
A Bayesian-Deep Learning Model for Estimating COVID-19 Evolution in Spain


Abstract
:1. Introduction
2. Model
2.1. Long Short Term Memory (LSTM)
2.2. Poisson-Gamma Model
3. COVID-19 Modelling
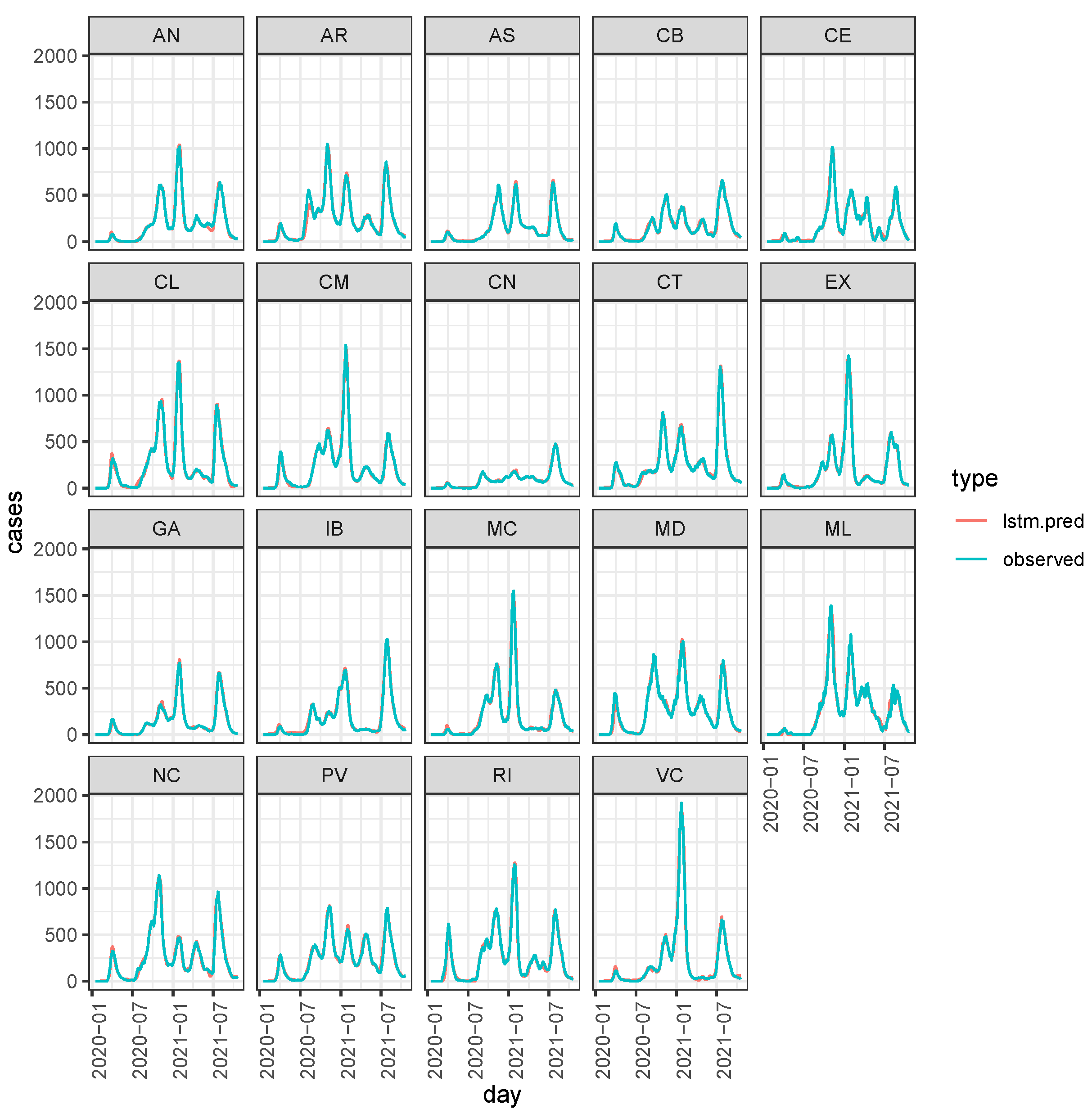
