Financial Distress Prediction and Feature Selection in Multiple Periods by Lassoing Unconstrained Distributed Lag Non-linear Models


Abstract
1. Introduction
2. Background
2.1. Literature on Financial Distress Prediction
2.1.1. Financial Factors and Variable Selection
2.1.2. Macroeconomic Conditions
2.1.3. Related Literature on Chinese Listed Companies
2.2. Distributed Lag Models
3. Methodology
3.1. Logistic Regression Framework with Distributed Lags
3.1.1. The Logistic Regression-Distributed Lag Model with Accounting Ratios Only
3.1.2. The Logistic Regression-Distributed Lag Model with Accounting Plus Macroeconomic Variables
3.2. The Lasso–Logistic Regression-Distributed Lag Model
| Algorithm 1. An alternating direction method of multipliers (ADMM) algorithm framework for lasso–logistic with lagged variables (5). 1: Dual residual and prime residua denote ||βk+1 − βk||2 and ||αk+1 − βk+1||2 respectively. 2: N denotes the maximum iterative number of the ADMM algorithm. |
Require:
|
3.3. The Lasso–SVM Model with Lags for Comparison
| Algorithm 2. A finite Armijo–Newton algorithm for the sub-problem (19a). 1: δ is the parameter associated with finite Armijo Newton algorithm and between 0 and 1. |
Require:
|
| Algorithm 3. An ADMM algorithm framework for lasso–support vector machine (SVM) with lagged variables (16) |
Require:
|
4. Data
4.1. Sample Description
4.2. Covariate
4.2.1. Firm-Idiosyncratic Financial Indicator
4.2.2. Macroeconomic Indicator
4.3. Data Processing
5. Empirical Results and Discussion
5.1. Preparatory Work
5.2. Analyses of Results
5.2.1. The Results of the Accounting-Only Model and Analyses
5.2.2. The Results and Analyses of the Model of Accounting Plus Macroeconomic Variables
5.2.3. The Results of Lasso–SVM-Distributed Lag (LSVMDL) Models and Analyses
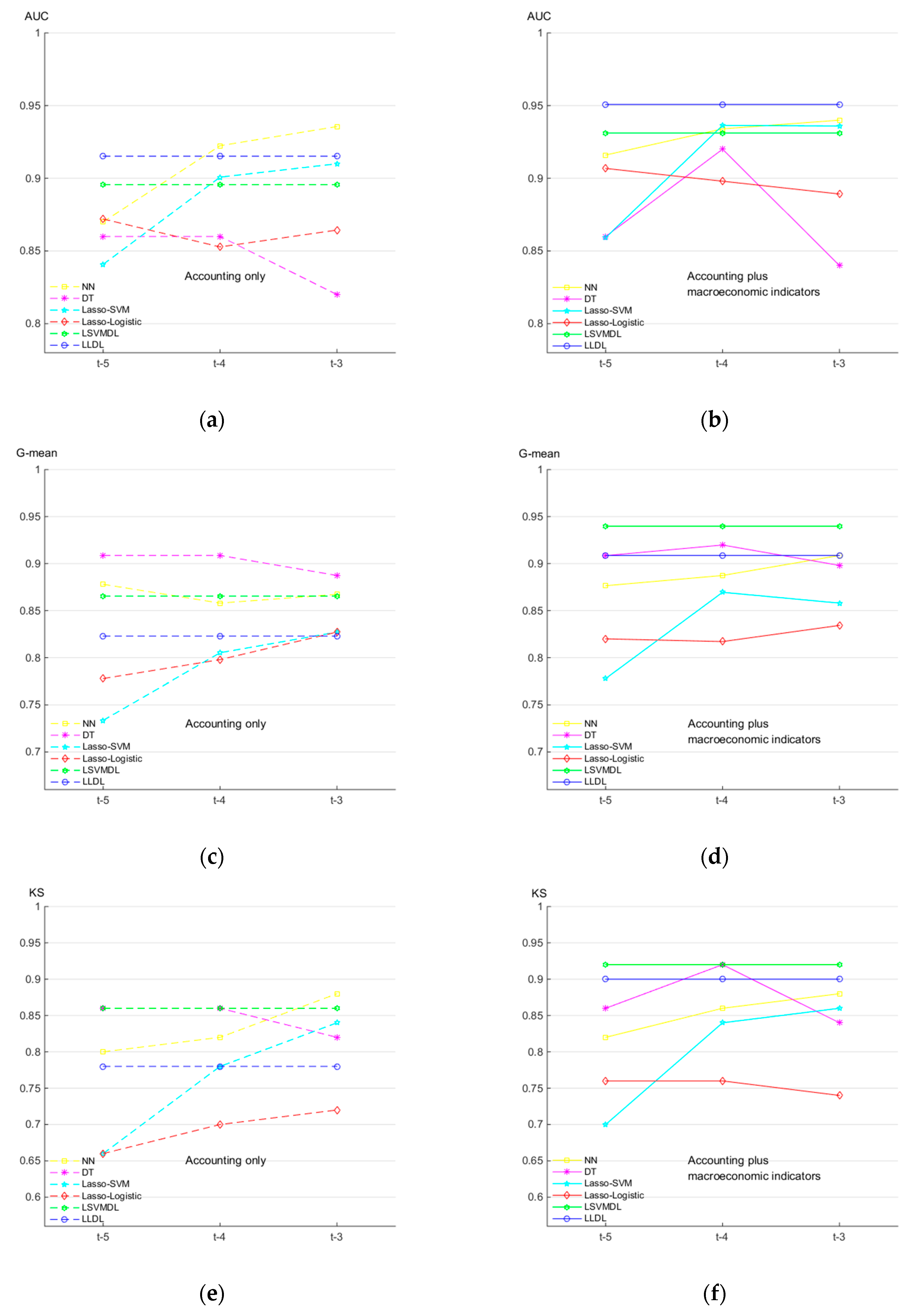
5.2.4. Comparison with Other Models
5.2.5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Altman, E.I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Lau, A.H.L. A five-state financial distress prediction model. J. Account. Res. 1987, 25, 127–138. [Google Scholar] [CrossRef]
- Jones, S.; Hensher, D.A. Predicting firm financial distress: A mixed logit model. Account. Rev. 2004, 79, 1011–1038. [Google Scholar] [CrossRef]
- Hernandez Tinoco, M.; Holmes, P.; Wilson, N. Polytomous response financial distress models: The role of accounting, market and macroeconomic variables. Int. Rev. Financ. Anal. 2018, 59, 276–289. [Google Scholar] [CrossRef]
- Zmijewski, M.E. Methodological issues related to the estimation of financial distress prediction models. J. Account. Res. 1984, 22, 59–82. [Google Scholar] [CrossRef]
- Ross, S.; Westerfield, R.; Jaffe, J. Corporate Finance; McGraw-Hill Irwin: New York, NY, USA, 2000. [Google Scholar]
- Geng, R.; Bose, I.; Chen, X. Prediction of financial distress: An empirical study of listed Chinese companies using data mining. Eur. J. Oper. Res. 2015, 241, 236–247. [Google Scholar] [CrossRef]
- Westgaard, S.; Van Der Wijst, N. Default probabilities in a corporate bank portfolio: A logistic model approach. Eur. J. Oper. Res. 2001, 135, 338–349. [Google Scholar] [CrossRef]
