Measuring Arithmetic Word Problem Complexity through Reading Comprehension and Learning Analytics



Abstract
1. Introduction
1.1. Complexity of Arithmetic Word Problems
- The open sentences approach, based on the situation of the question within the statement [19].
1.2. Measuring the Complexity of AWP Statements through a Technological Environment
1.3. Predicting Student Performance When Solving AWPs
2. Material and Methods
2.1. Procedure for Measuring the Complexity of AWPs
2.2. Instrument
2.3. Experimental Design
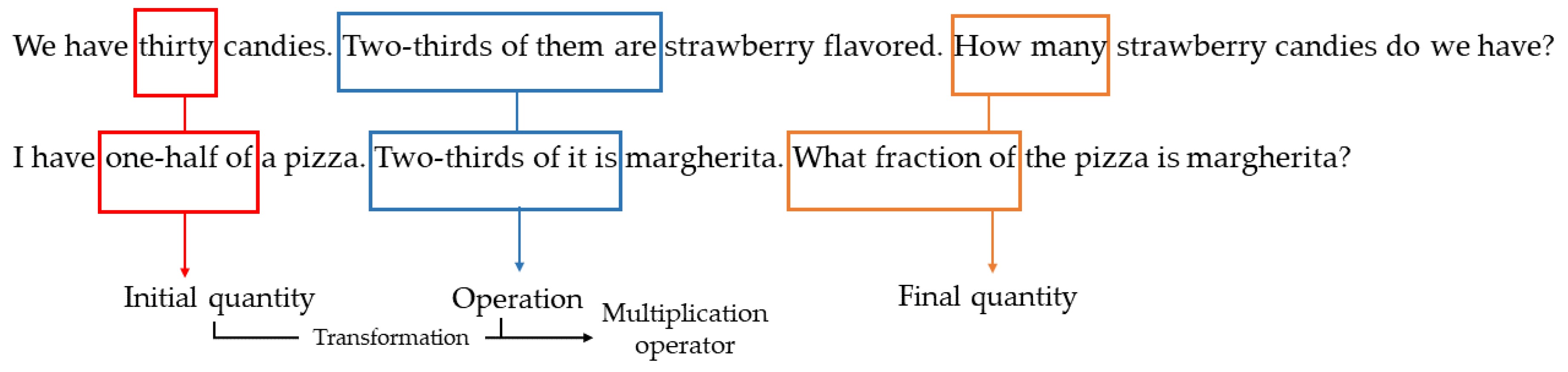
- Task 1: We have thirty candies. Two-thirds of them are strawberry flavored. How many strawberry candies do we have? (From the original: Tenemos treinta caramelos. Si dos tercios son de fresa, ¿cuántos caramelos son de fresa?) The possible answers are 5, 10, 17, 20 and 45.
- Task 2: I have one-half of a pizza. Two-thirds of it is margherita. What fraction of the pizza is margherita? (From the original: Tengo media pizza. Si dos tercios son de margarita, ¿qué porción de pizza es de margarita?) The possible answers are , , , and .
2.4. Research Hypotheses
- H1: The change from natural to fractional numbers increases the complexity of AWPs. According to Perera Dzul [39], difficulties begin when students face the study of fractions, without having prior knowledge and enough situations in daily life that present problems related to rational numbers. Gairín and Muñoz [40], in a study on textbooks for the teaching of rational numbers in secondary education in Spain, affirm that rational numbers are overshadowed by the study of procedural aspects, making it difficult to transfer this concept to daily life problems.
- H2: The use of the fraction as an operator makes statements harder to understand. Authors like Hart [41] have already shown how challenging a syntagm of the type “two-thirds of them are” can be. Sanz, Figueras and Gómez [42] have also observed that students from 15 to 16 years old find it difficult to tackle this expression when presented literally in simple operative exercises.
- H3: Operating on a rational whole is more difficult than operating on a natural whole. Problems arise when the concept of the whole is reformulated. If the whole is not a natural but a fractional number, solving an AWP becomes a more difficult task [43].
