1. Introduction
The development of continuous-time stochastic volatility models is deemed crucial in the field of modern finance. The attraction of stochastic volatility models mainly resides in their capacity to explain many stylized facts observed in the financial market such as fat tails, the leverage effect and the volatility smile/skew on implied volatility surfaces. See, for example, Hull and White [
1], Stein and Stein [
2], Heston [
3] and Lewis [
4]. In 2017, Grasselli [
5] proposed a new model called the 4/2 stochastic volatility model which embraces the celebrated Heston model and the 3/2 model (Lewis [
4]) as special cases. The superposition of these two parsimonious models makes it possible for the new 4/2 model to better predict the evolution of the implied volatility surface. This leads to emerging interests in applications of Grasselli’s work to derivative pricing problems, such as Cui et al. [
6], Cui et al. [
7] and Zhu and Wang [
8]. In view of the success of the 4/2 model in terms of option pricing, Cheng and Escobar-Anel [
9] recently investigated a utility maximization problem under the 4/2 model. It seems, however, that little attention has been paid to portfolio optimization problems with the 4/2 model under Markowitz [
10]’s mean–variance criterion.
The single-period portfolio selection problem under mean–variance criterion can be traced back to the seminar work of Markowitz [
10]. Li and Ng [
11] and Zhou and Li [
12] generalized Markowitz’s work to multi-period and continuous settings, respectively. In particular, Zhou and Li [
12] applied the standard results on the linear–quadratic stochastic control theory combined with an embedding technique to solve the problem in a financial market where all the market coefficients are deterministic. Many researchers then realized the potential of diversification. For example, Shen et al. [
13] solved the problem under the constant elasticity of the variance model by imposing an exponential integrability condition on the market price of risk. Shen and Zeng [
14] went a step forward by considering the optimal investment–reinsurance problem for a mean–variance insurer in an incomplete market where the market price of risk depends on an affine-form and square-root process, and they derived the modified locally square-integrable optimal strategy. Sun et al. [
15] further extended Shen and Zeng [
14]’s results to the case with multiple risky assets and random liabilities. For other previous works, one can refer to Chiu and Wong [
16], Yu [
17], Lv et al. [
18], Tian et al. [
19], Sun and Guo [
20] and the references therein.
In the aforementioned literature, however, the optimal strategies depend on the initial position of state variables, which is due to the non-separability of the variance operator under mean–variance criterion in the sense of Bellman’s optimality principle. In other words, once the investor arrives at any new position at a future time, the optimal strategy determined at the new position is inconsistent with the initial one unless the investor commits to the initial strategy over the whole investment period. This optimal strategy is therefore time-inconsistent, and is referred to as the pre-commitment strategy in the literature. The notion of time-inconsistency under mean–variance paradigm stemmed from the work of Strotz [
21]. In recent years, the time-inconsistency of the mean–variance portfolio selection problem has received considerable attention. For example, Basak and Chabakauri [
22] determined a time-consistent strategy by using a backward recursion approach starting from the terminal time. Alternatively, Björk et al. [
23] proposed the game theoretical approach and studied the subgame-perfect Nash equilibrium for the mean–variance problem. The equilibrium value function and the equilibrium strategy can be explicitly derived under Markovian settings by essentially solving an extended Hamilton–Jacobi–Bellman (HJB) equation. Rather than searching for the time-consistent equilibrium strategy, Pedersen and Peskir [
24] pioneered the dynamically optimal approach to deal with the time-inconsistency of the statically optimal (pre-commitment) strategy. Along with this approach, previous works include Pedersen and Peskir [
25], Zhang [
26] and the references therein.
According to the law of one price, identical assets must have an identical price. There is, however, ample evidence of violations in the law of one price and of the prevalence of a mispricing phenomenon in the financial market. See, for example, Lamont and Thaler [
27], Liu and Longstaff [
28] and Liu and Timmermann [
29]. This leads to growing interests in portfolio optimization problems with mispricing in recent years. Yi et al. [
30] studied a utility maximization problem with model ambiguity and mispricing in a financial market consisting of a risk-free asset, a market index, and a pair of mispricing stocks with the constant return rate and volatility. Ma et al. [
31] considered a problem for a defined contribution plan with mispricing under the Heston model. Considering the methodology developed by Björk et al. [
23] to deal with the time inconsistency under mean–variance paradigm, Wang et al. [
32] investigated a mean–variance investment–reinsurance problem with mispricing in the context of constant volatility. Other preceding research outputs on the portfolio optimization problems with mispricing include Gu, Viens and Yi [
33], Gu, Viens and Yao [
34], Wang et al. [
35], to name but only a few.
