On High-Order Iterative Schemes for the Matrix pth Root Avoiding the Use of Inverses



Abstract
1. Introduction
2. A General Method for Approximating the Matrix pth Root Free of Inverse Operators
2.1. Convergence
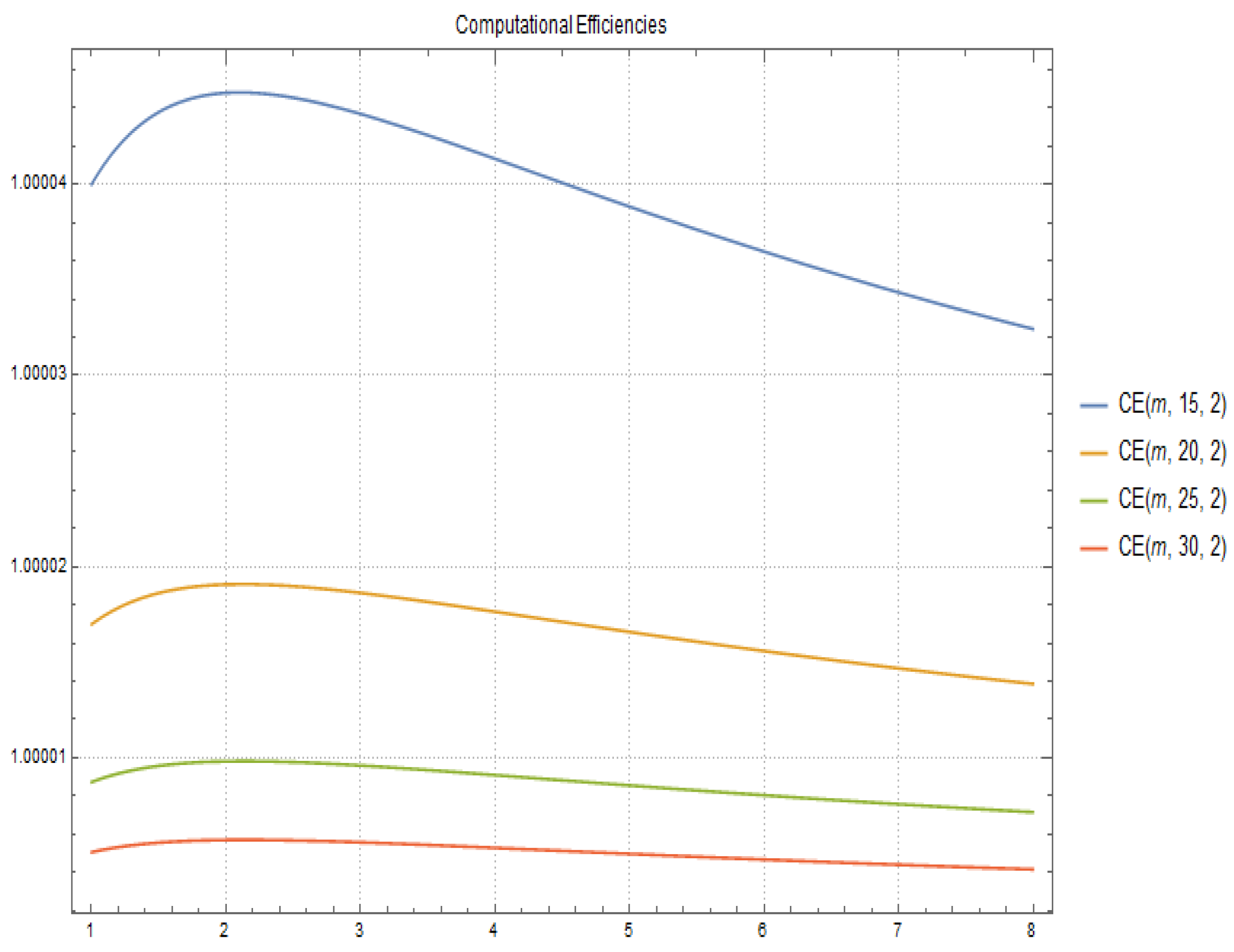
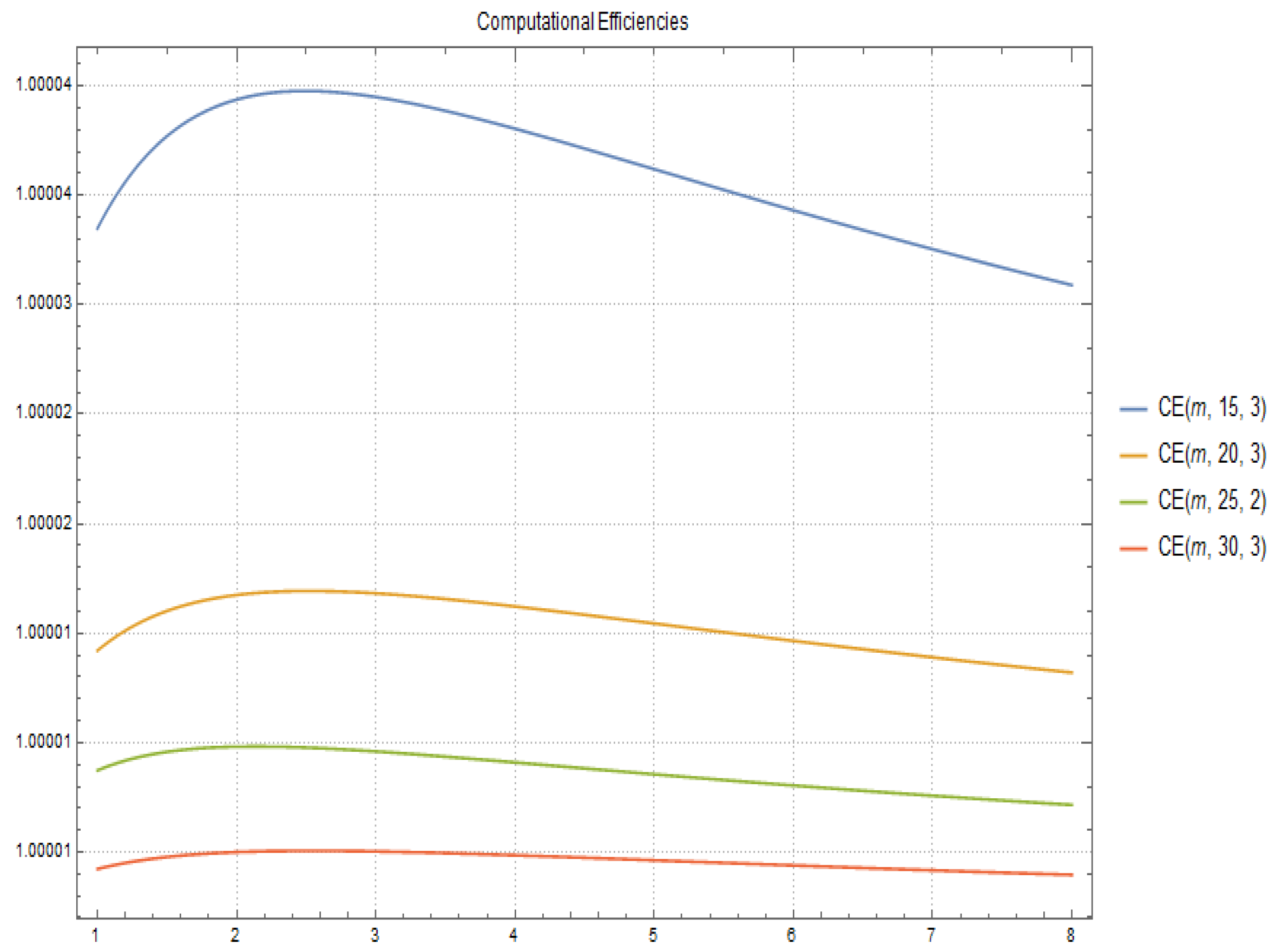
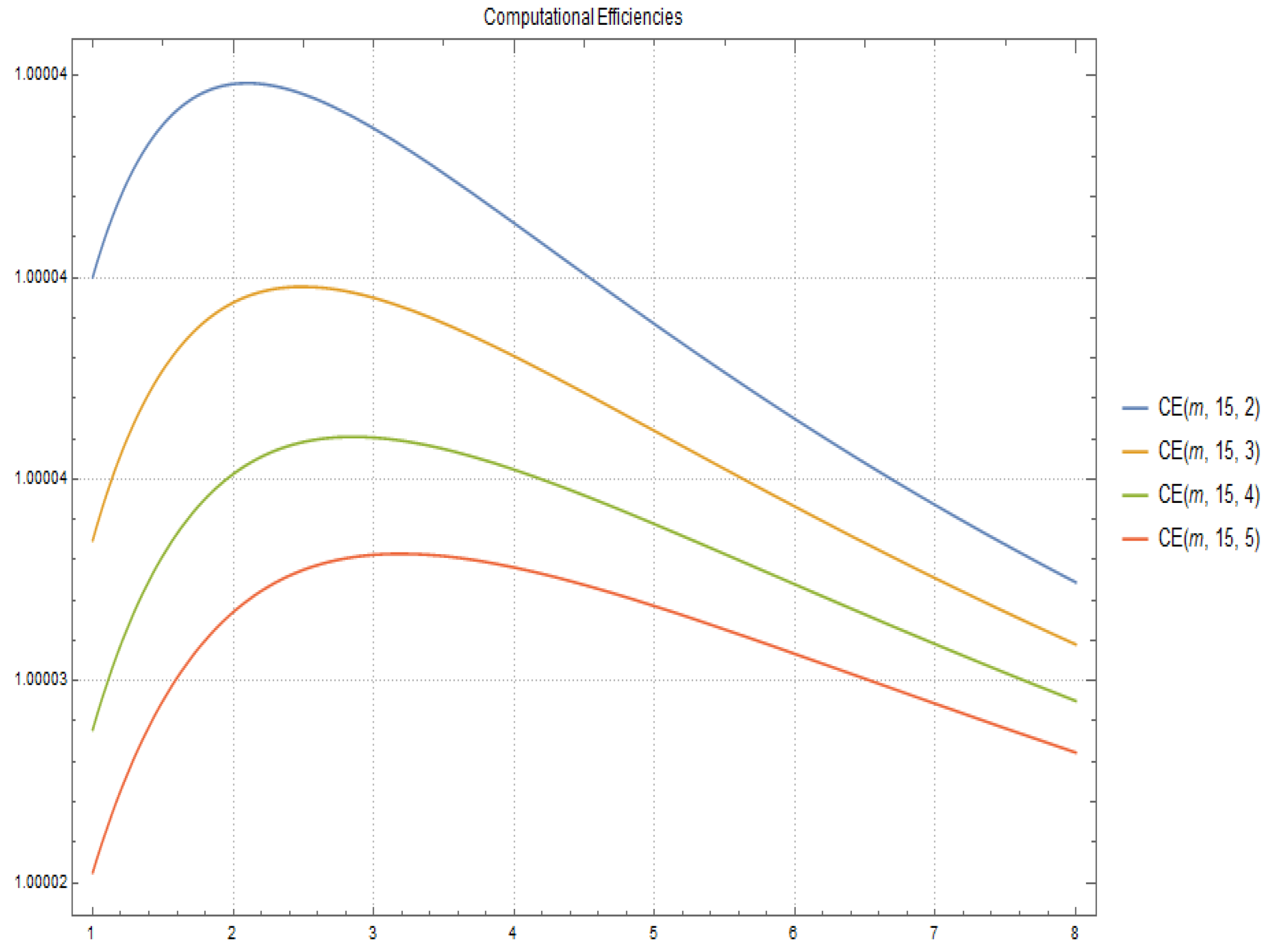
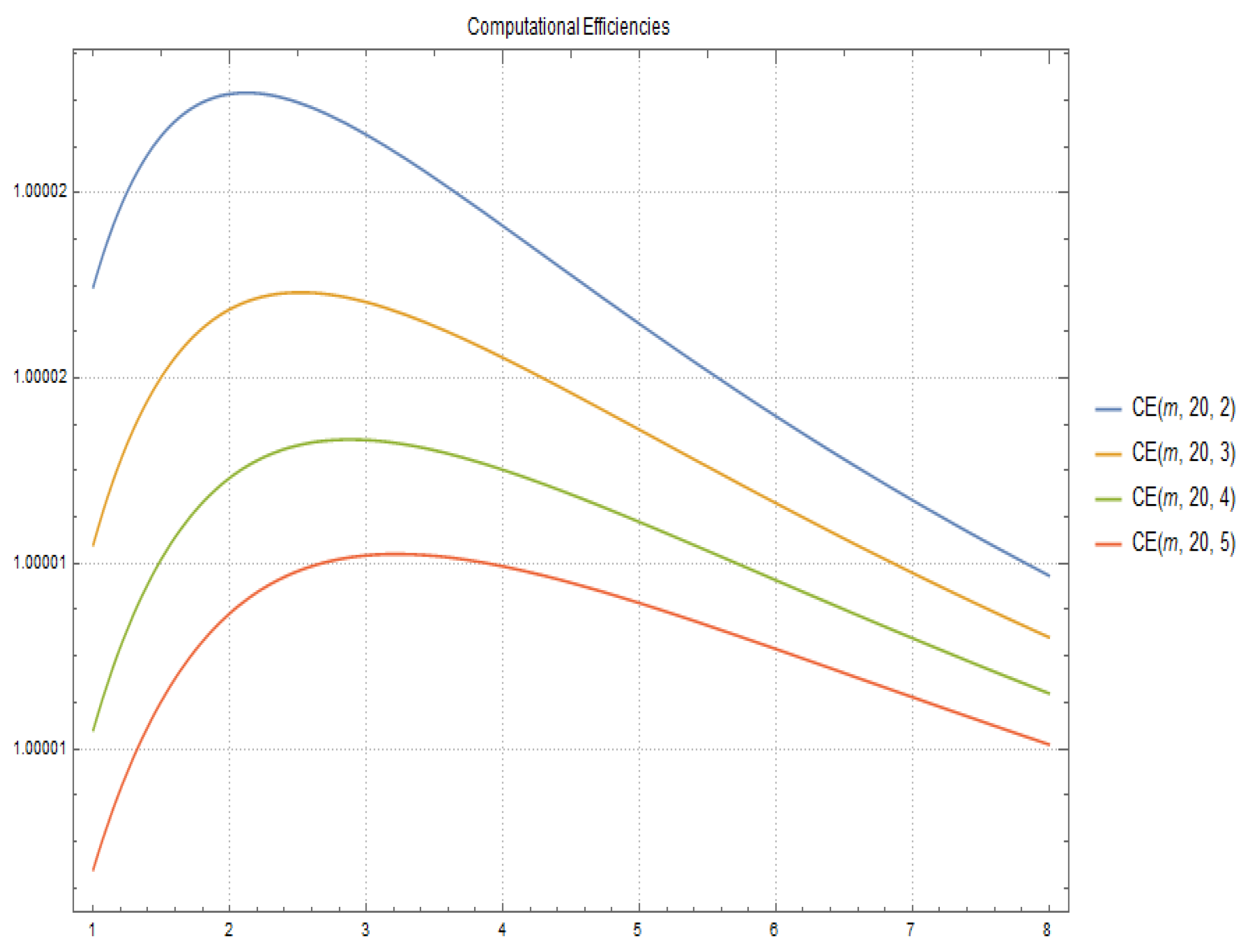
2.2. Computational Cost and Efficiency
- the computation of matrix , given by means of using (4), is and its computational efficiency is
- the computation of method (2) has a computational cost of and its computational efficiency is
- the computational cost of method (5) is obtained directly by and its computational efficiency is
3. Applications Related to Differential Equations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Higham, N.J. Newton’s method for the matrix square root. Math. Comp. 1986, 46, 537–549. [Google Scholar]