3. Analysis and Results
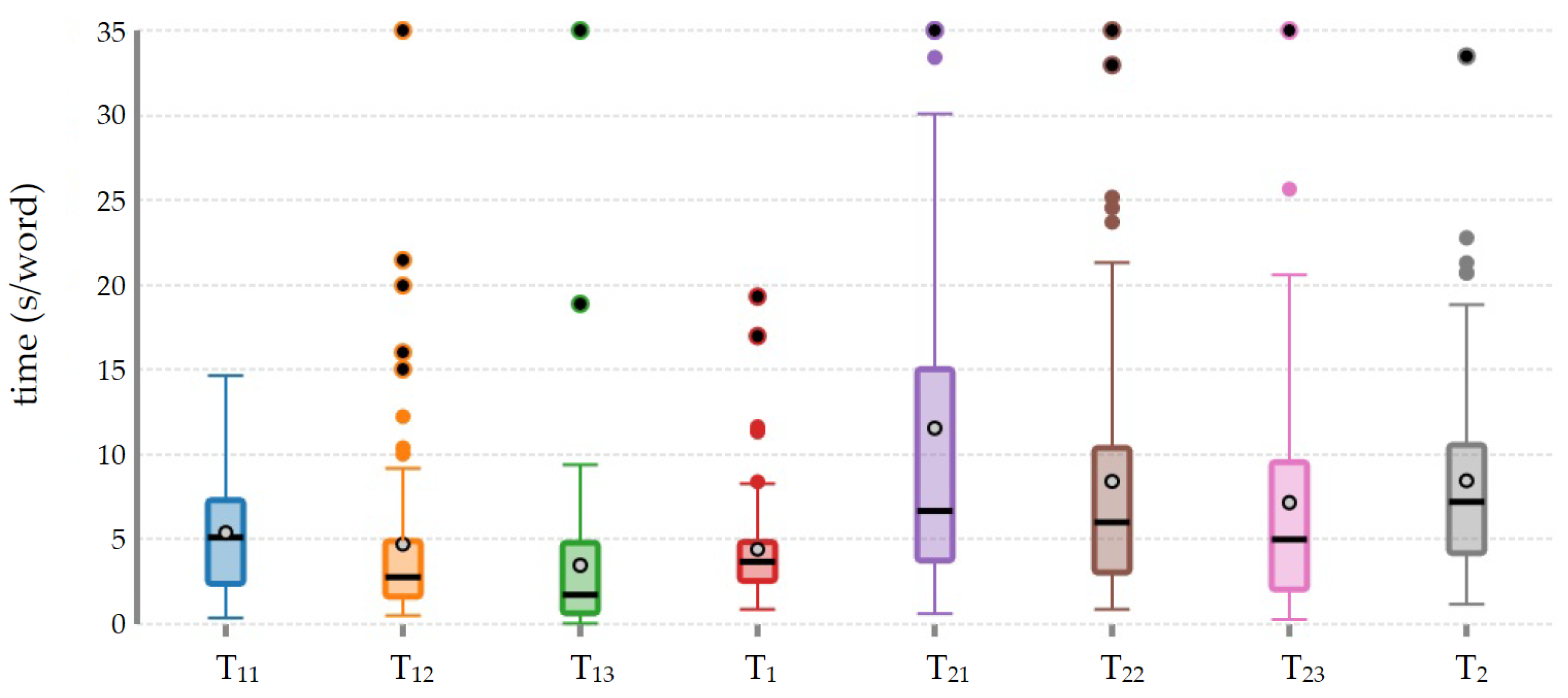
- H1: The change from natural to fractional numbers increases the complexity of AWPs. The median reading time of propositions P11 and P21 increases from 5.12 s/word to 6.68 s/word (see also the difference reported in Figure 5). This rise in complexity is due to the change from a natural to a fractional initial quantity. The difference in medians is statistically significant according to the Wilcoxon signed-rank test (p-value ). The results thus confirm this hypothesis.
- H2: The use of the fraction as an operator makes statements harder to understand. The median reading time of propositions that use the fraction as an operator (i.e., 2.78 s/word for P12 and 6.01 s/word for P22) is shorter than that of the proposition using the fraction as a quantity (i.e., 6.68 s/word for P21). The difference in medians is not statistically significant for task 2 according to the Wilcoxon signed-rank test (p-value ). The difference is significant for task 1 (p-value ) mainly due to the ease of operating on a natural whole, as we analyze below in H3. Thus, the syntagm “of them are” does not introduce further complexity to the statements in the AWPs studied.
