1. Introduction
In the scientific community, there has recently been increasing interest in approaching different estimation problems in systems with observations proceeding from multiple sensors. Evidently, this availability yields better estimations, since the information supplied from several sensors may compensate for the possible adverse effects of some faulty sensors, communication errors, or defects when using a single sensor. According to the way that information is fused, the estimation techniques can be categorized into two large groups:
centralized and
distributed methods. In the former group, all the observations from all the sensors are directly sent to the fusion center to be processed in a single fusion estimator. In the latter, the observations at each sensor are independently processed, providing a local estimator, and, afterwards, in the fusion center, a single distributed fusion estimator is built from these local estimators. Both fusion “architectures” have strengths and weaknesses, meaning that they can be used alternatively in practice, depending on the problem at hand. As is already known, the centralized method provides a theoretical, optimal solution to the estimation problem; in contrast, this may imply a heavy computational burden, and a high bandwidth may be required. Moreover, the architecture cannot be changed [
1,
2,
3,
4]. In contrast, the situation with the distributed fusion method the opposite. This method has great advantages over the centralized one due to the fact that it requires a lower computational load and communication costs, and is more robust in terms of failure and flexibility. However, the disadvantage of this method is that the optimality condition of the estimators is lost [
2,
5,
6]. Nevertheless, this weakness is acceptable when considering the advantages that this methodology presents, accounting for the slight difference that there may be in practice between the estimators obtained by both methods.
Furthermore, in data transmission problems, random delays, packet dropouts, or missing measurements frequently occur. These problems are caused by limited communication capabilities or some failures in transmission components. In the real domain, there is a wide-ranging literature on signal linear processing under uncertain outputs based on both centralized (see, e.g., [
7,
8,
9], among others) and distributed fusion methods (see, e.g., [
10,
11,
12,
13,
14]). In all of them, different scenarios concerning the initial state-space model and the characteristics of the observations from the sensors are considered. More specifically, by considering these three mixed uncertainties, the centralized fusion linear optimal estimation problem has been solved in [
8]. In multi-sensor systems with missing measurements, the centralized and distributed fusion estimators have been obtained in [
9] and [
11,
12], respectively, by assuming different conditions for the noise variances and updating the state at each sensor. An analysis of the effects of these packet losses has been developed in [
15] for the centralized Kalman filtering and [
12,
16] for the distributed fusion filtering problem. Moreover, the distributed fusion estimation problem has also been studied in networked systems, for a class of uncertain sensor networks with multiple delays [
7,
10], and assuming correlated noises [
13,
14]. In the above references, the situations referring to the uncertainties in the observations are usually modeled by Bernoulli random parameters with known probabilities. Indeed, this is the most common probability distribution to describe the different types of uncertainty.
In the last two decades, the interest in hypercomplex domains has considerably grown due to their adequacy in describing a high number of physical phenomena. Their usefulness lies in the fact that they operate in higher-dimensional spaces, and are thus able to explain the relationships between the dimensions. As an example, we can mention the use of hypercomplex domains in virtual reality [
17,
18], acoustic applications [
19,
20], communication [
21,
22], image processing [
23,
24], seismic phenomena [
25,
26], robotics [
27,
28], materials [
29,
30], avionics [
31,
32], etc.
At the same time, the need to address, among other aspects, the signal processing problem by using 4D hypercomplex algebras arises. To date, quaternion algebra has been the most commonly used type of algebra in signal processing, since it is a normed division algebra. Specifically, in the optimal signal estimation problem, under the so-called widely linear (WL) processing, the signal quaternion and its three involutions have to be considered. Nevertheless, the processes involved in the model can present some properties that lead to a reduction in the dimension of the model by considering the quaternion signal itself, called strictly linear (SL) processing, or a two-dimensional vector given by the quaternion signal and its involution over the pure unit quaternion, named semi-widely linear (SWL) processing. This reduction in the dimension of the model entails a major decrease in the computational burden. In this framework, the WL estimation problem has been studied in [
17,
19,
31] for different real problems, and algorithms based on the Kalman filter have been proposed in the quaternion field. Moreover, in multi-sensor systems, the WL distributed fusion estimation problem has been addressed in [
33,
34,
35,
36,
37]. In addition, for systems with missing observations, WL and SWL filtering, prediction and smoothing algorithms have been designed in [
38] and [
39], respectively, with correlation hypotheses on the state and observation noises considered in the latter. Additionally, the WL estimation problem in multi-sensor systems with random delays, packet dropouts, and uncertain observations has been studied in [
40]. It should be highlighted that quaternion processing is not always the most appropriate methodology. In fact, the use of tessarine signals can bring, under certain conditions, a better performance of the estimators, as has been tested in [
41,
42,
43].
However, the signal estimation problem in the tessarine domain has hardly been studied at all. This is due to the fact that the set of tessarine random variables does not have a Hilbert space structure; therefore, it is difficult to calculate the LS linear estimator. Recently, in [
41], a metric has been defined in the tessarine domain that satisfies the properties necessary to guarantee the existence and uniqueness of the projection. Moreover, by making an analogy with the quaternion domain, the authors define
-properness, and prove that the tessarine widely linear (TWL) estimation error coincides with that of
, which yields a considerable reduction in the computational cost of obtaining the optimal solution. Later, the
-properness definition is established in [
42], obtaining the same result for the TWL and
estimation errors. These types of
-properness have been used in [
43] to approach the LS linear centralized fusion estimation problem of signals from multi-sensor observations with random delays.
Considering these benefits for the
-properness, in this paper, we address both distributed and centralized fusion LS estimation problems in tessarine systems with mixed uncertainties of randomly delayed and missing observations proceeding from multiple sensors. At each sensor and instant of time, each tessarine component can be updated, delayed, or contain only noise, independently of the remaining sensors. We have also assumed a correlation between the signal and observation noises, which is a very desirable property for multi-sensor systems, since the observations act as output feedback [
14]. By using an innovation approach, recursive algorithms are derived to compute the LS distributed and centralized fusion filters. These have been characterized for both
-proper scenarios, where the reduction in the system dimension is clearly reflected. A decrease in the computational burden can also be observed by using the distributed filtering algorithm instead of the centralized one and, although the distributed algorithm provides suboptimal estimators, a simulation example shows that the differences between them may be insignificant in practice.
The rest of the paper is organized as follows. In
Section 2, the notation that will be used throughout the paper is established, as well as a revision of the main concepts and results in the tessarine domain. Next, in
Section 3, the tessarine state and observation equations (both the real and available ones) are established, as well as the hypotheses on the processes involved. The different mixed uncertainties are modelled by using Bernoulli random variables with known parameters, whose values of one or zero determine if an observation is updated, delayed, or contains only noise. Then, the augmented model (by considering the three conjugations) is presented in
Section 4, and the conditions for the processes which guarantee
-properness are studied. The reduction in the model under these
-properness conditions is shown and, in this scenario, a recursive algorithm is proposed to obtain the local optimal LS linear filtering estimators. Subsequently, in
Section 5, by considering the compact model, that is, the observations from all the sensors, a recursive algorithm is devised to obtain the optimal LS linear centralized fusion filter under
-properness conditions. Adittionally, a method for the recursive computation of the
distributed fusion filter as the LS matrix-weighted linear combination of the optimal local LS linear estimators is proposed in
Section 6. Afterwards, a numerical simulation example in
Section 7 illustrates several items: (i) the superiority of both fusion filters over the local ones, (ii) the performance of the fusion filters increases as the updating and delay probabilities become greater and by comparing the same probability that the observation is updated or delayed; (iii) the accuracy of the centralized fusion filter is better than the distributed one, but the difference is almost insignificant. Finally, a section of conclusions (
Section 8) and two appendixes with the proofs of all the results in the paper have been included.
2. Preliminaries
In this section, we introduce the basic notation that will be used in this paper. Matrices will be written in bold, upper-case letters, column vectors in bold, lower-case letters, and scalar quantities in lightfaced letters. We will use the superscripts “*”, “” and “” to represent the tessarine conjugate, transpose and conjugate transpose, respectively. For , we will denote the zero matrix, the identity matrix of dimension n, and and , the column vector of dimension n with all its elements 1 or 0, respectively. Letters , and will represent the set of integer, real and tessarine field, respectively. Moreover, (respectively, ) means that is a real (respectively, tessarine) matrix. Similarly, (respectively, ) means that is a m-dimensional real (respectively, tessarine) vector.
In addition, and will denote the expectation and covariance operators and is a diagonal matrix with the elements specified on the main diagonal. Finally, “∘” and “⊗” denote the Hadamard and Kronecker products, respectively, and , the Kronecker delta function. We will use the following property of the Hadamard product:
Property 1. If and , then .
Throughout this paper, and unless otherwise stated, all the random variables are assumed to have zero-mean. Next, we present a review of the tessarine domain.
Definition 1. A tessarine random signal is a stochastic process of the form [41]where , for , are real random signals and the imaginary units satisfy the identities: These properties of the imaginary units guarantee the commutative property of the product, implying a great advantage over the quaternion algebra, in which that property is not met. In contrast, the involutions defined in the quaternion domain cannot be defined in the tessarine one because they are auto-involutive. The conjugate of the tessarine signal given in (
1) is defined as
and the auxiliary tessarines as
It is also defined the real vector formed with the components of
in (
1),
, and the augmented tessarine signal vector constituted by the tessarine signal
and its conjugations, i.e.,
. The relationship between both vectors is given by the following expression
where
, with
This property is satisfied: .
As in the quaternion field ([
38]), we define the following product between tessarines, which will be crucial to model the intermittency and delay in the observations.
Definition 2. The product ★
between two tessarine signals is defined as The following property of the product ★ is easy to check.
Property 2. The augmented vector of is , where .
Definition 3. The pseudo autocorrelation function of the random signal is defined as , , and the pseudo cross-correlation function of the random signals and is defined as , .
The concept of
and
-properness we next define, was recently introduced in [
41] and [
42], respectively, and consists of the vanishing of some of the
pseudo correlation functions of the signal with its conjugations, in an analogous manner to what was in the quaternion domain.
Definition 4. A random signal is said to be -proper (respectively, -proper) if, and only if, the functions , with (respectively, ), vanish for all . Similarly, two random signals and are cross -proper (respectively, cross -proper) if, and only if, the functions , with (respectively, ), vanish for all . Finally, and are jointly -proper (respectively, jointly -proper) if, and only if, they are -proper (respectively, -proper) and cross -proper (respectively, cross -proper).
Note that, in TWL processing, the fact that
-properness is satisfied, causes a considerable reduction in the dimensions of the processes involved, with the consequent decrease in the computational cost. More specifically, in the most general case, TWL processing uses the augmented vectors formed by the process and its three conjugations. However, if tessarine linear processing is applied by considering only the process or the process and its conjugate, then they are denominated
and
linear processing, respectively. In [
41], the authors prove that, in general, the TWL estimation error is lower than that of
, but under
-properness conditions, both the TWL and
estimators coincide. Analogous considerations about
processing are shown in [
42]. Moreover, both papers propose statistical tests to experimentally check if a signal is
-proper, for
, and prove that, under certain conditions, the tessarine processing can obtain better estimators than the quaternion one. The statements above justify that the
-properness conditions are very desirable in practice. In this sense, it will be of great interest to determine under what conditions
-properness is guaranteed.
