1. Introduction
While the development of modern portfolio credit risk models started in the 1980–1990 decade [
1] within the framework of the Basel Accords, it is with the great credit crisis of 2008 [
2] that increasing attention started to be paid to the precise determination of the structure of dependence among default events. It is well established [
3] that tails of the distribution of the value of asset/liabilities portfolios are dominated by the structure of dependence rather than by the other fundamental components of credit risk (i.e., the marginal probability and the severity associated with each future default event). The vast research interest in modeling the structure of dependence resulted in the formalization of the so-called copula theory [
4,
5]. This “language” was explicitly adopted by the second generation of portfolio credit models to describe the dependence among loss events [
6,
7,
8,
9].
In this regard, the calibration issues raised by a particular structure of dependence (or, equivalently, the corresponding copula) can be as important as the choice of the structure itself. Generally, calibrating the dependence structure of a portfolio model is a demanding task, given the large number of parameters needed to provide a realistic description of the modeled dependencies, and considering that, on the other hand, historical data are usually not numerous enough to fill the sample space in a way sufficient for a precise estimation of the parameters.
In this work, we address a typical real-life problem: how to choose the frequency of the historical time series of default used to calibrate a classic credit portfolio model, CreditRisk
, in order to provide the most accurate estimation of the structure of dependence parameters, or, in other words, how the calibration error “scales” with the time series frequency. This problem is especially relevant for all the cases when the debtors underlying a credit portfolio are small/medium enterprises. The lack of market information, such as CDS spread, stock price, or bond yield, forces to calibrate the model using a reduced-form approach based on historical cluster data, such as default rate time series associated with the economic sector of each debtor. This case is typical in activities such as credit insurance, surety, and factoring. In most cases, publicly available time series have a sampling period ranging from one to three months (e.g., [
10]), while the calibrated CreditRisk
model is used on a projection horizon that is at least one year long (e.g., the unwind period required to quantify a capital requirement both in Solvency 2 and in Basel 3 regulatory frameworks).
CreditRisk
[
11], disclosed in 1997, belongs to the first generation of portfolio credit risk models of “actuarial inspiration”. Applications of CreditRisk
to the credit insurance sector are documented in the literature well before the 2008 financial credit crisis [
12,
13], while research activity is still ongoing in the area of actuarial science [
14]. At present, CreditRisk
is still one of the financial and actuarial industry standards for the assessment of credit risk in portfolios of financial loans or credit/suretyship policies.
Despite the vast research activity on this model and its calibration, the issue of using two different time scales for calibration and projection remains not investigated to date. The research conducted to date on the calibration of CreditRisk
[
14] has addressed the issues related to the decomposition of a given covariance matrix among the time series, which is the final necessary step to complete the calibration of the model. However, the covariance matrix is obtained by the “classical” estimator, under the assumption that the sampling period of the time series and the projection horizon are equal.
This work shows that calibrating the model at a shorter time scale than the projection horizon is possible, nontrivial, and convenient. The internal consistency of the CreditRisk assumptions when simultaneously imposed at different time scales has been proved and guarantees that the investigated calibration mode is not ill-posed. However, the form of the covariance estimator needed to obtain a set of parameters coherent with a specific projection horizon, using time series with a smaller sampling period, depends on the two chosen time scales. Indeed, the proposed estimator coincides with the classical one only when calibration and projection time scales are equal. Finally, we show that calibrating at a smaller time scale than the projection one provides a more precise estimation of the model parameters. The estimation error and its dependence on the difference between the two time scales are discussed.
The article is organized as follows. In
Section 2, we summarize assumptions and features of the CreditRisk
model. In
Section 3, we discuss the internal consistency of the model assumptions when imposing them to be simultaneously true at different time horizons. The calibration of the model parameters, which define the dependence structure, is considered in
Section 4. The different degree of precision of the estimators defined at increasing time scales is discussed in
Section 5. The techniques introduced in this work are applied to a real-world case study in
Section 6. The main results are summarized in
Section 7.
2. The CreditRisk+ Model
The CreditRisk
model is a portfolio model developed by Credit Suisse First Boston (CSFB) by Tom Wilde [
15] and coworkers, first documented in [
11] and later widely discussed in [
16]. It is a model actuarially inspired in the sense that losses are due only to default events and not to other sources of financial risk, e.g., variation of the credit standing (the so-called “credit migration” effect). CreditRisk
can be classified as a frequency–severity model, cast in a single-period framework, with the peculiarity that a doubly-stochastic process (i.e., the Poisson–Gamma mixture) describes the frequency of default events. Loss severity is assumed to be deterministic, although this ansatz can be easily relaxed at the cost of some additional computational burden. However, severity-related issues can be neglected for what follows.
The structure of dependence of default events is described using a factor model framework, where factors are unobservable (i.e., latent) stochastic “market” variables, whose precise financial/actuarial identification is irrelevant since the model integrates on all possible realizations (“market scenarios”). Therefore, CreditRisk can be further classified into the family of factor models and, in particular, into the subfamily of conditionally independent factor models, since, conditionally on the values assumed by the factors, defaults are supposed (by the model) to be independent.
The structure of the model can be summarized as follows. Let
N be the number of different risks in a given portfolio and
the default indicator function of the
i-th risk (
) over the time horizon
. The indicator function
is a Bernoulli random variable such that
The “portfolio loss”
L over the reference time horizon
is then given by
where each exposure
is supposed to be deterministic.
In order to ease the semianalytic computation of the distribution of L, the model introduces a new set of variables , each replacing the corresponding indicator function (). The new variables are supposed to be Poisson-distributed, conditionally on the value assumed by the market latent variables.
Assumption 1 (CreditRisk
distributional assumption)
. Given a time horizon and a set of N risky debtors, the number of insolvency events generated by each i-th debtor over is distributed as follows:where is an array of independent r.v.’s such thatand the factor loadings are supposed to be all non-negative and to sum up to unity: The
parameters set
is equivalent to the classical shape-scale parameterization
of each Gamma distributed r.v.
, after having imposed the assumption
, that is stated in the original formulation of the CreditRisk
model. Hence, the
k-th scale parameter
is equal to the variance
of
. Given the independence among
’s, the covariance matrix
takes the form
Assumption 1 implies that
is the unconditional expected default frequency
where
and that the identity between the expected values of the original Bernoulli variable
and the new Poisson variable
is granted:
The portfolio loss is now represented by the r.v.
In [
11], the distribution of
is obtained by using a recursive method, further described in [
17]. The accuracy, stability, and possible variants of the original algorithm are discussed in [
16]. The same distribution can be easily computed through Monte Carlo simulation due to the availability of a dedicated importance sampling algorithm in [
18].
Notice that, although the distributions of L and differ, the expected value of the portfolio loss is the same .