- H3: Operating on a rational whole is more difficult than operating on a natural whole. The median reading time of proposition P22 (i.e., 6.01 s/word) is longer than that of proposition P12 (i.e., 2.78 s/word). Differences are statistically significant according to the Wilcoxon signed-rank test (p-value ), as is also shown in Figure 5. Those results confirm the hypothesis that it was more complex to operate on a rational whole (e.g., one-half of a pizza) than to operate on a natural whole (e.g., thirty candies).
4. Predicting Student Success from the Proposed Complexity Measure
5. Discussion and Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Boonen, A.J.; van Wesel, F.; Jolles, J.; van der Schoot, M. The role of visual representation type, spatial ability, and reading comprehension in word problem solving: An item-level analysis in elementary school children. Int. J. Educ. Res. 2014, 68, 15–26. [Google Scholar] [CrossRef]
- Pape, S.J. Middle school children’s problem-solving behavior: A cognitive analysis from a reading comprehension perspective. J. Res. Math. Educ. 2004, 35, 187–219. [Google Scholar] [CrossRef]
- Vilenius-Tuohimaa, P.M.; Aunola, K.; Nurmi, J.E. The association between mathematical word problems and reading comprehension. Educ. Psychol. 2008, 28, 409–426. [Google Scholar] [CrossRef]
- Pólya, G. How to Solve It; Princeton University: Princeton, NJ, USA, 1945. [Google Scholar]
- Puig Espinosa, L.; Cerdán Pérez, F. Problemas Aritméticos Escolares [School Arithmetic Problems]; Síntesis: Madrid, Spain, 1988. [Google Scholar]
- NCTM. Principios y Estándares Para la Educación Matemática [Principles and Standards for School Mathematics Education]; SAEM THALES: Sevilla, Spain, 2003. [Google Scholar]
- OECD. PISA 2018 Assessment and Analytical Framework. 2019. Available online: https://doi.org/10.1787/b25efab8-en (accessed on 1 April 2020).
- Cunningham, A.E.; Stanovich, K.E. Early reading acquisition and its relation to reading experience and ability 10 years later. Dev. Psychol. 1997, 33, 934. [Google Scholar] [CrossRef] [PubMed]
- OECD. OECD Skills Outlook 2013: First Results from the Survey of Adult Skills. 2013. Available online: http://dx.doi.org/10.1787/9789264204256-en (accessed on 1 April 2020).
- Smith, M.C.; Mikulecky, L.; Kibby, M.W.; Dreher, M.J.; Dole, J.A. What Will Be the Demands of Literacy in the Workplace in the Next Millennium? Read. Res. Q. 2000, 35, 378–383. [Google Scholar] [CrossRef]
- Riley, M.S.; Greeno, J.G. Developmental analysis of understanding language about quantities and of solving problems. Cogn. Instr. 1988, 5, 49–101. [Google Scholar] [CrossRef]
- Verschaffel, L.; Greer, B.; De Corte, E. Making Sense of Word Problems; Swets & Zeitlinger: Lisse, The Netherlands, 2000. [Google Scholar]
- Daroczy, G.; Wolska, M.; Meurers, W.D.; Nuerk, H.C. Word problems: A review of linguistic and numerical factors contributing to their difficulty. Front. Psychol. 2015, 6, 348. [Google Scholar] [CrossRef]
- Castro Martínez, E.; Rico Romero, L.; Gil Cuadra, F. Enfoques de investigación en problemas verbales aritméticos aditivos [Research approaches in additive arithmetic word problems]. Ense Nanza Cienc. Rev. Investig. Exp. Didácticas 1992, 10, 243–253. [Google Scholar]
- Aiken, L.R., Jr. Verbal factors and mathematics learning: A review of research. J. Res. Math. Educ. 1971, 2, 304–313. [Google Scholar] [CrossRef]
- Moyer, J.C.; Sowder, L.; Threadgill-Sowder, J.; Moyer, M.B. Story problem formats: Drawn versus verbal versus telegraphic. J. Res. Math. Educ. 1984, 15, 342–351. [Google Scholar] [CrossRef]
- Kilpatrick, J. Variables and methodologies in research on problem solving. In Mathematical Problem Solving: Papers from a Research Workshop; Eric Clearinghouse for Science, Mathematics, and Environmental Education: Columbus, OH, USA, 1978; pp. 7–20. [Google Scholar]
- Goldin, G.A.; McClintock, C.E. Task Variables in Mathematical Problem Solving; ERIC Clearinghouse for Science, Mathematics, and Environmental Education: Columbus, OH, USA, 1979.