- Balcaen, S.; Ooghe, H. 35 years of studies on business failure: An overview of the classic statistical methodologies and their related problems. Br. Account. Rev. 2006, 38, 63–93. [Google Scholar] [CrossRef]
- Martin, D. Early warnings of bank failure: A logit regression approach. J. Bank. Financ. 1977, 1, 249–276. [Google Scholar] [CrossRef]
- Liang, D.; Tsai, C.F.; Wu, H.T. The effect of feature selection on financial distress prediction. Knowl. Based Syst. 2015, 73, 289–297. [Google Scholar] [CrossRef]
- Frydman, H.; Altman, E.I.; Kao, D.L. Introducing recursive partitioning for financial classification: The case of financial distress. J. Financ. 1985, 40, 269–291. [Google Scholar] [CrossRef]
- Leshno, M.; Spector, Y. Neural network prediction analysis: The bankruptcy case. Neurocomputing 1996, 10, 125–147. [Google Scholar] [CrossRef]
- Shin, K.S.; Lee, T.S.; Kim, H.J. An application of support vector machines in bankruptcy prediction model. Expert Syst. Appl. 2005, 28, 127–135. [Google Scholar] [CrossRef]
- Sun, J.; Li, H. Data mining method for listed companies’ financial distress prediction. Knowl. Based Syst. 2008, 21, 1–5. [Google Scholar] [CrossRef]
- Jiang, Y.; Jones, S. Corporate distress prediction in China: A machine learning approach. Account. Financ. 2018, 58, 1063–1109. [Google Scholar] [CrossRef]
- Purnanandam, A. Financial distress and corporate risk management: Theory and evidence. J. Financ. Econ. 2008, 87, 706–739. [Google Scholar] [CrossRef]
- Almamy, J.; Aston, J.; Ngwa, L.N. An evaluation of Altman’s Z-score using cash flow ratio to predict corporate failure amid the recent financial crisis: Evidence from the UK. J. Corp. Financ. 2016, 36, 278–285. [Google Scholar] [CrossRef]
- Liang, D.; Lu, C.C.; Tsai, C.F.; Shih, G.A. Financial ratios and corporate governance indicators in bankruptcy prediction: A comprehensive study. Eur. J. Oper. Res. 2016, 252, 561–572. [Google Scholar] [CrossRef]
- Scalzer, R.S.; Rodrigues, A.; Macedo, M.Á.S.; Wanke, P. Financial distress in electricity distributors from the perspective of Brazilian regulation. Energy Policy 2019, 125, 250–259. [Google Scholar] [CrossRef]
- Altman, I.E.; Haldeman, G.R.; Narayanan, P. ZETATM analysis A new model to identify bankruptcy risk of corporations. J. Bank. Financ. 1977, 1, 29–54. [Google Scholar] [CrossRef]
- Inekwe, J.N.; Jin, Y.; Valenzuela, M.R. The effects of financial distress: Evidence from US GDP growth. Econ. Model. 2018, 72, 8–21. [Google Scholar] [CrossRef]
- Ohlson, J. Financial ratios and the probabilistic prediction of bankruptcy. J. Account. Res. 1980, 18, 109–131. [Google Scholar] [CrossRef]
- Hillegeist, S.; Keating, E.; Cram, D.; Lundstedt, K. Assessing the probability of bankruptcy. Rev. Account. Stud. 2004, 9, 5–34. [Google Scholar] [CrossRef]
- Teresa, A.J. Accounting measures of corporate liquidity, leverage, and costs of financial distress. Financ. Manag. 1993, 22, 91–100. [Google Scholar]
- Shumway, T. Forecasting bankruptcy more accurately: A simple hazard model. J. Bus. 2001, 74, 101–124. [Google Scholar] [CrossRef]
- Hosaka, T. Bankruptcy prediction using imaged financial ratios and convolutional neural networks. Expert Syst. Appl. 2019, 117, 287–299. [Google Scholar] [CrossRef]
