1. Introduction
The world is currently experiencing a pandemic caused by the novel coronavirus, formally named COVID-19 by the World Health Organization (WHO). Development of a vaccine and antiviral drugs to treat COVID-19 is still ongoing, resulting in hospitalization and intensive care unit management as the only option in treating COVID-19. Thus, there is a dire need for research on modeling the outbreak of COVID-19 to help officials in their decision-making processes regarding interventions and allocation of resources [
1]. At the time this manuscript was being written, the pandemic was ongoing, and most of the epidemiological models developed focused on short-term predictions, identifying the daily peak of COVID-19 cases, predicting the duration of the pandemic, and estimating the possible impact of the measures implemented for minimizing exposure to the virus and decrease the fatality rate [
2,
3,
4,
5,
6,
7,
8,
9,
10].
As of 24 September 2020, the cumulative number of COVID-19 cases in Mexico was reported as 715,457 [
5], and 32,245,122 cases were reported worldwide [
11]. Thus, the main objective of this paper was to model the total number of COVID-19 cases per day at the national and the state level in Mexico while simultaneously providing straightforward information to decisionmakers; additionally, we sought to determine which model provides the most stable short-term predictions.
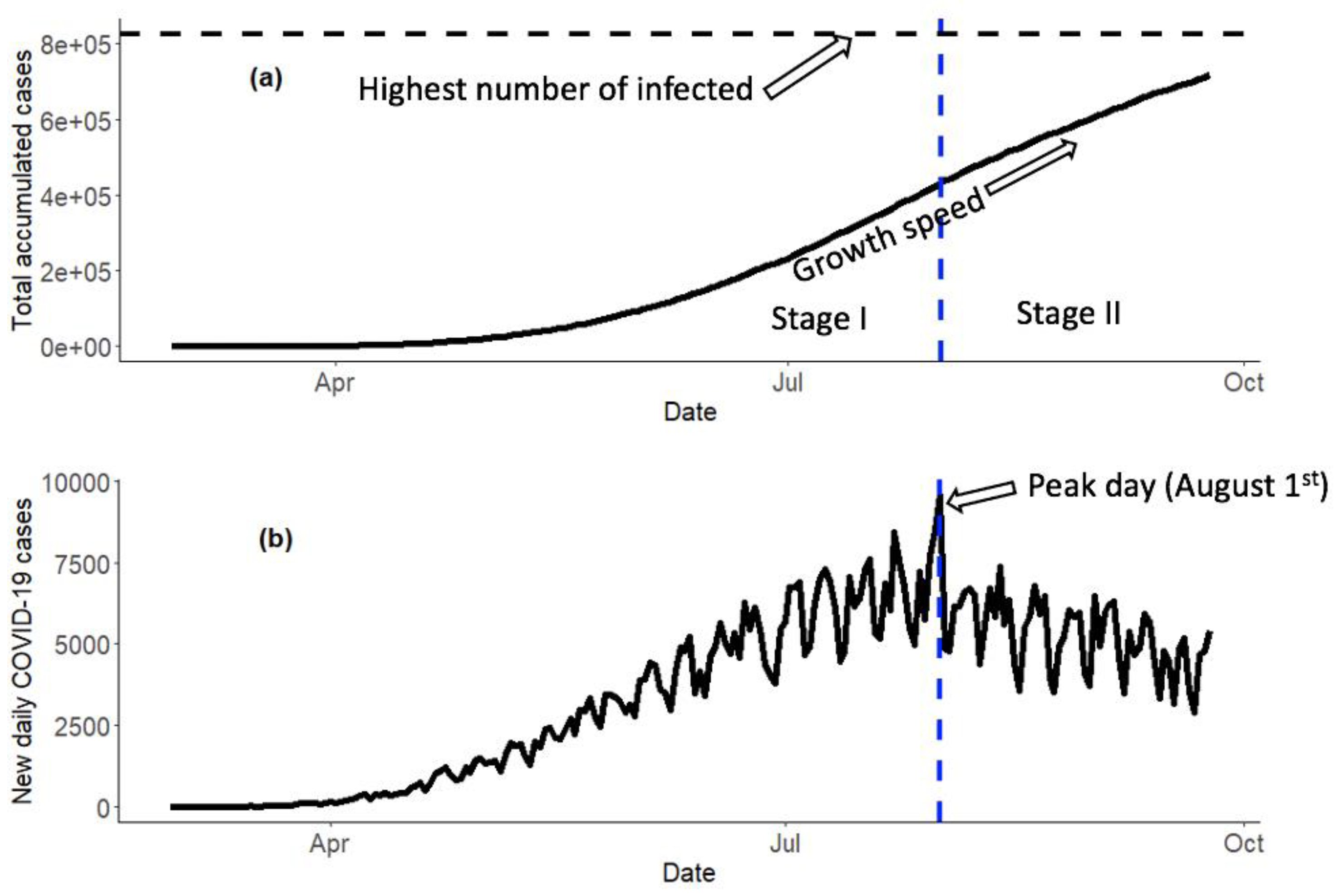
Figure 1 shows the accumulated cases and new cases at the national level in Mexico. This figure shows the first wave peak of the pandemic until the data cut-off of 24 September. Until the 24 September date, only a single wave of infections had been observed (on 1 August). The models developed in this research facilitate the obtaining of information to support decisionmakers in the strategic planning activities of the Mexican states, metropolitan areas, municipalities, or cities with high population density. Mexican officials can use these models to aid in the management process involving the needs and resources of the health services such as available hospital beds, intensive care units, and respirators, as well as personal protective equipment (PPE) for health personnel. For decisionmakers, such as public health officials, having access to daily and permanent monitoring at the center of the pandemic allows them to anticipate the purchase of the necessary medical equipment in advance. Further, the authors would like to share these models so that officials and statisticians outside of Mexico can make use of them for their own decision-making procedures during the length of the COVID-19 pandemic. The proposed methodology in this paper can easily be applied to COVID-19 worldwide.