Motivated by the above aspects, within the framework introduced by Pedersen and Peskir [
24] to overcome the time inconsistency under mean–variance criterion, in this paper we study a mean–variance portfolio selection problem that takes into consideration the family of 4/2 stochastic volatility models and mispricing simultaneously. The financial market consists of a risk-free asset, a market index and a pair of mispriced stocks. To solve this problem, we first apply the Lagrange multiplier method to relate the original problem to an unconstrained optimization problem. To solve the latter by using the dynamic programming approach, we establish the corresponding HJB equation. By solving the HJB equation explicitly, closed-form expressions of the statically optimal strategy and the corresponding optimal value function are derived. Based on an assumption on the model parameters combined with the investment horizon, we prove the necessary verification theorem from scratch and verify the admissibility of the optimal strategy. By solving the statically optimal strategy each time, the dynamically optimal strategy is explicitly derived. This time-consistent strategy keeps the wealth process strictly below the target (expected terminal wealth) before the terminal time. Moreover, we provide the results without mispricing and consider the special cases under the Heston and the 3/2 models. Finally, we present some numerical examples to illustrate the effects of some model parameters on the efficient frontier and the difference between static and dynamic optimality. In summary, compared with some related current research studies, the main contributions of this paper are as follows:
The market model incorporates the 4/2 model and mispricing simultaneously;
By making an assumption on the model parameters, a verification theorem is provided to guarantee that the candidate solution to the HJB equation is the optimal value function, and the admissibility of the optimal strategy is verified;
We derive both the statically optimal (pre-commitment) and the dynamically optimal (time-consistent) strategies explicitly for the mean–variance problem.
The remainder of this paper is structured as follows. In
Section 2, we formulate the market model and the mean–variance portfolio problem.
Section 3 is devoted to solving the HJB equation and deriving the closed-form expression of the optimal investment strategy of the unconstrained problem. In
Section 4, we present the statically optimal strategy and the dynamically optimal strategy for the mean–variance problem, and provide the results on some special cases. In
Section 5, some numerical examples are given to illustrate our theoretical results.
Section 6 concludes the paper.
2. Formulation of the Problem
Let be a fixed terminal time of decision making and be a complete probability space carrying five one-dimensional, mutually independent standard Brownian motions . The probability space is further equipped with a right-continuous, -complete filtration generated by the Brownian motions.
We consider a financial market setting where a risk-free asset, a market index, and a pair of stocks with mispricing can be continuously traded. The risk-free asset price
evolves over time as:
with the initial value
at time
, where the positive constant
is the risk-free interest rate. Let the price dynamic of the market index
be governed by the 4/2 stochastic volatility model (Grasselli [
5]):
with
and
at time
, where the constant
stands for a controller of the excess return, and the variance process
follows a Cox–Ingersoll–Ross (CIR) process with mean-reversion speed
, long-term mean
and volatility of volatility
. The Feller condition
is required such that
is strictly positive. We assume that two parameters
and
are non-negative constants and
.
Remark 1. It should be noted that the two non-negative constants and are critical in the 4/2 model (1), which makes the 4/2 model a superposition of the Heston model (Heston [3]) and the 3/2 model (Lewis [4]). Specifically, the case is known as the Heston model, while the case corresponds to the 3/2 model. The two mispriced processes are modeled as a pair of stocks
and
which are coupled via the pricing error:
where
and
evolve according to the following system of stochastic differential equations (SDEs):
with initial values
and
at time
, where
and
b are constant parameters. The term
characterizes the systematic risk of the market, while
stands for the idiosyncratic risk of stock
i,
. In particular,
describes the common risk whereas
represents the individual risk generated by the stock
i,
, respectively. The term
reveals the effect of mispricing on
ith stock’s price via the pricing error
defined above. Moreover, it can be shown that the pricing error
follows an Ornstein–Uhlenbeck (OU) process as a result of Itô’s formula:
with
, where two constant parameters
and
can be explained as liquidity terms which control the mean-reversion rate of the pricing error. To be specific, the lower liquidity decreases the velocity of reversion of the pricing error towards the long-term mean of zero. Following some previous studies, such as Liu and Timmermann [
29], Ma et al. [
31] and Wang et al. [
32], we hereby assume that
, which ensures the stability of the financial market.
