
Distribution Linguistic Fuzzy Group Decision Making Based on Consistency and Consensus Analysis



{kind=link}
Abstract
:1. Introduction
- The consistency of DLFPRs is redefined, and only the probability variation is considered, so the calculation is easier to understand.
- A new iterative algorithm for consistency recognition and adjustment is proposed to improve consistency level to acceptable level.
- A new iterative algorithm for recognition and adjustment of group consensus degree is proposed to improve group consensus degree.
2. Preliminaries
2.1. Linguistic Distribution Term Sets (LDTSs)
- If , then ;
- If , then , especially .
2.2. Distribution Linguistic Fuzzy Preference Relations (DLFPRs)
- ;
- .
3. Consistency-Adjustment Algorithm for DLFPRs
3.1. Multiplicative Consistency of DLFPRs
- (1)
- ;
- (2)
- is DLFPR;
- (3)
- .
- (1)
- For , , we have: , , then . Thus,
- (2)
- For , when , , we can obtain .Thus, is a DLFPR.
- (3)
- For , , we can attest:Then,Thus, we can obtain:Thus, DLFPR is of multiplicative consistency, which finishes the attestation of Theorem 1. □
3.2. Consistency Index of the DLFPR
- ,
- ;
- is a DLFPR of multiplicative consistency if .
3.3. Consistency-Adjustment Algorithm for DLFPRs
| Algorithm 1. Consistency-adjustment process for DLFPRs. |
| Input: The incipient DLFPR , the threshold of consistency and the adjusted parameter . |
| Output: The adjusted DLFPR , which is of acceptable multiplicative consistency. |
| Step 1. Let and . |
| Step 2. According to Theorem 1, let be a DLFPR with multiplicative consistency. |
| Step 3. Given
|
| Step 4. Compare the level of consistency with the threshold, if , then jump to step 8. Otherwise, advance to Step 5. |
