
Incremental DoE and Modeling Methodology with Gaussian Process Regression: An Industrially Applicable Approach to Incorporate Expert Knowledge


Abstract
:1. Introduction
- What benefits in the applicability of DoE methods for industrial processes can be achieved using the proposed method?
- What model quality can be achieved by the incremental modeling methodology, compared to a classical DoE and modeling method?
- How can expert knowledge be used to support the experimental design and modeling process?
2. Related Work
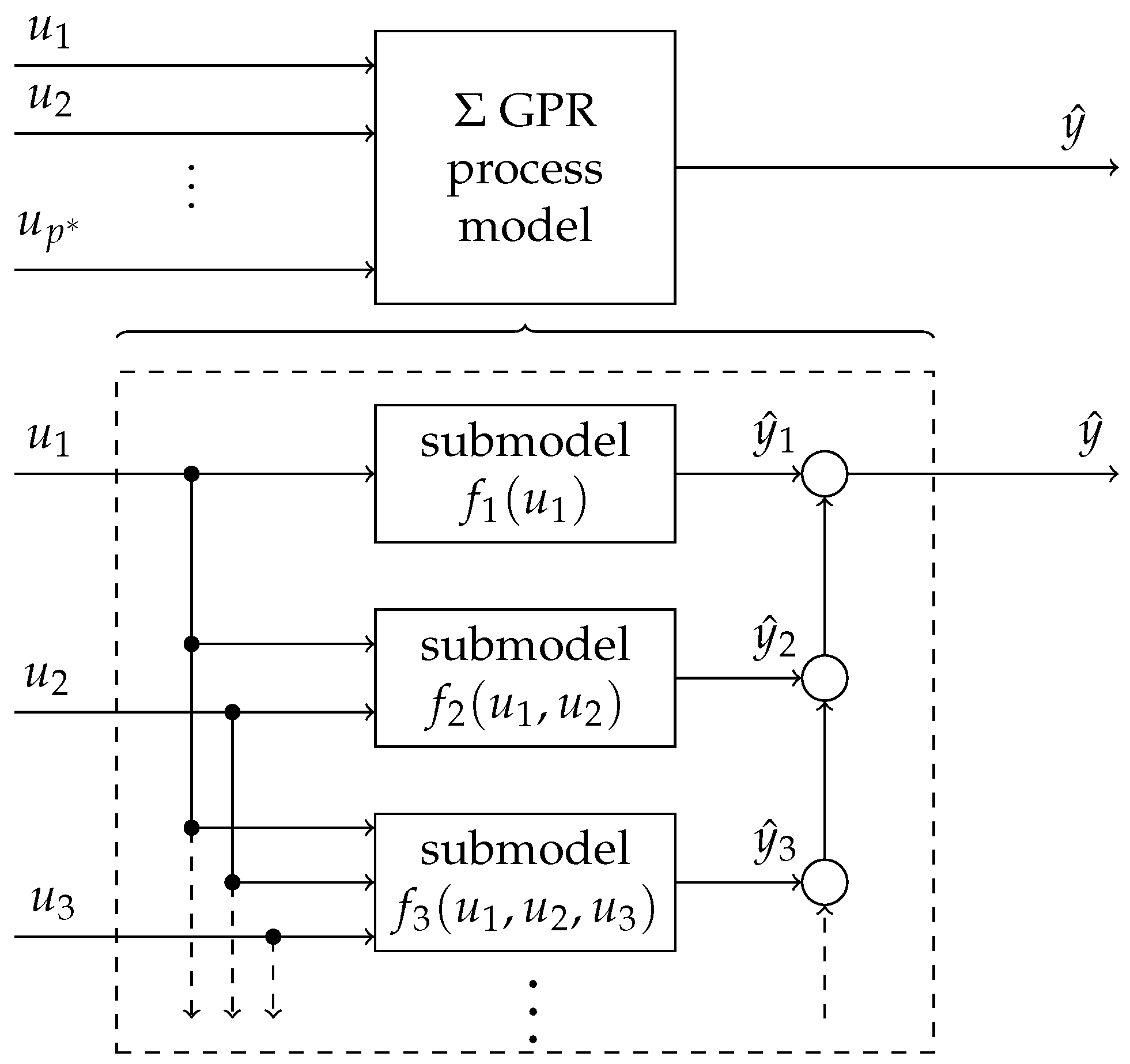
2.1. Additive Model Structures
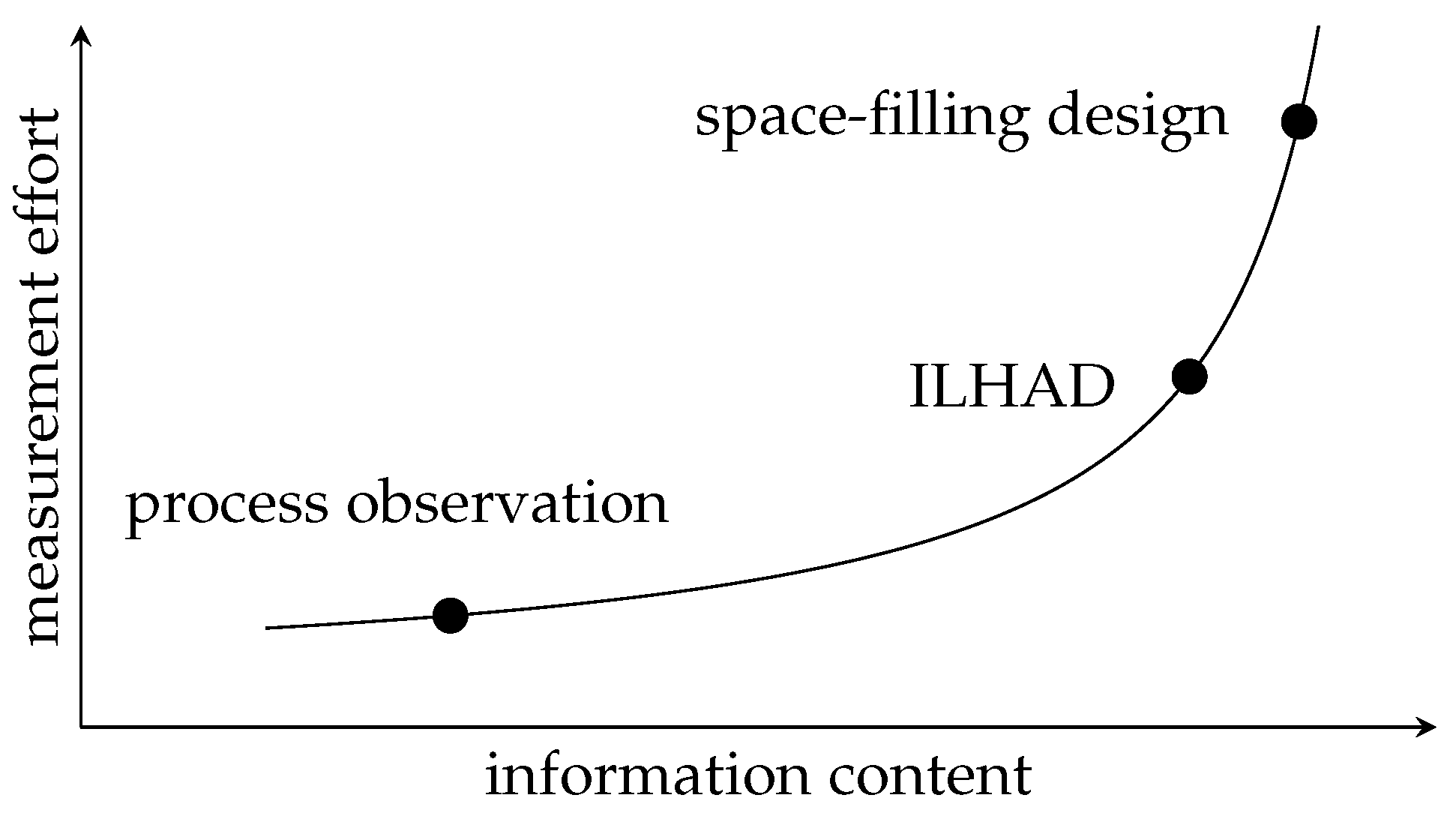
2.2. DoE for Industrial Applications
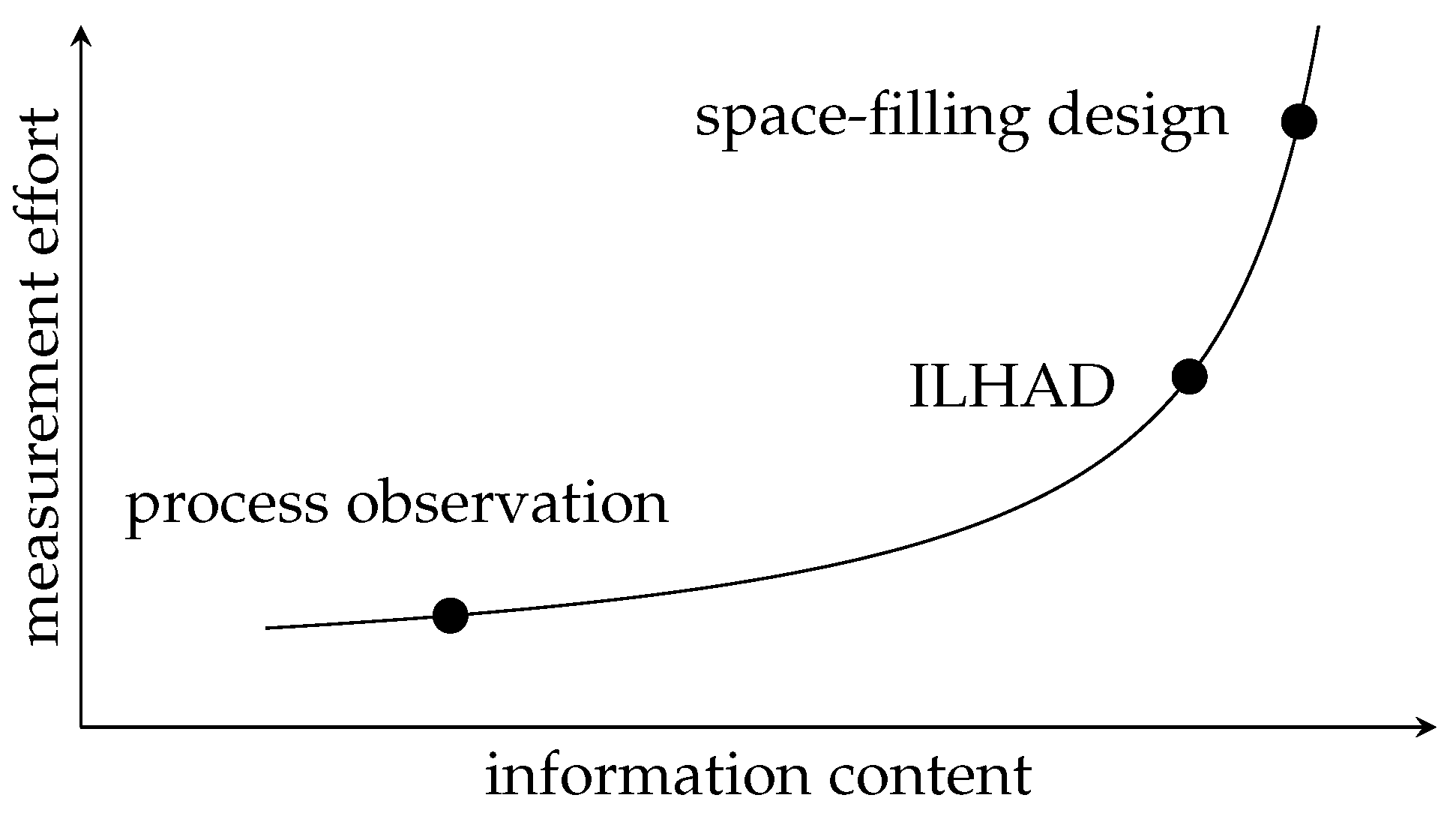
2.3. Stepwise DoE and Modeling Methodologies
3. Materials and Methods
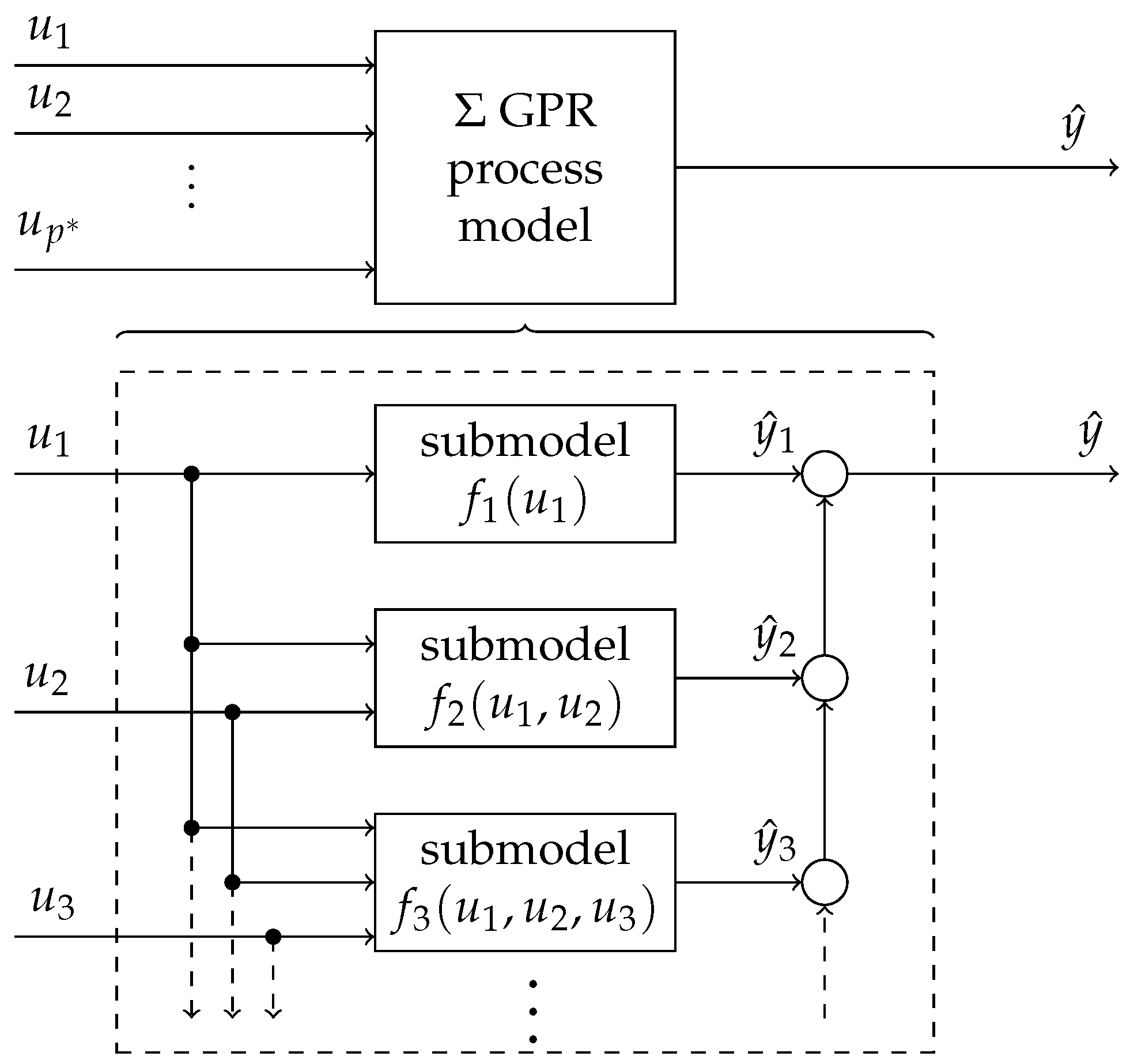
3.1. Incremental Models
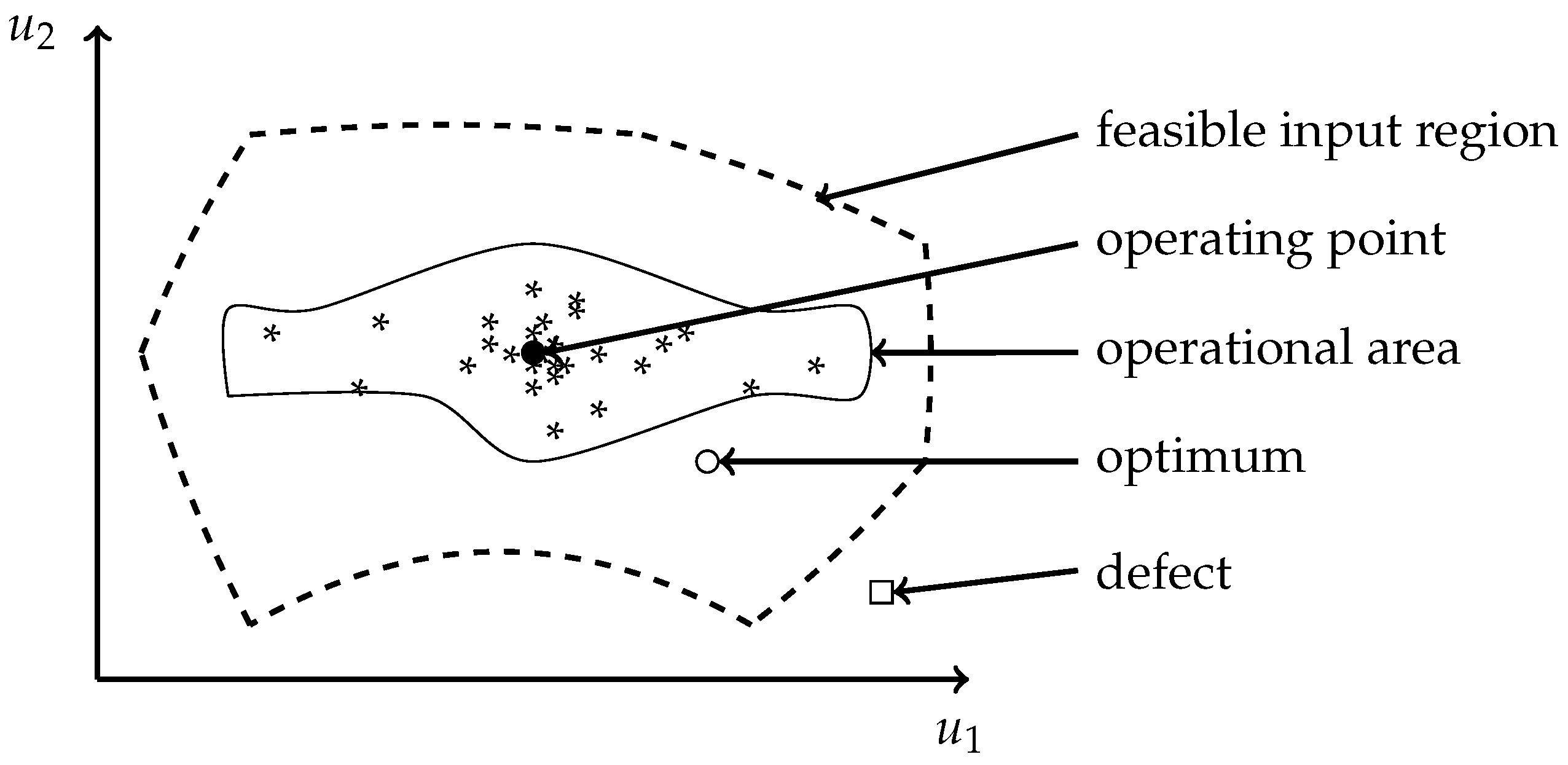
