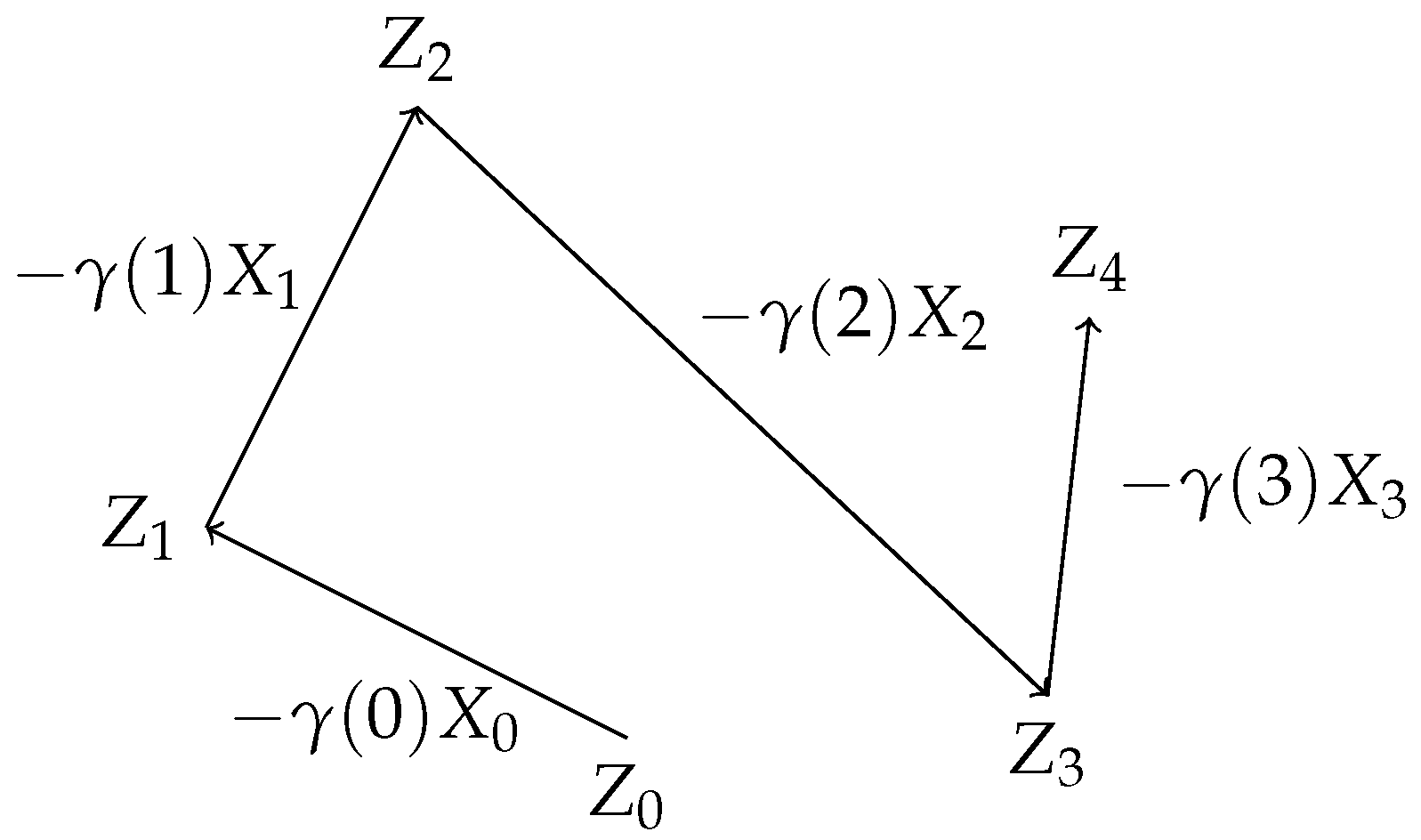2.1. Locally Bounded Stochastic Processes and Objective of the Work
The difference between two random variables of a stochastic process is a random variable known as increment. We say that random variable
with
is an
s-increment at time
t. For example, the 1-increments of a stochastic process
Z are
We focus our attention to a decomposition of into , such that is a positive real valued function and is a stochastic process on .
Definition 1. Let Z and X be stochastic processes and a function. Then is a decomposition of 1-increments of Z if Name X the director process of Z and γ the learning rate, and note it by .
This way of expressing a process allows to define
with respect to
, which gives us control of the difference between both values by means of
, as
Figure 1 shows. This is very useful if we intend to analyse the convergence of a stochastic process.
