In this section, we propose the
-level estimation algorithm for the proposed ridge fuzzy regression model. This algorithm modifies the method based on Choi et al. [
22] to estimate the fuzzy parameters. The term
-level estimation indicates that our algorithm uses
-levels to describe fuzzy data. By using
-level, we are able to develop a ridge fuzzy estimator which is not restricted to the distance between fuzzy numbers. We first briefly examine the original formulation of ridge regression model for crisp data.
3.1. Ridge Regression
Given a data set
, a multiple linear regression model assumes that the relationship between a dependent variable
,
and a set of explanatory variables
,
is linear. The model takes the form
or written alternatively in matrix notation as
. A vector
is a vector of observations on the dependent variable,
is a matrix of explanatory variables,
is a vector of regression coefficients to be estimated, and
is a vector of error terms. The standard estimator for
is the least squares estimator defined by
In the presence of multicollinearity, i.e., in state of extreme correlations among the explanatory variables
is poorly determined and susceptible to high variance. Thus, we may deliberately bias the regression coefficient estimates so as to control their variance. In this manner, the ridge regression estimator was introduced by Hoerl and Kennard [
18] as a penalized least squares estimator. It is achieved by minimizing the residual sum of squares (RSS) subject to a constraint on the size of the estimated coefficient vector [
25]:
Here
is a shrinkage parameter which controls the size of the coefficients. The larger the value of
, the greater the amount of shrinkage, and we have coefficients close to zero. The smaller the value of
is close to 0, we obtain the least squares solutions. Please note that by convention the input matrix
is assumed to be standardized and
is assumed to be centered before solving RSS(
). The ridge regression solution is
where
is the
identity matrix. The shrinkage parameter
is usually selected via K-fold cross validation. Cross validation is a simple and powerful tool often used to calculate the shrinkage parameter and the prediction error in ridge regression. The entire dataset is divided into
K parts, and trains the model on all but the
kth part. The model is validated on the
part, iterating for all
. The choice of
K is
or
in general.
3.2. Ridge Fuzzy Regression Algorithm
Let us consider a set of observations
where the dependent variable
,
and the explanatory variables
,
are triangular fuzzy numbers. We assume a linear relationship between the dependent and explanatory variables:
where
are the fuzzy regression parameters and
are the fuzzy error terms. ⊕ and ⊙ represent addition and multiplication between two fuzzy numbers, respectively. Often the
N equations are stacked together and written in matrix notation as
For more details on arithmetic operations between fuzzy numbers, see [
10,
26]. Please note that the above fuzzy variables can be symmetric or asymmetric, and be extended to various forms such as normal, parabolic, or square root fuzzy data. Since crisp sets are a special case of fuzzy sets, fuzzy inputs and fuzzy outputs, or fuzzy inputs and crisp outputs combinations are also possible. For illustration purposes, in this section, we present our ridge fuzzy regression model using triangular membership functions.
