In this section, we briefly introduce the fundamentals of RL and IRL.
2.1. Reinforcement Learning
RL [
9] is an area of Machine Learning concerned with the problem of sequential decision-making. This problem has been modeled in decision theory as a Markov Decision Process (MDP). An MDP is a 4-tuple {
,
,
,
} where
is the state space,
is the action space,
defines the (stochastic) transition from one state to another, and a reward function
. The function
gives the probability of changing to a certain state from another one after performing an action, and models the interactions with the environment. The state signal
describes the environment at discrete time
t. Let
A be a discrete set. In the state
, the decision process can select an action from the action space
. The execution of the action in the environment changes the state to
following the probabilistic transition function
. Each decision triggers an immediate scalar reward given by the reward function
that represents the value of the decision taken in the state
. The goal of the process is to maximize at each time-step
t the expected discounted return defined as:
where the
parameter is the discount factor and the expectation
E is taken with the probabilistic state transition
[
10]. The discounted return takes into account not only the immediate reward got at time
t but also the future rewards. The discount factor controls the importance of the future rewards. A policy is a function
and represents a particular behavior inside the MDP. Another way of representing a policy is as a probability distribution over the state–action pairs
. The Action-value function (Q-function)
is the expected return of a state–action pair given the policy
:
The goal of the RL algorithm is to find an optimal
such as
. The optimal policy
is automatically derived from
as it is defined in Equation (
3):
This problem is highly related with the Multi Armed Bandit problem in which it has a first motivation and benchmark [
11,
12,
13].
Two main streams exist in the RL framework: value function algorithms and policy gradient algorithms. The former tries to find a function that maps state–action pairs with their expected return for the desired task. The latter works in the policies space trying to adjust a parametric policy via gradient ascent to find one that accomplishes the task. Soft Q-learning, used in this paper (see
Section 2.2.1), should be included in the first group.
2.2. Inverse Reinforcement Learning
In RL, the source of information for the learned control or behavior is the reward function. This signal must be rich enough to evaluate all the key decisions taken in the learning process to converge to the optimal policy. Nevertheless, in many cases, the design of the reward function is difficult especially when the policy we want to find is very specific with respect to the selection of actions (i.e., a bad selection of an action can give a result far from the expected control or trajectory). In these cases, the definition of a rough reward function can be derived in unsatisfactory policies. IRL addresses the problem from another point of view. Given a set of examples taken from real life or from an expert, the goal of IRL is to find a reward function that can provide, after an RL process, a policy that generates results similar to those presented as examples [
14,
15,
16]. Formally, given {
,
,
} and a policy
(from examples or an expert), we want to find the set of reward functions {
} where
is an optimal policy in the MDP {
,
,
,
}. In the practical cases, we are not provided with a policy
but with a set of examples derived from it. In this case, the goal is to define rewards that generate policies consistent with the provided examples.
Several IRL approaches consider the existence of a vector
of feature functions
and a set of examples
, that is, sequences of pairs
made by an expert or the real phenomena in the nature. It is assumed that the feature functions
measure properties that are relevant for the decision process (e.g., in the experiment proposed in [
17], they are the current occupancy of a specific cell in the gridworld, in a driving simulator they can be properties of the driving style such as change of line, crash with other car...). Given an MDP, a discounted feature expectation vector is defined for a policy
and a discount factor
as
In the case of the description of the real process, we do not know the implicit policy and it is estimated using the set of examples
These definitions are also valid for episodes with infinite time horizon (
). Considering a model of the reward function as a linear combination of the feature functions
, the feature expectation vector of a policy
completely determines the expected sum of discounted rewards for acting using this policy [
16,
17]. The goal of IRL is to optimize the reward function to generate a policy
with a discounted feature expectation vector
that accomplishes:
Matching feature expectation vectors is an ill-posed problem: there are many solutions, including the degenerate solution (that is assigning probability zero to the trajectories of the set
) for this optimization problem. Several formulations of the IRL problem have been proposed. The work by [
16] formulates the problem as a linear programming optimization while the work in [
17] proposes a quadratic programming optimization problem. The difficulty with these approaches is that they provide as output a mixture of policies that guarantees in expectation Equation (
6). Given a finite set of policies
, a new mixed policy can be built whose discounted feature expectation vector is a convex combination of those of the set of policies
, where the probability of choosing policy
is
. We can calculate the probabilities
finding the closest point to
in the convex closure of
solving a quadratic programming problem [
17]. In the simulation domain (and specifically in pedestrian simulation), a mixture of policies that, in expectation, satisfies feature matching is not acceptable because it can produce a feeling of random and non-realistic behaviors. Other works [
18,
19] have focused on avoiding the degenerate solution of the optimization problem.
