1. Introduction
Learning to program computers is a difficult process for novice students and also for professors [
1] as it not only means acquiring new knowledge, but also fundamentally applying this knowledge to solve problems [
2]. Therefore, it becomes a complex task because it requires students to master higher-order cognitive skills [
3].
On the other hand, analogies are didactic tools used very frequently in the educational sector, and from observed experience, it can be determined that some professors include them in their curricula in a planned way and others adopt them only as part of their explanations in the classroom.
The scientific literature reports few experiences in the use of analogies for teaching-learning in a CS1, one of which is Collece 2.0, a programming learning environment that has been extended with mixed reality techniques and uses the analogy of roads and traffic signs for the study of recursion concepts [
4,
5,
6]. In turn, Sukamto and Megasari [
7] developed a model that converts source code into analogy images using state machines for teaching programming.
Likewise, there are models based on analogies for teaching processes in fields other than a CS1, which is how Strunz and Louie [
8] proposed a model of analogy between energy storage and data processing in a computer for teaching electrical engineering concepts. For his part, Plappally [
9] designed a model of analogies using concept maps for the first year of mechanical engineering courses. Additionally, Stockdill et al. [
10] implemented a correspondence-based analogy model to choose representations of mathematical problems, among others.
Taking into consideration the ease of incorporating analogies in a teaching–learning process and the difficulties reported in the scientific literature in a CS1, this study proposed a model of knowledge discovery based on machine learning and text mining, which took as input the didactic teaching strategy with analogies and obtained a set of patterns for possible scenarios that can be used with a greater degree of assertiveness when presenting an analogy on a CS1.
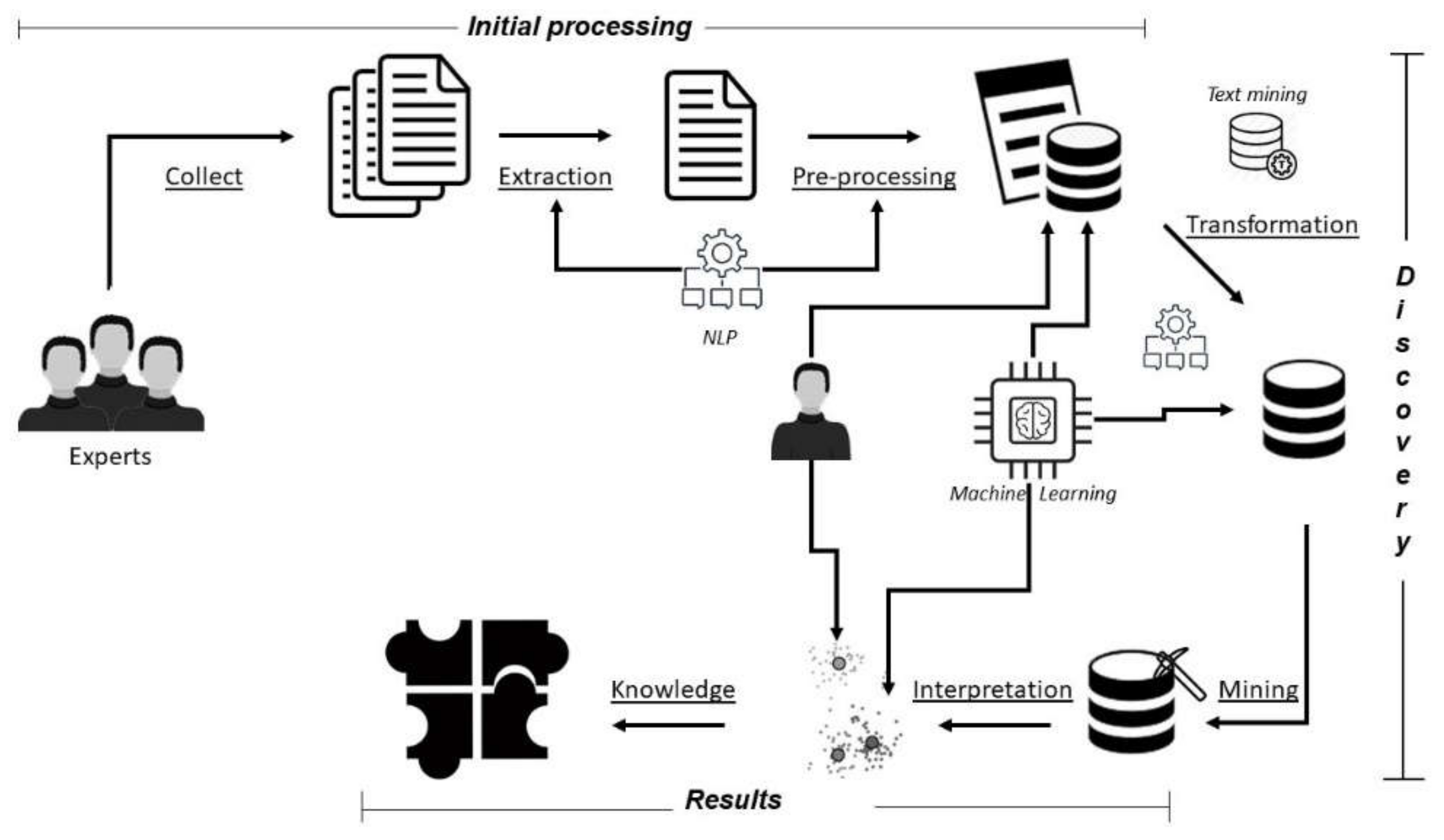
In the collection of information, a semi-structured questionnaire was used to characterize the formal and non-formal analogical processes developed in a CS1 class with university professors. This questionnaire collected information from the professor, university, course, and the analogies used in teaching for four fundamental concepts: entries, exits, conditionals, and cycles. The application of this survey reported a total of 570 examples of analogies in 15 universities of five countries (Mexico, Ecuador, Argentina, Spain, and Colombia) with a total of 33 expert professors in CS1 in university computer programs that train professionals in software development.
The proposed knowledge model has three stages: initial processing, discovery, and results. In the initial processing stage, three activities were developed: data collection, extraction, and pre-processing. Two major activities were carried out in the discovery stage: transformation and mining. Finally, in the results stage, the findings found in the mining process were complemented, for this, techniques of the Natural Language Toolkit (NLTK) were implemented through three tasks: linguistic analysis, textual analytics, and experimental analysis.