- Korol, T. Dynamic Bankruptcy Prediction Models for European Enterprises. J. Risk Financ. Manag. 2019, 12, 185. [Google Scholar] [CrossRef]
- Gregova, E.; Valaskova, K.; Adamko, P.; Tumpach, M.; Jaros, J. Predicting Financial Distress of Slovak Enterprises: Comparison of Selected Traditional and Learning Algorithms Methods. Sustainability 2020, 12, 3954. [Google Scholar] [CrossRef]
- Kovacova, M.; Kliestik, T.; Valaskova, K.; Durana, P.; Juhaszova, Z. Systematic review of variables applied in bankruptcy prediction models of Visegrad group countries. Oeconomia Copernic. 2019, 10, 743–772. [Google Scholar] [CrossRef]
- Kliestik, T.; Misankova, M.; Valaskova, K.; Svabova, L. Bankruptcy Prevention: New Effort to Reflect on Legal and Social Changes. Sci. Eng. Ethics 2018, 24, 791–803. [Google Scholar] [CrossRef]
- López, J.; Maldonado, S. Profit-based credit scoring based on robust optimization and feature selection. Inf. Sci. 2019, 500, 190–202. [Google Scholar] [CrossRef]
- Maldonado, S.; Pérez, J.; Bravo, C. Cost-based feature selection for Support Vector Machines: An application in credit scoring. Eur. J. Oper. Res. 2017, 261, 656–665. [Google Scholar] [CrossRef]
- Li, J.; Qin, Y.; Yi, D. Feature selection for Support Vector Machine in the study of financial early warning system. Qual. Reliab. Eng. Int. 2014, 30, 867–877. [Google Scholar] [CrossRef]
- Duffie, D.; Saita, L.; Wang, K. Multi-Period Corporate Default Prediction with Stochastic Covariates. J. Financ. Econ. 2004, 83, 635–665. [Google Scholar] [CrossRef]
- Greene, W.H.; Hensher, D.A.; Jones, S. An Error Component Logit Analysis of Corporate Bankruptcy and Insolvency Risk in Australia. Econ. Rec. 2007, 83, 86–103. [Google Scholar]
- Figlewski, S.; Frydman, H.; Liang, W.J. Modeling the effect of macroeconomic factors on corporate default and credit rating transitions. Int. Rev. Econ. Financ. 2012, 21, 87–105. [Google Scholar] [CrossRef]
- Tang, D.Y.; Yan, H. Market conditions, default risk and credit spreads. J. Bank. Financ. 2010, 34, 743–753. [Google Scholar] [CrossRef]
- Chen, C.; Kieschnick, R. Bank credit and corporate working capital management. J. Corp. Financ. 2016, 48, 579–596. [Google Scholar] [CrossRef]
- Jermann, U.; Quadrini, V. Macroeconomic effects of financial shocks. Am. Econ. Rev. 2012, 102, 238–271. [Google Scholar] [CrossRef]
- Carpenter, J.N.; Whitelaw, R.F. The development of China’s stock market and stakes for the global economy. Annu. Rev. Financ. Econ. 2017, 9, 233–257. [Google Scholar] [CrossRef]
- Hua, Z.; Wang, Y.; Xu, X.; Xu, X.; Zhang, B.; Liang, L. Predicting corporate financial distress based on integration of support vector machine and logistic regression. Expert Syst. Appl. 2007, 33, 434–440. [Google Scholar] [CrossRef]
- Li, H.; Sun, J. Hybridizing principles of the Electre method with case-based reasoning for data mining: Electre-CBR-I and Electre-CBR-II. Eur. J. Oper. Res. 2009, 197, 214–224. [Google Scholar] [CrossRef]
- Cao, Y. MCELCCh-FDP: Financial distress prediction with classifier ensembles based on firm life cycle and Choquet integral. Expert. Syst. Appl. 2012, 39, 7041–7049. [Google Scholar] [CrossRef]