| Step 5. Seek the element with the lowest consistency level, where . |
| Step 6. Generate the new DLFPR with and |
| Step 7. Let , then back to Step 2. |
| Step 8. Let . |
| Step 9. End. |
4. Consensus Measures and Consensus Model for DLFPRs
| Algorithm 2. Consensus-adjustment process for DLFPRs. |
| Input: The distribution linguistic information decision-making matrices , the threshold of group consensus index , the adjustment cost of DMs |
| Output: The adapted distribution linguistic information decision-making matrices , which is of acceptable consistency and consensus degree. |
| Step 1. Determine the magnitude of with . If , then jump to Step 5; otherwise, advance to Step 2. |
| Step 2. Seek out the smallest element , which means there is the lowest consensus degree between and , then search for the similarity matrices . |
| Step 3. Based on , looking for the element with the smallest value , which shows and differ the most greatly on the evaluation of alternative in regard to attribute . Then, or need be adjusted. |
| Step 4. Adjust according to the adjustment cost and of DMs and . |
| If , then the LDE should be changed into . |
| If , then the LDE should be changed into . |
| Step 5. Output the new distribution linguistic information decision-making matrices . |
| Step 6. End. |
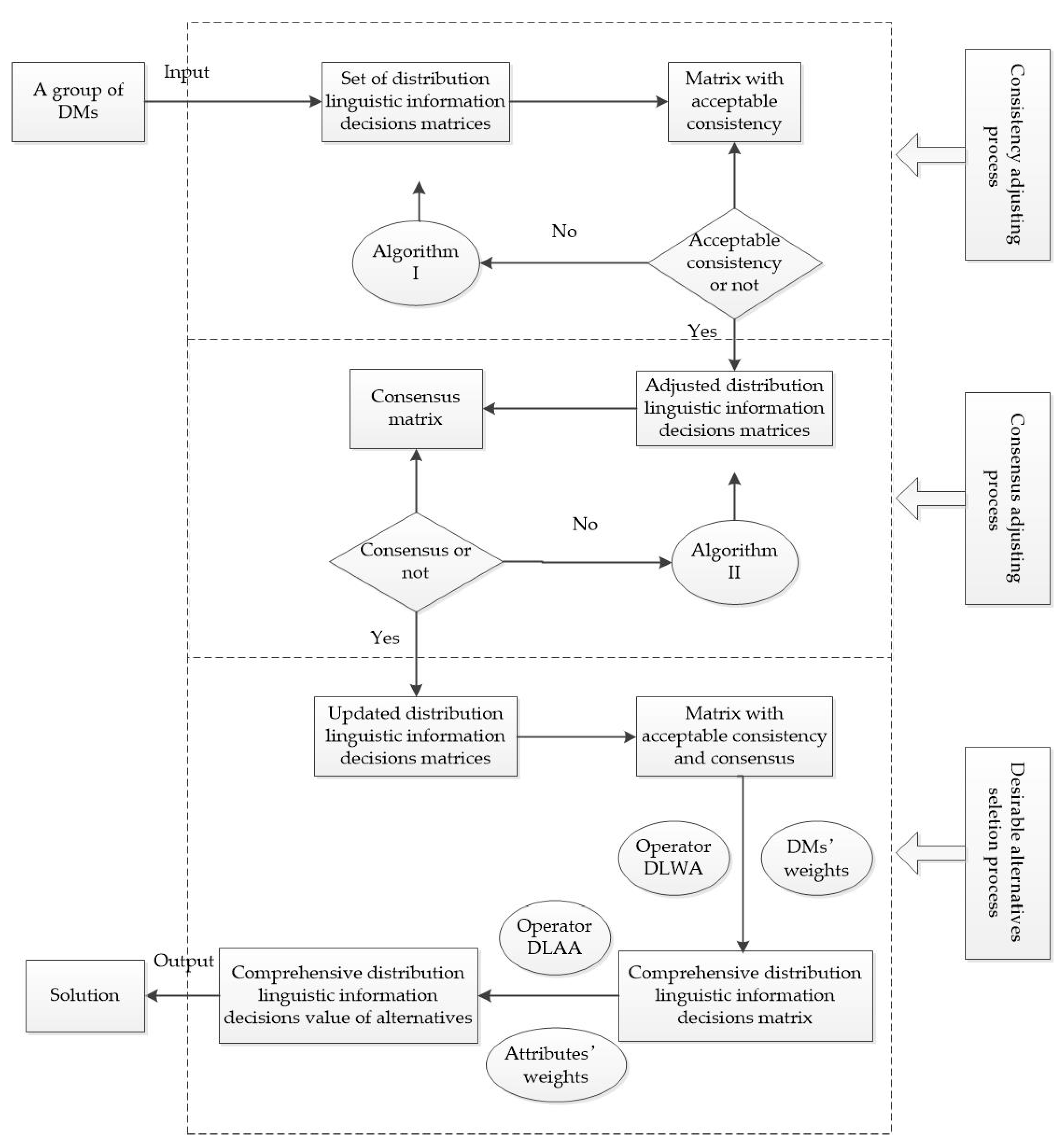
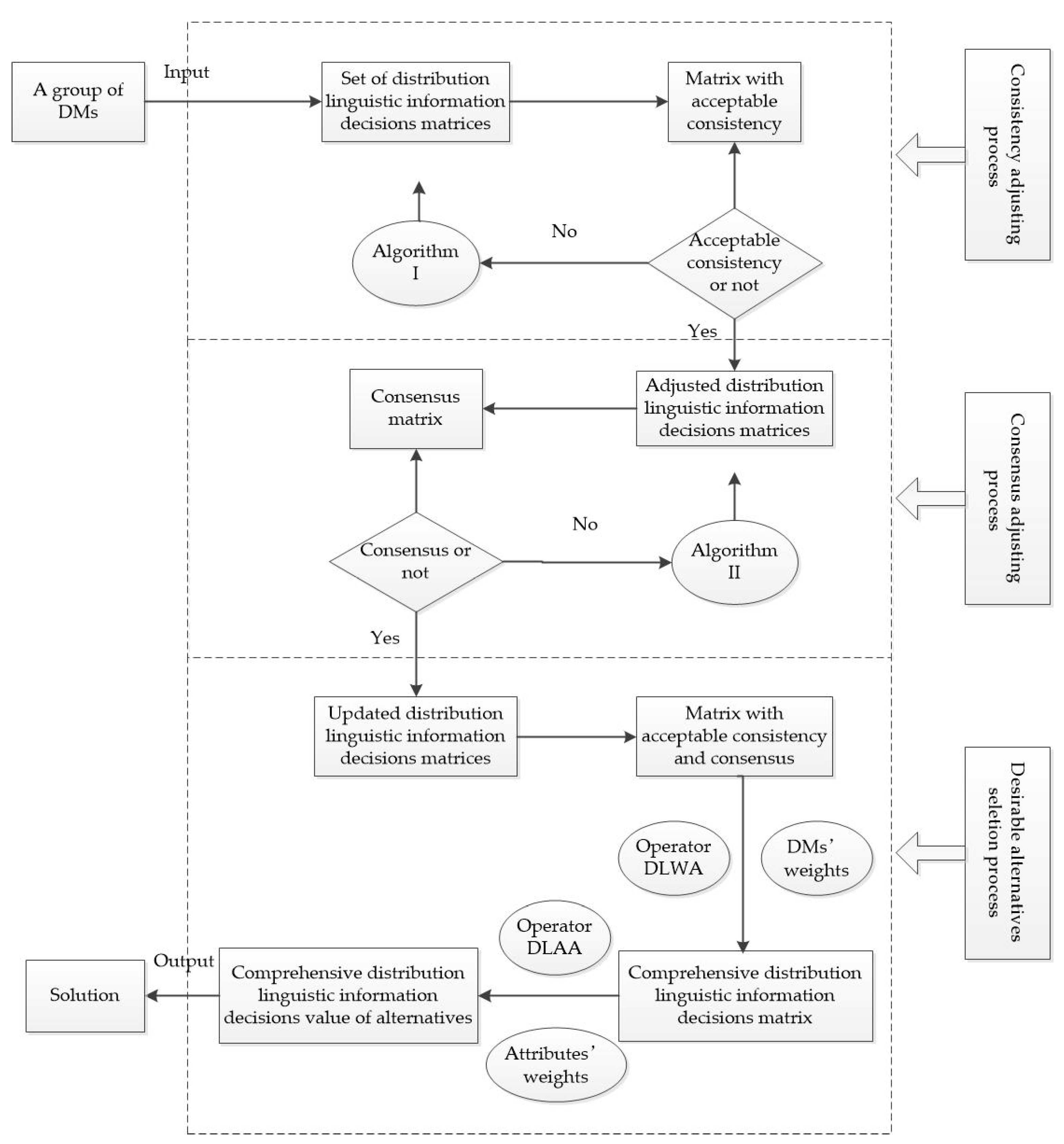
5. Distribution Linguistic Fuzzy GDM (DLFGDM) Method
6. Numerical Examples and Comparative Discussion
6.1. Application to Select the Best Equity Incentive Mode
6.2. Comparative Discussion
6.2.1. Application of the Method in Zhang et al.
6.2.2. Application of the Method in Tang et al.
- It is essential to improve the level of consistency and consensus in GDM. However, Zhang et al. [10] did not check the consistency of the original DLFPRs, but directly carried out the consensus degree test by defining , ignoring the consistency adjustment within the experts, and then directly used the weighted average method to update and adjust, which results in insufficient retention of the original language information of the experts and a large range of changes. Therefore, the developed DLFGDM method includes not only the consistency identification but also the consistency improvement method, so the application of it will be more reliable.
- Compared to the method of Tang et al. [38], our scheme has a different ranking. However, Tang et al. [38] only use the goal programming model based on expected consistency for adjustment, without consensus test and consensus improvement. Due to the influence of subjective and objective factors, the evaluation information proposed by experts may differ greatly, and there may be differences between them. Therefore, the direct application of the established expert weight to the final evaluation ranking may lead to the results being not reliable and lack of rationality. Our DLFGDM method measures and adjusts the consensus degree, and uses the weighted average operator to form a comprehensive consensus matrix to comprehensively deal with the experts’ opinions, which is more reasonable, more reliable and has a wider application prospect.
7. Conclusions
- Based on the new distance formula, a new consistency index is introduced.
