
A Wavelet-Based Method for the Impact of Social Media on the Economic Situation: The Saudi Arabia 2030-Vision Case


Abstract
1. Introduction and Motivation
2. Textual Data Analysis
2.1. Existing Statistical Methods
2.2. Multidimensional Methods: Correspondence Analysis and Classification
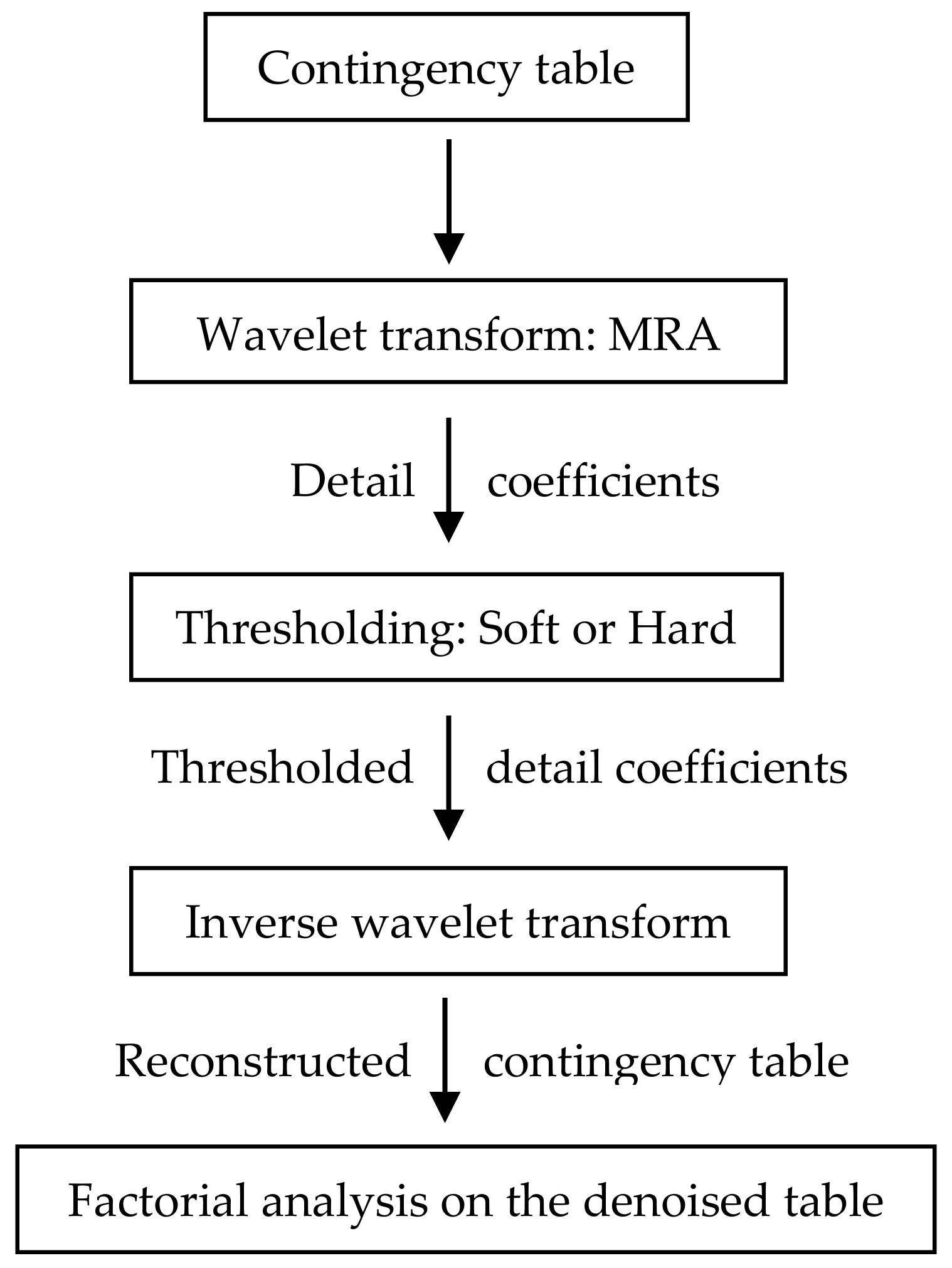
3. The Wavelet Method for Textual Data
- Step 1: In the classical methods, the data applied may suffer from many problems such as the lack of data, and essentially imprecision and fuzziness. Wavelet technique consists in resolving these circumstances before processing by applying denoising methods, reconstruction of missing data and correction of fuzzy parts.
- Step 2: The construction of the contingency tables in textual analysis is always denoised in all the classical methods. By applying wavelet denoising, a clean data basis is obtained and thus a denoised contingency table.
- Step 3: A second processing on the contingency table consists in classical methods to eliminate the least information forms (the forms with minimal frequency) in the lexical corpus, by letting to zero the corresponding values in the contingency table. However, considering a table (as equivalent to an image for example) and letting to zero in mathematical image processing may lead to non-accurate results and lacunarity. Recall that small parts in a time series may form together a great piece. In wavelet theory there is no need to eliminate these parts, while their effect may be evaluated on the whole image via their wavelet coefficients.
- Step 4: Being constructed the clean contingency table; a reprocessing by the factorial correspondence analysis is conducted.
