Recognizing Human Races through Machine Learning—A Multi-Network, Multi-Features Study




Abstract
:1. Introduction
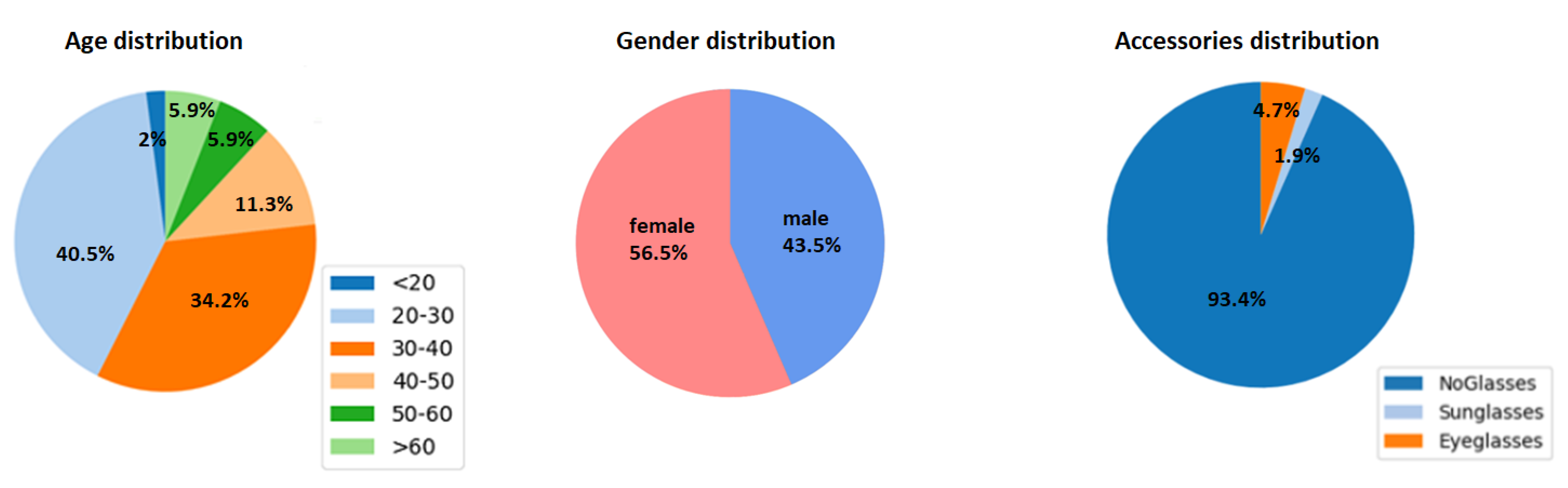
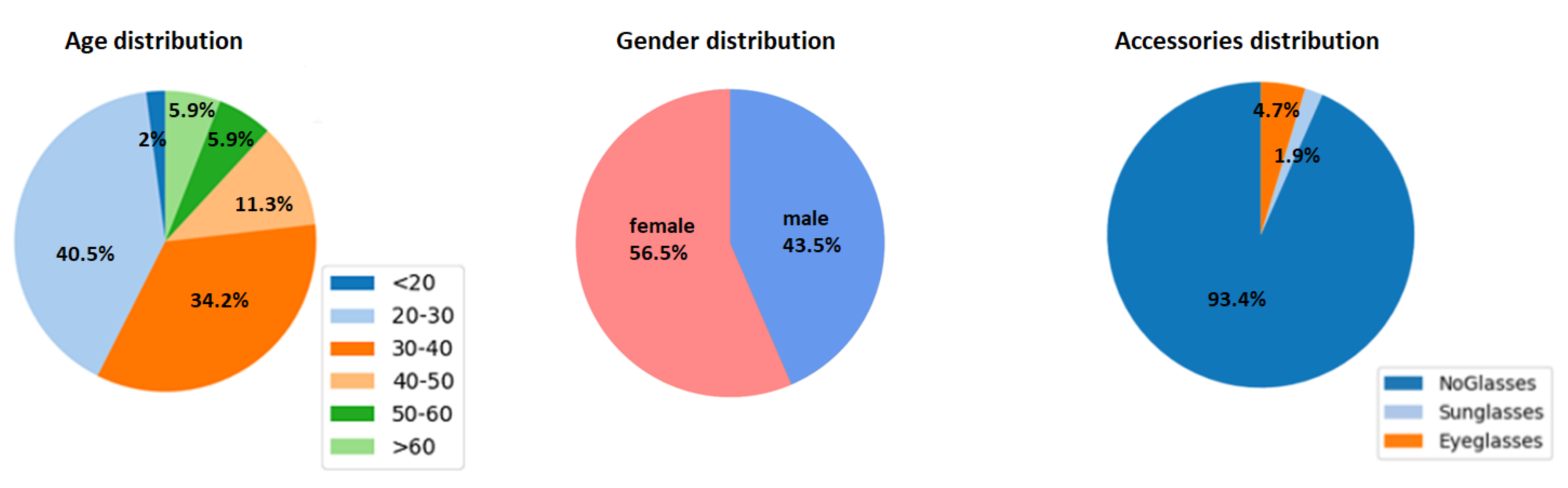
- The gathering of a large-scale “in the wild” face dataset (FaceARG) annotated with race and ethnicity information. To our knowledge, we gathered the largest available face database (of more than 175,000 images) annotated with race, age, gender and accessories information.
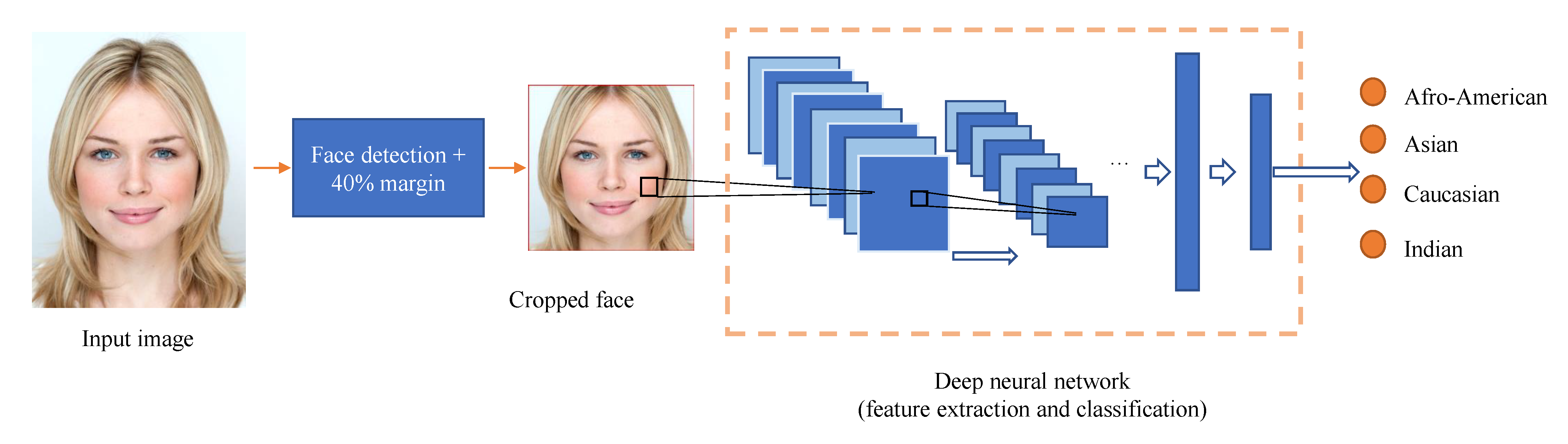
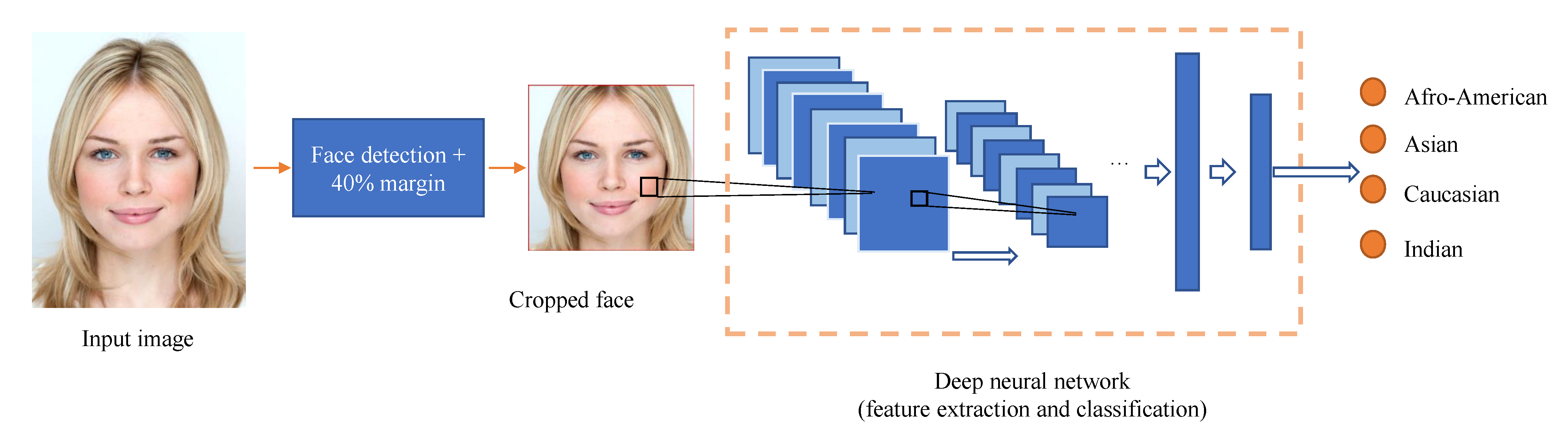
- The training and comparison of four state of the art convolutional neural networks (CNN) on the specific use case of racial classification. The taxonomy we propose contains four racial labels: Asian, Black, Caucasian and Indian.