- The definition of multiplicative consistency of DLFPR is presented to include only the variation of distributed language evaluation probability. A new consistency adjustment algorithm is proposed, which preserves the original appraisement information as far as possible and adjusts the lowest consistency element each time.
- A new consensus degree and a consensus promotion algorithm are developed by considering the costs of experts.
- Two operators are used to integrate the distribution linguistic elements to derive alternative sorting.
- Without considering the limited knowledge and complex problems in real decision making, the evaluation information may be incomplete.
- The predetermined expert weights and attribute weights remain unchanged, which lacks certain rationality.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, L.L.; Yuan, J.J.; Gao, X.Y.; Jiang, D.W. Public transportation development decision-making under public participation: A large-scale group decision-making method based on fuzzy preference relations. Technol. Forecast Soc. Chang. 2021, 172, 121020. [Google Scholar] [CrossRef]
- Chen, Z.S.; Liu, X.L.; Chin, K.S.; Pedrycz, W.; Tsui, K.L.; Skibniewski, M.J. Online-review analysis based large-scale group decision-making for determining passenger demands and evaluating passenger satisfaction: Case study of high-speed rail system in China. Inf. Fusion. 2021, 69, 22–39. [Google Scholar] [CrossRef]
- Wang, L.J.; Chen, J. Research on Equity incentive decision-making based on Rough set Theory. China Circ. Econ. 2017, 23, 51–52. [Google Scholar]
- Lovsky, S.A. Decision-making with a fuzzy preference relation. Fuzzy Sets Syst. 1978, 1, 155–167. [Google Scholar]
- Liu, C.-H.; Liu, B. Using DANP-mV model to improve the paid training measures for travel agents amid the COVID-19 pandemic. Mathematics 2021, 9, 1924. [Google Scholar] [CrossRef]
- Yager, R.R.; Abbasov, A.M. Pythagorean membership grades, complex numbers, and decision making. Int. J. Intell. Syst. 2013, 28, 436–452. [Google Scholar] [CrossRef]
- Wu, P.; Zhou, L.G.; Zheng, T.; Chen, H.Y. A Fuzzy Group Decision Making and Its Application Based on Compatibility with Multiplicative Trapezoidal Fuzzy Preference Relations. Int. J. Fuzzy Syst. 2017, 19, 683–701. [Google Scholar] [CrossRef]
- Zadeh, L.A. The concept of a linguistic variable and its application to approximate reasoning-I. Inf. Sci. 1975, 8, 199–249. [Google Scholar] [CrossRef]
- Herrera, F.; Martinez, L. A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. Fuzzy Syst. 2000, 8, 746–752. [Google Scholar]
- Zhang, G.Q.; Dong, Y.C.; Xu, Y.F. Consistency and consensus measures for linguistic preference relations based on distribution assessments. Inf. Fus. 2014, 17, 46–55. [Google Scholar] [CrossRef]
- Guo, W.T.; Huynh, V.N.; Sriboonchitta, S. A proportional linguistic distribution based model for multiple attribute decision making under linguistic uncertainty. Ann. Oper. Res. 2017, 256, 305–328. [Google Scholar] [CrossRef]
- Huang, J.; Li, Z.J.; Liu, H.C. New approach for failure mode and effect analysis using linguistic distribution assessments and TODIM method. Reliab. Eng. Syst. Saf. 2017, 167, 302–309. [Google Scholar] [CrossRef]
- Wu, Y.Z.; Li, C.C.; Chen, X.; Dong, Y.C. Group decision making based on linguistic distributions and hesitant assessments: Maximizing the support degree with an accuracy constraint. Inf. Fusion. 2018, 41, 151–160. [Google Scholar] [CrossRef]
- Liang, Y.Y.; Ju, Y.B.; Qin, J.D.; Pedrycz, W. Multi-granular linguistic distribution evidential reasoning method for renewable energy project risk assessment. Inf. Fusion. 2021, 65, 147–164. [Google Scholar] [CrossRef]
