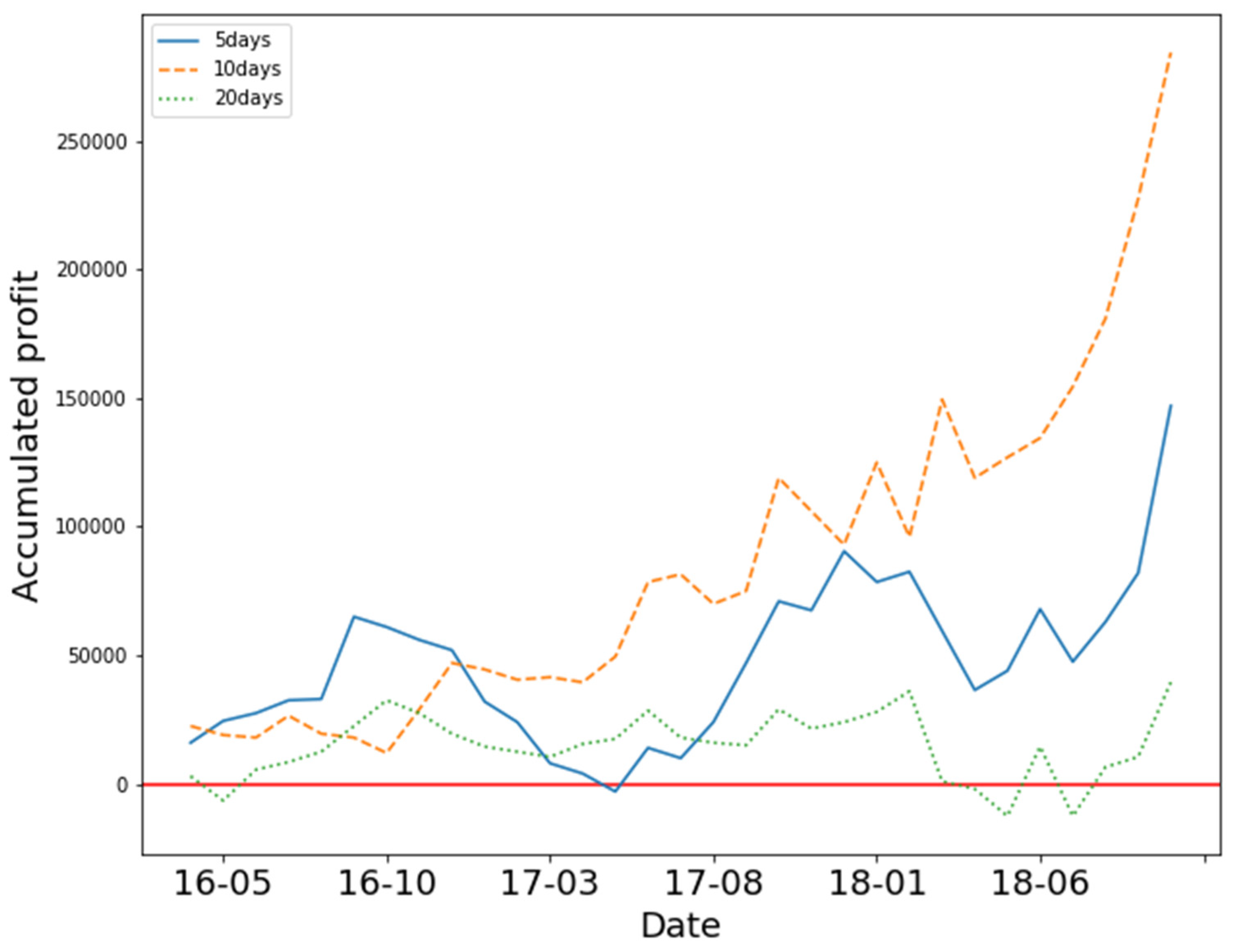
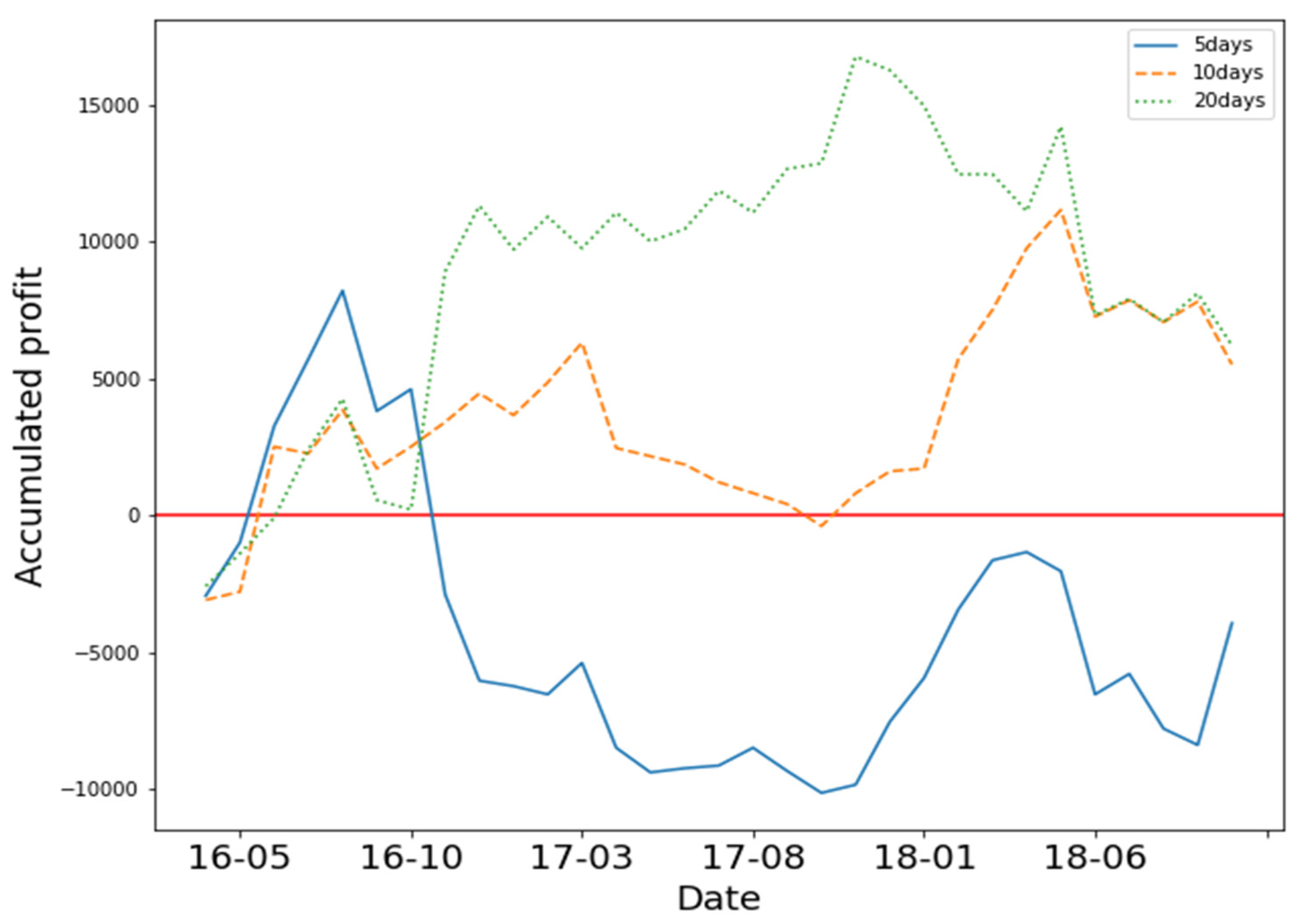
In
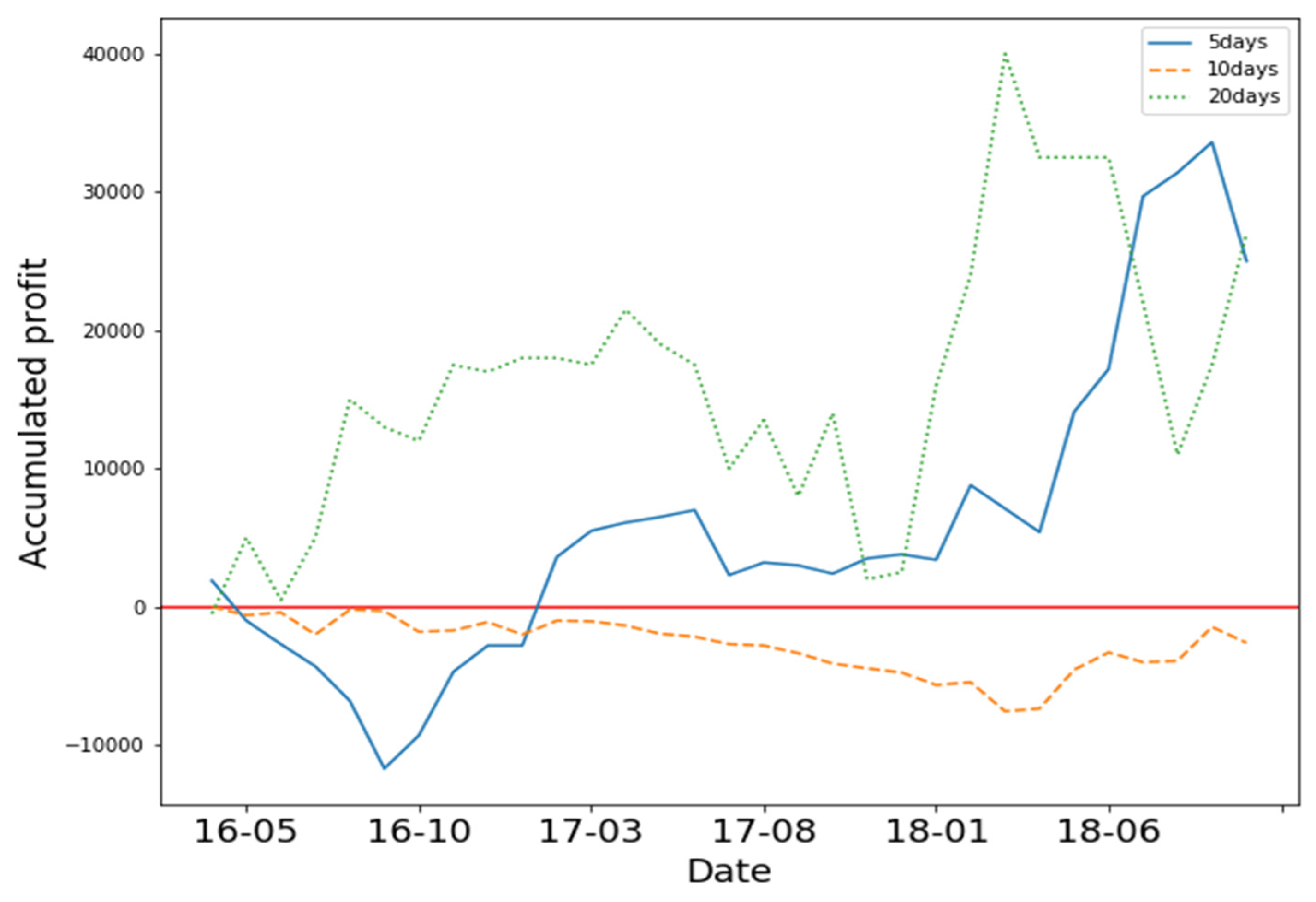
Figure 3, the Y axis represents accumulated profit, and the X axis represents time. The three different lines represent the accumulated profit of the three different states. The results show that 5-day and 20-day states yielded positive profit. The 10-day states yielded negative profit. We found that training the model with 5 days of OHCLV on 0050 yielded the best performance.