- Finally, multiple facial image corruption experiments are employed in order to understand what facial features the networks see as relevant in perceiving race, and to compare the way the race is perceived by humans and the convolutional networks. These experiments show an agreement of the human perception with the computer based classification, but they also show that the CNN based systems are robust, largely invariant to missing facial features or regions.
2. Related Works
3. Race and Gender Faces in the Wild
4. Race Detection Using Convolutional Neural Networks
5. Experimental Results
5.1. Training
5.2. Evaluation Protocol
5.3. Race Detection
5.4. Robustness Analysis
- Blur/occlusion of the eye region: the eyes were masked/blurred in order to determine their importance in the race classification problem.
- Blur/occlusion of the nose region: the nostril region was masked/blurred in order to determine its importance in the race classification problem.
- Blur/occlusion of the mouth region: the mouth region was masked/blurred in order to determine its importance in the race classification problem.
- Grayscale conversion: this transformation is performed in order to determine the importance of the chromatic information.
- Increase/decrease the image brightness: these transformations are performed in order to determine the robustness of the classifier towards overexposed and underexposed images.
- Blur the entire image with a Gaussian filter of size 17 × 17: this transformation corresponds to low resolution image (similar to the ones captured from bad quality surveillance cameras).
Comparison to the State of the Art
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wade, P.; Takezawa, Y.I.; Smedley, A. Human Race. In Encyclopaedia Britannica. Available online: https://www.britannica.com/topic/race-human (accessed on 28 July 2020).