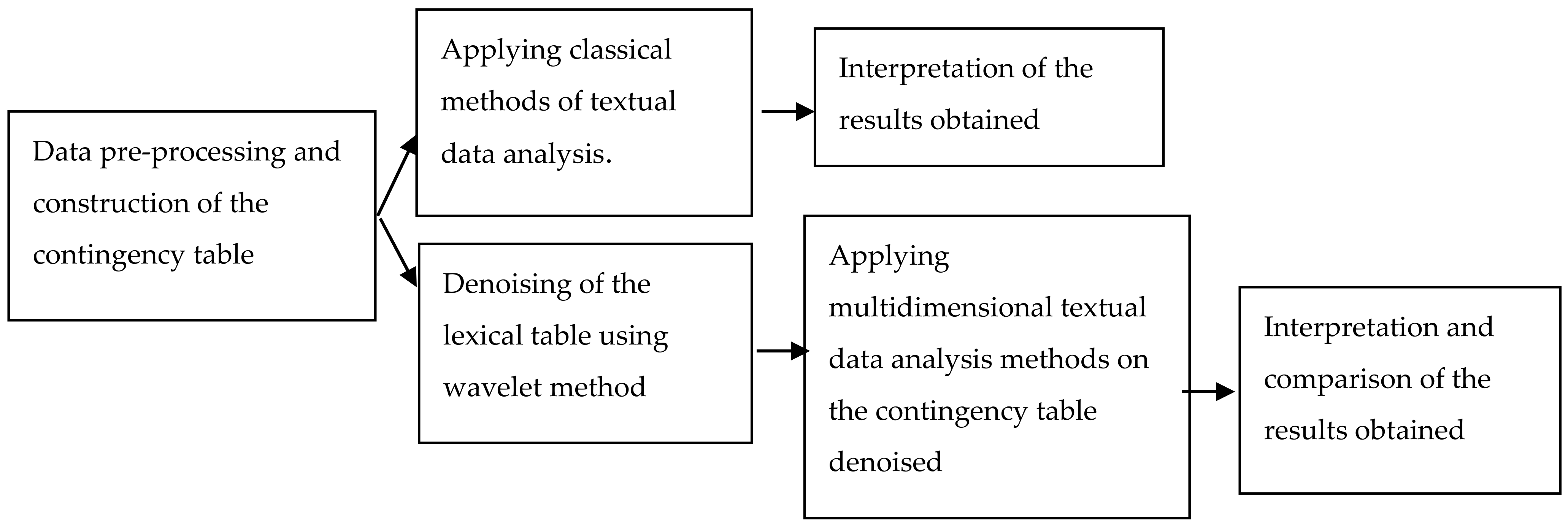
4. Data Analysis
5. Results and Discussions
5.1. Correspondence Analysis before Denoising
5.1.1. Variance Explained by the Factors
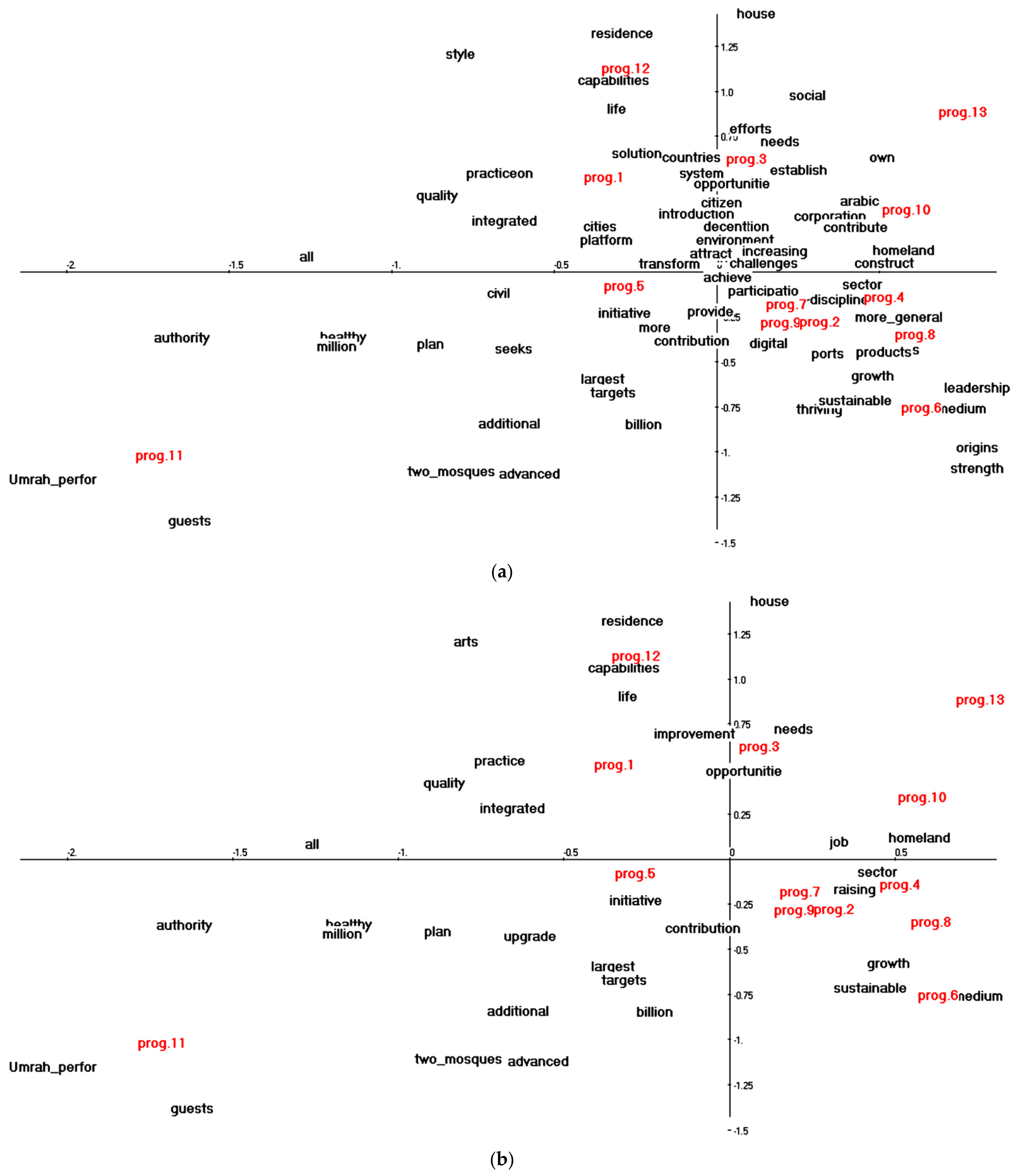
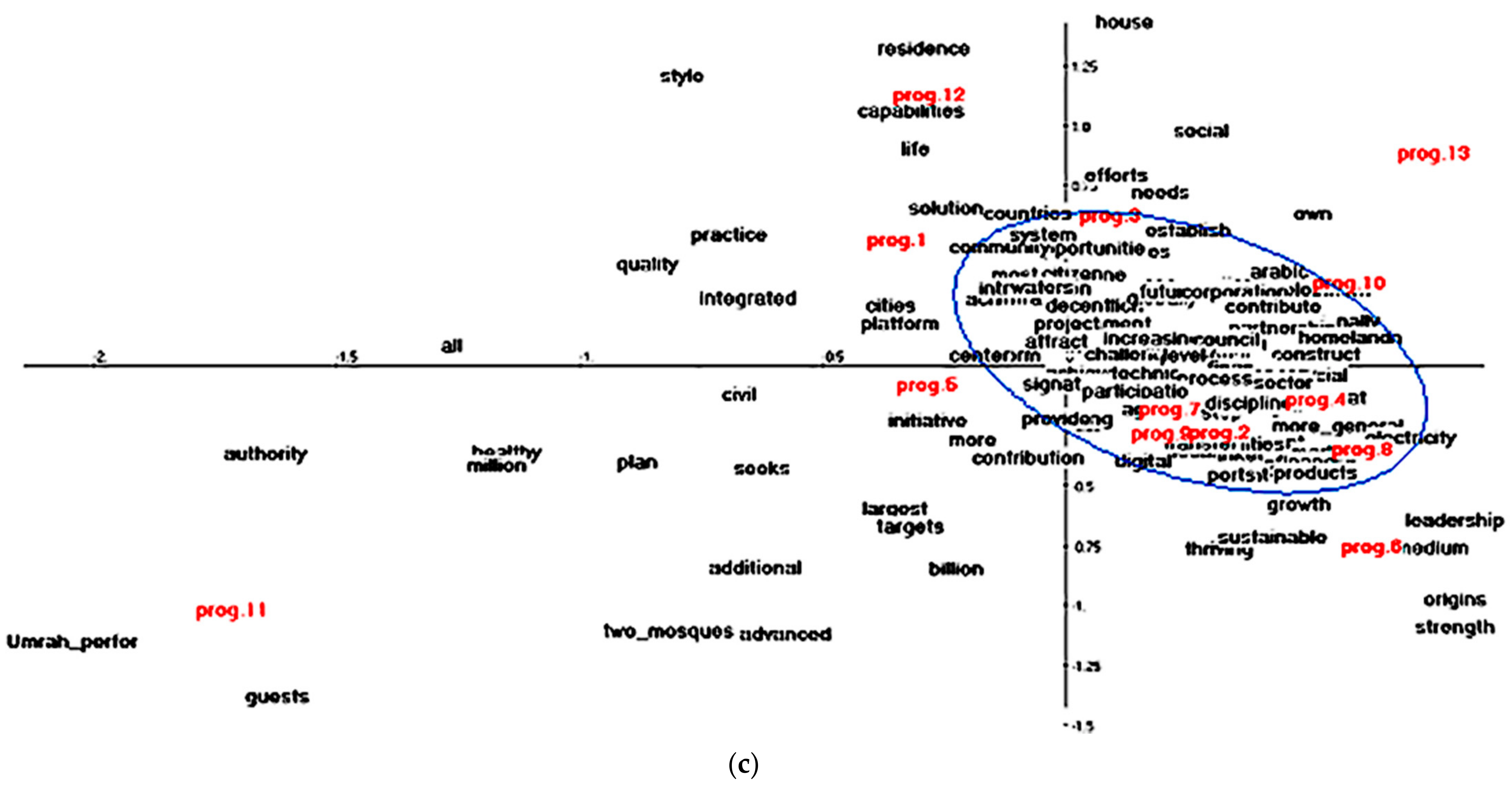
5.1.2. Representation of the First Factorial Plan
5.2. Correspondence Analysis after Denoising
5.2.1. Variance Explained by the Factors
5.2.2. Absolute and Relative Contribution of the Modalities
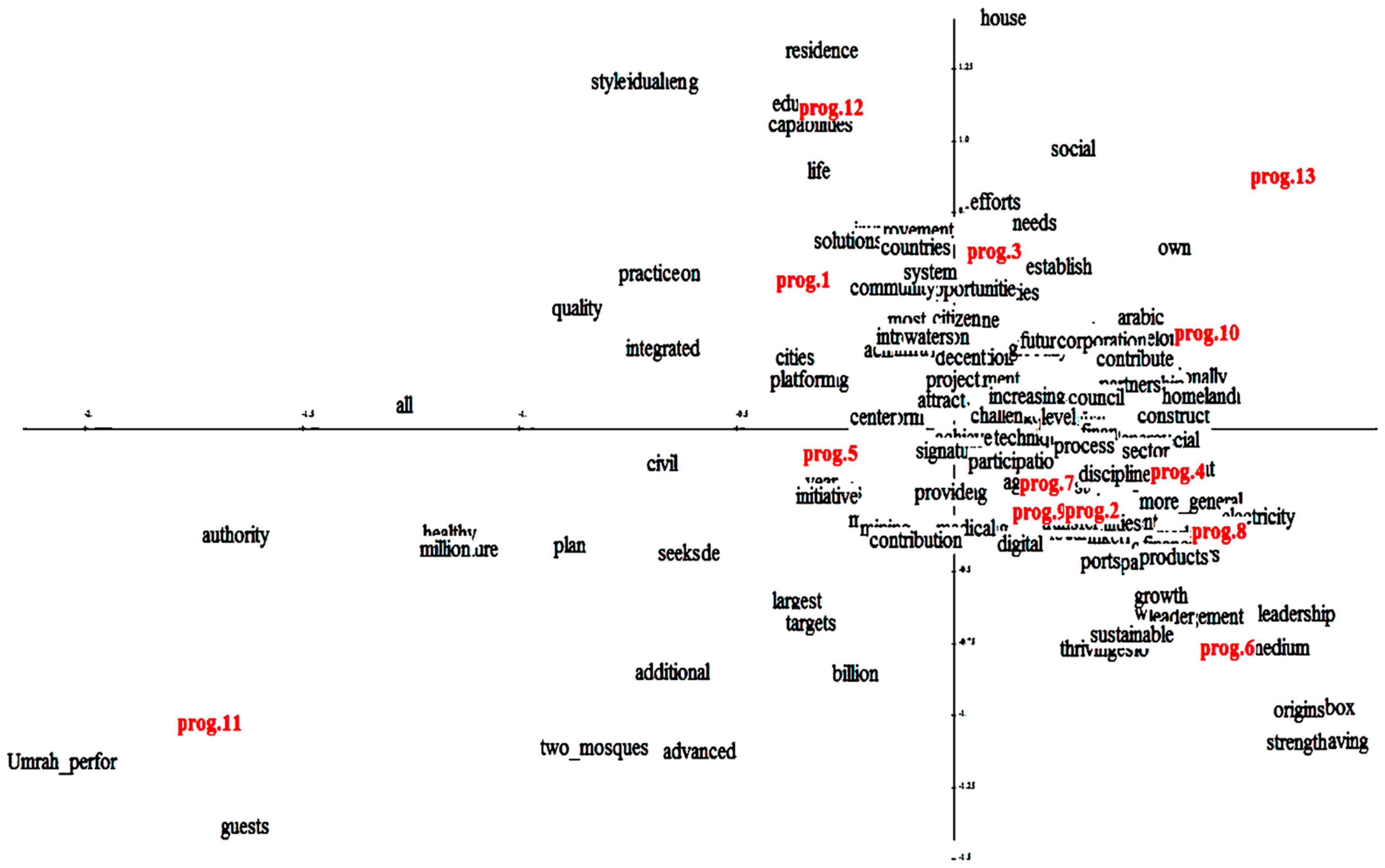
5.2.3. Representation of the First Factorial Plan
5.3. Classification Results: Kohonen Map
6. Further Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A


References
- Antweiler, W.; Frank, M.Z. Is all that talk just noise? The information content of internet stock message boards. J. Financ. 2004, 59, 1259–1294. [Google Scholar] [CrossRef]
- Dershowitz, I.; Dershowitz, N.; Koppel, M.; Akiva, N. Unsupervised decomposition of a document into authorial components. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, Stroudsburg, PA, USA, 19–24 June 2011; pp. 1356–1364. [Google Scholar]
- Gentzkow, M.; Shapiro, J.M. What drives media slant? Evidence from U.S. daily newspapers. Econometrica 2010, 78, 35–71. [Google Scholar]
- Koppel, M.; Argamon, S.; Shimoni, A.R. Automatically categorizing written texts by author gender. Lit. Linguist. Comput. 2002, 17, 401–412. [Google Scholar] [CrossRef]
- Park, L.; Ramamohanarao, K.; Plalaniswamo, M. A novel document retrieval method using the discrete wavelet transform. ACM Trans. Inf. Syst. 2005, 23, 267–298. [Google Scholar]
- Smail, N. Contribution à L’analyse et à la Recherche D’information en Texte Intégral: Application de la Transformée en Ondelettes Pour la Recherche et L’analyse de Textes; Sciences de l’information et de la communication; Université Paris-Est: Paris, France, 2009. (In French) [Google Scholar]