The rest of this paper is organized as follows. In
Section 2, the conceptual foundation of this study is presented.
Section 3 describes the proposed discovery model.
Section 4 shows the results obtained when applying the discovery model. In
Section 5, the results are discussed and a structural model is presented to build analogies to teach programming concepts, which was validated through an experiment with professors and students. Finally,
Section 6 presents the conclusions and future work.
2. Literature Review
The teaching–learning processes of computer programming are a complex task, and the results of teaching programming show that professors do not generate a reflection process in problem solving [
11], despite the fact that many students do not have previous training experience in this field [
12]. This is even more so when facing a CS1 as it requires cognitive abstraction skills, logical-mathematical skills, and the ability to solve problems algorithmically [
13].
On the other hand, the learning of programming through analogous representations is a process where work has been underway for some years and whose purpose is to reduce the level of abstraction that programming requires to facilitate its understanding [
4,
14].
This is how an analogy is a connection of two situations with common relationship patterns between them and they are bidirectional [
15]. Analogy can be explanatory when it poses new concepts and principles in familiar terms and creative when it stimulates the solution and the identification of a new problem and the generalization of knowledge [
16].
The word analogy was initially a mathematical concept that meant proportion [
17] and it was later considered as not corresponding to an identity of two relationships but rather ensures a similarity of correlations [
18]. That is to say, it does not imply symmetric equality, but a relationship used with the purpose of clarifying, structuring, and evaluating the unknown from what is known [
19].
Through analogies, one can develop the creativity, imagination, skills, and attitudes necessary for the critical use of scientific models and to shape one’s own reality [
20,
21]. Furthermore, analogies can stimulate the professor-researcher to take into consideration the students’ prior knowledge [
22].
Analogies are a relevant research topic in the field of teaching [
23]. Currently, there is an analog didactic model (ADM), which helps students find concepts that already exist in their cognitive structures on which a new learning is built [
24].
Alternatively, artificial intelligence (AI) is a simulation of the human intelligence process in machines [
25,
26], where one of its most important fields is machine learning, which together with natural language processing (NLP) are contributing significantly to the development of science through research [
27].
