1. Introduction
Mortality projections are used by insurance companies, pension providers and public policy makers for forecasting expected payments of benefits contingent on human lives (such as insurance benefits and pensions) as well as their distribution. Specifically, insurance companies use such projections for pricing of products, solvency calculations and risk assessments. With the upcoming new international insurance accounting standard, the allowance for risk will be required in the financial reporting as well.
Lee-Carter stochastic mortality model is one of the most popular models applied in practice for forecasting expected human mortality and its distribution. Lee and Carter [
1] models mortality rates according to the following formula:
where
is central mortality rate (ratio of the number of deaths to the exposed to risk) for age
x in year
t,
,
,
are parameters depending on age
x or on year
t, and
are independent and identically distributed (i.i.d.) random residuals with zero means.
In its original form and according to the later modifications, see Brouhns et al. [
2] or Lee and Miller [
3] for instance, Lee-Carter model supposes two stage estimation procedure. First, parameters
,
and
are estimated using the matrix singular value decomposition (SVD) method or by fitting a Poisson bi-linear regression. Secondly, parameter
, which might be interpreted as time varying index representing the general trend of human mortality improvements, is modelled separately as time series, most often as a simple random walk with drift (RWD):
where
is the drift (or trend) parameter and
are i.i.d. residuals with zero means.
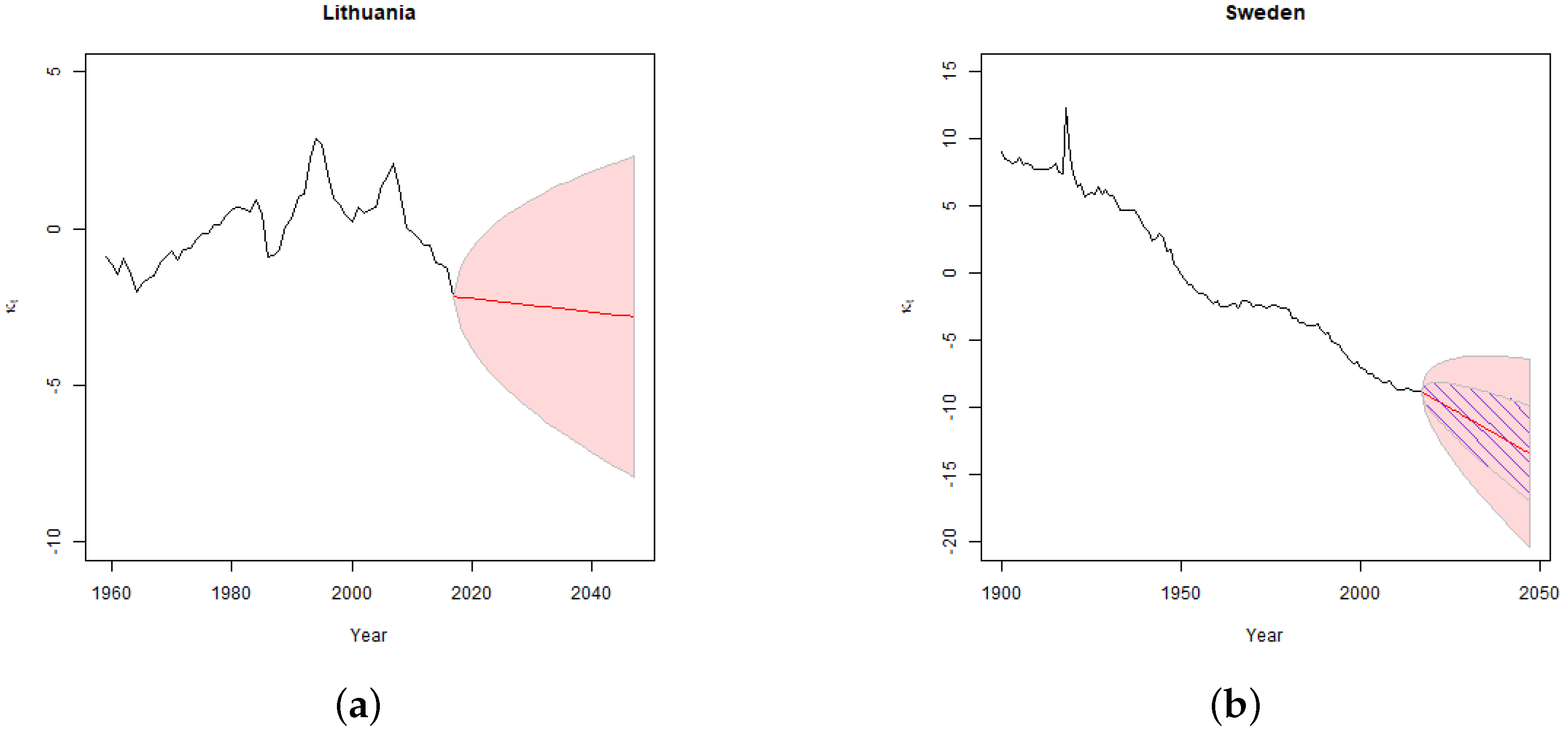
Despite its popularity Lee-Carter model has several limitations. The model ensures adequate fit only if the underlying data contains a stable mortality trend. For example,
Figure 1 shows the results of fitting classical Lee-Carter model to mortality data which either has a volatile trend or includes an outlier.
In the Lithuanian case the standard Lee-Carter model produces projections with unacceptably wide confidence intervals due to volatile historic mortality experience which poorly fit a linear trend assumption. The country experienced a sharp increase in mortality rates after the collapse of the Soviet Union (that was experienced by many ex-USSR countries) which was followed by a gradual decline in mortality rates after the country’s independence and the accession to the EU. Consistent Swedish mortality improvement was distorted by the effect of 1918–1920 Spanish flu pandemic. Thus, the estimated variance of the Swedish projections averages the variance observed during the periods of usual mortality development and that of the pandemic period.