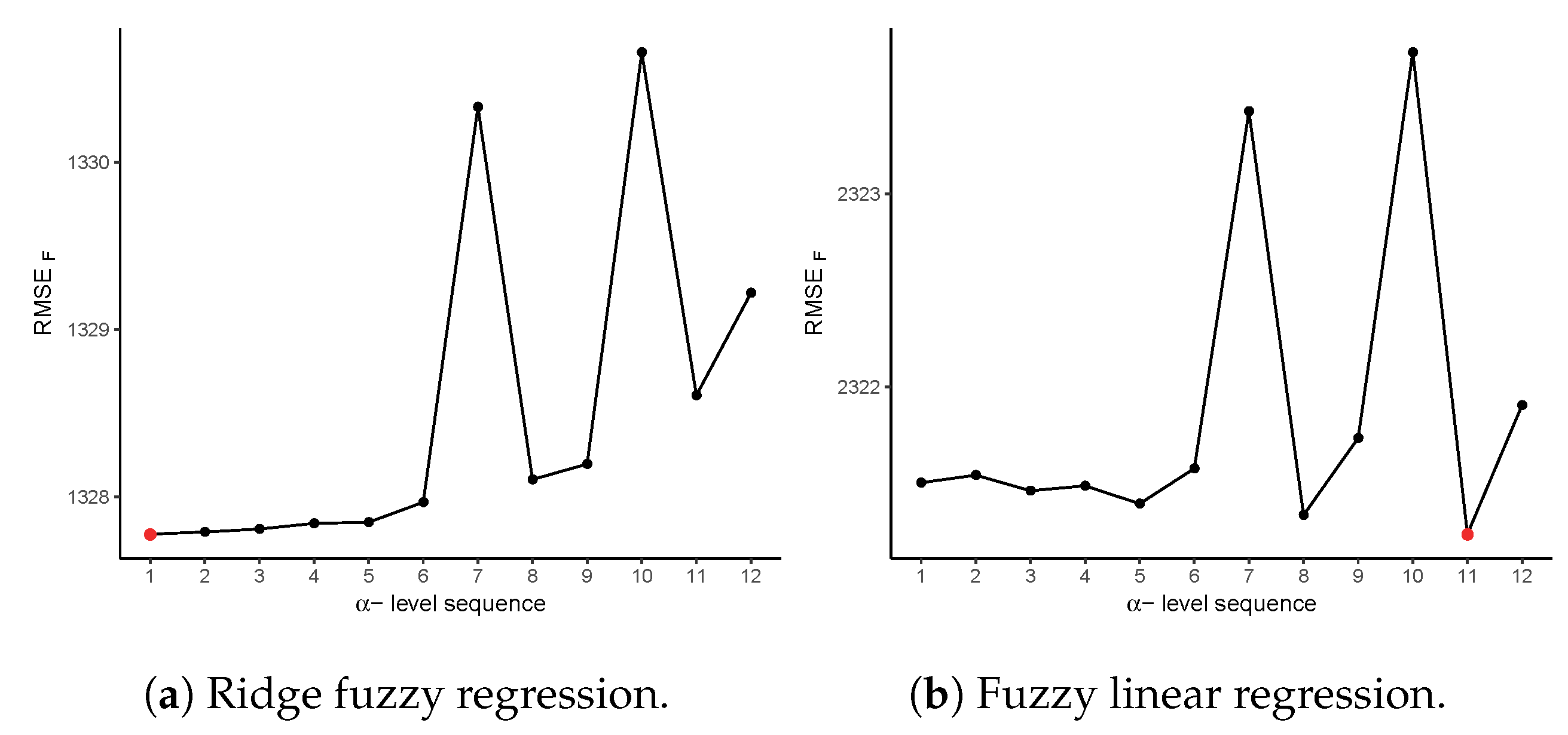
We divide the given data into training and test sets. The model is computed from the training set , and later its performance is evaluated on the test set . Note again that N is the total number of observations, n is the number of observations for the training set, and m is the number of observations for the test set, such that . We fit our ridge