In addition, Knowledge Discovery in Databases (KDD) is a process that facilitates findings and analysis with the purpose of extracting unusual patterns in the form of rules or functions [
28,
29,
30] through techniques that include data mining (DM) and text mining (TM) [
31] as fundamental elements of machine learning.
Despite the beginning of machine learning dating back several decades, it is currently considered as an emerging field for developing research processes [
32], demonstrating unexpected results in complex situations that resemble processes developed by human experts or superior to them [
33].
Machine learning generates learning with low computational complexity [
34] by which it is possible to extract behavior patterns from a dataset and build predictive models [
35] using two phases in data processing: training and testing [
33]. Furthermore, the training data requires standardization processes to ensure its efficiency [
36]. An important feature of machine learning is the continuous upgrade, which can lead to changes in training data [
37].
Additionally, machine learning takes into consideration three types of learning: supervised, unsupervised, and semi-supervised [
38,
39]. In supervised learning, classification, regression, and prognosis tasks are identified with techniques such as trees and decision rules, neural networks, support vector machines, and Bayesian classifiers, among others. Unsupervised learning features grouping tasks, association, and reduction with techniques such as clustering and dimensionality reduction techniques, while techniques such as transductive support vector machines and hope maximization are found in semi-supervised learning [
40,
41,
42].
Another important area of machine learning is deep learning [
43,
44], natural language processing (NLP) [
25], and text mining, which are computer and statistical techniques developed in the early nineties [
45] used to discover new non-explicit information in source documents [
46,
47] and was aimed at discovering patterns through the right combination of artificial intelligence, machine learning, statistics, and data mining [
48]. Text mining is currently used for various operations such as in image analysis [
49], in biomedical fields (hospitals and clinics) [
50,
51], in the analysis of profiles of university students [
52], in geosciences (geology, geophysics, geochemistry and remote sensing) [
53], and in the automotive sector [
54], among others.
There are several moments in the methodological processes formulated in text mining. Verma, Ranjan, and Mishra proposed two stages: classification and extraction [
55]. In contrast, Sukanya and Biruntha established five different steps: purpose of study, information retrieval, processing, extraction, and results [
56]. Similarly, Miner et al. proposed four tasks: collecting, organizing, analyzing, and assimilating [
57]. Uysal and Gunal introduced four stages: pre-processing, extraction, selection, and classification [
58]. In addition, text mining incorporates data mining tasks that are also used in machine learning within its learning types. These tasks are association, classification, and segmentation [
27,
28,
41,
59].
5. Discussion
It can be seen in the vast majority of the analogies collected in this study that professors wrote them including key verbs that are commonly used in computational terminology and combined them with contexts and actions that are part of people’s daily activities. Therefore, the most used categories were: cooking recipes, arithmetic calculations, purchases, sales, school situations, housework, and games, among others.
In addition, the professors used a greater proportion of analogies that could be computationally modeled instead of those that were general and could not be converted into computer programs.
The discussion for each of the three types of learning contemplated in this study is presented in greater detail below.
In supervised learning, professors incorporate verbs such as to enter, to read, to write and to register, to represent an input action, in addition, the examples are presented repetitively in the context of cooking recipes, payroll basic exercises, calculation of arithmetic operations, processing student’s grades, transactions and purchases, and actions in electronic devices, among others.
In these rules, it can also be stated that professors include keywords in the use of verbs such as to obtain, to calculate, to generate, to invoice, and to print, which are commonly used in computational terminology to denote an output. In addition, some of the examples found were: obtaining a kitchen recipe, the calculation or printing a payroll, arithmetic, geometric operations, invoices, etc. There were also outputs that represent actions such as obtaining an adequate combination of garments, cars, and clothing, stimuli and the results of processes of electronic devices.
When analyzing the rules found for the analogies used to study the concept of conditional, it is also observed that professors included characteristic verbs of the specific terminology such as to choose, to evaluate, to determine, and to compare. The contexts analyzed were presented when choosing a meal from a menu, evaluating mathematical concepts, student’s evaluation aspects, and activities such as doing housework, crossing the street, visiting, traveling, eating, dancing, choice of clothing, etc.
Finally, the rules generated in the analogies used to teach the concept of cycle also included verbs that are closely related to the specific terminology at the time of presenting a computational example for this concept, some of them were do, count, repeat, add, and average. Action such as sums, averages, age counts, wages, multiples, passengers, steps, students, among others, were also recorded.
