1. Introduction and Context of the Empirical Application
Asthma is recognized as one of the most important chronic diseases that affects millions of people worldwide. This disease produces a decrease in the quality of life, disability and premature death of people in all ages [
1]. In addition, it continues to be an important source of global economic burden in terms of costs and social impact [
2,
3]. Asthma is described as a heterogeneous disease by the Global Initiative for Asthma (GINA:
https://ginasthma.org) and usually characterized as a chronic airway inflammation. It is defined by the history of respiratory symptoms such as chest tightness, cough, shortness of breath, and wheeze that varies over time and in intensity together with variable expiratory airflow limitation. Although it is not strictly a definition, this description captures the essential features for clinical purposes. The National Asthma Education and Prevention Program (
https://www.nhlbi.nih.gov/science/national-asthma-education-and-prevention-program-naepp) has classified asthma as: intermittent, mild persistent, moderate persistent, and severe persistent. These classifications are based on severity, which is determined by symptoms and lung function tests. According to [
4], in recent decades, the asthma prevalence is increasing in many countries, especially among children and adolescents. Therefore, strategies based on scientific evidence are crucial to generate better preventive measures as well as greater access and adherence to treatments that reduce the economic burden. Thus, organizations, such as the Global Asthma Network (
http://www.globalasthmanetwork.org/index.php), the International Study of Asthma and Allergies in Children (
http://isaac.auckland.ac.nz), and the mentioned GINA, have been created worldwide to generate scientific evidence and disseminate information on the best care of asthma in terms of its prevention and management.
The scientific evidence about asthma is strongly related to data analysis, which is already part of medical decision-making or medical decision science, a process increasingly associated with data science and big data [
5,
6,
7,
8,
9,
10,
11]. Then, data analysis tools as predictive models provide precious information to the areas of clinical practice, medical research and public health [
12,
13,
14,
15]. One of the most popular predictive models for fitting the presence or absence of a disease by means of categorical data, especially by considering data with a binary response, is the logistic regression [
16]. Modeling and prediction for correlated and uncorrelated binary data through the logistic regression model have been carried out in different areas of science and especially in medicine. The logistic regression model is one of the most useful statistical tools due to its good properties and easy interpretation; read more information in [
16,
17,
18]. This model presents statistical challenges that have a strong implication on the results and can compromise the inference, predictions and, consequently, the conclusions, as well as data-driven medical decisions making. In this regard, once the model has been fitted to the binary response data, it is essential to check that its fit is valid. There are several manners to make this validation in models for binary data [
19]. Recent advances in model checking and diagnostics have been developed by several authors [
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30]. For more details and references regarding to statistical diagnostics, see
Section 3.
In a recent study [
4], children and adolescents, who were diagnosed with persistent or intermittent asthma, have been in medical follow-up for at least one year in a public hospital at São Paulo, Brazil. The patients in the study were 362 children and adolescents aged from 6 to 20 years of old, of both sexes (59% male patients and 41% female patients) from numerous ethnicities. Clinical examinations detected whether or not the patients had a fixed airway obstruction (FAO hereafter). These results were reported based on gender, age, height, region and pulmonary function test data when there is no significant response to a bronchodilator. Patients were classified into four groups according to their current asthma severity: [Group 1] Intermittent asthma; [Group 2] Mild persistent asthma; [Group 3] Moderate persistent asthma; and [Group 4] Severe persistent asthma. The explanatory variables considered are duration of treatment in years (
treatment hereafter), blood test presence or absence of eosinophilia (increased number of circulating eosinophils in the blood,
eosinophilia hereafter) and sum of all levels of all factors that produce allergy (
allergy hereafter) following the radio allergosorbent test (RAST). The interval (mean ± SD) of the variables
treatment and RAST are (5.946 ± 3.255) and (7.064 ± 4.051), respectively, with SD denoting their standard deviation. The observations, grouped by severity level and analyzed by using a mixed model [
17], allow us to include the correlation and variability due to factors that were not observed in the study. Because the interest is to analyze or predict the asthma state through the binary response variable FAO, a mixed-effect logistic regression model can be proposed [
31] to describe this response.
