The Optimal Setting of A/B Exam Papers without Item Pools: A Hybrid Approach of IRT and BGP

 ,
, 
 ,
,
Abstract
1. Introduction
1.1. Background
1.2. Literature Review
1.2.1. Importance of the RQ
1.2.2. Implications of Exam Fairness and Novelty of the RQ
1.2.3. Relevance of the IRT wrt the Analysis of the RQ
- Decide on the desirable curve and target for the information function, based on the testing objective.
- Select a set of items from a question bank and calculate the test information amount for each item.
- Add and delete items and recalculate the sum of information amounts for all included items.
- Repeat steps 2–3 until the aggregated information amount approaches the target for the test and becomes satisfactory.
1.2.4. Relevance of BGP and the Novelty of the IRT–BGP Approach
1.3. Results: A Brief
2. Methods
2.1. Experimental Flow
2.2. IRT Modelling
2.3. BGP Modelling
2.4. Short Summary
3. Results
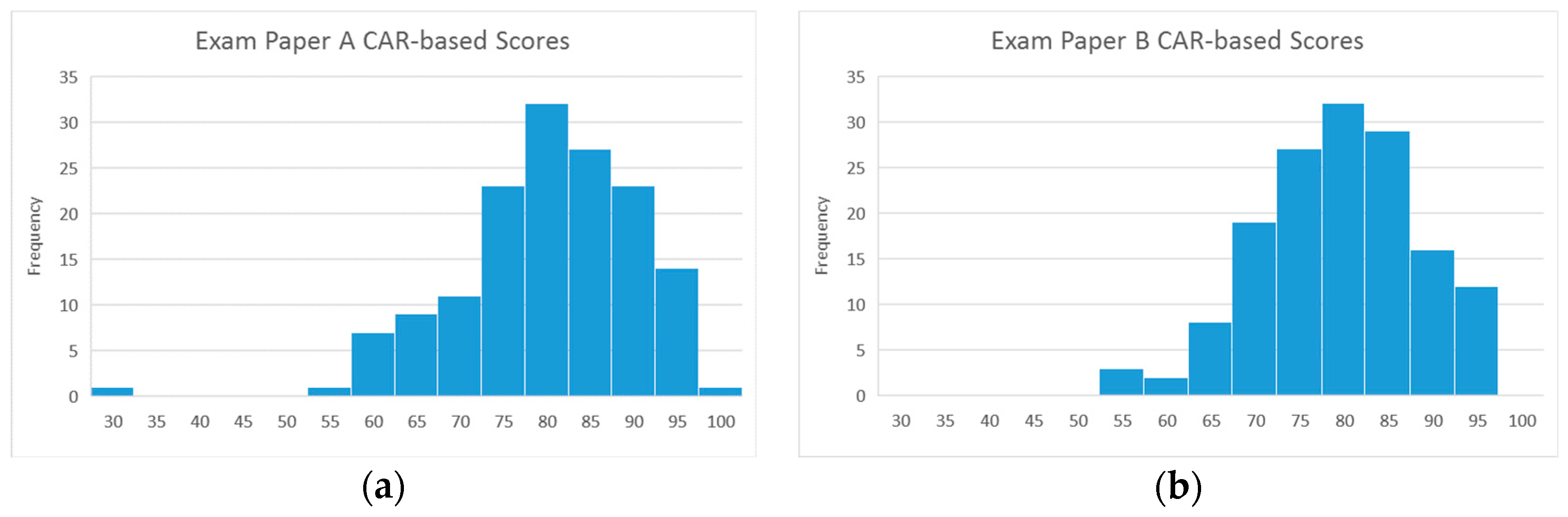
3.1. The Unfair A/B Test
3.2. Estimating the Item Parameters Using IRT
3.3. Modelling the Problem Using the BGP Model
4. Discussion and Implications
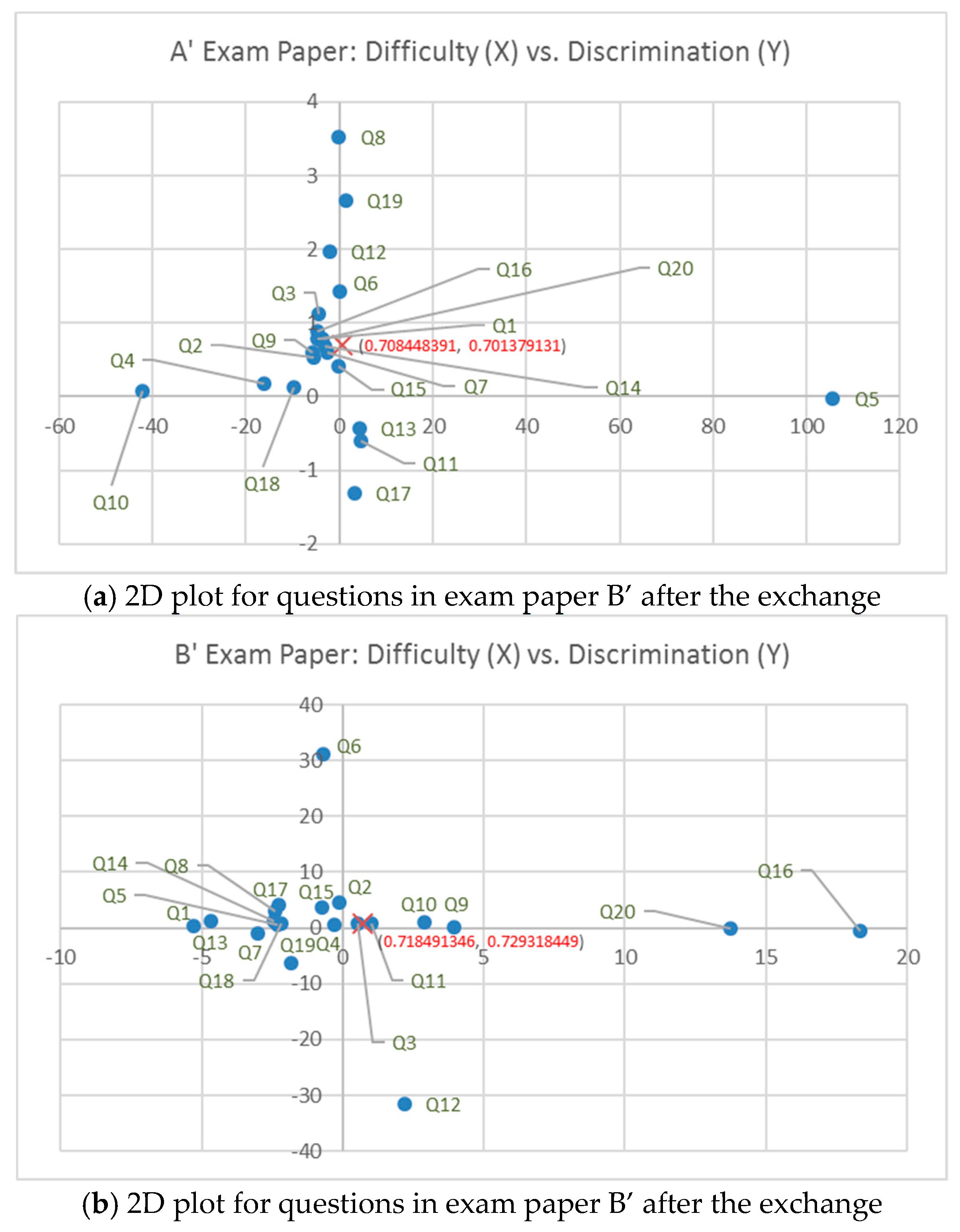
4.1. Analysis of the Exchange Plan
4.2. Distributions of Question Items in New Exam Papers
4.3. The Role of Weights: A Further Analysis
A Sensitivity Analysis
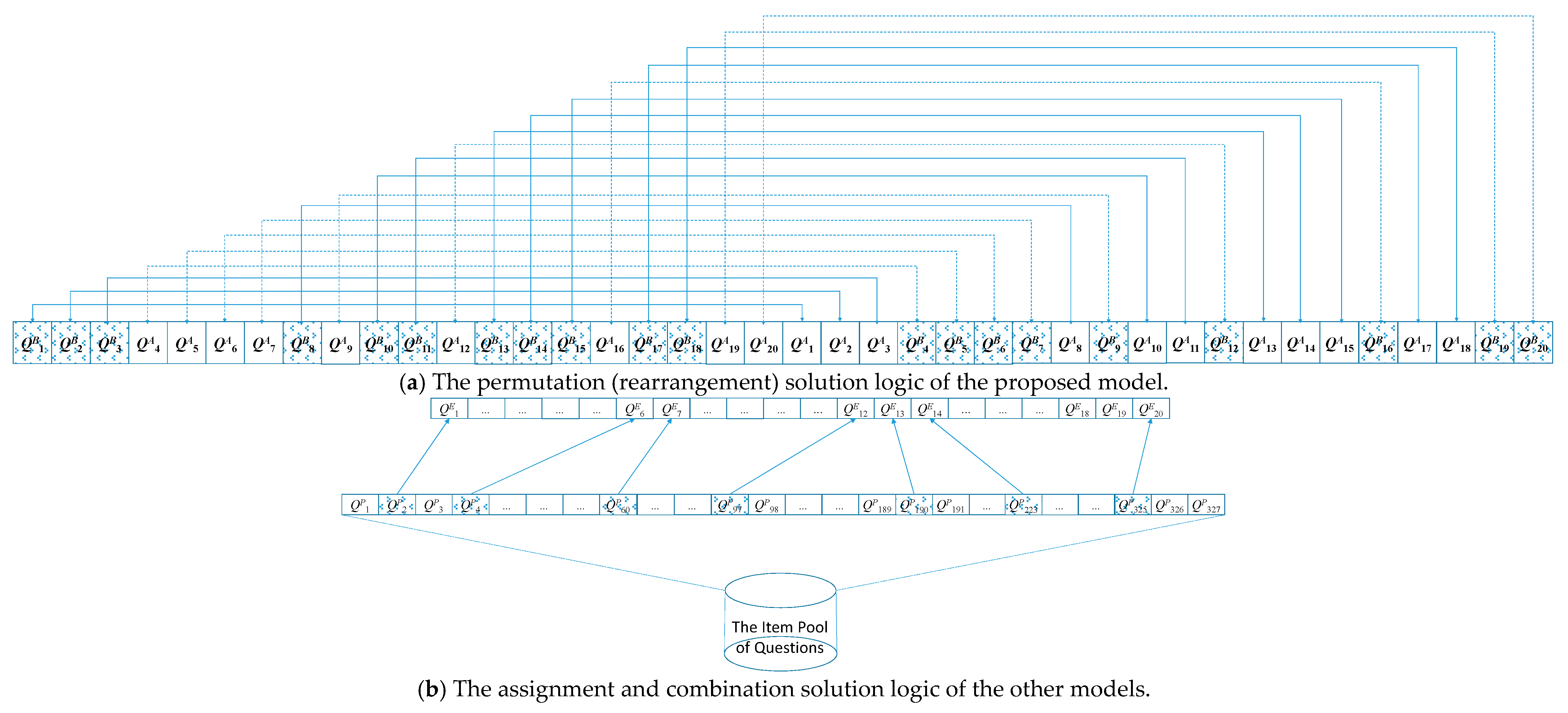
4.4. Flow for Future Implementation of IRT–BGP
- (1)
- The teacher or teacher’s team construct both the original A and B exam papers, with each pair of questions being associated with a certain piece of knowledge.