3. Model Formulation
Consider a tessarine state
satisfying the following state equation:
where
, for
, are deterministic matrices and
is a tessarine noise.
We also assume that
R sensors exist, providing each of them with a real observation,
, satisfying the following equation:
with
a tessarine noise.
As it occurs in multiple practical situations, due to failures in communication channels, network congestion or some other causes, the available observations can suffer delays and even contain only noise in an intermittent manner. This fact can be modelled by the following equation for the available observation in each sensor,
, for
:
For each sensor and for , is a tessarine random vector whose components are composed by independent Bernoulli random variables , with with known probabilities , respectively. Values of one or zero for these Bernoulli variables indicate if the corresponding component of the available observation is updated, one-step delayed or only contains noise. These variables must satisfy that, for each , or at each instant of time; that is, if one of them takes value 1, the other one is 0, or both are 0; moreover, . In this sense, if , then ; that is, it contains the updated observation component; if , then , the available observation component is that delayed one instant of time and, finally, if , then ; that is, it contains only noise. Observe that the initial available observation is updated.
We assume the following hypotheses for the model defined in (
2)–(
4):
Hypothesis 1 (H1). and , are white noises with pseudo variances and , respectively. Moreover, they are correlated at the same instant of time, with .
Hypothesis 2 (H2). is independent of for , with .
Hypothesis 3 (H3). For each sensor , and , the Bernoulli variables in are independent of those in , for . The same hypothesis for and with .
Hypothesis 4 (H4). The initial state, , (whose pseudo variance is denoted by ) and the noises , and , for , , are mutually independent.
An example of the above scenario can be found in the problem of dynamic targeting tracking (see, e.g., [
13]) and, in particular, in the problem of tracking the rotations of an aircraft [
35,
36].
4. Local -Proper LS Linear Filtering Problem
In this section, the local LS linear filtering problem is studied for the tessarine model described above; that is, for each sensor
, the optimal lineal estimation problem of the signal
is addressed from the observations provided by that sensor
i. For this purpose, firstly, the model is formulated at each sensor, by considering both delays and the internittency in the avilable observation equation. Moreover, due to the great computational advantages, the conditions on the processes involved to ensure
-properness are proposed. Once the model has been formulated, a recursive algorithm is presented to obtain the optimal local LS linear filters. In
Section 6, this algorithm will be necessary to address the distributed fusion LS linear filtering problem.
4.1. Local -Proper Model Formulation
For each sensor
, the augmented version of the model defined in Equations (
2)–(
4) is as follows
where
with
, for
, and
, defined in Property 2. Moreover, the
pseudo variances of the augmented white noises
and
are denoted by
and
, respectively,
, and
.
Next, conditions for the processes involved in (
5), which guarantee a
-properness scenario, are given in Property 3.
Property 3. Consider the model described in Equation (5): - 1.
If and are -proper, and is a block diagonal matrix of the formthen is -proper. If additionally , , is -proper, and and are cross -proper, then and are jointly -proper. In this scenario,with Moreover, .
- 2.
By substituting in the last item by and the matrix by this otherand assuming that the Bernoulli parameters now satisfy that and , , an identical property can be established for the joint -properness of and . In this case, the expectation of the multiplicative noises are given bywithand
Note that these
-property conditions allow us to reduce the dimension of the available observations; that is,
and
, for
and
-proper scenarios, respectively, and hence, the observation equation given in (
5) is now expressed in the following terms:
where
with
and
Moreover, under
-properness, for
and
,
where the matrices
, for
, are defined in Property 3.
Remark 1. Let us observe that the -properness also causes a dimension reduction in the remaining processes and matrices involved in Equation (5). More specifically, in the -proper scenario, , , and , are substituted by , , , and ; and, in the -proper scenario, by , , , and (given in (6)). The corresponding pseudo variance matrices of the noises and as well as its pseudo cross-covariance matrix, will be denoted by , , and , respectively; moreover, . 4.2. Local LS Filtering Estimators
Given the model described in (
5), with the available observation equation in (
7) for the
-proper scenarios, a recursive algorithm to calculate the local LS filtering estimators is presented in this section. This estimator, denoted by
, represents at each sensor
i, the optimal LS linear estimator of the signal
from the observations
. Note that this estimator can be obtained by projecting
over the linear space spanned by the observations
. At the tessarine domain, the existence and uniqueness of this projection is guaranteed ([
41]). To derive this algorithm, the innovations are used, instead of the observations, defined as
, with
the optimal LS linear estimator of the observation
from the observations until the previous instant, that is,
.
Theorem 1. For each sensor , the optimal filter, , is obtained by extracting the first n components of , which satisfies this expressionwhere , can be recursively calculated aswith initial conditions , and . The innovations, , satisfy this relationwith initial condition and . Moreover, the matrices are obtained by this expressionwithand given in (16). The pseudo-covariance matrix of the innovations, , is calculated as followswith the matrices , for , given byand , by this other relation Moreover, satisfies the following recursive formula Finally, the pseudo covariance matrices of the filtering errors, , are obtained from , which satisfies the following recursive formulawith , calculated by this other equationand initial conditions , and . Remark 2. Notice that, similarly to QWL processing, TWL processing is isomorphic to the real processing;thus, any WL algorithm could be equivalently expressed through a real formalism. In other words, the three approaches (QWL, TWL and ) are completely equivalent. However, this equivalence vanishes under properness conditions.
Effectively, under , for , properness conditions, the dimension of the observation vector is reduced 4/k times, which leads to estimation algorithms with a lower computational load with respect to the ones derived from a TWL approach (see [44] for further details). Specifically, this computational load is of order for the TWL local LS filtering algorithm, whereas this is of order for the , for , algorithms. Similar comments can be applied to the following centralized and distributed fusion filtering algorithms.
5. -Proper Centralized Fusion Linear Filtering Problem
In this section, we approach the centralized fusion LS linear filtering problem, that is, by using the observations from all the sensors jointly. For this purpose, we consider the augmented vector for both real and available observation, denoted by
, and
, respectively. In this way, the observation equations now are given as follows
where
,
, for
, and
, with
,
. Moreover,
, and
, with the matrix
given by
.
However, as previously commented on in
Section 4.1, under
-properness conditions, it is possible to reduce the dimension of the available observation equation, which can be expressed as follows:
where
,
, with
,
given in (
8), and
. Moreover,
with
and
, for
, given in (
9).
Note that the centralized fusion LS linear filter under -properness conditions, , is the optimal LS linear estimator of the signal from the observations . This optimality condition is harmed by the computational complexity, especially as the number of the sensors increases.
The next corollary contains a recursive algorithm to determine the centralized fusion linear filter, for the state equation in (
5), and the real and available observation equations described in (
19) and (
20), respectively, which can be derived by following an analogous proof to that used in Theorem 1.
Corollary 1. For previously described model, the optimal centralized fusion filter, , is obtained by extracting the first n components of , which are recursively calculated as followswhere satisfies this formulawith initial conditions . Moreover, , , where , with , for , defined in Remark 1, and , for , with given in Property 3. The innovations, , are obtained as followswith , , and , with , and , for , defined in Remark 1. The matrices satisfy this relationshipwith given in (14). The pseudo covariance matrix of the innovations, , is obtained from this expressionwherewith computed in (16), and given by Finally, the filtering error covariance matrices, , are calculated from , which satisfy the following equationwhere can be recursively obtained from this relationwith initial conditions , and . 6. -Proper Distributed Fusion LS Linear Filter
Our aim in this section is to address the distributed fusion LS linear filter under
properness conditions,
, which in turn is calculated by extracting the first
n-components from
. This last estimator is a linear function of the local filters
, calculated in
Section 4, whose weights are those minimizing the mean squared error, and as is known, is of the form
where
. Moreover, taking into account Theorem 3 in [
41], the matrices of the above expression are computed as follows
where
. Moreover, the distributed fusion linear filtering error covariance matrices under
properness conditions,
, are obtained from
, which satisfies the equation
with
, and
given in (
16).
Then, it will be necessary to calculate these matrices
, for
, to obtain
. With this purpose, a recursive formula is proposed in Lemma 4, which involves the computation of another intermediate matrices through Lemmas 1–3, as well as some of the matrices defined in Theorem 1. The proof is deferred to the
Appendix B.
Note that, in contrast to the centralized fusion LS linear filter, the distributed fusion filter presented here loses the optimality condition; however, it does considerably reduce the computational burden. Moreover, in many practical situations, the difference in performance is so insignificant that this fact, in conjunction with the lower computational cost, makes the distributed filter preferable to the centralized one.
Lemma 1. For the model described in Section 4.1, the following expressions are satisfied for the defined expectations .where , , , and is given in (29). . .
Lemma 2. Let us consider the model described in Section 4.1. Then, the matrices , for , satisfy this relationshipwith the initial condition , and where , , with recursively computed as indicated in Lemma 3, and is obtained as follows Moreover, , is calculated from this expression Lemma 3. Considering the model described in Section 4.1, the matrices , for , are obtained from this equationwith initial condition . Moreover, the following recursive formula allows us to compute the matrices , Lemma 4. For the model described in Section 4.1, the pseudo-cross-covariance matrices of the local filters, denoted by , for , are calculated as followswhere satisfies this equationwith initial conditions . 7. Numerical Simulations
Our aim in this section is to show the performance of the proposed centralized and distributed fusion linear filters algorithms in several situations: on the one hand, in comparison with the local LS filters obtained at each sensor; on the other, focusing on the proposed fusion algorithms, to analyze the accuracy of the estimators by supposing different probabilities of updating, delay, and uncertainty in the observations from the sensors. In all of these situations, -properness conditions were assumed, which entails a considerable reduction in the computational burden.
For this purpose, let us consider the scalar tessarine model with delayed and uncertain observations produced by five sensors, described by the Equations (
2)–(
4), with
. Hypotheses (H1)–(H4), established in
Section 3, are also assumed to be satisfied. Moreover, the pseudo-covariance matrices of the noises and the initial state were defined with a general structure, differentiating between both
and
-proper scenarios. More specifically, the covariance matrices of the real state noise is given as follows:
Moreover, the other matrices in hypothesis (H1),
and
, for
, are given by the following relation between the noises
and
:
with
scalar constants (
), and
tessarine zero-mean white Gaussian noises, independent of
, with real covariance matrices,
, where
.
To complete the initial conditions of the model, the variance matrix of the real initial state is given as follows:
All these assumptions in each of the -proper scenarios, as well as the values considered in the parameters of the Bernoulli random variables (detailed below, in accordance with the conditions established in Property 3), guarantee that and are jointly -proper. These parameters are assumed to be constant in time, that is, , for , , and (Note that in the -proper scenario, , for all , , ; and, in the -proper scenario, and , for , ).
