1. Introduction
Since the 1960s chaos theory has played an increasingly important role in the development of many scientific fields such as economics and finance [
1,
2,
3,
4,
5]. Interest in nonlinear modeling, and particularly in studying chaotic system, defined as a nonlinear deterministic process that appears to be random and presents sensitivity to initial conditions, has risen significantly. In fact, literature displays numerous publications searching for nonlinear and chaotic behavior in macroeconomic and financial time series [
2]. Our research is included within this framework which aims to unveil the nonlinear dynamics in the shipping market. Specifically, we examine the existence of nonlinearity and chaos in dry bulk shipping rates time series.
Maritime transport plays an outstanding role in the worldwide economy, since over 90% of all world trade is transported by sea and it is the most profitable method of carrying goods and raw materials in masse throughout the world [
6]. Specifically, ocean shipping freight rates constitute a significant proportion of the production inputs cost and determine to some extent the final commodities’ prices in overseas consumption centers [
7]. Dry bulk freight rates are commonly represented by the Baltic Dry Index (BDI) [
8] that has been proposed to be a measure of the shipping rates for certain raw materials [
9]. The BDI is considered a global trade indicator [
10] and serves as an indicator for the commodities, currency, and equity markets [
8]. Moreover, it is considered an accurate “barometer” of economic activity and an efficient indicator for forecasting industrial production and economic growth because it captures changes in the early stages of the global supply chain. In summary, as Guan et al. [
11] highlighted, BDI not only reflects the evolution of the dry bulk shipping market but can also mirror the state of the world economy and the trend in international trade.
Given their interest, it is not surprising that, as mentioned by Chen et al. [
12], knowledge of freight rate dynamics has attracted a great deal of attention among researchers in the shipping community. Stopford [
13] emphasizes the great importance of forecasting shipping prices for the stakeholders involved in the maritime industry: shipping companies, cargo owners, shipbuilders, bankers, or regulators. In addition, he points out that forecasts can achieve a high degree of complexity and in many cases, they have had limited success. Forecasting freight rates is a complex task because they are influenced by many features [
14], such as political, economic, and natural conditions [
11]. Among the many influences on the shipping market, Stopford [
13] focused on factors affecting the demand for sea transport (i.e., world economy, seaborne commodity trade, and random shocks) and affecting the supply (i.e., world fleet, shipbuilding deliveries, and scrapping and freight revenues). Zeng et al. [
15] suggested that the complexity as well as the non-stationary and nonlinear nature of freight rates series in the bulk shipping market escalate the difficulty in forecasting freight rates. In this sense, Chen et al. [
12] mentioned that the dry bulk shipping industry is characterized as highly volatile. Moreover, Geman and Smith [
16] focused on extreme volatility in the shipping markets, particularly in freight rates, because the inelasticity of supply to demand shocks when no inventory is available causes large fluctuations in the change through time. For the aforementioned reasons, accurate freight rate prediction presents an important challenge for researchers [
15,
17].
However only a limited number of studies that unveil the existence of nonlinearity and chaos can be found (e.g., [
17,
18,
19]). Specifically, Goulielmos and Psifia [
17] found a nonlinear behavior and low-dimensional chaos in the time charter freight rates series dynamics using the Hurst exponent, BDS test and Lyapunov exponent. Goulielmos and Psifia [
18] detected a nonlinear behavior in the freight rates time series dynamic by applying the BDS test. Goulielmos et al. [
19] found evidence of chaos, applying techniques like rescaled range analysis, correlation dimension and Lyapunov exponent. In conclusion, previous research on chaos has used methods from other sciences that are not appropriate for diagnosing chaos (for example BDS test or Hurst exponent) or that have not been adapted to take into account the specific characteristics of financial time series like noise and the limited and low sample size (e.g., correlation dimension method or Lyapunov exponent test). Hence, their conclusions could be misleading [
20,
21,
22]. It can be concluded that the existence of chaos in ocean freight rates continues to be an open and important issue. Its relevance resides in that the existence of low-dimensional chaos could enable a reliable short-run prediction, but not in the long-run, since a chaotic system presents sensitivity on initial conditions and therefore is unstable [
23].