In the language of copula functions, the structure of dependence implied by (
3) corresponds [
19] to a multivariate Clayton copula, i.e., an Archimedean copula where latent variables are Gamma-distributed (for the relation between Archimedean copula functions and factor models see, e.g., ([
9] [§2.1])). The copula parameters are the factor loadings
and they can be gathered, taking into account the normalization condition stated in Assumption 1, in an
matrix
:
which is, for typical values of
N and
K, much smaller than the
covariance matrix between the default indicators
.
Remark 1. This work is specifically focused on improving the estimation of the CreditRisk copula parameters . Further investigations on the properties of CreditRisk dependence structure, apart from those needed for the estimation improvement, and its comparison with the other copulae are beyond the scope of this study.
As shown in [
14], it holds
where
is the Kronecker delta. Equation (
12) allows the calibration of the factor loadings, and thus of the dependence structure of the CreditRisk
model, by matching the observed covariance matrix of historical default time series with model values. However, since the model is defined in a single-period framework, with a reference “forecasting” time horizon
, that is typically of 1 year, i.e.,
, it is not a priori evident how to use historical time series with a different frequency (e.g., quarterly) in a consistent way, when calibrating the model parameters. Naively, it is reasonable to expect that the larger the information provided by the historical time series (i.e., the higher the frequency), the better the calibration. This issue is addressed in the next sections.
3. CreditRisk+ Using Multiple Unwind Periods
The original CreditRisk formulation, summarized in Assumption 1, defines the model in a uniperiodal framework, where only one time scale is considered. In this section, we discuss the internal consistency of the model assumption when imposing it more than once at distinct time scales. In this context, the expression “internal consistency” means that it is possible and well-posed imposing Assumption 1 to be true at two distinct time scales. The same applies also considering a slightly modified version of the CreditRisk framework (i.e., imposing Assumption 2, introduced in the following, instead of Assumption 1).
Extending the original CreditRisk
formulation to a multiperiod framework enables the calibration of the model considering a time scale different from the one chosen for its application. The results presented in this section are applied in the next
Section 4 to estimate the elements of the matrix
Estimating
A is a fundamental step in order to complete the calibration of the model. In
Section 4 estimators are defined using historical series sampled with a period that is not necessarily equal to the projection horizon on which
and
are defined.
Section 5 shows the convenience of choosing a sampling period shorter than the projection horizon in order to evaluate
.
3.1. The Single Unwind Period Case
As discussed in
Section 2, in CreditRisk
each risk (i.e., debtor) is modeled by a Poisson distributed r.v.
, although the Bernoulli distribution is the natural choice to represent absorbing events, such as default. Assumption 1 is convenient in terms of analytical tractability since
distribution can be computed through a semianalytical method. However, in order to address the problem of calibrating CreditRisk
in a “roll-over” framework, defined by an arbitrary set of time intervals, it is useful to recover the Bernoulli representation of each debtor by introducing a new r.v.
.
Both the r.v. and its distribution parameter can take values larger than 1. This is formally correct, given that , despite not coping with the representation of absorbing events, that can occur at most once by definition. The so-called “Poisson approximation”, introduced by substituting with , is numerically sound as approaches to zero—a condition that is well fulfilled in most real world relevant cases.
Indeed, Assumption 1 implies that
where the distribution parameter is
It holds by construction
Computing the integral in (
15) and then approximating the term
with its second order Taylor series centered at
leads to the following result.
Proposition 1 (Asymptotic equivalence between Bernoulli and Poisson representation of risks)
. Let where is distributed according to Assumption 1. ThenFurther, Proposition 1 implies that
, provided that
. Moreover, the same result enables also the exact satisfaction of
, in case the stochastic parameter
is redefined through the substitution
, where
verifies the following modified version of (
16):
It is worth noticing that the substitution
discussed in
Section 2 implies the preservation of the expected value
due to the fact that it is done before the introduction of the market factors
. On the other hand, restoring the Bernoulli representation of each risk after having introduced the dependence structure requires the results presented in Proposition 1.
Proposition 1 permits the introduction of a slightly modified version of the CreditRisk model that is asymptotically equivalent to the original one stated in Assumption 1. The equivalence between the two models is further analyzed in the next sections.
Assumption 2 (Modified CreditRisk
distributional assumption)
. Given a time horizon and a set of N risky debtors, the number of insolvency events generated by each i-th debtor over is represented by the r.v. , where the distribution parameter satisfies (14). Assumptions on market factors Γ and factor loadings Ω
remain the same stated in Assumption 1. In Assumption 2 the linear dependence of the parameters from the latent variables has been replaced with a log link function. Thus, the modified version of CreditRisk is also referred to as “exponential” in the following.
3.2. The Multiple Unwind Periods Case
This section investigates the consequences of imposing the internal consistency of Assumption 1 or Assumption 2 at distinct time scales. Assumptions 3 and 4 are introduced hereinafter, in order to specify the family of parameters that have to be considered at the distinct time intervals where the model is applied.
The following assumption guarantees the internal consistency at different time scales of the classical CreditRisk model, defined in Assumption 1.
Assumption 3 (CreditRisk
parameters at different time scales)
. Let be a partition of the time interval . Let Assumption 1 be satisfied over each j-th interval by the set (), where is the r.v. representing the i-th risk observed during the j-th interval and the following holds for the associated set of parameters and market factors:where . Further, the following assumption guarantees the internal consistency at different time scales of the modified version of CreditRisk model, introduced in Assumption 2.
Assumption 4 (Modified CreditRisk parameters at different time scales). Let be a partition of the time interval . Let Assumption 2 be satisfied over each j-th interval by the set (), where is the r.v. representing the i-th risk observed during the j-th interval. The associated set of parameters and market factors satisfies the same assumptions stated in Assumption 3.
Finally, for the sake of simplicity, the additional Assumption 5 is introduced, with regard to the independence among market factors considered at different times. However, being possible that real-data time series violate Assumption 5, this assumption is weakened in the following
Section 3.3.
Assumption 5 (Non-autocorrelated market factors)
. Given Assumption 3, let Considering the assumptions introduced above, we prove that CreditRisk is internally consistent when extended to a roll-over framework.
Theorem 1 (Internal consistency of CreditRisk
in absence of autocorrelation)
. Let us consider a set of risks (), observed through a time horizon , and an arbitrary partition of , such that Assumptions 3 (“CreditRisk parameters at different time scales”) and Assumption 5 (“non-autocorrelated market factors”) are verified withfor each , and . Then satisfies Assumption 1 (“CreditRisk distributional assumption”) over .The statement above remains true replacing Assumption 3 with Assumption 4 (“modified CreditRisk parameters at different time scales”) and Assumption 1 with Assumption 2 (“modified CreditRisk distributional assumption”), ceteris paribus.
This result shows that extending the CreditRisk model to a multiperiod framework is well-posed.
Remark 2. The choice implies no loss of generality, since a different (positive) constant is equivalent to redefine the variances of the market factors .