In this work we refer to 1–2–3 models as two-step models due to the method used to estimate their parameters [
12]. The method is performed in two steps that will combine information from time series models with non-linear growth models and polynomial models. The two-step estimation is a process, also known as the Cochrane–Orcutt procedure, which is defined as:
“A two-step estimation of a linear regression model with first-order serial correlation in the errors. In the first step the first-order autocorrelation coefficient is estimated using the ordinary least squares residuals from the main regression equation. In the second step this estimate is used to rescale the variables so that the regression in terms of rescaled variables has no serial correlation in the errors. This is an example of feasible generalized least squares estimation” [
13].
Several machine learning (ML) and artificial intelligence (AI) models have demonstrated acceptable performance in the modeling of the COVID-19 pandemic; our proposed methodology meets this expectation in addition to a simple estimation of the parameters. Unlike the susceptible–infected–recovered–deceased (SIRD) models, the proposed models do not require setting or assuming the value of any parameter to obtain the estimates [
14,
15]. Finally, another advantage of our models is the interpretability of their parameters, that is, estimates of some parameters directly linked to the pandemic can be obtained.
The article is structured as follows: In
Section 2, we summarize the most relevant literature regarding the modeling of the COVID-19 pandemic. Next, in
Section 3, the data used are presented and the proposed methodology is described.
Section 4 shows the main results of the investigation. Finally, in
Section 5, the main conclusions are presented, and the limitations of this research are discussed.
2. Literature Review
Research exists with data-driven approaches such as autoregressive (AR) and autoregressive integrated moving average (ARIMA), ranging from simple models (exponential smoothing) to more complex models such as ARIMAX, ARCH, GARCH, and ARFIRMA [
2,
7,
8,
10,
16,
17]. For example, we used an ARIMA model with data compiled by Johns Hopkins University to predict models for the daily confirmed cases in countries where the pandemic was peaking and to predict and anticipate the resources of the healthcare systems [
18]. Unfortunately, these data-driven models fail to fit the data and often lack accuracy [
6,
19]. Additionally, the parameters of these models cannot be interpreted according to the reality of the pandemic. This interpretability barrier causes statisticians and officials to make their decisions on the basis of predictive models instead of the peak of the pandemic or the growth of the pandemic. A useful model for policy and public health decisionmakers during the COVID-19 pandemic would be a model that, in addition to obtaining accurate predictions, provides insights on the evolution or current behavior of the pandemic. Another approach is real-time forecasting using a generalized logistic growth model. This method has been previously used in China to generate short-term forecasting of COVID-19 cases [
20,
21], as well as with data from Canada, France, India, South Korea, and the UK to forecast daily cases [
22,
23]. These models are incredibly useful in that they provide information on the current state of the pandemic. However, in this study, we had two aims regarding logistic growth models: (1) to demonstrate that their assumption of independence of and (2) that their modeling performance at the earlier stages of the pandemic is not optimal but can be improved by the incorporation of an autoregressive component [
4,
9].