- Ju, Y.B.; Liang, Y.Y.; Luis, M.; Gonzalez, E.D.R.S.; Giannakis, M.; Dong, P.W.; Wang, A.H. A new framework for health-care waste disposal alternative selection under multi-granular linguistic distribution assessment environment. Comput. Ind. Eng. 2020, 145, 106489. [Google Scholar] [CrossRef]
- Wang, X.K.; Wang, Y.T.; Zhang, H.Y.; Wang, J.Q.; Li, L.; Goh, M. An asymmetric trapezoidal cloud-based linguistic group decision-making method under unbalanced linguistic distribution assessments. Comput. Ind. Eng. 2021, 160, 107457. [Google Scholar] [CrossRef]
- Dong, Y.; Hong, W.; Xu, Y. Measuring consistency of linguistic preference relations: A 2-tuplelinguistic approach. Soft Comput. 2013, 17, 2117–2130. [Google Scholar] [CrossRef]
- Dong, Y.; Xu, Y.; Li, H. On consistency measures of linguistic preference relations. Eur. J. Oper. Res. 2008, 189, 430–444. [Google Scholar] [CrossRef]
- Jin, F.; Ni, Z.; Chen, H.; Li, Y. Approaches to decision making with linguistic preference relations based on additive consistency. Appl. Soft Comput. 2016, 49, 71–80. [Google Scholar] [CrossRef]
- Jin, F.; Ni, Z.; Pei, L.; Chen, H.; Tao, Z.; Zhu, X.; Ni, L. Approaches to group decision making with linguistic preference relations based on multiplicative consistency. Comput. Ind. Eng. 2017, 114, 69–79. [Google Scholar] [CrossRef]
- Tang, X.A.; Peng, Z.L.; Zhang, Q.; Pedrycz, W.; Yang, S.L. Consistency and consensus-driven models to personalize individual semantics of linguistic terms for supporting group decision making with distribution linguistic preference relations. Knowl. Based. Syst. 2019, 189, 105087. [Google Scholar] [CrossRef]
- Zhao, M.; Ma, X.Y.; Wei, D.W. A method considering and adjusting individual consistency and group consensus for group decision making with incomplete linguistic preference relations. Appl. Soft Comput. 2017, 54, 322–346. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Z.S. Interactive algorithms for improving incomplete linguistic preference relations based on consistency measures. Appl. Soft Comput. 2016, 42, 66–79. [Google Scholar] [CrossRef]
- Cai, M.; Gong, Z.W.; Cao, J. The consistency measures of multi-granularity linguistic group decision making. J. Intell. Fuzzy Syst. 2015, 29, 609–618. [Google Scholar]
- Zhao, S.H.; Dong, Y.C.; Wu, S.Q.; Luis, M. Linguistic scale consistency issues in multi-granularity decision making contexts. Appl. Soft Comput. 2021, 101, 107035. [Google Scholar] [CrossRef]
- Wang, Y.C.; Tsai, H.R.; Chen, T. A selectively fuzzified back propagation network approach for precisely estimating the cycle time range in wafer fabrication. Mathematics 2021, 9, 1430. [Google Scholar] [CrossRef]
- Gong, K.X.; Chen, C.F.; Wei, Y. The consistency improvement of probabilistic linguistic hesitant fuzzy preference relations and their application in venture capital group decision making. J. Intell. Fuzzy Syst. 2019, 37, 2925–2936. [Google Scholar] [CrossRef]
- Gao, J.; Xu, Z.S.; Liang, Z.L.; Liao, H.C. Expected consistency-based emergency decision making with incomplete probabilistic linguistic preference relations. Knowl. Based. Syst. 2019, 176, 15–28. [Google Scholar] [CrossRef]
- Yodmun, S.; Witayakiattilerd, W.; Averbakh, I.L. Stock selection into portfolio by fuzzy quantitative analysis and fuzzy multicriteria decision making. Adv. Oper. Res. 2016. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.W.; Liang, H.M.; Gao, Y.; Zhang, G.Q. The optimization-based aggregation and consensus with minimum-cost in group decision making under incomplete linguistic distribution context. Knowl. Based. Syst. 2018, 162, 92–102. [Google Scholar] [CrossRef]