- Castro, E.; Rico, L.; Batanero, C.; Castro, E. Dificultad en problemas de estructura multiplicativa de comparacioó [Difficulty in multiplicative comparison word problems]. In Proceedings of the Fifteenth PME Conference, Assisi, Italy, 29 June–4 July 1991; Volume 1, pp. 192–198. [Google Scholar]
- Vergnaud, G. A classification of cognitive tasks and operations of thought involved in addition and subtraction problems. In Addition and Subtraction; Carpenter, T., Moser, J., Eds.; Romberg: London, UK, 1982; pp. 39–59. [Google Scholar]
- Hunt, K.W. Syntactic maturity in schoolchildren and adults. Monogr. Soc. Res. Child. Dev. 1970, 35. [Google Scholar] [CrossRef]
- Alonso-García, S.; Aznar-Díaz, I.; Cáceres-Reche, M.P.; Trujillo-Torres, J.M.; Romero-Rodríguez, J.M. Systematic Review of Good Teaching Practices with ICT in Spanish Higher Education. Trends and Challenges for Sustainability. Sustainability 2019, 11, 7150. [Google Scholar] [CrossRef]
- Conole, G.; Gašević, D.; Long, P.; Siemens, G. Message from the LAK 2011 general & program chairs. In International Learning Analytics & Knowledge Conference 2011; Association for Computing Machinery (ACM): New York, NY, USA, 2011. [Google Scholar]
- López-Iñesta, E.; Costa, D.G.; Grimaldo, F.; Vidal-Abarca Gámez, E. Read&Learn: Una herramienta de investigación para el aprendizaje asistido por ordenador [Read&Learn: A research tool for computer-assisted learning]. Magister Rev. Misc. Investig. 2018, 30, 21–28. Available online: https://doi.org/10.17811/msg.30.1.2018.21-28 (accessed on 1 May 2020).
- Romero, C.; Ventura, S.; García, E. Data mining in course management systems: Moodle case study and tutorial. Comput. Educ. 2008, 51, 368–384. [Google Scholar] [CrossRef]
- Sanz, M.T.; González-Calero, J.A.; Arnau, D.; Arevalillo-Herráez, M. Uso de la comprensión lectora para la construcción de un modelo predictivo del éxito de estudiantes de 4° de Primaria cuando resuelven problemas verbales en un sistema inteligente [Using reading comprehension to build a predictive model for the fourth-grade grade students’ achievement when solving word problems in an intelligent tutoring system]. Rev. Educ. 2019, 384, 41–69. [Google Scholar]
- Gašević, D.; Dawson, S.; Siemens, G. Let’s not forget: Learning analytics are about learning. TechTrends 2015, 59, 64–71. [Google Scholar] [CrossRef]
- Siemens, G.; Long, P. Penetrating the fog: Analytics in learning and education. EDUCAUSE Rev. 2011, 46, 30. [Google Scholar]
- Hernández-Lara, A.B.; Perera-Lluna, A.; Serradell-López, E. Applying learning analytics to students’ interaction in business simulation games. The usefulness of learning analytics to know what students really learn. Comput. Hum. Behav. 2019, 92, 600–612. [Google Scholar] [CrossRef]
- Wong, J.; Baars, M.; de Koning, B.B.; van der Zee, T.; Davis, D.; Khalil, M.; Houben, G.J.; Paas, F. Educational theories and learning analytics: From data to knowledge. In Utilizing Learning Analytics to Support Study Success; Springer: Berlin/Heidelberg, Germany, 2019; pp. 3–25. [Google Scholar]
- López-Iñesta, E.; Garcia-Costa, D.; Grimaldo, F.; Sanz, M.T.; Vila-Francés, J.; Forte, A.; Botella, C.; Rueda, S. Efecto de la Retroalimentación Orientada al Acierto: Un Caso de Estudio de Analítica del Aprendizaje [The Effect of Task-Oriented Feedback: A Learning Analytics Case Study]; Actas de las Jornadas sobre Enseñanza Universitaria de la Informática (JENUI), 2020; Volume 5, pp. 337–340. Available online: http://www.aenui.net/ojs/index.php?journal=actas_jenui&page=article&op=view&path%5B%5D=551 (accessed on 1 June 2020).