Figure 1b shows that just one outlier of the year 1918 has a major effect on the estimated confidence intervals of the projected time varying index.
Standard Lee-Carter model has limited possibilities of dealing with such distortions and usually the key practical recipe of achieving adequate fit is to cut the data used for model-fitting to the latest stable mortality period, see Gylys and Šiaulys [
4], Lee and Miller [
3], Tuljapurkar et al. [
5]. In addition, the classical Lee-Carter model projections do not allow for parameter uncertainty. Some authors, e.g., Brouhns et al. [
6], Koissi et al. [
7], applied bootstrap methods to estimate the effect of uncertainty in estimated parameters. However, the results of such analysis are affected by the general limitations of the Lee-Carter model as described above.
State-space time series models (SSMs) (see Durbin and Koopman [
8], Harvey [
9], West and Harrison [
10]) defined by relations
where vector
is observed, vector
is unobserved state parameter vector, and
p is an arbitrary distribution. SSM offers a natural opportunity to extend the Lee-Carter model both in terms of the alternative coherent fitting procedure and the possibility to flex the model by introducing additional parameters to ensure a better fit. A linear Gaussian state-space model, often called
Dynamic Linear Model (DLM) is one the most popular SSM in applications This model can be represented by the following two equations:
where
and
are the Gaussian errors and
,
,
,
are the parameter matrixes. Thus, we can express Lee-Carter model in state-space representation by treating Equation (
1) as observation equation and Equation (
2) of the time varying index
as an the state equation.
State-space models can be traced back to highly influential paper by Kalman [
11]. Although initially these methods were applied predominantly in engineering and signal processing, over time it became a recognized statistical modelling technique. Examples of application of the SSMs in mortality analysis are presented by Fung et al. [
12], Kogure and Kurachi [
13] and Pedroza [
14] among others.
As an extension, we applied
SSM with regime-switching (SSM with switching). Such models are often referred to multi-process models and are DLMs conditionally on a sequence of indicator variables, which represent varying regimes. In the context of the mortality modelling such regimes may be interpreted as switching between stable and volatile socio-economic development conditions which positively or negatively affect the mortality development. Such models were successfully applied in economics for modelling of business cycles, see for instance Hamilton [
15], Kaufmann [
16] and Kim and Nelson [
17] among others.
Thus, the aim of the paper is to explore the possibilities of SSMs to develop an alternative solution of dealing with the two common general problems, as illustrated above, encountered in practice when modelling mortality. We treat the pandemics, wars, other significant one-off fluctuations in mortality rates as a natural phenomenon to be considered in the projections. We also show how to use flexibility of SSMs to deal with one-time change in socio-economic development, which, for example, was experienced by many Central and Eastern European countries. The focus of the analysis is estimation of confidence intervals of the projected mortality rates, in particular at the tails of the distributions, which is important for insurers’ solvency and economic capital models, rather than just the central mortality forecast. The performance of the models is assessed by using the mortality data of Lithuania and Sweden, but the issues and possible application is not limited to these countries.
We estimate the model parameters using Gibbs sampler, which is the primary Markov chain Monte Carlo (MCMC) method for SSMs with switching. Output from the Gibbs sampler also allows us to take into account parameter uncertainty. For ensuring the comparability of results, we also use the Gibbs sampler for fitting DLMs. For model comparison we use marginal likelihoods estimated with sequential Monte Carlo technique based on auxiliary particle filter.
The study covers ages from 25 to 74 and is primary aimed at the assessment of mortality risk at insurance companies. However, the methods used can be extended to analysis of mortality of older ages and can be used for assessment of longevity risk, which is particular important for pension products providers. For the analysis we use the general population data from Human Mortality Database for ages 25–74 grouped in 5 year age groups for the following periods: Lithuania 1959–2017, Sweden 1900–2017. Human Mortality Database (
https://www.mortality.org) is maintained by the University of California, Berkeley (USA), and the Max Planck Institute for Demographic Research (Germany). Data for our research was downloaded in February 2020.
The paper is organized as follows.
Section 2 provides an overview of the models used, the Gibbs sampler as well as the methodology used for model comparison.
Section 3 provides the detailed description of the algorithms.
Section 4 deals with details of the MCMC diagnostics and the model-fitting and comparison results.
Section 5 provides overview of the forecasting results.
Section 6 concludes the paper with the discussion of the results, implications for the mortality modelling and areas for further research.
2. State-Space Lee-Carter Models
We develop two different specifications of state-space Lee-Carter model: based on DLM and SSM with switching. For comparison we use the results derived by the classical Lee-Carter method fitted using SVD, therefore, some details of the classical model are also provided.
2.1. DLM
By using the general expression (
3) of DLM, we can formulate state-space Lee-Carter model by the following two equations:
In the observation Equation (
4), symbol
denotes vector with
N coordinates, where
N is the total number of age groups. Each coordinate of this vector
is the specific centered log-mortality rate
Parameter
is a column vector of
N age specific parameters
, which determine the impact of the time varying index on log-mortality rates. Matrix
is a diagonal
matrix with all diagonal elements equal to
.
In the state Equation (
5), element
is the time varying index, which represents the general trend of changes in mortality rates with time,
is the drift of
which continues for the whole fitting period. Coordinate
represents the additional drift element in the time period
and symbol
denote the standard indicator function. Thus, during the periods
the model assumes that the total drift of parameter
is
. As in the classical Lee-Carter model, we assume that both drift parameters stay constant during the fitting period and we apply the following covariance matrix of errors of the state parameter
:
The above model maintains many of the features of the classical Lee-Carter model. The time varying index follows a RWD. Contrary to the classical Lee-Carter model we allow a one-time change in drift at some time moment but otherwise drifts are not allowed to vary in time. Such structure ensures that the model is sufficiently rigid, which is important for making long-term forecasts. On the other hand, the feature of one-time change in drift allows us to model major changes in environment, which cannot be modelled in the classical model. As in the classical Lee-Carter model the general trend of mortality modelled with parameter is translated to age specific log-mortality rates via the parameters , and the random residuals , are assumed to be i.i.d.