As represented in
Figure 1, we can think of
as the value of the process at time
t, while
is the vector going from
to
. For the article, it is important to remember this, since we are constantly referring to
as points in
while
are managed as direction vectors in
. This distinction is only practical for our purposes.
The trajectories of stochastic approximation algorithms, such as stochastic gradient descent (SGD), are indeed samples of stochastic processes. Furthermore, they are usually expressed by means of their decomposition of 1-increments, as can be seen in the following examples.
Example 1. SGD [4] is the cornerstone of machine learning to solve the function optimization problem. The objective of SGD is to minimize an objective function for some unknown probability distribution and random variable defined on . This function l is known as loss function, and it is usually differentiable with respect to η, allowing the definition of SGD aswhere are estimates of . We can see , and, therefore, SGD, as a stochastic process. Indeed, letbe the product probability space (This space is guaranteed to exist according to Kolmogorov extension theorem (see for example Theorem 2.4.4 and following examples in [13])) over infinite sequences. Hence we can define the stochastic process X on such that where for every it is . This implies that is a decomposition of 1-increments of SGD. In addition, we observe that depends only on last observation and t, which is known as a non-stationary Markov chain.
Example 2. This example is worked in [5]. Again, we focus on the function optimization problem, using the same notation as in previous example. In this case, the estimation update of the minimum is defined aswhere is a matrix in known after information available at time t and , where Y is a function mapping each to a random variable on the same probability space . Similarly as in previous example, Y can be thought as a random variable in the product probability space (Equation (4)) that depends on previous , such that for every it is . If we define , then is a decomposition of 1-increments of Z with . Here, Z is not a (non-stationary) Markov chain, since may depend on for all .
The naming of
as learning rate is commonly used in the machine learning research branch [
4,
14,
15,
16]. The director process
X determines the direction
at time
t of the update Equation (
1) with
as reference point, while
specifies a certain distance to travel along that direction
. Moreover we demand some constraints to both factors. Condition imposed to
is usually found in the literature [
3,
4,
5]. A learning rate
holds the standard constraint if;
Before we show the condition for the director process X, we fix some notation used throughout the article. Consider the natural filtration generated by stochastic process Z, that is, for all . Then is a filtration and by definition Z is adapted to .
Intuitively, every
of a filtration is a
-algebra that classifies the elements of
. For example, if
is the set of colours,
can gather warm and cold colours into separate and complementary sets. The fact that a random variable
is
-measurable implies that
sends all warm colours to the same value and all cold colours also to the same value. Somehow
is then not providing any additional information about elements of
beyond the classification of
. The sequence
is increasing, in the sense that
for all