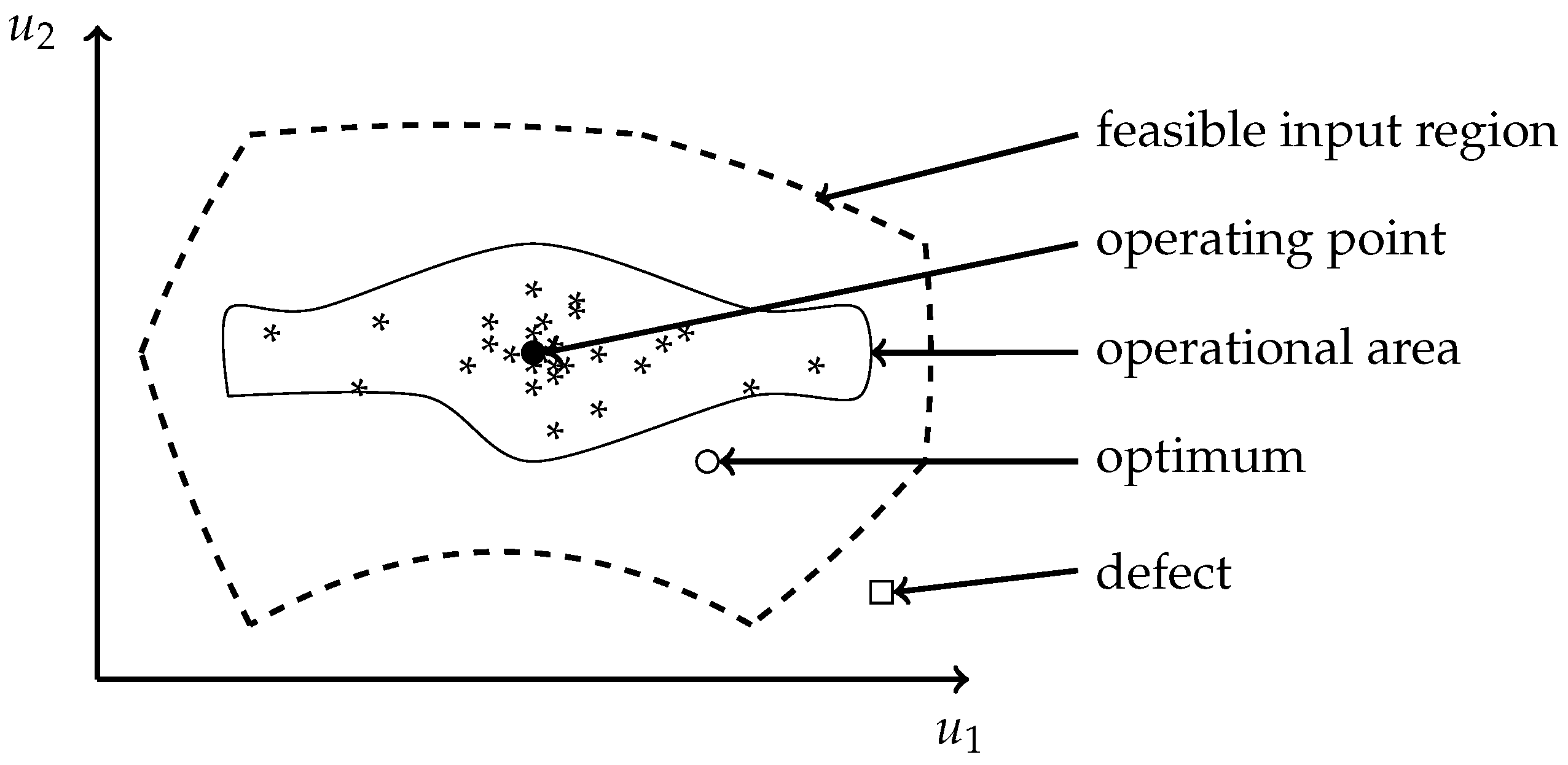
3.2. Experimental Design
3.3. Gaussian Process Regression
3.3.1. Fundamentals
3.3.2. Hyperparameter
3.4. Zero-Forcing in a Subspace
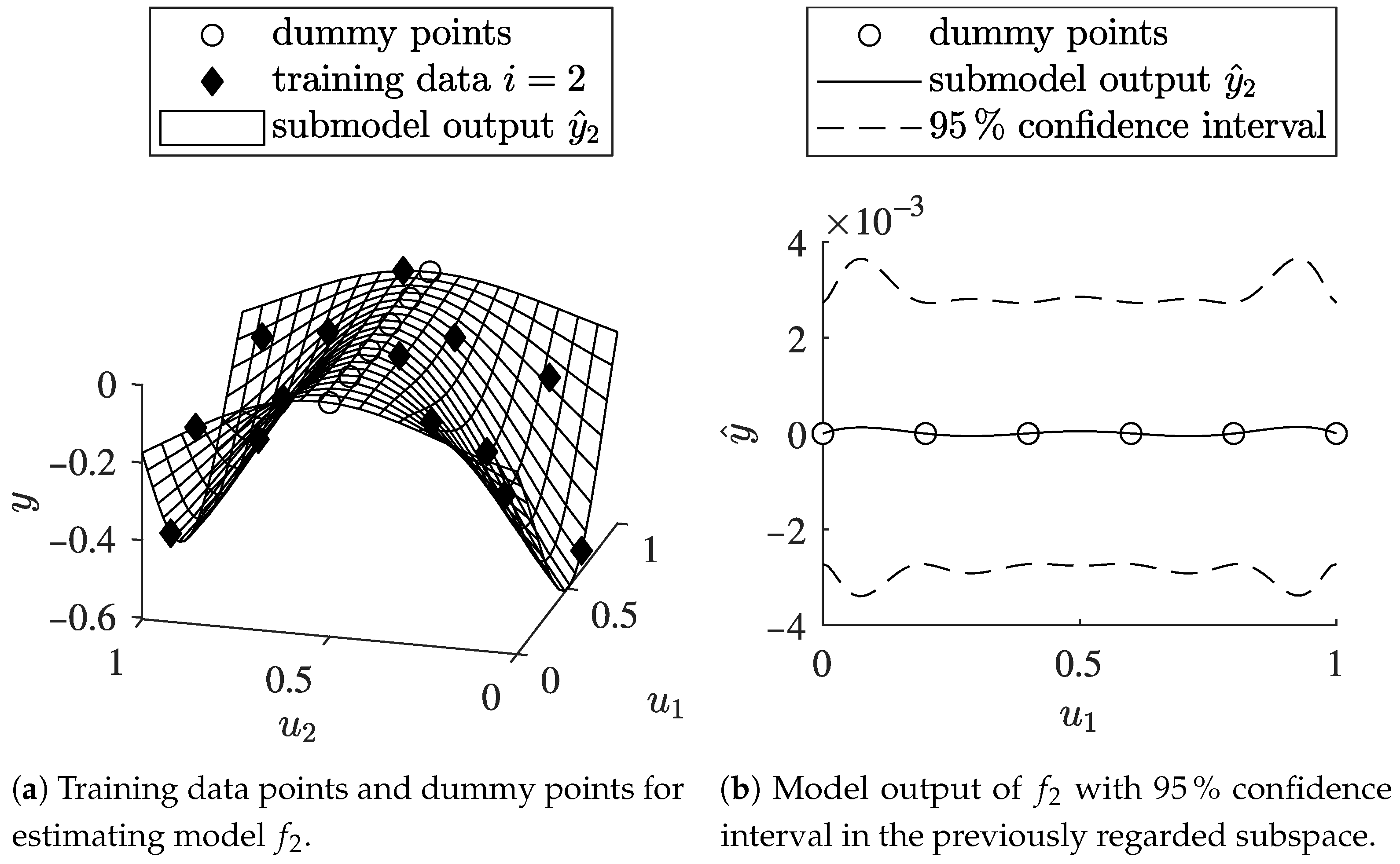
3.4.1. Additional Dummy Points
3.4.2. Nonstationary Kernel Function
4. Results
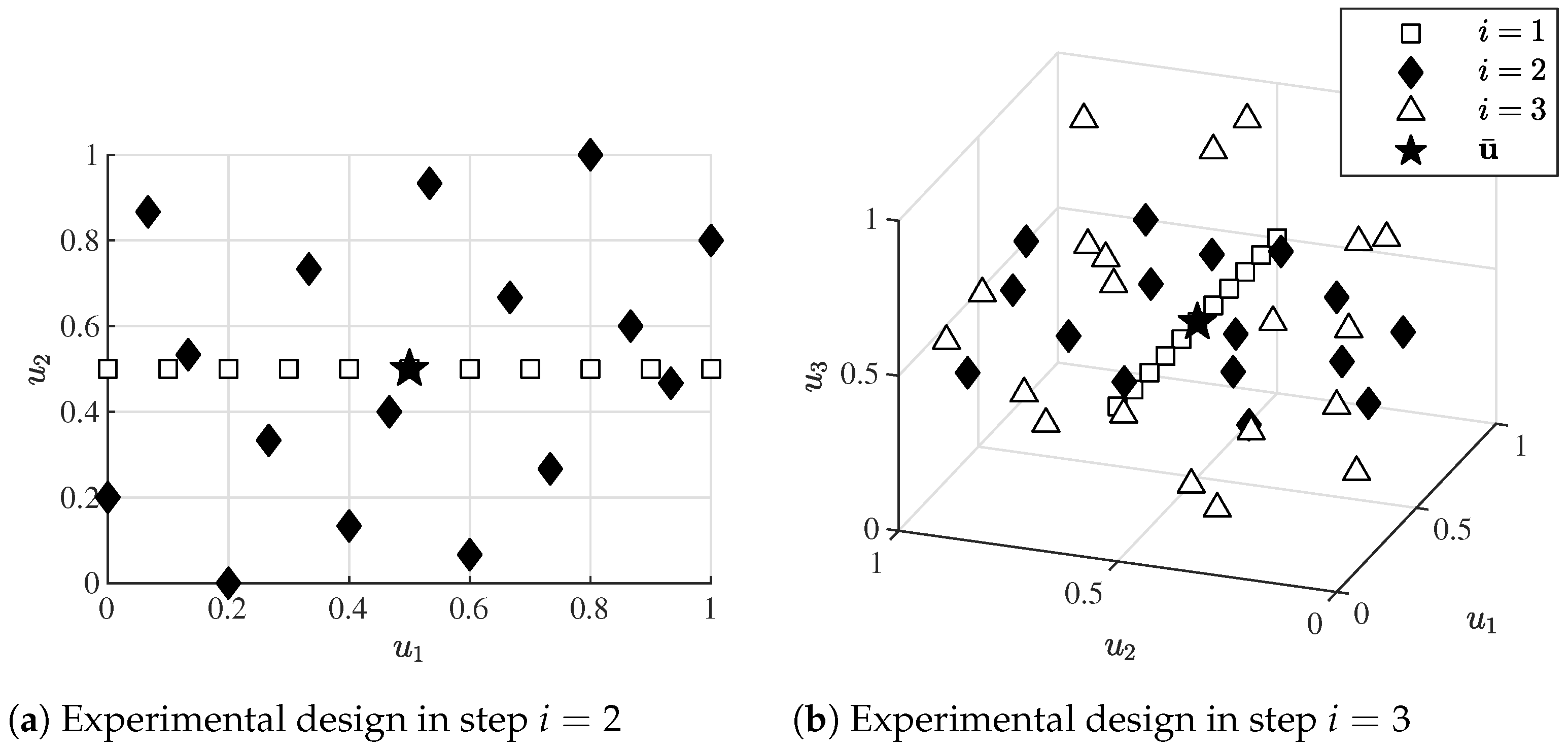
4.1. Computer Simulation Experiment
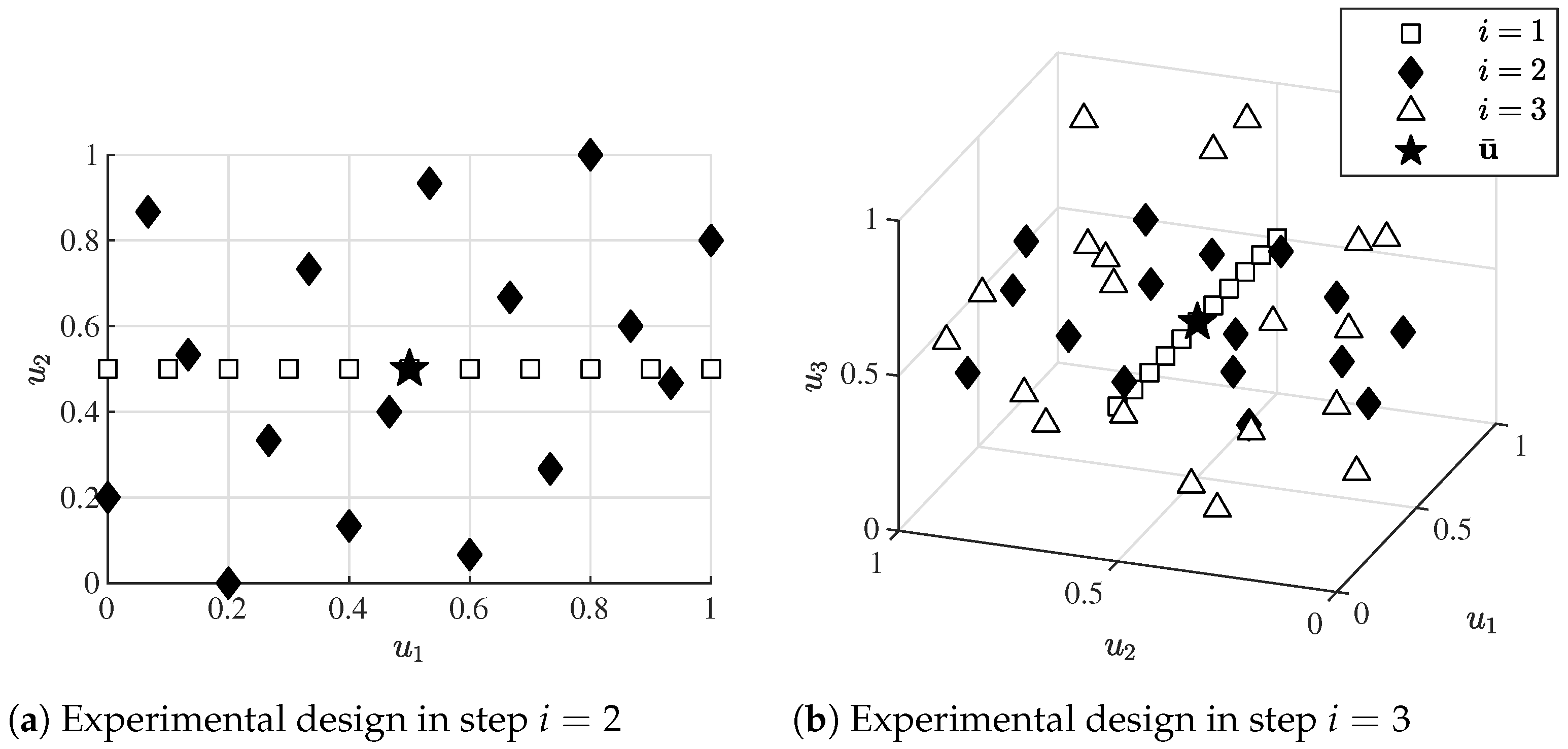
4.1.1. Comparison of Different Submodel Structures in ILHAD
4.1.2. Comparison of ILHAD and a Single Step GPR Model
4.1.3. Examination of the Kernel Length Scales
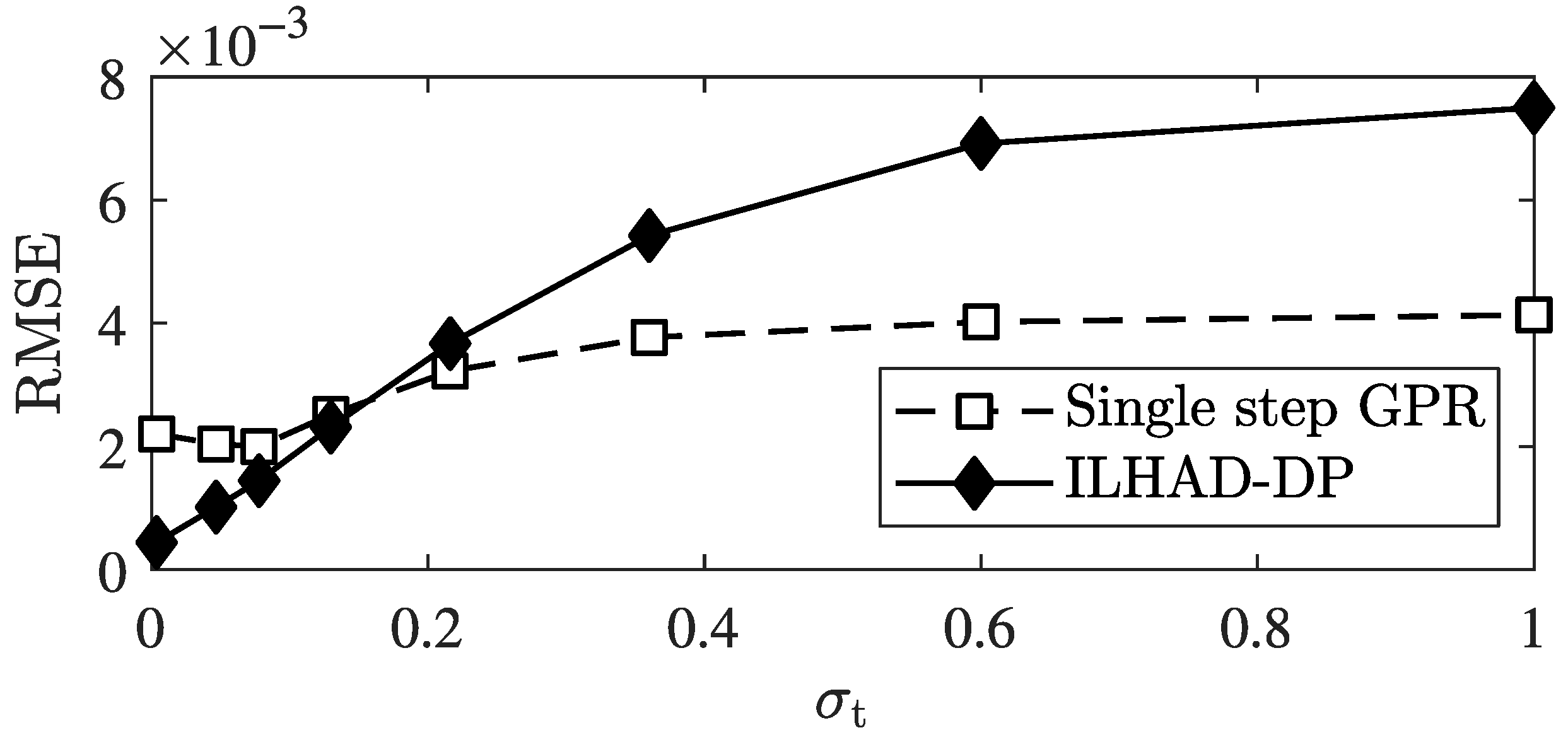
4.1.4. Influence of Noise and the Number of Performed Modeling Steps
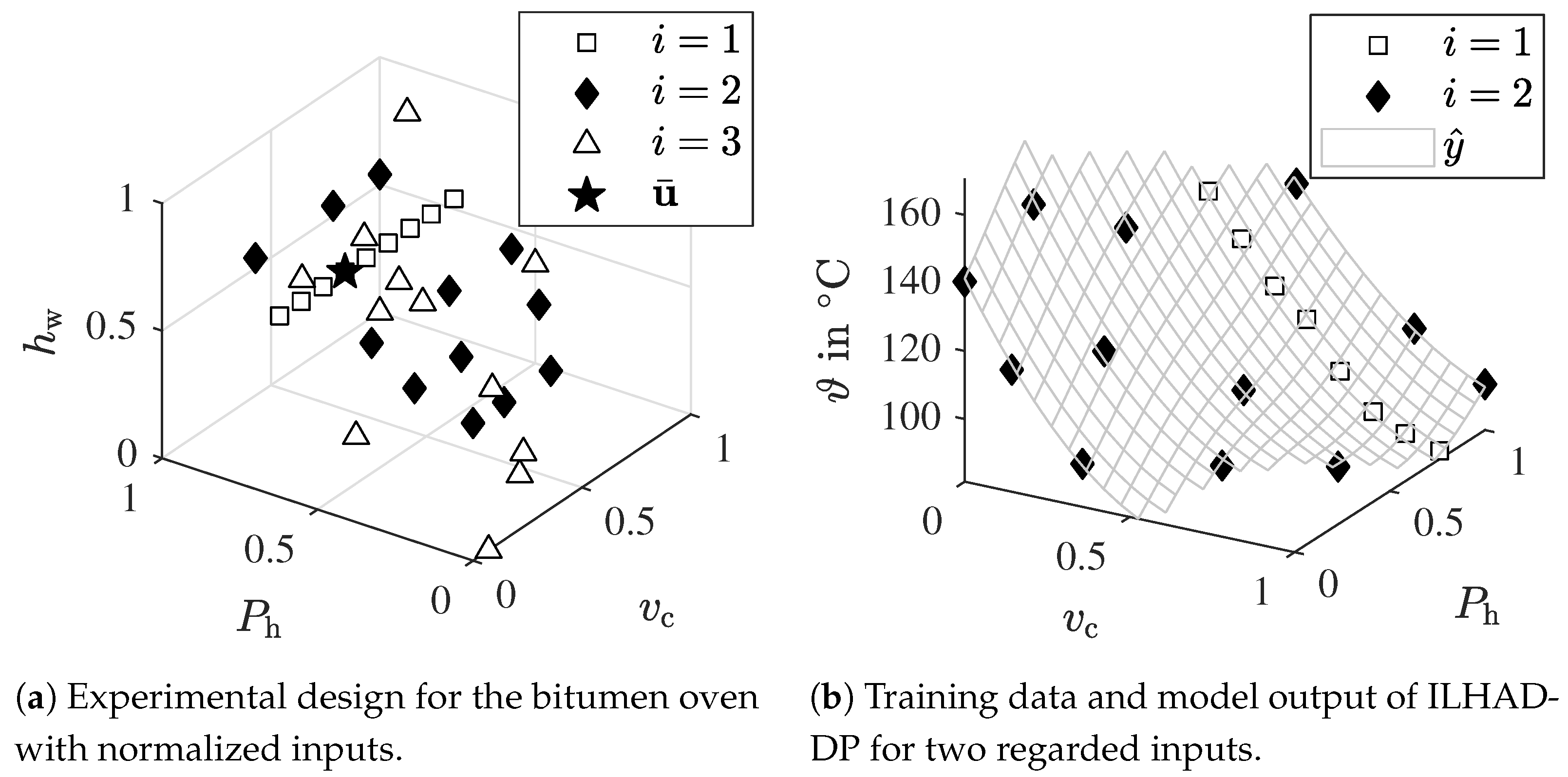
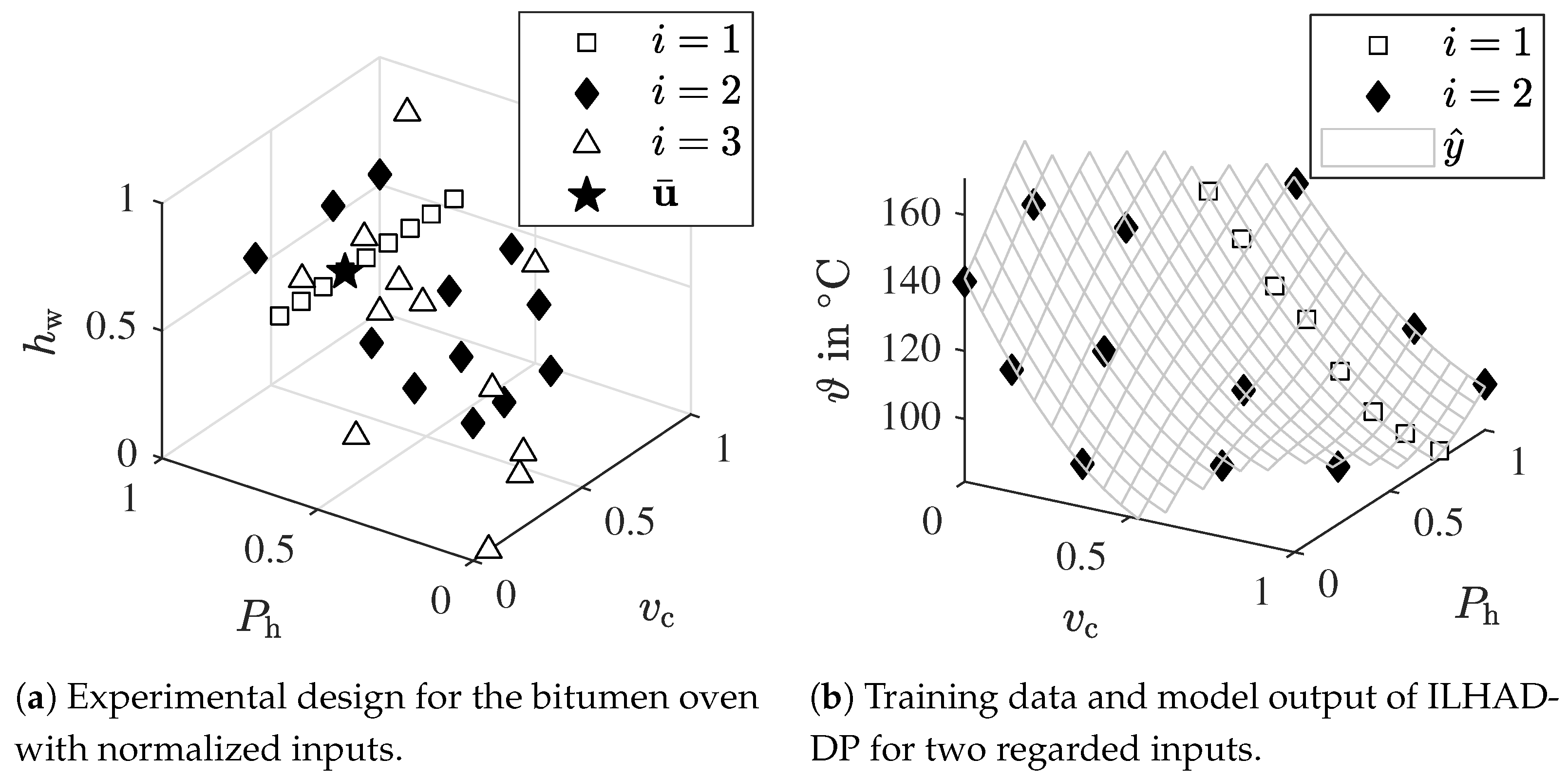
4.2. Bitumen Oven
5. Discussion
5.1. Model Quality
5.2. The Role of Domain Experts
5.3. Comparison of ILHAD-DP and ILHAD-NS
5.4. Applicability