- Darwin, C. The Descent of Man and Selection in Relation to Sex; D. Appleton: New York, NY, USA, 1888; Volume 1. [Google Scholar]
- Fu, S.; He, H.; Hou, Z.G. Learning race from face: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2483–2509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brown, T.I.; Uncapher, M.R.; Chow, T.E.; Eberhardt, J.L.; Wagner, A.D. Cognitive control, attention, and the other race effect in memory. PLoS ONE 2017, 12, e0173579. [Google Scholar] [CrossRef] [PubMed]
- Kelly, D.J.; Quinn, P.C.; Slater, A.M.; Lee, K.; Ge, L.; Pascalis, O. The other-race effect develops during infancy: Evidence of perceptual narrowing. Psychol. Sci. 2007, 18, 1084–1089. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Valentine, T. A unified account of the effects of distinctiveness, inversion, and race in face recognition. Q. J. Exp. Psychol. 1991, 43, 161–204. [Google Scholar] [CrossRef]
- Phillips, P.J.; Jiang, F.; Narvekar, A.; Ayyad, J.; O’Toole, A.J. An other-race effect for face recognition algorithms. ACM Trans. Appl. Percept. (TAP) 2011, 8, 14. [Google Scholar] [CrossRef]
- Roomi, S.M.M.; Virasundarii, S.; Selvamegala, S.; Jeevanandham, S.; Hariharasudhan, D. Race classification based on facial features. In Proceedings of the IEEE 2011 Third National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), Hubli, India, 15–17 December 2011; pp. 54–57. [Google Scholar]
- Tin, H.H.K.; Sein, M.M. Automatic Race Identification from Face Images in Myanmar. In Proceedings of the The First International Conference on Energy Environment and Human Engineering (ICEEHE 2013), Yangon, Myanmar, 21–23 December 2013. [Google Scholar]
- Klare, B.; Jain, A.K. On a taxonomy of facial features. In Proceedings of the 2010 Fourth IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS), Washington, DC, USA, 27–29 September 2010; pp. 1–8. [Google Scholar]
- Narang, N.; Bourlai, T. Gender and ethnicity classification using deep learning in heterogeneous face recognition. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar]
- Wang, W.; He, F.; Zhao, Q. Facial Ethnicity Classification with Deep Convolutional Neural Networks. In Proceedings of the Chinese Conference on Biometric Recognition, Chengdu, China, 14–16 October 2016; pp. 176–185. [Google Scholar]
- Katti, H.; Arun, S. Can you tell where in India I am from? Comparing humans and computers on fine-grained race face classification. arXiv 2017, arXiv:1703.07595. [Google Scholar]
- Ryu, H.J.; Adam, H.; Mitchell, M. Inclusivefacenet: Improving face attribute detection with race and gender diversity. arXiv 2017, arXiv:1712.00193. [Google Scholar]
- Wang, M.; Deng, W.; Hu, J.; Tao, X.; Huang, Y. Racial faces in the wild: Reducing racial bias by information maximization adaptation network. In Proceedings of the IEEE International Conference on Computer Vision, (ICCV 2019), Seoul, Korea, 27 October–2 November 2019; pp. 692–702. [Google Scholar]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. Ms-celeb-1m: A dataset and benchmark for large-scale face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 87–102. [Google Scholar]
- Face++. Available online: https://www.faceplusplus.com/ (accessed on 13 October 2020).
- Yucer, S.; Akçay, S.; Al-Moubayed, N.; Breckon, T.P. Exploring Racial Bias within Face Recognition via per-subject Adversarially-Enabled Data Augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 18–19. [Google Scholar]
- Torralba, A.; Efros, A.A. Unbiased look at dataset bias. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 1521–1528. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 4278–4284. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Bai, Z.; Li, Y.; Woźniak, M.; Zhou, M.; Li, D. DecomVQANet: Decomposing visual question answering deep network via tensor decomposition and regression. Pattern Recognit. 2020, 110, 107538. [Google Scholar] [CrossRef]
- Wozniak, M.; Wieczorek, M.; Silka, J.; Polap, D. Body pose prediction based on motion sensor data and Recurrent Neural Network. IEEE Trans. Ind. Inform. 2020, 17, 2101–2111. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going deeper with embedded fpga platform for convolutional neural network. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; ACM: New York, NY, USA, 2016; pp. 26–35. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167, 448–456. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.J.; Fei-Fei, L.; Yuille, A.; Huang, J.; Murphy, K. Progressive neural architecture search. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 19–34. [Google Scholar]