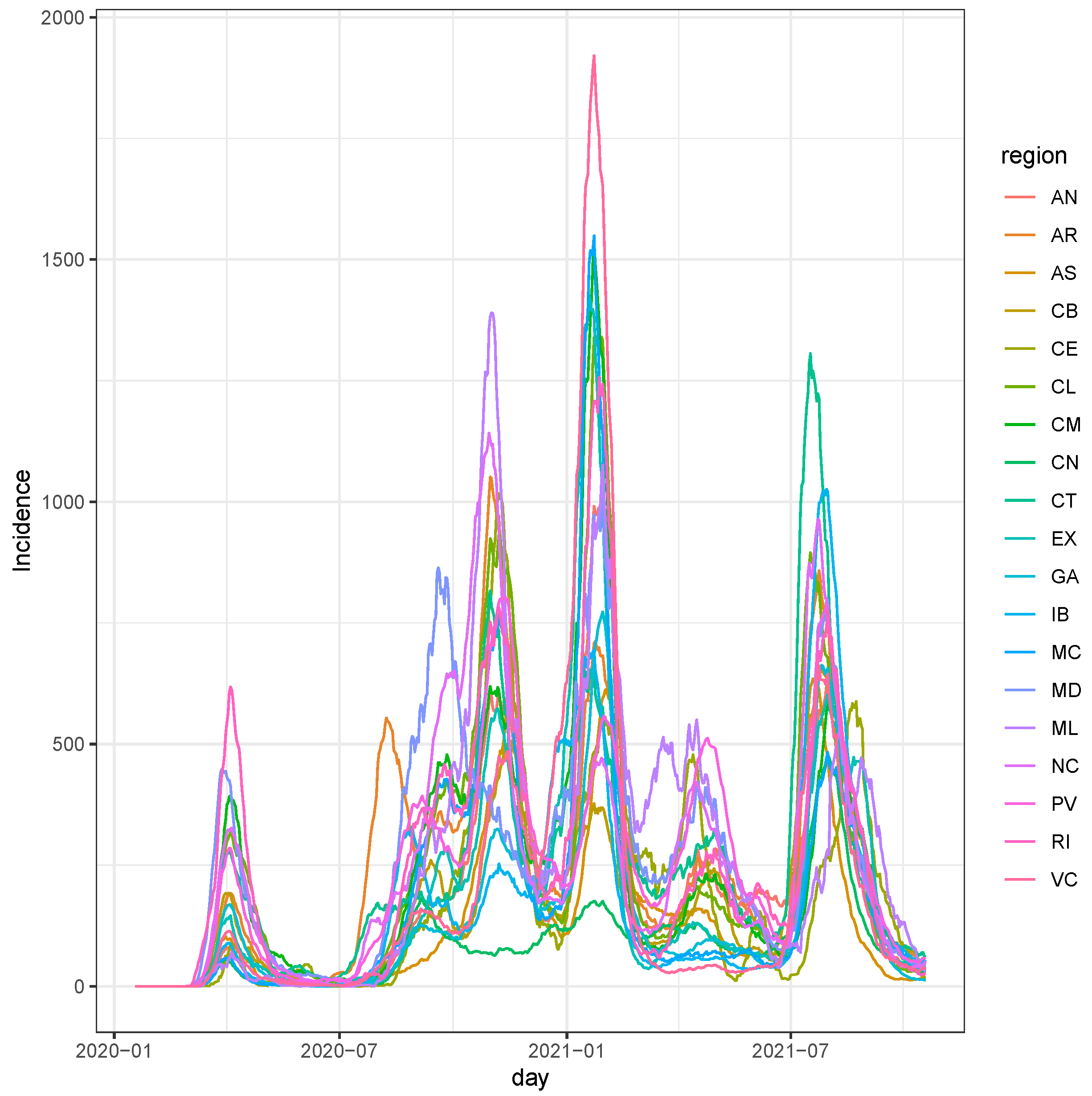
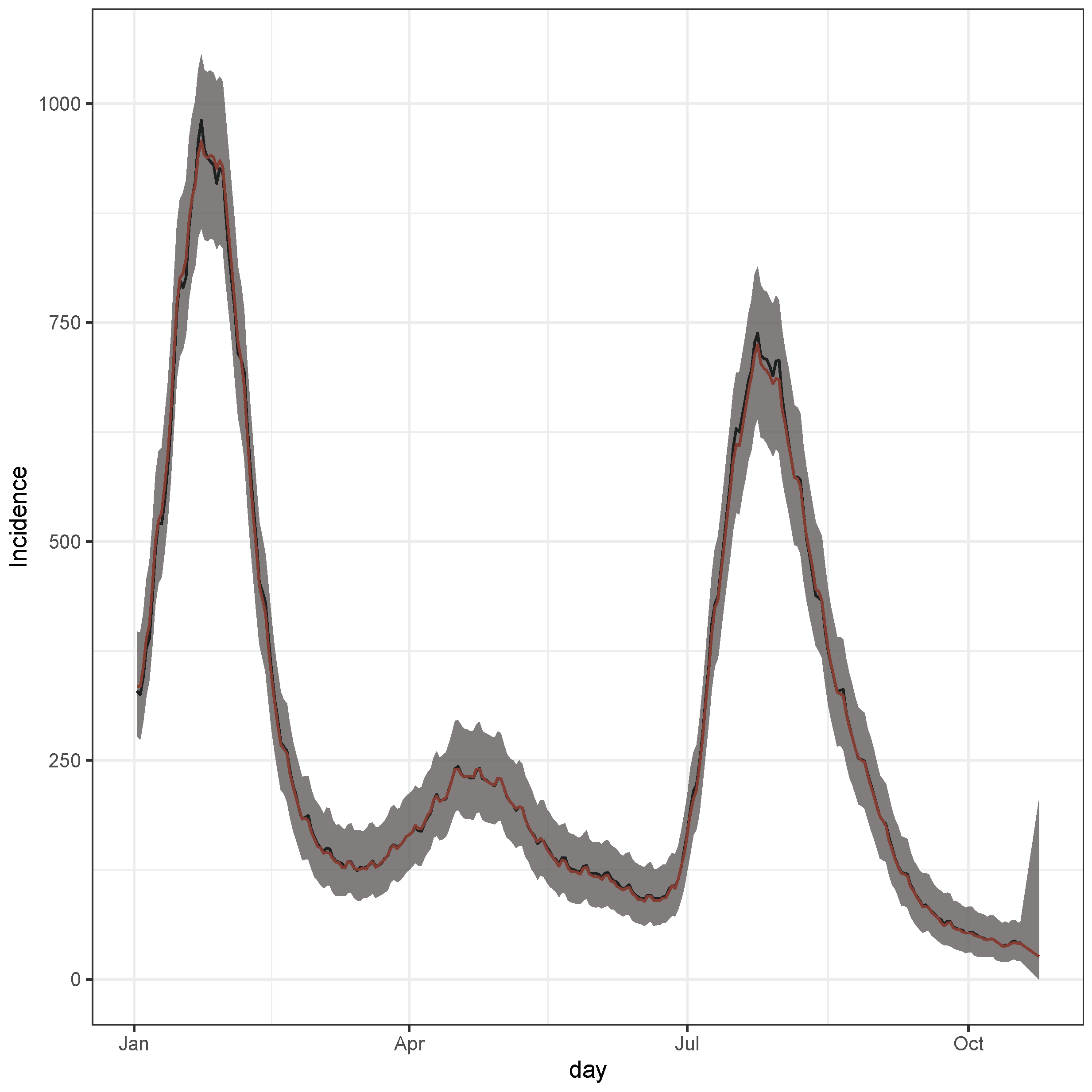
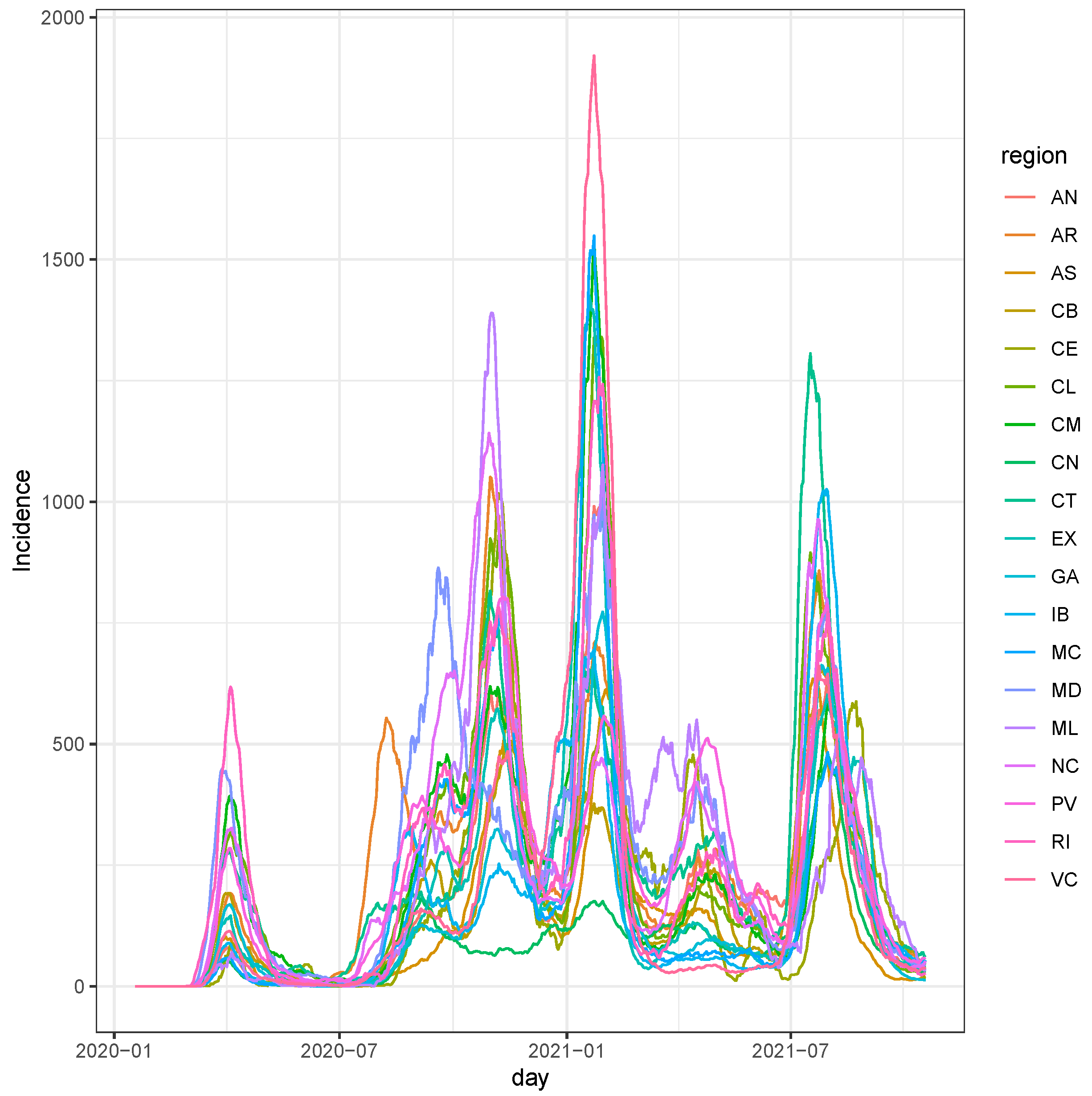
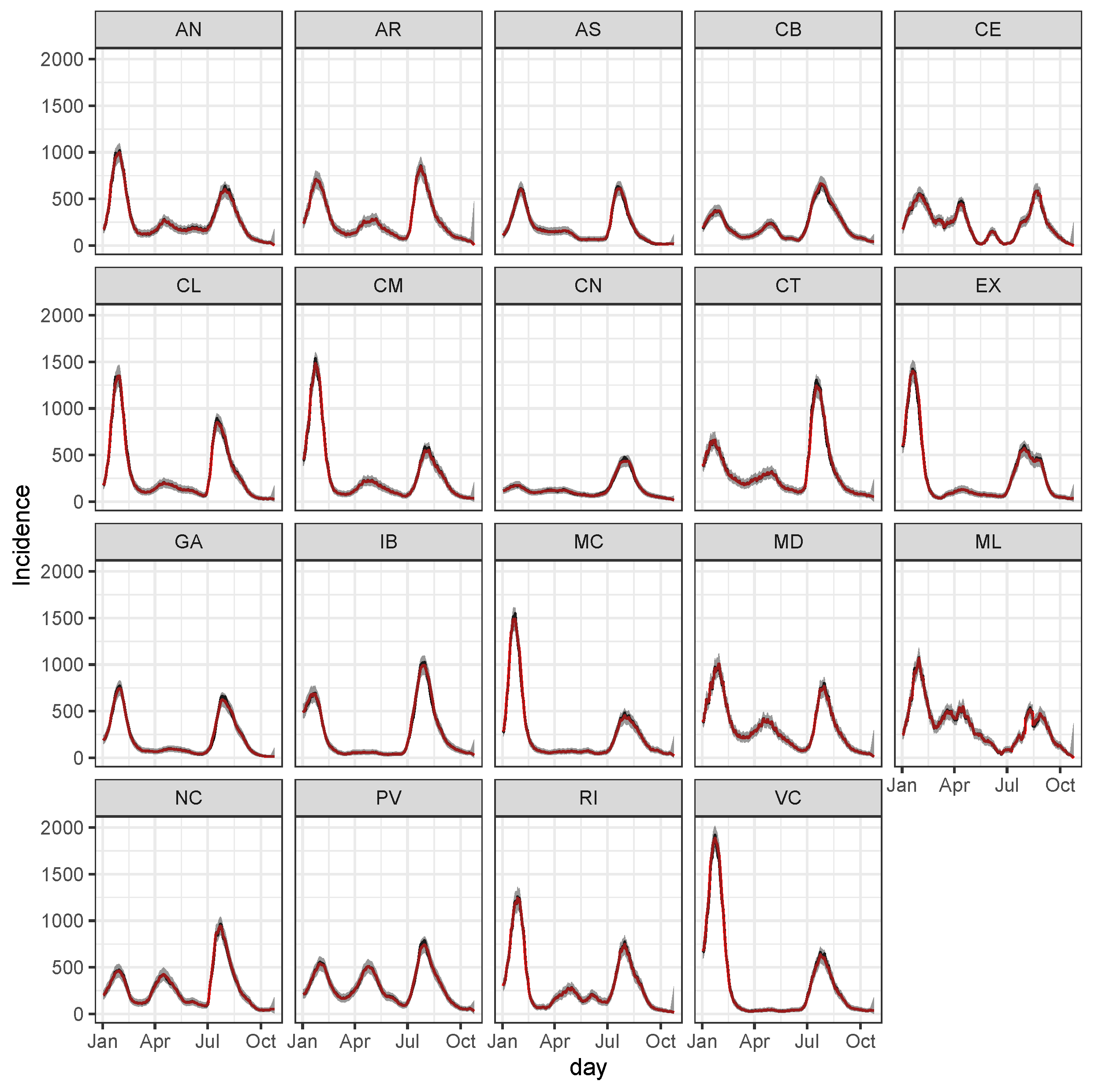
3.1. Data
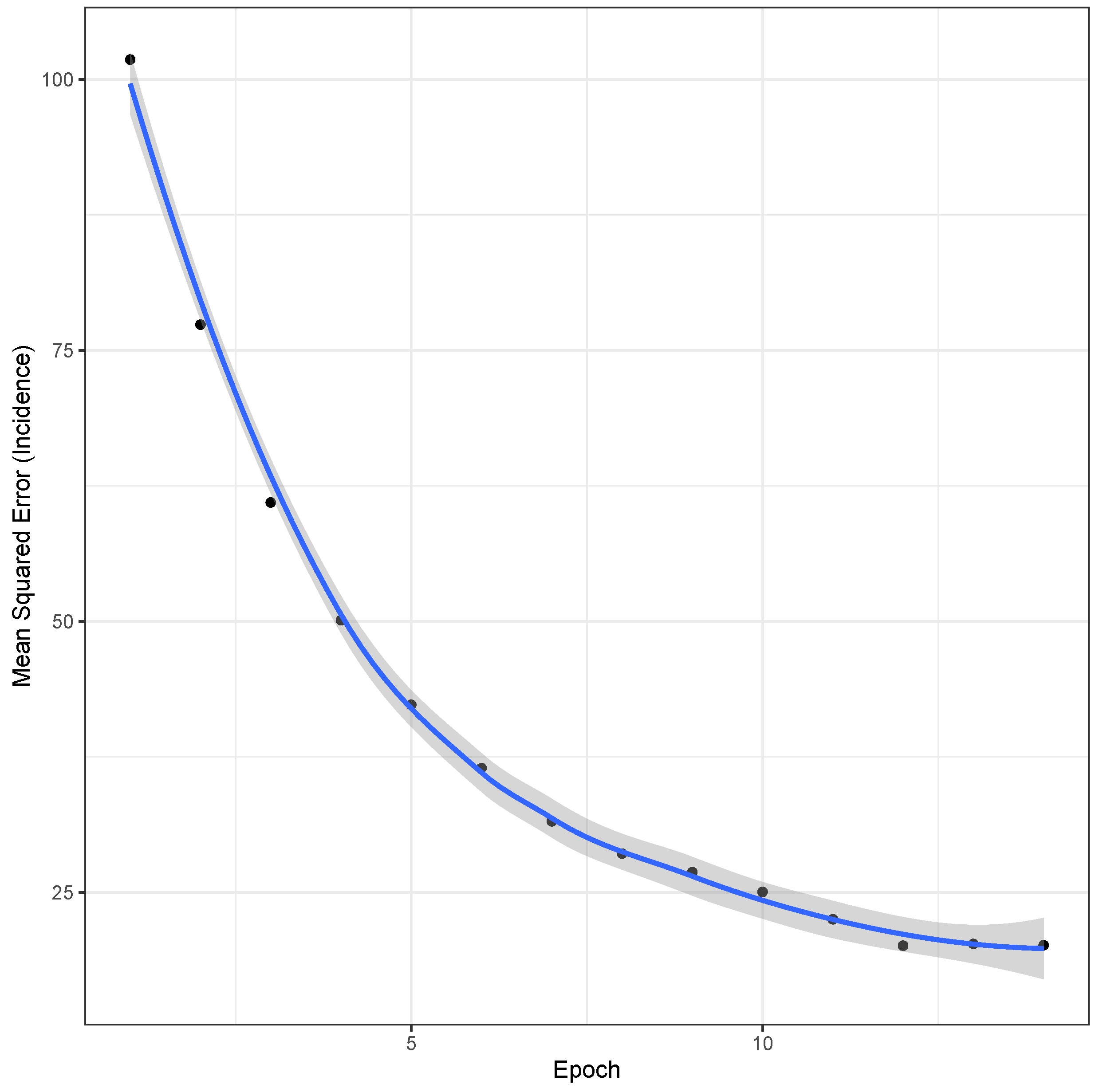