The primary objective of this work is to provide data-influence analytics using a mixed-effect logistic regression model applied to the asthma disease. This analytics is based on global and local influence diagnostic techniques, which are used simultaneously in this study but often used separately. Therefore, the main contribution of this research is to consider global and local influence diagnostic techniques simultaneously in a mixed-effect logistic regression model applied to asthma world-real data. Such a joint usage allows us to identify situations which could not be detected if we use these techniques separately. In addition, predictive performance measures are considered for such a data-influence analytics. The secondary objectives of this work related to the application are: (i) to provide an algorithm that summarizes the methodology proposed in this study as a mechanism for improved scientific evidence in asthma data; (ii) to determine what explanatory variables are associated with FAO and to model the probability that the patient presents FAO given the asthma severity group in which it was classified; (iii) to identify values that, after their elimination, cause disproportionate changes in the estimates of the model parameters and allow us to improve its predictive performance; and (iv) to detect patients who are too different medically in relation to FAO.
This article is organized as follows.
Section 2 describes the mixed-effects logistic regression model for the asthma status study. In
Section 3, we present the methodology for data-influence analytics of the described predictive model.
Section 4 and
Section 5 introduce the global and local influence techniques. The Monte Carlo and Metropolis–Hastings methods are presented in
Section 6 to calculate the respective influence measures. In
Section 7, we provide the computational aspects and algorithms used in this study. In
Section 8, the quality of the fitted mixed-effects logistic regression model for studying asthma status is analyzed. Finally, in
Section 9, the conclusions and proposals for future studies are discussed.
2. Mixed-Effects Logistic Regression Model for Asthma Status Study
To study the asthma status of children and adolescents at a public hospital of São Paulo, Brazil, we consider a clustered data set by current severity of asthma of
patients, with
q being used in
Section 5. In the context of mixed models, the clustered data set has four asthma severity groups, defined in the introduction, labeled by
i, with the
ith group being conformed by
patients, for
, where
in this study. The asthma status is represented by the binary response variable
, with
if the patient
j in the
ith group is classified with FAO; otherwise,
for
, with
. The probability
is modeled as a function of the explanatory variables, which include the duration of the treatment (in years),
(
treatment); an indicator variable of eosinophilia,
(
eosinophilia); and sum of all levels of all factors that produce allergy according to the RAST,
(
allergy). The change between asthma severity groups is accommodated through random intercept
. Then, our mixed-effect logistic regression model is described by
, with
and
where
represent the values of
, respectively, and
Let
be the vector of unknown parameters of the proposed mixed-effect logistic regression model. The maximum likelihood (ML) estimate of
, standard error (SE),
p-values, and sensitivity (Sens), specificity (Spec) and accuracy (Acc) performance measures are presented in
Table 1. Computational aspects related to parameter estimation and calculation of prediction performance measures are described in
Section 7. The procedure of formulation of the mixed-effect logistic regression model until obtaining the final prediction model is summarized in Algorithm 1.
| Algorithm 1 Formulation/estimation/fit/validation of the mixed-effect logistic regression |
- 1:
Collect a sample of data according to a mixed-effect logistic regression model. - 2:
Conduct an exploratory data analysis to show evidence of mixed effects in the logistic regression model. - 3:
Estimate the parameters of the mixed-effect logistic regression model with the ML method. - 4:
Use the asymptotic properties of the ML estimators to obtain the SE and p-values associated with each parameter estimated in step 3. - 5:
Calculate Sens, Spec and Acc performance measures to validate the model.
|
The results related to the fixed effects of the model indicate that the explanatory variables
treatment and
eosinophilia are significant at 5% according to the
p-values of
Table 1, which are 0.12% and 2.20%, respectively. Then, the overall level of both covariates to reach significance is 5%. This level is one of the most commonly used in the literature and it is chosen as a benchmark to make other inferences and obtain the necessary conclusions. However, this does not prevent any reader can draw her/his own conclusions by means of the
p-values reported in the tables of the present manuscript. Note that this significance level of 5% is also adopted as a benchmark for the post-deletion of cases after applying the data-influence analytics detailed in the following sections. The estimates with positive sign of the
treatment and
eosinophilia coefficients indicate that, for a given group, as the treatment time of a patient increases, the probability of presenting FAO increases as well. In addition, a patient with eosinophilia is more likely to present FAO. Note that the SD associated with the random intercept distribution is greater than zero. Hence, heterogeneity is detected among the four asthma severity groups. Regarding to the performance of the model predictive,
Table 1 reports that the probability of correct classification of having FAO is 69.69%, the probability of correct classification of not having FAO is 75.98%, and probability of correct classification is 75.41%.