- Liu, N.N.; He, Y.; Xu, Z.S. A new approach to deal with consistency and consensus issues for hesitant fuzzy linguistic preference relations. Appl. Soft Comput. 2019, 76, 400–415. [Google Scholar] [CrossRef]
- Yao, S.B. A New Distance-based consensus reaching model for multi-attribute group decision-making with linguistic distribution assessments. Int. J. Comput. Int. Syst. 2018, 12, 395–409. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.S.; Zhang, X.; Pedrycz, W.; Wang, X.J.; Martinez, L. K-means clustering for the aggregation of HFLTS possibility distributions: N-two-stage algorithmic paradigm. Knowl. Based. Syst. 2021, 227, 107230. [Google Scholar] [CrossRef]
- Gao, Y.; Li, D.S. A consensus model for heterogeneous multi-attribute group decision making with several attribute sets. Expert Syst. Appl. 2019, 125, 69–80. [Google Scholar] [CrossRef]
- Jin, F.F.; Garg, H.; Pei, L.D.; Liu, J.P.; Chen, H.Y. Multiplicative consistency adjustment model and data envelopment analysis-driven decision-making process with probabilistic hesitant fuzzy preference relations. Int. J. Fuzzy Syst. 2020, 22, 2319–2332. [Google Scholar] [CrossRef]
- Yu, W.Y.; Zhang, Z.; Zhong, Q.Y. Consensus reaching for MAGDM with multi-granular hesitant fuzzy linguistic term sets: A minimum adjustment-based approach. Ann. Oper. Res. 2021, 300, 443–466. [Google Scholar] [CrossRef]
- Wu, T.; Liu, X.W.; Qin, J.D.; Herrera, F. Consensus evolution networks: A consensus reaching tool for managing consensus thresholds in group decision making. Inf. Fusion. 2019, 52, 375–388. [Google Scholar] [CrossRef]
- Tang, X.A.; Zhang, Q.; Peng, Z.L.; Yang, S.L.; Pedrycz, W. Derivation of personalized numerical scales from distribution linguistic preference relations: An expected consistency-based goal programming approach. Neural. Comput. Appl. 2019, 31, 8769–8786. [Google Scholar] [CrossRef]
- Li, C.C.; Dong, Y.C.; Herrera, F.; Herrera-Viedma, E.; Martínez, L. Personalized individual semantics in computing with words for supporting linguistic group decision making: An application on consensus reaching. Inf. Fusion. 2017, 33, 29–40. [Google Scholar] [CrossRef] [Green Version]
- Martínez, L.; Herrera, F. Challenges of computing with words in decision making. Inf. Sci. 2014, 258, 218–219. [Google Scholar] [CrossRef]
- Martínez, L.; Ruan, D.; Herrera, F. Computing with words in decision support systems: An overview on models and applications. Int. J. Comput. Int. Syst. 2010, 3, 382–395. [Google Scholar]
- Liu, J.; Martínez, L.; Wang, H.M.; Rodríguez, R.M.; Novozhilov, V. Computing with words in risk assessment. Int. J. Comput. Int. 2010, 3, 396–419. [Google Scholar]
- Rodríguez, R.M.; Martínez, L.; Herrera, F. Hesitant fuzzy linguistic term sets for decision making. IEEE Trans. Fuzzy Syst. 2012, 20, 109–119. [Google Scholar] [CrossRef]
- Labella, Á.; Liu, H.B.; Rodríguez, R.M.; Martínez, L. A cost consensus metric for consensus reaching processes based on a comprehensive minimum cost model. Eur. J. Oper. Res. 2020, 281, 316–331. [Google Scholar] [CrossRef]
- Romero, Á.L.; Rodríguez, R.M.; Martínez, L. Computing with comparative linguistic expressions and symbolic translation for decision making: ELICIT information. IEEE Trans. Fuzzy Syst. 2020, 28, 2510–2522. [Google Scholar] [CrossRef]
- Zhang, Z.M.; Chen, S.M. Group decision making based on acceptable multiplicative consistency and consensus of hesitant fuzzy linguistic preference relations. Inf. Sci. 2020, 541, 531–550. [Google Scholar] [CrossRef]