- Shen, F.; Liu, Y.; Wang, R. A dynamic financial distress forecast model with multiple forecast results under unbalanced data environment. Knowl. Based Syst. 2020, 192, 1–16. [Google Scholar] [CrossRef]
- Gasparrini, A.; Armstrong, B.; Kenward, M.G. Distributed lag non-linear models. Stat. Med. 2010, 29, 2224–2234. [Google Scholar] [CrossRef]
- Gasparrini, A.; Scheipl, B.; Armstrong, B.; Kenward, G.M. Penalized Framework for Distributed Lag Non-Linear Models. Biometrics 2017, 73, 938–948. [Google Scholar] [CrossRef] [PubMed]
- Wilson, A.; Hsu, H.H.L.; Chiu, Y.H.M. Kernel machine and distributed lag models for assessing windows of susceptibility to mixtures of time-varying environmental exposures in children’s health studies. arXiv 2019, arXiv:1904.12417. [Google Scholar]
- Nelson, C.R.; Schwert, G.W. Estimating the Parameters of a Distributed Lag Model from Cross-Section Data: The Case of Hospital Admissions and Discharges. J. Am. Stat. Assoc. 1974, 69, 627–633. [Google Scholar] [CrossRef]
- Hammoudeh, S.; Sari, R. Financial CDS, stock market and interest rates: Which drives which? N. Am. J. Econ. Financ. 2011, 22, 257–276. [Google Scholar] [CrossRef]
- Lahiani, A.; Hammoudeh, S.; Gupta, R. Linkages between financial sector CDS spreads and macroeconomic influence in a nonlinear setting. Int. Rev. Econ. Financ. 2016, 43, 443–456. [Google Scholar] [CrossRef]
- Almon, S. The distributed lag between capital appropriations and expenditures. Econometrica 1965, 33, 178–196. [Google Scholar] [CrossRef]
- Dominici, F.; Daniels, M.S.L.; Samet, Z.J. Air pollution sand mortality: Estimating regional and national dose—Response relationships. J. Am. Stat. Assoc. 2002, 97, 100–111. [Google Scholar] [CrossRef]
- Wooldridge, J.M. Econometric Analysis of Cross Section and Panel Data; MIT Press: Cambridge, MA, USA, 2010. [Google Scholar]
- Park, H.; Sakaori, F. Lag weighted lasso for time series model. Comput. Stat. 2013, 28, 493–504. [Google Scholar] [CrossRef]
- Glowinski, R.; Marroco, A. Sur l’approximation, par éléments finis d’ordre un, et la résolution, par pénalisation-dualité d’une classe de problèmes de Dirichlet non linéaires. ESAIM Math. Model. Numer. 1975, 9, 41–76. [Google Scholar] [CrossRef]
- Dantzig, G.; Wolfe, J. Decomposition principle for linear programs. Oper. Res. 1960, 8, 101–111. [Google Scholar] [CrossRef]
- Hestenes, M.R. Multiplier and gradient methods. J. Optim. Theory. Appl. 1969, 4, 302–320. [Google Scholar] [CrossRef]
- Chambolle, A.; Pock, T. A first-order primal-dual algorithm for convex problems with applications to imaging. J. Math. Imaging Vis. 2011, 40, 120–145. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Found. Trends. Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Mangasarian, O.L. A finite Newton method for classification. Optim. Methods Softw. 2002, 17, 913–929. [Google Scholar] [CrossRef]
- Shon, T.; Moon, J. A hybrid machine learning approach to network anomaly detection. Inf. Sci. 2007, 177, 3799–3821. [Google Scholar] [CrossRef]
- Liu, D.; Qian, H.; Dai, G.; Zhang, Z. An iterative SVM approach to feature selection and classification in high-dimensional datasets. Pattern Recognit. 2013, 46, 2531–2537. [Google Scholar] [CrossRef]