In our model, we stochastically assess the deviations from the centered log-mortality rates, and the Lee-Carter parameters
, which represent the general shape of changes in log-mortality rates with age, are expected to be fixed. We set
for
, as in the most of the classical Lee-Carter model’s applications, and deduct it from log-mortality rates before starting the fitting process, see Equation (
6). Overall, in applications of the Lee-Carter model, parameter
has proved to be one of the most predictable model parameters. For example, in the bootstrap analysis performed by Koissi [
7], variation in the estimates of parameter
was predominantly related to very young ages (below 20 years) and old ages above 80 years, and for the remaining ages was very stable. Therefore, we consider that the simplification of fixing
parameter does not have a significant effect on the results of the analysis.
As in the classical Lee-Carter model we apply the following identifiability constraint for parameters
:
The constraint is applied in step
of algorithm
presented in
Section 3.2, where the estimated parameters
are re-weighted with the corresponding adjustments made to the mean and scale of the estimates of
. Thus, after the re-weighting the distribution of the term
is unchanged.
The key feature of the SSMs is that they enable estimation of the distribution of each of the unobservable parameters
, by using the observed data
. The recursive algorithm, called Kalman filter, which is based on the method of orthogonal projections and uses the features of the conditional Normal distribution, updates the estimate of the mean and variance of
with the new evidence contained in
in order to derive the mean and variance of
. For the equation of the basic Kalman filter, see step
of algorithm
described in
Section 3.1. Thus, assuming that the collection of the model parameters
,
, is known, we can run the filter for all
and derive the distribution of
, which shall contain the mean and variance of time varying index
for
. The detailed description of the method used to estimate the parameter collection
is presented in
Section 2.3.
2.2. SSM with Switching
The basic equations of our state-space Lee-Carter model with switching remain (
4) and (
5). The key difference from the previous model is that we assume that the error terms
,
, follow a mixture of two zero mean Normal distributions with the following covariance matrixes:
each of them corresponding to one of the two regimes. We restrict
and use a binary index
: low variance regime
and high variance regime
. Therefore, in SSM with switching the errors of the parameter
depending on its parametrization may have much heavier tails with respect to tail of standard Normal distribution.
The switching between the two regimes is assumed to follow the Markov process with constant transition probabilities as introduced by Hamilton [
15]. We define two probabilities
which imply that:
Consequently, the parameter collection of the model with switching contains three extra parameters: vector of variances instead of one variance and vector of transition probabilities .
Conditionally on values of
,
, we can recursively estimate probabilities of
and
, by taking into account the corresponding probabilities at the time moment
, as well as the likelihood of being in a particular state, which is driven by the deviation of the change
from its expected value
: the higher the deviation is, the more likely is that the process has moved to high variance regime. For details see step
of algorithm
described in
Section 3.3.
Conditionally on values of
,
, we can apply the basic Kalman filter as described in
Section 2.1. The only difference is that the matrix
can vary in different update steps of the filter; however, this does not change the basic operation of the algorithm.
The key benefit from using the SSM with switching is that it enables us to segregate the total variance of
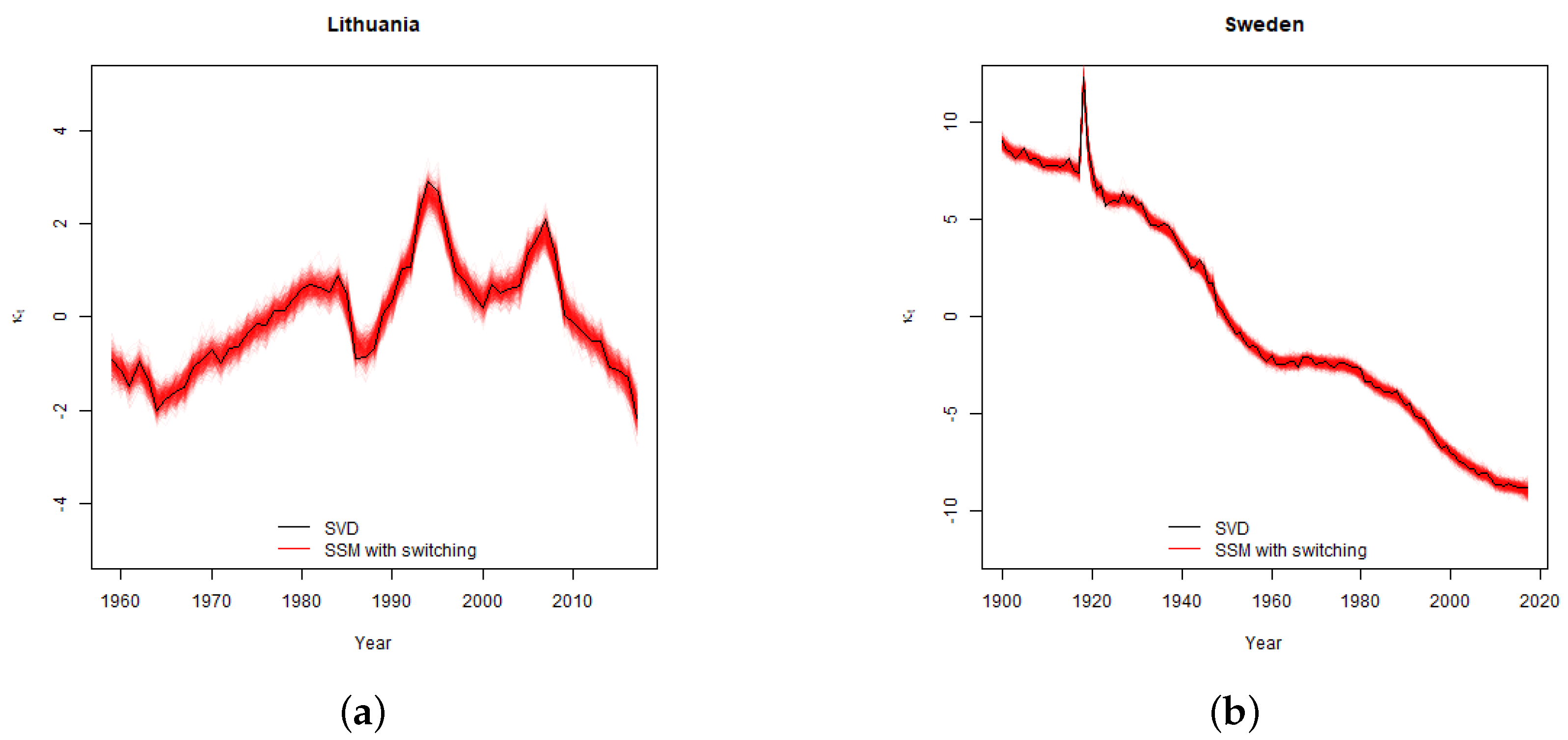
, which is generally recognized to be the key source of variability of mortality rates, into the variance during the periods of the “normal” socio-economic development and the variance during the periods such as epidemics, wars, changes economic and political systems, etc. As shown in
Figure 1, the development of the general mortality trend may be far from constant, therefore, the classical Lee-Carter approach, which averages the variance of
over the fitting periods might miss important features of the real life development, especially when the purpose of the analysis is estimation of the confidence intervals of the mortality forecasts rather than just the central forecast.