3. Data-Influence Analytics in Mixed-Effects Logistic Regression Model
Data-influence analytics is used to identify potentially influential cases that can affect the parameter estimates and the quality of the model prediction. This can allow us to detect implicit problems in the data set and cases that, after being removed, might modify the inferences/predictions and conclusions drawn from the analysis and possibly altering the decisions made from the study results.
In the statistical literature there are two main techniques for detecting influential cases. The first one corresponds to global influence diagnostics, performed commonly by case-deletion, which consists of the elimination of cases of the total data set; see details in, for example, Refs. [
32,
33,
34,
35,
36]. The second one corresponds to local influence diagnostics that allows us to identify cases that, under small perturbations in the model or in the data, may cause disproportionate changes in the estimates of the model parameters; see details in, for example, Refs. [
22,
24,
25,
26,
27,
28,
30,
37,
38,
39].
The difference between both techniques is that local influence diagnostics does not require the elimination of cases and allows us simultaneously evaluating the joint influence of all potentially influential cases. Nevertheless, both techniques can be connected to generate a more complete diagnostics, that is the proposal of this work. On the one hand, global influence by case-deletion [
36] is a technique which develops a diagnostic measure by evaluating the difference between the estimates of model parameters before and after deleting potentially influential cases from the data set. On the other hand, the local influence technique [
37,
39] derives diagnostic measures by using the curvature of the influence graph for an appropriate function.
For the mixed-effects logistic regression model, we combine the global influence diagnostics proposed in [
40] for the model with incomplete data and the local influence diagnostics presented in [
24] for binary response variables, both supported in the Monte Carlo integration and sampling observations from the Metropolis–Hastings algorithm.
Let the random effects of the mixed-effects logistic regression model be represented as a missing (unobserved) data set,
, and augmented with the observed data set
. Then, the complete data set can be represented as
. Thus, the complete-data log-likelihood function for the model parameter
is given by
where
and
is the density function of the normal distribution of mean zero and variance
for
and
. Subsequently, inspired by the expectation-maximization (EM) algorithm [
40,
41,
42], we develop global and local influence measures based on the conditional expectation of the complete-data log-likelihood function,
, where the expectation is calculated with respect to the conditional density function
.
4. The Global Influence Diagnostics
The global influence technique allows us to study the effect of deleting cases or case-groups on the estimate of
. Thus, for the mixed-effects logistic regression model, there are two kinds of interesting deletions. One of them is the deletion of each case, in order to evaluate the influence of the deleted case on the ML estimate of
. And the other one is the case-group deletion, in order to evaluate the influence of the deleted case-group on the ML estimate of
. In this context, consider the following notations. A quantity with a subscript “
” means the relevant quantity with the
th case or
ith group deleted. Hence, we define
,
and
as the observed, unobserved and complete data sets, respectively, with the
th case or
ith group deleted. Additionally, we define
as the ML estimate of
obtained with the
th case or
ith group deleted. Then, according to [
40], in order to assess the influence of
th case or
ith group on the ML estimate
, the difference between
and
is calculated through the global influence measure given by
where
However, the measure given in (
1) implies calculating
for every case. Hence, The procedure can be computationally intensive depending upon the size of the data set. Therefore, in [
40] is proposed a one-step approximation
of
given by
where
Note that
depends on only the ML estimate
to save the computation time. Consequently, substituting (
2) into (
1), the global influence measure is given by
where the derivatives included in
are
To study the influence of
th case or
ith group, we propose to work with the benchmark
where
and
correspond to the mean and SE of all values of
.
5. The Local Influence Diagnostics
The local influence technique allows us to study the effect of minor modifications or perturbations in the model or the data on the estimate of due to some source of uncertainty of model. One of the sources of uncertainty which is crucial in mixed-effects logistic regression models corresponds to the binary response variable. Note that, in this case, the response may assume only values zero or one, so that the local influence technique cannot be applied with direct perturbation of the response, but its probability of success can perturbed as described below.