- (2)
- A pre-test that uses the original papers is given to two individual random groups of students who are not the respondents in the real test.
- (3)
- The answers to all the questions in the pre-test are recorded, and the correctness of the answers is justified to form the data warehouse required for subsequent analysis.
- (4)
- Use IRT to estimate the guessing, difficulty and discrimination parameters for each item contained in A and B, based on the data available in (3).
- (5)
- Build a (BGP–item exchange planning) model using the item parameters estimated in (4). Solve the model to determine an ‘exchange plan’. Obtain two new exam papers, A’ and B’ by reference to the plan.
- (6)
- The new A’ and B’ exam papers are used to test two student groups in the real A/B test.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix B
Appendix C
Appendix D
Appendix E
Appendix F

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Qj in Exam Paper A | Planned Exchanges | Qj in Exam Paper B | Remark (yj) | Exchanges (BGP–IEP) | yj (BGP–IEP) |
|---|---|---|---|---|---|
| Q1 | Q1 | 1 | ⇋ | 1 | |
| Q2 | ⇋ | Q2 | 0 | ⇋ | 1 |
| Q3 | ⇋ | Q3 | 0 | ⇋ | 1 |
| Q4 | ⇋ | Q4 | 0 | 0 | |
| Q5 | ⇋ | Q5 | 0 | 0 | |
| Q6 | ⇋ | Q6 | 0 | 0 | |
| Q7 | ⇋ | Q7 | 0 | 0 | |
| Q8 | ⇋ | Q8 | 0 | ⇋ | 1 |
| Q9 | ⇋ | Q9 | 0 | 0 | |
| Q10 | Q10 | 1 | ⇋ | 1 | |
| Q11 | Q11 | 1 | ⇋ | 1 | |
| Q12 | ⇋ | Q12 | 0 | 0 | |
| Q13 | Q13 | 1 | ⇋ | 1 | |
| Q14 | ⇋ | Q14 | 0 | ⇋ | 1 |
| Q15 | Q15 | 1 | ⇋ | 1 | |
| Q16 | ⇋ | Q16 | 0 | 0 | |
| Q17 | ⇋ | Q17 | 0 | ⇋ | 1 |
| Q18 | Q18 | 1 | ⇋ | 1 | |
| Q19 | Q19 | 1 | 0 | ||
| Q20 | ⇋ | Q20 | 0 | 0 | |
| Summary | 7 | 11 |
| Attributes of A’ (BGP–IEP) | Value | Absolute Distance | Attributes of B’ (BGP–IEP) | Value |
| 14.58637 | 0.5587864 | 14.02758 | ||
| 14.36983 | 0.2008591 | 14.16897 | ||
| 3.304500 | 0.01418366 | 3.318683 | ||
| Subtotal | 0.7738291 | |||
| Attributes of A’ (BGP–IEP II) | Value | Directional Distance | Attributes of B’ (BGP–IEP II) | Value |
| 14.52774 | +0.4415311 | 14.08621 | ||
| 14.47663 | +0.4144685 | 14.06216 | ||
| 3.398857 | +0.1745316 | 3.224326 | ||
| Subtotal | 1.030531 |
References
- Embretson, S.E.; Reise, S.P. Item Response Theory for Psychologists; Lawrence Erlbaum Associates: New Jersey, NJ, USA, 2013. [Google Scholar]
- Firestone, W.A.; Donaldson, M.L. Teacher evaluation as data use: What recent research suggests. Educ. Assess. Eval. Account. 2019, 31, 289–314. [Google Scholar] [CrossRef]
- Johnes, J. Operational research in education. Eur. J. Oper. Res. 2015, 243, 683–696. [Google Scholar] [CrossRef]
- Saad, S.; Carter, G.W.; Rothenberg, M.; Israelson, E. Chapter 3: Understanding test quality—Concepts of reliability and validity. In Testing and Assessment: An Employer’s Guide to Good Practices by Employment and Training Administration; U.S. Department of Labour: Washington, DC, USA, 1999; pp. 1–11. [Google Scholar]
- Wang, S.P.; Hsieh, Y.K.; Zhuang, Z.Y.; Ou, N.C. Solving an outpatient nurse scheduling problem by binary goal programming. J. Ind. Prod. Eng. 2014, 31, 41–50. [Google Scholar] [CrossRef]
- Eignor, D.R. The standards for educational and psychological testing. In APA Handbooks in Psychology, APA Handbook of Testing and Assessment in Psychology; Geisinger, K.F., Bracken, B.A., Carlson, J.F., Hansen, J.-I.C., Kuncel, N.R., Reise, S.P., Rodriguez, M.C., Eds.; Test theory and testing and assessment in industrial and organizational psychology; American Psychological Association: Clark University, Worcester, MA, USA, 2013; Volume 1, p. 74. [Google Scholar] [CrossRef]
- Helms, J.E. Fairness is not validity or cultural bias in racial-group assessment: A quantitative perspective. Am. Psychol. 2006, 61, 845. [Google Scholar] [CrossRef] [PubMed]
- Camilli, G. Test fairness. Educ. Meas. 2006, 4, 221–256. [Google Scholar]
- Shohamy, E. Performance assessment in language testing. Annu. Rev. Appl. Linguist. 1995, 15, 188–211. [Google Scholar] [CrossRef]
- Shohamy, E. Critical language testing and beyond. Stud. Educ. Eval. 1998, 24, 331–345. [Google Scholar] [CrossRef]
- Tan, P.J.-B. Students’ adoptions and attitudes towards electronic placement tests: A UTAUT analysis. Am. J. Comput. Technol. Appl. 2013, 1, 14–23. [Google Scholar]