2.3. Parameter Estimation with Gibbs Sampler
There are two main approaches to fitting of SSMs: maximum likelihood (MLE) and Bayesian Markov Chain Monte Carlo (MCMC). For estimation of the parameter collection
of DLM Lee-Carter we can easily apply MLE, see e.g., [
12]. However, as noted by Frühwirth–Schnatter [
18], in case of SSM with switching the marginal likelihood where both latent processes
and
s are integrated out, is not available in the closed form. In addition, MLE does not explicitly allow for uncertainty in model parameters, which is an important element in satisfying our aim to estimate realistic confidence intervals of the forecasts.
Therefore, for model-fitting we apply MCMC method called Gibbs sampler, which was also used in some earlier applications of the state-space Lee-Carter model without regime-switching by Fung et al. [
12], Kogure and Kurachi [
13], Pedroza [
14]. The Gibbs sampler draws samples of parameter values from sequentially updated conditional distributions. Thus, if we have a parameter vector
, the Gibbs sampler at each iteration
would sequentially draw samples of
for
from
, where
denotes draw of parameter
at
j iteration. As shown by Geman and Geman [
19] under certain mild conditions the distribution of draws
converge to the true distribution of
if
, independently of the starting values of
.
The general difficulty in constructing and using the Gibbs sampler is the requirement at each step to have conditional distributions of the sampled parameters. In our case, conditional distributions of time invariant parameters can be derived from Equations (
4) and (
5); however, the complication arises of implementing a proper conditional sampler of the unobserved state parameter
and, in the case of model with switching, the collection vector of regimes
. This issue was successfully resolved by Forward Filtering Backwards Sampling (FFBS) algorithm presented in algorithm
in
Section 3.1, see also Carter and Kohn [
20] and Frühwirth-Schnatter [
21] for additional information.
We note that the Gibbs sampler is a Bayesian estimation method, thus in addition to the estimated parameters the conditional distributions at each step of the sampling scheme depend on the selected priors. We denote the collection of priors for DLM and SSM with switching and respectively, where and are conjugate multivariate/univariate Normal priors, are conjugate gamma priors, and are conjugate beta priors.
The details of descriptions of the parameter estimation algorithms are provided in
Section 3.2 and
Section 3.3.
2.4. Forecasting
As noted in the previous section, Gibbs sampler after its convergence produces draws from the posterior joint distribution of parameters. Thus, after discharging certain number of initial draws (called burn or warm-up phase) we can use the draws as an input for the forecasting simulations of the state-space models. For both models DLM and SSM with switching we simulate the projected mortality rates for periods in the following way.
- (i)
Depending on the model, DLM or SSM with switching, sample parameter collection ψ or from the matrix of Gibbs sampler draws obtained during the model-fitting phase after the warm-up. In this step, we are sampling the parameter values from their joint posterior distributions.
- (ii)
For SSM with switching, draw sample of regime indicators for the forecasted period using step of the algorithm (see Section 3.3). As
are not available for time moments
, multiplication by the probability
in position (ii.2) of algorithm
may be disregarded.
- (iii)
For SSM with switching, using sampled parameters and and regime vector from step simulate for time moments by supposing thatwhere is switching between and depending on the simulated . In case of DLM, use as a fixed variance.
- (iv)
Using sampled parameters and and sampled vector from step (iii), as well as allowing that errors are i.i.d., simulate for time moments and age groups by supposing that
- (v)
Calculate mortality rates, having in mind that for all possible x and t.
In case of the classical Lee-Carter model, we do not have draws from the posterior distribution of the parameters. We can partially allow for parameter uncertainty in the classical Lee-Carter model by allowing for uncertainty of the drift, see [
3], the distribution of which follows from the RWD assumption of
. Except for
, for the simulation we use fixed parameters, estimated via SVD and time series fitting process. Therefore, the classical Lee-Carter model provides less comprehensive treatment of parameter uncertainty than SSMs. For the classical Lee-Carter model we simulate the projected mortality rates for time moments
by the following algorithm.
- (i)
Draw from .
- (ii)
Simulate for from .
- (iii)
Simulate for by supposing that .
- (iv)
Calculate mortality rates for all possible x and t, by formula
2.5. Comparison of State-Space Models
For the state-space model comparison, we use marginal likelihood. We apply the following formula by Chib [
22]:
where
,
is the marginal log-likelihood,
is the log-likelihood conditional on the estimated parameters,
is log density of prior at
and
is the log density of posterior at
.