Let
be a
perturbation vector in
and
be the perturbed mixed-effects logistic regression model, where
is the density function of
perturbed by
and
is its corresponding complete-data log-likelihood function. Assume that there is a
non-perturbation vector such that
and
for all
. To assess the local influence of
on the ML estimate
, one can consider the Q-displacement function [
38] given by
, where
is the ML estimate of
that maximizes
and the expectation is calculated with respect to the conditional density function
. Therefore,
. Following the arguments given in [
37] to characterize the behavior of
at
, in [
41] is shown that the normal curvature
of
at
, in the direction of a unit vector
, is given by
where
is a
matrix evaluated at
,
is a
symmetric and semipositive definite matrix evaluated at
, and
is the
perturbation matrix evaluated at
and
. Nevertheless, the measure given in (
4) is invariant under reparametrization of
. In [
41] also is proposed the conformal normal curvature
at
, in the direction of a unit vector
, as
Let
be the
r non-zero eigenvalues of
and
be their corresponding orthogonal eigenvectors. Based on
Q, the aggregate contribution vector defined as
is used to assess the local influence of
, where
[
41,
43]. To study the influence of
, we work with the following benchmark. The
th case or
ith group are potentially influential if
, where
and
are the mean and SE of
values.
Arbitrarily perturbing the model or data may lead to unreliable results regarding to the influence diagnostics. In [
44] is proposed a form for selecting an appropriate perturbation vector
, for the model
, based on the expected Fisher information matrix with respect to
. This matrix is given by
, with
where the expectation is calculated with respect to
; see more information about the properties of this matrix in [
44]. Then, a perturbation vector
is appropriate if
evaluated at
equals
, that is,
, with
, and
being the
identity matrix. Now, if
, we can always reparametrize the perturbed model
by considering the one-to-one transformation
, such that
evaluated at
is equal to
.
In this context, because perturbing the probability of success given by
, with
, is not appropriate, the perturbation
can be considered, where the elements
are stated as
and the non-perturbation vector is
. Thus, the derivative different from zero involved in
is
Note that, when
, the derivative given in (
5) is equal to zero. In practice, initially we carry out the local influence diagnostics for cases with
, and then we alternate the values of
to perform the diagnostics with
.
7. Computational Framework
To carry out the procedure of data-influence analytics, we summarize the methodology that has been introduced in
Section 2,
Section 3,
Section 4,
Section 5 and
Section 6 by means of Algorithms 3–6. Specifically, Algorithm 6 corresponds to the full procedure of data-influence analytics, which implements the other three algorithms sequentially through what we denominate phases. In Phase I, Algorithm 3 is called for executing the procedure of sampling observations from the Metropolis–Hastings algorithm. In Phases II and III, Algorithms 4 and 5 are designed to execute global and local influence diagnostics, respectively. Note that when we refer to global and local influence diagnostics, these include the post-deletion analysis which consists of evaluating the impact on the estimates, SE, and
p-values, relative change (RC), and predictive performance measures (Sens, Spec and Acc using the selection criteria Sens = Spec) of the groups or cases detected due to their potential influence. Based on results obtained in the Phases II and III, Phase IV decides the cases that need a new post-deletion analysis. Thus, with the results obtained in Phase IV, Phase V performs the final post-deletion analysis.
The proposed methodology is implemented in the
R and
RStudio software [
45].
R is a non-commercial open source software for statistical computing and graphics and
RStudio is an integrated development environment (IDE) for
R. Both of them can be downloaded from
www.r-project.org and
www.rstudio.com, respectively. For an application of
R and
RStudio in medical sciences, see [
46]. Some
R packages related to fit of non-normal data with mixed effects are available in
CRAN.R-project.org [
47]. Specifically, we use the
base package for descriptive statistics and the
lme4 package for fitting the mixed-effects logistic regression model. We use the command
glmer of the
lme4 package for the ML estimation of
based on the AGHQ procedure with 25 quadrature points. We employ the
matrixcalc package for calculations associated with global and local influence measures, whereas the
PresenceAbsence package is considered for calculating the Sens, Spec and Acc measures.