The models used in this paper are based on statistical linear models, classic time series, and restricted growth—called limited growth or nonlinear growth models [
1,
2,
3,
13,
24]—as well as real-time forecasting using generalized logistic growth model [
4,
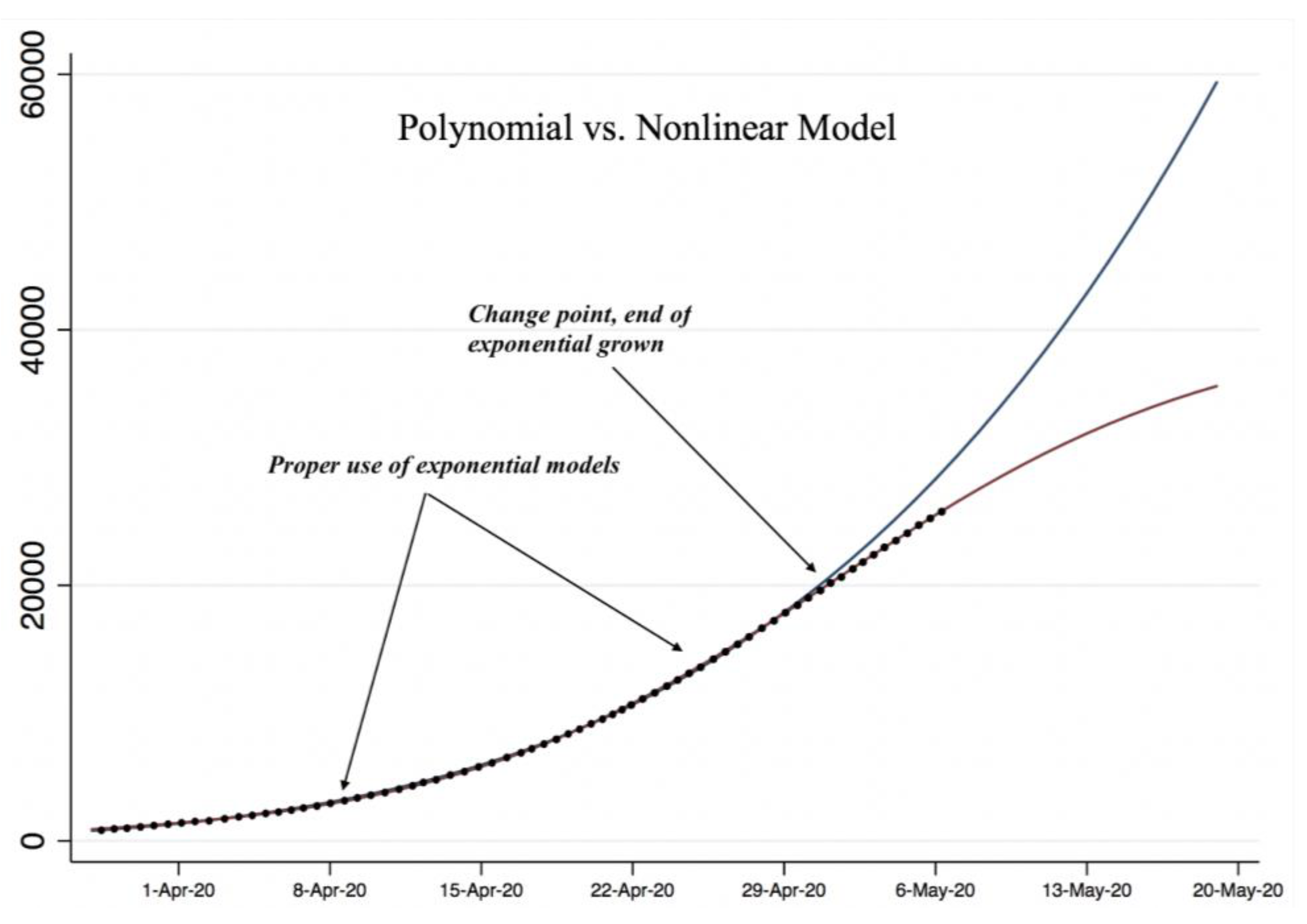
25]. In this paper, we propose estimations in two stages of the pandemic utilizing polynomial and nonlinear growth functions while incorporating an autoregressive component with the purpose of meeting the assumption of independence of residuals. First, we propose using a polynomial function estimated using the Prais–Winsten methodology to estimate the first stage of the pandemic (when exponential growth of COVID-19 cases was observed). Our rationale for choosing a third-degree polynomial model was the following: under certain scenarios: it can be converted into an increasing monotonic function, which is essential when modeling the total of accumulated cases; the degree is three since it shows simplicity with respect to higher-order polynomials; and when its behavior is observed, it has the shape of an “S”.
Next, in the second stage of the pandemic (when the peak of COVID-19 cases was reached), we propose utilization of nonlinear growth functions, logistic, and Gompertz in order to predict the total cumulative number of cases and the growth rate of the spread of COVID-19. In each of the models estimated before and after the peak of the pandemic, at the second stage of modeling, we added an autoregressive component of order one (AR (1)) to compare the results to the models that do not account for the violation of independence of residuals. This approach has been successfully used to model plant and animal growth where measuring the same unit can lead to violation of independence of residuals [
9,
25,
26]. Next, we selected the best estimate equation to model the pandemic by using Vuong’s test criterion [
27]. We anticipated the proposed model to have good performance similar to neural networks (NN) or support vector machines (SVM). A disadvantage of NN is that it is difficult to generate a day-to-day prediction in addition to finding the growth rate and finding the maximum number of cases. These are not a problem for the functions we propose. Furthermore, artificial intelligence (AI) has been used to identify, track, and forecast COVID-19 cases. However, AI models are difficult to interpret—the process by which they arrive at a decision is often referred to as a “black box” due to the complexity in understanding how AI models arrive at certain conclusions [
28]. The complex interpretation may create a barrier for decisionmakers looking for straightforward solutions in the middle of a pandemic. Moreover, we anticipate our proposed modeling of the pandemic will meet the assumption of independence of residuals. In contrast to NN, our proposed model can provide predictions and will facilitate interpreting parameters such as the highest number of infected individuals, growth speed, the initial number of infected individuals, and the autoregressive parameter to measure the lag in reporting the new daily cases of infections.