Term
can be calculated in the closed form for DLM, but for SSM with switching the likelihood function would be a mixture of
Normal distributions, the direct assessment of which is not practical. Therefore, we use the sequential Monte Carlo method based on auxiliary particle filter of Pitt and Shephard [
23] which was adapted to SSM with switching by Kaufmann [
16]. The details of the algorithm are provided in
Section 3.4.
The term
we estimate similarly as in [
22] by using the sequentially running Gibbs sampler for each of the parameters in the collection
and estimating their posterior likelihood at the mean points of
from MCMC runs by the following algorithm:
Estimate as a mean of the appropriate likelihood function of the parameter evaluated over the parameters of MCMC runs of the Gibbs sampler sampled as described in Section 3.2 and Section 3.3.
Estimate by fixing the parameter at the value and by performing additional run of Gibbs sampler as in the first step.
- - -
Estimate by fixing the parameters at the values and by performing additional run of Gibbs sampler as in the first step.
At the end we calculate the total posterior log-likelihood:
3. Algorithms
3.1. Forward Filtering Backwards Sampling (FFBS) Algorithm 1
(i) Conditionally on the initial distribution , which we assume to be known, for run the Kalman filter recursion in order to obtain estimated distributions of unobserved state parameter vector given the observation , as well as the distribution of the one step ahead predictions . Using the general Kalman filter equations, see for instance, Chapter 4 by Durbin and Koopman [
8], we derive the following recursion formulas for the state-space Lee-Carter model mentioned in Equations (
4) and (
5):
where
,
is estimated covariance matrix of the observation,
is an estimated residual,
is an identity matrix, and the matrix
is called the Kalman gain.
(ii)
Sample by supposing that .
(iii)
Treat one step forward sample as an observation and apply the Kalman filter to it.
According to Carter and Kohn [
20], for
, we should sample
by supposing that
, with
3.2. Gibbs Sampler Algorithm 2 for DLM
(o)
Initiate the sampler using an arbitrary starting parameter collection and collection of priors .
(i)
Sampleconditionally on ψ, and store vector of values by applying FFBS algorithm with the initial distribution Simulation results are usually insensitive to selection of , provided be sufficiently large. We use .
(ii)
Sample conditionally on and , from the bivariate Normal distributionwhere is a vector of changes in , while is a matrix of dimension with the formwhere number of the first lines is the number of periods before change in trend of occurred. (iii)
Sample , conditionally on and , from the inverse Gamma distributionwhere is the standard indicator function. (iv)
Sample , conditionally on and , from the Normal distribution.
Considering that we assume that the matrix of measurement errors
is diagonal, we can sample
for each age group
separately:
where
is a vector of centered observations for age group
x.
(v)
Sample , conditionally on and , from the inverse Gamma distribution: (vi) Reweight and related parameters to ensure that the sum of elements of is equal to unit. We proceed as follows:
(vii) Collect the updated parameters to collection ψ and proceed to step (i).
3.3. Gibbs Sampler Algorithm 3 for SSM with Switching
(o)
Initiate the sampler using an arbitrary starting parameter collection , collection of priors and an arbitrary vector .
(i)
Sampleconditionally on and the regime vector , and store vector of values by applying FFBS algorithm with the initial distribution Simulation results are usually insensitive to selection of , provided be sufficiently large. We use .
(ii)
Sample vector , conditionally on , , and in the following way:
(ii.1)
Calculate the initial probabilities of the two regimes by assuming that the filter is initialized with the following stationary Markov chain probabilities: (ii.2)
For use the recursive procedure described in [20]: (ii.3)
Sample from the Bernoulli distribution with the success probability .
(ii.4)
For sample recursively from the Bernoulli distribution with the one of the following success probabilities depending on the value of : (ii.5) Collect the sampled regime indicators to the vector .
We remark here that steps (iii)–(v) of the presented algorithm are constructed following results from [
17].
(iii)
Sample , conditionally on , from beta distributionswhere and are prior parameters and symbol denotes the number of transitions from the regime i to the regime j in the regime vector . (iv)
Sample , conditionally on , and , from the bivariate Normal distributionHere:, , and are defined in algorithm , is vector of numbers with the index i corresponding to regimes in vector , is matrix consisting of the doubled vector A, and symbol ⊙
denotes the element-wise matrix multiplication. (v)
Sample , conditionally on , and , from the inverse Gamma distribution.
(v.1)
Sample using the inverse gamma distributionand suppose that . (v.2)
Sample number from the inverse Gamma distributionwhere summation is performed over the moments for which .
(v.3)
If the sampled , define . Otherwise, leave h from the previous run.
(vi)
Sample , conditionally on and , from the Normal distribution.
Considering that we assume that the matrix of measurement errors
is diagonal, we sample
for each age group
separately:
where
is a vector of centered observations for age group
x.
(vii)
Sample , conditionally on and , from the inverse Gamma distribution: (viii) Reweight and related parameters to ensure that the sum of elements of is equal to unit. We proceed as follows:
(ix) Include the updated parameters to the collection and proceed to step (i).
3.4. Particle Filter Algorithm 4 for Marginal Likelihood for SSM with Switching
In this subsection, we provide the details of the auxiliary particle filter algorithm used to evaluate the log-likelihood conditional on the model parameters , which in turn is used to calculate the marginal likelihood.
(o)
With the parameter collection initiate the filter by drawing R times with replacement from the output of the Gibbs sampler and generating R draws of from Bernoulli distribution with probability (i)
For each and , conditionally on pair sample sequentially the pair in the following way:
(i.1)
Using the basic Kalman filter, for derive the one step ahead predictionwhere and . Obviously, in this filter we consider only the last state line of equitation (
5) as the drifts are fixed.
(i.2)
For find the matrix and .
(i.3)
For calculate and standardize probabilities (i.4) Sample using the derived probabilities in step (i.3).
(i.5)
Given the sampled element with the basic Kalman filter, calculate the distribution of the prediction given by the observation (i.6) Sample and proceed to the step (i.1).