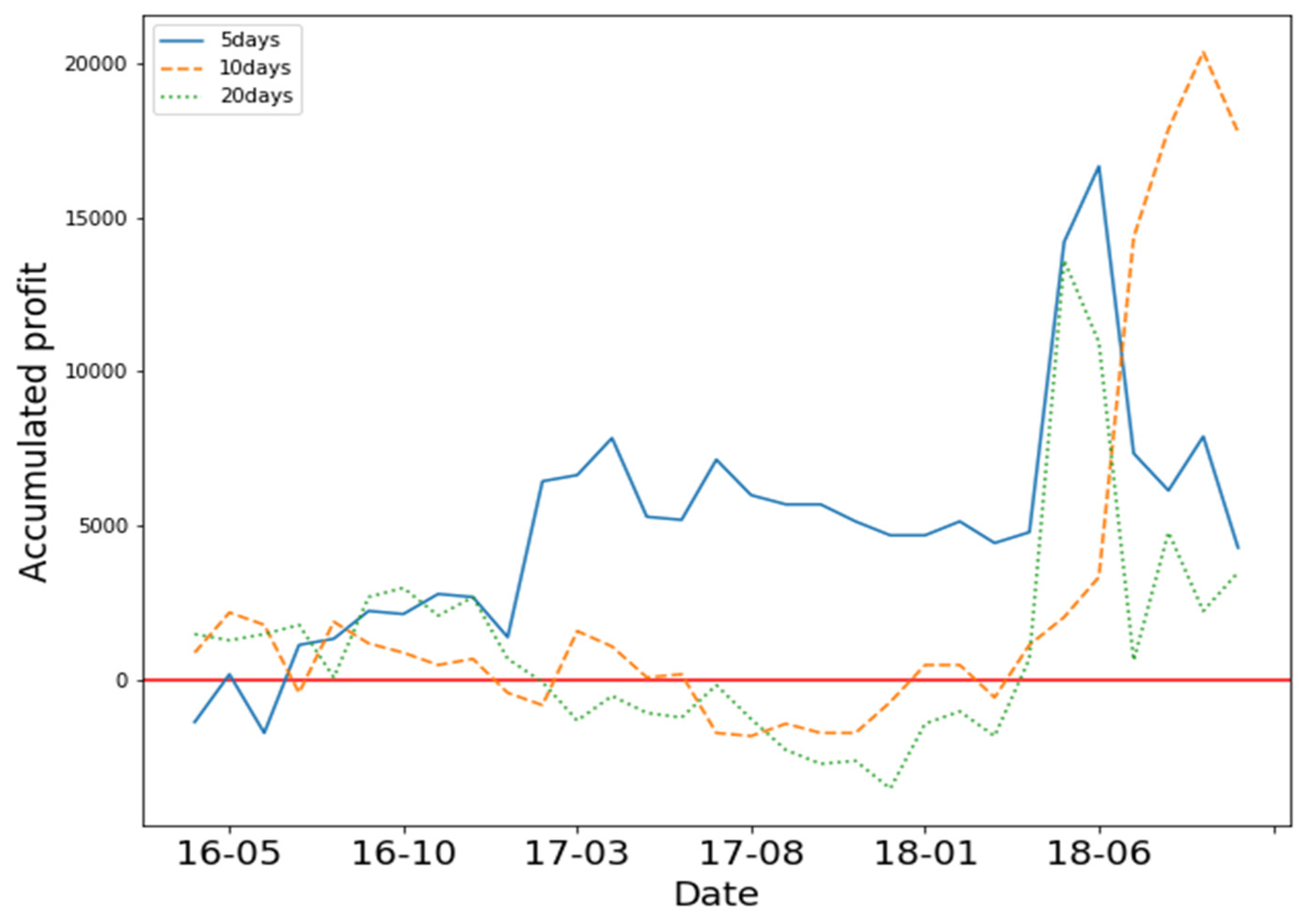
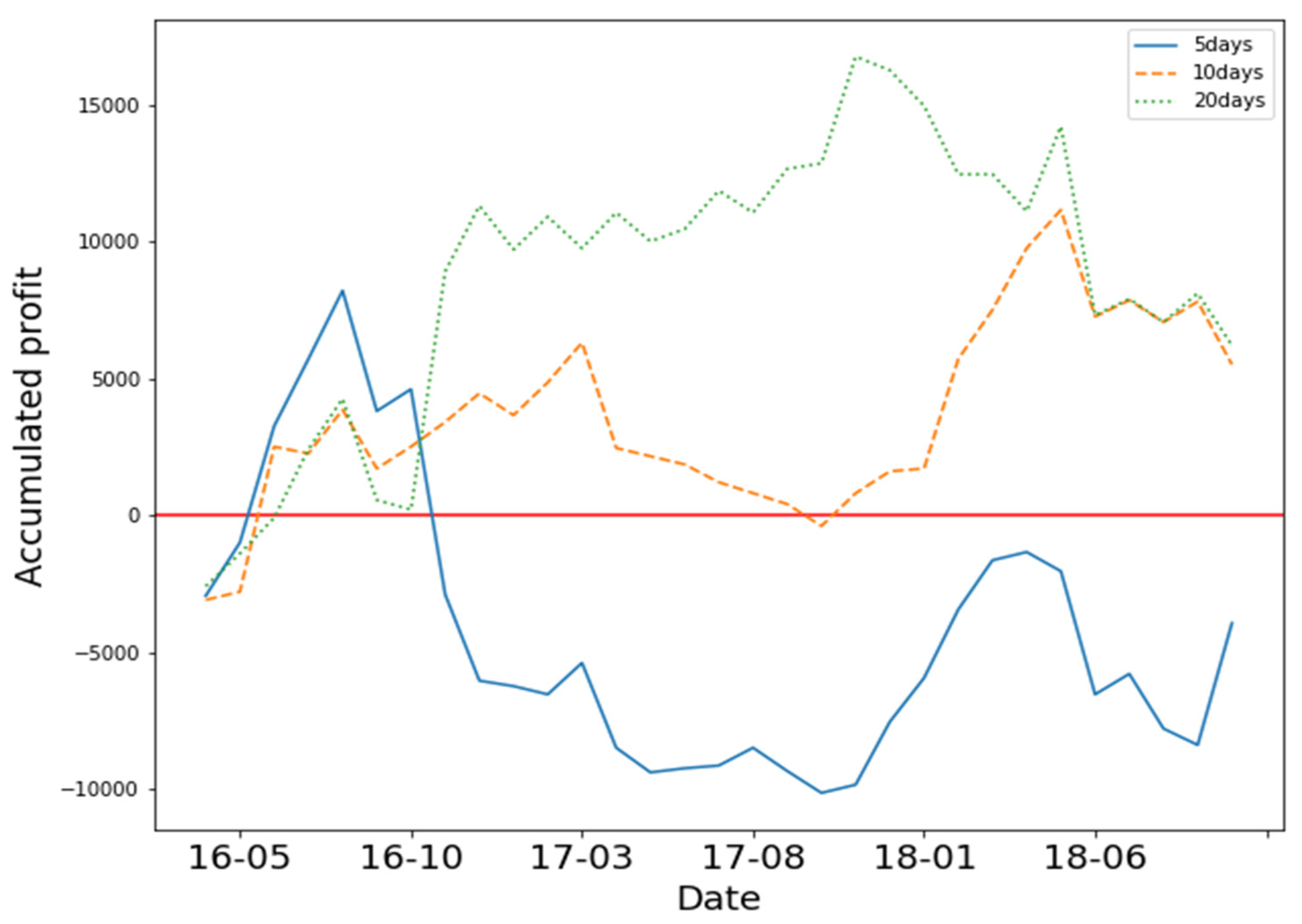
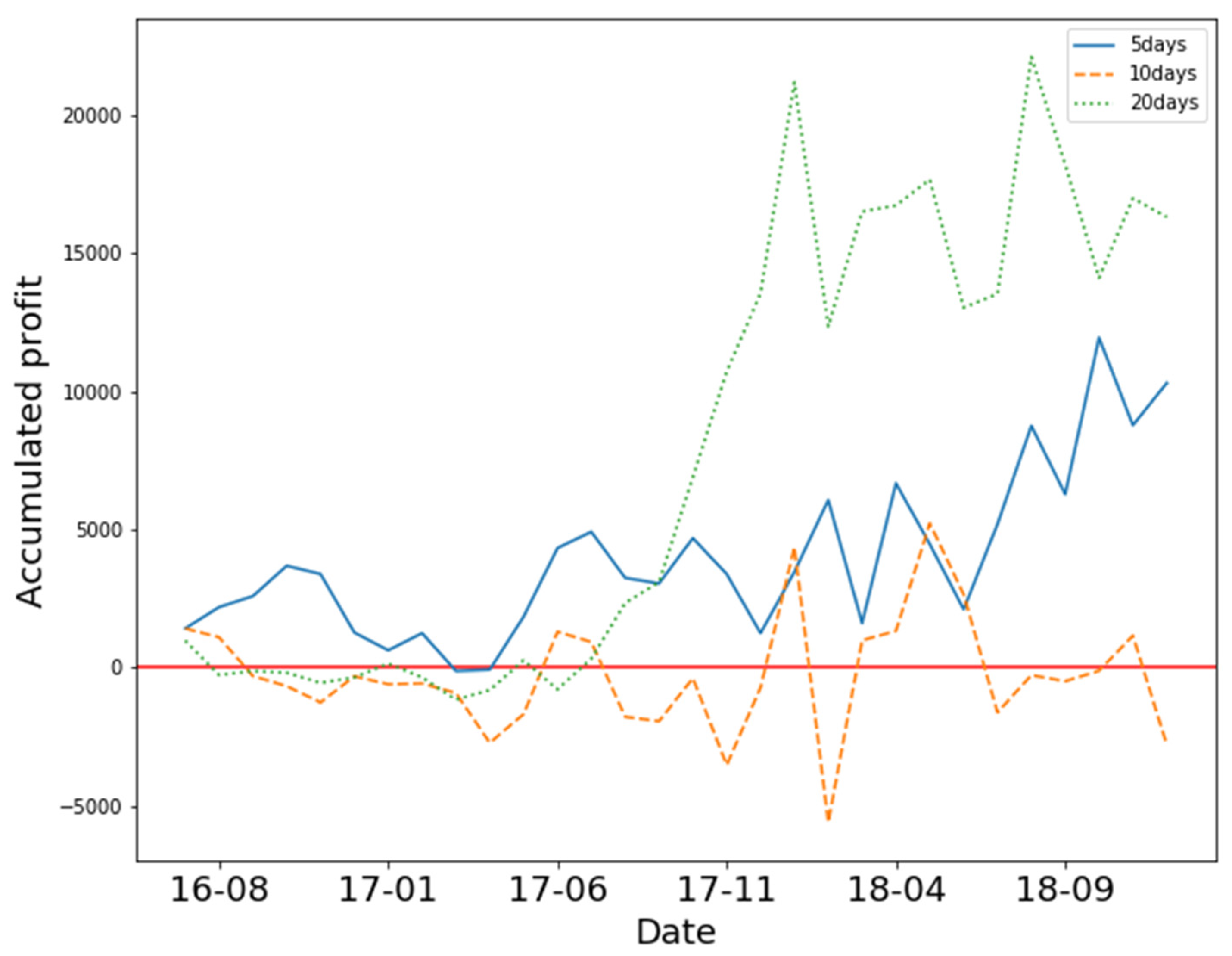
In
Figure 4, the results show that 5-day, 10-day and 20-daysstates yielded positive profit. Training the model with 10 days of OHCLV on 1101 yielded the best performance. In addition, the model suffered a large loss in June 2018.
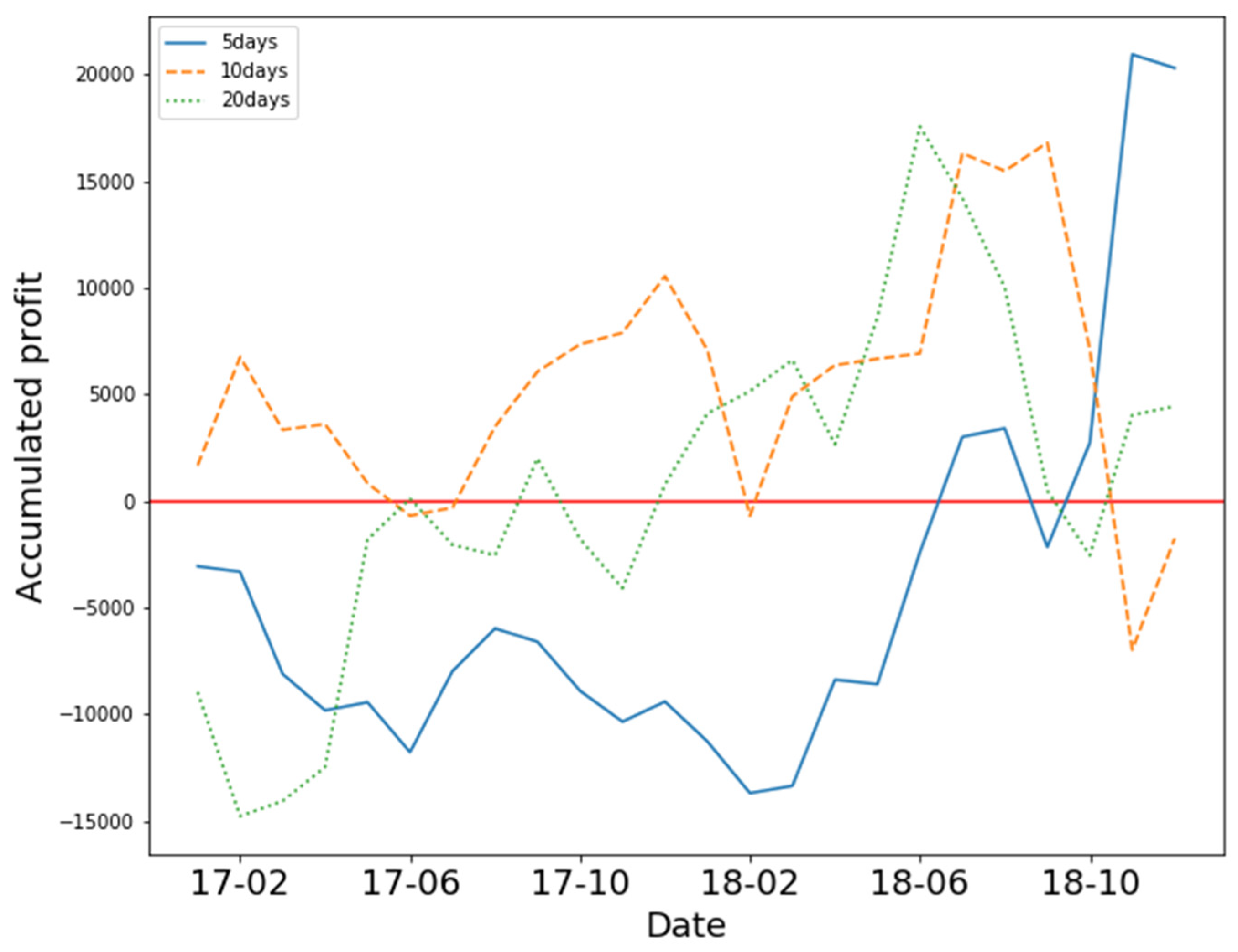
In
Figure 5, the results show that all three states yielded positive profits over time. Training the model with 10 days of OHCLV on 2330 yielded the best performance.
In
Figure 6, the results show that 10-day and 20-day states yielded positive profit, and the 5-day state yielded negative profit. Training the model with 10 and 20 days of OHCLV on 2881 yielded the best performance. The model for the 5-day state suffered a large loss in November 2016.
In
Figure 7 and
Figure 8, we trained the model to trade leveraged ETFs. Again, the Y axis represents accumulated profit, the X axis represents time, and the three different lines represent the accumulated profit of the three different states.
