
An RFM Model Customizable to Product Catalogues and Marketing Criteria Using Fuzzy Linguistic Models: Case Study of a Retail Business




Abstract
1. Introduction
2. Materials and Methods
2.1. Literature Review
2.2. Theoretical Fundamentals
2.2.1. The 2-Tuple Fuzzy Linguistic Model
2.2.2. The Fuzzy Linguistic 2-Tuple RFM Model
- Recency (R): the time (in units such as days, months and years) since the most recent purchase transaction or shopping visit.
- Frequency (F): The total number of purchase transactions or shopping visits in the period examined.
- Monetary value (M): the total value of the purchases within the period examined.
- Data collection: let U = {u1, …, u#U} be the set of customers who have made at least one purchase over a pre-established analysis period. Let T = {(u1, d1, a1), …, (u#T, d#T, a#T)} be the details of transactions or purchases made by such customers in this period, where the ui ∈ U identifies the customer of such a purchase on the date di for the amount of ai.
- Customer aggregation: in this phase, T is aggregated at the customer level, obtaining the set TU = {(u1, r1, f1, m1), …, (u#U, r#U, f#U, m#U)}, where re would be the days since the last purchase of the customer ue (using a later fixed reference date for all customer purchases), fe is the number of times the customer has purchased and me contains the total amount of these purchases.
- Score computation: in this step, the set RFM = {(u1, R1, F1, M1, RFM1), …, (u#U, R#U, F#U, M#U, RFM#U)} with the fuzzy linguistic 2-tuple RFMScores is obtained. First, a symmetric and uniformly distributed domain S using five linguistic labels is defined. These labels have a semantic meaning for the variables of the RFM model referring to the degree of agreement with the goodness of the variable:Let S = {s0, …, sT} be with T = 4: s0 = very bad = VB; s1 = bad = B; s2 = neutral = N; s3 = good = G; and s4 = very good = VG, with the definition shown in Figure 2.
2.2.3. Analytical Hierarchical Process (AHP)
Structuring of the Decision Problem into a Hierarchical Model
Making Pairwise Comparisons and Obtaining the Judgmental Matrix
Obtaining Local Weights and Consistency of Comparisons
3. Results
3.1. Developed Approach
3.2. Steps of Economic and Mathematical Model
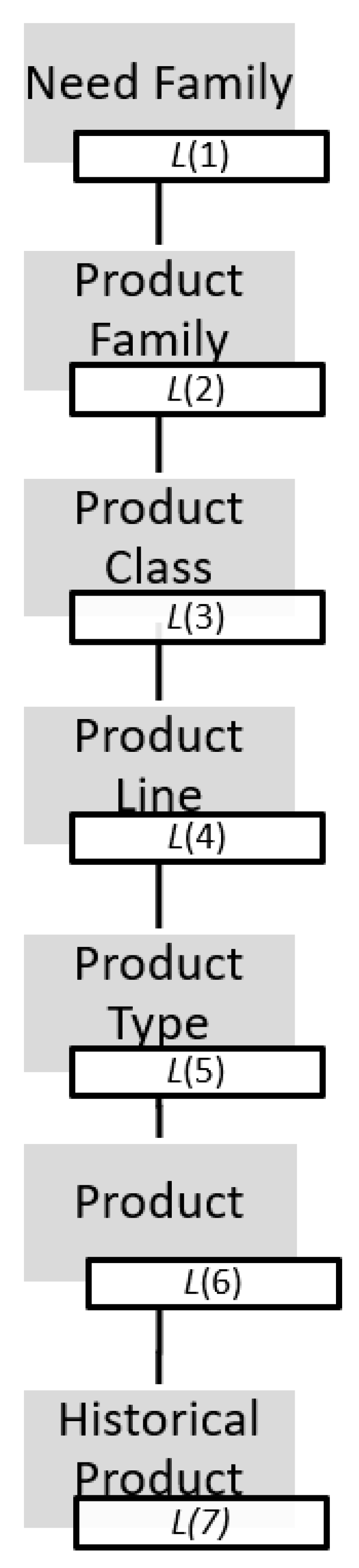
3.2.1. Product Representation: Step 1
3.2.2. RFM Based on Product Hierarchy: Step 2
Obtaining the Weights of Each Product
- Structuring of the decision problem into a hierarchical model
- 2.