In summary, we present these two models (polynomial and nonlinear growth models) because of ease of interpretation for non-statistician decisionmakers, their stable and useful predictions while accounting for the autocorrelation of the data, and their insights regarding the current state of the pandemic. Therefore, the objectives of this paper were to:
- (1)
specify the polynomial function and nonlinear growth models (logistic and Gompertz) that include an autoregression component for dealing with the autocorrelated observations in the growth data in two stages: before and after the inflection point of the pandemic is reached, and
- (2)
compare the different polynomial and nonlinear growth functions in their ability to describe the number of cases of the COVID-19 pandemic.
4. Results
Table 1 displays the dates when COVID-19 cases peaked at the national level and in the three Mexican states selected for the study.
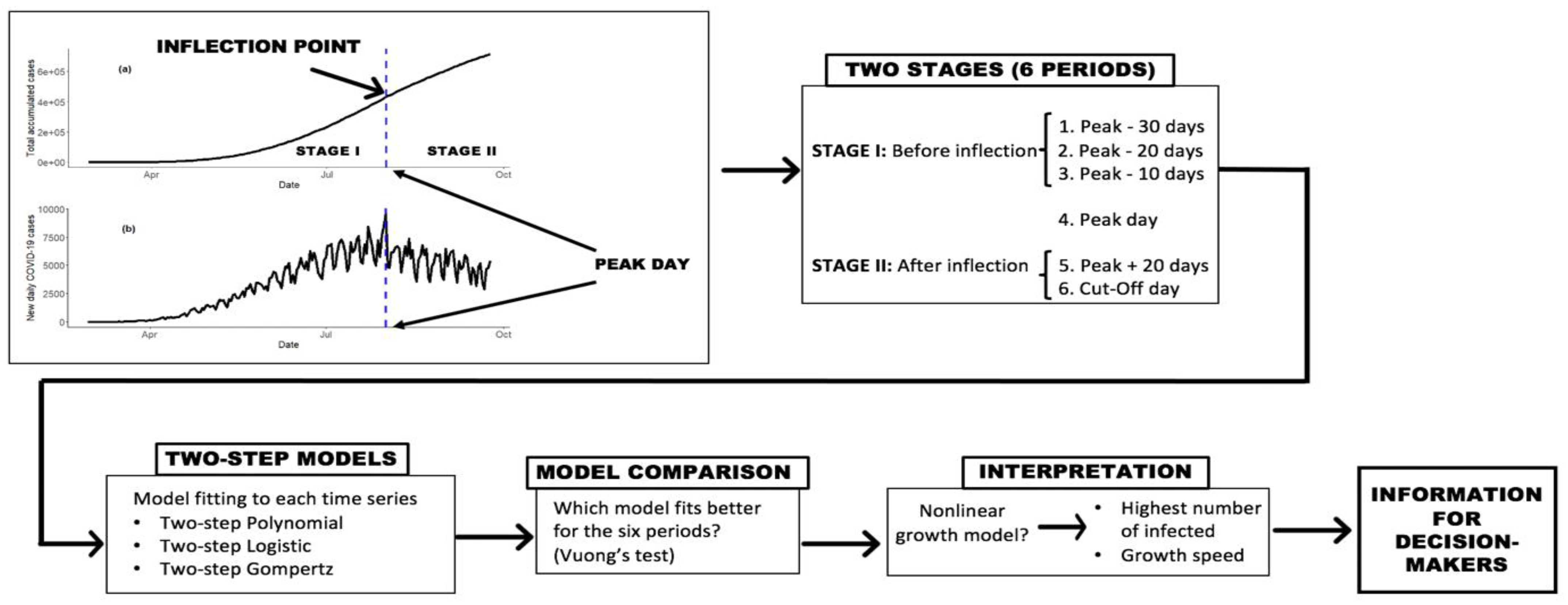
As previously mentioned, the proposed models were adjusted to six time periods. We used Voung’s test for each time point to see which model fit best. The
p-values obtained via Voung’s test for the alternative Hypothesis 2A (H
2A) can be seen in
Table 2. Note that the
p-values for the alternative Hypothesis 2B (H
2B) were the complement of the
p-values for the alternative Hypothesis 2A (H
2A). For example, comparing the polynomial and logistic models, in
Table 2, we can see the
p-value obtained for the state of Tamaulipas on 24 September was 0.9650 for the H
2A and its complement 0.0350 was the
p-value for the H
2B. At the significance level α = 0.05, we rejected the null hypothesis in favor of H
2B, suggesting that the logistic model fits the data better than the polynomial model.
Table 3 summarizes which models fit better for each region at each of the six time periods examined. In general, it is easy to see that the nonlinear growth models did not fit better than the polynomial models on dates before and during the peak of the first wave of the pandemic was reached. On the other hand, when examining the dates prior to the first wave peak of the pandemic, we found a negligible difference between the models. More importantly, examinations of model comparisons between dates before and during the peak of the pandemic revealed that no model worked better than any other. That is, in terms of modeling the growth rate of COVID-19 cases, there was no difference between the models. However, in the late phase of the pandemic, after the inflection point, the nonlinear growth models performed better than the polynomial model fit.