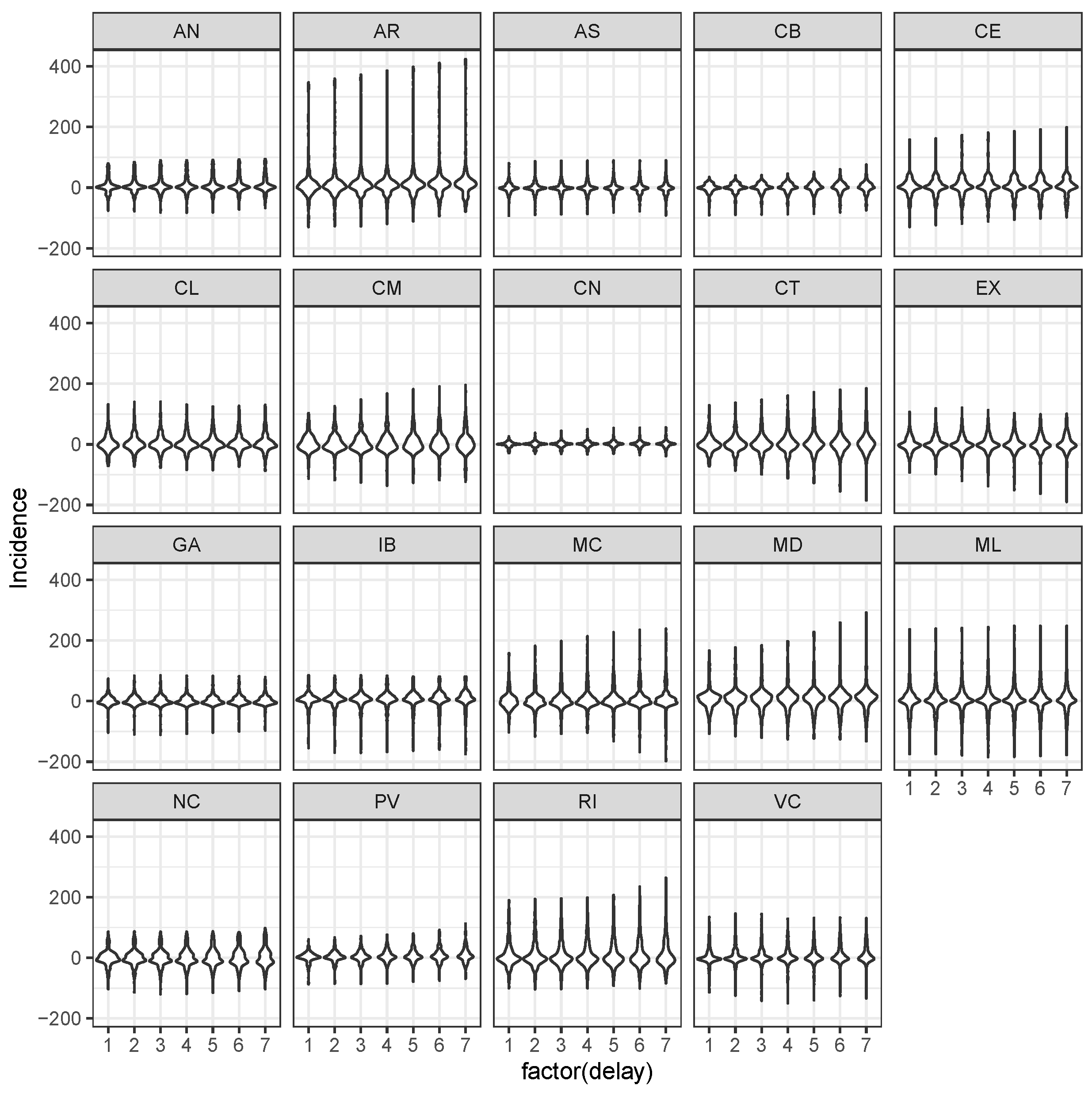
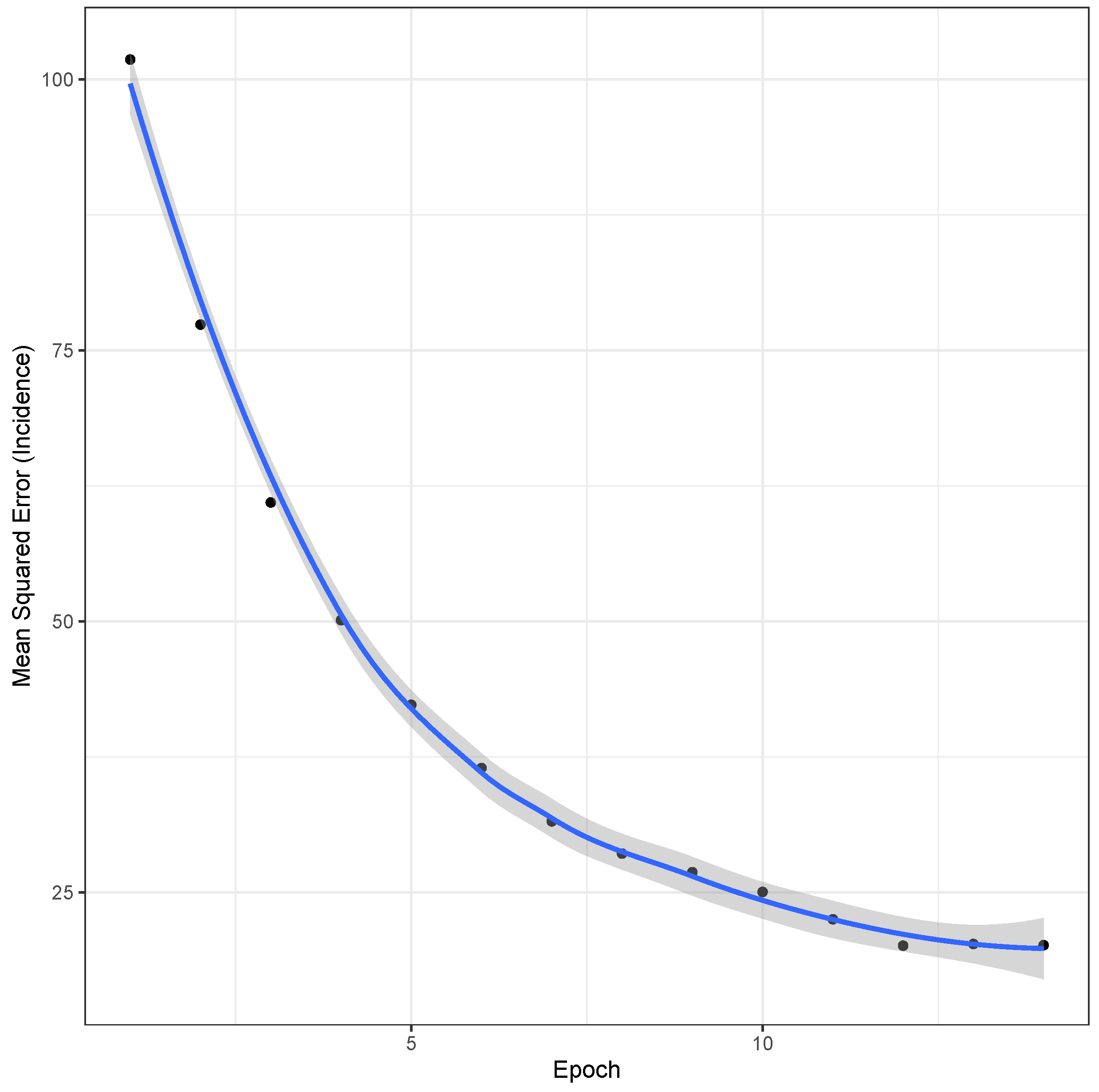
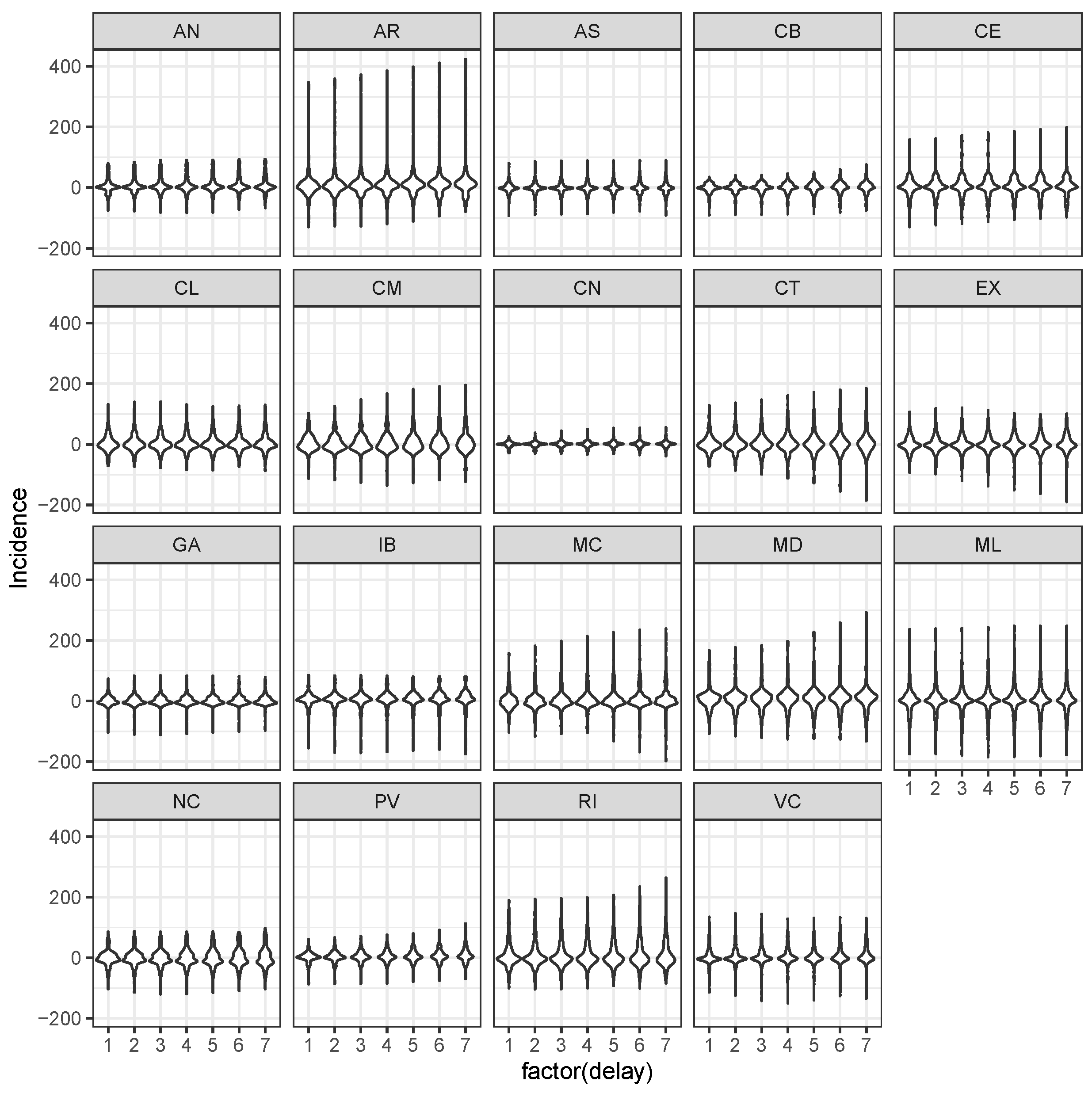
3.2. LSTM Interpolation
- sequence evolution, that is, for all ;
- between-sequence evolution that is for all , .