- Tan, P.J.-B.; Hsu, M. Designing a System for English Evaluation and Teaching Devices: A PZB and TAM Model Analysis. Eurasia J. Math. Sci. Technol. Educ. 2018, 14, 2107–2119. [Google Scholar] [CrossRef]
- Berry, R.A.W. Novice teachers’ conceptions of fairness in inclusion classrooms. Teach. Teach. Educ. 2008, 24, 1149–1159. [Google Scholar] [CrossRef]
- Ortner, T.M.; Weißkopf, E.; Gerstenberg, F.X. Skilled but unaware of it: CAT undermines a test taker’s metacognitive competence. Eur. J. Psychol. Educ. 2013, 28, 37–51. [Google Scholar] [CrossRef]
- Paufler, N.A.; Clark, C. Reframing conversations about teacher quality: School and district administrators’ perceptions of the validity, reliability, and justifiability of a new teacher evaluation system. Educ. Assess. Eval. Account. 2019, 31, 33–60. [Google Scholar] [CrossRef]
- Reimann, N.; Sadler, I. Personal understanding of assessment and the link to assessment practice: The perspectives of higher education staff. Assess. Eval. High. Educ. 2017, 42, 724–736. [Google Scholar] [CrossRef][Green Version]
- Skedsmo, G.; Huber, S.G. Measuring teaching quality: Some key issues. Educ. Assess. Eval. Account. 2019, 31, 151–153. [Google Scholar] [CrossRef]
- Wei, W.; Yanmei, X. University teachers’ reflections on the reasons behind their changing feedback practice. Assess. Eval. High. Educ. 2018, 43, 867–879. [Google Scholar] [CrossRef]
- Lord, F.M. The relation of test score to the trait underlying the test. Educ. Psychol. Meas. 1953, 13, 517–549. [Google Scholar] [CrossRef]
- Sijtsma, K.; Junker, B.W. Item response theory: Past performance, present developments, and future expectations. Behaviormetrika 2006, 33, 75–102. [Google Scholar] [CrossRef]
- Griffore, R.J. Speaking of fairness in testing. Am. Psychol. 2007, 62, 1081–1082. [Google Scholar] [CrossRef]
- Miller, J.D. The measurement of civic scientific literacy. Public Underst. Sci. 1998, 7, 203–223. [Google Scholar] [CrossRef]
- Bauer, M.W.; Allum, N.; Miller, S. What can we learn from 25 years of PUS survey research? Liberating and expanding the agenda. Public Underst. Sci. 2007, 16, 79–95. [Google Scholar] [CrossRef]
- Bauer, M.W. Survey research and the public understanding of science. In Handbook of Public Communication of Science & Technology; Bucchi, M., Trench, B., Eds.; Routledge: New York, NY, USA, 2008; pp. 111–130. [Google Scholar]
- Cajas, F. Public understanding of science: Using technology to enhance school science in everyday life. Int. J. Sci. Educ. 1999, 21, 765–773. [Google Scholar] [CrossRef]
- Mejlgaard, N.; Stares, S. Participation and competence as joint components in a cross-national analysis of scientific citizenship. Public Underst. Sci. 2010, 19, 545–561. [Google Scholar] [CrossRef]
- Kawamoto, S.; Nakayama, M.; Saijo, M. A survey of scientific literacy to provide a foundation for designing science communication in Japan. Public Underst. Sci. 2013, 22, 674–690. [Google Scholar] [CrossRef] [PubMed]
- Miller, J.D.; Pardo, R. Civic scientific literacy and attitude to science and technology: A comparative analysis of the European Union, the United States, Japan, and Canada. In Between Understanding and Trust: The Public, Science, and Technology; Dierkes, M., von Grote, C., Eds.; Harwood Academic Publishers: Amsterdam, The Netherlands, 2000; pp. 81–129. [Google Scholar]
- Wu, S.; Zhang, Y.; Zhuang, Z.-Y. A systematic initial study of civic scientific literacy in China: Cross-national comparable results from scientific cognition to sustainable literacy. Sustainability 2018, 10, 3129. [Google Scholar] [CrossRef]
- Lord, F.M. Practical applications of item characteristic curve theory. J. Educ. Meas. 1977, 14, 117–138. [Google Scholar] [CrossRef]
- Yen, W.M. Use of the three-parameter logistic model in the development of a standardized achievement test. In Applications of Item Response Theory; Hambleton, R.K., Ed.; Educational Research Institute of British Columbia: Vancouver, CO, Canada, 1983; pp. 123–141. [Google Scholar]
- Theunissen, T.J.J.M. Binary programming and test design. Psychometrika 1985, 50, 411–420. [Google Scholar] [CrossRef]
- Boekkooi-Timminga, E. Simultaneous test construction by zero-one programming. Methodika 1987, 1, 102–112. [Google Scholar]