Recently, the use of deep learning has been included in the IRL framework for problems with large or continuous state and action spaces. The work by [
20] proposes a version of the Maximum Entropy IRL problem with a nonlinear representation of the reward function using a neural network for robotic manipulation. The work by [
21] derives from the generative adversarial network paradigm a model-free imitation learning algorithm that extracts directly a policy from data.
Some of these approaches have been used in the problem domain of the pedestrian simulation. The work by [
22] uses the approach discussed in [
17]. The authors propose a geometric interpretation that builds a convex hull extracting critical information from the normals of the facets of that hull. The problem is that the process suffers from the curse of dimensionality with the number of chosen features. The work in [
23] extends the problem to the multi-agent setting. The authors study a traffic-routing domain and find a formulation similar to that proposed in [
16]. The multi-agent problem is decomposed in multiple agent-based optimizations, each one focusing on a part of the state space assuming a complete observation of it. Recently, interest has also focused on deep learning-based solutions. The work by [
24] uses Deep Inverse Reinforcement Learning for multiple path planning for predicting crowd behavior in the distant future. The work by [
25] implemented Inverse Reinforcement Learning using two algorithms: the Maximum Entropy algorithm and the Feature Matching algorithm to estimate the reward function of cyclists in following and overtaking interactions with pedestrians.
In this paper, we propose formulating IRL as a maximum causal entropy estimation task [
26,
27] to overcome the problems of policy mixture creation and degenerate solutions of the previous cited proposals. The maximum entropy principle [
28] is an extensively used statement in statistics and probability theory. Applied in the IRL context, it prescribes the policy that is consistent with the example set of trajectories that has no any other assumptions (bias) about the problem or data [
26]. This criterion is applied by maximizing Shannon’s expected information conditional entropy
, where
Y are the predicted variables of the model and
X are the side information about the problem that we do not want to model and the expectation is taken with respect to the joint probability of
Y and
X. In the MDPs context, the predicted variables
are sequences of actions in
and the side information variables
are the provided sequence of states
generated by interaction with the environment [
26]. The
causal entropy [
29,
30] goes a step further considering that the causally conditioned probability of a random variable
depends only on the
previous sequence of states and actions occurred in the time sequence
(note the double vertical line for distinguishing causal probability from conditioned probability and note that the sequences of variables go from 1 to time
t and
for states and actions, respectively. The causal entropy is then defined for an infinite horizon context as [
27,
31]:
where the expectation in each time period
t is taken from the joint probability distribution of
and
, which depends on the transition probability of the MDP (
) and the policy
.
The formulation of IRL as a maximum causal entropy estimation is as follows:
To solve this non-convex optimization problem, it is converted to an equivalent convex one considering a Lagrangian relaxation of Equation (
8) and a dual problem formulation. From now on in this subsection, we follow the discussion and given demonstrations of [
31].
First, we consider the following partial Lagrangian relaxation:
For a fixed
, the objective function can be maximized since the feasible set is closed and bounded. Then, we define
as the value of this optimization problem (Equation (
9)) for a fixed
. Since any solution of the optimization problem shown in Equation (
8) is feasible for this problem, this implies that
is an upper bound of the optimal value of Equation (
8). The dual problem formulation finds the lowest upper bound:
This is a convex optimization problem. The work by [
31] proves that strong duality holds for the original problem (Equation (
8)) and the dual problem (Equation (
10)). Therefore, if we denote
to the primal optimal value, then the following holds:
.
We can relax the optimization problem of Equation (
9) for the other constraints leading to another Lagrangian relaxation optimization problem:
Following the same reasoning than before, the dual problem
is a convex optimization problem.
2.2.1. Soft Q-Learning
The practical solution of the problem formulated in Equation (
12) has the form of a gradient-based algorithm [
31]. It has three steps: first, find a parameterized policy
with the current reward
. Second, evaluate the policy and calculate
. Third, use a gradient-ascent with respect to parameters
to adjust the value of the linear reward. The gradient of the dual problem is
.