- Lebart, L.; Salem, A. Statistique Textuelle; Dunod: Paris, France, 1994. [Google Scholar]
- Abdessalem, H.; Benammou, S. A wavelet technique for the study of economic socio-political situations in a textual analysis framework. J. Econ. Stud. 2018, 45, 586–597. [Google Scholar] [CrossRef]
- Greenacre, M.J. Correspondence Analysis in Practice, 2nd ed.; Chapman and Hall, CRC: London, UK, 2007. [Google Scholar]
- Greenacre, M.J. Theory and Applications of Correspondence Analysis; Academic Press: London, UK, 1984. [Google Scholar]
- Kohonen, T. Self-organized formation of topologically correct feature maps. Biol. Cybern. 1982, 43, 56–59. [Google Scholar] [CrossRef]
- Fischer, P.; Baudoux, G.; Wouthers, J. Wavepred: A wavelet-based algorithm for the prediction of transmembrane proteins. Comm. Math. Sci. 2003, 1, 44–56. [Google Scholar]
- Arfaoui, S.; Ben Mabrouk, A.; Cattani, C. New Type of Gegenbauer-Hermite Monogenic Polynomials and Associated Clifford Wavelets. J. Math. Imaging Vis. 2020, 62, 73–97. [Google Scholar] [CrossRef]
- Arfaoui, S.; Ben Mabrouk, A.; Cattani, C. New Type of Gegenbauer-Jacobi-Hermite Monogenic Polynomials and Associated Continuous Clifford Wavelet Transform. Acta Appl. Math. 2020, 170, 1–35. [Google Scholar] [CrossRef]
- Bin, Y.; Meng, X.-H.; Liu, H.-J.; Wang, Y.-F. Prediction of transmembrane helicals segments in transmembrane proteins based on wavelet transform. J. Shangahai Univ. 2006, 10, 308–318. [Google Scholar]
- Bin, Y.; Zhang, Y. A simple method for predicting transmembrane proteins based on wavelet transform. Int. J. Biol. Sci. 2013, 9, 22–33. [Google Scholar]