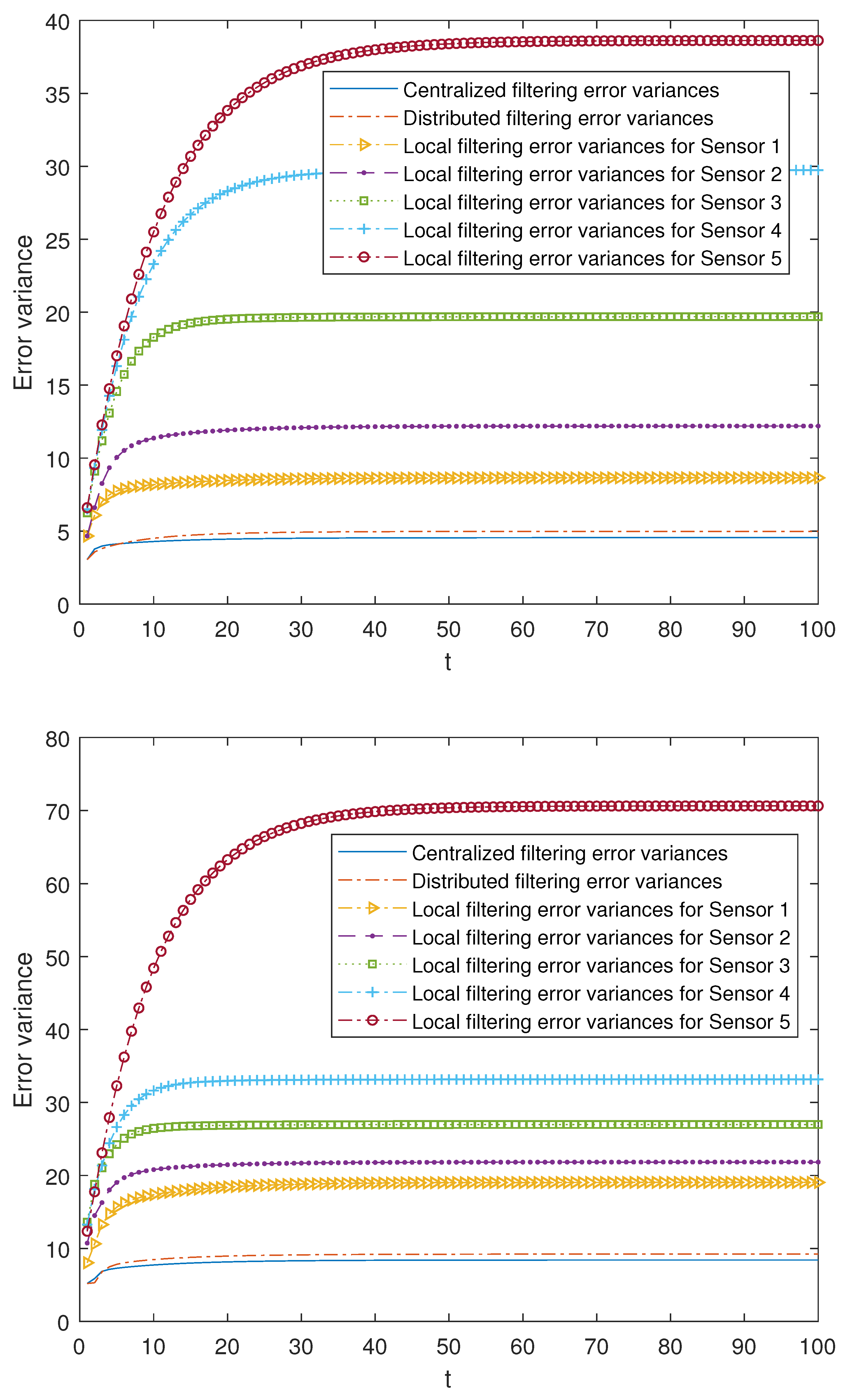
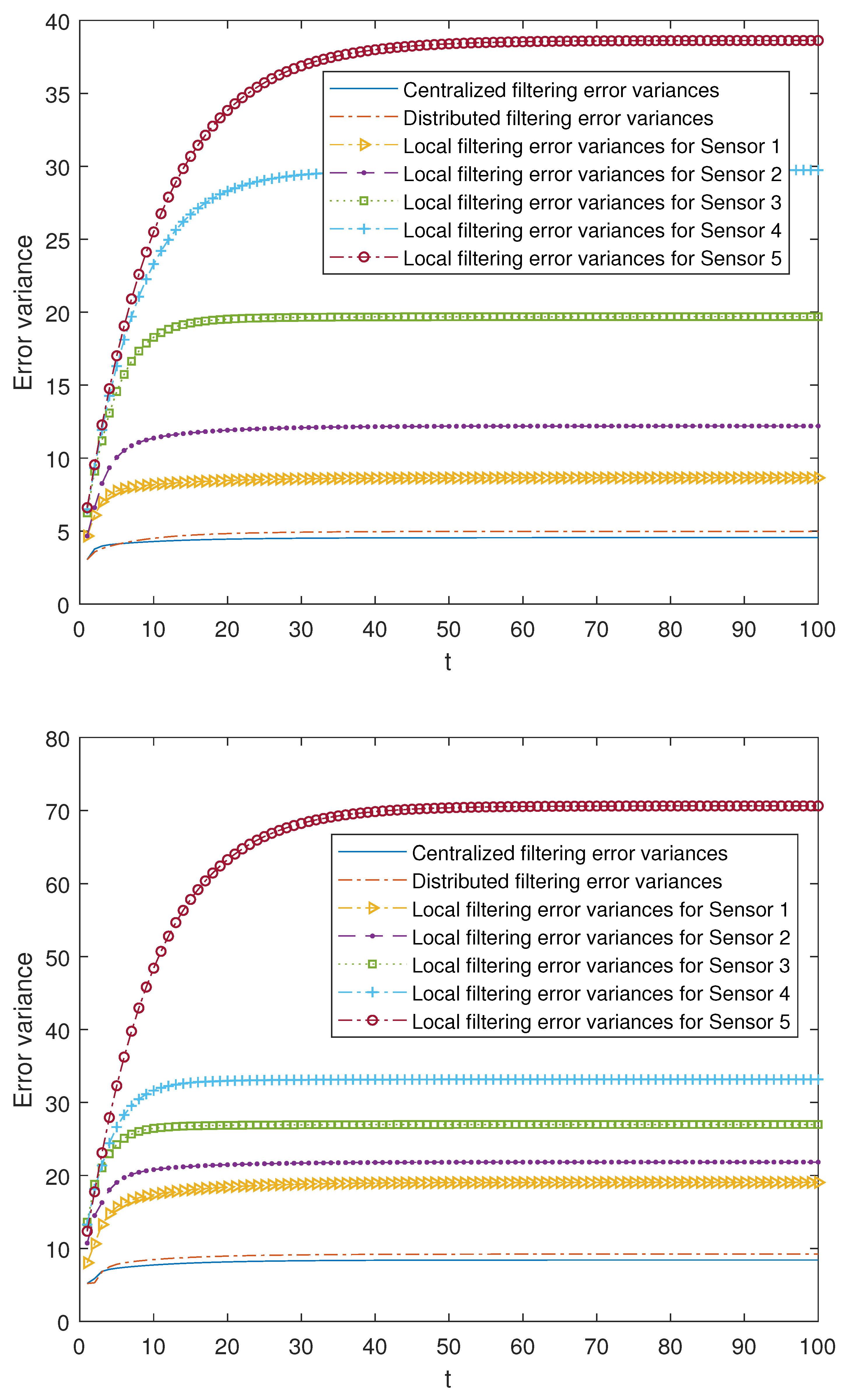
Firstly, taking fixed values for the probabilities for each of the -proper scenarios, the error variances of the local filters are compared with those of the centralized and distributed ones. These probabilities differ at each of the sensors, which allows us to make an initial attempt to contrast the three situations referred to the model, that is, the updated, delayed and uncertain observations. In this sense,
In the -proper case:
- -
Sensor 1: ,
- -
Sensor 2: ,
- -
Sensor 3: ,
- -
Sensor 4: ,
- -
Sensor 5: .
In the -proper case:
- -
Sensor 1: , , ,
- -
Sensor 2: , , ,
- -
Sensor 3: , , ,
- -
Sensor 4: , , ,
- -
Sensor 5: , for and .
The results are displayed in
Figure 1. The superiority of both centralized and distributed fusion filters over the local ones at each sensor can be observed, as well as the fact that these fusion filters have practically the same effectiveness, since their error variances are very close. Moreover, the local filtering error variances reflect the previously described three situations, considering the fact that the observations from sensors 1 and 2 are more conducive to being updated, those from sensors 3 and 4, delayed, and the most unfavorable case is for those from 5, since there exists a greater probability that they contain only noise. As before, the local error variances increase; then, the performance of the local filters becomes poorer as the situation of the updated, delayed and uncertain observations is more likely. Analogous results can be obtained by considering other different values of the Bernoulli parameters.