Let
,
be three Markov controls denoting the proportions of wealth invested in the market index
, and the pair of stocks
and
at time
t, respectively. We write
and such deterministic functions
are referred to as feedback control laws in the literature. Suppose that the market is frictionless and no restrictions on leverage and short-selling are enforced, the investor decides to construct a self-financing portfolio of
and
over the investment period
. So the controlled wealth process
is described by the following system of SDEs:
with
, where we write
to simplify our notation. Let
denote the probability measure with the initial value
at time
. Accordingly,
and
denote the associated expectation and variance under the probability measure
, respectively.
Definition 1 (Admissible strategy). Given any fixed , a strategy π is said to be admissible if for any , it holds that:
- 1.
,
- 2.
,
- 3.
.
The set of all admissible strategies is denoted by .
The investor wishes to determine an admissible strategy solving the following mean–variance portfolio problem.
Definition 2. The mean–variance portfolio problem is a stochastic optimization problem denoted bywhere ξ is a fixed and given constant serving as a target. We denote the corresponding optimal value function by . Remark 2. Here, we impose , which precludes the trivial case when the investor simply takes the risk-free strategy over the investment period . This condition is consistent with some previous studies, such as Shen et al. [13], Sun and Guo [20] and Sun et al. [15]. As discussed in the Introduction, the mean–variance problem (
5) is time-inconsistent due to the presence of the variance operator in the mean–variance objective. We take the dynamically optimal approach as championed by Pedersen and Peskir [
24] to address the problem of time-inconsistency. For readers’ convenience, we adapted the definition of the dynamic optimality (Definition 2 in Pedersen and Peskir [
24]) into the current context.
Definition 3 (
Dynamic optimality).
A control is said to be dynamically optimal in mean–variance portfolio problem (5) for given and fixed, if for every given and fixed and every strategy such that with , there exists a control w satisfying , with such that Upon considering the nature of the dynamically optimal approach, as discussed in the Introduction, we shall first pay attention to the static optimality (pre-commitment) for the mean–variance problem (
5).
Due to the convexity of the objective function in the problem (
5), we can deal with the linear constraint
by introducing a Lagrange multiplier
. The associated (dual) Lagrangian is formulated as follows:
According to the Lagrangian duality theorem (Luenberger [
36]), the mean–variance problem (
5) is, in fact, equivalent to the following min–max stochastic optimization problem:
This suggests that two steps are involved to obtain the static optimality of the mean–variance problem (
5). First of all, we should solve the internal unconstrained stochastic optimization problem with regard to
with
fixed and given. Subsequently, we turn to optimize Lagrange multiplier
in the external static problem. Hence, we are supposed to determine the optimal strategy of the following quadratic-loss minimization problem in the first place:
with
fixed and given.
3. Solution to the Unconstrained Problem
In this section, we devote to solving the unconstrained quadratic-loss minimization problem (
8) by using the dynamic programming approach. For this, we first define the optimal value function as
where
is short for
at time
. For the function
, it must satisfy the following HJB equation due to dynamic programming principle:
where we denote
as the following differential operator:
for
, with the boundary condition
. Then, the first-order minimization condition yields the optimal control:
Inserting (
11) into the HJB Equation (
10) and simplifying the expression, we obtain the following second-order partial differential Equation (PDE) for function
H:
In the next proposition, we shall construct an explicit solution denoted by
to PDE (
12).
Proposition 1. One solution to second-order PDE (12) isand the optimal feedback control is given bywherewithandwith . Proof. We propose a candidate solution to the second-order PDE (
12) in the following form:
with
and
. Then, we have the following partial derivatives:
Substituting (
19) into (
12) and reshuffling terms yield
This indicates that we have the following two identities:
and
Upon considering the boundary condition
, we obtain the following expression of
by solving (
20):
As for (
21), we can separate it with respect to variables
v and
as follows:
Thus, we have the following system of ordinary differential equations (ODEs) from (
22) due to the arbitrariness of
and
:
We see that both (
23) and (24) are Riccati ODEs, and once these two equations are solved, the explicit expression of solution
to (25) can be immediately derived.