From an economic point of view, the existence of chaos has several important implications. As Brooks [
24] points out, these consequences affect aspects such as model appropriateness, market efficiency and predictability. LeBaron [
25] argues that chaos in economics had a broad array of potential applications such as forecasting or understanding international business cycles. The presence of chaos can also provide a potential explanation for seemingly random fluctuations in the economy and financial markets [
26] and a wider range of time series behavior. Specifically, linear models may not adequately capture the sharp movements and large fluctuations that characterize financial and economic series and hence are not appropriate to describe economic phenomena like stock market bubbles and crashes, depressions, and the occurrence of business cycles. On the contrary, chaotic models may be well suited to explain these behavioral patterns [
27]. Another important implication of the presence of chaos is that controllability of the system is feasible, since there is some deterministic structure underlying the data [
28]. Interestingly, chaos also represents a radical change of view on business cycles [
28]. The traditional exogenous approach to economic fluctuations assumes that economic equilibria are determinate and intrinsically stable, so that in the absence of persistent exogenous shocks the economy will tend to a steady state, but due to stochastic shocks a stationary pattern of fluctuations is observed. In contrast, with the new approach based on chaos theory, business cycles are endogenously explained and are based on the marked nonlinear deterministic structure that can characterize the economic system.
Concerning the degree of predictability of the series, if the system is completely random, its behavior is not predictable at all, while if it exhibits chaotic behavior, we can forecast the system in short periods of time [
29]. However, when chaos exists, although short-run forecasting may be more accurate, long-run forecasting then becomes impossible due to the sensitivity to initial conditions. In addition, traditional linear forecasting methods would not be successful and nonlinear models should be applied [
26]. The presence of chaos also indicates the possibility of using nonlinear trading rules and is likewise understood as a hallmark of an inefficient market [
30]. In practical terms, this implies that in financial markets accurate short-run forecasts can be achieved and investors can make profits with an adequate strategy, while the long-run behavior of these time series is not predictable in any way [
31].
As noted above, linear models have proven to be ill-suited for describing and fitting many economic phenomena such as the business cycles. In contrast, the nonlinear approach can capture the features of economic and financial series and their sudden fluctuations, and hence plays a relevant role in economic modeling [
32]. Likewise, dynamical systems involving time delays have applications in a number of fields such as biology, population dynamics and economics [
33]. The delayed model can produce oscillating trajectories for the solutions under certain conditions and explain the business cycles [
34,
35]. Delay differential equations have derivatives depending explicitly on the value of variables at times in the past and are adopted to represent systems with time delay. In general, delay differential equation models can be more accurate than those based on ordinary differential equations when it is necessary to capture oscillatory dynamics. In the last few years, the literature on the oscillation theory of delay differential equations is growing very quickly and among the topics studied the oscillation of solutions has been the most extensively investigated [
36]. The core of the theory lies in setting the conditions for the existence or non-existence of oscillatory solutions. This is an area of research with interesting applications in many fields and closely related to chaos, which is characterized by irregular and unpredictable oscillations [
37]. Hence, oscillatory behavior of the solutions of a class of nonlinear delay differential equations is an important area for future research.