- Boekkooi-Timminga, E.; van der Linden, W.J. Algorithms for automated test construction. In Computers in Psychology: Methods, Instrumentation and Psychodiagnostics; Maarse, F.J., Mulder, L.J.M., Sjouw, W.P.B., Akkerman, A.E., Eds.; Swets & Zeitlinger: Lisse, The Netherlands, 1987; pp. 165–170. [Google Scholar]
- Adema, J.J. Methods and models for the construction of weakly parallel tests. Appl. Psychol. Meas. 1992, 16, 53–63. [Google Scholar] [CrossRef]
- Swanson, L.; Stocking, M.L. A model and heuristic for solving very large item selection problems. Appl. Psychol. Meas. 1993, 17, 151–166. [Google Scholar] [CrossRef]
- Charnes, A.; Cooper, W.W. Multiple Criteria Optimization and Goal Programming. Oper. Res. 1975, 23, B384. [Google Scholar]
- Aouni, B.; Ben Abdelaziz, F.; Martel, J.M. Decision-maker’s preferences modeling in the stochastic goal programming. Eur. J. Oper. Res. 2005, 162, 610–618. [Google Scholar] [CrossRef]
- Chang, C.-T. Multi-choice goal programming. Omega Int. J. Manag. Sci. 2007, 35, 389–396. [Google Scholar] [CrossRef]
- Chang, C.-T.; Chen, H.-M.; Zhuang, Z.-Y. Revised multi-segment goal programming: Percentage goal programming. Comput. Ind. Eng. 2012, 63, 1235–1242. [Google Scholar] [CrossRef]
- Kettani, O.; Aouni, B.; Martel, J.M. The double role of the weight factor in the goal programming model. Comput. Oper. Res. 2004, 31, 1833–1845. [Google Scholar] [CrossRef]
- Romero, C. Extended lexicographic goal programming: A unifying approach. Omega Int. J. Manag. Sci. 2001, 29, 63–71. [Google Scholar] [CrossRef]
- Silva, A.F.D.; Marins, F.A.S.; Dias, E.X.; Miranda, R.D.C. Fuzzy Goal Programming applied to the process of capital budget in an economic environment under uncertainty. Gestão Produção 2018, 25, 148–159. [Google Scholar] [CrossRef]
- Aouni, B.; Kettani, O. Goal programming model: A glorious history and a promising future. Eur. J. Oper. Res. 2001, 133, 225–231. [Google Scholar] [CrossRef]
- Chang, C.-T.; Zhuang, Z.-Y. The Different Ways of Using Utility Function with Multi-Choice Goal Programming Transactions on Engineering Technologies; Springer: Dordrecht, The Netherlands, 2014; pp. 407–417. [Google Scholar]
- Tamiz, M.; Jones, D.; Romero, C. Goal programming for decision making: An overview of the current state-of-the-art. Eur. J. Oper. Res. 1998, 111, 569–581. [Google Scholar] [CrossRef]
- Caballero, R.; Ruiz, F.; Rodriguez-Uría, M.V.R.; Romero, C. Interactive meta-goal programming. Eur. J. Oper. Res. 2006, 175, 135–154. [Google Scholar] [CrossRef]
- Chang, C.-T.; Chung, C.-K.; Sheu, J.-B.; Zhuang, Z.-Y.; Chen, H.-M. The optimal dual-pricing policy of mall parking service. Transp. Res. Part A Policy Pract. 2014, 70, 223–243. [Google Scholar] [CrossRef]
- Colapinto, C.; Jayaraman, R.; Marsiglio, S. Multi-criteria decision analysis with goal programming in engineering, management and social sciences: A state-of-the art review. Ann. Oper. Res. 2017, 251, 7–40. [Google Scholar] [CrossRef]
- Hocine, A.; Zhuang, Z.-Y.; Kouaissah, N.; Li, D.-C. Weighted-additive fuzzy multi-choice goal programming (WA-FMCGP) for supporting renewable energy site selection decisions. Eur. J. Oper. Res. 2020, 285, 642–654. [Google Scholar] [CrossRef]
- Jones, D.; Tamiz, M. Goal programming in the period 1990–2000. In Multiple Criteria Optimization: State-of-the-Art Annotated Bibliographic Survey; Ehrgott, M., Gandibleux, X., Eds.; Kluwer Academic: Dordrecht, The Netherlands, 2002; pp. 130–172. [Google Scholar]
- Sawik, B.; Faulin, J.; Pérez-Bernabeu, E. Multi-criteria optimization for fleet size with environmental aspects. Transp. Res. Procedia 2017, 27, 61–68. [Google Scholar] [CrossRef]
- Zhuang, Z.-Y.; Su, C.-R.; Chang, S.-C. The effectiveness of IF-MADM (intuitionistic-fuzzy multi-attribute decision-making) for group decisions: Methods and an empirical assessment for the selection of a senior centre. Technol. Econ. Dev. Econ. 2019, 25, 322–364. [Google Scholar] [CrossRef]
- Chang, W.-T. Research Digest: The Three-Parameter Logistic Model of Item Response Theory. E-papers of the National Academy of Educational Research (Taiwan, ROC). 2011. Volume 7. Available online: https://epaper.naer.edu.tw/index.php?edm_no=7 (accessed on 19 May 2020).