In the following, we first solve Equation (
23) of
. When
and
, we have
When
and
, Riccati ODE (
23) is reduced to the following linear ODE:
Integrating both sides of (
26) with respect to time
t yields
When
, we set
as given in (
17) above. If
, we can rewrite (
23) as follows:
where
and
are given by (
17). Upon considering the boundary condition
, we find
If
, then (
27) can be simplified to
where
is given in (
17) above. Integrating both sides of (
28) with respect to time
t upon considering the boundary condition
, we obtain
If
, then (
23) can reformulated as follows:
After calculations upon considering the boundary condition
, we find
Then, we pay attention to the ODE (24) of
. Considering
we can rearrange the terms in (24) to have the following formulation:
After some calculations, upon considering the boundary condition
, we have
Finally, a direct integral calculation on both sides of (25) upon considering the boundary condition
yields (
15). □
The following proposition presents strict monotonicity results of and with respect to time t, which in turn leads to the non-positiveness of and over .
Proposition 2. Functions and given by (16) and (18), respectively, are strictly increasing with respect to time t, and thus non-positive over . Proof. By differentiating
given in (16) with respect to
t, we obtain
It is obvious that holds for the first three cases. As for the fourth and the fifth cases, note that when , we must have .
Similarly, a direct differentiation of
given in (
18) leads to
Finally, upon considering the boundary condition , we can conclude that and are non-positive over . □
To facilitate further discussions, we now present some auxiliary results on the OU process and the CIR process in the literature. The first lemma (Lemma 1) is adapted from Lemma 4.3 in Benth and Karlsen [
37].
Lemma 1. Consider the OU process in (3). If ε is a constant such thatthen we have The second lemma (Lemma 2) follows from Theorem 5.1 in Zeng and Taksar [
38].
Lemma 2. Consider the CIR process in (1). We have Inspired by the above results, throughout the rest of paper, we impose the following assumption on the model parameters and the investment horizon :
Assumption 1. The model parameters and the investment horizon satisfy:whereand Remark 3. It follows from Proposition 2 above that as , we have , which indicates the feasibility of the assumption on . As for the assumption on , it is straightforward to have and are decreasing and increasing with respect to T, respectively. This means when the investment horizon is small enough, the assumption on is well established as well.
We next define four Doléans–Dade exponential processes
and
as follows:
We shall study the integrability of and which will be used in the proof of Theorem 1 below.
Lemma 3. Suppose that Assumption 1 holds. Then, and satisfy Proof. Let
be any given constant. Then, the following equation of
k
admits two positive roots:
with the first root satisfying
. In particular, when
, we have
. From Assumption 1, we have
According to Theorem 15.4.6 in Cohen and Elliott [
39], we then find that
satisfies
By applying the same technique to
and
, it is straightforward to obtain (
31) due to Assumption 1. So we omit the details here. □
To end this section, we shall prove a verification theorem from scratch which guarantees that the candidate solution
derived in (
13) coincides with the optimal value function
defined in (
9) to the quadratic-loss minimization problem (
8). Furthermore, we will also prove the admissibility of the optimal strategy obtained in (
14) in the sense of Definition 1.
Theorem 1 (
Verification theorem).
Suppose that Assumption 1 holds. Then, the optimal strategy given in (14) for the problem (8) is admissible, and the optimal controlled wealth process evolves asfor , with given and fixed such that , where processes , and are given in (30). Moreover, we havefor any . In particular, the optimal value function of problem (8) is given bywith , and given by (15), (16), and (18), respectively. Proof. In the following, we will finish the proof with two steps. At step 1, we show that the optimal strategy
given in (
14) is admissible. At step 2, we verify that the candidate solution
G given in (
13) is indeed the optimal value function
H defined in (
9).