- MacLellan, C.J.; Liu, R.; Koedinger, K.R. Accounting for Slipping and Other False Negatives in Logistic Models of Student Learning. In Proceedings of the International Conference on Educational Data Mining (EDM), Madrid, Spain, 26–29 June 2015. [Google Scholar]
- Rasch, G. Studies in Mathematical Psychology: I. Probabilistic Models for some Intelligence and Attainment Tests; Danmarks pædagogiske Institut: Copenhagen, Denmark, 1960. [Google Scholar]
- Pitarque, A.; Roy, J.F.; Ruiz, J.C. Redes neurales vs modelos estadísticos: Simulaciones sobre tareas de predicción y clasificación [Neural network and statistical models: Simulations on prediction and classification tasks]. Psicológica 1998, 19, 387–400. [Google Scholar]
- Reed, S.K. A structure-mapping model for word problems. J. Exp. Psychol. Learn. Mem. Cogn. 1987, 13, 124. [Google Scholar] [CrossRef]
- Schwartz, J.L. The Role of Semantic Understanding in Solving Multiplication & Division Word Problems. Final Report; Division for Study & Research in Education, Massachusetts Institute of Technology: Cambridge, MA, USA, 1981. [Google Scholar]
- Kieren, T.E. (Ed.) The rational number construct: Its elements and mechanisms. In Recent Research on Number Learning; ERIC Clearinghouse for Science, Mathematics, and Environmental Education: Columbus, OH, USA, 1980; pp. 125–149. [Google Scholar]
- Hegarty, M.; Mayer, R.E.; Monk, C.A. Comprehension of arithmetic word problems: A comparison of successful and unsuccessful problem solvers. J. Educ. Psychol. 1995, 87, 18. [Google Scholar] [CrossRef]
- Perera Dzul, P.B.; Valdemoros Álvarez, M.E. Enseñanza experimental de las fracciones en cuarto grado [Fraction experimental teaching in fourth grade]. Educ-Mat 2009, 21, 29–61. [Google Scholar]
- Gairín, J.; Múñoz, J.M. El Número Racional Positivo en la Práctica Educativa: Estudio de una Propuesta Editorial [The Rational Number in Educational Practice: The Examination of a Publisher Proposal]. IX Simposio SEIEM. 2005. Available online: https://www.seiem.es/docs/comunicaciones/GruposIX/pna/gairinmunoz.pdf (accessed on 1 June 2020).