- Romero, C. A general structure of achievement function for a goal programming model. Eur. J. Oper. Res. 2004, 153, 675–686. [Google Scholar] [CrossRef]
- Romero, C. Handbook of Critical Issues in Goal Programming; Pergamon Press: São Paulo, Brazil, 2014. [Google Scholar]
- Popper, K. The Logic of Scientific Discovery; Routledge: London, UK, 1992. [Google Scholar]
- Martel, J.M.; Aouni, B. Incorporating the decision-maker’s preferences in the goal-programming model. J. Oper. Res. Soc. 1990, 41, 1121–1132. [Google Scholar] [CrossRef]
- Lin, C.C. A weighted max—Min model for fuzzy goal programming. Fuzzy Sets Syst. 2004, 142, 407–420. [Google Scholar] [CrossRef]
- Yaghoobi, M.A.; Tamiz, M. A method for solving fuzzy goal programming problems based on MINMAX approach. Eur. J. Oper. Res. 2007, 177, 1580–1590. [Google Scholar] [CrossRef]
- Greenwood, J.A.; Sandomire, M.M. Sample size required for estimating the standard deviation as a per cent of its true value. J. Am. Stat. Assoc. 1950, 45, 257–260. [Google Scholar] [CrossRef]
- Zeleny, M. The pros and cons of goal programming. Comput. Oper. Res. 1981, 8, 357–359. [Google Scholar] [CrossRef]
- Klein, J. The failure of a decision support system: Inconsistency in test grading by teachers. Teach. Teach. Educ. 2002, 18, 1023–1033. [Google Scholar] [CrossRef]
- Ignizio, J.P. Goal Programming and Extensions; Lexington Books: Lexington, MA, USA, 1976. [Google Scholar]
- DeMars, C.E. Item information function. In SAGE Encyclopedia of Educational Research, Measurement, and Evaluation; Frey, B.B., Ed.; SAGE Publications Inc.: The Thousand Oaks, CA, USA, 2018; pp. 899–903. [Google Scholar] [CrossRef]
- Moghadamzadeh, A.; Salehi, K.; Khodaie, E. A comparison the information functions of the item and test on one, two and three parametric model of the item response theory (IRT). Procedia Soc. Behav. Sci. 2011, 29, 1359–1367. [Google Scholar] [CrossRef]
- Gulliksen, H. Theory of Mental Tests; Wiley: New York, NY, USA, 1950. [Google Scholar]
- Birnbaum, A. Some latent trait models and their use in inferring an examinee’s ability. In Statistical Theories of Mental Test Scores (chapters 17–20); Lord, F.M., Novick, M.R., Eds.; Addison-Wesley: Boston, MA, USA, 1968. [Google Scholar]
- Moustaki, I.; Knott, M. Generalized latent trait models. Psychometrika 2000, 65, 391–411. [Google Scholar] [CrossRef]







| Item | Q1 | Q2 | Q3 | Q4 | Q5 | Q6 | Q7 | Q8 | Q9 | Q10 |
| A | 87.2% | 87.9% | 45.6% | 100% | 94.6% | 62.4% | 82.6% | 98.0% | 96.6% | 22.8% |
| B | 98.0% | 93.9% | 98.6% | 54.7% | 80.4% | 76.4% | 52.7% | 95.9% | 37.2% | 97.3% |
| |A–B| | 10.80% | 6.00% | 53.00% | 45.30% | 14.20% | 14.00% | 29.90% | 2.10% | 59.40% | 74.50% |
| Item | Q11 | Q12 | Q13 | Q14 | Q15 | Q16 | Q17 | Q18 | Q19 | Q20 |
| A | 55.0% | 94.0% | 99.3% | 91.9% | 75.2% | 98.0% | 98.0% | 81.9% | 38.3% | 93.3% |
| B | 92.6% | 98.6% | 85.1% | 87.2% | 51.4% | 100% | 96.6% | 77.0% | 29.1% | 87.2% |
| |A–B| | 37.60% | 4.60% | 14.20% | 4.70% | 23.80% | 2.00% | 1.40% | 4.90% | 9.20% | 6.10% |
| A Exam Paper | B Exam Paper | |||||
|---|---|---|---|---|---|---|
| Qj | PjAguessing | PjADifficulty | PjADiscrimination | PjBguessing | PjBDifficulty | PjBDiscrimination |
| Q1 | 0.062693 | −5.28596 | 0.35833 | 0.371513 | −4.67323 | 0.788151 |
| Q2 | 0.733727 | −0.11029 | 4.477341 | 0.010156 | −5.40925 | 0.525375 |
| Q3 | 0.073052 | 0.524729 | 0.757966 | 0.036918 | −4.31039 | 1.127738 |
| Q4 | 0.999148 | −16.0528 | 0.182542 | 1.8 × 10−14 | −0.32322 | 0.616322 |
| Q5 | 0.082952 | 105.6133 | −0.0263 | 0.000153 | −2.33305 | 0.655196 |
| Q6 | 0.265127 | 0.05209 | 1.432473 | 1.1 × 10−17 | −0.68727 | 31.1551 |
| Q7 | 0.052179 | −2.63839 | 0.605141 | 0.491215 | −3.0337 | −0.97887 |
| Q8 | 0.057648 | −2.40507 | 3.092044 | 0.908461 | −0.14645 | 3.522721 |
| Q9 | 0.07932 | −5.7558 | 0.597789 | 0.000115 | 3.946901 | 0.134206 |