3.3. Internal Consistency and Autocorrelation in Time Series
As shown in
Section 2, the dynamics of each parameter
is induced by the latent Gamma factors only. Imposing Assumption 5 to any (arbitrarily short) time scale implies that considered time series
must exhibit zero autocorrelation. Hence autocorrelation must be completely absent from the historical default frequencies too.
However, this requirement could not be satisfied by the observed time series used in calibrating the model. Indeed, we need to verify that the model can preserve its internal consistency if autocorrelation has to be considered.
The purpose of this work is to investigate whether it is possible and convenient to calibrate the CreditRisk model at a time scale that copes with the available historical data (i.e., the sampling period of the historical time series) instead of using the same time scale needed for projections (usually bigger). Hence, in case it is not possible to preserve the internal consistency of the model at each arbitrary time scale, due to the presence of autocorrelation, it is sufficient to ask that it holds up to the smallest of the two time scales of interest—the historical sampling period and the projection horizon.
Let us specialize to the constant mesh case . This choice copes with a typical real case, where the sampling period of the available historical time series is constant and the considered projection horizon is a multiple of it. Under these premises, a weakened version of Assumption 5 is introduced.
Assumption 6 (Autocorrelated market factors)
. Given Assumption 3, for each k-th latent variable, considered at the time scale , a time-invariant ACF exists, such thatFurthermore, the following closure with respect to the addition holdsfor a couple of shape and scale parameters. Assumption 6 is considered instead of Assumption 5 to state the following alternate version of Theorem 1.
Theorem 2 (Internal consistency of CreditRisk
model in presence of autocorrelation)
. Let us consider a set of risks (), observed through a time horizon , and a uniform partition of , such that Assumption 3 (“CreditRisk parameters at different time scales”) and Assumption 6 (“autocorrelated market factors”) are verified withfor each , and . Then satisfies Assumption 1 (“CreditRisk distributional assumption”) over .The statement above remains true replacing Assumption 3 with Assumption 4 (“modified CreditRisk parameters at different time scales”) and Assumption 1 with Assumption 2 (“modified CreditRisk distributional assumption”), ceteris paribus.
Assumption 6 can be either well-posed or ill-posed, depending on the considered
. The trivial case
for each
copes with Assumption 5. Correlated Gamma variables, as well as the distributional properties of the sum of Gamma variables, have been intensively studied in the literature, and this is still an active research field [
20,
21,
22,
23], due to its relevance for information technology. At least in case of identically distributed Gamma variables—such as
in our framework—with ACF obeying to a power-law
the distribution of the sum
is known to be approximately Gamma [
20], while more generical cases imply the sum to be distributed differently [
22,
23]. Moreover, it is known that partial sums of independent Gamma variables can be used to generate sequences of (auto)correlated Gamma variables [
21].
Remark 3. The exponential ACF in Equation (27) provides a non-trivial case that satisfies Assumption Assumption 6 and, thus, Theorem 2. In the following Section 4.4, Theorem 2 permits the estimation of A in presence of autocorrelated time series. Equation (27) is then considered in Section 5.3 to investigate numerically the estimators introduced in Section 4.4. However, to date, a general framework is missing to tell whether a given lets the partial sums remain (approximately) Gamma distributed, with the exception of exponential ACFs. The estimators introduced in
Section 4.4 to consider autocorrelation in time series are still applicable to an inconsistent framework, provided that at least the latent variables
(defined onto the projection horizon) are Gamma distributed and
satisfy the mean and variance requirements implied by Assumption 6 above.
4. Calibration of the Structure of Dependence
The model is calibrated based on a partition of the risks in H homogeneous sets , . In this context “homogeneity” means that two risks belonging to the same set have the same vector of factor loadings . The sets have an explicit time dependence since they can change by the occurrence of defaults. On the contrary, the structure of dependence, defined by is supposed to be time-independent.
Hence, solving the calibration problem requires the evaluation of
H factor loading vectors , that link each of the homogenous clusters to the K latent variables;
K volatilities , needed to specify the distribution of each of the latent variables.
The calibration is achievable by a two-step procedure. Firstly, the matrix
, introduced in
Section 3, is estimated. Then,
A is decomposed under the proper constraints in order to evaluate
and
separately. This section describes a method to complete the first step, providing an estimator of
A both for the single and the multiple unwind period cases, with a moment-matching approach that allows expressing
as a function of the covariance matrix among the historical frequencies of default. The second step is addressed later in
Section 6, which provides an example of calibration using a real data set.
Adopting the standard CreditRisk
Assumption 1, Equation (
12) can be used to link the covariance matrix among the historical frequencies of default with the matrix
A. In
Section 4.1,
is provided in the case of historical frequencies of default, sampled with the same tenor of the projection horizon. In
Section 4.2,
is generalized to the case of historical frequencies of default sampled with an arbitrary tenor.
Furthermore, in
Section 4.3,
is determined under the exponential version of the CreditRisk
framework, introduced in Assumption 2. Thanks to this modified assumption, the corresponding functional form of
is simpler than the one obtained in
Section 4.2 based on Assumption 1.
Section 4.2 and
Section 4.3 cope with Assumption 5, that implies absence of autocorrelation in time series. The final
Section 4.4 uses Assumption 6 instead, generalizing the main results presented in this section to the case where autocorrelation must be taken into account. In this case, the simpler form of
obtained in
Section 4.3 comes in handy in the generalization to the non-trivial ACF case.
4.1. The Single Unwind Period Case
The first case considered is that of a single unwind period
. For each set
, let
,
and
. The expected values of
and
are respectively:
Remark 4. The slight abuse of notation in (28) is done to avoid the introduction of a new symbol to represent . However, the letters chosen for indexing risks and cluster (“i” and “h” respectively) are maintained in the following of this work, clarifying the meaning of the “q” symbol each time it is used. For any pair of sets of risks
, the covariance between the default frequencies is:
that, using Equation (
12), becomes:
Equation (
31) shows the relation between the observed covariance of default frequencies and the factor loadings, describing the structure of dependence of the model.
Moreover, assuming that all risks in a given homogenous set share the same factor loadings, the above expression simplifies to:
Notice that the second term in Equation (
32) is present only when
, and becomes quickly negligible as
grows (since
).
Equation (
32) enables the estimation of
A over the same time scale
used for projections:
4.2. The Multiple Unwind Period Case
Let us consider a set of
H time series defined using a constant step
. As done in
Section 2, each variable introduced in
Section 4.1 for the time interval
can be redefined over each of the considered time intervals. Namely, in the following we use the set of observables quantities
, measured either over
or
or a generic time interval
. For the latter two cases, we introduce the notation
and
, respectively. Further, the variables
are introduced.