- Yang, T.J.; Howard, A.; Chen, B.; Zhang, X.; Go, A.; Sandler, M.; Sze, V.; Adam, H. Netadapt: Platform-aware neural network adaptation for mobile applications. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 285–300. [Google Scholar]
- Ma, D.S.; Correll, J.; Wittenbrink, B. The Chicago face database: A free stimulus set of faces and norming data. Behav. Res. Methods 2015, 47, 1122–1135. [Google Scholar] [CrossRef] [Green Version]
- Minear, M.; Park, D.C. A lifespan database of adult facial stimuli. Behav. Res. Methods Instrum. Comput. 2004, 36, 630–633. [Google Scholar] [CrossRef] [Green Version]
- Lyons, M.J.; Akamatsu, S.; Kamachi, M.; Gyoba, J.; Budynek, J. The Japanese female facial expression (JAFFE) database. In Proceedings of the Third International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 14–16. [Google Scholar]
- Strohminger, N.; Gray, K.; Chituc, V.; Heffner, J.; Schein, C.; Heagins, T.B. The MR2: A multi-racial, mega-resolution database of facial stimuli. Behav. Res. Methods 2016, 48, 1197–1204. [Google Scholar] [CrossRef] [Green Version]
- Setty, S.; Husain, M.; Beham, P.; Gudavalli, J.; Kandasamy, M.; Vaddi, R.; Hemadri, V.; Karure, J.; Raju, R.; Rajan, B.; et al. Indian movie face database: A benchmark for face recognition under wide variations. In Proceedings of the 2013 Fourth National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), Jodhpur, India, 18–21 December 2013; pp. 1–5. [Google Scholar]
- Hwang, B.W.; Roh, M.C.; Lee, S.W. Performance evaluation of face recognition algorithms on asian face database. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 19 May 2004; pp. 278–283. [Google Scholar]
- Ricanek, K.; Tesafaye, T. Morph: A longitudinal image database of normal adult age-progression. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 341–345. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Hinton, G.; Srivastava, N.; Swersky, K. Neural Networks for Machine Learning: Overview of Mini-Batch Gradient Descent. 2016. Available online: http://www.cs.toronto.edu/~tijmen/csc321/slides/lecture_slides_lec6.pdf (accessed on 20 October 2020).
- Kang, D.; Han, H.; Jain, A.K.; Lee, S.W. Nighttime face recognition at large standoff: Cross-distance and cross-spectral matching. Pattern Recognit. 2014, 47, 3750–3766. [Google Scholar] [CrossRef]
- Maeng, H.; Liao, S.; Kang, D.; Lee, S.W.; Jain, A.K. Nighttime face recognition at long distance: Cross-distance and cross-spectral matching. In Proceedings of the Asian Conference on Computer Vision, Daejeon, Korea, 5–9 November 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 708–721. [Google Scholar]
- Gao, W.; Cao, B.; Shan, S.; Chen, X.; Zhou, D.; Zhang, X.; Zhao, D. The CAS-PEAL large-scale Chinese face database and baseline evaluations. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2008, 38, 149–161. [Google Scholar]
- Linnaeus, C. Systema Naturae, 12th ed.; Laurentii Salvii: Stockholm, Sweden, 1767; Volume 2. [Google Scholar]
- von Luschan, F. Beiträge zur Völkerkunde der Deutschen Schutzgebiete; D. Reimer: Berlin, Germany, 1897. [Google Scholar]
- Farkas, L.G.; Katic, M.J.; Forrest, C.R. International anthropometric study of facial morphology in various ethnic groups/races. J. Craniofacial Surg. 2005, 16, 615–646. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wen, Y.F.; Wong, H.M.; Lin, R.; Yin, G.; McGrath, C. Inter-ethnic/racial facial variations: A systematic review and Bayesian meta-analysis of photogrammetric studies. PLoS ONE 2015, 10, e0134525. [Google Scholar] [CrossRef] [Green Version]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Fraser, I.H.; Craig, G.L.; Parker, D.M. Reaction time measures of feature saliency in schematic faces. Perception 1990, 19, 661–673. [Google Scholar] [CrossRef] [PubMed]
- Sinha, P.; Balas, B.; Ostrovsky, Y.; Russell, R. Face recognition by humans: Nineteen results all computer vision researchers should know about. Proc. IEEE 2006, 94, 1948–1962. [Google Scholar] [CrossRef]
- Sadr, J.; Jarudi, I.; Sinha, P. The role of eyebrows in face recognition. Perception 2003, 32, 285–293. [Google Scholar] [CrossRef]
- Stephen, I.D.; Perrett, D.I. Color and face perception. In Handbook of Color Psychology; Elliot, A.J., Fairchild, M.D., Franklin, A., Eds.; Cambridge Handbooks in Psychology; Cambridge University Press: Cambridge, UK, 2015; pp. 585–602. [Google Scholar] [CrossRef]
- Funderburg, L. The Changing Face of America. In National Geographic, October 2010. Available online: https://www.nationalgeographic.com/magazine/2013/10/changing-face-america/ (accessed on 1 December 2020).