| Q10 | 0.151572 | 2.907607 | 0.900514 | 0.067808 | −42.2536 | 0.083154 |
| Q11 | 0.343063 | 1.018947 | 0.886161 | 0.006117 | 4.488719 | −0.59619 |
| Q12 | 0.009758 | −2.09139 | 1.962636 | 7.98 × 10−8 | 2.201958 | −31.5338 |
| Q13 | 0.06416 | −4.66897 | 1.220194 | 2.52 × 10−6 | 4.233981 | −0.4289 |
| Q14 | 0.018908 | −2.44744 | 1.211052 | 0.000189 | −3.02158 | 0.687387 |
| Q15 | 0.002061 | −0.72737 | 3.737409 | 1.46 × 10−11 | −0.12289 | 0.416349 |
| Q16 | 0.052894 | −4.75631 | 0.885629 | 1 | 18.33097 | −0.4557 |
| Q17 | 0.017352 | −2.26877 | 4.149376 | 0.018236 | 3.143843 | −1.31879 |
| Q18 | 0.022078 | −2.16509 | 0.759793 | 0.013546 | −9.85322 | 0.121235 |
| Q19 | 0.28291 | 1.288772 | 2.668051 | 0.261825 | −1.85502 | −6.41667 |
| Q20 | 0.061449 | −3.56639 | 0.791395 | 0.004878 | 13.74994 | −0.13957 |
| Total | 3.43205 | 56.46538 | 30.64953 | 3.191133 | −27.9266 | −2.03558 |
| Question Items in Exam Paper A | Planned Exchanges | Question Items in Exam Paper B | Remark (yi) |
|---|---|---|---|
| Q1 | ⇋ | Q1 | 1 |
| Q2 | ⇋ | Q2 | 1 |
| Q3 | ⇋ | Q3 | 1 |
| Q4 | Q4 | 0 | |
| Q5 | Q5 | 0 | |
| Q6 | Q6 | 0 | |
| Q7 | Q7 | 0 | |
| Q8 | ⇋ | Q8 | 1 |
| Q9 | Q9 | 0 | |
| Q10 | ⇋ | Q10 | 1 |
| Q11 | ⇋ | Q11 | 1 |
| Q12 | Q12 | 0 | |
| Q13 | ⇋ | Q13 | 1 |
| Q14 | ⇋ | Q14 | 1 |
| Q15 | ⇋ | Q15 | 1 |
| Q16 | Q16 | 0 | |
| Q17 | ⇋ | Q17 | 1 |
| Q18 | ⇋ | Q18 | 1 |
| Q19 | Q19 | 0 | |
| Q20 | Q20 | 0 | |
| Summary | 11 |
| Exam Paper A’ | Exam Paper B’ | |||||
|---|---|---|---|---|---|---|
| Qj | pj(guessing) | pj(difficulty) | pj(discrimination) | pj(guessing) | pj(difficulty) | pj(discrimination) |
| Q1 | 0.371513 | −4.67323 | 0.788151 | 0.062693 | −5.28596 | 0.35833 |
| Q2 | 0.010156 | −5.40925 | 0.525375 | 0.733727 | −0.11029 | 4.477341 |
| Q3 | 0.036918 | −4.31039 | 1.127738 | 0.073052 | 0.524729 | 0.757966 |
| Q4 | 0.999148 | −16.0528 | 0.182542 | 1.80 × 10−14 | −0.32322 | 0.616322 |
| Q5 | 0.082952 | 105.6133 | −0.0263 | 0.000153 | −2.33305 | 0.655196 |
| Q6 | 0.265127 | 0.05209 | 1.432473 | 1.10 × 10−17 | −0.68727 | 31.1551 |
| Q7 | 0.052179 | −2.63839 | 0.605141 | 0.491215 | −3.0337 | −0.97887 |
| Q8 | 0.908461 | −0.14645 | 3.522721 | 0.057648 | −2.40507 | 3.092044 |
| Q9 | 0.07932 | −5.7558 | 0.597789 | 0.000115 | 3.946901 | 0.134206 |
| Q10 | 0.067808 | −42.2536 | 0.083154 | 0.151572 | 2.907607 | 0.900514 |
| Q11 | 0.006117 | 4.488719 | −0.59619 | 0.343063 | 1.018947 | 0.886161 |
| Q12 | 0.009758 | −2.09139 | 1.962636 | 7.98 × 10−8 | 2.201958 | −31.5338 |
| Q13 | 2.52 × 10−6 | 4.233981 | −0.4289 | 0.06416 | −4.66897 | 1.220194 |
| Q14 | 0.000189 | −3.02158 | 0.687387 | 0.018908 | −2.44744 | 1.211052 |
| Q15 | 1.46 × 10−11 | −0.12289 | 0.416349 | 0.002061 | −0.72737 | 3.737409 |
| Q16 | 0.052894 | −4.75631 | 0.885629 | 1 | 18.33097 | −0.4557 |
| Q17 | 0.018236 | 3.143843 | −1.31879 | 0.017352 | −2.26877 | 4.149376 |
| Q18 | 0.013546 | −9.85322 | 0.121235 | 0.022078 | −2.16509 | 0.759793 |
| Q19 | 0.28291 | 1.288772 | 2.668051 | 0.261825 | −1.85502 | −6.41667 |
| Q20 | 0.061449 | −3.56639 | 0.791395 | 0.004878 | 13.74994 | −0.13957 |
| Total | 3.318683 | 14.16897 | 14.02758 | 3.3045 | 14.36983 | 14.58637 |
| Attributes of A’ | Value | Gap | Attributes of B’ | Value |
| 14.58637 | 0.5587864 | 14.02758 | ||
| 14.36983 | 0.2008591 | 14.16897 | ||
| 3.304500 | 0.01418366 | 3.318683 | ||
| Subtotal | 0.7738291 | |||
| Attributes of A | Value | Gap | Attributes of B | Value |
| 30.64953 | 32.68511 | −2.03558 | ||
| 56.46538 | 84.39198 | −27.9266 | ||
| 3.43205 | 0.240917 | 3.191133 | ||
| Subtotal | 117.318007 |
| Qj in Exam Paper A | Planned Exchanges | Qj in Exam Paper B | Remark (yj) | Exchanges (Unweighted) | yj (Unweighted) |
|---|---|---|---|---|---|
| Q1 | ⇋ | Q1 | 1 | ⇋ | 1 |
| Q2 | ⇋ | Q2 | 1 | ⇋ | 1 |
| Q3 | Q3 | 0 | ⇋ | 1 | |
| Q4 | ⇋ | Q4 | 1 | 0 | |
| Q5 | ⇋ | Q5 | 1 | 0 | |