t. Therefore, a filtration characterizes space
with sequentially higher levels of information or classification. Denote
the conditional expectation given
[
10]. Recall that if
Y is a random variable in
then
is in turn a
-measurable random variable.
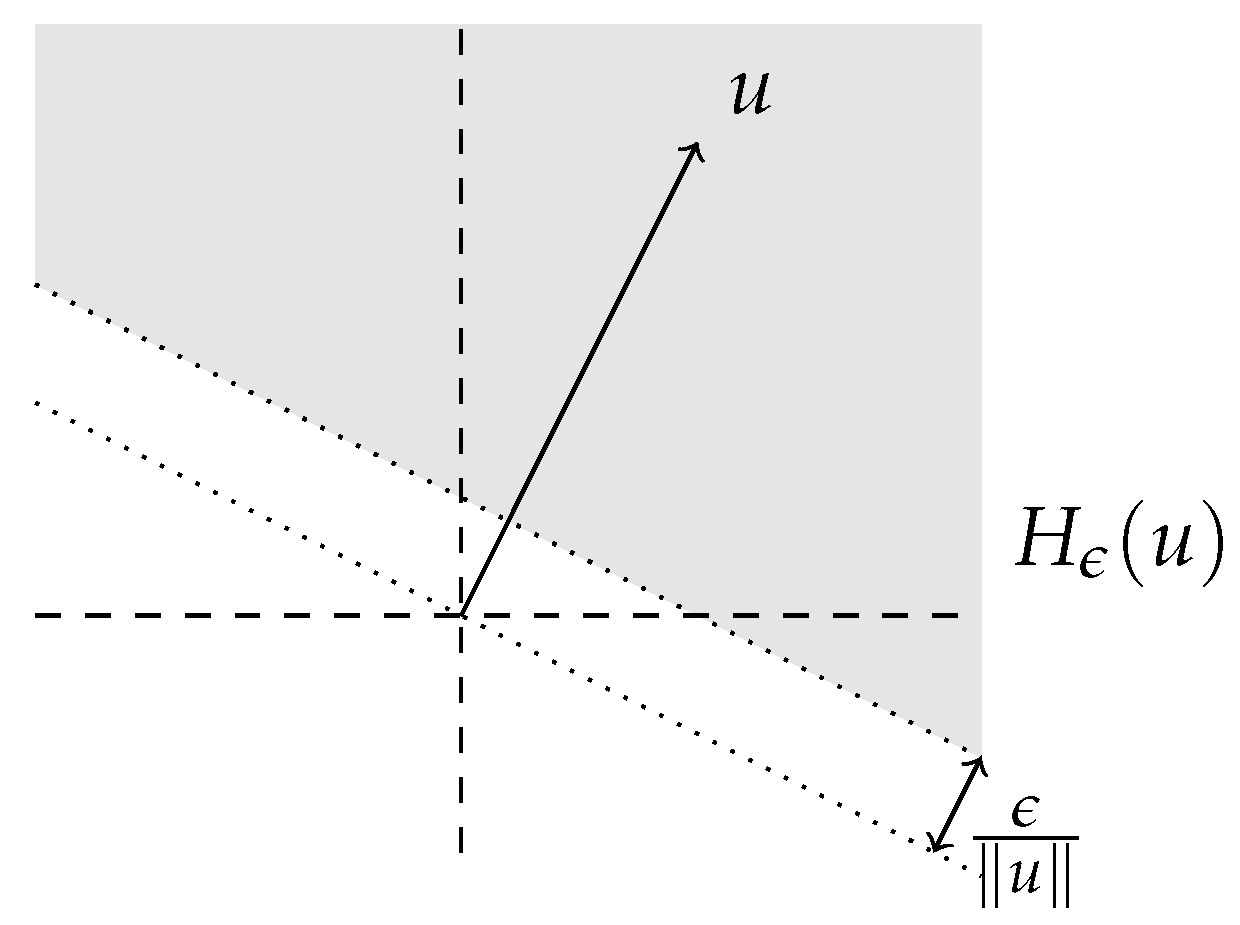
Hence, if
then
X is locally and linearly bounded by function
if
These two constraints are finally combined to present the kind of stochastic processes we are interested in.
Definition 2. Let Z be a stochastic process and be a function. We say that Z is locally bounded byif there is a decomposition of 1-increments with γ holding the standard constraint and X locally and linearly bounded by ϕ.
Furthermore, if a.s. we say is the initial point of Z.
For instance, Examples 1 and 2 observed in this section define Z as a locally bounded process. We see it below.
Example 3. Recall Example 1. In the same reference [4], the optimization algorithm is asked to hold additional conditions in order to prove its convergence. We added the convergence theorem in Appendix A. Some of the conditions arewhere is the optimal point of L. Standard constraint to γ is clearly asked. Moreover is a starting point. It remains to be seen if X is locally and linearly bounded by some function . Indeed, if we define , then the property is easily checked. Hence Z is locally bounded by ϕ with initial point .
Example 4. Recall Example 2. Convergence theorem in [5], which is added in the Appendix A, demands below conditions;where L is a function to optimize. For this example, Z is then locally bounded by with initial point . Just as an observation, property of being determined after information available at time t, is the same as seeing as a -measurable random variable over the product probability space. We are interested on studying the almost sure convergence of
Z to a point
. A stochastic process
Z almost surely (a.s.) converges to a point
if
Examples 3 and 4 show us that we can understand the results in [
4,
5] as the almost sure convergence of some locally bounded processes. In this paper, we are interested in characterizing the almost sure convergence of locally bounded processes. The objective of this work is to create a theory that allows to prove the a.s. convergence of locally bounded processes that covers Examples 3 and 4 and whose applicability generalizes to a wider set of processes, such as the one described below:
Example 5. Assume the function defined in , and the optimization method Z defined by its director process where and are positive definite and symmetric matrices. For simplicity, this example shows a stochastic process with no random phenomena associated. We wonder about the convergence of process Z, and if so, whether it converges to the point of that optimizes function f. From Theorems A1 and A2 found in the literature (included in Appendix A) it is not possible to prove a.s. convergence of Z, since conditionsBottou resemblance and C.3, respectively, are not satisfied. That is, because is possibly negative a.s. Further on, Z is assumed to be locally bounded by where is its corresponding decomposition of 1-increments, unless otherwise indicated.
2.3. Expected Direction Set
We now define one key object of our work named the expected direction set. It focuses on gathering all directions that the update may take at time t conditioned to . Before the definition we provide some concepts and notation.