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hirsch-Kreinsen, H.; Kubach, U.; von Wichert, G.; Hornung, S.; Hubrecht, L.; Sedlmeir, J.; Steglich, S. Key Themes of Industrie 4.0; Technical Report; Research Council of the Plattform Industrie 4.0: Munich, Germany, 2019. [Google Scholar]
- Fisher, O.J.; Watson, N.J.; Escrig, J.E.; Witt, R.; Porcu, L.; Bacon, D.; Rigley, M.; Gomes, R.L. Considerations, challenges and opportunities when developing data-driven models for process manufacturing systems. Comput. Chem. Eng. 2020, 140, 106881. [Google Scholar] [CrossRef]
- Freiesleben, J.; Keim, J.; Grutsch, M. Machine learning and Design of Experiments: Alternative approaches or complementary methodologies for quality improvement? Qual. Reliab. Eng. Int. 2020, 36, 1837–1848. [Google Scholar] [CrossRef]
- Freeman, L.J.; Ryan, A.G.; Kensler, J.L.K.; Dickinson, R.M.; Vining, G.G. A Tutorial on the Planning of Experiments. Qual. Eng. 2013, 25, 315–332. [Google Scholar] [CrossRef]
- Simpson, J.R.; Listak, C.M.; Hutto, G.T. Guidelines for Planning and Evidence for Assessing a Well-Designed Experiment. Qual. Eng. 2013, 25, 333–355. [Google Scholar] [CrossRef]
- Voigt, T.; Kohlhase, M.; Nelles, O. Incremental Latin Hypercube Additive Design for LOLIMOT. In Proceedings of the 25th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA 2020), Vienna, Austria, 8–11 September 2020; pp. 1602–1609. [Google Scholar]
- Nelles, O. Nonlinear System Identification: From Classical Approaches to Neural Networks, Fuzzy Models, and Gaussian Processes; Springer Nature: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Schielzeth, H. Simple means to improve the interpretability of regression coefficients. Methods Ecol. Evol. 2010, 1, 103–113. [Google Scholar] [CrossRef]