R codes with the implementation of the proposed methodology are available from the authors upon request.
| Algorithm 3 Procedure of sampling observations from the Metropolis–Hastings algorithm. |
- 1:
Collect clustered binary data and a vector with the values of the covariates denoted by for the fixed effects, with and . - 2:
Formulate a mixed-effects logistic regression model and determine the ML estimates of its parameters by using the AGHQ procedure with 25 quadrature points. - 3:
Generate a random sample from the normal distribution with zero mean and variance and calculate the elements of the matrix given in ( 9). - 4:
Generate data from the conditional density function given in ( 6) by using the Metropolis-Hastings method defined in Algorithm 2.
|
| Algorithm 4 Procedure for global influence diagnostics. |
- 1:
Based on the data generated in Algorithm 3, approximate the vector given in ( 7) for th case and ith case-group, with and . - 2:
Calculate the global influence measures , given in ( 3), for th case and ith case-group, with and . - 3:
Compute the benchmark for the cases and case-groups identifying potentially influential points. - 4:
Perform post-deletion analysis with the cases or case-groups detected as potentially influential.
|
| Algorithm 5 Procedure for local influence diagnostics. |
- 1:
Based on the data generated in Algorithm 3, approximate the Fisher information matrices and given in (8). - 2:
Calculate the local influence measures , with and . - 3:
Compute the benchmark and identify potentially influential points. - 4:
Alternate values of grouped binary data , with and ; carry out steps 2 to 4 of Algorithm 3; and then continue with steps 1 to 3. - 5:
Perform post-deletion analysis with the cases detected as potentially influential.
|
| Algorithm 6 Procedure for data-influence analytics. |
- 1:
Produce the formulation, estimation, fit and validation of the model with Algorithm 1. - 2:
Consider the Metropolis-Hastings method to obtain observations as in Algorithm 2. - 3:
Execute Phase I (sampling observations using Metropolis–Hastings) with Algorithm 3. - 4:
Perform Phase II (global influence diagnostics) with Algorithm 4. - 5:
Carry out Phase III (local influence diagnostics) with Algorithm 5. - 6:
Establish Phase IV (Phase II and Phase III for post-deletion analysis). - 7:
Conduct Phase V based on the results of Phase IV to perform the final post-deletion analysis.
|
8. Model Quality
To evaluate the quality of the mixed-effects logistic regression model used in the study with asthma data, we carry out Phases II and III for data-influence analytics described in Algorithm 6. The results are the following.
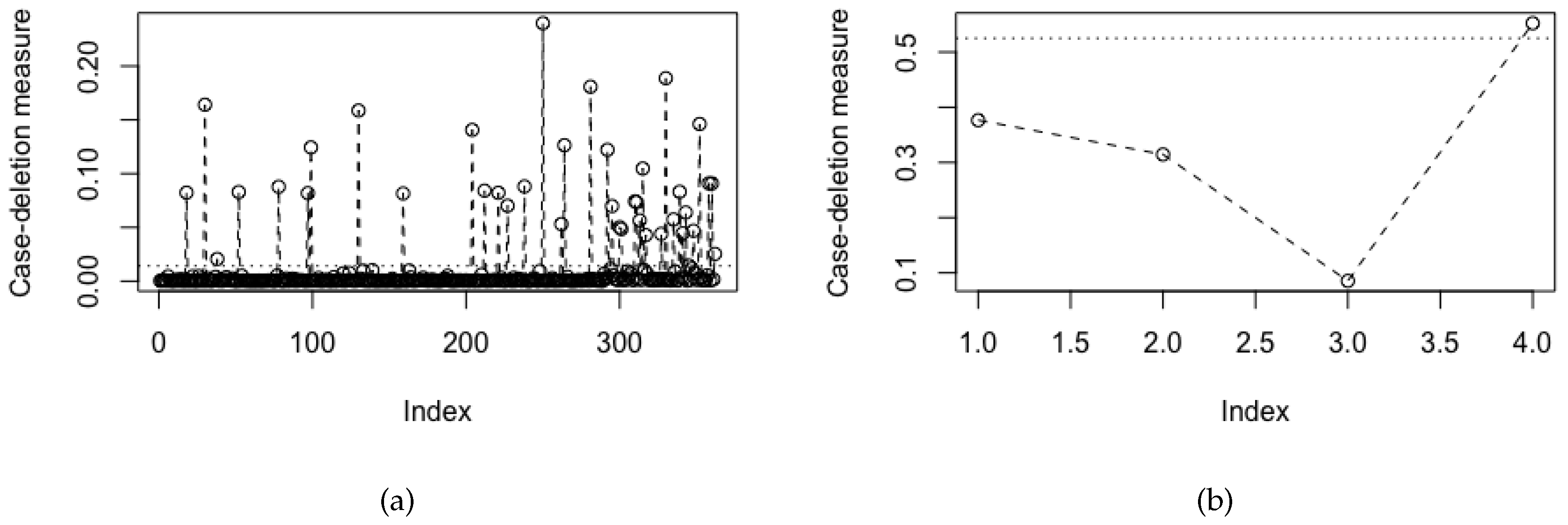
Figure 1 shows the index plots of global influence measures for (a) the cases with benchmark equal to 0.0141 and (b) the case-groups with benchmark equal to 0.5250. All potentially influential cases from the four groups identified from
Figure 1a have been displayed in
Table 2. In addition,
Figure 1b indicates the Group 4 (severe persistent asthma) as potentially influential.