- Tiwari, R. Intrinsic value estimates and its accuracy: Evidence from Indian manufacturing industry. Future Bus. J. 2016, 2, 138–151. [Google Scholar] [CrossRef]
- Shanker, M.; Hu, M.Y.; Hung, M.S. Effect of data standardization on neural network training. Omega Int. J. Manag. Sci. 1996, 24, 385–397. [Google Scholar] [CrossRef]
- Kacer, M.; Ochotnicky, P.; Alexy, M. The Altman’s revised Z’-Score model, non-financial information and macroeconomic variables: Case of Slovak SMEs. Ekon. Cas. 2019, 67, 335–366. [Google Scholar]



{kind=link}
{kind=link}
| Solvency | Operational Capabilities |
| 1 Total liabilities/total assets (TL/TA) | 9 Sales revenue/average net account receivable (SR/ANAR) |
| 2 Current assets/current liabilities (CA/CL) | 10 Sales revenue/average current assets (SR/ACA) |
| 3 (Current assets–inventory)/current liabilities (CA-I)/CL | 11 Sales revenue/average total assets (AR/ATA) |
| 4 Net cash flow from operating activities/current liabilities (CF/CL) | 12 Sales cost/average payable accounts (SC/APA) |
| 5 Current liabilities/total assets (CL/TA) | 13 Sales cost/sales revenue (SC/SR) |
| 6 Current liabilities/shareholders’ equity (CL/SE) | 14 Impairment losses/sales profit (IL/SP) |
| 7 Net cash flow from operating and investing activities/total liabilities (NCL/TL) | 15 Sales cost/average net inventory (SC/ANI) |
| 8 Total liabilities/total shareholders’ equity (TSE/TL) | 16 Sales revenue/average fixed assets (SR/AFA) |
| Profitability | Structural Soundness |
| 17 Net profit/average total assets (NP/ATA) | 27 Net asset/total asset (NA/TA) |
| 18 Shareholder equity/net profit (SE/NP) | 28 Fixed assets/total assets (FA/TA) |
| 19 (Sales revenue–sales cost)/sales revenue (SR-SC)/SR | 29 Shareholders’ equity/fixed assets (SE/FA) |
| 20 Earnings before interest and tax/average total assets (EIA/ATA) | 30 Current liabilities/total liabilities (CL/TL) |
| 21 Net profit/sales revenue (NP/SR) | 31 Current assets/total assets (CA/TA) |
| 22 Net profit/average fixed assets (NP/AFA) | 32 Long-term liabilities/total liabilities (LL/TL) |
| 23 Net profit attributable to shareholders of parent company/sales revenue (NPTPC/SR) | 33 Main business profit/net income from main business (MBP/NIMB) |
| 24 Net cash flow from operating activities/sales revenue (NCFO/SR) | 34 Total profit/sales revenue (TP/SR) |
| 25 Net profit/total profit (NP/TP) | 35 Net profit attributable to shareholders of the parent company/net profit (NPTPC/NP) |
| 26 Net cash flow from operating activities/total assets at the end of the period (NCFO/TAEP) | 36 Operating capital/total assets (OC/TA) |
| 37 Retained earnings/total assets (RE/TA) | |
| Business Development and Capital Expansion Capacity | |
| 38 Main sales revenue of this year/main sales revenue of last year (MSR(t)/MSR(t-1)) | 41 Net assets/number of ordinary shares at the end of year (NA/NOS) |
| 39 Total assets of this year/total assets of last year (TA(t)/TA(t-1)) | 42 Net cash flow from operating activities/number of ordinary shares at the end of year (NCFO/NOS) |
| 40 Net profit of this year/net profit of last year (NP(t)/NP(t-1)) | 43 Net increase in cash and cash equivalents at the end of year/number of ordinary shares at the end of year (NICCE/NOS) |