- Hastie, T.J.; Tibshirani, R.J. Generalized Additive Models; Chapman and Hall/CRC: Boca Raton, FL, USA, 1990. [Google Scholar]
- Bujalski, M.; Madejski, P. Forecasting of Heat Production in Combined Heat and Power Plants Using Generalized Additive Models. Energies 2021, 14, 2331. [Google Scholar] [CrossRef]
- Duvenaud, D.; Nickisch, H.; Rasmussen, C.E. Additive Gaussian Processes. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Granada, Spain, 12–15 December 2011; Curran Associates Inc.: Red Hook, NY, USA, 2011; NIPS’11, pp. 226–234. [Google Scholar]
- Yeom, C.U.; Kwak, K.C. The Development of Improved Incremental Models Using Local Granular Networks with Error Compensation. Symmetry 2017, 9, 266. [Google Scholar] [CrossRef] [Green Version]
- Pedrycz, W.; Kwak, K.C. The development of incremental models. IEEE Trans. Fuzzy Syst. 2007, 15, 507–518. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; Association for Computing Machinery: New York, NY, USA, 2016; KDD ’16, pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Montgomery, D. Design and Analysis of Experiments; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2017. [Google Scholar]
- Astakhov, V.P. Screening (sieve) design of experiments in metal cutting. In Design of Experiments in Production Engineering; Springer: Cham, Switzerland, 2016; pp. 1–37. [Google Scholar]
- Santner, T.J.; Williams, B.J.; Notz, W.I. The Design and Analysis of Computer Experiments; Springer: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Chen, C.C.; Chiang, K.T.; Chou, C.C.; Liao, Y.C. The use of D-optimal design for modeling and analyzing the vibration and surface roughness in the precision turning with a diamond cutting tool. Int. J. Adv. Manuf. Technol. 2011, 54, 465–478. [Google Scholar] [CrossRef]
- Emmert-Streib, F.; Dehmer, M. Evaluation of Regression Models: Model Assessment, Model Selection and Generalization Error. Mach. Learn. Knowl. Extr. 2019, 1, 521–551. [Google Scholar] [CrossRef] [Green Version]
- Saleh, A.K.M.E.; Arashi, M.; Kibria, B.M.G. Theory of Ridge Regression Estimation with Applications; John Wiley & Sons: Hoboken, NJ, USA, 2019; Volume 285. [Google Scholar]
- Rasmussen, C. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Lu, L.; Anderson-Cook, C.M.; Martin, M.; Ahmed, T. Practical choices for space-filling designs. Qual. Reliab. Eng. Int. 2021. [Google Scholar] [CrossRef]
- Kleijnen, J.P.C. Design and Analysis of Simulation Experiments; Springer: Cham, Switzerland, 2015. [Google Scholar]
- Cabral-Farias, R.; Pronzato, L.; Rendas, M.J. Incremental construction of nested designs based on two-level fractional factorial designs. Preprint hal-02483004. 2020. Available online: https://hal.archives-ouvertes.fr/hal-02483004 (accessed on 29 August 2021).