- Making pairwise comparison
- 3.
- Obtaining local weights and consistency of comparisons
Obtaining the Fuzzy Linguistic 2-Tuple RFM Value for Each Customer and Each Product
3.2.3. Customer Segmentation by 2-Tuple RFM Value per Product: Step 3
3.2.4. Strategy by Segment under Business and Product Preferences: Step 4
3.3. Case of the Model Implementation
3.3.1. Step 1: Product Hierarchy Definition
3.3.2. Step 2: RFMScore Definition Based on Product Hierarchy
Step 2.1: Obtaining the RFM Weights for Each Historical Product
- Structuring the decision problem into a hierarchical model
- 2.
- Making pairwise comparisons
- 3.
- Obtaining local weights and consistency of matrix comparisons
Step 2.2: Obtaining the 2-Tuple RFM Value for Each User and Product
3.3.3. Step 3: Clustering Customers Based on RFMScore for Each Product Hierarchy
3.3.4. Step 4: Strategy by Segment under Business and Product Preferences
4. Discussion
4.1. Global RFMScore Definition
- Defining recency, frequency and monetary global variables.
- 2.
- Obtaining fuzzy linguistic 2-tuple RFM model.
- 3.
- Calculating the RFMScores and the fuzzy linguistic 2-tuple RFMScore.
- 4.
- Clustering customers based on global RFMScore.
4.2. Comparing and Enriching Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wedel, M.; Kannan, P.K. Marketing Analytics for Data-Rich Environments. J. Mark. 2016, 80, 97–121. [Google Scholar] [CrossRef]
- Maechler, N.; Neher, K.; Park, R. From touchpoints to journeys: Seeing the world as customers do. McKinsey Q. 2016, 2, 2–10. [Google Scholar]
- Said, E.; Macdonald, E.K.; Wilson, H.N.; Marcos, J. How organizations generate and use customer insight. J. Mark. Manag. 2015, 31, 1158–1179. [Google Scholar] [CrossRef]
- Moorman, C. Top Ten Results from the CMO Survey—August 2019. Available online: https://tinyurl.com/yx75qt3f (accessed on 21 December 2019).
- Ransbotham, S.; Kiron, D.; Prentice, P.K. Minding the analytics gap. MIT Sloan Manag. Rev. 2015, 56, 63–68. [Google Scholar]
- Bresciani, S.; Ferraris, A.; Del Giudice, M. The management of organizational ambidexterity through alliances in a new context of analysis: Internet of Things (IoT) smart city projects. Technol. Forecast. Soc. Chang. 2018, 136, 331–338. [Google Scholar] [CrossRef]
- Scuotto, V.; Arrigo, E.; Candelo, E.; Nicotra, M. Ambidextrous innovation orientation effected by the digital transformation. Bus. Process Manag. J. 2019, 26, 1121–1140. [Google Scholar] [CrossRef]
- Taiminen, H.M.; Karjaluoto, H. The usage of digital marketing channels in SMEs. J. Small Bus. Enterp. Dev. 2015, 22, 633–651. [Google Scholar] [CrossRef]
- Verhoef, P.C.; Broekhuizen, T.; Bart, Y.; Bhattacharya, A.; Dong, J.Q.; Fabian, N.; Haenlein, M. Digital transformation: A multidisciplinary reflection and research agenda. J. Bus. Res. 2021, 122, 889–901. [Google Scholar] [CrossRef]
- Matarazzo, M.; Penco, L.; Profumo, G.; Quaglia, R. Digital transformation and customer value creation in Made in Italy SMEs: A dynamic capabilities perspective. J. Bus. Res. 2021, 123, 642–656. [Google Scholar] [CrossRef]
- Kartajaya, H.; Setiawan, I.; Kotler, P. Marketing 4.0. LID Editorial. 2018. Available online: https://www.ucentral.edu.co/sites/default/files/inline-files/WP03_Lavirtualidad_zapata_Web.pdf (accessed on 1 June 2021).