Polynomial and nonlinear growth models were useful for modeling the beginning of the epidemic (see
Figure 1) until reaching the maximum peak of daily cases for the pandemic [
5]. On the other hand, nonlinear growth models were more accurate and effective when more information was available, and the maximum peak of daily cases was reached. Furthermore, time series models allowed for practical real-time monitoring of when (a) exponential growth was beginning, (b) exponential growth was in effect, and (c) exponential growth was about to end, which indicated that the epidemic was reaching its end. Finally, the nonlinear growth models allowed for describing the behavior at the end of the pandemic and monitoring and detecting a possible second wave of the epidemic. In general, the logistic and Gompertz models had the better fit. For example, for the state of Tamaulipas, we used the Gompertz model, which was one of the models with better fit for the peak point + 20 days. We could estimate the maximum number of COVID-19 cases
= 63,640, the cases’ growth speed
= 0.0156, and the initial number of cases
= 162.
4.1. Model Performance
Once the models were estimated, it was possible to predict the total cases and the most recent information on rates (or percentage) of positive active COVID-19, outpatients, stable hospitalized patients, seriously hospitalized patients, and intubated hospitalized patients. Likewise, with the information from the SENTINEL Prevention Model, we estimated the total number of asymptomatic COVID-19 positive cases.
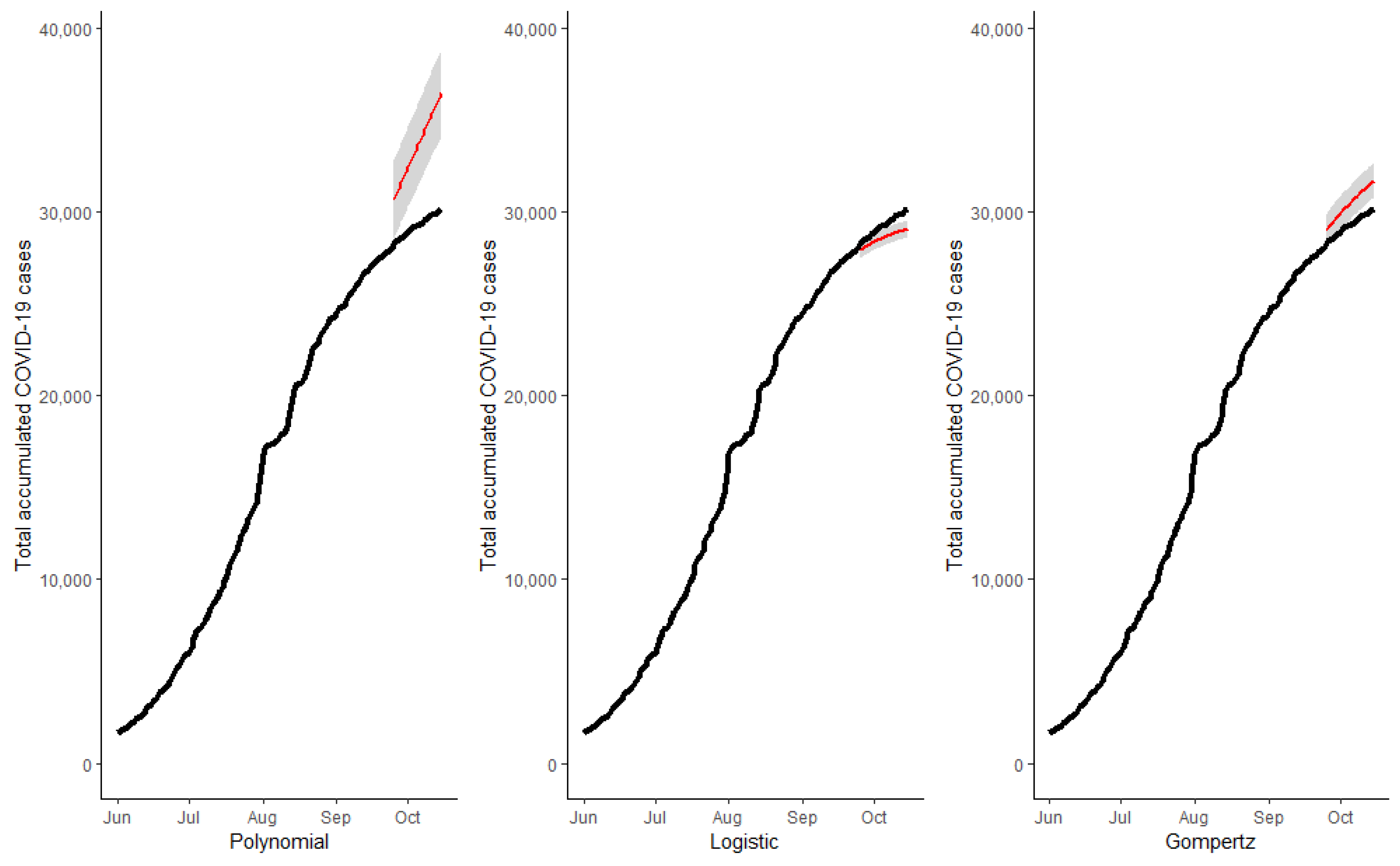
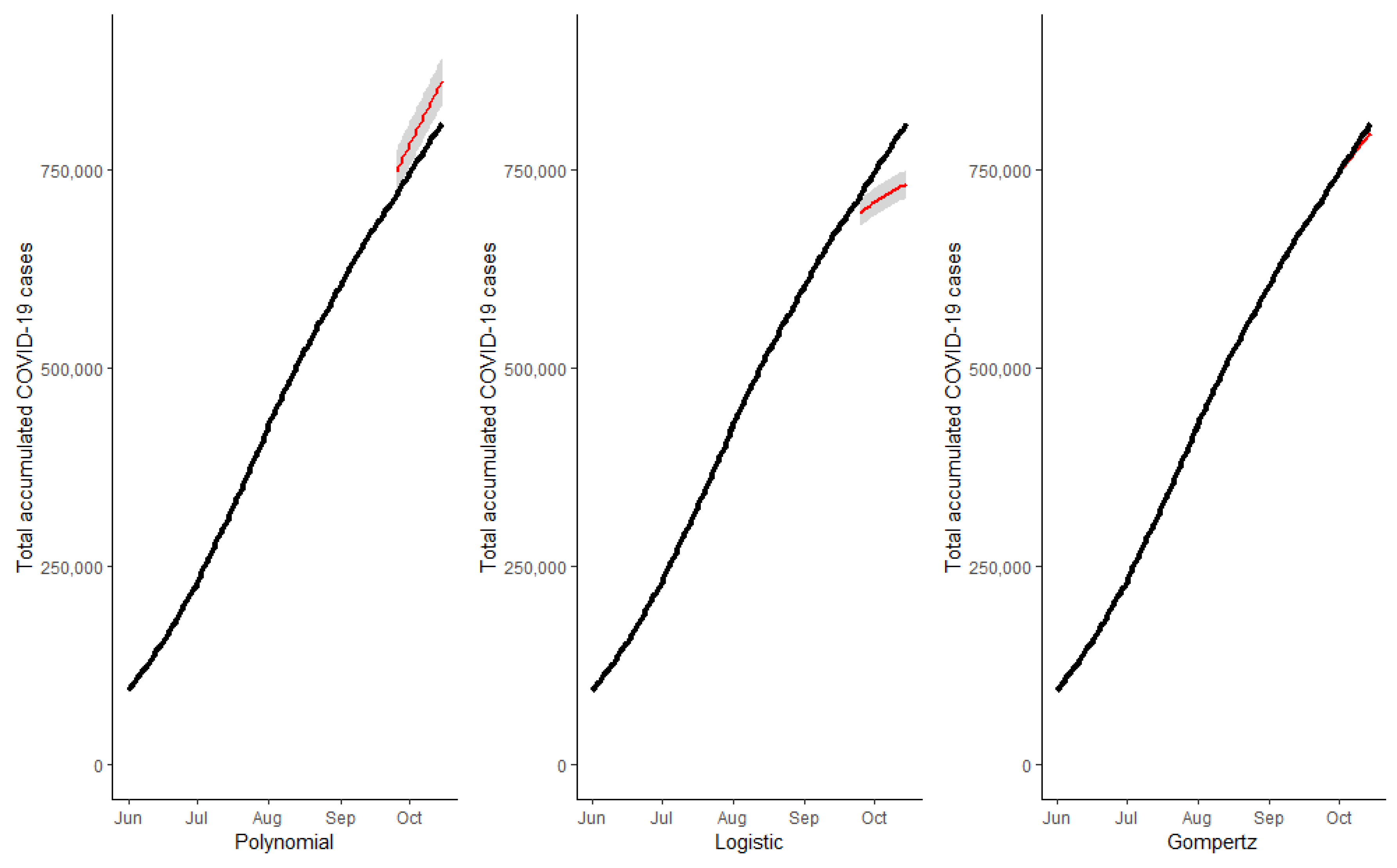
Figure 4,
Figure 5,
Figure 6 and
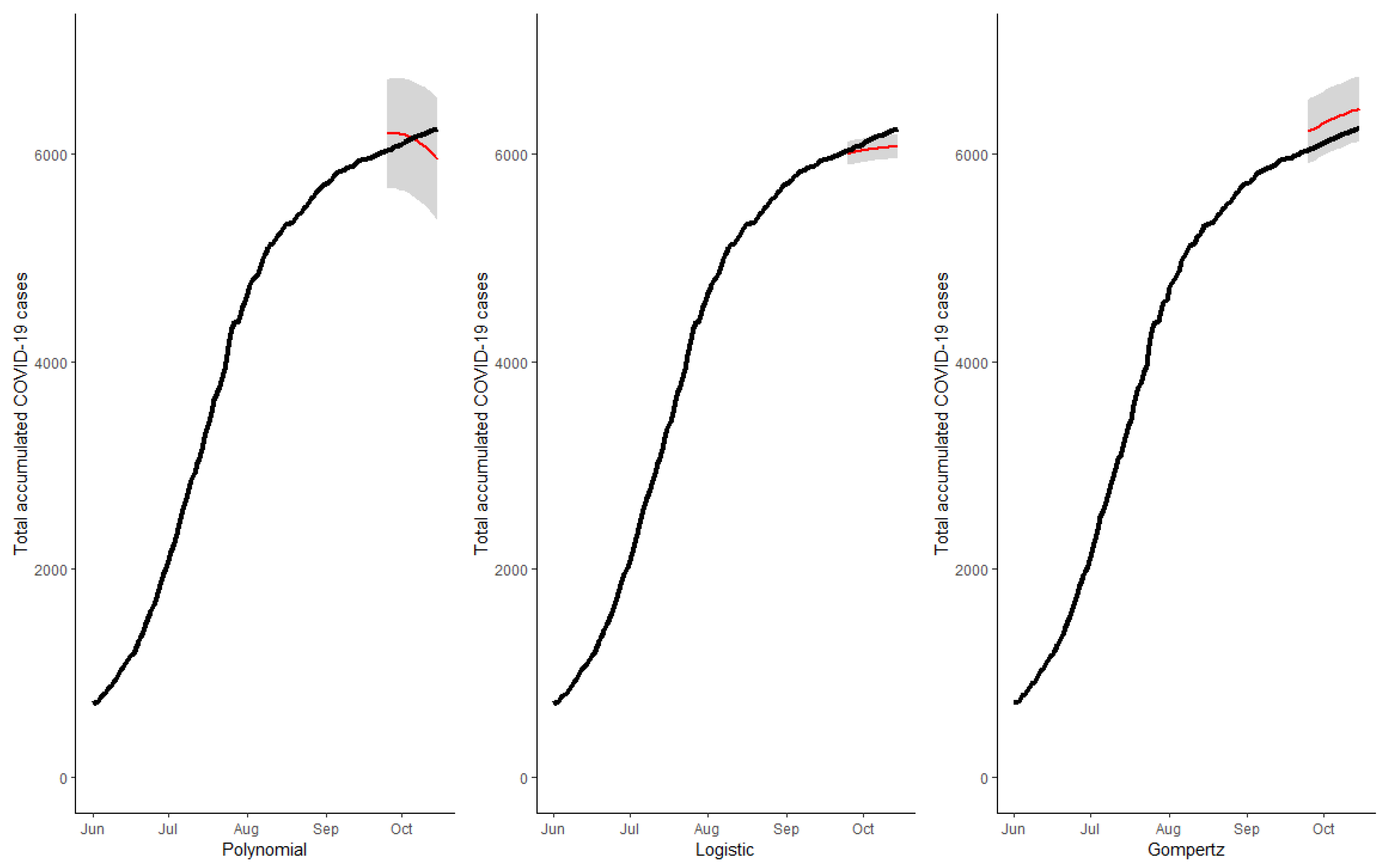
Figure 7 show the cumulative total cases of COVID-19 through 15 October (21 days out of the initial sample which was 24 September) for the four case studies (solid black line). These figures also show, with a red line, the point predictions made by each of the three models, as well as the area covered by the prediction intervals of said estimates with gray shading. In
Figure 4, we can observe that the predictions made by the logistic and Gompertz models were relatively good, but not so in the case of the polynomial model, which even predicted a decrease in the total accumulated cases (which was not possible in the context studied).
Figure 5 corresponds to the state of Tamaulipas—in this figure, we can see that the worst predictions were also made by the polynomial model. In
Figure 6, we can see the predictions for the state of Quintana Roo, wherein the model that best made predictions was the logistic one, and the total number of cases was overestimated by the two other models. Regarding the predictions made for the country, in
Figure 7, we can see that the best predictions, by far, were made by the Gompertz model.
Table 4 shows the root mean square error (RMSE) of each model proposed for the three state case studies and at the national level at the six time periods of interest.