| Figure 1 | Description |
|---|---|
| 1 Real GDP growth (%) | Growth in the Chinese real gross domestic product (GDP) compared to the corresponding period of previous year (GDP growth is documented yearly and by province). |
| 2 Inflation rate (%) | Percentage changes in urban consumer price compared to the corresponding period of the previous year (inflation rate is documented regionally). |
| 3 Unemployment rate (%) | The data derived from the Labor Force Survey (population between 16 years old and retirement age, unemployment rate is documented yearly and regionally). |
| 4 Consumption level growth (%) | Growth in the Chinese consumption level index compared to the corresponding period of the previous year (consumption level growth is documented yearly and regionally). |
| Selected Indicator | Model 1 (Financial Ratios Only) | Model 2 (Financial Plus Macroeconomic Factor) | ||||
|---|---|---|---|---|---|---|
| t − 3 | t − 4 | t − 5 1 | t − 3 | t − 4 | t − 5 | |
| 1 Total liabilities/total assets | × 2 | × | 3.1671 (0.07) ***,3 | × | × | 3.5519 (0.07) *** |
| 2 Current liabilities/total assets | × | −3.356 (0.27) *** | × | × | −1.2292 (0.26) *** | × |
| 3 Sales revenue/average current assets | × | −0.5988 (0.19). | × | × | −3.887 (0.19) *** | × |
| 4 Sales revenue/average total assets | −0.4367 (0.14) *** | −5.7393 (0.24) *** | −1.8312 (0.14) ** | −0.5428 (0.14) ** | −0.3907 (0.23) ** | −3.5193 (0.14) *** |
| 5 Sales cost/sales revenue | 5.1892 (0.08) ** | × | × | 3.9211 (17.57) | × | × |
| 6 Impairment losses/sales profit | −0.4496 (0.08) *** | × | × | −0.5777 (0.08) *** | × | × |
| 7 Sales cost/average net inventory | −1.3265 (0.12) *** | × | × | −1.1143 (0.12) * | × | × |
| 8 Net profit/average total assets | × | −1.1919 (0.14) | × | × | −3.3509 (0.14) ** | × |
| 9 Shareholders’ equity/net profit | 5.4466 (0.17) *** | × | × | 4.0804 (0.18) *** | × | × |
| 10 (Sales revenue-sales cost)/sales revenue (net income/revenue) | × | × | × | −1.2209 (17.7) | × | × |
| 11 Net profit/average fixed assets | 1.3912 (0.31) ** | × | × | × | × | × |
| 12 Net profit/total profit | × | 0.2856 (0.14) *** | 0.0422 (0.09) * | × | 0.0371 (0.14) *** | × |
| 13 Net cash flow from operating activities/total assets | −4.8561 (0.11) *** | −2.6798 (0.11)** | −1.0999 (0.12) | −3.005 (0.1) * | −2.7581 (0.1) ** | −0.0304 (0.12) |
| 14 Fixed assets/total assets | 1.6395 (0.1) | 0.9142 (0.11) ** | × | 1.5972 (0.09) | × | 0.5416 (0.09) |
| 15 Shareholders’ equity/fixed assets | × | 1.0914 (0.09) *** | × | × | 0.0472 (0.09) ** | × |
| 16 Current liabilities/total liabilities | 2.2516 (0.06) * | × | 2.2987 (0.07) *** | 3.1472 (0.06) *** | × | 2.1535 (0.07) *** |
| 17 Current assets/total assets | −1.5197 (0.11) | × | × | −3.081 (0.11) * | × | × |
| 18 Long−term liabilities/total liabilities | × | 1.6 (0.07) * | × | × | 1.8855 (0.06) ** | × |
| 19 Main business profit/net income from main business | −3.3814 (0.1) *** | −1.0212 (0.1) *** | 5.2777 (0.1) *** | −4.0263 (0.1) *** | −0.9392 (0.1) *** | 5.876 (0.1) *** |
| 20 Net profit attributable to shareholders of the parent company/net profit | −3.5409 (0.13) *** | × | × | −2.159 (0.13) *** | × | × |