fuzzy regression model on the training set by the following estimation algorithm:
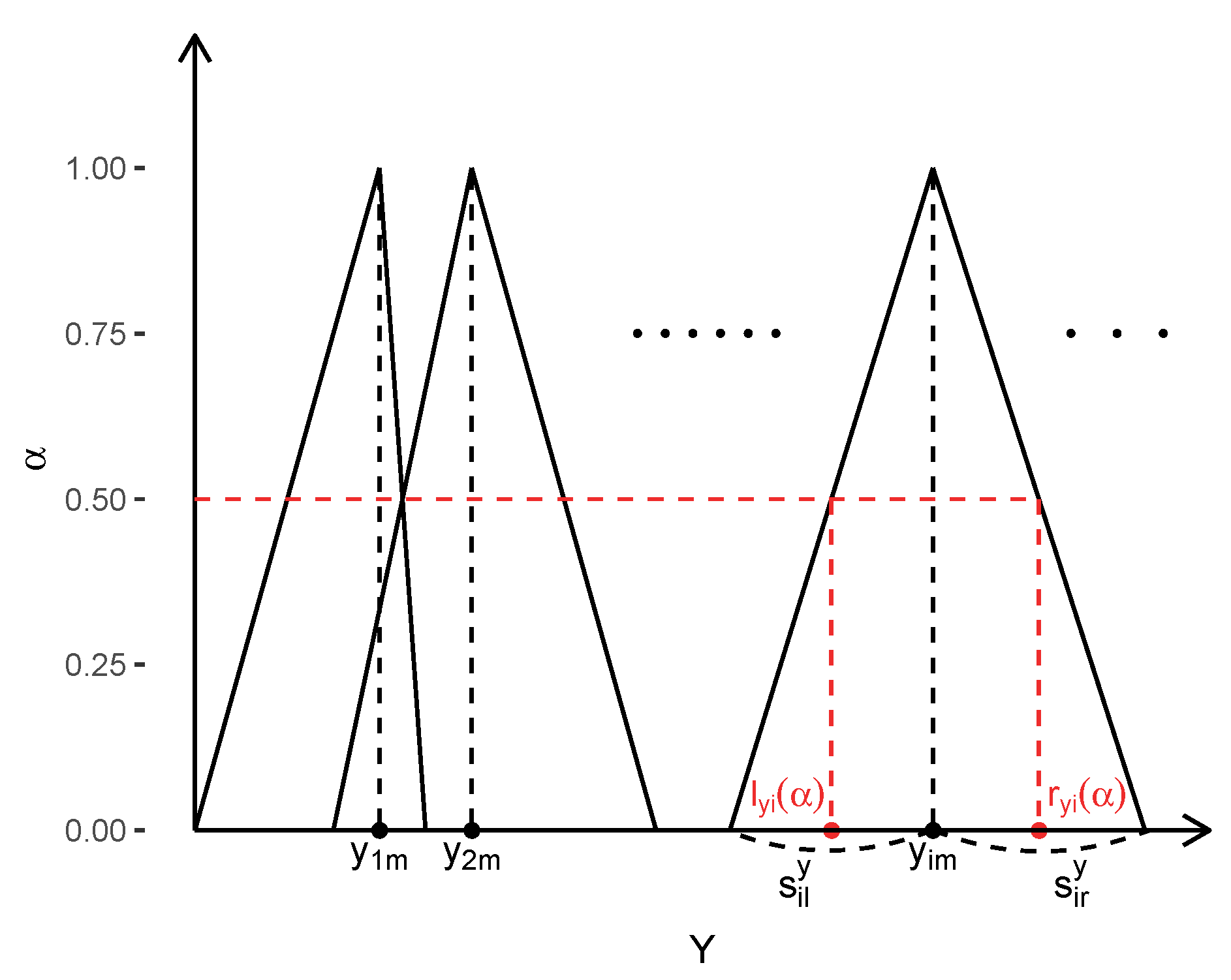
Step 1: Create
-level sets of the triangular fuzzy input and output as illustrated in
Figure 1. For any
-level in
,
where
are the left and right spreads of the dependent and explanatory variables, respectively. The
-levels are denoted by the sequence
for some
K with
.