(ii)
From the draws , calculate the one step likelihood by the formulawhereis based on the model errors not depending on . (iii) Using the Markov property of the model find the marginal log-likelihood conditioned on
:
5. Results of Forecasting
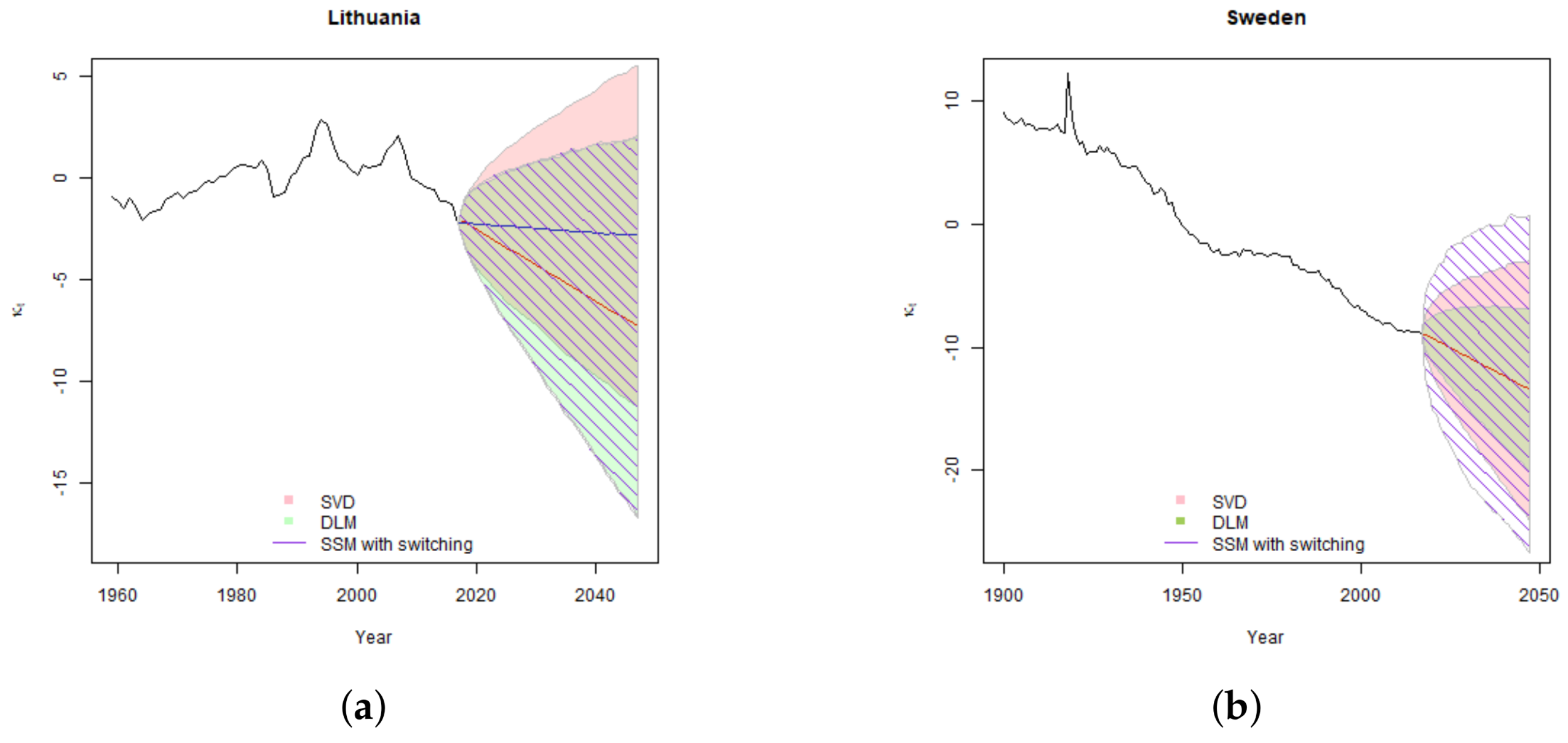
In this section, we provide details of the mortality forecasts derived using the SVD, DLM and SSM with switching models. We present the results for two different confidence levels: and . Level correspond to 1 in 200 years loss event and is used in assessment of insurers solvency in the European Solvency II regulatory regime.
By taking exponentials on both sides of Equation (
1), we can represent the modelled mortality rates as follows:
which shows that the variability in projected mortality rates can be considered to arise multiplicatively from three sources: variation in constant which represents the increase in mortality with age (which we ignore due to its insignificance as a simplification), variation in trend, mainly driven by the parameter
, and the remaining random variation. In the remainder of this section, we first discuss the modelled uncertainty of
, and in the next subsection, we consider how this uncertainty translates to the variation of the overall mortality rate.
5.1. Projections of Parameter
As can be seen from Equation (
2), the uncertainty of the parameter
is driven by variation in drift parameter
and the residual error. The results of the simulations of
are provided in
Figure 5 for confidence level of
, and in
Figure 6 for confidence level
.