- Iannazzo, B. On the Newton method for the matrix pth root. SIAM J. Matrix Anal. Appl. 2006, 28, 503–523. [Google Scholar] [CrossRef]
- Guo, C.-H.; Higham, N.J. A Schur-Newton method for the matrix pth root and its inverse. IAM J. Matrix Anal. Appl. 2006, 28, 788–804. [Google Scholar] [CrossRef]
- Iannazzo, B. A note on computing the matrix square root. Calcolo 2003, 40, 273–283. [Google Scholar] [CrossRef]
- Petkov, M.; Bors̆ukova, S. A modified Newton method for obtaining roots of matrices. Annu. Univ. Sofia Fac. Math. 1974, 66, 341–347. (In Bulgarian) [Google Scholar]
- Smith, M.I. A Schur algorithm for computing matrix pth roots. SIAM J. Matrix Anal. Appl. 2003, 24, 971–989. [Google Scholar] [CrossRef]
- Amat, S.; Ezquerro, J.A.; Hernández-Verón, M.A. On a new family of high-order iterative methods for the matrix pth root. Numer. Linear Algebra Appl. 2015, 22, 585–595. [Google Scholar] [CrossRef]
- Guo, C.-H. On Newton’s method and Halley’s method for the principal pth root of a matrix. Linear Algebra Appl. 2010, 432, 1905–1922. [Google Scholar] [CrossRef]
- Iannazzo, B. A family of rational iterations and its application to the computation of the matrix pth root. SIAM J. Matrix Anal. Appl. 2008, 30, 1445–1462. [Google Scholar] [CrossRef]
- Amat, S.; Ezquerro, J.A.; Hernández-Verón, M.A. Approximation of inverse operators by a new family of high-order iterative methods. Numer. Linear Algebra Appl. 2014, 21, 629–644. [Google Scholar] [CrossRef]
- Higham, N.J.; Al-Mohy, A.H. Computing Matrix Functions; The University of Manchester, MIMS EPrint: Manchester, UK, 2010; Volume 18. [Google Scholar]
- Szekeres, B.J.; Izsák, F. Finite difference approximation of space-fractional diffusion problems: The matrix transformation method. Comput. Math. Appl. 2017, 73, 261–269. [Google Scholar] [CrossRef]