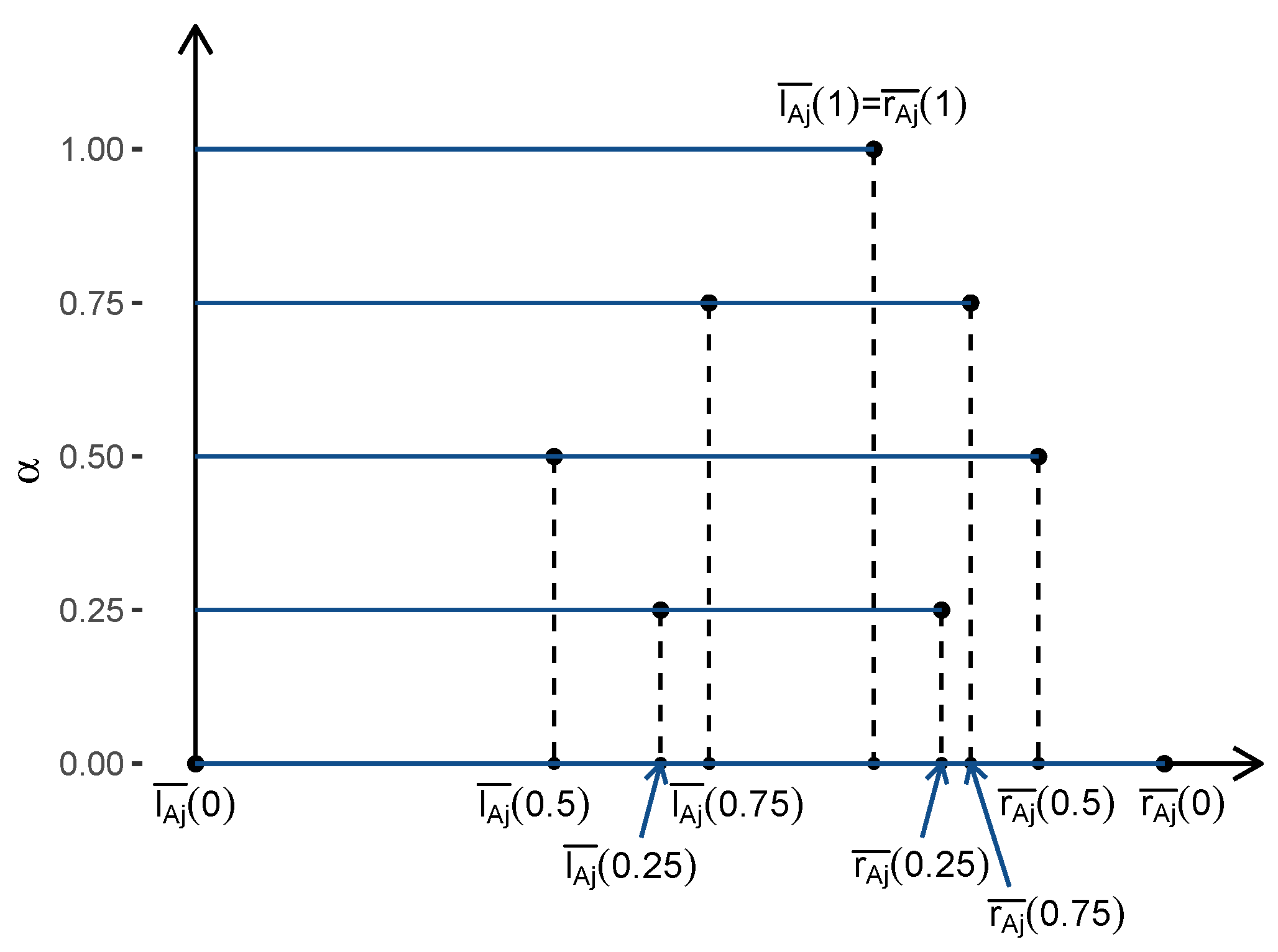
Step 2: Perform ridge regression of
on
for each
. Find the intermediate estimators
and
of
and
by minimizing the following respective ridge loss functions (see
Figure 2).
We assume the endpoints of the
-level set of
has been centered and the endpoints of
-level set of
has been standardized as is by convention in classical ridge regression [
25].
Step 3: Obtain the estimators
and
of
and
by modifying the intermediate estimators
and
so that the estimated coefficients form the membership function of a triangular fuzzy number. For this the following operations are performed (see
Figure 3).