In unsupervised learning, for the input concept, the association rules obtained were directly related to those extracted with the supervised learning techniques, in which the use of verbs plays an important role in the proposed sentence and with a greater emphasis on nouns in similar contexts.
The association rules for the output concept were more specific than the ones obtained in the classification task and they mainly used the same verbs and contexts. In addition, there were rules that involve actions in general contexts and not purely computational.
The association rules for the conditional concept were more detailed than those generated by classification techniques with a greater participation of nouns and contexts, but sharing the same verbs.
The association rules found in the analogies used for the teaching of cycles contained both the same verbs, nouns, and contexts as the classification rules, but these included more descriptors for verbs and nouns, which allowed us to contemplate a greater number of possibilities when analyzing analogical contexts to approach this concept with new examples.
In semi-supervised learning, the results of the grouping task in
Table 7 and
Table 8 reaffirm the main rules obtained in both the classification and association task previously analyzed. Despite carrying out internal groupings in each concept, subgroups that used the same verbs and contexts were already found.
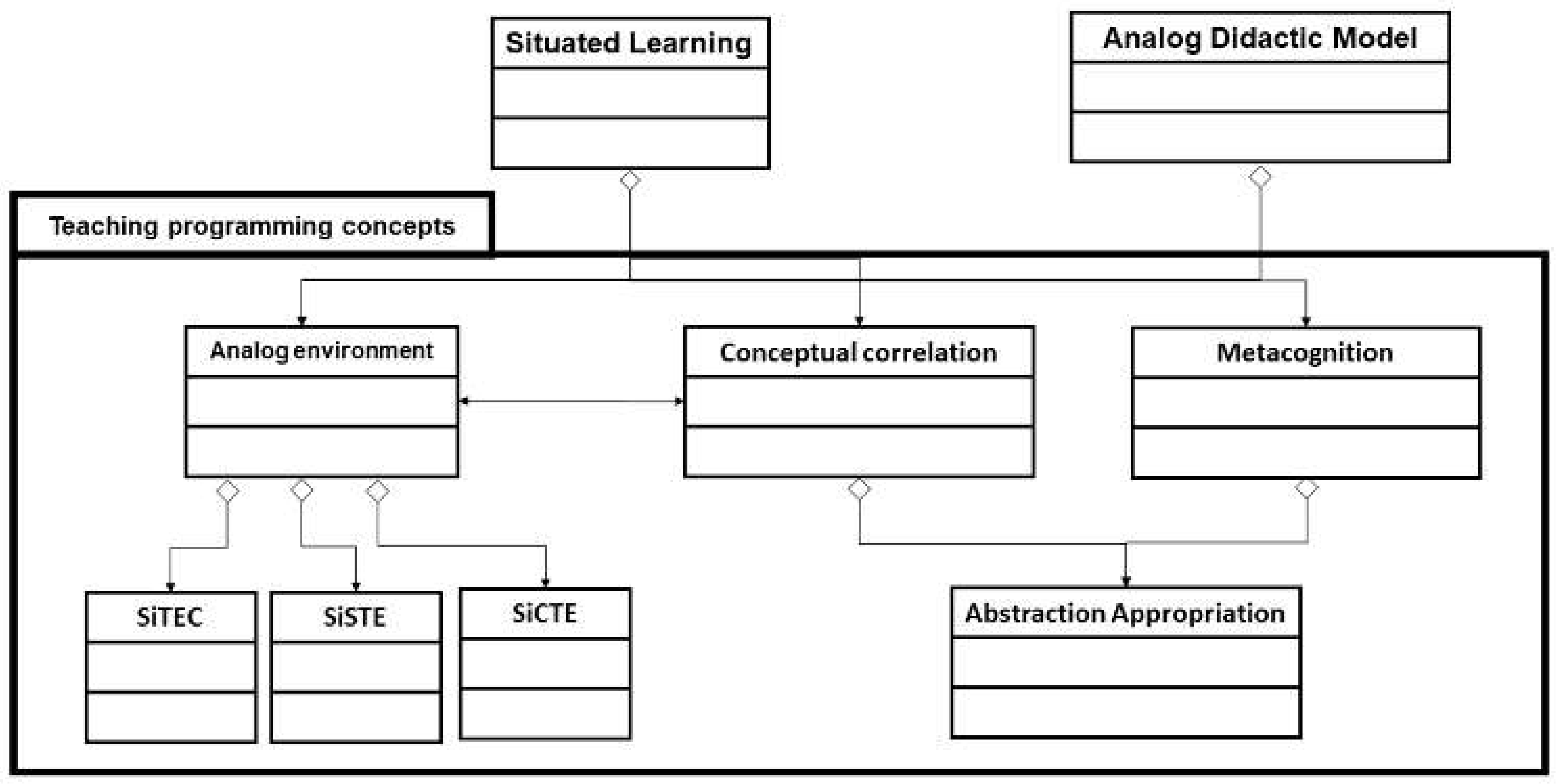
According to the results found in supervised, unsupervised, semi-supervised learning, linguistic analysis, textual analytics, and linked data, it can be presented as a model (
Figure 3) that integrates situated learning and the analogous didactic model to have a better approach to the fundamental concepts of programming to be taught by the professor.