Random variable
determines all expected directions of
Z at time
t that the stochastic process may follow assuming
. For example, if
is an observation, then
is a vector pointing to the expected update direction departing from point
given
. Denote the expected direction of
Z at
and time
t as
The expected direction from point
of Equation (
11) depends on
. That is, the path followed until reaching
matters. For instance, if
are different observations, such that
, then possibly
. We collect all expected directions at
and time
t in the vector set below;
The tools to define the expected direction set at after time are given, so we proceed to its formal definition.
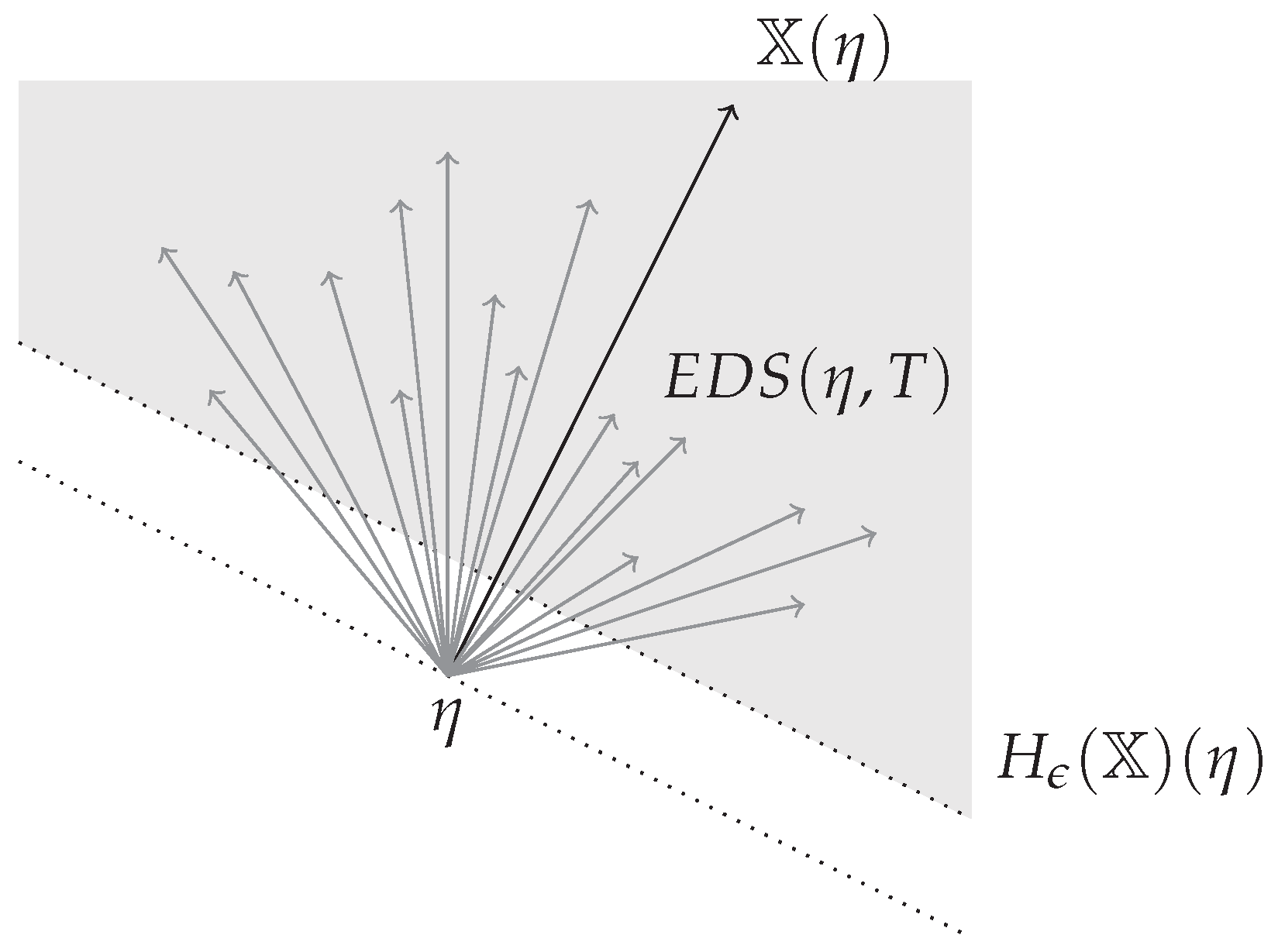
Definition 3. Let . Define the expected directions set of Z at after time as With a few words, is a vector set containing all expected directions (provided by the director process X) conditioned to for every outcome such that where . In Definition 3, depends on T. That is because to assess the convergence of an algorithm it is not important to consider all expected directions throughout all the process. For example, if an algorithm converges we can modify randomly all directions of the director process for just a particular time , and the resulting algorithm still converges. Roughly speaking, only the tail of a process matters to determine the convergence property. This concept is better addressed with Definition 4 in next section.