- Lu, L.; Anderson-Cook, C.M. Strategies for sequential design of experiments and augmentation. Qual. Reliab. Eng. Int. 2020. [Google Scholar] [CrossRef]
- Tharwat, A.; Schenck, W. Balancing Exploration and Exploitation: A novel active learner for imbalanced data. Knowl.-Based Syst. 2020, 210, 106500. [Google Scholar] [CrossRef]
- Sheng, X.; Ma, J.; Xiong, W. Smart Soft Sensor Design with Hierarchical Sampling Strategy of Ensemble Gaussian Process Regression for Fermentation Processes. Sensors 2020, 20, 1957. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, J.; Luo, Z.; Zheng, J.; Jiang, C. Incremental modeling of a new high-order polynomial surrogate model. Appl. Math. Model. 2016, 40, 4681–4699. [Google Scholar] [CrossRef]
- Schrangl, P.; Tkachenko, P.; del Re, L. Iterative Model Identification of Nonlinear Systems of Unknown Structure: Systematic Data-Based Modeling Utilizing Design of Experiments. IEEE Control Syst. Mag. 2020, 40, 26–48. [Google Scholar] [CrossRef]
- Fang, K.T.; Li, R.; Sudjianto, A. Design and Modeling for Computer Experiments; Chapman and Hall/CRC: New York, NY, USA, 2005. [Google Scholar]
- Ji, Y.B.; Alaerts, G.; Xu, C.J.; Hu, Y.Z.; Heyden, Y.V. Sequential uniform designs for fingerprints development of Ginkgo biloba extracts by capillary electrophoresis. J. Chromatogr. A 2006, 1128, 273–281. [Google Scholar] [CrossRef] [PubMed]
- Winker, P.; Fang, K.T. Optimal U—Type Designs. In Monte Carlo and Quasi-Monte Carlo Methods 1996; Springer: New York, NY, USA, 1998; pp. 436–448. [Google Scholar] [CrossRef]
- Pronzato, L.; Müller, W.G. Design of computer experiments: Space filling and beyond. Stat. Comput. 2012, 22, 681–701. [Google Scholar] [CrossRef]
- Guan, S.U.; Liu, J. Incremental Neural Network Training with an Increasing Input Dimension. J. Intell. Syst. 2004, 13, 43–70. [Google Scholar] [CrossRef]
- Bellman, R.E. Adaptive Control Processes; Princeton University Press: Princeton, NJ, USA, 1961. [Google Scholar] [CrossRef]
- Viana, F.A.C. Things you wanted to know about the Latin hypercube design and were afraid to ask. In Proceedings of the 10th World Congress on Structural and Multidisciplinary Optimization, Orlando, FL, USA, 19–24 May 2013; Volume 19. [Google Scholar]
- Ebert, T.; Fischer, T.; Belz, J.; Heinz, T.O.; Kampmann, G.; Nelles, O. Extended Deterministic Local Search Algorithm for Maximin Latin Hypercube Designs. In Proceedings of the IEEE Symposium Series on Computational Intelligence, Cape Town, South Africa, 7–10 December 2015. [Google Scholar]
- Chen, S.; Montgomery, J.; Bolufé-Röhler, A. Measuring the curse of dimensionality and its effects on particle swarm optimization and differential evolution. Appl. Intell. 2014, 42, 514–526. [Google Scholar] [CrossRef]
- Bergmann, D.; Harder, K.; Niemeyer, J.; Graichen, K. Nonlinear MPC of a Heavy-Duty Diesel Engine with Learning Gaussian Process Regression. IEEE Trans. Control. Syst. Technol. 2021, 1–17. [Google Scholar] [CrossRef]
- Goldberg, P.W.; Williams, C.K.I.; Bishop, C.M. Regression with input-dependent noise: A Gaussian process treatment. Adv. Neural Inf. Process. Syst. 1997, 10, 493–499. [Google Scholar]
- Genton, M.G. Classes of kernels for machine learning: A statistics perspective. J. Mach. Learn. Res. 2001, 2, 299–312. [Google Scholar]
- Lowe, D. Radial basis function networks-revisited. Math. Today 2015, 51, 124–126. [Google Scholar]
- Sobol, I.M. On the distribution of points in a cube and the approximate evaluation of integrals. USSR Comput. Math. Math. Phys. 1967, 7, 86–112. [Google Scholar] [CrossRef]
- Friedman, J.H. Multivariate adaptive regression splines. Ann. Stat. 1991, 19, 1–67. [Google Scholar] [CrossRef]
- Dette, H.; Pepelyshev, A. Generalized Latin Hypercube Design for Computer Experiments. Technometrics 2010, 52, 421–429. [Google Scholar] [CrossRef] [Green Version]
- Yue, X.; Wen, Y.; Hunt, J.H.; Shi, J. Active Learning for Gaussian Process Considering Uncertainties with Application to Shape Control of Composite Fuselage. IEEE Trans. Autom. Sci. Eng. 2021, 18, 36–46. [Google Scholar] [CrossRef]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Czitrom, V. One-Factor-at-a-Time versus Designed Experiments. Am. Stat. 1999, 53, 126–131. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Operating | Model | Submodel | ||
|---|---|---|---|---|
| Point | Type | Structure | on Test Data: | on Test Data: |
| Sobol Set | ||||
| Incre- | Polynomial | |||
| mental | Local model tree | |||
| GPR (ILHAD-DP) | ||||
| GPR (ILHAD-NS) | ||||
| Single | Polynomial | |||
| step | Local model tree | |||
| GPR | ||||
| Incre- | Polynomial | |||
| mental | Local model tree | |||
| GPR (ILHAD-DP) | ||||
| GPR (ILHAD-NS) | ||||
| Single | Polynomial | |||
| step | Local model tree | |||
| GPR |
| Test | N | Test | ILHAD-DP | ILHAD-NS | Single Step |
|---|---|---|---|---|---|
| Function | Data | Model: | Model: | GPR Model: | |
| (14) | |||||
| Sobol set | |||||
| Sobol set | |||||
| (15) | |||||
| Sobol set | |||||
| Sobol set |
| Test | Model | Sub- | Length Scales | ||
|---|---|---|---|---|---|
| Function | Type | Model | |||
| (13) | ILHAD- | ||||
| DP | |||||
| ILHAD- | |||||
| NS | |||||
| Single step | |||||
| (14) | ILHAD- | ||||
| DP | |||||
| ILHAD- | |||||
| NS | |||||
| Single step | |||||
| (15) | ILHAD- | ||||
| DP | |||||
| ILHAD- | |||||
| NS | |||||
| Single step | |||||
| Maximal | Noise | ILHAD-DP | ILHAD-NS | Single Step |
|---|---|---|---|---|
| Step | Level | Model: | Model: | GPR Model: |
| 4 | ||||
| 6 | ||||
| 8 | ||||
| Step | Polynomial | Local Model | ILHAD-DP | ILHAD-NS |
|---|---|---|---|---|
| Model: | Tree: | Model: | Model: | |
| RMSE in °C | RMSE in °C | RMSE in °C | RMSE in °C | |
| 1 | 27.62 | 29.69 | 26.44 | 26.44 |
| 2 | 6.37 | 4.63 | 4.83 | 4.81 |
| 3 | 4.32 | 4.07 | 3.02 | 3.29 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Voigt, T.; Kohlhase, M.; Nelles, O. Incremental DoE and Modeling Methodology with Gaussian Process Regression: An Industrially Applicable Approach to Incorporate Expert Knowledge. Mathematics 2021, 9, 2479. https://doi.org/10.3390/math9192479
Voigt T, Kohlhase M, Nelles O. Incremental DoE and Modeling Methodology with Gaussian Process Regression: An Industrially Applicable Approach to Incorporate Expert Knowledge. Mathematics. 2021; 9(19):2479. https://doi.org/10.3390/math9192479
Chicago/Turabian StyleVoigt, Tim, Martin Kohlhase, and Oliver Nelles. 2021. "Incremental DoE and Modeling Methodology with Gaussian Process Regression: An Industrially Applicable Approach to Incorporate Expert Knowledge" Mathematics 9, no. 19: 2479. https://doi.org/10.3390/math9192479
APA StyleVoigt, T., Kohlhase, M., & Nelles, O. (2021). Incremental DoE and Modeling Methodology with Gaussian Process Regression: An Industrially Applicable Approach to Incorporate Expert Knowledge. Mathematics, 9(19), 2479. https://doi.org/10.3390/math9192479