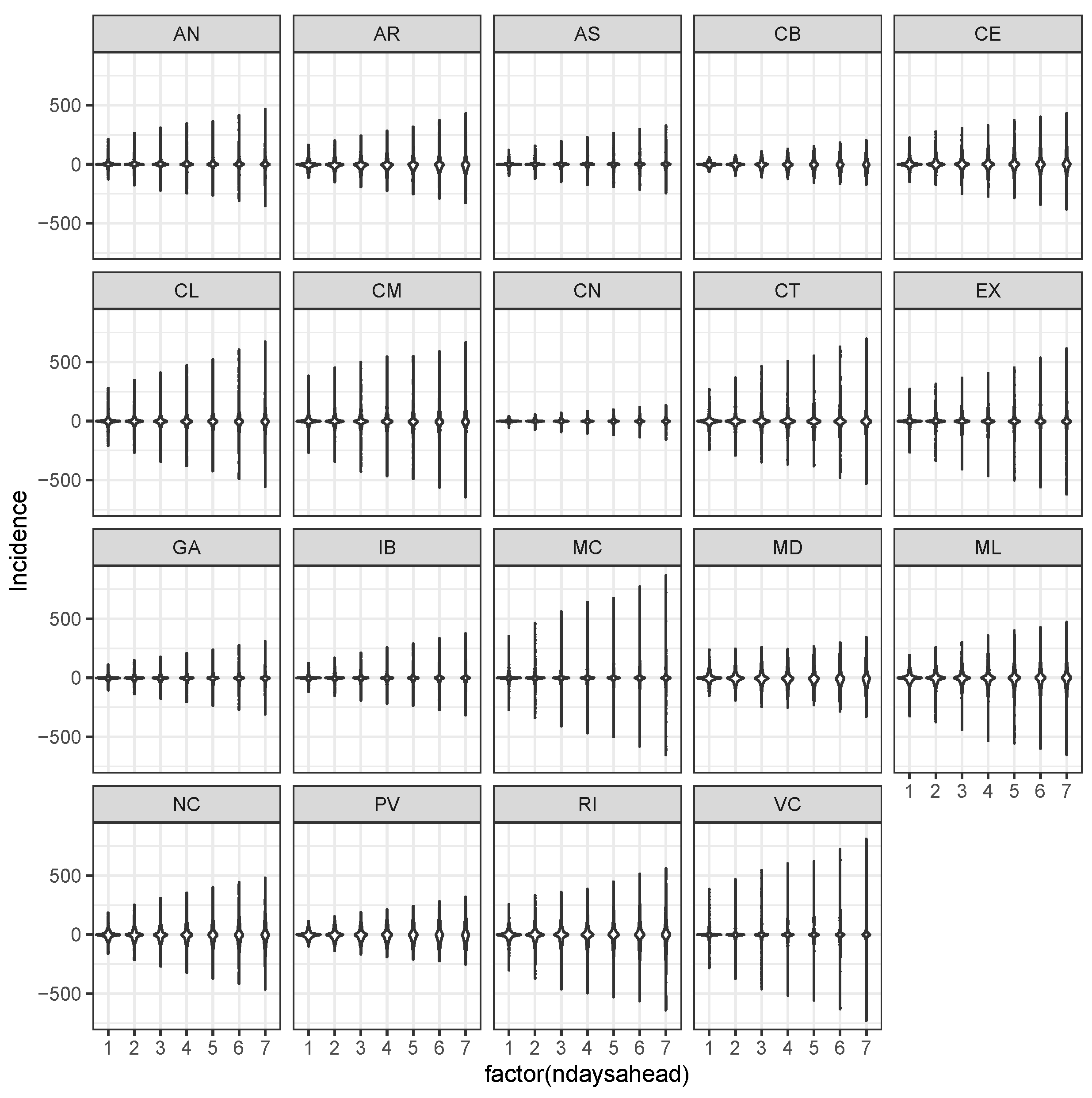
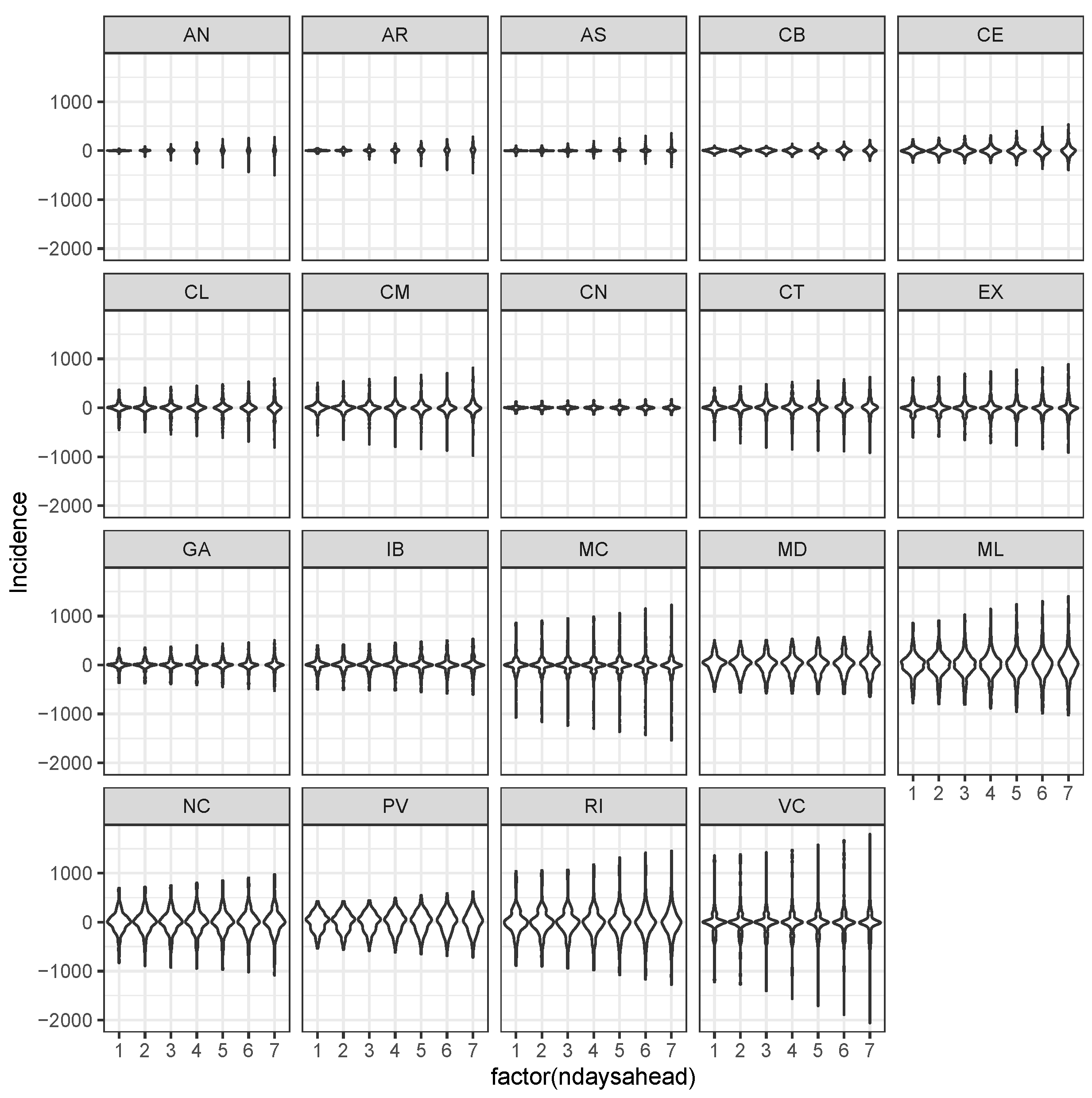
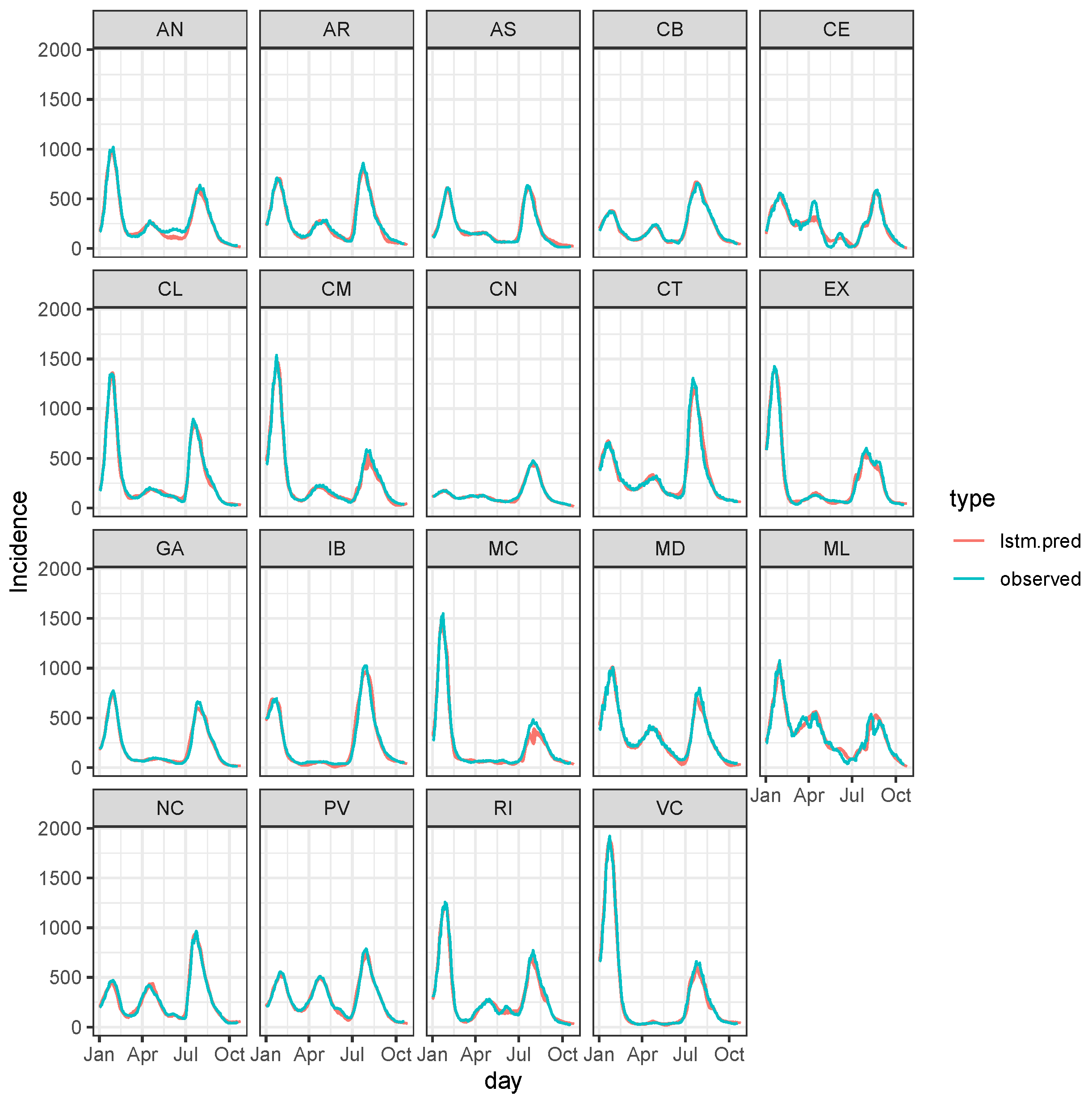
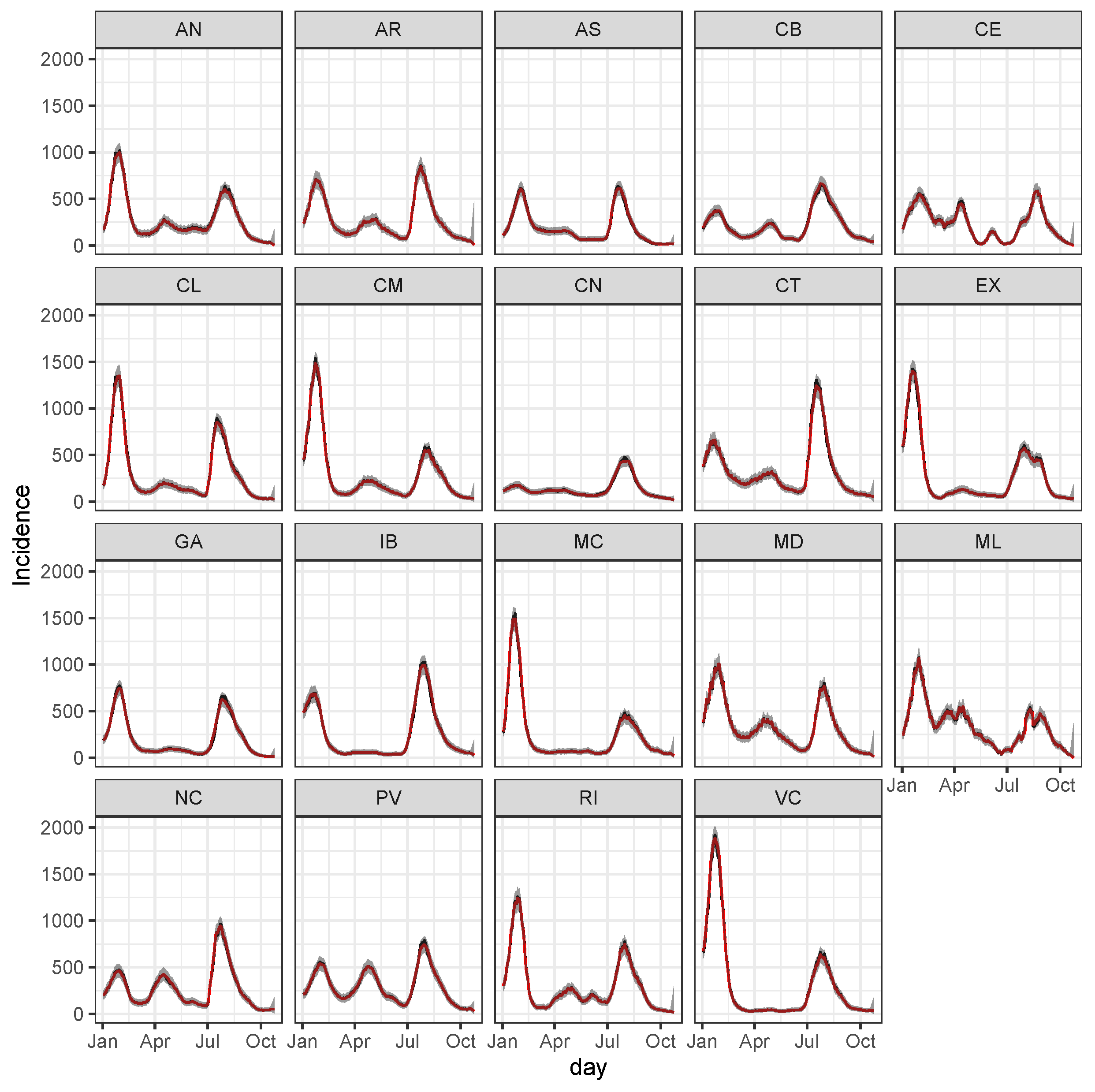
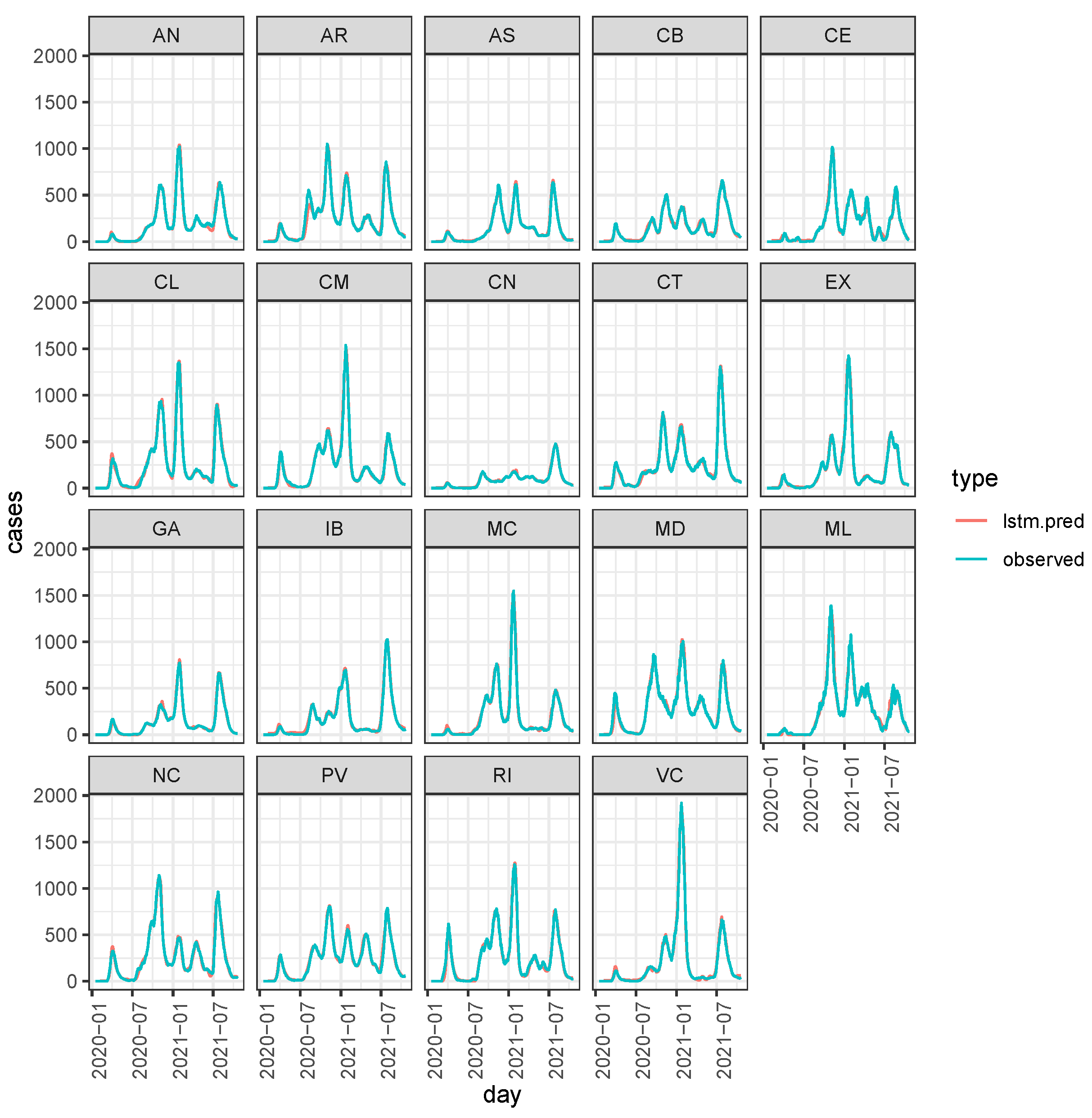
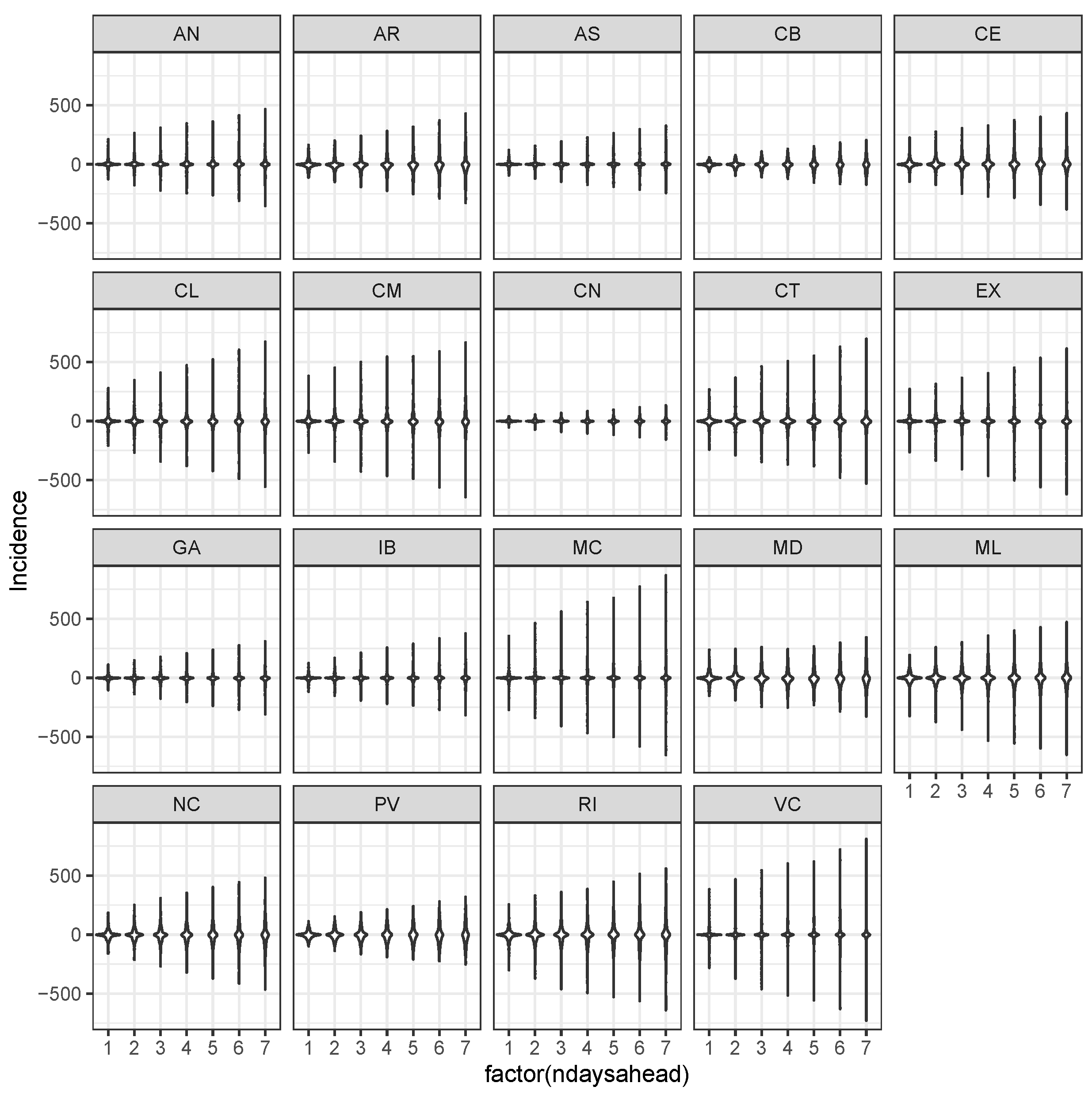
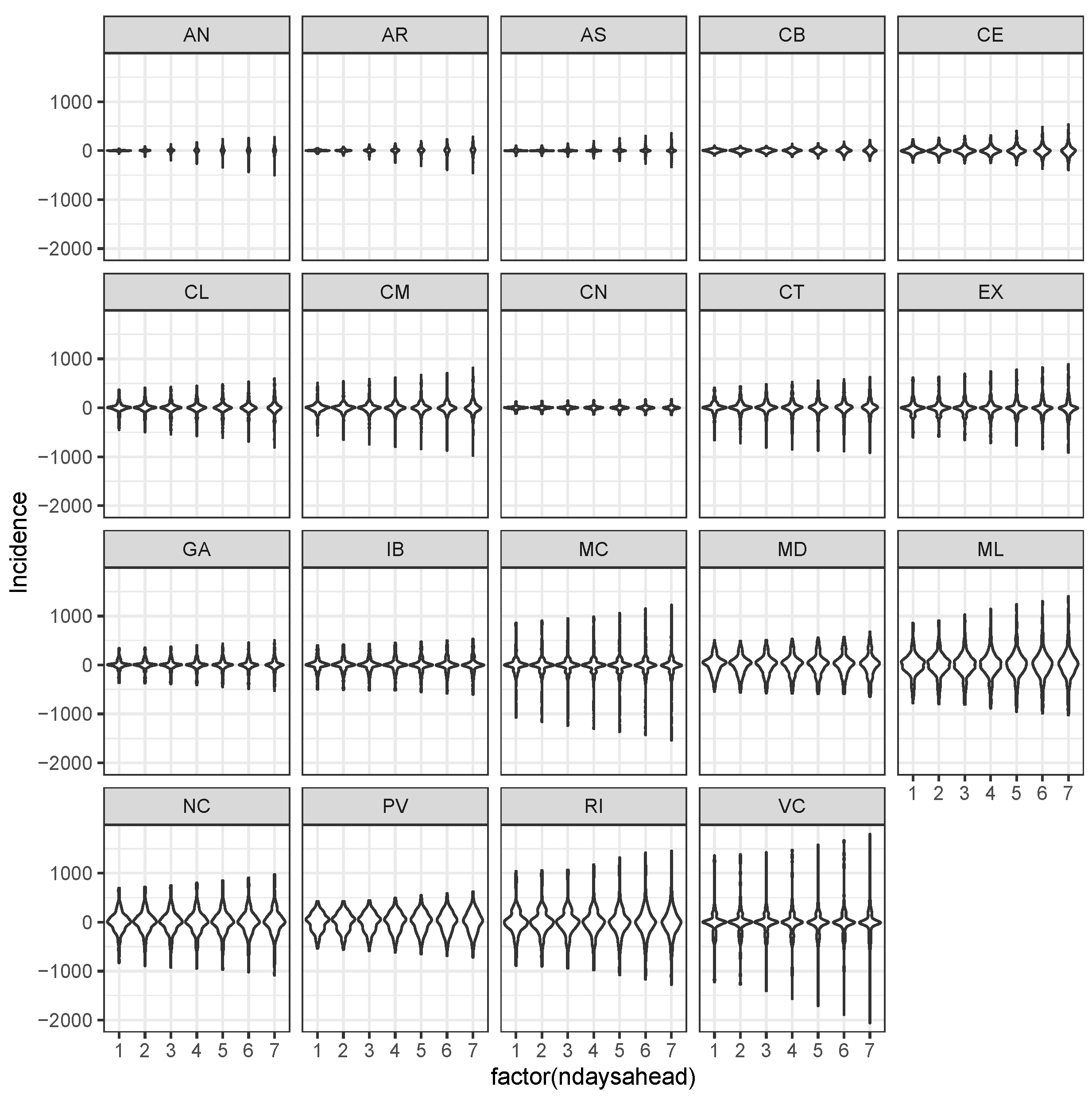
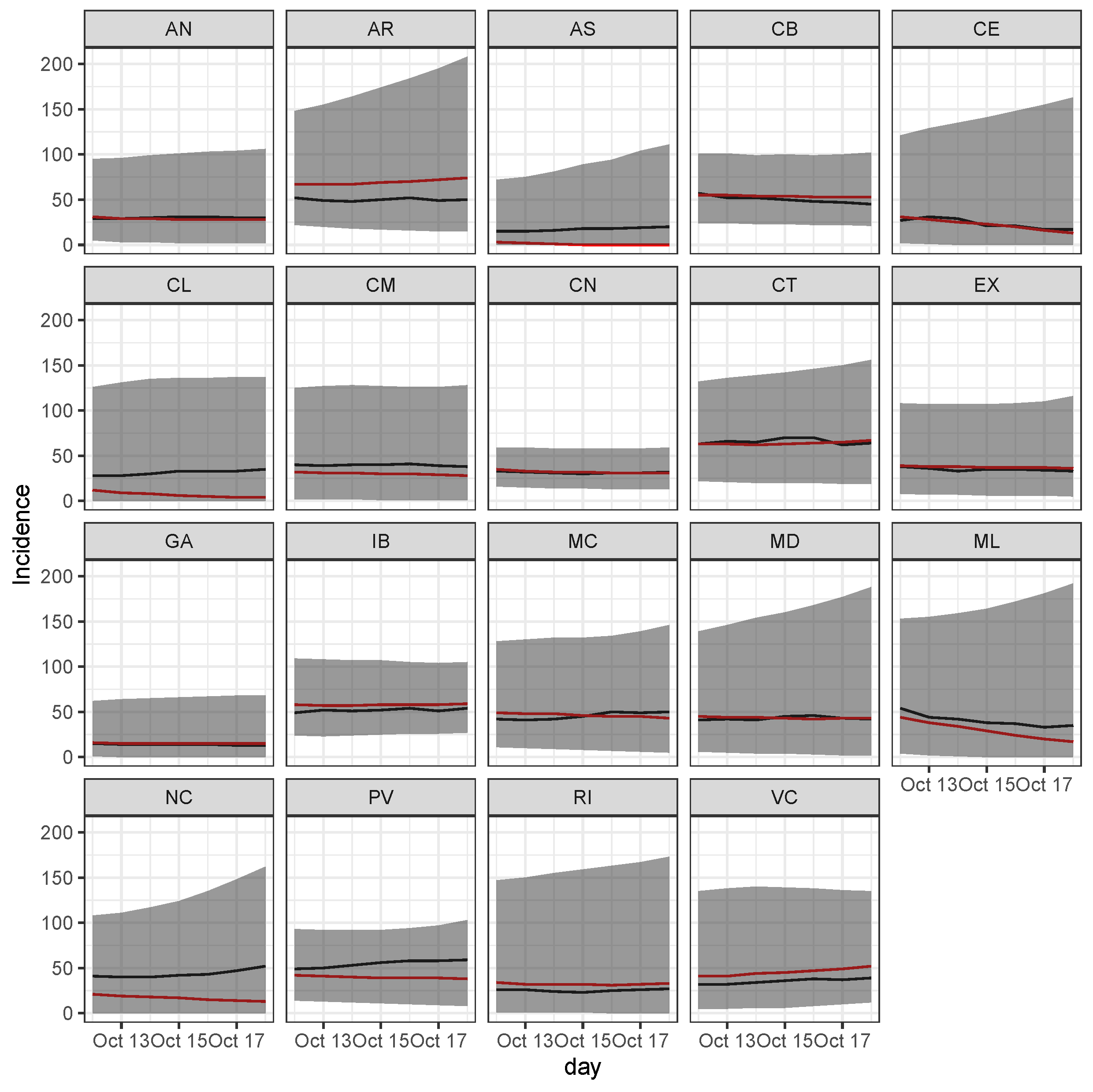
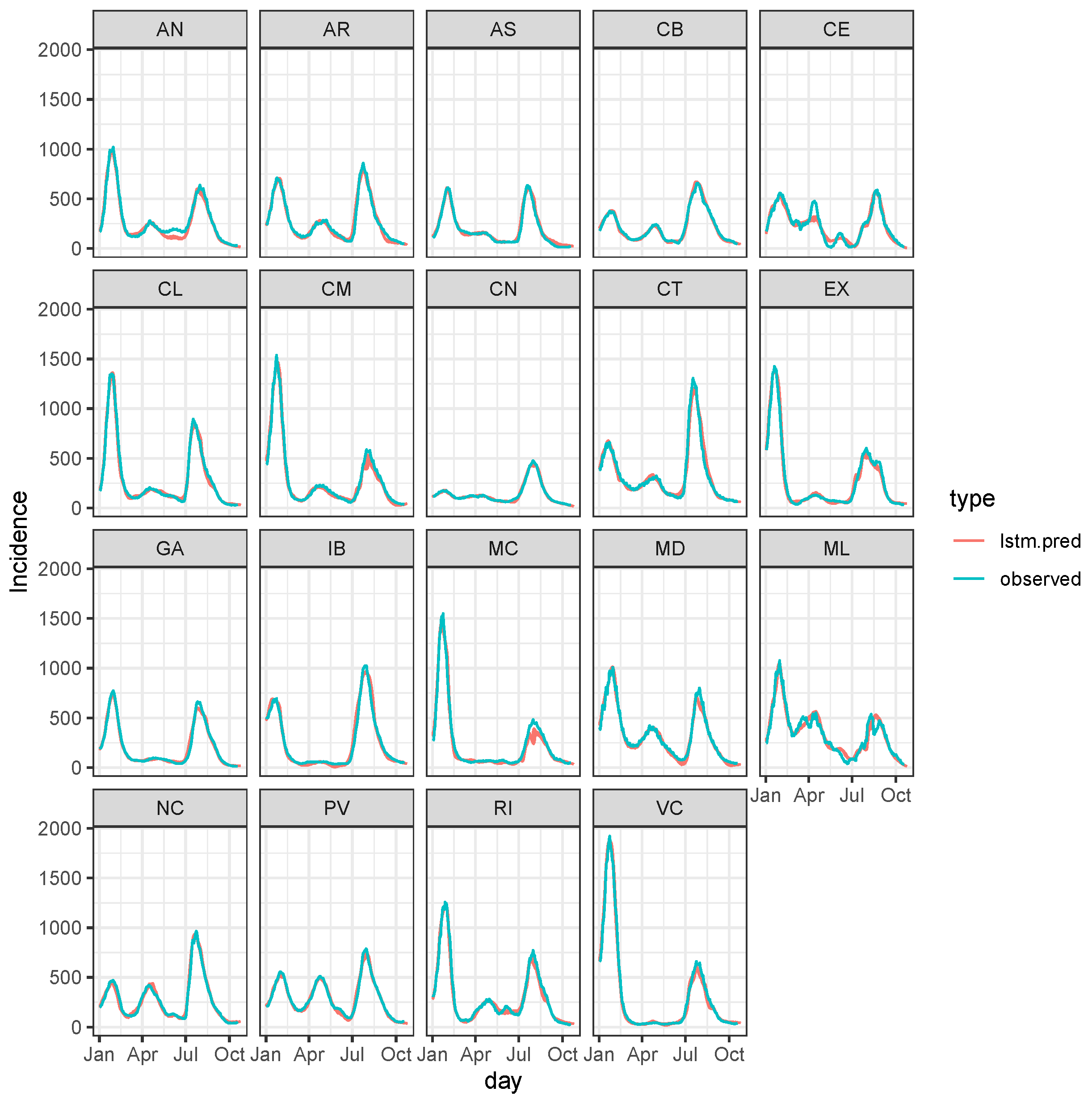
3.3. Bayesian Predictive Analysis and Goodness of Fit Assessment
3.4. Impact Scenarios
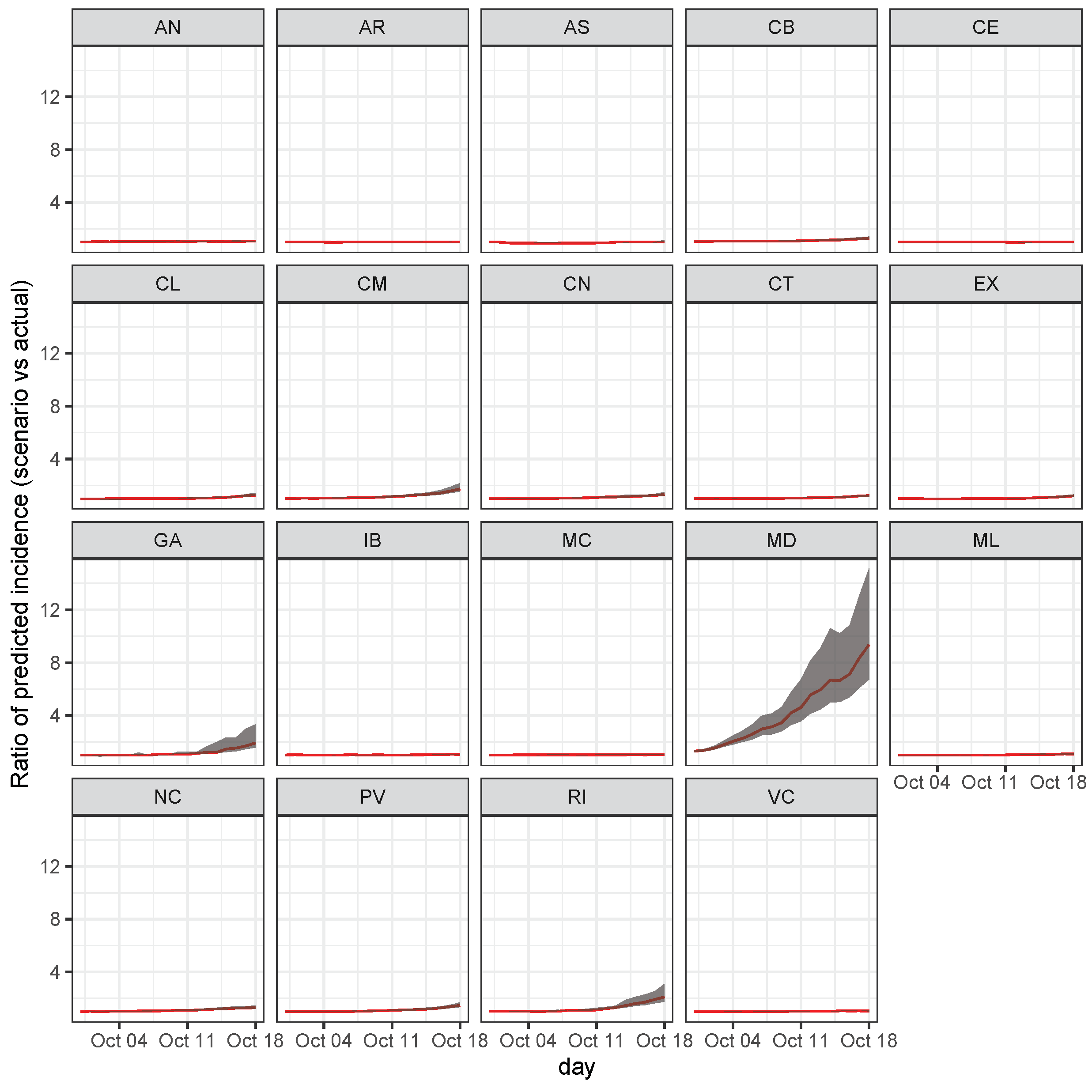
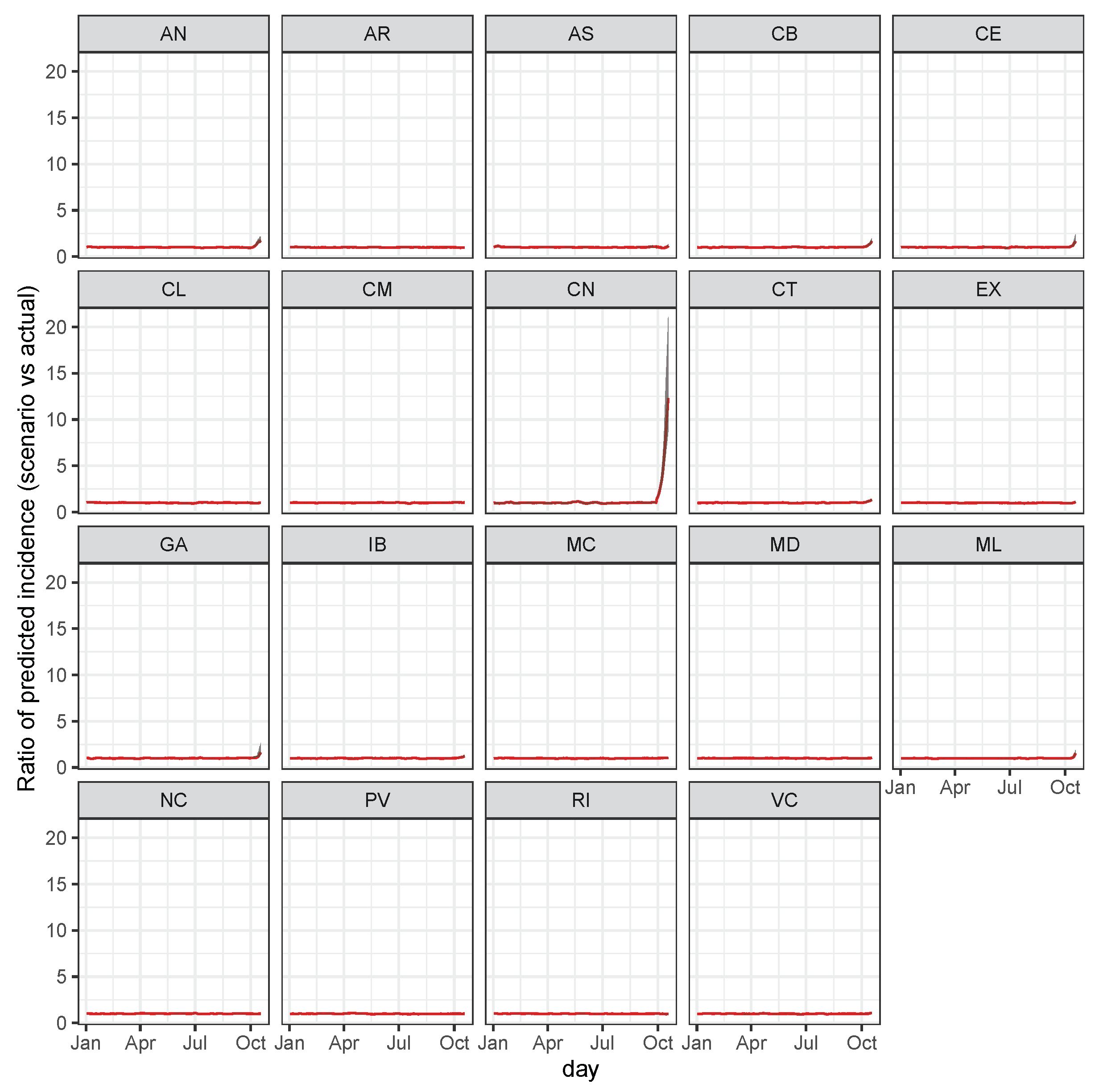
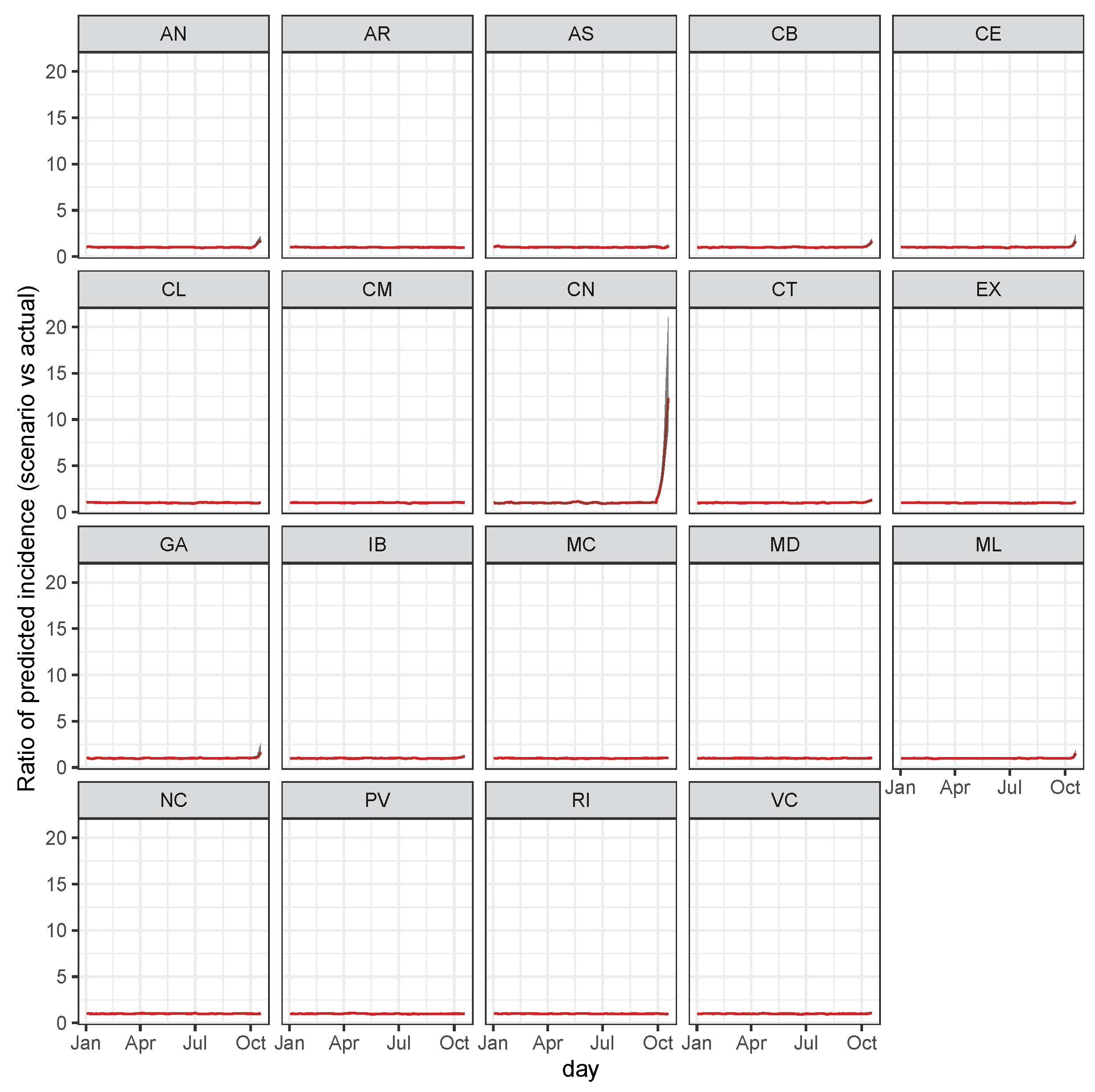
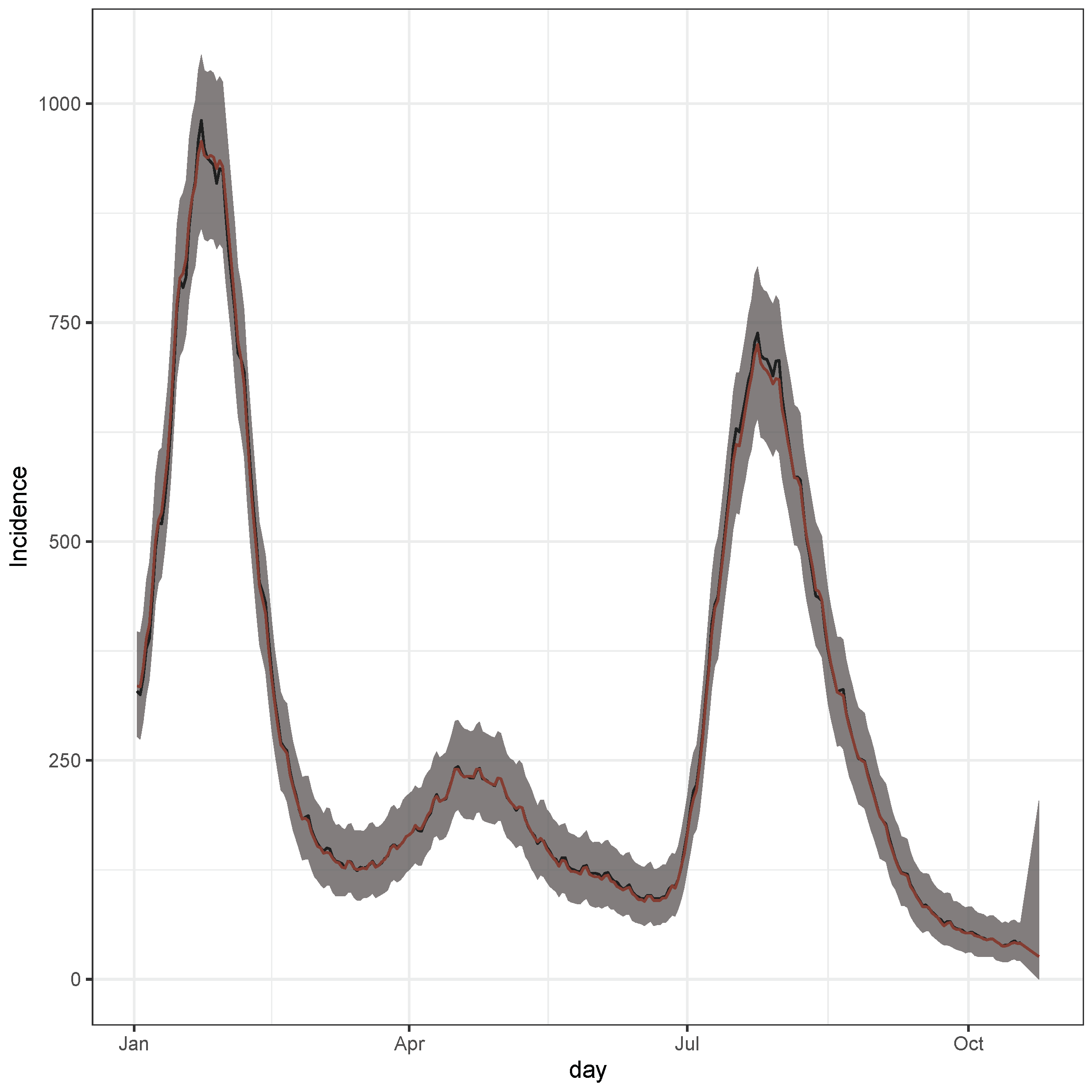
3.4.1. Scenario 1: The Case of Increase in Madrid
3.4.2. Scenario 2: Cases Increase in the Canary Islands
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Days Ahead Predictions | ||||||||
|---|---|---|---|---|---|---|---|---|
| Region | Variable | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| AN | inf (0.5%) | 6 | 5 | 4 | 4 | 4 | 3 | 2 |
| AN | obs. | 29 | 29 | 30 | 31 | 31 | 30 | 30 |
| AN | pred (50%) | 41 | 40 | 40 | 41 | 41 | 40 | 39 |
| AN | sup (99.5%) | 128 | 132 | 137 | 142 | 147 | 153 | 162 |
| AR | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AR | obs. | 52 | 49 | 48 | 50 | 52 | 49 | 50 |
| AR | pred (50%) | 41 | 38 | 37 | 36 | 35 | 34 | 34 |
| AR | sup (99.5%) | 385 | 394 | 404 | 415 | 426 | 438 | 449 |
| AS | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AS | obs. | 15 | 15 | 16 | 18 | 18 | 19 | 20 |
| AS | pred (50%) | 2 | 3 | 4 | 4 | 4 | 5 | 4 |
| AS | sup (99.5%) | 195 | 197 | 204 | 213 | 222 | 230 | 240 |
| CB | inf (0.5%) | 11 | 9 | 7 | 5 | 4 | 3 | 2 |
| CB | obs. | 57 | 52 | 52 | 50 | 48 | 47 | 45 |
| CB | pred (50%) | 43 | 41 | 41 | 39 | 39 | 38 | 37 |
| CB | sup (99.5%) | 104 | 110 | 117 | 124 | 132 | 140 | 150 |
| CE | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CE | obs. | 27 | 31 | 29 | 21 | 21 | 17 | 17 |