- Cattani, C. Fractals and hidden symmetries in DNA. Math. Prob. Eng. 2010, 2010, 507056. [Google Scholar] [CrossRef]
- Cattani, C. Wavelet algorithms for DNA analysis. In Algorithms in Computational Molecular Biology: Techniques, Approaches and Applications; Elloumi, A.M., Zomaya, Y., Eds.; Wiley Series in Bioinformatics; John Wiley & Sons: Hoboken, NJ, USA, 2011; pp. 799–842. [Google Scholar]
- Cattani, C. On the existence of wavelet symmetries in archaea DNA. Comput. Math. Methods Med. 2012, 2012, 673934. [Google Scholar] [CrossRef]
- Cattani, C. Complexity and symmetries in DNA sequences. In Handbook of Biological Discovery; Elloumi, A.M., Zomaya, Y., Eds.; Wiley Series in Bioinformatics; John Wiley & Sons: Hoboken, NJ, USA, 2013; pp. 700–742. [Google Scholar]
- Cattani, C.; Bellucci, M.; Scalia, M.; Mattioli, G. Wavelet analysis of correlation in DNA sequences. Izv. Vyss. Uchebn. Zaved. Radioelektron 2006, 29, 50–58. [Google Scholar]
- Schleicher, C. An Introduction to Wavelets for Economists; Staff Working Paper; Bank of Canada: Ottawa, ON, Canada, 2002. [Google Scholar]
- Audit, B.; Vaillant, C.; Arneodo, A.; d’Aubenton-Carafa, Y.; Thermes, C. Wavelet analysis of DNA bending profiles reveals structural constraints on the evolution of genomic sequences. J. Biol. Phys. 2004, 30, 33–81. [Google Scholar] [CrossRef]
- Coifman, R.; Wickerhauser, M. Adapted wave for denoising for medical signals and images. IEEE Eng. Med. Biol. Mag. 1995, 14, 578–586. [Google Scholar] [CrossRef]
- Ibrahim Mahmoud, M.M.; Ben Mabrouk, A.; Abdallah Hashim, M.H. Wavelet multifractal models for transmembrane proteins-series. Int. J. Wavelets Multires Inf. Process. 2016, 14, 1650044. [Google Scholar] [CrossRef]