Example 6. Recall Example 1. Assume that Z is then SGD. Then is a singleton. Indeed, is the same vector for all and all ω with and hence with any with . Finally This is the case of any non-stationary Markov chain.
2.4. Essential Expected Direction Set
Convergence property of an algorithm relates closely to directions followed after time as T tends to infinity. Equivalently, the direction set appearing repeatedly through the whole optimization process matters, while directions set only contemplated for a finite amount of iterations changes nothing, in terms of convergence guarantee. This direction set is named the essential expected directions set in this article.
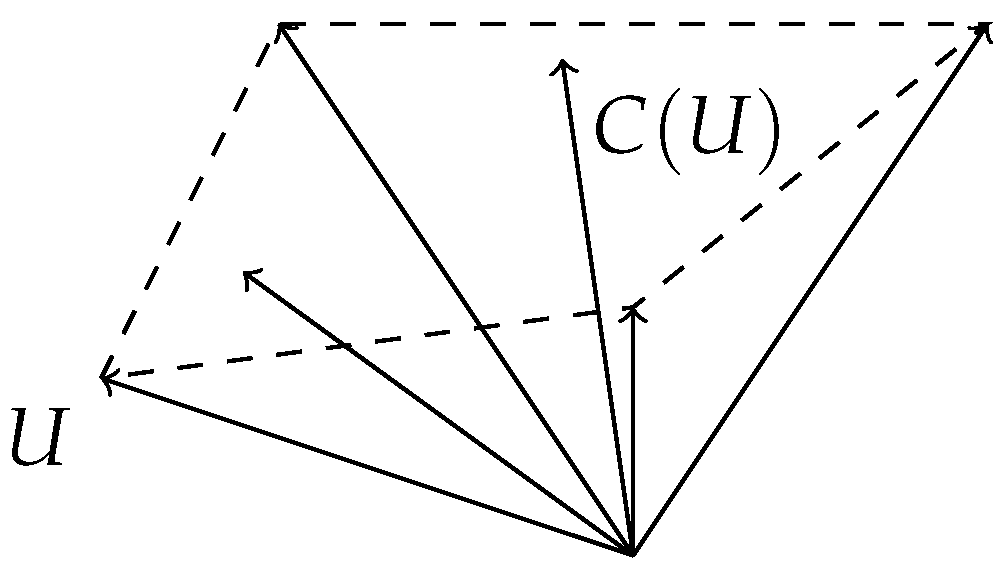
To define properly the essential expected directions set, we will use the convex vector subspace of a given vector set. Given a vector set
U in
, let
be the smallest convex vector subspace containing
U. See
Figure 2 as an illustrative example. Observe that
is always closed, but it may be unbounded.
Definition 4. Let . Define the essential expected directions set of Z at η as Example 7. Assume Z is any non-stationary Markov chain, such that SGD in Example 1. Then for any T. Indeed, we have seen in Example 6 that for any and where . Hencefor any with . Definition of
delimits the smallest subspace where all directions at
tend to. Clearly,
is also convex and closed (possibly empty). Deeper properties of this set lead to identify divergence symptoms. For example, if it is empty or unbounded, we face instability of the process at
. To see this, observe below result. The proof can be found in the
Appendix B.
Corollary 1. Let . Then is a non-empty bounded set if, and only if, there exists , such that is bounded.
This result relates with instability properties of Z. If is empty or unbounded, then the algorithm is unstable at , since expected directions with arbitrarily large norms exist after enough iterations. Clearly, if this situation is found for all points near the optimum, the algorithm can not converge to the solution. It is desirable instead that is compact (bounded) for some T for every , or equivalently, that is compact (bounded) and not empty.
In fact, since we are interested in the case where Z is locally bounded by (recall Definition 2), we can assume that is a non empty compact set, by virtue of below results.
Proposition 1. Let stochastic process Z be locally bounded by ϕ. Then is a non-empty compact set.
Proof. We know that
X is locally and linearly bounded. Hence, applying Jensen’s inequality
Let and , such that for some . Therefore, every has bounded norm by , implying that is a non-empty compact set. □
Below corollary is a consequence of Proposition 1 and Corollary 1.
Corollary 2. Let stochastic process Z be locally bounded by ϕ. Then is a non-empty compact set for all .




{kind=link}
{kind=link}
{kind=link}
{kind=link}