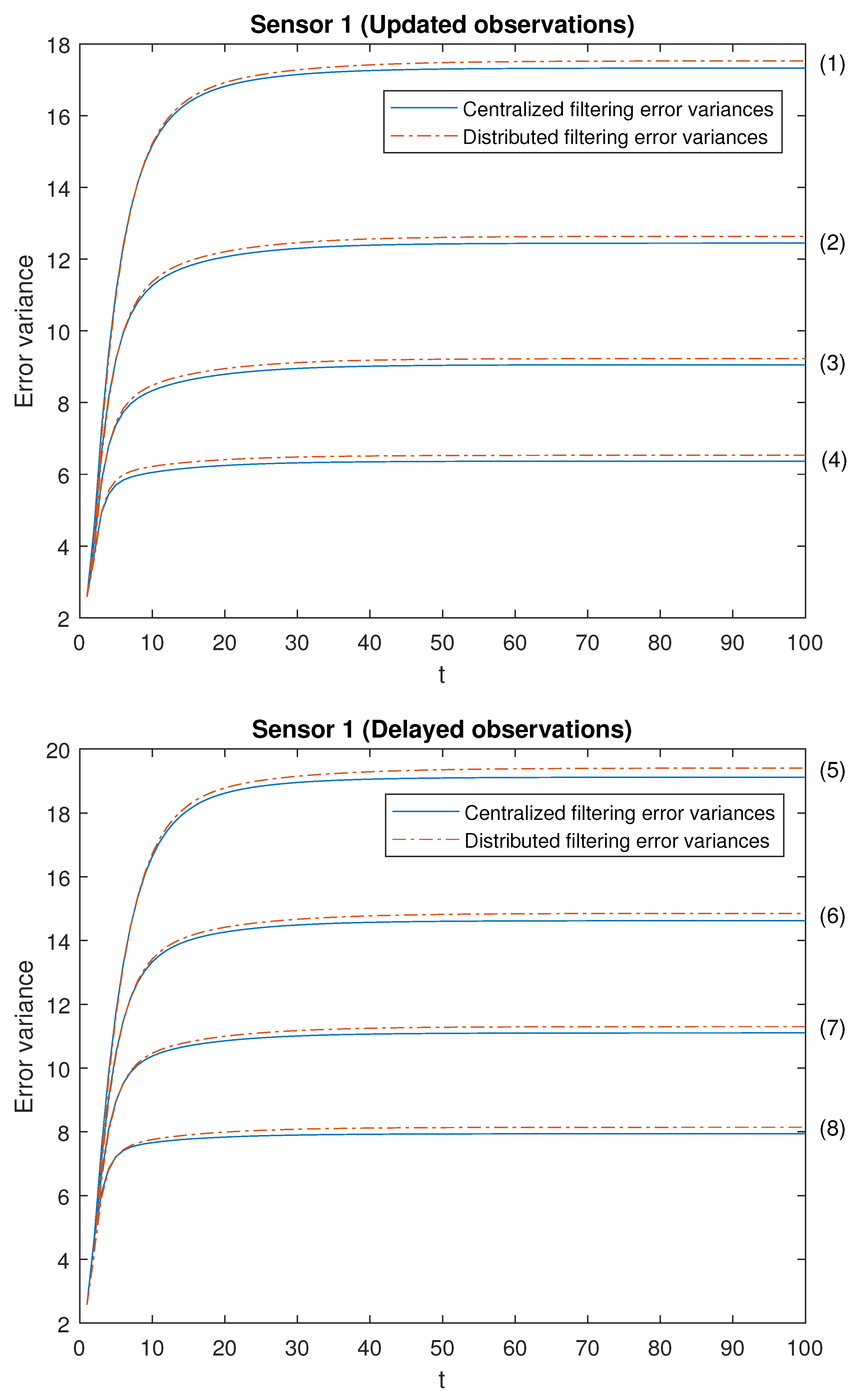
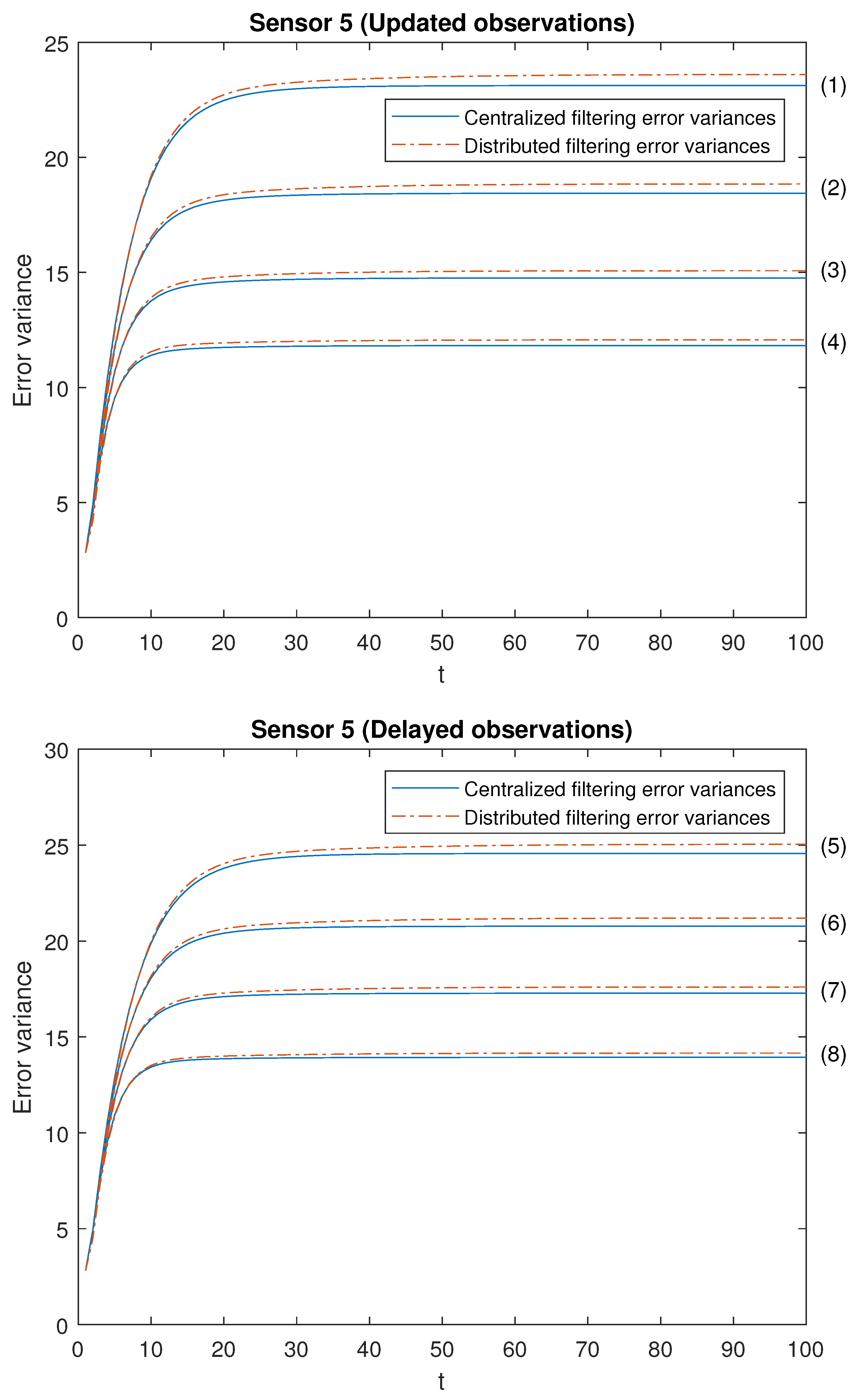
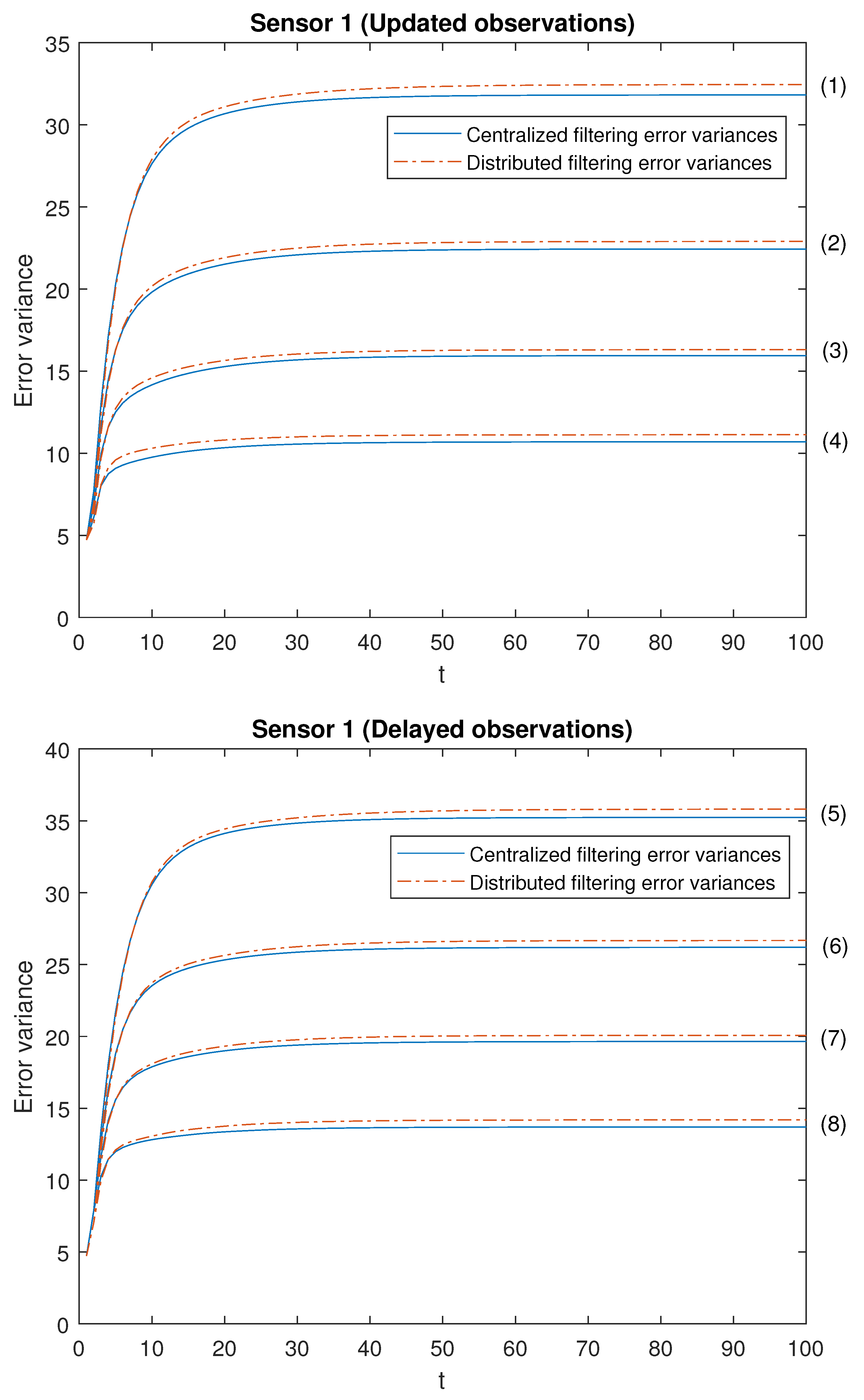
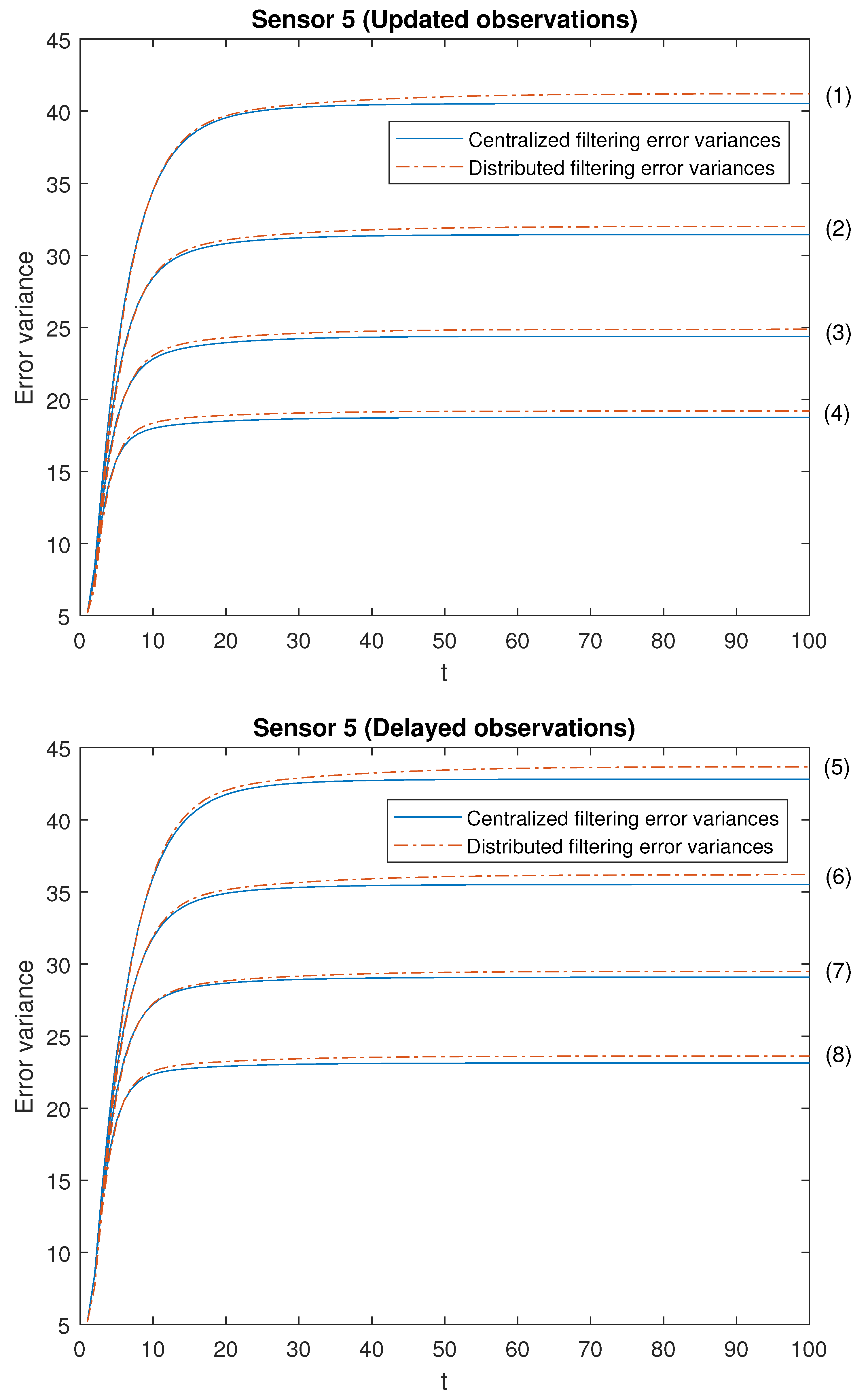
Our attention is focused on analyzing the accuracy of both centralized and distributed fusion filters in different situations concerning the observations produced by the sensors and in both -proper scenarios. For this purpose, we have considered the following cases with different values for the Bernoulli parameters:
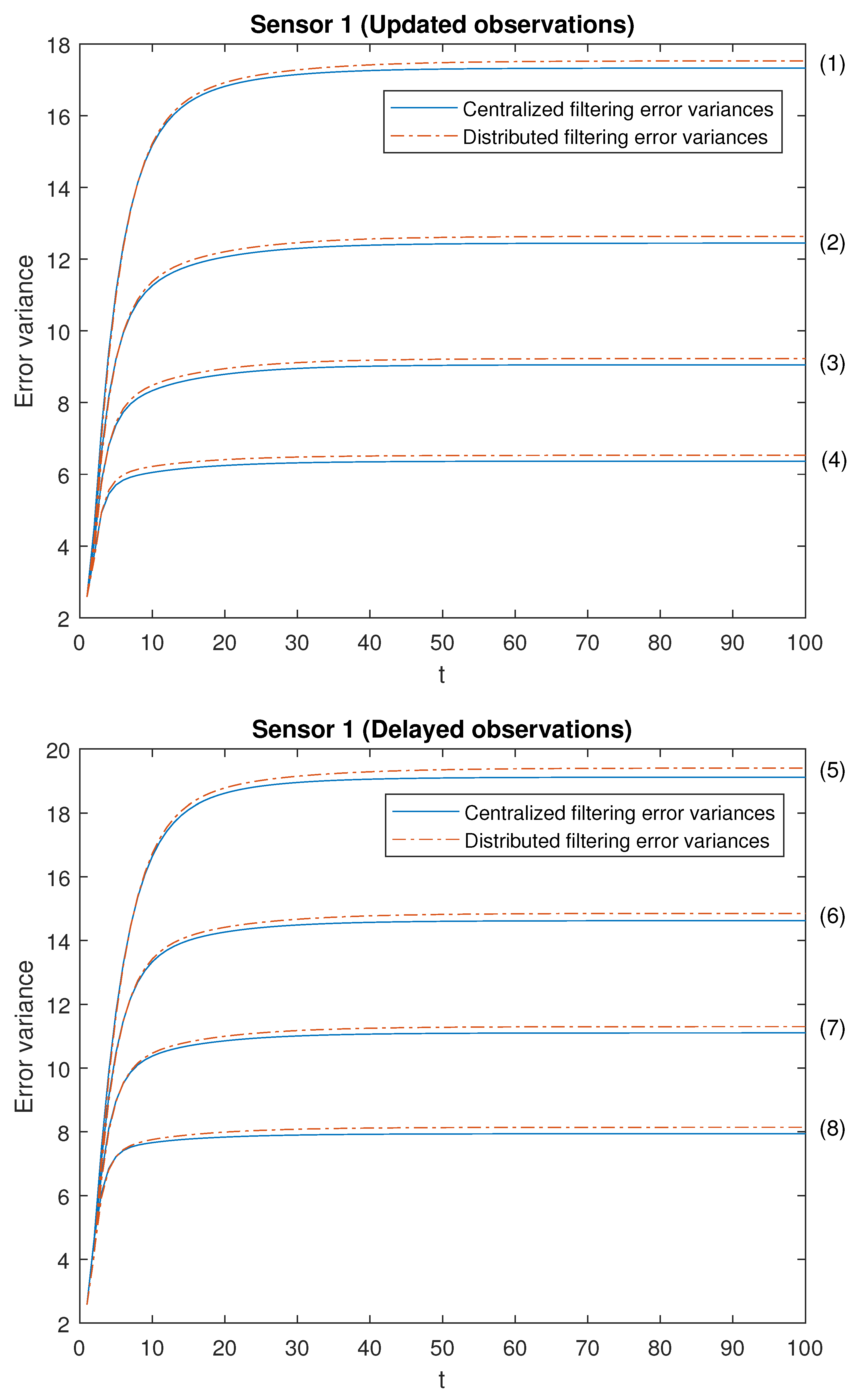
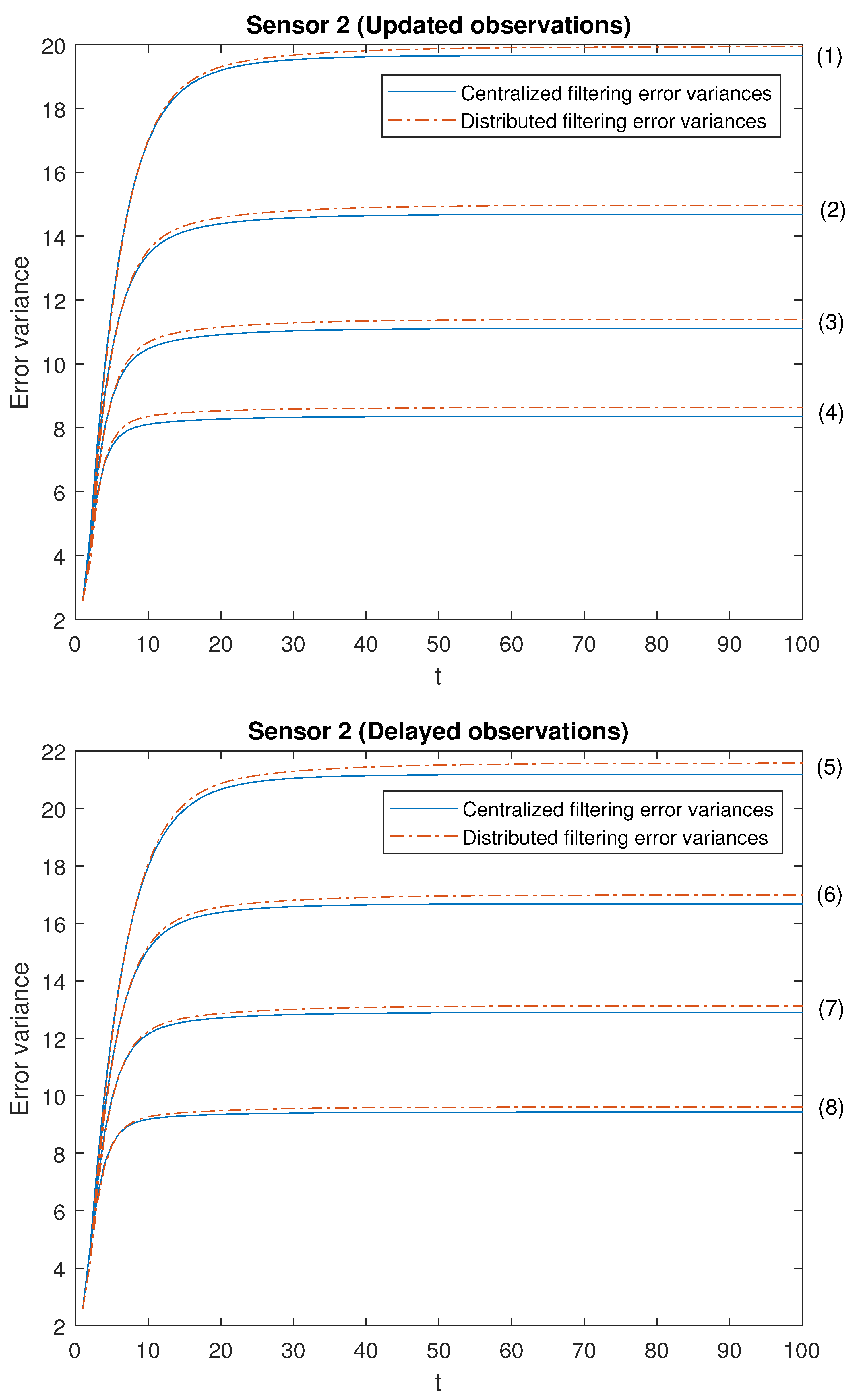
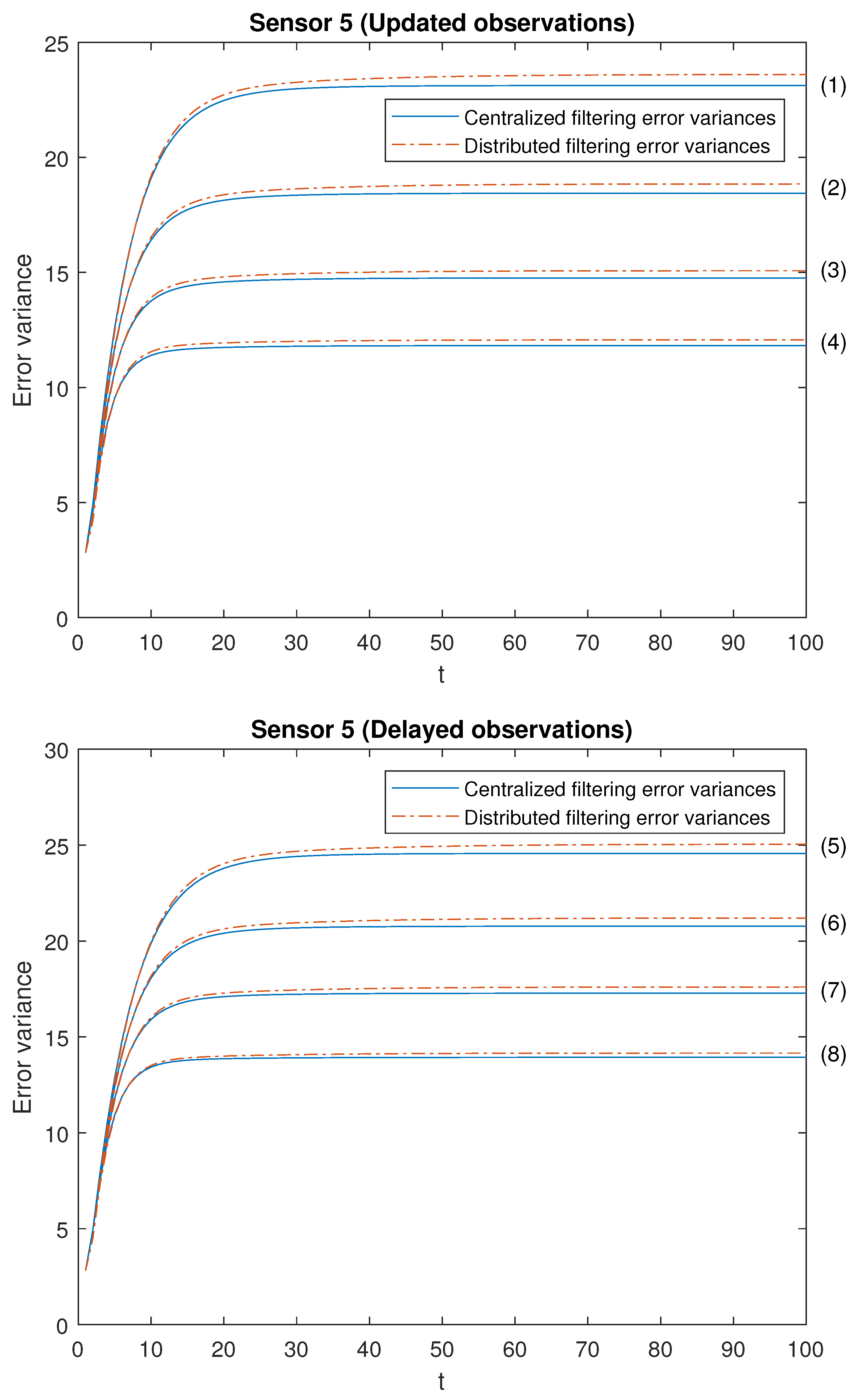
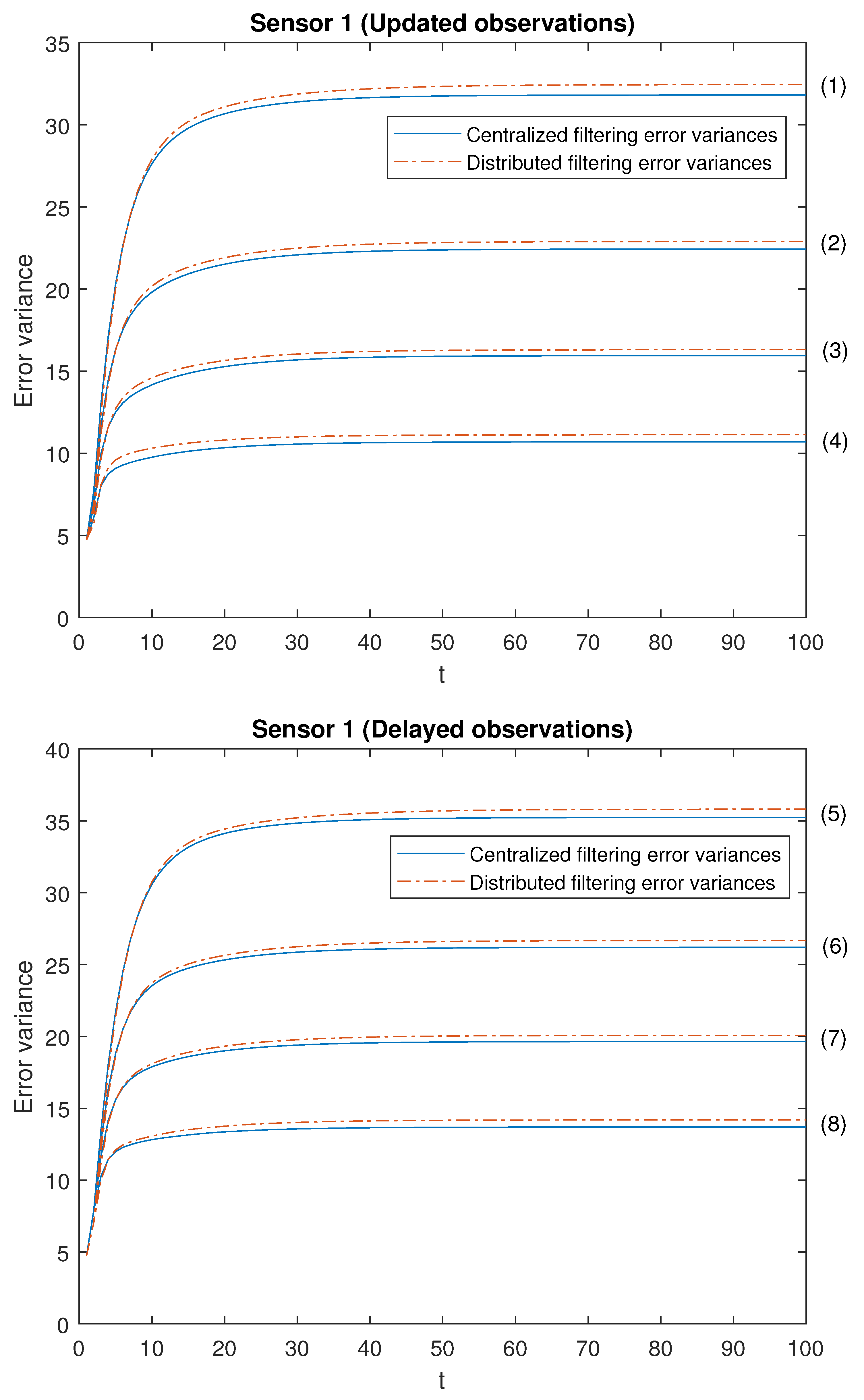
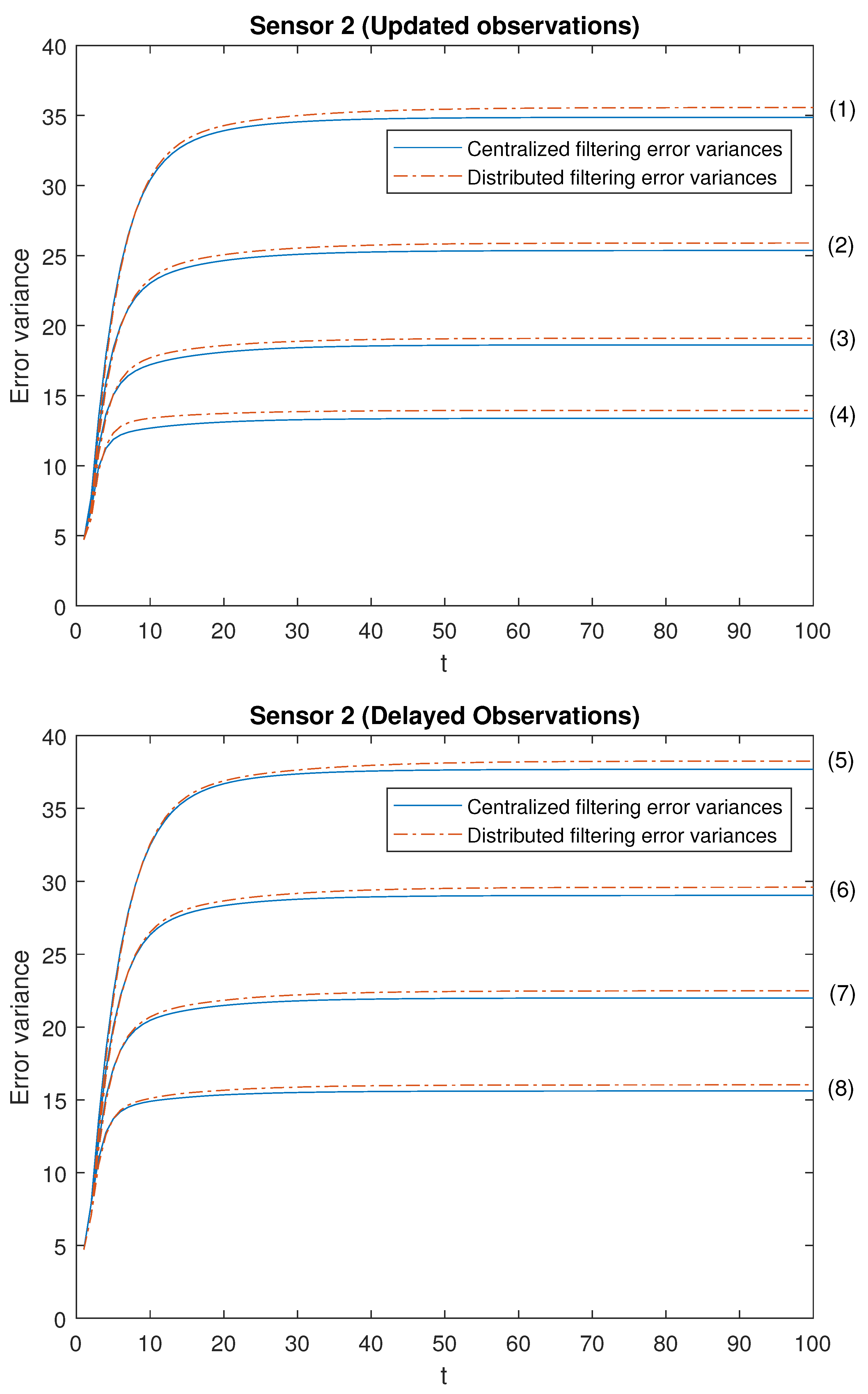
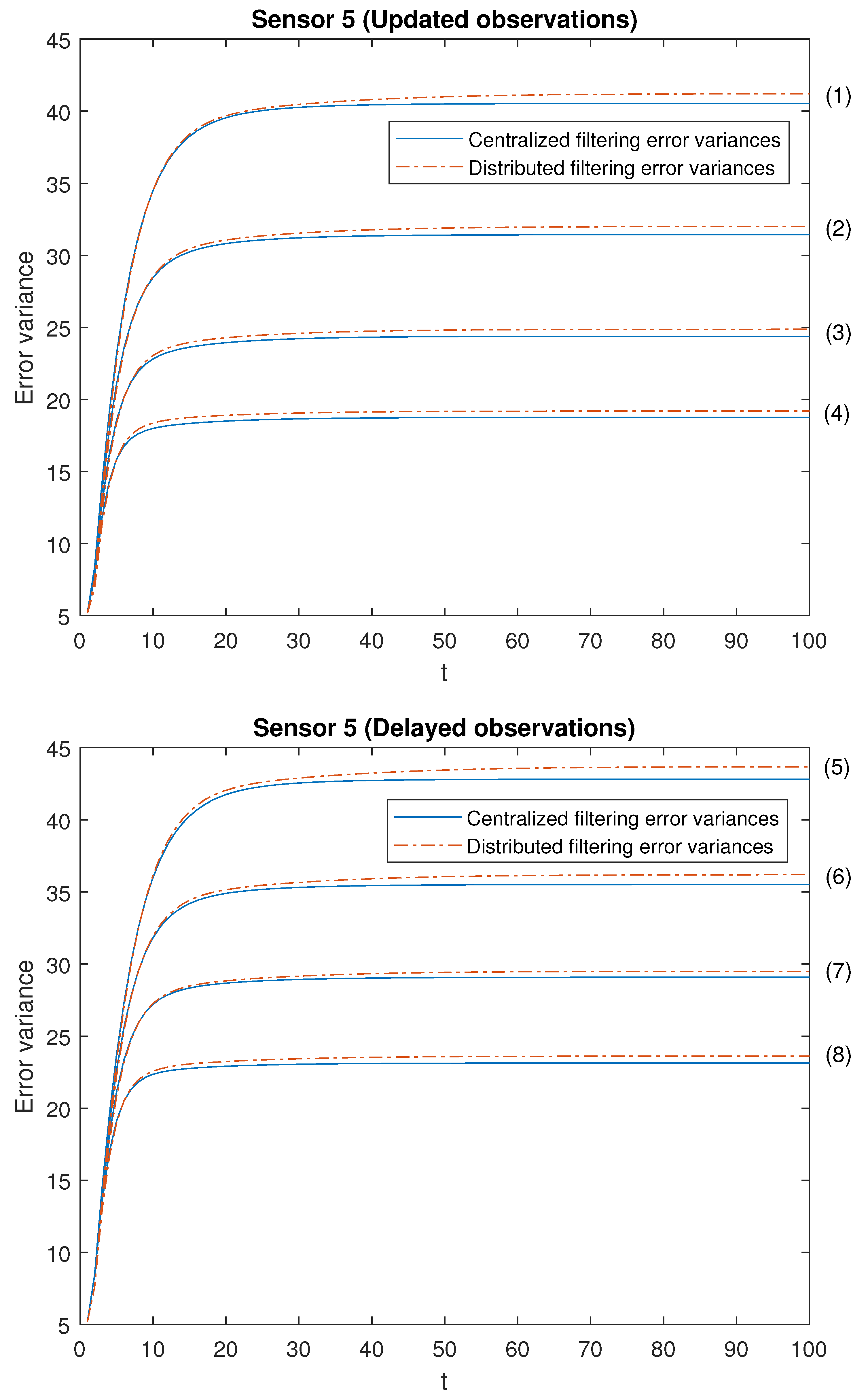
Note that the cases (1)–(4) in both scenarios allow us to contrast the performance of the filters by varying the probability that the observations are updated. Moreover, the cases (1)–(4) are sorted in ascending order of the update probabilities. We will start with case (1), in which there exists a low probability that the observations are updated (that is, they will most probably contain only noise), and this probability increases until case (4), in which it is more likely that the available observations are the updated ones. Analogous consideration about delayed observations in cases (5)–(8). Note that (5) is the most favorable case regarding uncertain observations and (8) is the most unfavorable case regarding uncertain observations. The error variances of both centralized and distributed fusion filters in all the situations described above for sensors 1, 2 and 5, are displayed in