- Kosnik, L.R. Determinants of contract completeness: An environmental regulatory application. Int. Rev. Law Econ. 2014, 37, 198–208. [Google Scholar] [CrossRef]
- Muller, C. La Statistique Lexicale. In Langue Française. Le Lexique; n°2; Guilbert, L., Ed.; Larousse: Paris, France, 1969; pp. 30–43. Available online: https://www.persee.fr/issue/lfr_0023-8368_1969_num_2_1 (accessed on 1 March 2021).
- Lebart, L. Validité des visualisations de données textuelles. In Le Poids des Mots, Actes des JADT04: Septièmes Journées Internationales D’Analyse Statistique des Données Textuelles; Purnelle, G., Fairon, C., Dister, A., Eds.; Presse Universitaires de Louvain: Ottignies-Louvain-la-Neuve, Belgium, 2004; pp. 708–715. [Google Scholar]
- Lebart, L.; Piron, M.; Morineau, A. Statistique Exploratoire Multidimensionnelle; Dunod: Paris, France, 1995. [Google Scholar]
- Lebart, L.; Salem, A. Analyse Statistique des Données Textuelles: Questions Ouvertes et Lexicométrie; Dunod: Paris, France, 1988. [Google Scholar]
- Fallery, B.; Rodhain, F. Quatre approches pour l’analyse de données textuelles: Lexicale, linguistique, cognitive, thématique, Congrès de l’AIMS. In Proceedings of the XVIème Conférence Internationale de Management Stratégique, Montréal, QC, Canada, 6–9 June 2007. [Google Scholar]
- Labbé, D. Normes de Dépouillement et Procédures D’analyse des Textes Politiques; Cahier du CERAT: Grenoble, France, 1990. [Google Scholar]
- Lemaire, B. Limites de la lemmatisation pour l’extraction de significations. In Proceedings of the Actes des 9émes Journées Internationales d’Analyse Statistique des Données Textuelles, Lyon, France, 12–14 March 2008; Volume 2, pp. 725–732. Available online: http://lexicometrica.univ-paris3.fr/jadt/jadt2008/tocJADT2008.htm (accessed on 1 March 2021).