| CE | pred (50%) | 30 | 25 | 23 | 22 | 20 | 18 | 16 |
| CE | sup (99.5%) | 192 | 200 | 207 | 215 | 222 | 230 | 239 |
| CL | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CL | obs. | 28 | 28 | 30 | 33 | 33 | 33 | 35 |
| CL | pred (50%) | 31 | 27 | 26 | 26 | 25 | 24 | 24 |
| CL | sup (99.5%) | 181 | 199 | 215 | 234 | 255 | 280 | 307 |
| CM | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| CM | obs. | 40 | 39 | 40 | 40 | 41 | 39 | 38 |
| CM | pred (50%) | 31 | 26 | 23 | 22 | 20 | 18 | 17 |
| CM | sup (99.5%) | 231 | 266 | 298 | 328 | 359 | 393 | 430 |
| CN | inf (0.5%) | 9 | 8 | 8 | 8 | 7 | 7 | 7 |
| CN | obs. | 33 | 32 | 31 | 30 | 31 | 31 | 32 |
| CN | pred (50%) | 35 | 34 | 34 | 34 | 33 | 33 | 33 |
| CN | sup (99.5%) | 84 | 84 | 84 | 85 | 85 | 86 | 88 |
| CT | inf (0.5%) | 9 | 8 | 7 | 6 | 5 | 4 | 4 |
| CT | obs. | 63 | 66 | 65 | 70 | 70 | 62 | 64 |
| CT | pred (50%) | 79 | 78 | 78 | 78 | 78 | 78 | 77 |
| CT | sup (99.5%) | 269 | 280 | 294 | 308 | 323 | 338 | 354 |
| EX | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| EX | obs. | 38 | 36 | 33 | 35 | 35 | 34 | 33 |
| EX | pred (50%) | 31 | 28 | 26 | 22 | 19 | 17 | 15 |
| EX | sup (99.5%) | 223 | 258 | 298 | 337 | 377 | 416 | 454 |
| GA | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| GA | obs. | 15 | 14 | 14 | 14 | 14 | 13 | 13 |
| GA | pred (50%) | 13 | 12 | 13 | 14 | 13 | 13 | 12 |
| GA | sup (99.5%) | 101 | 101 | 105 | 110 | 117 | 125 | 136 |
| IB | inf (0.5%) | 6 | 6 | 5 | 5 | 4 | 3 | 3 |
| IB | obs. | 49 | 52 | 51 | 52 | 54 | 51 | 54 |
| IB | pred (50%) | 54 | 56 | 56 | 57 | 58 | 58 | 59 |
| IB | sup (99.5%) | 192 | 199 | 207 | 217 | 230 | 244 | 259 |
| MC | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| MC | obs. | 42 | 41 | 42 | 45 | 50 | 49 | 50 |
| MC | pred (50%) | 15 | 9 | 7 | 4 | 2 | 1 | 0 |