- Liu, D.Y.; Chen, S.W.; Chou, T.C. Resource fit in digital transformation lessons learned from the CBC Bank global e-banking ptoject. Manag. Decis. 2011, 49, 1728–1742. [Google Scholar] [CrossRef]
- Chen, I.J.; Popovich, K. Understanding customer relationship management (CRM). Bus. Process Manag. J. 2003, 9, 672–688. [Google Scholar] [CrossRef]
- Kuchinka, D.G.J.; Balazs, S.; Gavriletea, M.D.; Djokic, B.-B. Consumer Attitudes toward Sustainable Development and Risk to Brand Loyalty. Sustainability 2018, 10, 997. [Google Scholar] [CrossRef]
- Sirgy, M.J. Self-congruity theory in consumer behavior: A little history. J. Glob. Sch. Mark. Sci. 2018, 28, 197–207. [Google Scholar] [CrossRef]
- Yuan, X.; Li, D.; Mohapatra, D.; Elhoseny, M. Automatic removal of complex shadows from indoor videos using transfer learning and dynamic thresholding. Comput. Electr. Eng. 2018, 70, 813–825. [Google Scholar] [CrossRef]
- Eger, L.; Komárková, L.; Egerová, D.; Mičík, M. The effect of COVID-19 on consumer shopping behaviour: Generational cohort perspective. J. Retail. Consum. Serv. 2021, 61, 102542. [Google Scholar] [CrossRef]
- Rahman, I.; Reynolds, D. The influence of values and attitudes on green consumer behavior: A conceptual model of green hotel patronage. Int. J. Hosp. Tour. Adm. 2017, 20, 47–74. [Google Scholar] [CrossRef]
- Hughes, A.M. Strategic Database Marketing; Probus Publishing Company: Chicago, IL, USA, 1994. [Google Scholar]
- Bult, J.R.; Wansbeek, T. Optimal Selection for Direct Mail. Mark. Sci. 1995, 14, 378–394. [Google Scholar] [CrossRef]
- Yeh, I.-C.; Yang, K.-J.; Ting, T.-M. Knowledge discovery on RFM model using Bernoulli sequence. Expert Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Gupta, S.; Hanssens, D.; Hardie, B.; Kahn, W.; Kumar, V.; Lin, N.; Ravishanker, N.; Sriram, S. Modeling customer lifetime value. J. Service Res. 2006, 9, 139–155. [Google Scholar] [CrossRef]
- Kumar, V.; Reinartz, W. Creating Enduring Customer Value. J. Mark. 2016, 80, 36–68. [Google Scholar] [CrossRef]
- Heldt, R.; Silveira, C.S.; Luce, F.B. Predicting customer value per product: From RFM to RFM/P. J. Bus. Res. 2021, 127, 444–453. [Google Scholar] [CrossRef]
- Moghaddam, S.Q.; Abdolvand, N.; Harandi, S.R. A RFMV model and customer segmentation based on variety of products. Inf. Syst. Telecommun. 2017, 5, 155. [Google Scholar]
- Virvilaitė, R.; Saladienė, V. Models investigation of factors affecting consumer impulsive purchase behaviour in retail envi-ronment. Econ. Manag. 2012, 17, 664–670. [Google Scholar] [CrossRef][Green Version]
- Chen, T. Impulse purchase varied by products and marketing channels. J. Int. Manag. Stud. 2008, 3, 154–161. [Google Scholar]
- Chang, H.-C.; Tsai, H.-P. Group RFM analysis as a novel framework to discover better customer consumption behavior. Expert Syst. Appl. 2011, 38, 14499–14513. [Google Scholar] [CrossRef]
- Bitran, G.R.; Mondschein, S.V. Mailing Decisions in the Catalog Sales Industry. Manag. Sci. 1996, 42, 1364–1381. [Google Scholar] [CrossRef]
- Miglautsch, J.R. Thoughts on RFM scoring. J. Database Mark. Cust. Strat. Manag. 2000, 8, 67–72. [Google Scholar] [CrossRef]
- Chang, E.-C.; Huang, S.-C.; Wu, H.-H. Using K-means method and spectral clustering technique in an outfitter’s value analysis. Qual. Quant. 2009, 44, 807–815. [Google Scholar] [CrossRef]
- Miglautsch, J.R. Application of RFM principles: What to do with 1-1-1 customers? J. Database Mark. 2002, 9, 319–324. [Google Scholar] [CrossRef]