In CreditRisk, arises from a doubly stochastic process, since each absorbing event is generated conditioned to the latent systematic factors. For the sake of simplicity, we neglect the idiosyncratic uncertainty brought by each . In fact, for large enough, the Bernoulli (or Poisson) r.v.’s contributions to the variance of are dominated by the contribution of . This permits the following assumption.
Assumption 7 (Large clusters)
. For each cluster () and each time interval it holds Then the following holds:
Proposition 2 (CreditRisk
scale-invariance law)
. Let us consider a set of risks (), observed through a time horizon and classified into a set of homogenous clusters (). Let Assumption 3 (“CreditRisk parameters at different time scales”), Assumption 5 (“non-autocorrelated market factors”) and Assumption 7 (“large clusters”) hold with for each and for each uniform partition of , (). Then, the couple satisfies the conservation lawfor each pair of clusters and each . Proposition 2 is one of the main results of this work. It allows to build an estimator of
using default frequencies
defined on a different time scale
. The dependence upon
m of the precision of the covariance estimator is discussed in
Section 5.
Indeed, applying Proposition 2 to Equation (
33), it is possible to calibrate the dependence structure of the CreditRisk
model, by first determining the elements of the
A matrix as
for any
, and then decomposing
A, thus obtaining a separate estimate of the
parameters. The SNMF decomposition can be performed, e.g., by using the technique described in [
14].
4.3. The Exponential Case
In this section the problem of calibrating the dependence structure is addressed using the exponential form of the model introduced in Assumptions 2 and 4. Theorem 1 proves that also the exponential form remains consistent when considering multiple unwind periods. Since now
variables are used instead of the corresponding
, the frequencies
and their complements
are replaced by
and
, defined by the substitution
in
and
definitions, respectively. Furthermore, it is convenient to introduce the following
where
The notation introduced in
Section 4.2 for
are extended to the exponential case as well. Hence, the sets of symbols
and
are also used. The log link function that relates
and
simplifies the form of the scale invariariance law presented in Proposition 2. Indeed, in this case the following holds.
Proposition 3 (Modified CreditRisk
scale-invariance law)
. Let us consider a set of risks (), observed through a time horizon and classified into a set of homogenous clusters (). Let Assumption 4 (“modified CreditRisk parameters at different time scales”), Assumption 5 (“non-autocorrelated market factors”) and Assumption 7 (“large clusters”) hold with for each and for each uniform partition of , (). Then obey to the conservation lawfor each pair of clusters and each . Proposition 3 states a conservation law for the modified version of the model, likewise Proposition 2 in the original (i.e., Poisson–Gamma) CreditRisk
framework. The form obtained for the LHS of Equation (
40) is simpler than the corrisponding LHS of Equation (
36). In general, this framework results to be more tractable than the original model. This is especially useful when estimating
A given a non-trivial ACF, as shown in the next
Section 4.4.
In this case,
A can be estimated as
where we have neglected the contribution of
. Definition (
38) and Proposition 3 imply
for each
.
4.4. Handling Autocorrelated Time Series in Calibration
In this section a generalization of estimators in Equations (
37) and (
42) is provided, in case Assumption 5 has to be replaced with Assumption 6 due to the presence of autocorrelation in time series. We preliminarily report below a second order approximation that comes in handy to generalize Equation (
37).
We now consider again the relation between
and
implied by Proposition 2, under the presence of autocorrelation for the latent variables. Unlike in
Section 3.2, in this case covariance terms at delay
cannot be nullified.
Replacing Equation (
43) into Equation (
44), we have
where
is a compact notation for the sum of all the terms of order 3 or greater. Given that
, the approximation
is numerically sound in practice and implies the following generalization of
in Equation (
37)
where the autocorrelation term
is defined as
This completes the extension of the linear case presented in
Section 4.2 to autocorrelated time series.
The exponential case—introduced in
Section 4.3—turns out to be more tractable, since the linear structure implied by Proposition 3 allows us to avoid approximations similar to the one applied to extend the linear case above. Indeed, only the simplification implied by Assumption 5 must be abandoned, implying
This is implied by the fact that
are still identically distributed for the same
h but not independent. Hence, the estimator in Equation (
42) becomes
where
5. The Advantage of a Short Sampling Period
Let us consider a -long projection period and a set of historical time series of defaults that span a (past) time interval of length . Typical examples can be year and . Moreover, let the historical time series be sampled with a period , which is m times smaller than (i.e., ). Considering year, realistic assumptions are (quarterly time series) or (monthly time series). Therefore, the considered time series are defined over intervals of length , defined by a schedule .
This section discusses the precision improvement achievable by calibrating the model on historical default time series with a period smaller than the time horizon on which the calibrated model is applied. Indeed, the statistical error on the determination of
A depends on
m, i.e., on the sampling frequency of the observations, as shown in
Section 5.1. Further, given Assumption 7 (“large clusters”), the statistical error can be written as a closed-form function of
m, as
approaches to zero (
). In the following, the assumption of “small” volatilities is referred to as “Gaussian regime”, because it implies
(
), as discussed in the proof of Theorem 3.
As in the previous
Section 3 and
Section 4, both the standard CreditRisk
framework (Assumptions 1 and 3) and the modified “exponential” version (Assumptions 2 and 4) are discussed hereinafter.
In applications where
’s are scarcely populated or
’s are not negligible, Theorem 3 is not guaranteed to cope with observations. This case is addressed in
Section 5.2, where the robustness of the closed-form expression (
54) is investigated by Monte Carlo simulations.
A numerical approach is maintained in
Section 5.3 as well, where the estimation error of
at different time scales is measured in presence of autocorrelation, following the generalization introduced in
Section 3.3 and
Section 4.4. In this case, the exponential version of the model comes in handy: indeed, it is observed that the error on the estimator introduced in (
46) (i.e., standard CreditRisk
version) does not decrease at increasing
m, while the opposite is true for the estimator presented in (
49) (i.e., exponential CreditRisk
version).
In
Section 4, the
estimator has been presented in multiple versions, depending on the considered model (standard or exponential version of CreditRisk
), the chosen sampling period
and the presence or absence of autocorrelation. Thus, it is worth introducing a compact notation to identify the different versions of
.
The expressions for
presented in (
37) and (
46) are addressed as “linear” estimators (as opposed to “exponential”) in the following. In these cases the symbol
is used, where
L stands for “linear” and
is the ratio between the projection and calibration time scales.
On the other hand, the expressions for
presented in (
42) and (
49) are addressed as “exponential” estimators and so the symbol
is used.
For the sake of brevity, when L or E is omitted, refers to both the cases and, when m is omitted, refers to the case.
The improvement in statistical precision with respect to the estimate with no subsampling, can be quantified by the following ratio:
Symbol
and its further specifications
and
can be used as well. The last short notation that results to be convenient in the following is
where
,
and
(
) are i.i.d. variables quantified using a sampling period
.