Arias [
79] states that the theory of situated learning establishes a relationship between the learner and the context, which is structured on a practical basis, therefore, to make the learning effective, the learner must be actively involved in actual instruction, that is, be part and product of the activity, the context, and the culture in which the instruction is developed and used [
80].
On the other hand, the analogous didactic model constitutes a teaching strategy that implies the active construction, coming from the students, of the elements that constitute the base domain of the analogy [
22].
The analogous environment refers to the real situation experienced by the students in their context; in this study, three environments were proposed:
Situated teaching environment in the classroom (SiTEC): When the situation is presented with physical elements in the classroom.
Situated and symbolic teaching environment (SiSTE): When it is observed indirectly (e.g., in simulated environments, immersive or digital environments, videos, among others).
Situated and Covert Teaching Environment (SiCTE): This occurs when the student who learns does so by imagining the situation.
In the conceptual correlation, the technical vocabulary is introduced, which is correlated with the options of the analogous environment to find meaning and understanding by comparing the concepts through the experiential analogy presented.
Finally, metacognition is the route of study of the professor’s teaching process, which guides the planning, execution, and control of mental actions and operations of students, which have been oriented together with the aforementioned stages and there is an action to regulate the teaching of computer programming.
A key element of the model in
Figure 3 is the analogy that the professor will use to teach a fundamental concept of programming. For the construction of an analogy, one must start from the concept to be taught, taking into consideration the three proposed analog environments (SiTEC, SiSTE, and SiCTE) and using experiential situations of the context where the learning takes place, so that the student can easily identify an analogy.
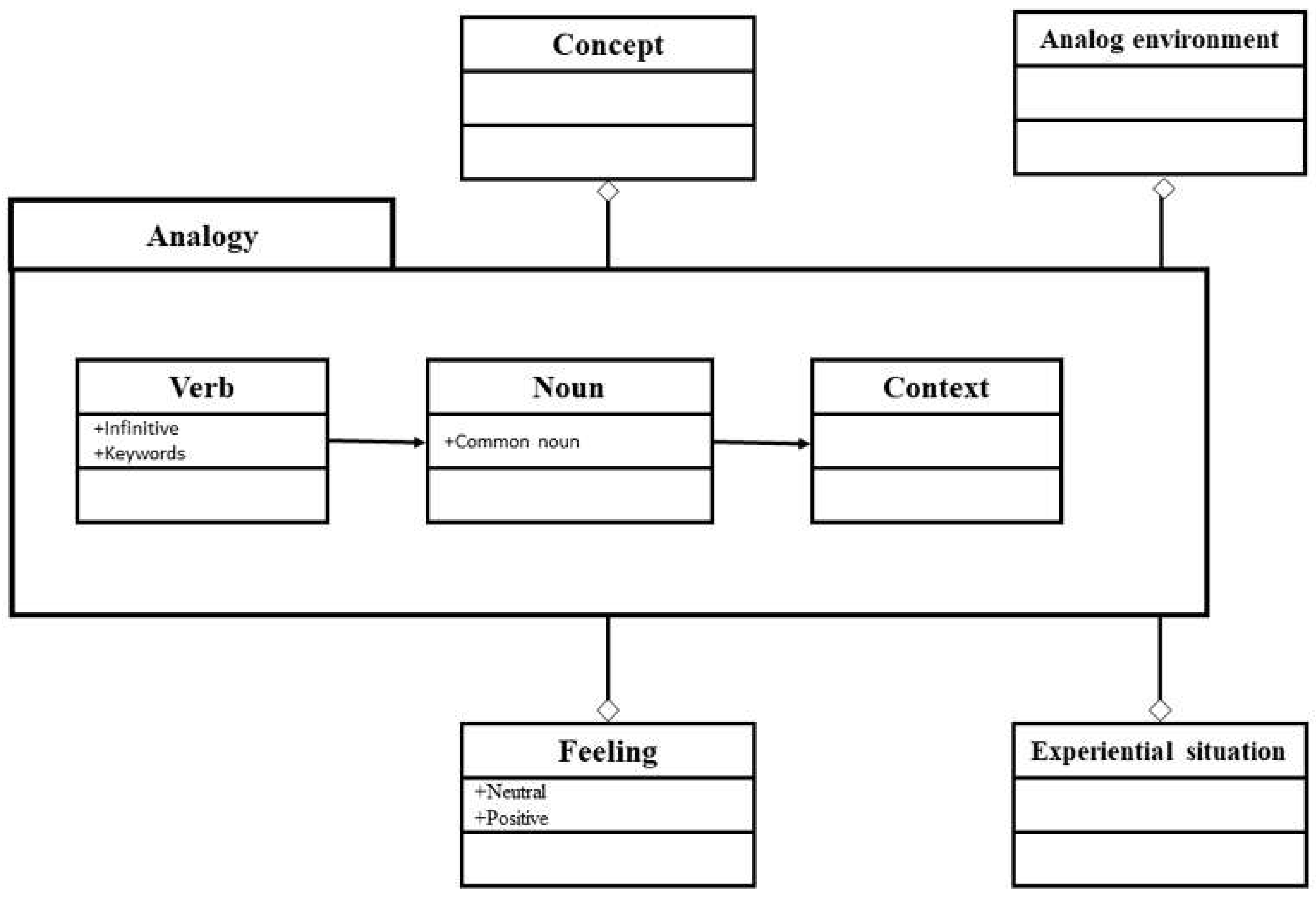
A proposal to build analogies and teach the concepts of programming fundamentals is to combine morphosyntactic elements with the most important findings of this study such as the inclusion of keywords from the terminology of computational examples, quantitative contexts, infinitive verbs, common nouns, and the sentiment analysis of sentences.
Therefore,