Figure 2,
Figure 3 and
Figure 4, for the
-proper scenario, and in
Figure 5,
Figure 6 and
Figure 7, for the
-proper one. In view of these figures, by first comparing the cases (1)–(4), it can be observed that the error variances of both fusion estimators decrease and, hence, the accuracy of the filters is better, as the probability that the observations at each sensor are updated increases. This is also true for cases (5)–(8), with delayed observations. Secondly, we compare, in both scenarios, the cases in pairs (1)–(5), (2)–(6), (3)–(7), (4)–(8). Note that each of these pairs represents the situations of updated and delayed observations with the same probability. From these figures, it can be observed that the error variances of the fusion filters are smaller when the observations are updated than when they are delayed. Finally, in all the cases and in both scenarios, these figures show that the filtering error variances of the centralized fusion estimators are lower than that of the distributed fusion ones, but the difference between them is insignificant, and this is even more acceptable in practice if we analyze the computational advantages of the calculus of the estimators by means of the distributed fusion filtering algorithm.
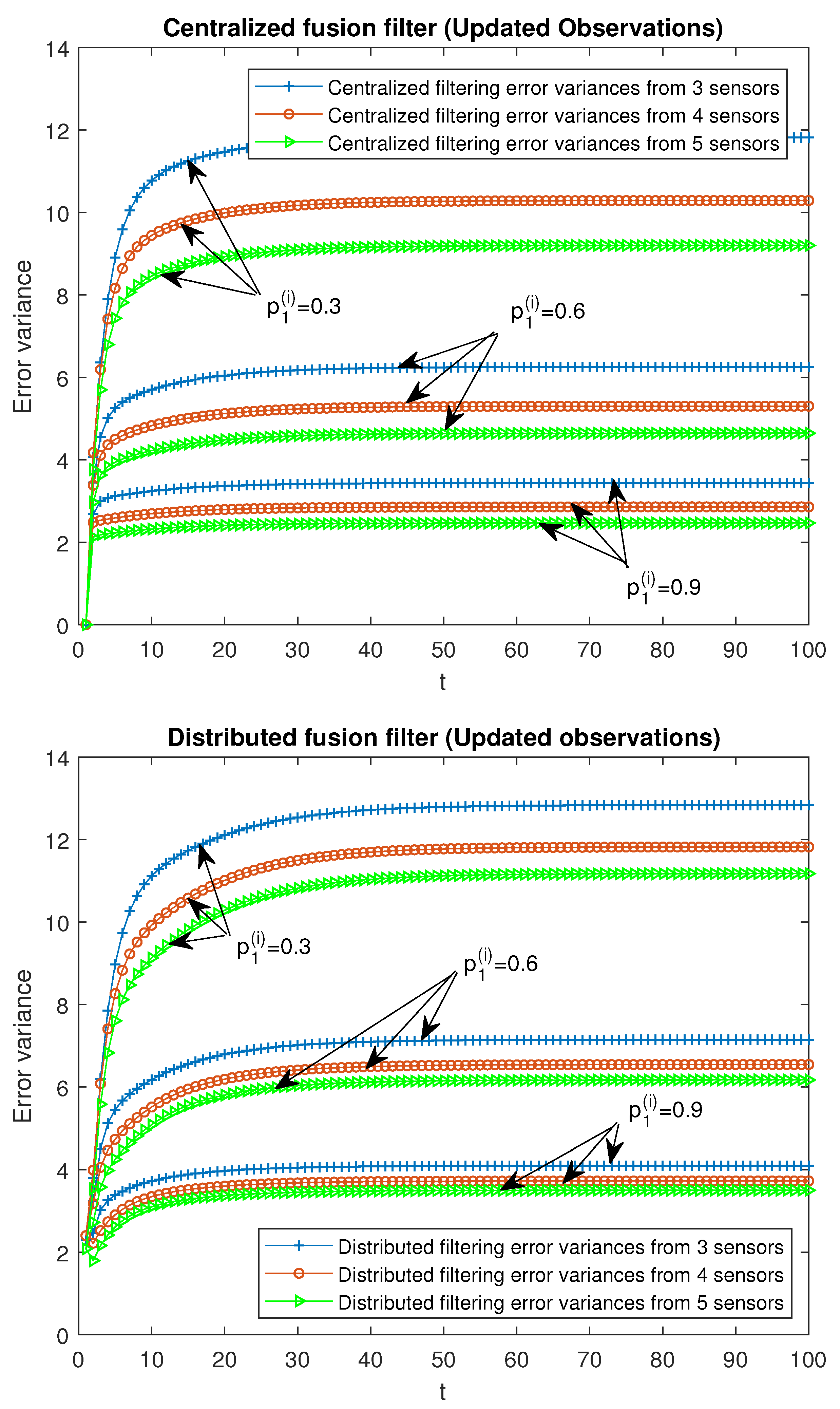
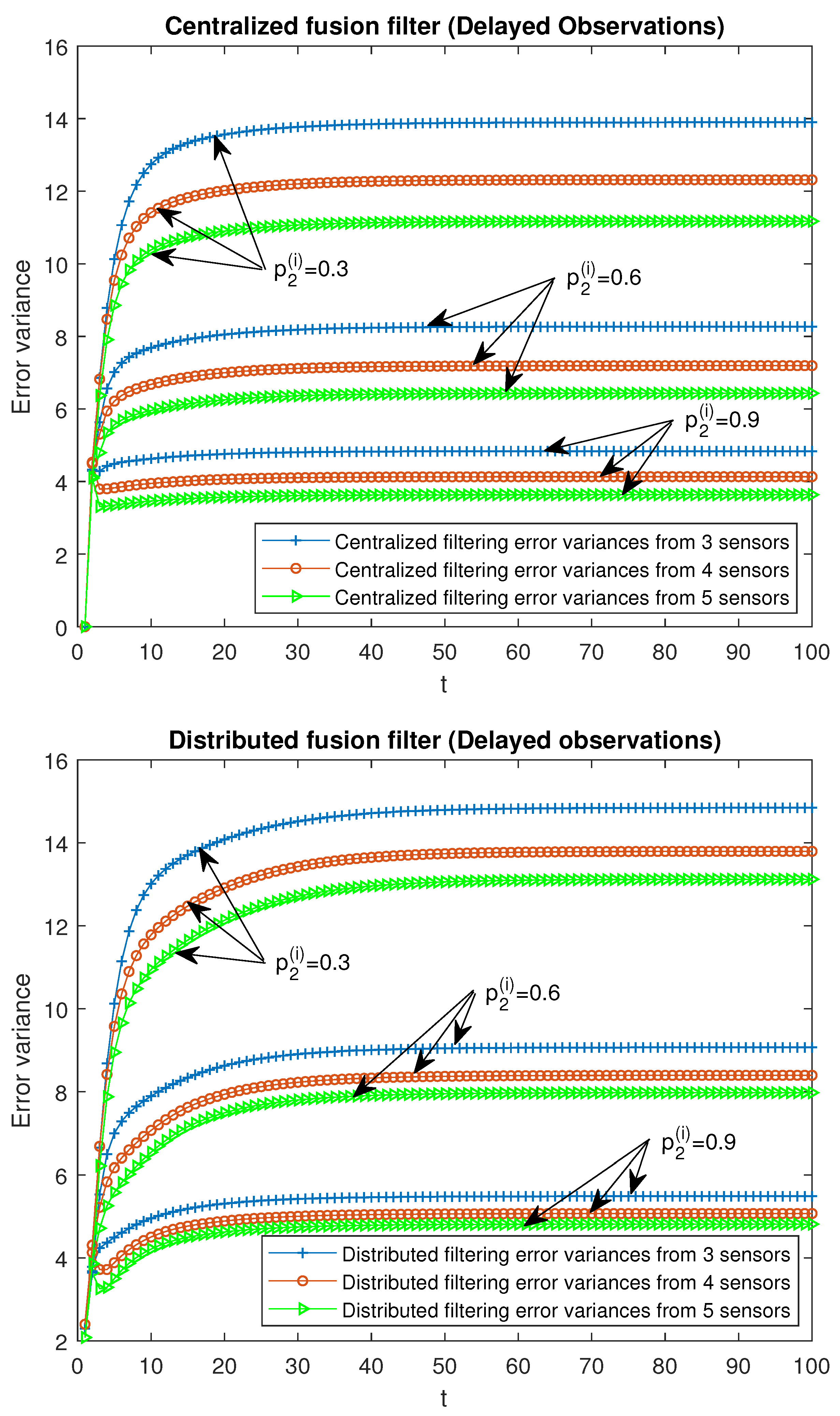