Remark 5. The notation “” refers to the fact the covariances involved in the definitions must be replaced with the corresponding sample estimators, when applying to historical time series. The same applies to the symbol .
5.1. Precision of at Different Time Scales under the Gaussian Regime
The following result quantifies the precision gain of performing CreditRisk
model calibration by historical time series available at increasing sampling frequencies. As anticipated, the precision of the estimated parameters increases as the sampling period decrease. This result holds under Assumption 7, in the limit
and considering absence of autocorrelation. The cases where some
is small (i.e., it does not verify Assumption 7) or where some
is not negligible are addressed numerically in the next
Section 5.2—showing that the precision is still increasing as shorter sampling periods are considered. The introduction of autocorrelation is addressed in
Section 5.3.
Theorem 3 (Estimation errors under Gaussian regime)
. Let us consider a set of risks, observed through a time interval and classified into a set of homogenous clusters (). Let Assumption 3 (“CreditRisk parameters at different time scales”), Assumption 5 (“non-autocorrelated market factors”) and Assumption 7 (“Large clusters”) hold with for a given uniform partition of , (; ). Let be the estimate of A needed to calibrate the CreditRisk model in order to project losses over the time horizon , such that and . Then the following is true for :Equation (54) remains true also considering Assumption 4 (“modified CreditRisk parameters at different time scales”) instead of Assumption 3. 5.2. Beyond the Gaussian Regime: Numerical Simulations
In this section we verify that both the estimators
and
are more precise at increasing
m. The closed-form results obtained in the Gaussian regime, discussed in
Section 5.1, hold when the factor volatilities
are much less than 1. Increasing
(
) the Gaussian regime becomes less satisfactory and the difference of precision amongst determinations with different values of
m becomes smaller. However, the error of
remains monotonically decreasing in
m, even far from the Gaussian regime conditions.
We considered a case study with a two-factors market (
,
). The couple of systematic factors induces the dependence between two populations of risks, as per the weights reported in
Table 1.
The volatilities (