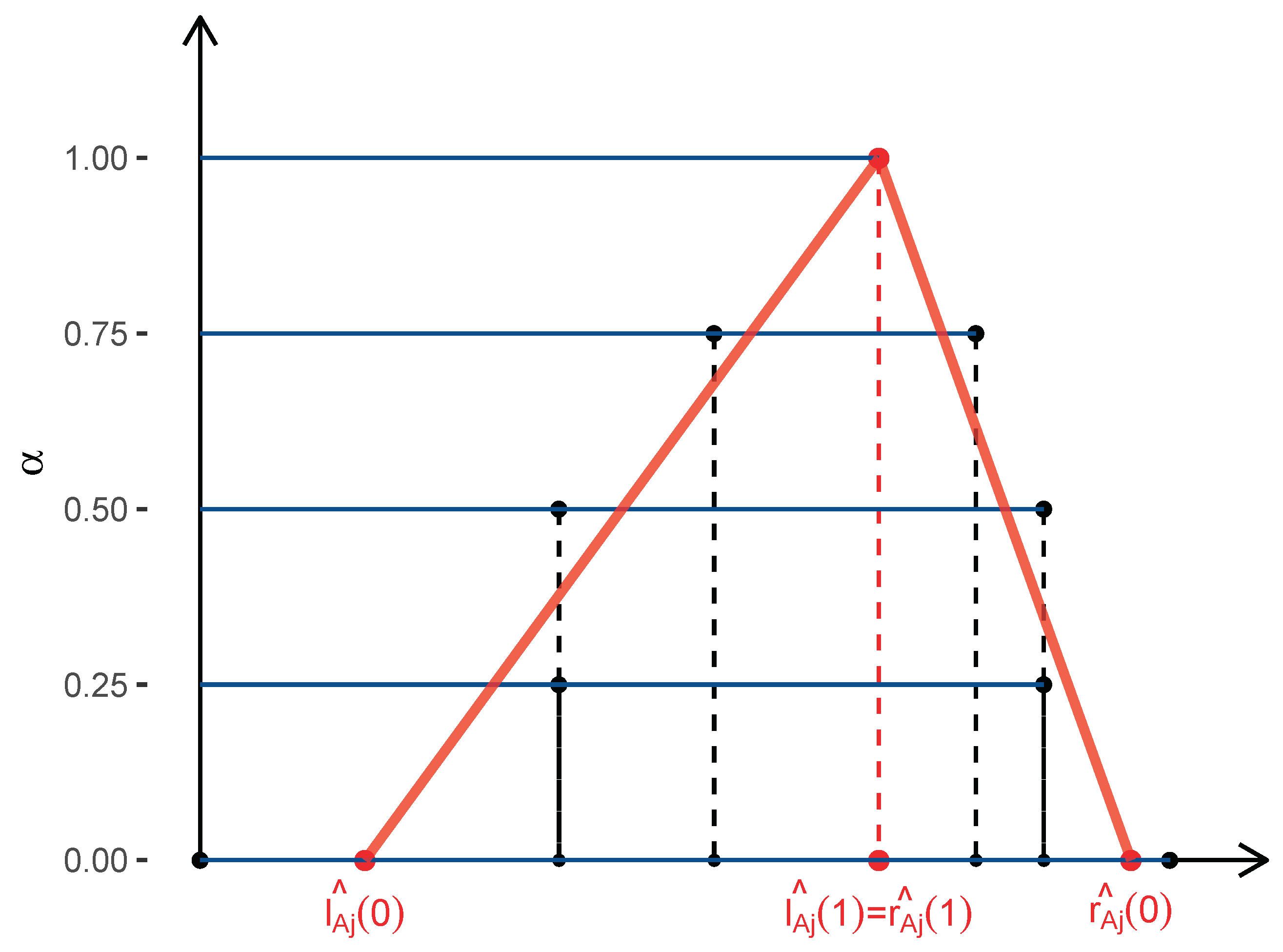
Step 4: Estimate the triangular fuzzy coefficient
and its membership function
by fitting a linear regression line through
and
for
, respectively. A constraint is given so that
satisfy the condition of
(see
Figure 4).
Step 5: Symmetric fuzzy inputs or outputs do not always guarantee that the estimated membership function
will also be symmetric. To reduce the difference between the true values with the fitted values we consider the following candidates:
or
where
is chosen as
, or
where
is chosen as
.
We present two performance criteria based on Diamond’s fuzzy distance measure [
27] to evaluate the proposed fuzzy estimators. Denote the dependent variable as
,
, and its predicted value as
,
. Here
n is the number of observations for the training set. We defined
(root mean square error for fuzzy numbers) and
(mean absolute percentage error for fuzzy numbers) as below.
Compute the for each of the membership functions, then select the one which minimizes the criterion.
Step 6: Repeat Steps 1–5 for selected -level sequences with equally spaced between 0 and 1. Choose the optimal set of -levels which minimizes . Finally, compute the fuzzy ridge coefficient estimate based on that selected sequence.