- Benzecri, J.-P. L’analyse des Données: L’analyse des Correspondances; Dunod: Paris, France, 1973. [Google Scholar]
- Escofier, B. Analyse factorielle et distances répondant au principe d’équivalence distributionnelle. Rev. Stat. Appliquée 1978, 26, 29–37. [Google Scholar]
- Escofier, B.; Pagès, J. Analyses Factorielles Simples et Multiples, Objectifs, Méthodes et Interprétation; Dunod: Paris, France, 2008. [Google Scholar]
- Graps, A. An introduction to wavelets. IEEE Comput. Sci. Eng. 1995, 2, 50–61. [Google Scholar] [CrossRef]
- Weedon, G.P. Time Series Analysis and Cyclostratigraphy: Examining Stratigraphic Records of Environmental Cycles; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Daubechies, I. Ten lectures on wavelets. In Proceedings of the CBMS-NSF Regional Conference Series in Applied Mathematics, Society for Industrial and Applied Mathematics, Philadelphia, PA, USA, 1 May 1992; Volume 61. [Google Scholar]
- Daubechies, I. Orthonormal bases of wavelets with finite support—connection with discrete filters. In Proceedings of the 1987 International Workshop on Wavelets and Applications, Marseille, France, 14–18 December 1987; Combes, J.M., Grossmann, A., Tchamitchian, P.H., Eds.; Springer: Berlin/Heidelberg, Germany, 1989. [Google Scholar]
- Härdle, W.; Kerkyacharian, G.; Picard, D.; Tsybakov, A. Wavelets Approximation and Statistical Applications, Lecture Notes in Statistics; Springer: Berlin/Heidelberg, Germany, 1998; p. 129. [Google Scholar]
- Percival, D.B.; Walden, A.T. Wavelet Methods for Time Series Analysis; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Nason, G.P.; Silverman, B.W. The stationary wavelet transform and some statistical applications. Wavelets Stat. Lect. Notes Stat. 1995, 103, 281–300. [Google Scholar]
- Aktan, B.; Ben Mabrouk, A.; Ozturk, M.; Rhaiem, N. Wavelet-Based Systematic Risk Estimation An Application on Istanbul Stock Exchange. Int. Res. J. Financ. Econ. 2009, 23, 34–45. [Google Scholar]
- Ben Mabrouk, A.; Rhaiem, N.; Benammou, S. Estimation of capital asset pricing model at different time scales, Application to the French stock market. Int. J. Appl. Econ. Financ. 2007, 1, 79–87. [Google Scholar]
- Ben Mabrouk, A.; Rhaiem, N.; Benammou, S. Wavelet estimation of systematic risk at different time scales, Application to French stock markets. Int. J. Appl. Econ. Financ. 2007, 1, 113–119. [Google Scholar]
- Ben Mabrouk, A.; Ben Abdallah, N.; Dhifaoui, Z. Wavelet Decomposition and Autoregressive Model for the Prevision of Time Series. Appl. Math. Comput. 2008, 199, 334–340. [Google Scholar]
- Ben Mabrouk, A.; Kortas, H.; Dhifaoui, Z. A wavelet support vector machine coupled method for time series prediction. Int. J. Wavelets Multiresolution Inf. Process. 2008, 6, 1–17. [Google Scholar] [CrossRef]
- Ben Mabrouk, A.; Kortass, H.; Benammou, S. Wavelet Estimators for Long Memory in Stock Markets. Int. J. Theor. Appl. Financ. 2009, 12, 297–317. [Google Scholar] [CrossRef]
- Ben Mabrouk, A.; Kahloul, I.; Hallara, S.-E. Wavelet-Based Prediction for Governance, Diversification and Value Creation Variables. Int. Res. J. Financ. Econ. 2010, 60, 15–28. [Google Scholar]
- Ben Mabrouk, A.; Ben Abdallah, N.; Hamrita, M.E. A wavelet method coupled with quasi self similar stochastic processes for time series approximation. Int. J. Wavelets Multiresolution Inf. Process. 2011, 9, 685–711. [Google Scholar]
- Ben Mabrouk, A.; Zaafrane, O. Wavelet Fuzzy Hybrid Model for Physico Financial Signals. J. Appl. Stat. 2013, 40, 1453–1463. [Google Scholar] [CrossRef]
- Ben Mabrouk, A. Wavelet-Based Systematic Risk Estimation: Application on GCC Stock Markets: The Saudi Arabia Case. Quant. Financ. Econ. 2020, 4, 542–595. [Google Scholar]
- Conlon, T.; Crane, M.; Ruskin, H.J. Wavelet multiscale analysis for hedge funds: Scaling and strategies. Phys. A 2008, 387, 5197–5204. [Google Scholar] [CrossRef]
- Gencay, R.; Selcuk, F.; Whitcher, B. An Introduction to Wavelets and Other Filtering Methods in Finance and Economics; Academic Press: Waltham, PA, USA, 2002. [Google Scholar]
- Donoho, D.; Johnstone, I. Ideal spatial adaptation by wavelet shrinkage. Biometrika 1994, 81, 425–455. [Google Scholar] [CrossRef]
- Donoho, D.; Johnstone, I. Denoising by soft thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef]