| MC | sup (99.5%) | 324 | 379 | 423 | 473 | 527 | 581 | 638 |
| MD | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| MD | obs. | 41 | 42 | 41 | 45 | 46 | 43 | 42 |
| MD | pred (50%) | 23 | 22 | 24 | 25 | 25 | 26 | 26 |
| MD | sup (99.5%) | 186 | 206 | 225 | 243 | 262 | 282 | 303 |
| ML | inf (0.5%) | 5 | 3 | 2 | 1 | 0 | 0 | 0 |
| ML | obs. | 54 | 44 | 42 | 38 | 37 | 33 | 35 |
| ML | pred (50%) | 57 | 51 | 47 | 43 | 40 | 37 | 33 |
| ML | sup (99.5%) | 211 | 214 | 218 | 224 | 232 | 242 | 255 |
| NC | inf (0.5%) | 3 | 2 | 2 | 1 | 1 | 1 | 0 |
| NC | obs. | 41 | 40 | 40 | 42 | 43 | 47 | 52 |
| NC | pred (50%) | 36 | 35 | 37 | 37 | 38 | 37 | 38 |
| NC | sup (99.5%) | 138 | 144 | 155 | 167 | 182 | 200 | 219 |
| PV | inf (0.5%) | 1 | 2 | 2 | 2 | 2 | 2 | 2 |
| PV | obs. | 49 | 50 | 53 | 56 | 58 | 58 | 59 |
| PV | pred (50%) | 49 | 50 | 50 | 52 | 53 | 52 | 53 |
| PV | sup (99.5%) | 252 | 239 | 236 | 236 | 238 | 242 | 247 |
| RI | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| RI | obs. | 26 | 26 | 24 | 23 | 25 | 26 | 27 |
| RI | pred (50%) | 19 | 14 | 13 | 11 | 9 | 7 | 5 |
| RI | sup (99.5%) | 232 | 244 | 261 | 281 | 305 | 335 | 372 |
| VC | inf (0.5%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| VC | obs. | 32 | 32 | 34 | 36 | 38 | 37 | 39 |
| VC | pred (50%) | 42 | 38 | 38 | 37 | 37 | 37 | 36 |
| VC | sup (99.5%) | 251 | 278 | 307 | 336 | 366 | 395 | 425 |

References
- Li, M.Y.; Muldowney, J.S. Global stability for the SEIR model in epidemiology. Math. Biosci. 1995, 125, 155–164. [Google Scholar] [CrossRef]
- Agosto, A.; Cavaliere, G.; Kristensen, D.; Rahbek, A. Modeling corporate defaults: Poisson autoregressions with exogenous covariates (PARX). J. Empir. Financ. 2016, 38, 640–663. [Google Scholar] [CrossRef] [Green Version]
- Agosto, A.; Giudici, P. A Poisson Autoregressive Model to Understand COVID-19 Contagion Dynamics. Risks 2020, 8, 77. [Google Scholar] [CrossRef]