- Lumsden, S.-A.; Beldona, S.; Morrison, A.M. Customer Value in an All-Inclusive Travel Vacation Club: An Application of the RFM Framework. J. Hosp. Leis. Mark. 2008, 16, 270–285. [Google Scholar] [CrossRef]
- Wei, J.T.; Lin, S.Y.; Wu, H.H. A review of the application of RFM model. Afr. J. Bus. Manag. 2010, 4, 4199–4206. [Google Scholar]
- Ernawati, E.; Baharin, S.S.K.; Kasmin, F. A review of data mining methods in RFM-based customer segmentation. J. Phys. Conf. Ser. 2021, 1869, 012085. [Google Scholar] [CrossRef]
- Carrasco, R.A.; Blasco, F.; Herrera-Viedma, E. A 2-tuple Fuzzy Linguistic RFM Model and Its Implementation. Procedia Comput. Sci. 2015, 55, 1340–1347. [Google Scholar] [CrossRef]
- Carrasco, R.A.; Blasco, M.F.; García-Madariaga, J.; Herrera-Viedma, E. A Fuzzy Linguistic RFM Model Applied to Campaign Management. Int. J. Interact. Multimed. Artif. Intell. 2019, 5, 21. [Google Scholar] [CrossRef]
- Martínez, R.G.; Carrasco, R.A.; Garcia-Madariaga, J.; Gallego, C.P.; Herrera-Viedma, E. A comparison between Fuzzy Linguistic RFM Model and traditional RFM model applied to Campaign Management. Case study of retail business. Procedia Comput. Sci. 2019, 162, 281–289. [Google Scholar] [CrossRef]
- Kumar, V. Customer Lifetime Value: The Path to Profitability; Now Publishers Inc.: Norwell, MA, USA, 2008. [Google Scholar]
- Fader, P. Customer Centricity: Focus on the Right Customers for Strategic Advantage; Wharton Digital Press: Philadelphia, PA, USA, 2020. [Google Scholar]
- Bolton, R. A Dynamic Model of the Duration of the Customer’s Relationship with a Continuous Service Provider: The Role of Satisfaction. Mark. Sci. 1998, 17, 45–65. [Google Scholar] [CrossRef]
- Baesens, B.; Viaene, S.; Poel, D.V.D.; Vanthienen, J.; Dedene, G. Bayesian neural network learning for repeat purchase modelling in direct marketing. Eur. J. Oper. Res. 2002, 138, 191–211. [Google Scholar] [CrossRef]
- Malthouse, E.C. Scoring Models. In Kellogg on Integrated Marketing; Iacobucci, D., Calder, B., Eds.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2003; pp. 227–249. [Google Scholar]
- Berry, M.J.; Linoff, G.S. Data Mining Techniques, 2nd ed.; Wiley Publishing, Inc.: Indianapolis, IN, USA, 2004. [Google Scholar]
- Malthouse, E.C.; Blattberg, R.C. Can we predict customer lifetime value? J. Interact. Mark. 2005, 19, 2–16. [Google Scholar] [CrossRef]
- Rud, O.P. Data Mining Cookbook: Modeling Data for Marketing, Risk, and Customer Relationship Management; John Wiley & Sons: Hoboken, NJ, USA, 2001. [Google Scholar]
- Zhang, Y.; Bradlow, E.T.; Small, D.S. Predicting Customer Value Using Clumpiness: From RFM to RFMC. Mark. Sci. 2015, 34, 195–208. [Google Scholar] [CrossRef]
- Wong, E.; Wei, Y. Customer online shopping experience data analytics: Integrated customer segmentation and customised services prediction model. Int. J. Retail Distrib. Manag. 2018, 46, 406–420. [Google Scholar] [CrossRef]
- Dursun, A.; Caber, M. Using data mining techniques for profiling profitable hotel customers: An application of RFM analysis. Tour. Manag. Perspect. 2016, 18, 153–160. [Google Scholar] [CrossRef]
- Peker, S.; Kocyigit, A.; Eren, P.E. LRFMP model for customer segmentation in the grocery retail industry: A case study. Mark. Intell. Plan. 2017, 35, 544–559. [Google Scholar] [CrossRef]
- Hamdi, K.; Zamiri, A. Identifying and segmenting customers of pasargad insurance company through RFM model (RFM). Int. Bus. Manag. 2016, 10, 4209–4214. [Google Scholar]