- Wang, Y.; Liao, H.; Feng, Y.; Xu, X.; Luo, J. Do they all look the same? Deciphering Chinese, Japanese and Koreans by fine-grained deep learning. arXiv 2016, arXiv:1610.01854. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| VGG-19 Results | Inception-ResNet-v2 Results | |||||
| Pr | Re | F1 | Pr | Re | F1 | |
| Afro-American | 96.68 | 97.96 | 97.32 | 96.88 | 98.20 | 97.54 |
| Asian | 98.27 | 97.76 | 97.32 | 98.43 | 97.92 | 98.18 |
| Caucasian | 94.91 | 94.00 | 94.45 | 95.61 | 95.00 | 95.30 |
| Indian | 94.37 | 94.52 | 94.44 | 94.51 | 94.32 | 94.41 |
| Overall | 96.06 | 96.06 | 96.06 | 96.36 | 96.36 | 96.36 |
| Accuracy | 96.06 | 96.36 | ||||
| SeNet Results | Mobilenet V3 Results | |||||
| Pr | Re | F1 | Pr | Re | F1 | |
| Afro-American | 95.27 | 98.32 | 96.77 | 96.97 | 98.44 | 97.70 |
| Asian | 97.94 | 96.96 | 97.45 | 98.52 | 98.20 | 98.36 |
| Caucasian | 95.43 | 94.28 | 94.85 | 96.20 | 94.12 | 95.15 |
| Indian | 94.95 | 94.00 | 94.47 | 94.89 | 95.80 | 9.534 |
| Overall | 95.90 | 95.89 | 95.89 | 96.64 | 96.64 | 96.64 |
| Accuracy | 95.89 | 96.64 | ||||
| SENet | VGG-19 | |||||||
| Afro | Asian | Cauc. | Indian | Afro | Asian | Cauc. | Indian | |
| Afro | 2458 | 14 | 10 | 18 | 2449 | 10 | 15 | 26 |
| Asian | 35 | 2424 | 22 | 19 | 13 | 2444 | 29 | 14 |
| Cauc. | 31 | 24 | 2357 | 88 | 26 | 23 | 2350 | 101 |
| Indian | 56 | 13 | 81 | 2350 | 45 | 10 | 82 | 2363 |
| Resnet-v2 | Mobilenet V3 | |||||||
| Afro | Asian | Cauc. | Indian | Afro | Asian | Cauc. | Indian | |
| Afro | 2455 | 6 | 10 | 29 | 2461 | 5 | 15 | 19 |
| Asian | 15 | 2448 | 22 | 15 | 22 | 2455 | 15 | 8 |
| Cauc. | 15 | 14 | 2375 | 93 | 24 | 21 | 2353 | 102 |
| Indian | 49 | 16 | 77 | 2358 | 31 | 11 | 63 | 2395 |
| Experiment | African-American | Asian | Caucasian | Indian | Acc | ||||
|---|---|---|---|---|---|---|---|---|---|
| Pr | Re | Pr | Re | Pr | Re | Pr | Re | ||
| Eye blur | 96.92 | 93.04 | 96.51 | 86.16 | 82.66 | 94.20 | 87.42 | 88.08 | 90.37 |
| Eye occlusion | 93.99 | 83.84 | 75.81 | 80.72 | 93.46 | 70.92 | 68.11 | 87.48 | 80.74 |
| Nose blur | 97.89 | 96.68 | 98.03 | 97.44 | 95.15 | 93.32 | 91.60 | 95.04 | 95.62 |
| Nose occlusion | 89.79 | 96.00 | 98.37 | 91.64 | 90.79 | 91.48 | 90.08 | 89.32 | 92.11 |
| Mouth blur | 91.62 | 98.36 | 98.41 | 96.48 | 94.86 | 93.04 | 94.53 | 91.24 | 94.78 |
| Mouth occlusion | 82.06 | 97.00 | 98.21 | 94.48 | 92.82 | 88.88 | 94.43 | 84.84 | 91.30 |
| Grayscale | 94.83 | 97.68 | 97.48 | 97.52 | 90.40 | 96.40 | 96.59 | 87.24 | 94.71 |
| Brightness + + | 96.88 | 96.76 | 95.53 | 97.48 | 96.00 | 89.28 | 89.76 | 94.32 | 94.46 |