- Iannazzo, B.; Manasse, C. A Schur logarithmic algorithm for fractional powers of matrices. SIAM J. Matrix Anal. Appl. 2013, 34, 794–813. [Google Scholar] [CrossRef][Green Version]
- Higham, N.J.; Lin, L. An improved Schur–Pade algorithm for fractional powers of a matrix and their Fréchet derivatives. SIAM J. Matrix Anal. Appl. 2013, 34, 1341–1360. [Google Scholar] [CrossRef]
- Marino, G.; Scardamaglia, B.; Karapinar, E. Strong convergence theorem for strict pseudo-contractions in Hilbert spaces. J. Inequalities Appl. 2016, 2016, 134. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| p | Original Method Computing | New Combined Method with Smaller Cost |
|---|---|---|
| 2 | ||
| 4 | ||
| 6 | ||
| 8 |
| p | Original Method Computing | New Combined Method with Smaller Cost |
|---|---|---|
| 2 | ||
| 4 | ||
| 6 | ||
| 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amat, S.; Busquier, S.; Hernández-Verón, M.Á.; Magreñán, Á.A. On High-Order Iterative Schemes for the Matrix pth Root Avoiding the Use of Inverses. Mathematics 2021, 9, 144. https://doi.org/10.3390/math9020144
Amat S, Busquier S, Hernández-Verón MÁ, Magreñán ÁA. On High-Order Iterative Schemes for the Matrix pth Root Avoiding the Use of Inverses. Mathematics. 2021; 9(2):144. https://doi.org/10.3390/math9020144
Chicago/Turabian StyleAmat, Sergio, Sonia Busquier, Miguel Ángel Hernández-Verón, and Ángel Alberto Magreñán. 2021. "On High-Order Iterative Schemes for the Matrix pth Root Avoiding the Use of Inverses" Mathematics 9, no. 2: 144. https://doi.org/10.3390/math9020144
APA StyleAmat, S., Busquier, S., Hernández-Verón, M. Á., & Magreñán, Á. A. (2021). On High-Order Iterative Schemes for the Matrix pth Root Avoiding the Use of Inverses. Mathematics, 9(2), 144. https://doi.org/10.3390/math9020144