- Paul, M.; Held, L. Predictive assessment of a non-linear random effects model for multivariate time series of infectious disease counts. Stat. Med. 2011, 30, 1118–1136. [Google Scholar] [CrossRef] [PubMed]
- Giuliani, D.; Dickson, M.M.; Espa, G.; Santi, F. Modelling and predicting the spread of Coronavirus (COVID-19) infection in NUTS-3 Italian regions. BMC Infect. Dis. 2020, 20, 700. [Google Scholar]
- Davis, R.A.; Fokianos, K.; Holan, S.H.; Joe, H.; Livsey, J.; Lund, R.; Pipiras, V.; Ravishanker, N. Count time series: A methodological review. J. Am. Stat. Assoc. 2021, 3, 1–15. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Breiman, L. Statistical modeling: The two cultures (with comments and a rejoinder by the author). Stat. Sci. 2001, 16, 199–231. [Google Scholar] [CrossRef]
- Polson, N.G.; Sokolov, V. Deep Learning: A Bayesian Perspective. Bayesian Anal. 2017, 12, 1275–1304. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems, 2015. Software. 2015. Available online: tensorflow.org (accessed on 25 August 2021).
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. A 2021, 379, 20200209. [Google Scholar] [CrossRef] [PubMed]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. Phys. D Nonlinear Phenom. 2020, 404, 132306. [Google Scholar] [CrossRef] [Green Version]
- West, M.; Harrison, J. The Dynamic Linear Model. In Bayesian Forecasting and Dynamic Models; Springer: New York, NY, USA, 1989; pp. 105–141. [Google Scholar] [CrossRef]
- Wöllmer, M.; Eyben, F.; Graves, A.; Schuller, B.; Rigoll, G. Bidirectional LSTM networks for context-sensitive keyword detection in a cognitive virtual agent framework. Cogn. Comput. 2010, 2, 180–190. [Google Scholar] [CrossRef] [Green Version]
- Conn, P.B.; Johnson, D.S.; Williams, P.J.; Melin, S.R.; Hooten, M.B. A guide to Bayesian model checking for ecologists. Ecol. Monogr. 2018, 88, 526–542. [Google Scholar] [CrossRef]