| Brightness– | 96.44 | 94.36 | 91.59 | 98.04 | 84.84 | 95.12 | 95.57 | 79.32 | 91.71 |
| Image blur | 94.72 | 96.96 | 94.11 | 97.20 | 93.35 | 89.88 | 91.35 | 89.60 | 93.41 |
| Original | 96.88 | 98.20 | 98.43 | 97.92 | 95.61 | 95.00 | 94.51 | 94.32 | 96.36 |
| Method | CNN | Classes | Dataset | Accuracy |
|---|---|---|---|---|
| [11] | VGG | Asian, Caucasian | LDHF, VIS images, 1m | 78.98% |
| [12] | 5 layers CNN | Black, White | Morph II | 99.7% |
| [12] | 5 layers CNN | Chinese, Non-Chinese | CAS-PEAL | 99.81% |
| [13] | VGG | South Indian, North Indian | CNSIFD [13] | 62.00% |
| [61] | Resnet [34] | Chinese, Japanese, Korean | Twitter, Celeb-A | 75.03% |
| Ours | Resnet v2 | Asian vs Non-Asian | LDHF, VIS, 1m | 100% |
| Ours | Resnet v2 | Asian, Afro, Caucasian, Indian | internet images | 96.36% |
| Ours | Resnet v2 | Asian vs Non-Asian | CAS-PEAL, Accesory | 99.05% |
| Ours | Resnet v2 | Asian vs Non-Asian | CAS-PEAL, Aging | 100% |
| Ours | Resnet v2 | Asian vs Non-Asian | CAS-PEAL, Background | 98.76% |
| Ours | Resnet v2 | Asian vs Non-Asian | CAS-PEAL, Distance | 99.08% |
| Ours | Resnet v2 | Asian vs Non-Asian | CAS-PEAL, Expression | 99.52% |
| Ours | Resnet v2 | Asian vs Non-Asian | CAS-PEAL, Lightning | 95.55% |
| Ours | Resnet v2 | Asian vs Non-Asian | CAS-PEAL, Normal | 99.61% |
| Image Type | Dataset Subset | Accuracy |
|---|---|---|
| visible spectrum | indoor, 1 m | 100% |
| visible spectrum | outdoor, 60 m | 100% |
| visible spectrum | outdoor, 100 m | 100% |
| visible spectrum | outdoor, 150 m | 97.97% |
| near infra-red spectrum | indoor, 1 m | 100% |
| near infra-red spectrum | outdoor, 60 m | 68% |
| near infra-red spectrum | outdoor, 100 m | 10.75% |
| near infra-red spectrum | outdoor, 150 m | 2.17% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Darabant, A.S.; Borza, D.; Danescu, R. Recognizing Human Races through Machine Learning—A Multi-Network, Multi-Features Study. Mathematics 2021, 9, 195. https://doi.org/10.3390/math9020195
Darabant AS, Borza D, Danescu R. Recognizing Human Races through Machine Learning—A Multi-Network, Multi-Features Study. Mathematics. 2021; 9(2):195. https://doi.org/10.3390/math9020195
Chicago/Turabian StyleDarabant, Adrian Sergiu, Diana Borza, and Radu Danescu. 2021. "Recognizing Human Races through Machine Learning—A Multi-Network, Multi-Features Study" Mathematics 9, no. 2: 195. https://doi.org/10.3390/math9020195
APA StyleDarabant, A. S., Borza, D., & Danescu, R. (2021). Recognizing Human Races through Machine Learning—A Multi-Network, Multi-Features Study. Mathematics, 9(2), 195. https://doi.org/10.3390/math9020195