- Weng, C.-H. Knowledge discovery of digital library subscription by RFC itemsets. Electron. Libr. 2016, 34, 772–788. [Google Scholar] [CrossRef]
- He, X.; Li, C. The Research and Application of Customer Segmentation on E-Commerce Websites. In Proceedings of the 2016 6th International Conference on Digital Home (ICDH), Guangzhou, China, 2–4 December 2016; pp. 203–208. [Google Scholar] [CrossRef]
- Rezaeinia, S.M.; Rahmani, R. Recommender system based on customer segmentation (RSCS). Kybernetes 2016, 45, 946–961. [Google Scholar] [CrossRef]
- Marisa, F.; Ahmad, S.S.S.; Yusof, Z.I.M.; Fachrudin, F.; Akhriza, T.M. Segmentation Model of Customer Lifetime Value in Small and Medium Enterprise (SMEs) using K-Means Clustering and LRFM Model. Int. J. Integr. Eng. 2019, 11. [Google Scholar] [CrossRef]
- Patel, Y.S.; Agrawal, D.; Josyula, L.S. The RFM-based ubiquitous framework for secure and efficient banking. In Proceedings of the 2016 International Conference on Innovation and Challenges in Cyber Security (ICICCS-INBUSH), Greater Noida, India, 3–5 February 2016; pp. 283–288. [Google Scholar]
- Hosseini, Z.Z.; Mohammadzadeh, M. Knowledge discovery from patients’ behavior via clustering-classification algorithms based on weighted eRFM and CLV model: An empirical study in public health care services. Iran. J. Pharm. Res. 2016, 15, 355. [Google Scholar]
- Dachyar, M.; Esperanca, F.M.; Nurcahyo, R. Loyalty Improvement of Indonesian Local Brand Fashion Customer Based on Customer Lifetime Value (CLV) Segmentation. IOP Conf. Ser. Mater. Sci. Eng. 2019, 598, 012116. [Google Scholar] [CrossRef]
- Monalisa, S.; Nadya, P.; Novita, R. Analysis for Customer Lifetime Value Categorization with RFM Model. Procedia Comput. Sci. 2019, 161, 834–840. [Google Scholar] [CrossRef]
- Maćkiewicz, A.; Ratajczak, W. Principal components analysis (PCA). Comput. Geosci. 1993, 19, 303–342. [Google Scholar] [CrossRef]
- Karamizadeh, S.; Abdullah, S.M.; Manaf, A.A.; Zamani, M.; Hooman, A. An overview of principal component analysis. J. Signal Inf. Process. 2013, 4, 173. [Google Scholar] [CrossRef]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Paul, L.C.; Suman, A.A.; Sultan, N. Methodological analysis of principal component analysis (PCA) method. Int. J. Comput. Eng. Manag. 2013, 16, 32–38. [Google Scholar]
- Bryant, F.B.; Yarnold, P.R. Principal-Components Analysis and Exploratory and Confirmatory Factor Analysis; American Psychological Association: Washington, DC, USA, 1995. [Google Scholar]
- Suh, E.; Noh, K.; Suh, C. Customer list segmentation using the combined response model. Expert Syst. Appl. 1999, 17, 89–97. [Google Scholar] [CrossRef]
- Kaymak, U. Fuzzy target selection using RFM variables. In Proceedings of the Joint 9th IFSA World Congress and 20th NAFIPS Interna-tional Conference (Cat. No. 01TH8569), Vancouver, BC, Canada, 25–28 July 2001; pp. 1038–1043. [Google Scholar]
- Hsieh, N.C. An integrated data mining and behavioural scoring model for analysing bank customers. Expert Syst. Appl. 2004, 27, 623–633. [Google Scholar] [CrossRef]
- Tsai, C.-Y.; Chiu, C.-C. A purchase-based market segmentation methodology. Expert Syst. Appl. 2004, 27, 265–276. [Google Scholar] [CrossRef]
- Buckinx, W.; Poel, D.V.D. Customer base analysis: Partial defection of behaviourally loyal clients in a non-contractual FMCG retail setting. Eur. J. Oper. Res. 2005, 164, 252–268. [Google Scholar] [CrossRef]