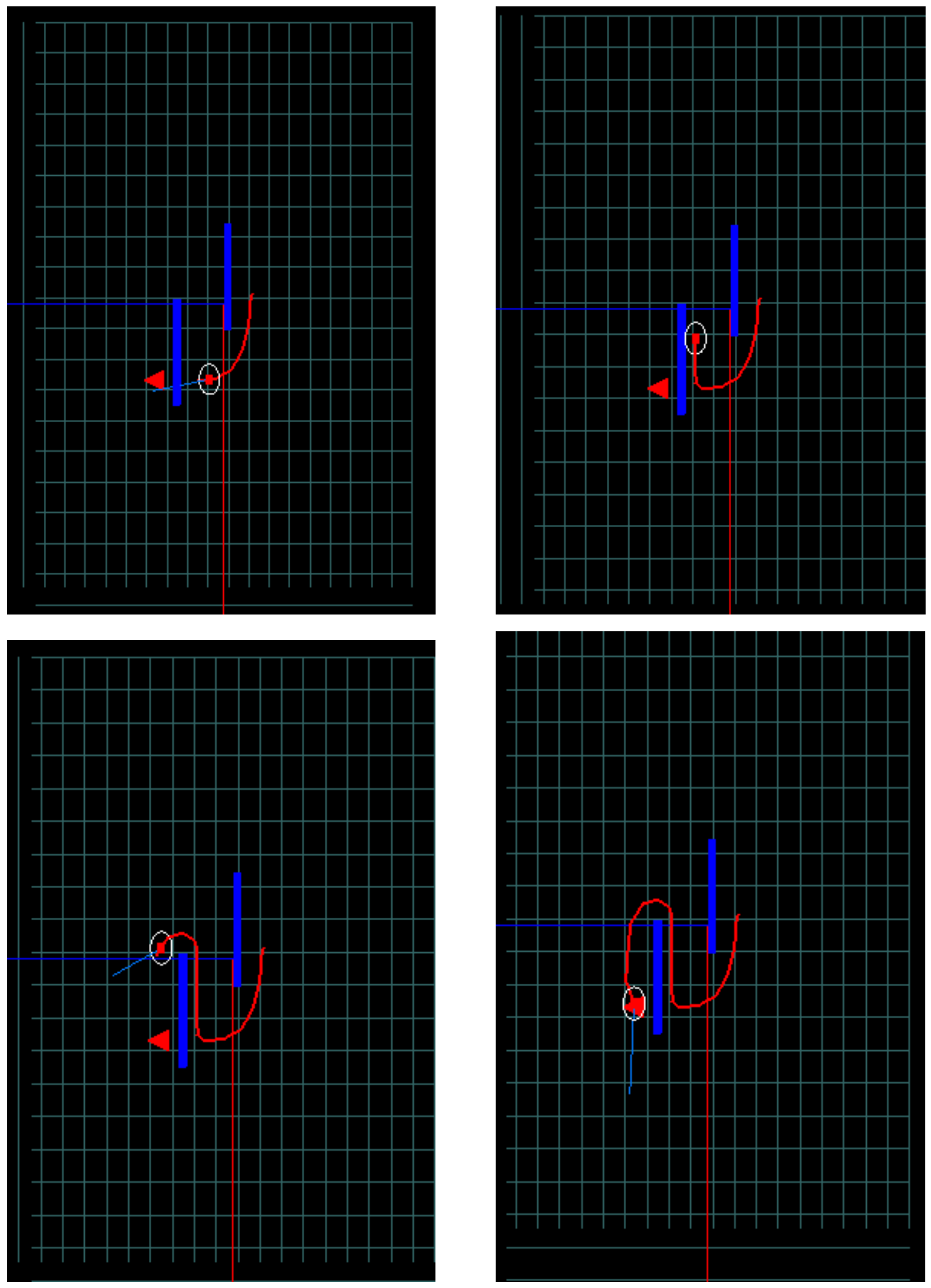
When the transition probabilities are known, the policy can be found using Dynamic Programming. If they are not known, as in this case (model-free case), the authors propose the use of algorithm Soft Q-learning that is a variation of the Q-learning algorithm, a well-known temporal difference learning method in RL. The schema are summarized in Algorithm 1.
A Soft Q-learning algorithm uses a recursive updating rule to back-up the value function defined as:
where
and
is the proposed linear reward
. The presence of a Softmax-type distribution of the values of Q is a result of the application of the maximum entropy principle, which provides Boltzmann-like solutions. When there is a
with
considerably larger than the others, the update rule transforms in the Q-learning rule, selecting
. On the contrary, when the values of the actions for the state
s are similar, all the actions contribute in the rule.