Step
Substituting the optimal strategy (
14) into the controlled wealth process (
4) leads to
with
. Applying Itô’s lemma to
, we have
with
. By explicitly solving the linear SDE of
, we then have the following closed-form expression:
where
and
are defined in (
30) above. This in turn shows the optimal controlled wealth process
given by (
32). We now proceed to show that the optimal strategy
given in (
14) is admissible. To this end, we first show that
Indeed, from the expression of
given in (
32), we have
where the positive constant
K might differ between lines, the second inequality makes use of Jensen’s inequality and the non-positiveness of functions
and
from Proposition 2, and the last strictly inequality is due to Assumption 1 on
and Lemma 1. This in turn leads to the establishment of Condition 3 in Definition 1 by Jensen’s inequality. Then, we show that Condition 1 in Definition 1 is satisfied:
Indeed, in view of the expression of
given in (
14), we obtain
where
K is a positive constant, and the last strict inequality follows from (
34) as well as the fact that the CIR process
has a finite second moment at time
, which is continuous in time
t (see, for example, Cox et al. [
40]). Recalling that
given in (
3) is an OU process, we can write the solution explicitly:
where
is
Brownian motion due to Lévy’s characterization of Brownian motion. Then, upon noticing that
is normally distributed with mean zero and variance
, we find that
where
is a positive constant. Therefore, in view of the expressions of
and
given in (
14), we find that Condition 2 in Definition 1 holds as well:
where
K is a positive constant. Using the same technique, we also have
The above results show that the optimal strategy (
14)
and completes the first part of the proof.
Step
Applying Itô’s lemma to the candidate solution
G given in (
13) of the HJB Equation (
10) for any admissible strategy
, we have
Due to the pathwise continuity of
, all the stochastic integrals on the right-hand side of (
35) are clearly continuous local martingales under measure
. Then, there exists a sequence of stopping times localizing all the local martingales (see, for example, page 76 in Le Gall [
41]). We therefore denote the associated localizing sequence by
such that
almost surely as
. Similar to the preceding definition of the probability measure
, we let
denote the probability measure with initial data
given and fixed at time
. Thus, integrating both sides of (
35) from
t to
and taking expectation lead to
From the expression of candidate function
G given in (
13), we find
where
K is a positive constant independent of
V and
, and the inequality makes use of the non-positiveness of functions
and
over
from Proposition 2. On the one hand, we notice that
is
integrable for any admissible strategy
. On the other hand, since candidate function
G given in (
13) satisfies the HJB Equation (
10), then we must have
,
almost surely for all
. Hence, passing to the limit in (
36) and applying Lebesgue’s dominated convergence theorem to the left-hand side and the monotone convergence theorem to the right-hand side of (
36), respectively, we obtain
which implies that, for any admissible strategy
, we have
with any
fixed and given. Meanwhile, from Proposition 1 above, we know:
with admissible strategy
given by (
14), which means
Combining these two results, we can finally conclude that the candidate solution
G coincides with the optimal value function
H, i.e.,
for any
fixed and given. In particular, the optimal value function of the quadratic-loss minimization problem (
8) is given by (
33). □
4. Static and Dynamic Optimality of the Problem
In this section, we derive the statically optimal strategy and the dynamically optimal strategy of the mean–variance portfolio problem (
5) by utilizing the preceding results. As a matter of fact, in view of (
6) and (
7) above, we now only need to solve the following static optimization problem with respect to the Lagrange multiplier
to obtain the static optimality and the corresponding optimal value function for the mean–variance problem (
5)
Reformulating (
39) as a quadratic functional over
, we find that the optimal value function of the mean–variance problem (
5) can be obtained from
if the coefficient of the quadratic term is strictly negative. Indeed, upon noticing that
given in (
14) is the unique optimal strategy for the quadratic loss minimization problem (
8), we must have
where:
stands for the risk-free strategy over the period
. This implies that the quadratic coefficient of
in (
40) is strictly negative as desired. Therefore, the maximum to the right-hand side of (
40) is uniquely attained at