- Coussement, K.; Poel, D.V.D. Improving customer attrition prediction by integrating emotions from client/company interaction emails and evaluating multiple classifiers. Expert Syst. Appl. 2009, 36, 6127–6134. [Google Scholar] [CrossRef]
- Chen, Y.L.; Kuo, M.H.; Wu, S.Y.; Tang, K. Discovering recency, frequency, and monetary (RFM) sequential patterns from customers’ purchasing data. Electron. Commer. Res. Appl. 2009, 8, 241–251. [Google Scholar] [CrossRef]
- Hosseini, S.M.S.; Maleki, A.; Gholamian, M.R. Cluster analysis using data mining approach to develop CRM methodology to assess the customer loyalty. Expert Syst. Appl. 2010, 37, 5259–5264. [Google Scholar] [CrossRef]
- Li, Y.-M.; Lin, C.-H.; Lai, C.-Y. Identifying influential reviewers for word-of-mouth marketing. Electron. Commer. Res. Appl. 2010, 9, 294–304. [Google Scholar] [CrossRef]
- Sekhavat, Y.A.; Fathian, M.; Gholamian, M.R.; Alizadeh, S. Mining important association rules based on the RFMD tech-nique. Int. J. Data Anal. Tech. Strateg. 2010, 2, 1–21. [Google Scholar] [CrossRef]
- Albadvi, A.; Norouzi, A.; Sepehri, M.M.; Amin Naseri, M.R. An Integrated Pareto/NBD-fuzzy weighted RFM model for customer segmentation in non-contractual setting. J. Bus. Manag. 2014, 6, 417–440. [Google Scholar]
- Güçdemir, H.; Selim, H. Integrating multi-criteria decision making and clustering for business customer segmentation. Ind. Manag. Data Syst. 2015, 115, 1022–1040. [Google Scholar] [CrossRef]
- Song, M.; Zhao, X.E.H.; Ou, Z. Statistic-based CRM approach via time series segmenting RFM on large scale data. In Proceedings of the 9th International Conference on Utility and Cloud Computing, Shanghai, China, 6–9 December 2016; pp. 282–291. [Google Scholar]
- Li, H.; Yang, X.; Xia, Y.; Zheng, L.; Yang, G.; Lv, P. K-LRFMD: Method of customer value segmentation in shared trans-portation filed based on improved K-means algorithm. J. Phys. Conf. Ser. 2018, 1060, 012012. [Google Scholar] [CrossRef]
- Hajmohamad, M.M.; Rahimi, N.; Sasanizadeh, B. PRFM Model Developed for the Separation of Enterprise Customers Based on the Distribution Companies of Various Goods and Services. J. Syst. Manag. 2021, 6, 77–99. [Google Scholar] [CrossRef]
- Hwang, S.; Lee, Y. Identifying customer priority for new products in target marketing: Using RFM model and TexRank. Marketing 2021, 17, 125–136. [Google Scholar]
- Chen, Q.; Huang, M. Rough fuzzy model based feature discretization in intelligent data preprocess. J. Cloud Comput. 2021, 10, 1–13. [Google Scholar] [CrossRef]
- Bueno, I.; Carrasco, R.A.; Porcel, C.; Kou, G.; Herrera-Viedma, E. A linguistic multi-criteria decision making methodology for the evaluation of tourist services considering customer opinion value. Appl. Soft Comput. 2021, 101, 107045. [Google Scholar] [CrossRef]
- Herrera, F.; Martinez, L. A model based on linguistic 2-tuples for dealing with multigranular hierarchical linguistic contexts in multi-expert decision-making. IEEE Trans. Syst. Man Cybern. Part B 2001, 31, 227–234. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E. Aggregation operators for linguistic weighted information. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 1997, 27, 646–656. [Google Scholar] [CrossRef]
- Porcel, C.; Tejeda-Lorente, A.; Martínez, M.A.; Herrera-Viedma, E. A hybrid recommender system for the selective dis-semination of research resources in a technology transfer office. Inf. Sci. 2012, 184, 1–19. [Google Scholar] [CrossRef]