Figure 4 presents the elements that an analogy may contain to teach these concepts through the use of sentences with elliptical or tacit subject that do not have the explicit subject in the grammatical structure, that is, they have the form of instructions and are categorized in the affirmative imperative grammatical mood.
The findings presented in this study of supervised, unsupervised, semi-supervised learning, linguistic analysis, textual analytics, and linked data will allow us to select the most appropriate verbs, nouns and contexts for the concepts of input, output, conditional, and cycle, to later use computational thinking as a didactic strategy [
81] in a CS1.
For example, according to the elements suggested in
Figure 4, the following analogies can be used to teach the following concepts of programming fundamentals: enter a password in an ATM (input), obtain an invoice for the purchase of products (output), choose a dish from the restaurant menu (conditional), and add the values of each product of a purchase (cycle).
Validation
The evaluation process of this study was carried out in two moments, first with professors of a CS1 and then with their students. For the first moment of evaluation, the positivist paradigm was used, with a quantitative approach, using the analytical empirical method, with a descriptive type of research and through a pre-experiment with pre-test and post-test.
In this experimental process, two professors participated from two universities in Colombia, CESMAG University (private) and University of Nariño (public), who belong to the Systems Engineering program in the subject called Introduction to Programming and Fundamentals of Programming, respectively, which is in the first academic semester of each curriculum.
Consequently, the experimental design proposed was G O1 X O2, where G is the experimental group formed by the two professors who guide the CS1 in each university. Likewise, O1 was formed by the bank of examples of analogies that these professors were asked to write to explain the concepts of input, output, conditional and cycles, presenting a total of 14 examples for the course Introduction to Programming and 17 examples for Programming Fundamentals.
Then, the professors were given the experimental treatment X, which consisted of the model of the creation of analogies proposed in this research. Finally, they were asked to re-build the analogies for each concept, according to the recommendations of the experimental treatment and whose result was O2, obtaining the same number of initial examples raised by each professor.