As a result of the 21-day predictions mentioned above, the number of new cases of COVID-19 can be obtained, and the results for the four case studies and the three models are shown in
Table 5,
Table 6,
Table 7 and
Table 8. These results are based on the official data source of the daily releases issued by the Mexican Secretaria de Salud on its website
https://coronavirus.gob.mx/as of 15 October 2020 [
5].
4.2. Autocorrelation
An autoregressive model was fitted to the residuals of the logistics and Gompertz models estimated in a single stage to eliminate the autocorrelation. We fit an autoregressive model to the logistic and Gompertz functions to eliminate the residual autocorrelation. The analysis revealed that the inclusion of an autoregressive component of the second order improved the fit of the data. For example, for the state of Aguascalientes,
Figure 8a,b shows the autocorrelation residual and partial autocorrelation plots for models without the autoregressive terms. In these figures, it is clear that the residuals show a pattern of dependency. Furthermore,
Figure 8c,d demonstrates a good fit, and there is no evidence of linear relationship. The patterns in the data revealed that nonlinear models with autoregressive terms met assumptions of independence. The models showed good fit while accounting for autocorrelation of residuals while providing better interpretability of the model coefficients in terms of growth rate, maximum number of cases, and initial number of cases. Thus, the model proposed in this paper produces a substantial improvement of the predictions.