| 21 Operating capital/total assets | −2.1682 (0.16) *** | × | × | −0.328 (0.16) * | × | × |
| 22 Main sales revenue of this year/main sales revenue of last year | × | × | 2.9534 (0.1) ** | × | × | 2.5545 (0.11) ** |
| 23 Net assets/number of ordinary shares at the end of year | × | −6.255 (0.07) *** | × | × | −5.8881 (0.07) *** | × |
| 24 Real Consumer Price Index (CPI) growth (%) | × | × | × | × | −0.2536 (0.06) | 0.7531 (0.05) |
| 25 Real GDP growth (%) | × | × | × | −2.4867 (0.09) *** | −1.6404 (0.11) | −0.9319 (0.1) |
| 26 Consumption level growth (%) | × | × | × | −0.9931 (0.08) ** | −1.8625 (0.06) | × |
| 27 Unemployment rate (%) | × | × | × | 2.7262 (0.07) *** | × | × |
| Selected Indicator | Model 1 | Model 2 | ||||
|---|---|---|---|---|---|---|
| t − 3 | t − 4 | t − 5 | t − 3 | t − 4 | t − 5 | |
| 1 Total liabilities/total assets | 32.1469 | 7.7613 | × | 10.7109 | 7.8039 | × |
| 2 Current assets/current liabilities | × | 13.7838 | −23.2184 | × | 27.1895 | −14.1113 |
| 3 Current liabilities/total assets | × | −28.6108 | −25.7518 | × | −11.9697 | × |
| 4 Net cash flow from operating and investing activities/total liabilities | −11.7710 | −9.2197 | −4.7334 | −10.8928 | −4.2075 | −4.0695 |
| 5 Sales revenue/average current assets | −13.2180 | −5.5190 | −2.3310 | × | −3.5302 | −2.3478 |
| 6 Impairment losses/sales profit | −3.8743 | −0.8378 | −0.1417 | −5.0528 | × | −2.1980 |
| 7 Sales cost/average net inventory | −4.2927 | × | × | −8.5432 | × | × |
| 8 Sales revenue/average fixed assets | 7.5395 | 4.0548 | 4.3177 | × | × | × |
| 9 (Sales revenue–sales cost)/sales revenue | × | −4.1270 | 5.6701 | −1.3797 | −4.4148 | × |
| 10 Net profit attributable to shareholders of the parent company/sales revenue | 3.8270 | × | × | 6.1038 | × | × |
| 11 Net cash flow from operating activities/sales revenue | × | −15.5682 | × | × | −6.9168 | × |
| 12 Net profit/total profit | −1.6296 | 5.6995 | 1.6336 | −2.4791 | 2.4036 | −0.4364 |
| 13 Net cash flow from operating activities/total assets at the end of the period | −12.3631 | −19.5928 | −4.4420 | −2.1426 | × | −0.1701 |
| 14 Fixed assets/total assets | 0.2474 | 3.0676 | 8.7795 | 5.4054 | × | 1.7320 |
| 15 Current liabilities/total liabilities | × | × | 9.6303 | 5.1482 | 4.3620 | 10.0672 |
| 16 Current assets/total assets | −12.3003 | −6.7341 | −0.4332 | −9.4098 | × | −0.5753 |
| 17 Long-term liabilities/total liabilities | −5.7781 | 0.8473 | 2.0308 | × | 6.4801 | 4.2084 |
| 18 Main business profit/net income from main business | −7.3785 | −7.8631 | −9.5525 | −2.7997 | −4.3300 | −4.3107 |
| 19 Net profit attributable to shareholders of the parent company/net profit | −10.7914 | −6.3596 | 9.1739 | −5.9123 | 1.7203 | 1.9460 |
| 20 Operating capital/total assets | × | 19.8833 | × | × | × | 8.6408 |
| 21 Retained earnings/total assets | × | × | 30.8895 | × | × | 0.9384 |
| 22 Main sales revenue of this year/main sales revenue of last year | × | × | 25.2376 | 0.7510 | 0.0517 | 13.5974 |
| 23 Net profit of this year/net profit of last year | −16.5430 | 17.9966 | −7.8113 | × | 5.9123 | −6.9035 |