When analyzing the analogies raised in O1 with those obtained in O2, it can be seen that the teachers considered elements such as the syntactic structure, the context, and the analogous environment. In addition, the first professor replaced six of the 14 examples initially proposed and the second professor changed five of the 17 examples. It was also observed that 100% of the initial analogies were restructured according to the syntactic recommendation to use a verb, a noun, and a context, incorporating the use of keywords as the main verb in each topic taught.
Similarly, all analogies in O2 were shorter in length than those in O1. For example, the analogy for teaching compound conditionals presented in O1, whose wording was “when asking about the age of a student, you must establish if is of legal age or not”, and in O2, which was worded as follows: “Evaluate the age of a student and determine if is of legal age or not” being 37.2% smaller in extent, maintaining the context and adapting the syntactic structure.
In a second moment, the implementation of the analogies was evaluated according to the bank of examples obtained in O2 with students of a CS1 and compared with the previous courses oriented by the same professors in which they used the analogies of O1. In this case, the experiment had the same paradigm, approach, method, and type of research already mentioned with the professors, where the only difference was the research design, which was experimental with control groups and experimental with pre- and post-test.
In the experimental process, 154 students participated from the two universities already mentioned in San Juan de Pasto (Col) distributed in four groups and whose experimental design for CESMAG University was: G1 O3 X O4 and G2 O5–O6 and for The University of Nariño: G3 O7 X O8 and G4 O9–O10.
The groups G1 and G3 corresponded to the experimental groups of each university, while G2 and G4 were their control groups, respectively. In addition, X was the experimental treatment that consisted of using analogies with the model proposed in this research as a didactic strategy for teaching the fundamental concepts of programming in a CS1. In turn, O3, O5, O7, and O9 were the pre-tests implemented to evaluate the students’ previous knowledge before facing the CS1. In addition, O4, O6, O8, and O10 were the post-tests performed at the end of the experimental treatment for both the experimental and control groups.
The G1 group was formed by 45 students (89% men and 11% women, aged between 16 and 20 years, and two students who retook the course) in the course Introduction to Programming of the first semester of Systems Engineering at CESMAG University, carried out between February and May of 2021, to whom O3 was implemented by means of a questionnaire to verify their previous knowledge in the concepts of input, output, conditional, and cycle. Then, during the course, the topics were explained through the experimental treatment X, and finally, the notes obtained in the academic evaluation process were considered as O4 posttests.
Likewise, the G2 control group was made up of 31 students (87% men and 13% women, aged between 17 and 22 years and a student who retook the course) who received the same course with the same professor during the months of August and November 2020 at the same university. This group was given the same initial questionnaire as the G1 group as a pre-test (O5), but no experimental treatment was applied (X), that is, the professor used the analogies proposed in O1 and the notes obtained were considered as O6.
On the other hand, G3 was formed by 40 students (83% men and 17% women, aged between 16 and 25 years, and no retaking of the course) of the course Fundamentals of Programming of the first semester of the Systems Engineering program at the University of Nariño, to whom O7 was also applied as a result of the previous knowledge, then, during the course, the topics were explained through the experimental treatment X, and finally, the notes obtained in the academic evaluation process were O8.
In the same way, G4 was the control group with 42 students (89% men and 11% women, aged between 16 and 23 years, and no retaking of the course) who received the same course with the same professor during May and September 2020 at the same university. This group was also given the same initial questionnaire as the G3 group as a pre-test (O9), but no experimental treatment (x) was applied and the grades obtained were O10.
The evaluation design for the two experimental groups and the two control groups was done through two academic follow-up activities: A group workshop (45%) and an individual quiz (55%) for each of the topics proposed in this study. The averages of the grades obtained in the pre- and post-test for the four groups are shown in
Table 8.
The marks obtained in the pre-tests of both the experimental and control groups were never higher than those obtained in the different posttests, concluding that students from both the public and private universities learn the fundamental concepts of programming in a CS1, therefore, it highlights the importance of this study. In addition, it is evident the difficulty presented in the concept of conditionals, obtaining positives results in the management of cycles and achieving an optimal appropriation in the handling of data input and output.