5. Conclusions
The modeling of the COVID-19 cases is a unique challenge for statisticians, considering the fact that the data are limited and there are often delays in updating the data. Our approach to modeling the pandemic can provide assistance to decision-making officials for containing and anticipating a “second wave” of the COVID-19 pandemic in Mexico. We divided the pandemic data into two stages, and at each stage, three two-step models were adjusted. In Stage I, as can be seen in
Table 3, the polynomial model of order three with an autoregressive error component of order one was computed through applying the Prais–Winsten or Cochrane–Orcutt estimation, which had a better performance than nonlinear growth models. In Stage II, after the peak of COVID-19 cases, two-step nonlinear growth models outperformed the polynomial model. Further, the models used in this paper were different than those used in predictive models using time series or machine learning; however, our model met the assumption of independence of residuals, and the interpretability of our model was superior to those of machine learning—particularly for government officials without a statistics or machine learning background.
Although it is not the objective of this research, another purpose for the proposed models concerns the identification of the peak of the pandemic. That is, an analytical way to know if the pandemic is currently in a period of growth, peak, or decline of sustained cases is through the adjustments of the models. For example, at the moment that any of the non-linear growth models fits significantly better than the other models, we will be at the point of sustained reduction of daily cases, which would mean that the peak has already passed, and that said model must be used to make predictions of total cases and obtain insights of the pandemic at that point.
In summary, this paper showed the efficacy of utilizing two different types of models estimated in two stages (stages depending on the state of the pandemic). The majority of the efforts to model the COVID-19 pandemic are nonlinear models, such as logistic and Gompertz [
4,
5]. However, these models do not take into account autoregression, thus possibly skewing short-, medium-, and long-term predictions. In contrast with the SIR models, where it is necessary to fix or assume a few initial parameters, our proposed models do not require initial parameter assumptions. Our first recommendation, due to simplicity in fitting the model, is that in the early stages of the pandemic where there was an exponential growth (during or before the peak), one should utilize a polynomial model of the third order estimated with an autoregressive component. Our second recommendation is that for the later, more advanced stages when the peak of the pandemic was reached, one should utilize a nonlinear growth model (logistic or Gompertz) estimated with an autoregressive component. In the event that two models show the best fit, if any of these is the polynomial model, it will be necessary to question whether it is in the public health decisionmakers’ interest to have insights (provided by the βs of the non-linear growth models) of the current state of the pandemic; if yes, then we recommend using the non-linear growth model. In the opposite case, where it is not in the interest of the decisionmakers to know insights of the pandemic, the use of the polynomial model is recommended since it does not require initial values for its estimation. Another scenario could be that within the tie, there are two linear growth models, wherein either of the two can be used.
This research is not without limitations. The projections resulting from the models were estimated without considering any type of intervention. In other words, the intervention effects—such as mask mandates, lockdowns, social distancing, or vaccines—are not considered in our models. Any of the aforementioned variables should be considered with care. Regarding vaccination, as this article was being written, there was no official site of the Mexican government where the total number of people vaccinated could be retrieved, only unofficial sites where progress is reported; however, these numbers are not trustworthy. Regarding the measures of lockdowns and use of face masks, given the federal nature of the country, the states of the republic are free to take or not take actions on their population; thus, to analyze any variable of this nature, an exhaustive study must be carried out on the states that took similar measures, and the effect of these measures must be evaluated by means of an effect or additive or multiplicative variable in the statistical model.
Due to the characteristics of the models used, the atypical characteristics of the COVID-19 pandemic, and the results and information derived from the monitoring strategy—well known in epidemiology science as SENTINEL Prevention Model—the following should be considered:
The data show a lot of variability from one day to another. Part of the noise caused by the dynamics of new case records was smoothed out by pre-processing the data (moving average) and the AR (1) component of the model; in future work, to further reduce the noise, we could add complex structures in the residuals, such as ARMA, ARIMA, or SARIMA. Furthermore, at the time of the data cut-off date, the second wave of the pandemic had not yet occurred. In the event that it is required to use this model for a second wave of the pandemic, care must be taken with the estimation of the components of the non-linear models (specifically the autoregressive and nonlinear component). That is, the nonlinear models used are not designed to model spikes in cases (second wave or third waves), and this will affect the estimation of parameters—such as growth speed, maximum cases, and the autoregressive component—being able to obtain estimates out of context of the pandemic (very high or low numbers), or uniroot problems in the time series component.
As previously mentioned, the residual autocorrelation analysis was performed, looking for linear autocorrelations. Regarding the precision of the predictions, future research will focus on comparing our proposed models against machine learning and artificial intelligence models. In some cases, such as the state of Aguascalientes, it was necessary to add a second order autoregressive component.
The benefit of utilizing a second-order autoregressive component is shown in
Table 9 for the state of Aguascalientes (before 20 August 2020). For the Gompertz nonlinear growth model, we corrected for the dependency between observations by including an autocorrelation term of the second order in the model that considerably improved the overall fit criteria. Thus, we recommend the inclusion of an autoregressive term of the second order when modeling COVID-19 case growth.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}