In [
31], the authors prove that this rule is a contraction that converges to a parameterized softmax policy
that is unique. This policy is defined as
for a given (learned) value function
with fixed
.
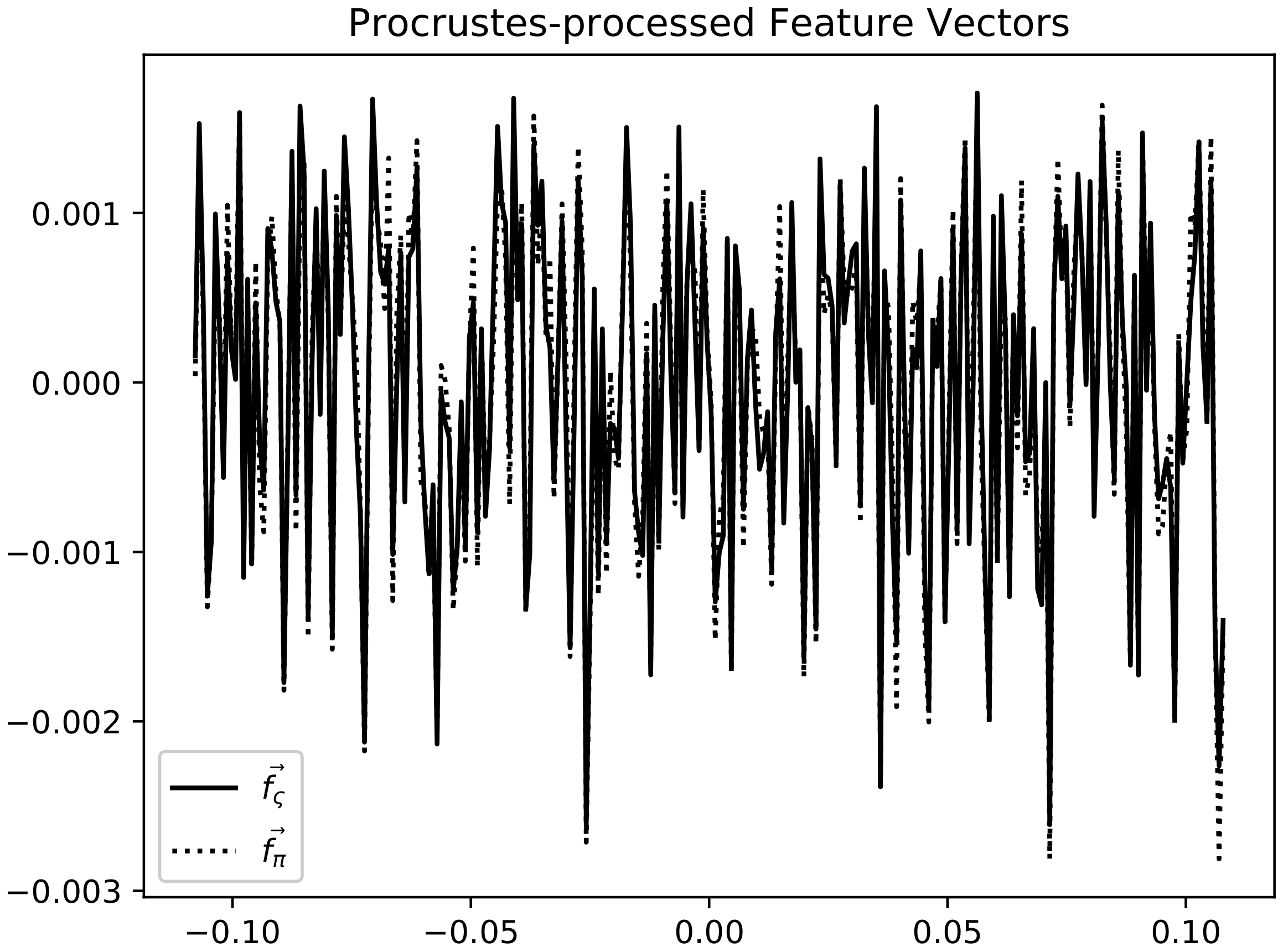
The problem is then solved with an iterative schema where the reward is adjusted using gradient ascent to get a new policy by means of a Soft Q-learning process and then calculates a feature vector more approximate to .
Soft Q-learning [
31] is described in Algorithm 2.
| Algorithm 2: Soft Q-Learning |
 |

 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}