Finally, a statistical analysis was performed to determine by means of the student’s probability T distribution [
80], the difference that exists between the grades obtained by the experimental group and the control group in each university. Thus, in both G
1 and G
3, the statistical values t (3.46 and 2.06) were greater than both the critical value of t of a queue (1.67 in both cases) and the critical value for two queues (1.99 in both cases). In addition, the record for one and two P tails was less than 5% in each case, which concludes that the grades obtained by G
1 and G
3, compared to those of G
2 and G
4, in each theme were statistically different.
Therefore, the aforementioned statistical analysis demonstrates the impact that the analogies built under the model proposed here can decrease the complexity of the topics for a student in a CS1.
6. Conclusions and Further Work
Professors included keywords that are typical of the terminology for computational examples in the writing of the analogies used in a CS1. Additionally, most of the contexts used in the analogies were of the quantitative type, where the numerical field has special importance.
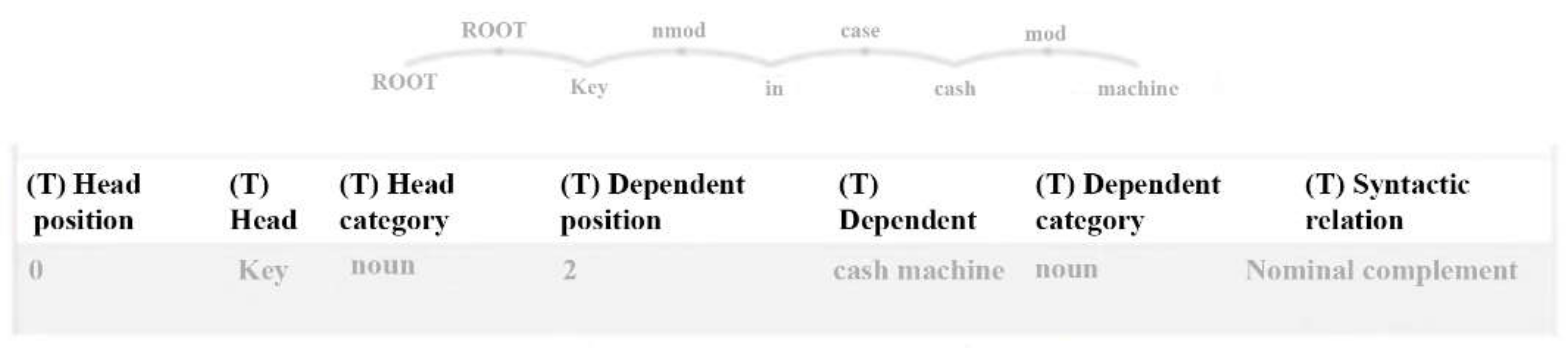
In the sentence structure described by the professors when writing the analogy, the most significant grammatical element of value established by the NLP techniques was the verb, which at the same time was also the main attribute in the tasks of classification, association, and segmentation.
In turn, numerical examples, cooking recipes, and games were the most widely used categories as a reference for the construction of analogies that allow the student to abstract a fundamental concept of computer programming.
In addition, the results obtained in unsupervised and semi-supervised learning confirmed and complemented those obtained in supervised learning, the first being more specific and the second being more general.
It was also observed that the association rules generated in this study presented a higher level of confidence than those found in the classification rules. In addition, they allowed us to obtain patterns of greater specificity for each of the evaluated concepts.
Similarly, the results found by grouping ratified the rules obtained by association and classification in the four concepts.
On the other hand, the linguistic analysis showed us that despite having a wide lexical variety in the four concepts, due to the wide geographical area from which the data were taken, the professors used analogies in common contexts.
There was a high level of agreement among the results of the linguistic analysis, textual analysis, and data linked by each concept compared to the results obtained with the supervised and unsupervised analysis techniques.
For its part, the sentiment analysis showed that the analogies described by the professors had, on average, a neutral wording (46.6%) in the vast majority, followed by positive feelings (36.5%), and to a lesser degree negative (17.1%).
The design of an effective analogy to teach fundamental concepts in a CS1 must combine morphosyntactic elements with keywords in the form of verbs, and those must be typical of the terminology of computational examples. In addition, they must be in quantitative contexts and accompanied by common nouns and with neutral or positive phrases.
For future work, we will design a recommendation system that will guide the professor in the approach of an analogy to address a fundamental concept of a CS1 and develop a visualization tool that supports the process of abstraction in computing environments.










{kind=link}
{kind=link}
{kind=link}
{kind=link}