| 24 Net increase in cash and cash equivalents at the end of year/number of ordinary shares | 14.4968 | 0.2728 | 11.3146 | 7.6436 | × | 0.2771 |
| 25 Real CPI growth (%) | × | × | × | −2.4001 | −0.7880 | 2.6728 |
| 26 Real GDP growth (%) | × | × | × | −1.0391 | −4.5598 | × |
| 27 Consumption level growth (%) | × | × | × | −1.0196 | −1.1848 | −2.8019 |
| 28 Unemployment rate (%) | × | × | × | 16.3215 | × | 14.3059 |
| NN | DT | Lasso–SVM | Lasso–Logistic | LSVMDL | LLDL | |
|---|---|---|---|---|---|---|
| Panel A: prediction performance of the existing models in time period t − 3 | ||||||
| AUC | 0.9356 | 0.8200 | 0.9100 | 0.8644 | 0.8956 | 0.9152 |
| G-mean | 0.8673 | 0.8874 | 0.8272 | 0.8272 | 0.8655 | 0.8230 |
| KS | 0.8800 | 0.8200 | 0.8400 | 0.7200 | 0.8600 | 0.7800 |
| Panel B: prediction performance of the existing models in time period t − 4 | ||||||
| AUC | 0.9224 | 0.8600 | 0.9008 | 0.8528 | 0.8956 | 0.9152 |
| G-mean | 0.8580 | 0.9087 | 0.8052 | 0.7979 | 0.8655 | 0.8230 |
| KS | 0.8200 | 0.8600 | 0.7800 | 0.7000 | 0.8600 | 0.7800 |
| Panel C: prediction performance of the existing models in time period t − 5 | ||||||
| AUC | 0.8700 | 0.8600 | 0.8408 | 0.8720 | 0.8956 | 0.9152 |
| G-mean | 0.8780 | 0.9087 | 0.7336 | 0.7778 | 0.8655 | 0.8230 |
| KS | 0.8000 | 0.8600 | 0.6600 | 0.6600 | 0.8600 | 0.7800 |
| NN | DT | Lasso–SVM | Lasso–Logistic | LSVMDL | LLDL | |
|---|---|---|---|---|---|---|
| Panel A: prediction performance of the existing models in time period t − 3 | ||||||
| AUC | 0.9400 | 0.8400 | 0.9360 | 0.8892 | 0.9312 | 0.9508 |
| G-mean | 0.9087 | 0.8981 | 0.8580 | 0.8343 | 0.9398 | 0.9087 |
| KS | 0.8900 | 0.8400 | 0.8600 | 0.7400 | 0.9200 | 0.9000 |
| Panel B: prediction performance of the existing models in time period t − 4 | ||||||
| AUC | 0.9340 | 0.9200 | 0.9364 | 0.8980 | 0.9312 | 0.9508 |
| G-mean | 0.8874 | 0.9198 | 0.8695 | 0.8171 | 0.9398 | 0.9087 |
| KS | 0.8600 | 0.9200 | 0.8400 | 0.7600 | 0.9200 | 0.9000 |
| Panel C: prediction performance of the existing models in time period t − 5 | ||||||
| AUC | 0.9160 | 0.8600 | 0.8592 | 0.9068 | 0.9312 | 0.9508 |
| G-mean | 0.8765 | 0.9085 | 0.7778 | 0.8200 | 0.9398 | 0.9087 |
| KS | 0.8200 | 0.8600 | 0.7000 | 0.7600 | 0.9200 | 0.9000 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, D.; Chi, G.; Lai, K.K. Financial Distress Prediction and Feature Selection in Multiple Periods by Lassoing Unconstrained Distributed Lag Non-linear Models. Mathematics 2020, 8, 1275. https://doi.org/10.3390/math8081275
Yan D, Chi G, Lai KK. Financial Distress Prediction and Feature Selection in Multiple Periods by Lassoing Unconstrained Distributed Lag Non-linear Models. Mathematics. 2020; 8(8):1275. https://doi.org/10.3390/math8081275
Chicago/Turabian StyleYan, Dawen, Guotai Chi, and Kin Keung Lai. 2020. "Financial Distress Prediction and Feature Selection in Multiple Periods by Lassoing Unconstrained Distributed Lag Non-linear Models" Mathematics 8, no. 8: 1275. https://doi.org/10.3390/math8081275
APA StyleYan, D., Chi, G., & Lai, K. K. (2020). Financial Distress Prediction and Feature Selection in Multiple Periods by Lassoing Unconstrained Distributed Lag Non-linear Models. Mathematics, 8(8), 1275. https://doi.org/10.3390/math8081275