- Cheng, C.-H.; Chen, Y.-S. Classifying the segmentation of customer value via RFM model and RS theory. Expert Syst. Appl. 2009, 36, 4176–4184. [Google Scholar] [CrossRef]
- Chen, D.; Sain, S.L.; Guo, K. Data mining for the online retail industry: A case study of RFM model-based customer seg-mentation using data mining. J. Database Mark. Cust. Strategy Manag. 2012, 19, 197–208. [Google Scholar] [CrossRef]
- Liu, D.-R.; Shih, Y.-Y. Integrating AHP and data mining for product recommendation based on customer lifetime value. Inf. Manag. 2005, 42, 387–400. [Google Scholar] [CrossRef]
- Saaty, T.L. Decision making with the analytic hierarchy process. Int. J. Serv. Sci. 2008, 1, 83. [Google Scholar] [CrossRef]
- Kotler, P.T. Marketing Management; Pearson Education: London, UK, 2019. [Google Scholar]
- Pradel, B.; Sean, S.; Delporte, J.; Guérif, S.; Rouveirol, C.; Usunier, N.; Dufau-Joel, F. A case study in a recommender system based on purchase data. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 377–385. [Google Scholar]
- Öcal, M.E.; Oral, E.L.; Erdis, E.; Vural, G. Industry financial ratios—Application of factor analysis in Turkish construction industry. Build. Environ. 2007, 42, 385–392. [Google Scholar] [CrossRef]
- Hair, J.F.; Anderson, R.E.; Babin, B.J.; Black, W.C. Multivariate Data Analysis: A Global Perspective; Pearson Education: London, UK, 2010. [Google Scholar]
- Ali, S.B.; Mahdi, A.; Malihe, J. The effect of employees’ performance appraisal procedure on their intrinsic motivation. Int. J. Acad. Res. Bus. Soc. Sci. 2012, 2, 161. [Google Scholar]
- Cid-López, A.; Hornos, M.J.; Carrasco, R.A.; Herrera-Viedma E y Chiclana, F. Linguistic model of multi-criteria decision making with expressive richness output variable. Expert Syst. Appl. 2017, 83, 350–362. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Intensity of Importance | Definition | Explanation |
|---|---|---|
| 1 | Equal importance | Two activities contribute equally to the objective |
| 2 | Weak or slight | |
| 3 | Moderate importance | Experience and judgement slightly favour one activity over another |
| 4 | Moderate plus | |
| 5 | Strong importance | Experience and judgement strongly favour one activity over another |
| 6 | Strong plus | |
| 7 | Very strong or demonstrated | An activity is favoured very strongly over another; its dominance is demons |
| importance | trated in practice | |
| 8 | Very, very strong | |
| 9 | Extreme importance | The evidence favouring one activity over another is of the highest possible order of affirmation |
| Reciprocals of Above | If activity i has one of the above non-zero numbers assigned to it when compared with activity j, then j has the reciprocal value when compared with i. | |
| 1.1–1.9 | If the activities are very close | It may be difficult to assign the best value, but when compared with other contrasting activities, the size of the small numbers would not be too noticeable, however, they can still indicate the relative importance of the activities. |
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Random consistency index (R.I.) | 0 | 0 | 0.58 | 0.9 | 1.12 | 1.24 | 1.32 | 1.41 | 1.45 | 1.49 |
| CRITIC | REFLEXIVE | EVOLVING | SEASONAL | IMPULSIVE | |
|---|---|---|---|---|---|
| CRITIC | 1 | 4 | 3 | 9 | 3 |
| REFLEXIVE | 1/4 | 1 | 1/3 | 8 | 2 |
| EVOLVING | 1/3 | 3 | 1 | 9 | 2 |