Figure 7 shows that 5-day and 20-day states yielded positive profit.
Figure 8 shows that the model suffered a large loss in November 2018.
As shown in
Table 4, we further used the win rate to analyze the performance of the framework. Our trading system’s win rates ranged between 48% and 60%; these low results were due to the goal of our framework, which was to build a framework that learns to trade a high stock spread between two days. The result show that our goal was achieved. Although we did not have a high win rate, we made a good profit.
4.3. The Evaluation of Financial Performance
The development of a strategy requires a good evaluation metric to judge whether the strategy is profitable. The most basic metrics include winning probability, odds ratio, maximum draw-down (MDD), and reward over MDD. We have listed the performance of our experiments in
Table 5,
Table 6,
Table 7 and
Table 8. In terms of profit factor (PF), if it is greater than 1, the strategy is in a profitable state. Generally, PF is recommended to be greater than 1.5, so that the cumulative profit and loss curve rises steadily. In the experiment, we observed that our trading model performed well for most parameters.
5. Conclusions and Future Work
Traditionally, it is difficult to create a trading strategy. We must analyze many aspects of the target—price data, technical indicators, and so on—after which we must decide when to trade and how many shares to trade. This is a difficult and time-consuming job for traders. Hence, we built an automated trading framework based on deep neural networks and reinforcement learning. The experiment used five different Taiwan stock constituents from January 2009 to December 2018.
We make three key contributions to the literature: focusing on the different deep neural networks, we found that LSTM outperformed other neural networks in financial time series prediction tasks based on our collected stock data. LSTM outperformed for four of five different stocks. The second contribution is our automated trading system, based on five kinds of basic daily price data (e.g., open price, highest price, closed price, lowest price, and volume). Our trading strategy was daily trading within two days. We obtained trading signals and sizes from our framework to decide whether to sell, hold or buy, and close the position the next day. We demonstrated that the proposed framework yielded good returns in some stocks. However, we only verified our framework on the Taiwan stock market, and we used the same neural network to construct a framework for five different stocks.
Recently, some researchers have proposed framework integrated stock prices and financial news for stock prediction. In future research, sentiment analysis of news articles should be integrated as another resource of information on the environment. A reinforcement learning model should also be applied in the cryptocurrency market, including Bitcoin, Ethereum, and so on.
A limitation is that the proposed model was only evaluated for one stock at the Taiwan stock market. Since we were limited with respect to funding, we only collected a small dataset for evaluating the proposed model. Future work should include verifying the proposed model by collecting a larger dataset.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}