- Hart, K.M. Ratio: Children’s Strategies and Errors: A Report of the Strategies and Errors in Secondary Mathematics Project; Nfer Nelson: Berkshire, UK, 1984. [Google Scholar]
- Sanz, M.T.; Figueras, O.; Gómez, B. Las fracciones, habilidades de alumnos de 15 a 16 años [Fractions, student’s skills from 15 to 16 years old]. Rev. Educ. Univ. Granada 2018, 25, 257–279. [Google Scholar]
- Sanz, M.T.; Valenzuela, C.; Figueras, O. “De lo que queda”, hacia un sistema tutorial inteligente [“What remains”, towards an intelligent tutorial system]. In Investigación en Educación Matemática XXIII; Sociedad Española de Investigación en Educación Matemática, SEIEM: Valladolid, Spain, 2019; p. 654. [Google Scholar]
- Ivars, P.; Fernández, C. Aprendiendo a mirar profesionalmente el pensamiento matemático de los estudiantes en el contexto de las prácticas de enseñanza. El papel de las narrativas [Learning to notice students’ mathematical thinking in the context of the teaching practices. The role of the narrative]. Ensayos. Rev. Fac. Educ. Albacete 2015, 30, 45–54. [Google Scholar]
- Garzón, E.; Sola, T.; Ortega, J.L.; A, M.J.; Gómez, G.E. Teacher Training in Lifelong Learning—The Importance of Digital Competence in the Encouragement of Teaching Innovation. Sustainability 2020, 12, 2852. [Google Scholar] [CrossRef]
- Rodríguez-García, A.M.; Aznar, I.; Cáceres, P.; Gomez, G. Digital competence in higher education: Analysis of the impact of scientific production indexed in Scopus database. Rev. Espacios 2019, 40, 14. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Prop | Task 1 | Prop | Task 2 |
|---|---|---|---|
| P11 | We have thirty candies | P21 | I have one-half of a pizza |
| Tenemos treinta caramelos | Tengo media pizza | ||
| P12 | Two-thirds of them are strawberry flavored | P22 | Two-thirds of it is margherita |
| Si dos tercios son de fresa | Si dos tercios son de margarita | ||
| P13 | How many strawberry candies do we have? | P23 | What fraction of the pizza is margherita? |
| ¿cuántos caramelos son de fresa? | ¿qué porción de pizza es de margarita? |
| Prop | Words | Nouns | Verbs | Numerals | Prepositions | Conjunctions | Level/Type |
|---|---|---|---|---|---|---|---|
| P11 | 3 | 1 | 1 | 1 | 0 | 0 | L0/Declarative |
| P12 | 6 | 1 | 1 | 2 | 1 | 1 | L1/Subordinate |
| P13 | 5 | 2 | 1 | 1 | 1 | 0 | L1/Interrogative |
| P21 | 3 | 1 | 1 | 1 | 0 | 0 | L0/Declarative |
| P22 | 6 | 1 | 1 | 2 | 1 | 1 | L1/Subordinate |
| P23 | 7 | 3 | 1 | 1 | 2 | 0 | L1/Interrogative |
| T11 | T12 | T13 | T1 | T21 | T22 | T23 | T2 | |
|---|---|---|---|---|---|---|---|---|
| Mean | 5.39 | 4.72 | 3.47 | 4.42 | 11.55 | 8.42 | 7.17 | 8.46 |
| Median | 5.12 | 2.78 | 1.73 | 3.67 | 6.68 | 6.01 | 5.01 | 7.21 |
| St. Dev. | 3.63 | 5.68 | 5.96 | 3.23 | 12.45 | 8.22 | 9.12 | 5.91 |
| Min | 0.37 | 0.51 | 0.04 | 0.88 | 0.62 | 0.88 | 0.27 | 1.19 |
| Max | 14.66 | 36.42 | 45.95 | 19.31 | 66.38 | 49.88 | 70.65 | 33.47 |
| Q1 | 2.36 | 1.61 | 0.64 | 2.50 | 3.58 | 3.05 | 2.03 | 4.18 |
| Q3 | 7.38 | 4.99 | 4.83 | 4.89 | 15.10 | 10.45 | 9.55 | 10.62 |
| Success | inverse | inverse | inverse | direct | direct | direct |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanz, M.T.; López-Iñesta, E.; Garcia-Costa, D.; Grimaldo, F. Measuring Arithmetic Word Problem Complexity through Reading Comprehension and Learning Analytics. Mathematics 2020, 8, 1556. https://doi.org/10.3390/math8091556
Sanz MT, López-Iñesta E, Garcia-Costa D, Grimaldo F. Measuring Arithmetic Word Problem Complexity through Reading Comprehension and Learning Analytics. Mathematics. 2020; 8(9):1556. https://doi.org/10.3390/math8091556
Chicago/Turabian StyleSanz, Maria T., Emilia López-Iñesta, Daniel Garcia-Costa, and Francisco Grimaldo. 2020. "Measuring Arithmetic Word Problem Complexity through Reading Comprehension and Learning Analytics" Mathematics 8, no. 9: 1556. https://doi.org/10.3390/math8091556
APA StyleSanz, M. T., López-Iñesta, E., Garcia-Costa, D., & Grimaldo, F. (2020). Measuring Arithmetic Word Problem Complexity through Reading Comprehension and Learning Analytics. Mathematics, 8(9), 1556. https://doi.org/10.3390/math8091556