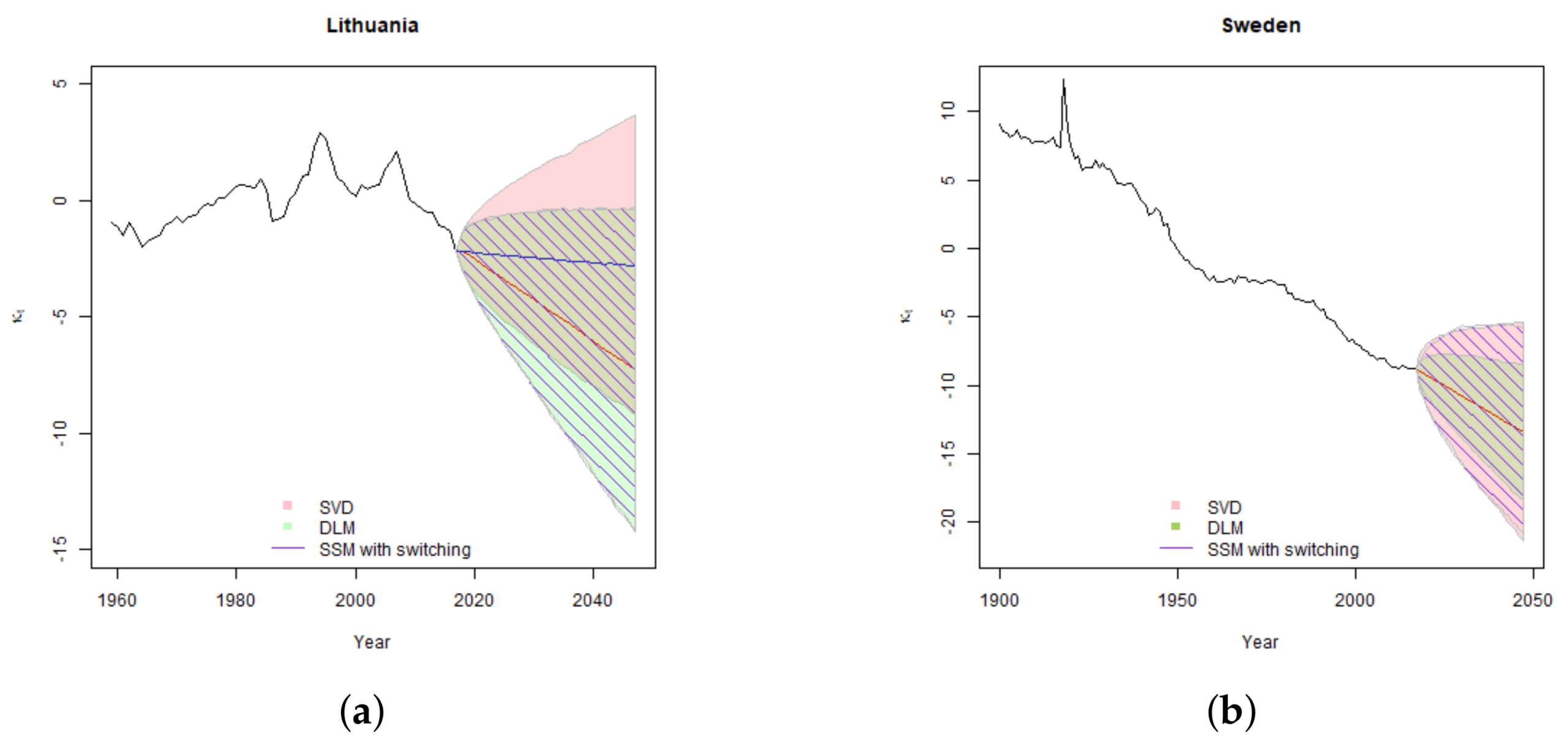
In the Lithuanian case, due to unsettled historic experience, the confidence intervals are wide for both SVD and state-space models. Allowance for one-time change in trend results in a more reasonable central forecast; however, it adds additional uncertainty of the second drift parameter . Thus although estimated error variance is lower in SSM case, the overall confidence interval of is even slightly wider than the one derived by using the classical Lee-Carter model.
In the Lithuanian case, the SSM with switching does not converge to two clearly expressed low and high variance regimes. Therefore, the distribution of error terms modelled as a mixture can be well approximated with Normal distribution. For this reason, the simulated confidence intervals for both models are very similar.
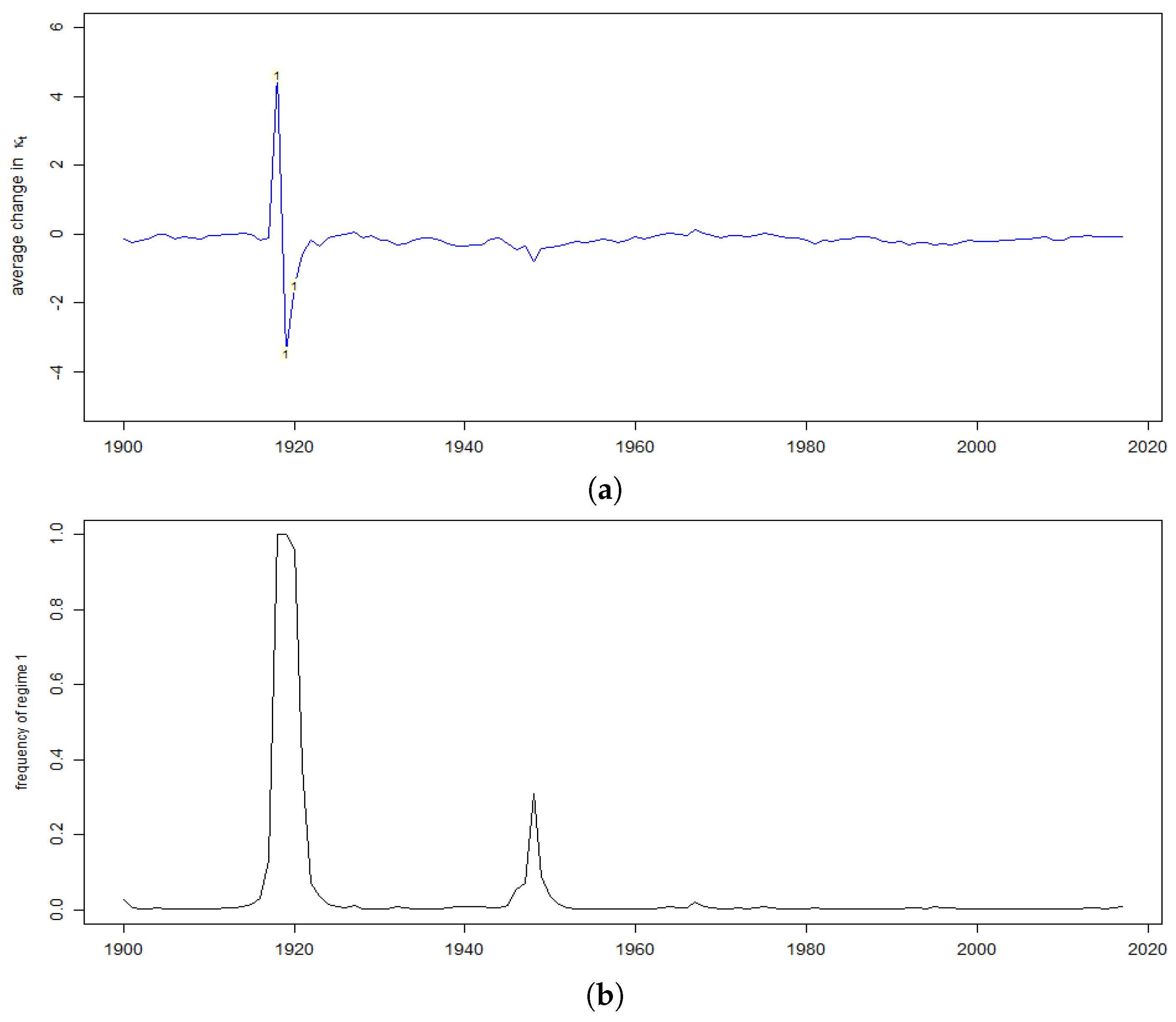