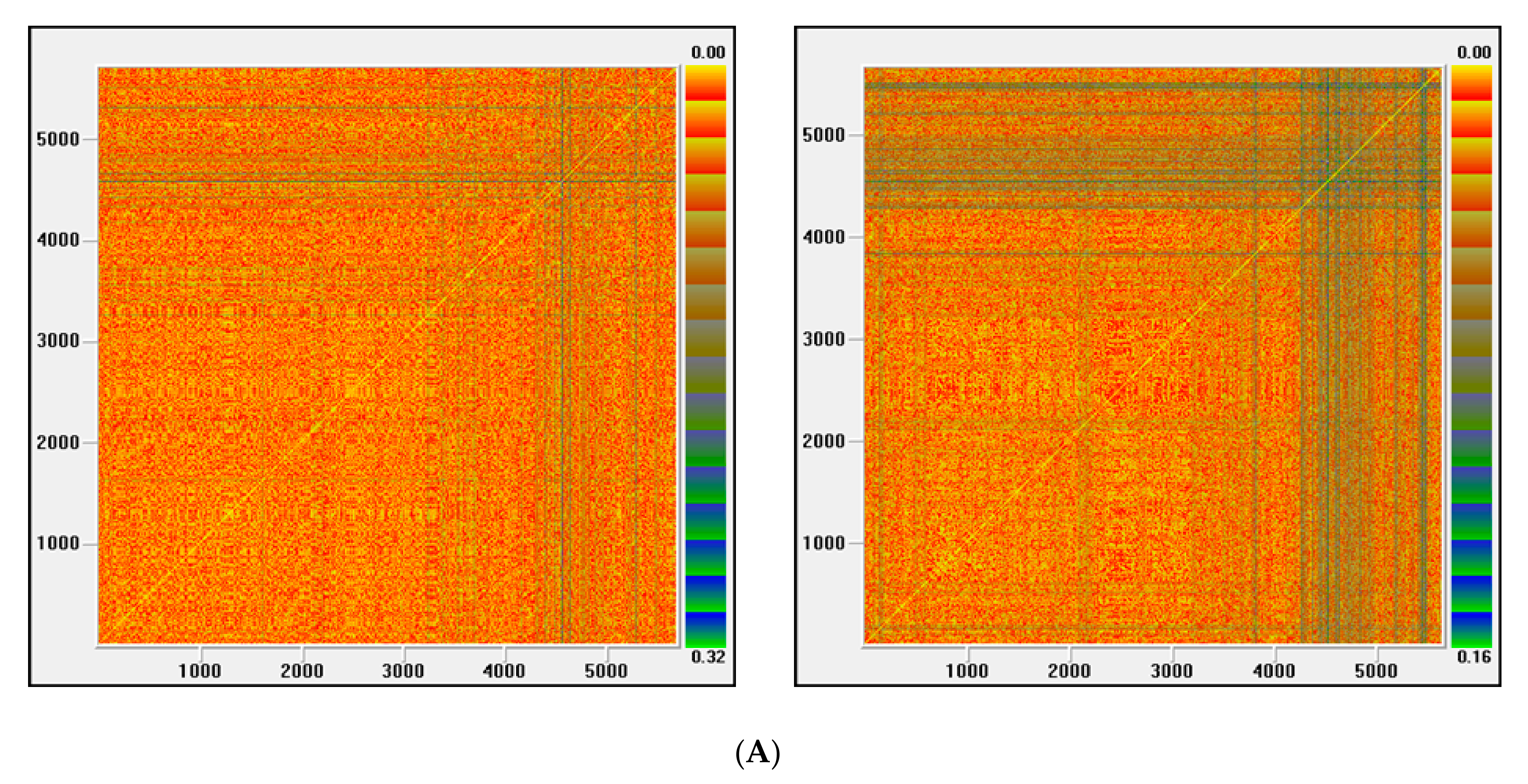
The basic aim of this research is to investigate the underlying dynamics of ocean freight rates as measured by the BDI. By using daily closing values from January 1990 to July 2013, we tested for the existence of nonlinearity and low-dimensional chaos. The paper also examines other issues such as the existence and modelling of volatility clustering. The proposed methodology considers the characteristics of chaotic time series, such as nonlinearity, determinism, sensitivity to initial conditions, fractal dimension and recurrence. Each characteristic is tested by the corresponding method. The existence of nonlinearities is tested by the application of a broad set of methods (Keenan, Tsay, White and BDS). In the same way, four methods (correlation dimension, Matilla-Garcia and Ruiz Marin (MGRM) test [
38], Lyapunov exponent test, adapted for noisy series [
21], and recurrence plots) have been applied to test for chaos. To make the conclusions of this work more robust, besides analyzing the series over the whole period, we have also examined the chaotic behavior over three sub-periods, which were selected by the evolution of volatility.
To this end the following methodology is applied to all time series [
32]. First, to evaluate stationarity of the BDI series, unit root tests were performed. Once it had been established that BDI series was I(1), the analysis was carried out on daily returns computed as first difference of the logarithmic price level. Linear dependence was then filtered out of the data by applying autoregressive moving average (ARMA) filters based on the Box–Jenkins methodology [
39]. Next, we applied a broad array of procedures to the residuals obtained to detect the existence of nonlinearity. If nonlinear dependence was detected, since linear structures had already been removed using the best fit ARMA model, it was indicative of some type of nonlinear dependence in the returns series resulting from a nonlinear stochastic system or a nonlinear deterministic chaotic system. Stochastic nonlinearity could be due to the presence of a volatility cluster, i.e., large variations tend to group together, which is a common characteristic of financial time series. In such a case, both generalized autoregressive conditional heteroskedasticity (GARCH) [
40] and exponential (EGARCH) [
41] models were fitted. Afterwards, as a distinctive feature of proposed methodology against published methods, the existence of chaotic structure was examined by a series of robust procedures, including those that are ideally suitable for noisy time series analysis, e.g., Lyapunov exponent test adapted for noisy series, MGRM test based on permutation entropy, and recurrence plots.