- Dong, Y.C.; Xu, Y.F. Consistency measures of linguistic preference relations and its properties in group decision making. Int. Conf. Fuzzy Syst. Knowl. Discov. 2006, 4223, 501–511. [Google Scholar]
- Jin, F.F.; Cao, M.; Liu, J.P.; Luis, M.; Chen, H.Y. Consistency and trust relationship-driven social network group decision-making method with probabilistic linguistic information. Appl. Soft Comput. 2021, 103, 107170. [Google Scholar] [CrossRef]
- Jin, F.F.; Liu, J.P.; Zhou, L.G.; Luis, M. Consensus-based linguistic distribution large-scale group decision making using statistical inference and regret theory. Group Decis. Negot. 2021, 30, 813–845. [Google Scholar] [CrossRef] [PubMed]
- Bai, C.Z.; Zhang, R.; Qian, L.X.; Wu, Y.N. Comparisons of probabilistic linguistic term sets for multi-criteria decision making. Knowl. Based. Syst. 2017, 119, 284–291. [Google Scholar] [CrossRef]
- Pang, Q.; Wang, H.; Xu, Z. Probabilistic linguistic term sets in multi-attribute group decision making. Inf. Sci. 2016, 369, 128–143. [Google Scholar] [CrossRef]
- Gou, X.; Xu, Z. Novel basic operational laws for linguistic terms, hesitant fuzzy linguistic term sets and probabilistic linguistic term sets. Inf. Sci. 2016, 372, 407–427. [Google Scholar] [CrossRef]
- Dong, H.J. On the selection of equity incentive mode in mixed reform of state-owned enterprises. Financ. Superv. 2019, 7, 97–102. [Google Scholar]
- Ben-Arieh, D.; Easton, T.; Evans, B. Minimum cost consensus with quadratic cost functions. IEEE Trans. Syst. Man Cybern. 2009, 39, 210–217. [Google Scholar] [CrossRef]
- Gong, Z.W.; Xu, X.X.; Guo, W.W.; Herrera-Viedma, E.; Cabrerizo, F.J. Minimum cost consensus modelling under various linear uncertain-constrained scenarios. Inf. Fusion. 2021, 66, 1–17. [Google Scholar] [CrossRef]
- Morente-Molinera, J.A.; Pérez, I.J.; Urena, M.R.; Herrera-Viedma, E. On multi-granular fuzzy linguistic modeling in group decision making problems: A systematic review. Knowl. Based. Syst. 2015, 74, 49–60. [Google Scholar] [CrossRef]
- Peng, H.G.; Wang, J.Q.; Zhang, H.Y. Multi-criteria outranking method based on probability distribution with probabilistic linguistic information. Comput. Ind. Eng. 2020, 141, 106318. [Google Scholar] [CrossRef]
- Li, S.L.; Wei, C.P. A large-scale group decision making approach in healthcare service based on sub-group weighting model and hesitant fuzzy linguistic information. Comput. Ind. Eng. 2020, 144, 106444. [Google Scholar] [CrossRef]
- Ren, R.X.; Tang, M.; Liao, H.C. Managing minority opinions in micro-grid planning by a social network analysis-based large scale group decision making method with hesitant fuzzy linguistic information. Knowl Based Syst. 2019, 189, 105060. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jin, F.; Li, C.; Liu, J.; Zhou, L. Distribution Linguistic Fuzzy Group Decision Making Based on Consistency and Consensus Analysis. Mathematics 2021, 9, 2457. https://doi.org/10.3390/math9192457
Jin F, Li C, Liu J, Zhou L. Distribution Linguistic Fuzzy Group Decision Making Based on Consistency and Consensus Analysis. Mathematics. 2021; 9(19):2457. https://doi.org/10.3390/math9192457
Chicago/Turabian StyleJin, Feifei, Chang Li, Jinpei Liu, and Ligang Zhou. 2021. "Distribution Linguistic Fuzzy Group Decision Making Based on Consistency and Consensus Analysis" Mathematics 9, no. 19: 2457. https://doi.org/10.3390/math9192457
APA StyleJin, F., Li, C., Liu, J., & Zhou, L. (2021). Distribution Linguistic Fuzzy Group Decision Making Based on Consistency and Consensus Analysis. Mathematics, 9(19), 2457. https://doi.org/10.3390/math9192457