| Q6 | ⇋ | Q6 | 1 | 0 | |
| Q7 | ⇋ | Q7 | 1 | 0 | |
| Q8 | ⇋ | Q8 | 1 | ⇋ | 1 |
| Q9 | Q9 | 0 | 0 | ||
| Q10 | Q10 | 0 | ⇋ | 1 | |
| Q11 | ⇋ | Q11 | 1 | ⇋ | 1 |
| Q12 | ⇋ | Q12 | 1 | 0 | |
| Q13 | Q13 | 0 | ⇋ | 1 | |
| Q14 | Q14 | 0 | ⇋ | 1 | |
| Q15 | Q15 | 0 | ⇋ | 1 | |
| Q16 | ⇋ | Q16 | 1 | 0 | |
| Q17 | ⇋ | Q17 | 1 | ⇋ | 1 |
| Q18 | Q18 | 0 | ⇋ | 1 | |
| Q19 | Q19 | 0 | 0 | ||
| Q20 | ⇋ | Q20 | 1 | 0 | |
| Summary | 12 | 11 |
| Attributes of A″ | Value | Gap | Attributes of B″ | Value |
| 14.52126 | 0.4285717 | 14.09269 | ||
| 14.27311 | 0.007420312 | 14.26569 | ||
| 3.118394 | 0.3863955 | 3.504789 | ||
| Objective Val. | 0.2558935 | |||
| Attributes of A’ | Value | Gap | Attributes of B’ | Value |
| 14.58637 | 0.5587864 | 14.02758 | ||
| 14.36983 | 0.2008591 | 14.16897 | ||
| 3.304500 | 0.01418366 | 3.318683 | ||
| Objective Val. | 0.257943 |
| Weight Portfolios Investigated | ||||||||
|---|---|---|---|---|---|---|---|---|
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | |
| 80% | 70% | 60% | 50% | 40% | 30% | 20% | 10% | |
| 10% | 10% | 10% | 10% | 10% | 10% | 10% | 10% | |
| A’ Discr. | 14.58637 | 14.58637 | 14.09269 | 14.31098 | 14.31098 | 14.30297 | 14.31098 | 14.31098 |
| A’ Diffi. | 14.36983 | 14.36983 | 14.26569 | 13.68014 | 13.68014 | 14.85866 | 13.68014 | 13.68014 |
| A’ Guess. | 3.30450 | 3.30450 | 3.50479 | 3.26494 | 3.26494 | 3.35825 | 3.26494 | 3.26494 |
| B’ Discr. | 14.02758 | 14.02758 | 14.52126 | 14.30297 | 14.30297 | 14.31098 | 14.30297 | 14.30297 |
| B’ Diffi. | 14.16897 | 14.16897 | 14.27311 | 14.85866 | 14.85866 | 13.68014 | 14.85866 | 14.85866 |
| B’ Guess. | 3.31868 | 3.31868 | 3.11839 | 3.35825 | 3.35825 | 3.26494 | 3.35825 | 3.35825 |
| D. Discr. | 0.55879 | 0.55879 | 0.42857 | 0.00801 | 0.00801 | 0.00801 | 0.00801 | 0.00801 |
| D. Diffi. | 0.20086 | 0.20086 | 0.00742 | 1.17852 | 1.17852 | 1.17852 | 1.17852 | 1.17852 |
| D. Guess. | 0.01418 | 0.01418 | 0.38640 | 0.09331 | 0.09331 | 0.09331 | 0.09331 | 0.09331 |
| Obj. (Agg.) | 0.05614 | 0.08073 | 0.10367 | 0.10914 | 0.08990 | 0.07066 | 0.05142 | 0.03218 |
| 10% | 20% | 30% | 40% | 50% | 60% | 70% | 80% | |
| 80% | 70% | 60% | 50% | 40% | 30% | 20% | 10% | |
| Exchanged Qs | Exchanging Details | |||||||
| Q1 | X | X | X | |||||
| Q2 | X | X | X | |||||
| Q3 | X | X | X | X | X | X | X | |
| Q4 | X | X | X | X | ||||
| Q5 | X | X | X | X | ||||
| Q6 | X | X | X | X | ||||
| Q7 | X | |||||||
| Q8 | X | X | X | X | X | X | ||
| Q9 | X | X | ||||||
| Q10 | X | X | X | X | ||||
| Q11 | X | X | X | X | X | X | ||
| Q12 | X | X | X | X | ||||
| Q13 | X | X | X | X | X | X | X | |
| Q14 | X | X | X | X | ||||
| Q15 | X | X | X | X | ||||
| Q16 | X | X | X | X | ||||
| Q17 | X | X | X | |||||
| Q18 | X | X | X | X | ||||
| Q19 | X | X | X | X | X | |||
| Q20 | X | X | X | X | ||||
| #Qs Exchanged | 11 | 11 | 8 | 11 | 11 | 9 | 11 | 11 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, Z.-Y.; Ho, C.-K.; Tan, P.J.B.; Ying, J.-M.; Chen, J.-H. The Optimal Setting of A/B Exam Papers without Item Pools: A Hybrid Approach of IRT and BGP. Mathematics 2020, 8, 1290. https://doi.org/10.3390/math8081290
Zhuang Z-Y, Ho C-K, Tan PJB, Ying J-M, Chen J-H. The Optimal Setting of A/B Exam Papers without Item Pools: A Hybrid Approach of IRT and BGP. Mathematics. 2020; 8(8):1290. https://doi.org/10.3390/math8081290
Chicago/Turabian StyleZhuang, Zheng-Yun, Chi-Kit Ho, Paul Juinn Bing Tan, Jia-Ming Ying, and Jin-Hua Chen. 2020. "The Optimal Setting of A/B Exam Papers without Item Pools: A Hybrid Approach of IRT and BGP" Mathematics 8, no. 8: 1290. https://doi.org/10.3390/math8081290
APA StyleZhuang, Z.-Y., Ho, C.-K., Tan, P. J. B., Ying, J.-M., & Chen, J.-H. (2020). The Optimal Setting of A/B Exam Papers without Item Pools: A Hybrid Approach of IRT and BGP. Mathematics, 8(8), 1290. https://doi.org/10.3390/math8081290