- Thaicharoen, S.; Altman, T.; Cios, K.J. Structure-Based Document Model with Discrete Wavelet Transforms and Its Application to Document Classification; Seventh Australasian Data Mining Conference (AusDM 2008), Glenelg, Australia. Conferences in Research and Practice in Information Technology (CRPIT); Australian Computer Society Inc.: Sydney, Australia, 2008; Volume 87. [Google Scholar]
- Miller, N.E.; Wong, P.C.; Brewster, M.; Foote, H. Topic lands—A wavelet based text visualization system. In Proceedings of the Conference on Visualization ’98, Research Triangle Park, NC, USA, 18–23 October 1998; pp. 189–196. [Google Scholar]
- Jaber, T.; Amira, A.; Milligan, P. A novel approach for lexical noise analysis and measurement in intelligent information retrieval. In Proceedings of the IEEE International Conference Pattern Recognition, Hong Kong, China, 20–24 August 2006; Volume 3, pp. 370–373. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantitative Analysis | Multidimensional Analysis | |
|---|---|---|
| Principle | Quantitative study of the text vocabulary (richness, distribution of words, etc.). | Analysis and visualization of the text content using factorial correspondence analysis and automatic classification. |
| Steps | -Segmentation of the corpus and identification of the graphical forms. -Assigning a sequence number to all the occurrences of the same graphical form [7,28,29,30]. | -Identifying graphical forms. -Keeping forms that carry information. -The graphical forms are subject to a lemmatization process. -A lexical matrix, considered as a particular contingency table, is constructed. The graphical forms are the rows of this table, while the columns correspond to the corpus parts [28]. |
| Advantages | Extremely helpful in the analysis of the vocabulary of different texts, the study of the evolution of an author style, and the comparison of many authors’ styles [27]. | Application of these techniques has proved a great value in the analysis of political speeches, interviews, open questions in surveys, electronic data, etc. This category of lexical analysis concentrates on the content of the texts rather than their forms, which make it a valuable tool for the comprehension of the corpus content. |
| Disadvantages | The main disadvantage of these techniques is that they give priority to the analysis of the form of the texts while neglecting the content. | Lexical table constructed could be noisy by various errors occurred while entering or segmentating [31]. Errors related to the lemmatization step (combining homonyms or polysemous words) affect the results of the multidimensional data analysis methods [32,33]. |
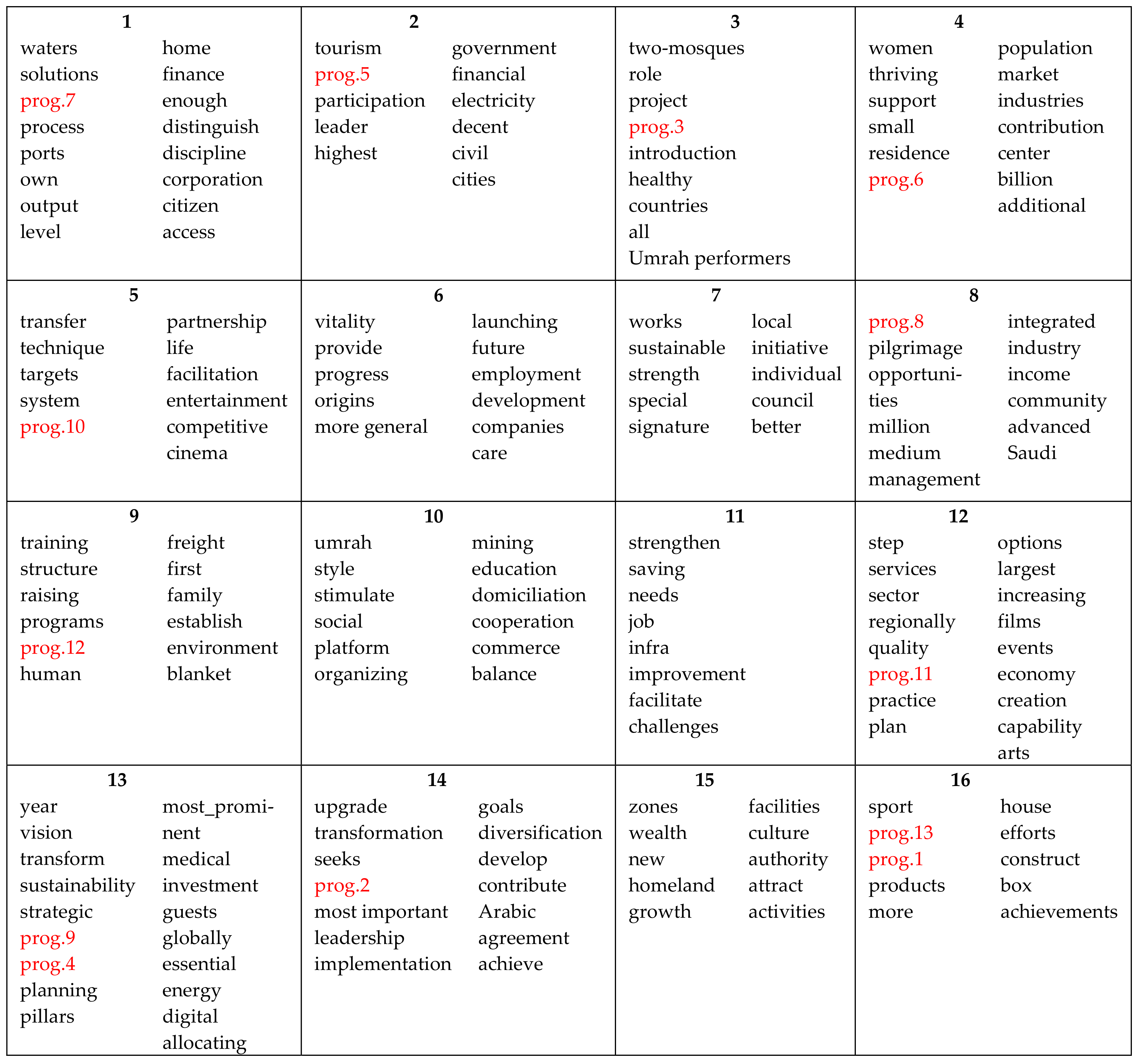
| Program | Corresponding Sector |
|---|---|
| Program1 | Quality of Life Program |
| Program2 | Financial Sector Development Program |
| Program3 | Housing Program |
| Program4 | Fiscal Balance Program |
| Program5 | National Transformation Program |
| Program6 | Public Investment Fund Program |
| Program7 | Privatization Program |
| Program8 | National Companies Promotion Program |
| Program9 | National Industrial Development and Logistics Program |
| Program10 | Strategic Partnerships Program |
| Program11 | Hajj and Umrah Program |
| Program12 | Human Capital Development Program |
| Program13 | Saudi Character Enrichment Program |
| Date | Program | Text |
|---|---|---|
| 03/2020 | Housing program | The housing program worked on using modern and varied construction techniques, which contributed to the fast and high quality delivery of housing units. |
| 05/2019 | Pilgrims’ and visitors’ services | Pilgrims’ and visitors’ service program is planning to reach 30 million pilgrims annually by 2030. |
| 03/2019 | Human capacity development | The human capabilities development program aims to achieve strategic objectives of the vision 2030. Building an integrated educational journey (lifelong learning) -Comprehensive support for talented people and developing their skills. -Enrolling in prestigious universities. -Improving equal access to quality education for all. |
| 11/2018 | National entrepreneurship | The national company leadership program works to raise the percentage of local content and diversify the economy by creating opportunities for small and medium-sized companies. |
| 11/2018 | Strategic partnerships | The strategic partnerships program contributes to achieving the Saudi Vision 2030 by building and deepening strategic economic partnerships at the regional and global level. |