,
) associated to the factors are chosen according to seven different scenarios (indexed by
), respectively as
For each scenario, the distributions of the estimators
and
(
) have been determined using
simulations of
where
(
) and
(
) is the number of risks belonging to each cluster. For both estimators the dynamic
is that reported in (
14). All risks belonging to the same cluster are supposed to have the same unconditioned intensity of default
To investigate the additional contribution to the error
, generated by the finiteness of each cluster, different values of
have been considered. In particular, the number of claims per each elementary temporal step
is extracted from a binomial distribution with parameter
For simplicity’s sake, it is assumed that each defaulted risk is instantly replaced by a new risk, keeping the population of each cluster constant in time. Finally, the case
(absence of binomial source of randomness) is also considered.
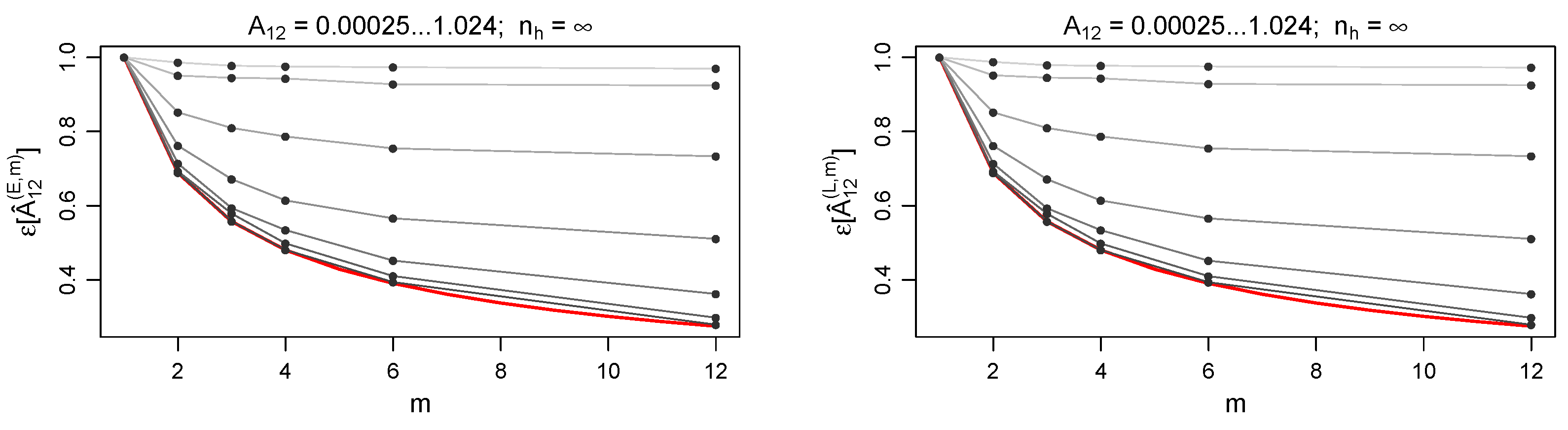
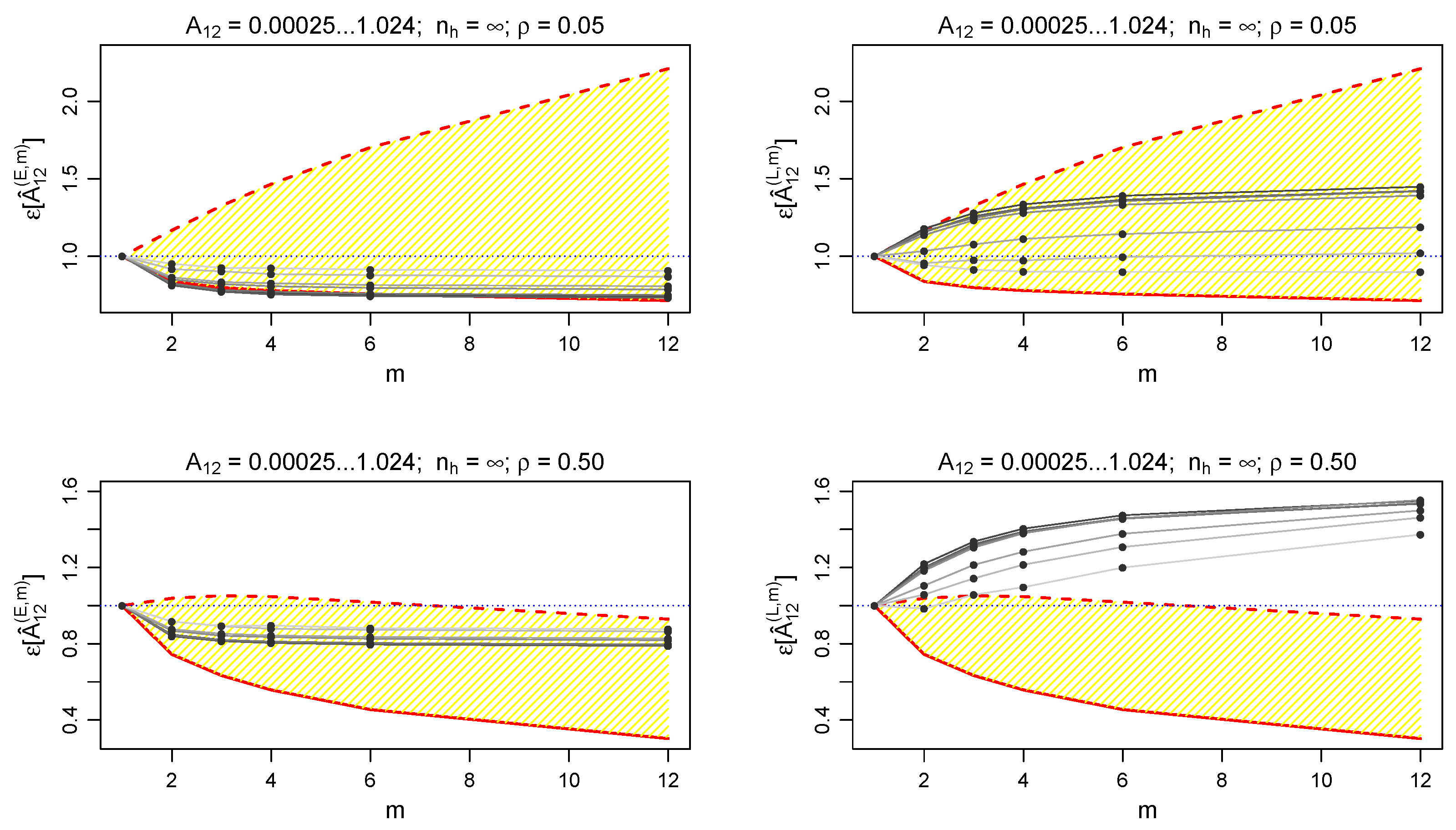
Figure 1 shows the behaviour of
as a function of
m, comparing various choices of
. In this case we are not considering yet the contribution to error due to the finite population (
for each cluster
h). Equation (
54) (red curve) is almost perfectly verified by the least volatility scenario (
). At increasing volatility values (brighter curves), the gain in precision obtained at higher
m is reduced, as well as the accordance with Equation (
54).
Since the transformation of
moving away from the Gaussian regime (i.e., increasing
) is smooth, estimating
with
remains convenient even for
, despite the fact that Equation (
54) is not verified anymore.
Comparison between the left and the right panel of
Figure 1 shows that the above argument holds both in the linear and in the exponential case. This fact is also verified for all the other results of this section.
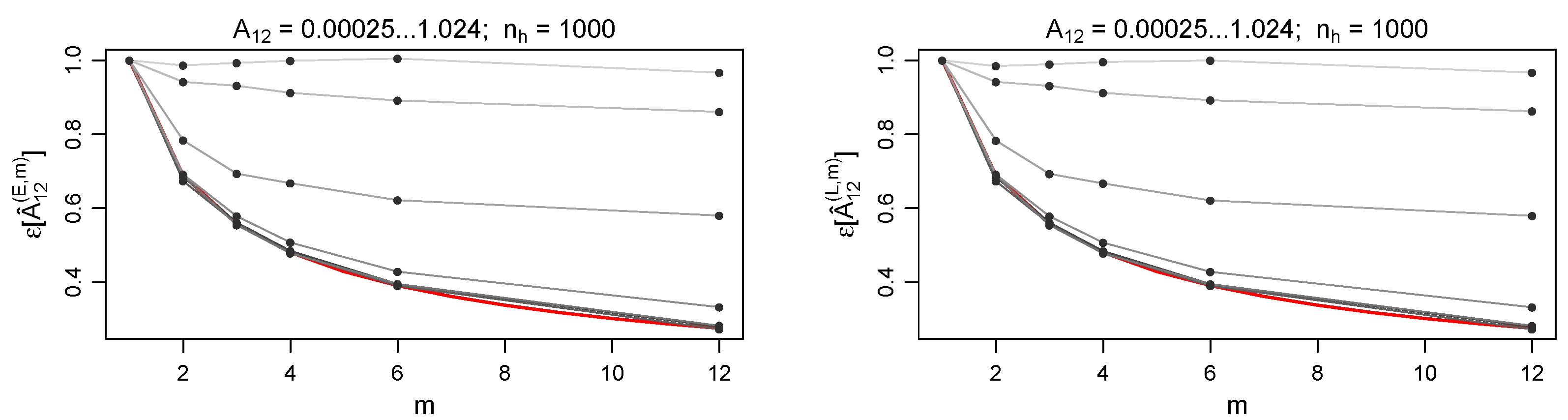
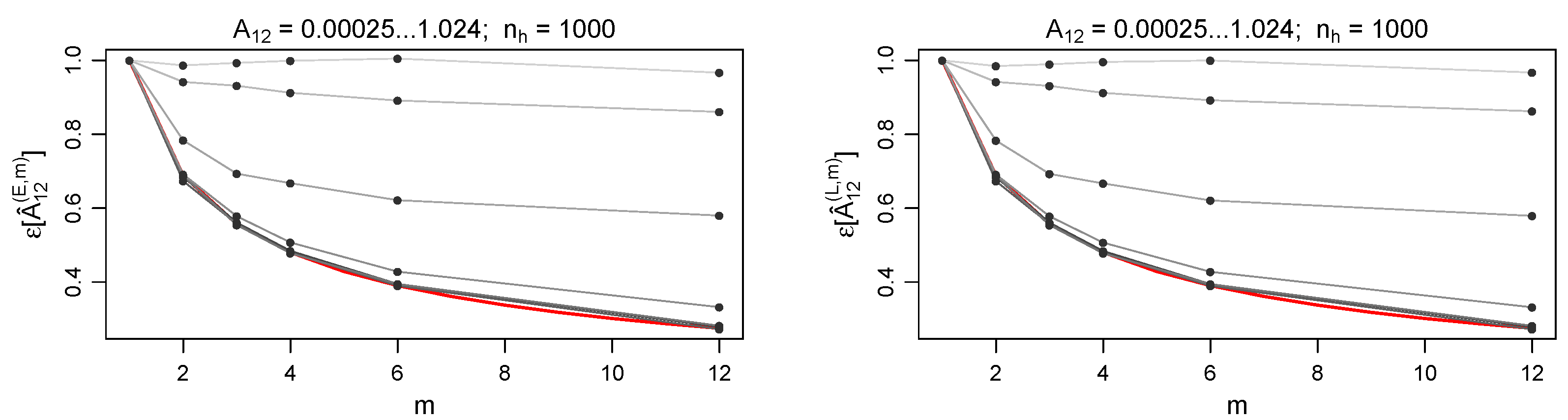
The results shown in
Figure 1 are numerically checked against the case of finite portfolio populations: we tested each of the
declared in Equation (
57). Even the smallest size considered (i.e.,
—
Figure 2), that is affected by the largest binomial contribution to the error, leads to results comparable to the ones observed in the
case. The size
is considered to be a limiting value for a realistic case.