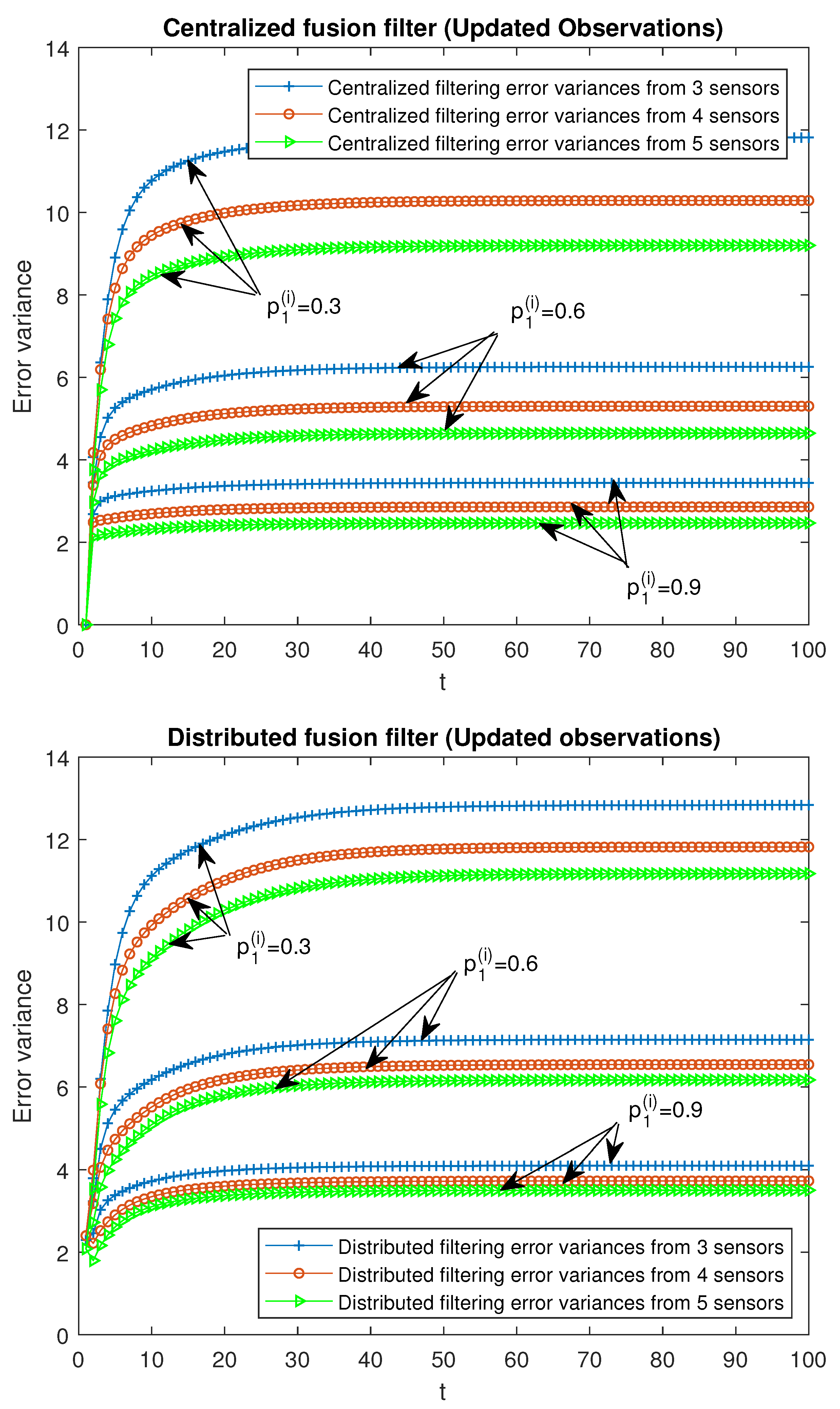
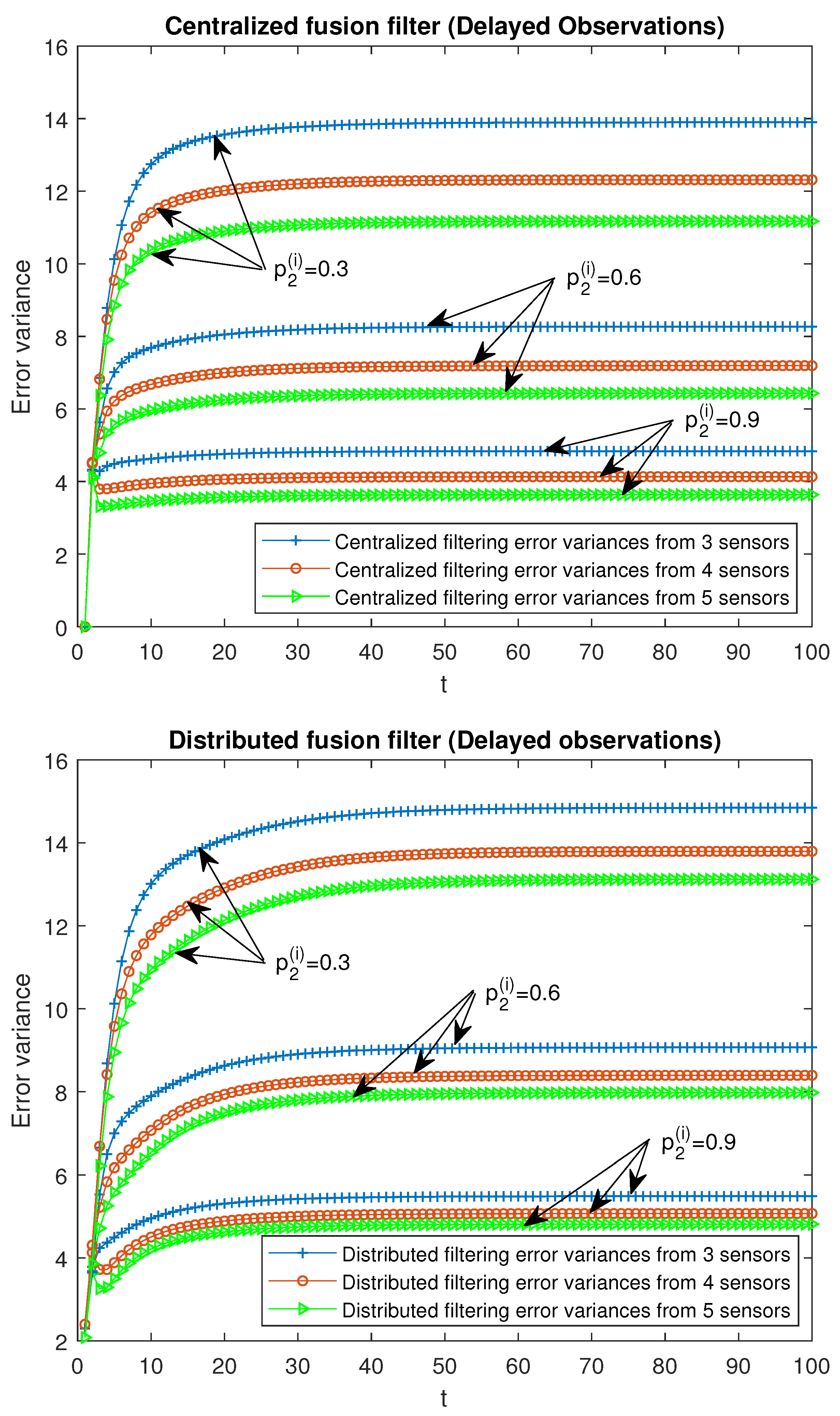
Finally, the performance of the proposed fusion filtering estimators is analyzed for different numbers of sensors, specifically, 3, 4 and 5 sensors in the
-proper scenario. It is considered that the observations from all the sensors are modeled by the same observation equation; that is, they have the same updating or delay probabilities, as well as the same variance and covariance of the noises. For the case of updated observations, three situations were analyzed:
for all
, and the remaining ones, 0.05; another analogous situations for delayed observations:
for all
, and the remaining ones, 0.05. In
Figure 8 and
Figure 9, the
-proper centralized and distributed fusion filtering error variances are displayed for the cases of updated and delayed observations, respectively. This was identitcal to that expressed in the above figures, but a better performance of both centralized and distributed filters was observed when the number of sensors increased.
8. Conclusions
In the last few decades, the scientific community has shown great interest in studying the signal estimation problem from multi-sensor observations, since better estimations are obtained with this method. The fact that there are several sensors reduces the number of possible failures in the communication channels as well as the adverse effects of some faulty sensors. Two methods have traditionally been