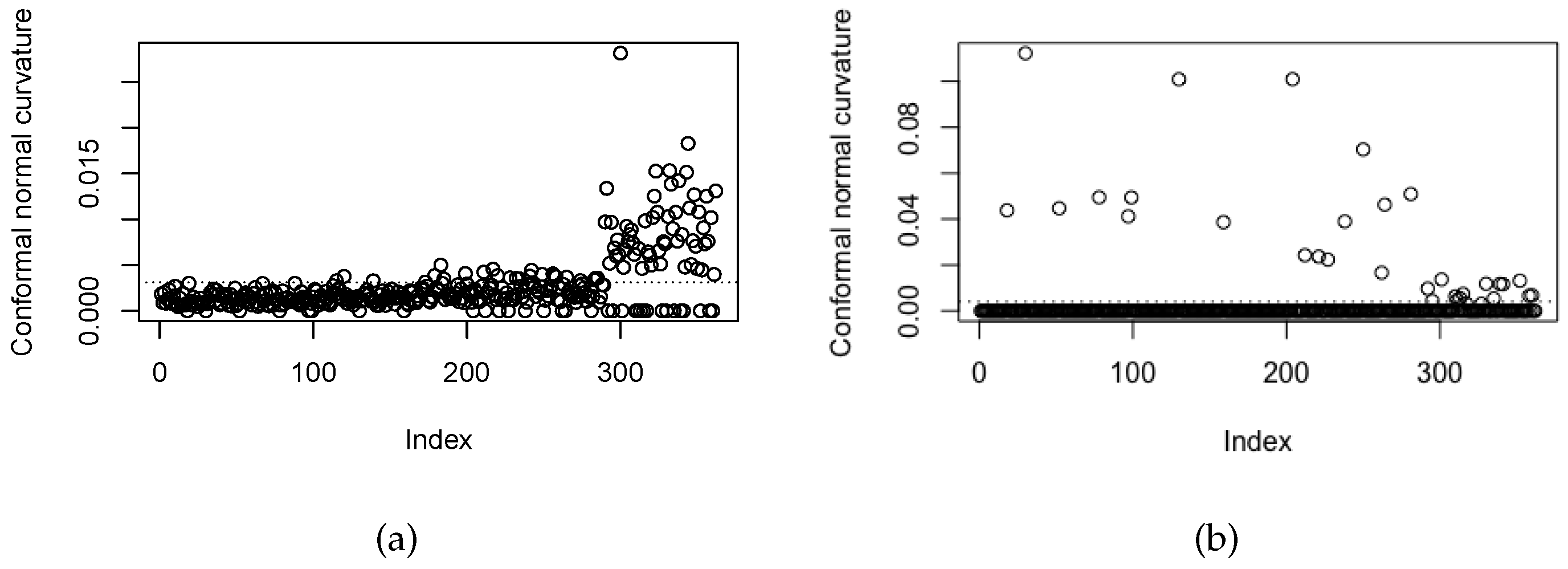
Figure 2a,b show index plots of local influence measures for (a)
with benchmark equal to 0.0031 and (b)
with benchmark equal to 0.0040. All local influence cases from four groups identified from
Figure 2 are reported in
Table 3.