We simulated the distribution of the estimator
as a function of
m, testing all the possible combinations of
and
declared in Equations (
55) and (
57).
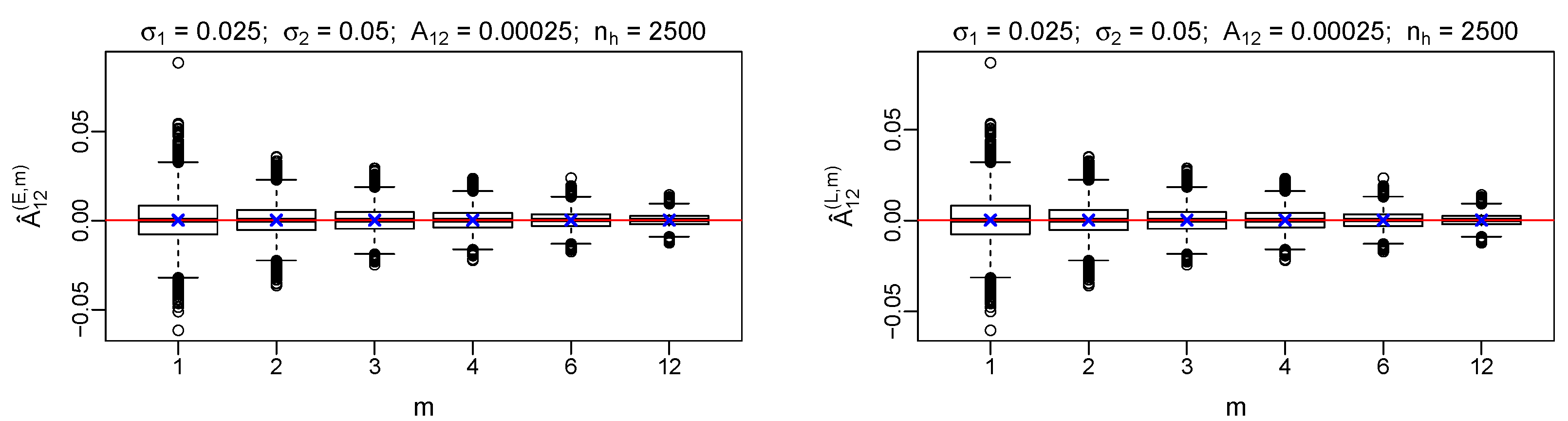
Figure 3 reports an example of the results. All the other considered
couples resulted to have a similar behavior. The visual comparison between
(blue “X” symbol) and
level (red horizontal line) shows that indeed
is unbiased, both in the linear and in the exponential case (Equations (
37) and (
42) respectively). The dispersion around the mean reduces at increasing
m, in agreement with both Equation (
54) and the numerical results in
Figure 1 and
Figure 2.
As implied by
Figure 2 and
Figure 3, the number of risks
does not play a relevant role (if any) in computing the ratio
, while the absolute value of the standard error
is sensitive to the size of the portfolio.
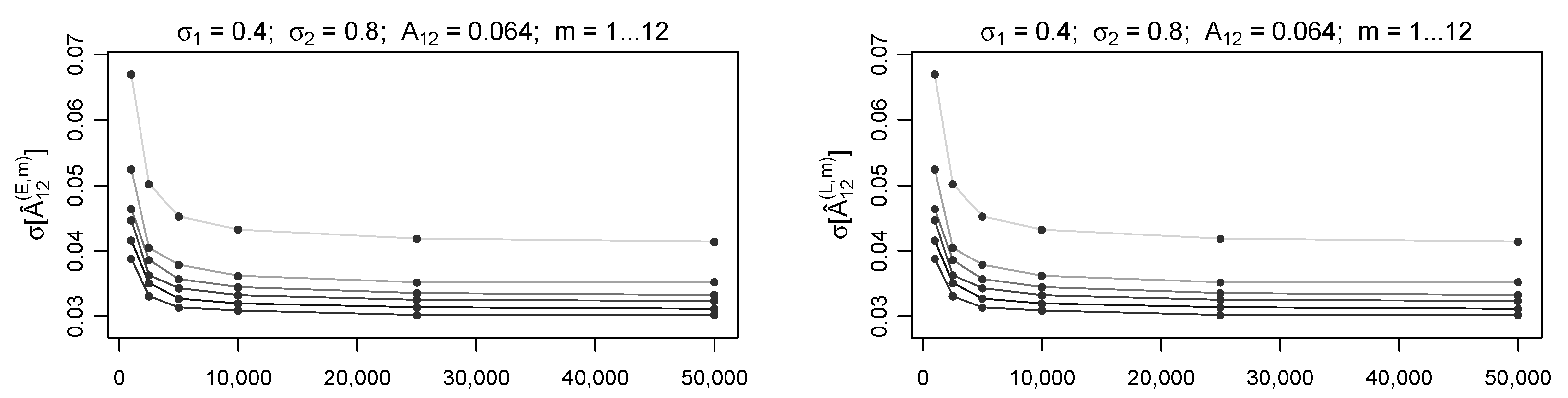
This fact is confirmed by the results shown in
Figure 4, where the estimates of
have been arranged as functions of
at fixed
and
m values. As expected, the standard error is greater when considering smaller
values, while the dependence on
of the error disappears quickly as approaching
.
5.3. Estimation Error in Presence of Autocorrelation
In
Section 5.2 the precision gain at increasing
m is measured in absence of autocorrelation. In this section, the same numerical simulations are re-performed, introducing autocorrelation and comparing the results against the theoretical estimation of
. The effect of autocorrelation on
is discussed in
Appendix B.
The numerical setup introduced above in
Section 5.2 has been maintained, with a further assumption about ACF. Indeed, we assume that each latent variable (
) obeys to the following ACF law, discussed in
Section 3.3
where the considered
values are
and
. For
cases, we have considered ACF’s resulting for the latent variables time series
obtained by the clustering operation
given the aforementioned ACF law at
time scale. Since the contribution of the finite population to the error has been shown to be neglectable in
Section 5.2, simulations in presence of autocorrelation have been performed under
assumption only.
Figure 5 shows that the estimator
remains more precise at increasing
m, even in presence of autocorrelation. The analytical results obtained in the Gaussian regime (i.e., theoretical superior and inferior estimates of
—dashed and solid red lines in
Figure 5), discussed in
Appendix B, are in good agreement with the numerical results obtained in the considered set up. All the empirical measures of
are included between the two theoretical limits (yellow areas).