| 10/2018 | Public investment funds | The public investment fund program works to enhance the role of the public investment fund as the effective engine to diversify the economy in the Kingdom, and to develop specific strategic sectors through developing and maximizing the impact of the fund’s investments. |
| 08/2018 | Privatization program | Privatization program is one of the programs to achieve Saudi Vision 2030 for the development of local and foreign investments. The involvement of the private sector in the process of adopting regulations and drawing up investment policies, including the privatization system, is a pioneering step to enhance the competitiveness of the investment environment and achieve the highest possible level of transparency and governance. |
| Factor | Eigenvalue | Explained Variance (%) | Cumulative Variance (%) |
|---|---|---|---|
| 1 | 0.23964162 | 15.22 | 15.22 |
| 2 | 0.20582392 | 13.07 | 28.29 |
| 3 | 0.17350014 | 11.02 | 39.31 |
| 4 | 0.15208723 | 9.66 | 48.96 |
| 5 | 0.14197041 | 9.02 | 57.98 |
| 6 | 0.13169175 | 8.36 | 66.34 |
| 7 | 0.12096496 | 7.68 | 74.02 |
| 8 | 0.10259253 | 6.51 | 80.54 |
| 9 | 0.09538481 | 6.06 | 86.60 |
| 10 | 0.08561771 | 5.44 | 92.03 |
| 11 | 0.07146756 | 4.54 | 96.57 |
| 12 | 0.05398047 | 3.43 | 100.00 |
| Absolute Contribution | Relative Contribution | |||
|---|---|---|---|---|
| Axis 1 | Axis 2 | Axis 1 | Axis 2 | |
| prog.1 | 8.80 | 19.90 | 0.15 | 0.29 |
| prog.2 | 2.80 | 2.70 | 0.08 | 0.07 |
| prog.3 | 0.00 | 15.50 | 0.00 | 0.23 |
| prog.4 | 5.10 | 0.30 | 0.10 | 0.00 |
| prog.5 | 7.70 | 0.10 | 0.20 | 0.00 |
| prog.6 | 6.90 | 12.50 | 0.12 | 0.18 |
| prog.7 | 1.20 | 1.10 | 0.04 | 0.03 |
| prog.8 | 7.00 | 2.60 | 0.16 | 0.05 |
| prog.9 | 1.10 | 3.80 | 0.03 | 0.11 |
| prog.10 | 4.80 | 3.20 | 0.09 | 0.05 |
| prog.11 | 51.30 | 17.70 | 0.64 | 0.19 |
| prog.12 | 1.30 | 16.30 | 0.02 | 0.20 |
| prog.13 | 2.00 | 4.40 | 0.04 | 0.07 |
| 1st Axis Explained Variance (%) | 2nd Axis Explained Variance (%) | Cumulative Variance (%) | |
|---|---|---|---|
| db4_hard | 45.99 | 29.13 | 75.12 |
| db4_soft | 59.39 | 33.73 | 93.12 |
| db6_hard | 54.60 | 26.83 | 81.43 |
| db6_soft | 60.64 | 34.25 | 94.89 |
| db8_hard | 46.61 | 28.19 | 74.80 |
| db8_soft | 61.19 | 34.79 | 95.98 |
| db16_har | 42.43 | 24.82 | 67.25 |
| db16_sof | 61.48 | 35.86 | 97.34 |
| Absolute Contribution | Relative Contribution | |||
|---|---|---|---|---|
| Axis 1 | Axis 2 | Axis 1 | Axis 2 | |
| prog.1 | 13.40 | 4.30 | 0.83 | 0.16 |
| prog.2 | 0.10 | 14.90 | 0.01 | 0.95 |
| prog.3 | 0.30 | 14.40 | 0.03 | 0.93 |
| prog.4 | 8.50 | 7.00 | 0.67 | 0.32 |
| prog.5 | 1.50 | 13.50 | 0.15 | 0.79 |
| prog.6 | 5.30 | 9.50 | 0.48 | 0.50 |
| prog.7 | 7.00 | 7.40 | 0.61 | 0.37 |
| prog.8 | 13.60 | 2.60 | 0.88 | 0.10 |
| prog.9 | 2.50 | 13.30 | 0.23 | 0.72 |
| prog.10 | 12.30 | 1.10 | 0.92 | 0.05 |
| prog.11 | 18.00 | 0.10 | 0.99 | 0.00 |
| prog.12 | 13.00 | 0.90 | 0.91 | 0.04 |
| prog.13 | 4.60 | 11.00 | 0.41 | 0.58 |
| Before Denoising | After Denoising | |||
|---|---|---|---|---|
| Axe 1 | Axe 2 | Axe 1 | Axe 2 | |
| Training | 0.05 | 0.14 | 0.98 | 0.02 |
| Partnership | 0.09 | 0.03 | 0.97 | 0.03 |
| Financial | 0.14 | 0.09 | 0.01 | 0.97 |
| Participation | 0.00 | 0.00 | 0.14 | 0.85 |
| Tourism | 0.23 | 0.13 | 0.12 | 0.83 |
| Upgrade | 0.23 | 0.13 | 0.01 | 0.97 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Balalaa, M.S.; Ben Mabrouk, A.; Abdessalem, H. A Wavelet-Based Method for the Impact of Social Media on the Economic Situation: The Saudi Arabia 2030-Vision Case. Mathematics 2021, 9, 1117. https://doi.org/10.3390/math9101117
Balalaa MS, Ben Mabrouk A, Abdessalem H. A Wavelet-Based Method for the Impact of Social Media on the Economic Situation: The Saudi Arabia 2030-Vision Case. Mathematics. 2021; 9(10):1117. https://doi.org/10.3390/math9101117
Chicago/Turabian StyleBalalaa, Majed S., Anouar Ben Mabrouk, and Habiba Abdessalem. 2021. "A Wavelet-Based Method for the Impact of Social Media on the Economic Situation: The Saudi Arabia 2030-Vision Case" Mathematics 9, no. 10: 1117. https://doi.org/10.3390/math9101117
APA StyleBalalaa, M. S., Ben Mabrouk, A., & Abdessalem, H. (2021). A Wavelet-Based Method for the Impact of Social Media on the Economic Situation: The Saudi Arabia 2030-Vision Case. Mathematics, 9(10), 1117. https://doi.org/10.3390/math9101117