used to build the fusion estimator from the observations of all the sensors: centralized and distributed methods. The first one has the advantage that it provides the optimal estimator whereas, with the distributed one, suboptimal estimators are obtained. However, the distributed method presents great advantages over the centralized one, such as flexibility, robustness, and a major reduction in the computational load (which is more significant with a large number of sensors), which make it preferable in practice, especially when considering the fact that in many real problems, the difference in performance between the estimators obtained by both methods may be almost insignificant.
The study of the signal estimation problem in hypercomplex domains has also considerably grown, since these domains allow for many real problems to be modeled in a better way. To date, most of the estimation problems have been addressed in the quaternion domain since it is a normed algebra. However, the tessarine signal processing can yield better estimators depending on the characteristics of the signal. Recently, it has been possible to endow the tessarine domain with a metric space structure that has the properties necessary to guarantee the existence and uniqueness of the orthogonal projection [
41] which is a way of obtaining the LS linear estimator. Therefore, the signal estimation problem was addressed in the tessarine domain in different scenarios, and properness conditions were defined that are analogous to those existing in the quaternion domain. This obtained a considerable reduction in the augmented system, and it led to a consequent decrease in computational cost.
In this paper, under
-properness conditions [
41,
42], the LS linear centralized and distributed fusion filtering problems of tessarine signals from multi-sensor observations have been studied, and recursive algorithms have been proposed to calculate them. The observations at each sensor and instant of time can be updated, delayed or contain only noise, independently from the other sensors. A correlation has also been assumed between the signal and observation noises. The
-properness conditions cause an important computational reduction in the calculus of the
-proper fusion filters in comparison with the TWL estimators, which makes these conditions desirable in practice. The theoretical results are illustrated in a numerical simulation example, in which the performance of the estimators calculated by using both fusion algorithms is compared by taking different values of the Bernoulli parameters modeling the updating, delay, or uncertainty in the observations.
Future research is planned to explore the signal estimation problem in other hypercomplex algebras, as well as to address the decentralized fusion estimation problem under -properness scenarios and different hypotheses on the observations.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}