Furthermore, the novelty and main contribution of this study lies in the fact that, as far as we know, it is the first time that these robust methods have been applied to detect chaos to such a relevant variable in the world economy, the freight shipping rate. The findings suggest that nonlinearity is present in the underlying process of the BDI although unlike previous studies, we found no sign of chaotic structure. In terms of the benefits of our research for both theory and practice, our results make a significant contribution to shedding light on the underlying behavior and dynamics in shipping rates. In general, our insights should be of great interest to all stakeholders concerned with the shipping industry, including, among others, stevedores, charterers, shipowners, brokers and investment banks.
The rest of the paper is organized as follows. The next section describes the methodological framework applied. The penultimate section presents the data sources used and the main results. Finally, in the final section, we present some conclusions and suggest future lines of research.
4. Conclusions
This paper analyzes the underlying dynamics of dry bulk shipping rates using daily data from the Baltic Dry Index. The entire sample has been divided into three periods, chosen according to the volatility behavior of the series, to make the conclusions of this empirical work more robust. Specifically, we tested for the existence of a chaotic regime in the shipping market by applying metric, topological and permutation entropy-based approaches. From a comprehensive view a great number of methods have been used (four for nonlinear analysis and four for chaotic behavior analysis) including the most suitable for noisy time series. The adopted methodology is based on each method checking one of the properties that characterize chaotic behavior. Our results support the existence of nonlinearity, which is not consistent with chaos, as measured by the four indications of chaotic behavior, throughout all investigated periods. Specifically, the underlying system is of high dimensionality does not present sensitive dependence on initial conditions, as well as not being characterized by recurrent states and by deterministic nonlinear structures. In addition, we show that GARCH/EGARCH models explain a significant part of the nonlinear structure that is found in the dry bulk shipping freight market. Our findings are in accordance with the conclusions of other researchers who use novel and suitable procedures for noisy series to detect chaos in other financial time series (e.g., [
21,
54]). On the other hand, our conclusion contradicts the findings of previous studies that found evidence of low dimensional chaos in shipping market but using a number of techniques that are not suitable for detecting chaos (e.g., the Hurst coefficient) or that do not account for noise (e.g., [
19]). Thus, their findings might be biased.
Regarding the benefits of our research for both theory and practice, results significantly contribute to illustrate the behavior and underlying dynamics of the maritime transport price. In general, our findings should be of great relevance to all stakeholders concerned with the maritime sector, such as institutional agencies, investors, charterers, shipowners, stevedores, and brokers. Important managerial insights can be drawn from analytical results. In particular, knowledge and forecasting of freight rates dynamics have a relevant role to improve the formulation of financial strategies, such as the pricing of derivatives and hedging instruments. Likewise, due to the volatile nature of freight rates to improve our volatility, forecasting accuracy is a major feature in successful risk management. Finally, since the BDI not only informs about the evolution of dry cargo shipping market but can also mirror the trends in international trade and consequently, the state of the world economy [
11], it could be considered an accurate “barometer” of the economic activity and an efficient indicator for forecasting industrial production and economic growth. Hence, our findings are useful for the design of optimal macroeconomic policies.
Further research on the nature and forecasting of shipping rates is still an outstanding issue, as a limited number of studies are available. Future research is needed to examine whether other types of nonlinear model, both parametric and non-parametric, might be able to account for the remaining nonlinear dependence in the series. Also, studying the existence of nonlinearity and chaos in the volatility series would help to complete this work. Finally, a new investigation could consist of studying the effects of the COVID−19 outbreak on the dynamics of the analyzed series, as well as specifically investigating how this phenomenon could have modified the results of this research.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