{kind=link}
{kind=link}
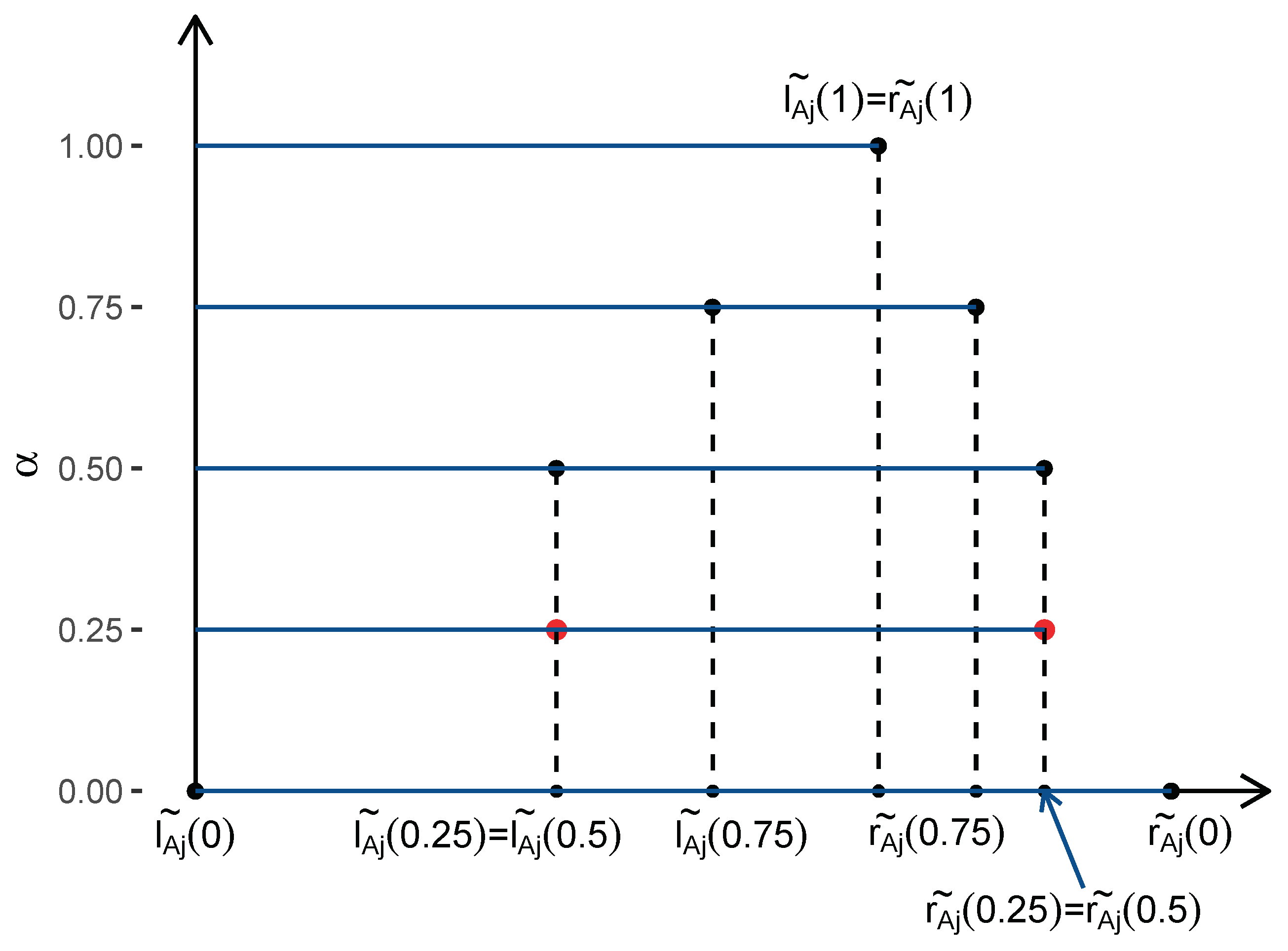{kind=link}
{kind=link}
{kind=link}
{kind=link}