Table 4 and
Table 5 display the results of estimates, SE,
p-values, RC and predictive performance measures from post-deletion analysis of the cases and case-groups detected as influential under global influence diagnostics (Phase II). Regarding to the parameter estimates of the fixed effects (
), note that after removing the cases detected as potentially influential for each group, the estimates present moderate changes, but the estimate related to the intercept random (
) presents a high change, in accordance with the RC values. In addition, inferential changes observed for the eosinophilia covariate pass from significant to not significant at 5%, when cases from Groups 3 and 4 are removed. With respect to the Sens, Spec and Acc measures, with Sens = Spec determining an optimal threshold equal to 0.1, once the potential influential cases of Groups 1, 2 and 3 are removed, the values of Sens, Spec and Acc increase considerably. Observe that the maximum values of Sens, Spec and Acc are obtained by removing the cases detected as potentially influential of Group 3, that is, 0.8333, 0.8328 and 0.8328, respectively. Under global influence analysis for the case-groups, the estimates related to fixed effects (
) present moderate changes and inferential changes at 5% in the covariate eosinophilia for the Group 4. Estimate of the variance parameter associated with the distribution of the random intercept (
) is almost zero, that is, the model does not capture the change or heterogeneity between asthma severity groups, suggesting a standard logistic regression model. In addition, after the Group 4 is removed, the values of Sens, Spec and Acc decrease.
The results of post-deletion analysis of the cases detected as influential by group under local influence diagnostics (Phase III) are presented in
Table 6 and
Table 7. We note that, after removing the cases detected as potentially influentials for each group, the estimates related to fixed effects (
) present moderate changes in all groups and inferential changes at 5% in the covariate eosinophilia for the Groups 4 and 3. Estimate of the variance parameter associated with the distribution of the random intercept (
) is almost zero, that is, the model not capture the change or heterogeneity between asthma severity groups, suggesting a standard logistic regression model. In relation to the Sens, Spec and Acc measures, with the selection criteria Sens = Spec determining an optimal threshold equal to 0.1, the values of Sens, Spec and Acc are equal to 0.6969, 0.7598, 0.7541, respectively, for all data. Now, after removing the cases detected as potentially influential of the Groups 1, 2 and 3, the values increase considerably. The maximum values are obtained by removing the cases detected as influential in the Group 3, that is, these values are 0.8333, 0.8371 and 0.8368, respectively. However, for the Group 4, these values decrease mainly for Spec and Acc.
According to results obtained in Phase II and III, we observe that the Groups 3 and 4 need more study (Phase IV). For that reason, we now perform post-deletion analysis considering each type of response.
Table 8 and
Table 9 displays the results of estimates, SE,
p-values, RC and predictive performance measures, with
and
of the Groups 3 and 4. For the global influence diagnostics, the cases with responses
for the Group 4 lead to a significant allergy covariate at 5%. For the cases with responses
, in both groups we conclude that the eosinophilia covariate is not significant at 5%. By observing the performance measures, after removing the cases with
of the Group 4, the values of these measures increase partially, whereas after removing the cases with
of the Group 3, the values of these measures increase substantially. For the local influence diagnostics, we observe that the cases with responses
and
of the Group 4, and cases with responses
of the Group 3 are related to the eosinophilia covariate which is not significant at 5%. In addition, the cases with responses
of the Group 4 are related to the estimate of the variance (
), which is almost zero and this is associated with the normal distribution of the random intercept. By observing the performance measures, after removing the cases with
of the Group 4 and
of the Group 3, the values of these measures increase. Thus, we decide to remove the cases with
of the Group 4 and cases with
of the Group 3 (Phase V). This makes sense because they are patients with severe persistent asthma (Group 4) but without FAO, or they have moderate persistent asthma (Group 3) and present FAO.
Table 10 and
Table 11 report the results of the post-deletion analysis. Observe that the eosinophilia covariate is not significant at 5%, and allergy is not significant at 10%. Nevertheless, the Sens, Spec and Acc measures present a large increase, that is, 0.8750, 0.8860 and 0.8851, respectively.
Table 12 reports the fit for the model reduced (without these covariates), and
Table 13 reports the performance measures of the prediction. Note that the variance increases and that the prediction measures decrease. Hence, these covariates must remain in the model. Therefore, the method of combining the global and local influence diagnostics at the group and cases levels allow us to obtain a model with higher prediction capacity and some inferential changes.