- Bayarri, M.; Castellanos, M. Bayesian checking of the second levels of hierarchical models. Stat. Sci. 2007, 22, 322–343. [Google Scholar]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Jaeger, H. The “Echo State” Approach to Analysing and Training Recurrent Neural Networks-with an Erratum Note; GMD Technical Report; German National Research Center for Information Technology: Bonn, Germany, 2001; Volume 148, p. 13. [Google Scholar]
- Wu, Y.; Ma, Y.; Liu, J.; Du, J.; Xing, L. Self-attention convolutional neural network for improved MR image reconstruction. Inf. Sci. 2019, 490, 317–328. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hamilton, J.D. Time Series Analysis; Princeton University Press: Princeton, NJ, USA, 2020. [Google Scholar]
- Campagnoli, P.; Petrone, S.; Petris, G. Dynamic Linear Models; Springer: New York, NY, USA, 2009. [Google Scholar]
- Karpatne, A.; Atluri, G.; Faghmous, J.H.; Steinbach, M.; Banerjee, A.; Ganguly, A.; Shekhar, S.; Samatova, N.; Kumar, V. Theory-guided data science: A new paradigm for scientific discovery from data. IEEE Trans. Knowl. Data Eng. 2017, 29, 2318–2331. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cabras, S. A Bayesian-Deep Learning Model for Estimating COVID-19 Evolution in Spain. Mathematics 2021, 9, 2921. https://doi.org/10.3390/math9222921
Cabras S. A Bayesian-Deep Learning Model for Estimating COVID-19 Evolution in Spain. Mathematics. 2021; 9(22):2921. https://doi.org/10.3390/math9222921
Chicago/Turabian StyleCabras, Stefano. 2021. "A Bayesian-Deep Learning Model for Estimating COVID-19 Evolution in Spain" Mathematics 9, no. 22: 2921. https://doi.org/10.3390/math9222921
APA StyleCabras, S. (2021). A Bayesian-Deep Learning Model for Estimating COVID-19 Evolution in Spain. Mathematics, 9(22), 2921. https://doi.org/10.3390/math9222921