Theorem 2. Suppose that Assumption 1 holds. For any initial data given and fixed such that , the statically optimal strategy of the mean–variance portfolio problem (5) is given byfor , and the corresponding optimal value function iswhere , and are given in (15), (16), and (18), respectively, and is given by (41). The controlled wealth process is given bywhere processes , and are given in (30). Moreover, the statically optimal strategy given by (42) is admissible, i.e., . Proof. Substituting
given by (
41) into (
40) leads to the optimal value function (
43). Replacing
in (
14) and (
32) with
gives the statically optimal strategy (
42) and the statically optimal controlled wealth process (
44), respectively. Following the proof in Theorem 1 above, it is obvious to see that the statically optimal strategy
. □
Remark 4. If we set either or in (42), then we obtain explicit solutions to the mean–variance problem with mispricing under the Heston model and the 3/2 model, respectively. Corollary 1. (No mispricing under the 4/2 model). Suppose that Assumption 1 holds. For any initial data given and fixed such that , the statically optimal strategy of the mean–variance portfolio problem (5) without mispricing is given byfor . The corresponding optimal value function iswhere is given in (16) and is given byand is given byThe controlled wealth process is given bywith given in (30). Moreover, the optimal strategy given in (45) is admissible, i.e., . Proof. If there is no mispricing in the market, then
, which reveals that
and
due to (
11). Moreover, since
m vanishes from the HJB Equation (
10) in this case, then
disappears as well. This in turn leads to (
45)–(
49) following from (
15), (
41)–(
44), respectively. □
As discussed in
Section 2, the statically optimal strategy
in Theorem 2 relies on the initial position of state variables
. We will now proceed to derive the dynamically optimal strategy under the framework developed by Pedersen and Peskir [
24].
Theorem 3. Suppose that Assumption 1 holds. For any initial data given and fixed such that , the dynamically optimal strategy of the mean–variance portfolio problem (5) is given byfor . The controlled wealth process evolves over time aswith for , where processes , and are given byand the help function is given bywith , and given in (15), (16), and (18), respectively. Proof. We start with identifying
with
t,
with
x,
with
v and
with
m in (
42). This leads to the following candidate:
We next show that this candidate
(
54) is dynamically optimal in the mean–variance portfolio problem (
5). To this end, we first take any other admissible strategy
such that
with
. Then, set
under the measure
. Replacing
with
in (
42), we see from (
42) that
, and thus
for any
. Due to the continuity of functions
u and
w, there exists a ball
such that
for
when
is small enough such that
. Therefore, since
is the unique continuous function such that the infimum within the HJB Equation (
10) is attained for any
, then we can set the exiting time
such that for
, it holds that
where
is a fixed positive constant. Replacing
by
in the boundary condition of the HJB Equation (
10) with
given by
it follows from (
38) with
in place of
that
where the strict inequality follows from the fact that
, since the triple
has continuous sample paths with probability one under
measure. From (
55), we then have
This shows that the candidate
proposed in (
54) is the dynamically optimal strategy for mean–variance portfolio problem (
5).
Substitute
into (
4) and denote the corresponding wealth process by
. Applying Itô’s lemma to
yields
where the help function
f is defined in (
53). Solving this linear SDE (
56) of
explicitly, we obtain the closed-form expression of
given in (
51). Moreover, it is easy to see that the initial value
leads to
for
. □
Corollary 2. (No mispricing under the 4/2 model). Suppose that the Assumption 1 holds. For any initial data given and fixed such that , the dynamically optimal strategy of the mean–variance portfolio problem (5) without mispricing is given byfor . The controlled wealth process evolves as:with for , where the help function is given bywith and are given in (47) and (16), respectively. Proof. The results follow from Corollary 1 and Theorem 3 directly. □
Remark 5. If we specify in Corollary 2, then we have the dynamically optimal strategy under the Heston model without mispricing; if we choose instead, then the results in Corollary 2 correspond to the ones under the 3/2 model without mispricing.
5. Numerical Examples
This section presents some numerical results to illustrate the theoretical results derived in the previous section. Throughout this section, unless stated otherwise, we consider the following market parameter setting adapted from Cheng and Escobar-Anel [
9] and Ma et al. [
31]:
.