9. Conclusions, Discussion, and Future Research
When patients belong to a specific group, such as patients classified according to their severity of asthma, the data present dependence and have a hierarchical structure that can be modeled through the use of mixed models [
17]. If the interest is to analyze or predict the binary response variables of individuals based on certain variables fixed or random measured from those individuals, a mixed-effect logistic regression model can be used [
17,
18]. This model is a typical predictive model widely used in practice.
This research reported the following findings:
- (i)
We have provided a data-influence analytics using a mixed-effect logistic regression applied to the asthma disease based on global and local influence diagnostic techniques, which are used simultaneously in this study but often used separately. Such a joint usage allowed us to identify situations which could not be identified if we use these techniques separately. In the case of our application, this data-influence analytics is provided in
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8,
Table 9,
Table 10,
Table 11,
Table 12 and
Table 13 and
Figure 1 and
Figure 2.
- (ii)
We have considered predictive performance measures for these analytics. In the case of our application, results for these predictive performance measures are provided in
Table 1,
Table 5,
Table 7,
Table 9,
Table 11, and
Table 13.
- (iii)
We have given an algorithm that summarizes the methodology proposed in this study; see Algorithm 4.
- (iv)
We have proposed and implemented a methodology for the data-influence analytics of this type of predictive models, which allows the provision of improved scientific evidence in asthma data, to evaluate if the data contain particular observations that may impact on the conclusions to be drawn from the analysis and, therefore, impact the medical decision-making.
- (v)
We have illustrated the proposed methodology with a case study of real-world data regarding to the asthma data collected from a public hospital at São Paulo, Brazil.
The case study has shown that the new methodology allowed us to obtain a model with the high predictive capacity, identify patients who are too different medically in relation to fixed airway obstruction values, especially for severe persistent asthma and moderate persistent asthma groups. In addition, we explained what characteristics or explanatory variables are associated with fixed airway obstruction, in order to model the probability of fixed airway obstruction given the asthma severity group in which it was classified. The results of this work can be taken as a contribution to the data-influence analytics in predictive models applied to the asthma disease. Note that improving the data quality with analytics has gained attention in recent years, especially in medicine. It allows us to identify anomalies increasing the efficiency of medical experiments, while maintaining a high level of data quality. Thus, it is possible to avoid inaccurate conclusions from results of the study. Therefore, good statistical practices must be followed with sophisticated techniques, such as those presented in this work related to detection of influential data and outliers, as well as other possible inconsistencies in the data; see the studies presented in [
48,
49], which support our discussion in terms of data quality and analytics in medicine. Thus, our study can be a knowledge addition to the toolkit of diverse practitioners, including medical doctors, applied statisticians, and data scientists.
Some themes for future research, which arose from the present investigation, are the following:
- (i)
The procedure of data-influence analytics is very useful for identifying a set of the particular observations termed influential. However, this set may include other type of particular observations that are those so-called outliers. These outliers are those that are not well fitted by the model and their detection is based commonly on the residual analysis. Therefore, developing a methodology, which allows the identification of outliers detected in a data set using different types of residuals for mixed-effects logistic regression models, is of interest for future study about quality of fitted and prediction capability of the model [
50].
- (ii)
An important aspect to be considered when medical data are analyzed is censorship. Model parameter estimates with censored data is more efficient than when censorship is not considered. Indeed, if censored cases are present and a censoring is not considered, it is not possible to estimate the variance of the censored part. Nevertheless, if the censored case is used, such a variance may be estimated from the data. In addition, asymptotic behavior and performance of maximum likelihood estimators in more complex statistical models can be studied in [
51,
52]. Estimation methods for the regression parameters upon a high censoring may be studied by a mixture structure [
53,
54,
55].
- (iii)
An extension of the present study to the multivariate case is also of practical relevance [
52,
56,
57].
- (iv)
Incorporation of temporal, spatial, functional, and quantile regression structures in the modeling, as well as errors-in-variables, and PLS regression, are also of interest [
26,
29,
30,
58,
59,
60,
61,
62,
63].
Therefore, the proposed methodology in this investigation promotes new challenges and offers an open door to explore other theoretical and numerical issues. Research on these and other issues are in progress and their findings will be reported in future articles.






{kind=link}
{kind=link}