| SEASONAL | 1/9 | 1/8 | 1/9 | 1 | 1/9 |
| IMPULSIVE | 1/3 | 1/2 | 1/2 | 9 | 1 |
| Matrix H | Matrix CRITIC | Matrix REFLEXIVE | Matrix EVOLVING | Matrix SEASONAL | Matrix ACCESSORIES | |
|---|---|---|---|---|---|---|
| Consistency Ratio | 0.089 | 0.030 | 0.004 | 0.037 | 0.004 | 0.000 |
| <0.1 | <0.05 | <0.05 | <0.05 | <0.05 | <0.05 |
| Matrix H | Matrix CRITIC | Matrix REFLEXIVE | Matrix EVOLVING | Matrix SEASONAL | Matrix ACCESSORIES | ||
|---|---|---|---|---|---|---|---|
| wCRITIC | 0.45 | wR | 0.18 | 0.23 | 0.10 | 0.08 | 0.44 |
| wREFLEXIVE | 0.15 | wF | 0.07 | 0.12 | 0.26 | 0.44 | 0.44 |
| wEVOLVING | 0.25 | wM | 0.75 | 0.65 | 0.64 | 0.47 | 0.11 |
| wSEASONAL | 0.03 | ||||||
| wIMPULSIVE | 0.13 |
| Global Fuzzy Linguistic 2-Tuple RFM Clusters | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Fuzzy linguistic 2-tuple RFMScore per product hierarchy clusters | WORSE | NEW | CHURN | TOP | Total | % | CRITIC | REFLEXIVE | EVOLVING | SEASONAL | IMPULSIVE |
| TOP ALL BUT NOT REFLEXIVE | 55 | 464 | 5669 | 6188 | 3% | ↑ | ↓ | ↑ | ↑ | ↑ | |
| TOP ALL BUT NO SEASONAL | 52 | 1354 | 5006 | 22,597 | 29,009 | 13% | ↑ | ↑ | ↑ | ↓ | ↑ |
| LOW IN ALL CATEGORIES | 55,064 | 18,706 | 11,022 | 750 | 85,542 | 39% | ↓ | ↓ | ↓ | ↓ | ↓ |
| GROWTH POTENTIAL | 5150 | 13,190 | 20,112 | 8730 | 47,182 | 22% | → | ↓ | ↓ | ↓ | → |
| HIGH POTENTIAL FOR REFLEXIVE AND SEASONAL | 465 | 7194 | 15,156 | 28,463 | 51,278 | 23% | → | ↓ | ↑ | ↓ | → |
| Total | 60,731 | 40,499 | 51,760 | 66,209 | 219,199 | 100% | |||||
| Linguistic Labels for Global RFMScore | Linguistic Labels for Global RFMScore | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VB | B | N | G | VG | Total | VB | B | N | G | VG | Total | ||||
| Linguistic labels for RFMScore per product hierarchy | VB | 23,862 | 3538 | 27,400 | Linguistic labels for RFMScore per product hierarchy | VB | 87% | 6% | 13% | ||||||
| B | 3538 | 44,075 | 7184 | 3 | 54,800 | B | 13% | 80% | 13% | 0% | 25% | ||||
| N | 7148 | 40,242 | 7409 | 54,799 | N | 13% | 73% | 14% | 25% | ||||||
| G | 39 | 7373 | 43,577 | 3811 | 54,800 | G | 0% | 13% | 80% | 14% | 25% | ||||
| VG | 3811 | 23,589 | 27,400 | VG | 0% | 7% | 86% | 13% | |||||||
| Total | 27,400 | 54,800 | 54,799 | 54,800 | 27,400 | 219,199 | Total | 100% | 100% | 100% | 100% | 100% | 100% | ||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez, R.G.; Carrasco, R.A.; Sanchez-Figueroa, C.; Gavilan, D. An RFM Model Customizable to Product Catalogues and Marketing Criteria Using Fuzzy Linguistic Models: Case Study of a Retail Business. Mathematics 2021, 9, 1836. https://doi.org/10.3390/math9161836
Martínez RG, Carrasco RA, Sanchez-Figueroa C, Gavilan D. An RFM Model Customizable to Product Catalogues and Marketing Criteria Using Fuzzy Linguistic Models: Case Study of a Retail Business. Mathematics. 2021; 9(16):1836. https://doi.org/10.3390/math9161836
Chicago/Turabian StyleMartínez, Rocío G., Ramon A. Carrasco, Cristina Sanchez-Figueroa, and Diana Gavilan. 2021. "An RFM Model Customizable to Product Catalogues and Marketing Criteria Using Fuzzy Linguistic Models: Case Study of a Retail Business" Mathematics 9, no. 16: 1836. https://doi.org/10.3390/math9161836
APA StyleMartínez, R. G., Carrasco, R. A., Sanchez-Figueroa, C., & Gavilan, D. (2021). An RFM Model Customizable to Product Catalogues and Marketing Criteria Using Fuzzy Linguistic Models: Case Study of a Retail Business. Mathematics, 9(16), 1836. https://doi.org/10.3390/math9161836