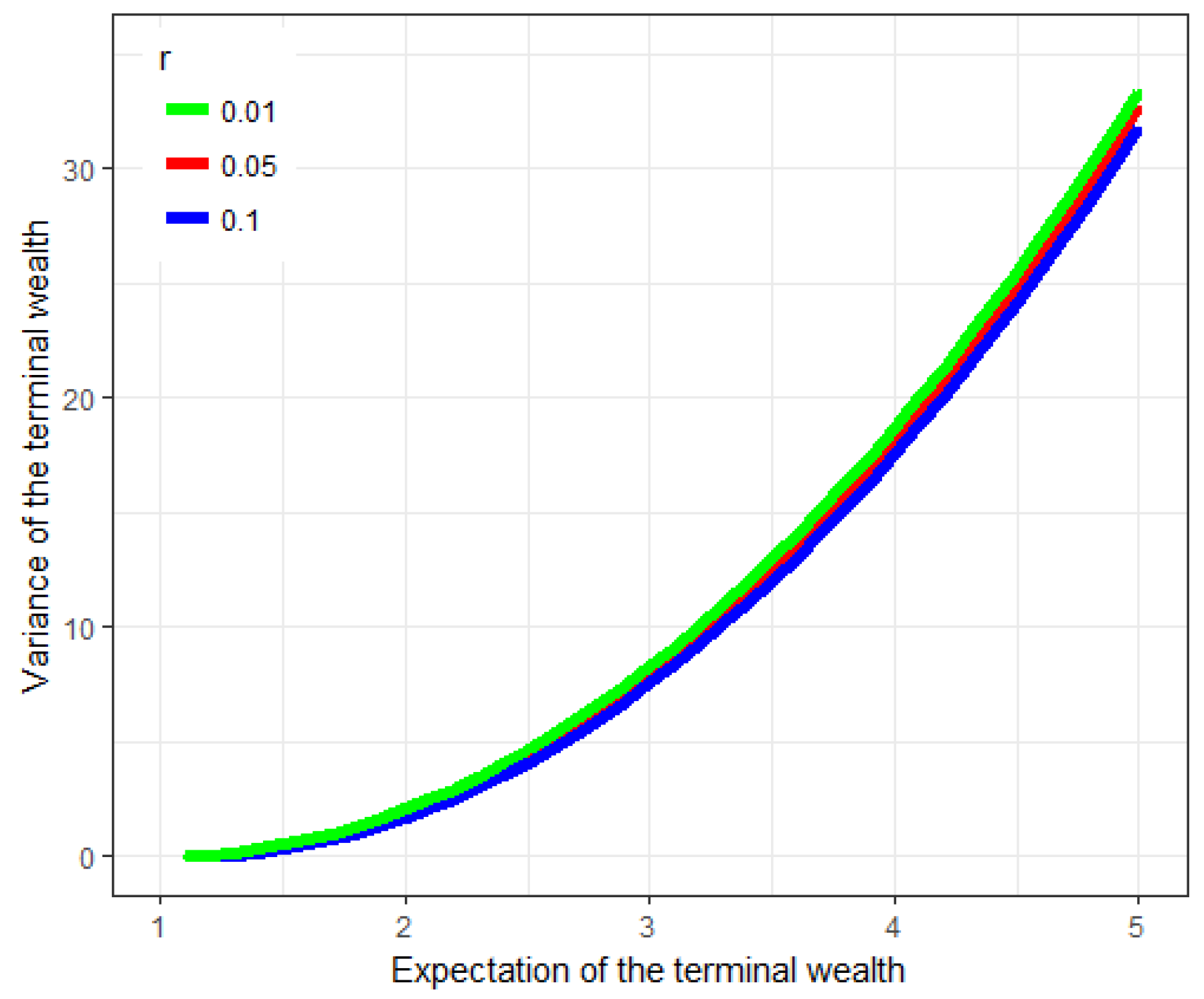
Figure 1 and
Figure 2 below display the effects of
r and
on the efficient frontier, respectively. As a matter of fact, when the interest rate
r increases, the investor can obtain more expected return by investing in the risk-free asset, and thus undertake less risk. Meanwhile, from the economic implications of
, the investor can obtain a higher risk premium of
as
increases. This leads to a lower value of
when the same
is asked for.
Figure 3 contributes to the evolution of the efficient frontier with respect to
. When we vary
from
to
, the efficient frontier moves downwards. One possible explanation is that since
partially characterizes the liquidity term, then as
increases, the pricing error
in (
3) has a faster mean-reversion rate towards the long-term zero such that the investor can bear less risk coming out of the pricing error between
and
.