Moreover, precision gain (i.e.,
) at
is also possible when using the estimator
, introduced in Equation (
46). However, due to the approximation introduced in this case, the estimator is not convenient (i.e.,
) in the majority of the considered configurations.
6. An Application to Market Data
This section provides an example of the calibration technique applied to a real-world data set. The calibration technique is applied to a set of historical time series of bad loan rates supplied from the Bank of Italy. “Bad loan” is a subcategory of the broader class “Non-Performing Loan” and it is defined as exposures to debtors that are insolvent or in substantially similar circumstances [
24].
In particular, the chosen data set is composed of the quarterly historical series TRI30496 (
) over a five year period (from 1 January 2013 to 31 December 2017,
,
). The data are publicly available at [
10]. The time series are supplied by the customer sector (“counterpart institutional sector”) and geographic area (“registered office of the customer”). The latter, in the example, is held fixed to a unique value that corresponds to the whole country (Italy).
Table 2 and
Table 3 report the definition of the 6 different clusters and their main features.
By inspection of
Table 3, it is possible to perform a rough estimate of
. Equation (
14) implies that the following holds for coefficients of variation
(
):
Furthermore, the normalization requirement over the factor loadings
implies
Hence we can state that
has the same order of magnitude of
. Since
, results in
Section 5.2 suggest that this data set is not far from the Gaussian regime and so there is an appreciable increase of precision in estimating
with
.
is estimated by applying Equation (
42) over a one-year period. The results obtained for
(
) are reported in
Table 4.
The elementwise precision gain for
,
, obtained under the Gaussian regime assumption, is shown in
Table 5. This result is obtained applying definition (
51) and Equation (
A25) both to the cases
and
. Equation (
A25) has been shown to be valid under the Gaussian regime, discussed in
Section 5.1.
In this case, the preliminary decomposition of
, that would be needed using the Monte Carlo method discussed in
Section 5.2, is not needed.
According to Equation (
54), the elements of
reported in
Table 5 should be all approximately equal to
, since they should depend only on the couple
(
and
in this case). However, in a real world case like the one considered, the assumption of zero autocorrelation is satisfied with a different precision by each time series
. Furthermore, the estimated covariance matrices might need to be regularized (indeed the Higham regularization algorithm [
25] was used both for
and
series). Hence, a different ratio for each element
is justified. Nonetheless, it is worth noticing that all the ratios reported in
Table 5 have the same order of magnitude of the predicted value
.
Knowledge of the historical number of risky subjects
for each cluster (
) at each observation date (
) allows to take into account the binomial contribution to the error
, both for
(quarterly series) and
(yearly series), although the finiteness of the population does not add a relevant contribution to the error, as already observed in
Section 5.2.
Table 6 provides Monte Carlo estimation of
, which considers also the role of
. Since the values in
Table 6 provide a measure of the error in the determination of
, it turns out that the estimates reported in
Table 4 are elementwise consistent one with the other.
The Monte Carlo estimation of
, as done in
Section 5.2, requires the a priori knowledge of the true dependence structure
. Since this is a case study, we do not have an a priori parameterization of the calibrated model. Hence, we have used
estimated from
instead, as a proxy of the “true” model parameters. The computation of
from
is discussed below.
In order to complete the CreditRisk
calibration, we have to decompose
and find the factor loadings matrix
together with the vector of systematic factors variances
. To do so, we use the Symmetric Non-negative Matrix Factorization (SNMF), an iterative numerical method to search an approximate decomposition of
which satisfies the requirements of the CreditRisk
model over
(i.e., all elements
and
). The application of SNMF to CreditRisk
is discussed in detail in [
14]. In the following, we give evidence only of the implementation details necessary to address this case study. Being an iterative method, SNMF requires an initial choice of matrixes
such that
. It is not required that
, nor all the elements of
and
have to be positive. We set
from the eigenvalues decomposition of
.
For the considered data set, the eigenvalues decomposition returned the set of eigenvalues and eigenvectors reported in
Table 7.
We use the notation to address the quantities over which the normalization requirement of CreditRisk has not been imposed yet.
Since more than the
of variance is explained by the first three eigenvectors, we reduced the dimensionality of the latent variables vector to be
. Hence we define
and
. In general, SNMF aims to minimize iteratively the cost function
where
is the Frobenious norm, eventually weighted, and
is a free parameter to weight the asymmetry penality term. Further details on the method are available in [
14]. The application of SNMF method, together with the normalization constraint over the factor loadings, leads to the result reported in
Table 8.
A reasonable economic interpretation supports the set of parameters resulting from the calibration process described above. Indeed, factor loadings associated with the “general government” sector () are completely distinct from the ones of the other sectors (i.e., this is the only sector mainly depending on the factor): this fact copes with the different nature of the public entities from the ones belonging to the other considered sectors. Furthermore, “companies” () share approximately the same dependence structure. The same applies when considering “households” (). Finally, the “institutions serving households” sector () shares the same latent factor () but shows a different balance between idiosyncratic and systematic factor loadings compared to “households”, that is coherent with the nature of a sector strongly linked to “household” sectors, despite not being completely equivalent.
Results in
Table 8 have been used to quantify the estimation errors reported in
Table 6.
7. Conclusions
In this work, we have investigated how to calibrate the dependence structure of the CreditRisk model, when the sampling period of the (available) default rate time series is different from —the length of the future time interval chosen for the projections.
Preliminarily, we proved that CreditRisk remains internally consistent when imposing the underlying distributional assumption to be simultaneously true at different time scales (Theorem 1). The model internal consistency is robust against the introduction of autocorrelation, depending on the considered ACF form (Theorem 2).
Then the problem has been approached in terms of moment matching, providing two asymptotically equivalent formulations for estimating the covariance matrix
A amongst the systematic factors of the model (Propositions 2 and 3). The choice between the two estimators of
A, provided in Equations (
37) and (
42), depends on the functional form (linear or exponential) that links the probability of claim/default and the latent variables. Both the estimators are explicitly dependent on the ratio
, allowing for the calibration of the model at a time scale that is different from the one chosen for applying the calibrated model. Both the estimators have been generalized to autocorrelated time series in Equations (
46) and (
49), although only the latter (i.e., exponential case) is an exact result, while a second-order approximation has been adopted for the linear case.
Furthermore, calibrating the model on a shorter time scale than the projection horizon has been proved to be convenient in terms of reduced estimation error on . Analytical expressions for the error are provided in the Gaussian regime (i.e., small variances of the latent variables) by Theorem 3. In contrast, the case of increasing variance has been investigated numerically, confirming that, in general, the precision of the calibration is higher when employing historical data with a shorter sampling period. It has been verified that the convenience of calibrating the model at short time scales also remains in the presence of autocorrelation, although this is guaranteed only in the exponential framework, where an exact correction term is available.
Finally, the techniques presented in this work are shown to be numerically sound when applied to a real, publicly available data set of Italian bad loan rates.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}