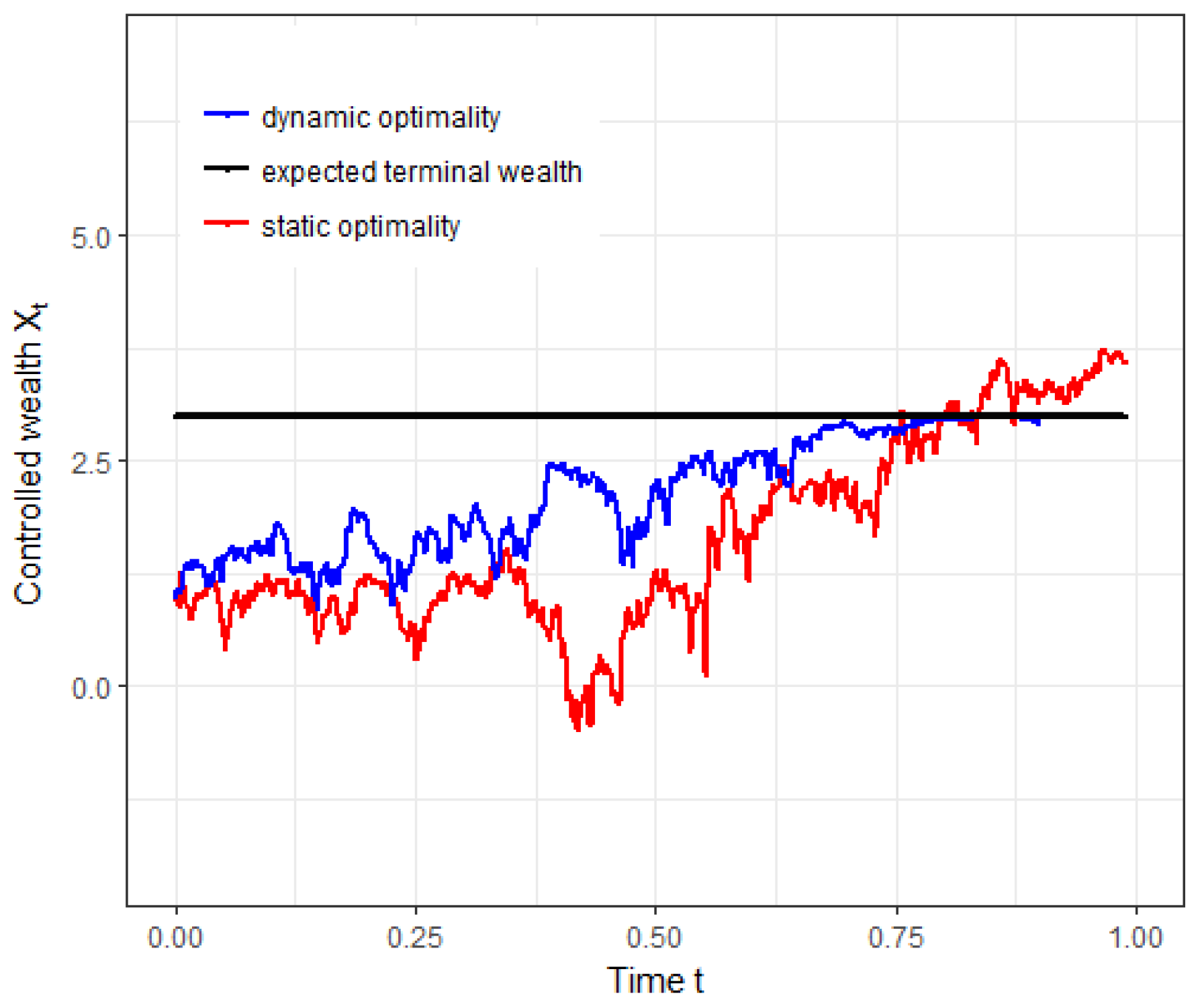
We finally give a simulation experiment to illustrate the difference between the dynamics of
and
. As shown in
Figure 4 below, two optimal wealth processes have significantly different trajectories while using the same random numbers. Particularly, we observe that the dynamically optimal wealth process
is strictly below the expected terminal wealth
when
in this case, which is consistent with the conclusion derived in Theorem 3 above.



{kind=link}
{kind=link}
{kind=link}
{kind=link}