In the Swedish case, DLM gives a narrower estimate of confidence interval with respect to SVD generally due to the better fit and the lower error variance. For Sweden SSM with switching converges into two different regimes: low probability and high variance pandemic regime and high probability low variance usual development regime. Thus, the distribution of the error terms when modelled as a mixture, has much heavier tails than when it is approximated with a single Normal distribution. This results in significantly wider confidence intervals for SSM with switching, especially at 99.5% confidence level. We note that the width on the difference in confidence intervals is driven by model differences, not the poor fit. As shown in model comparison
Section 4.4, despite having the widest confidence intervals SSM with switching has higher log-likelihood that DLM and is a preferred model for Sweden.
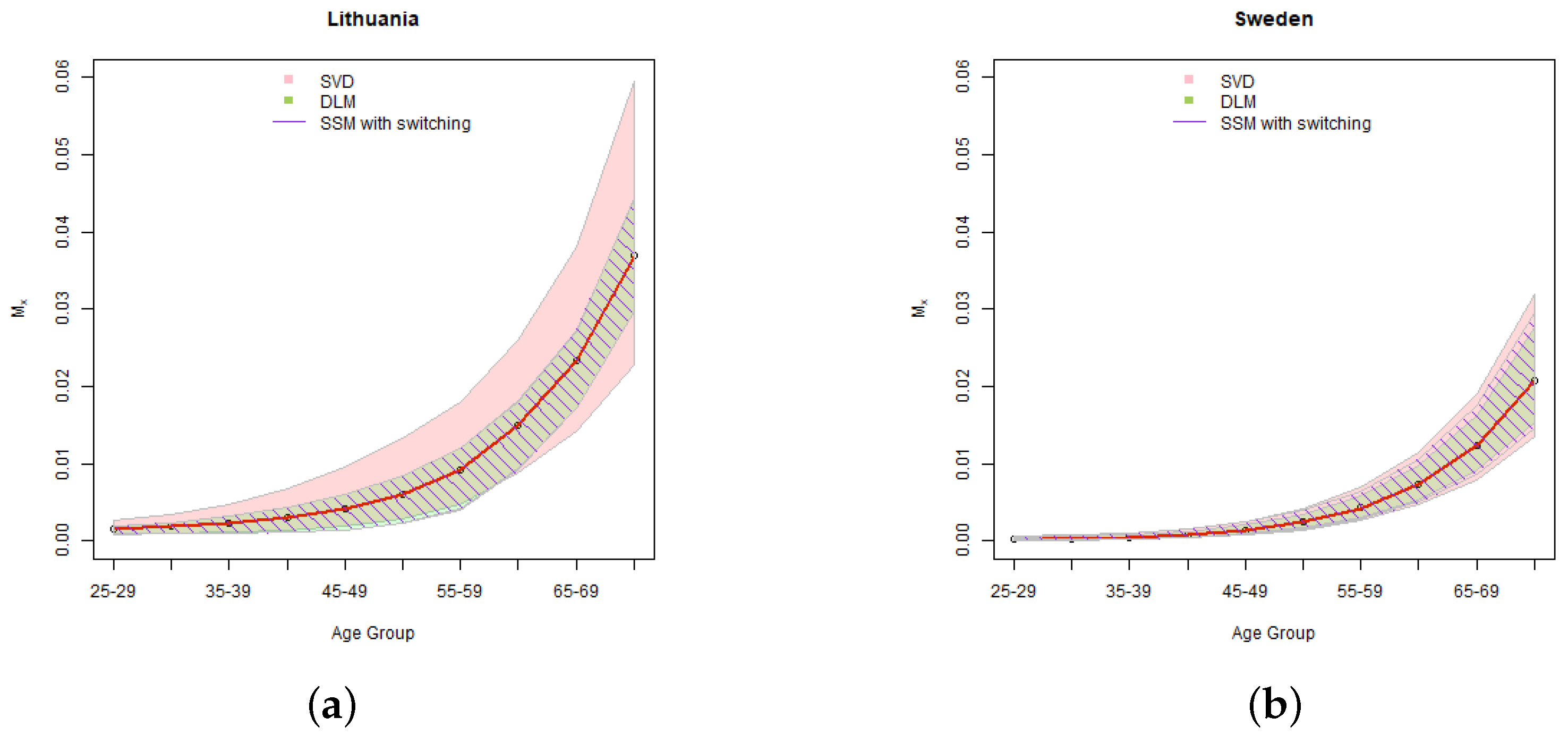
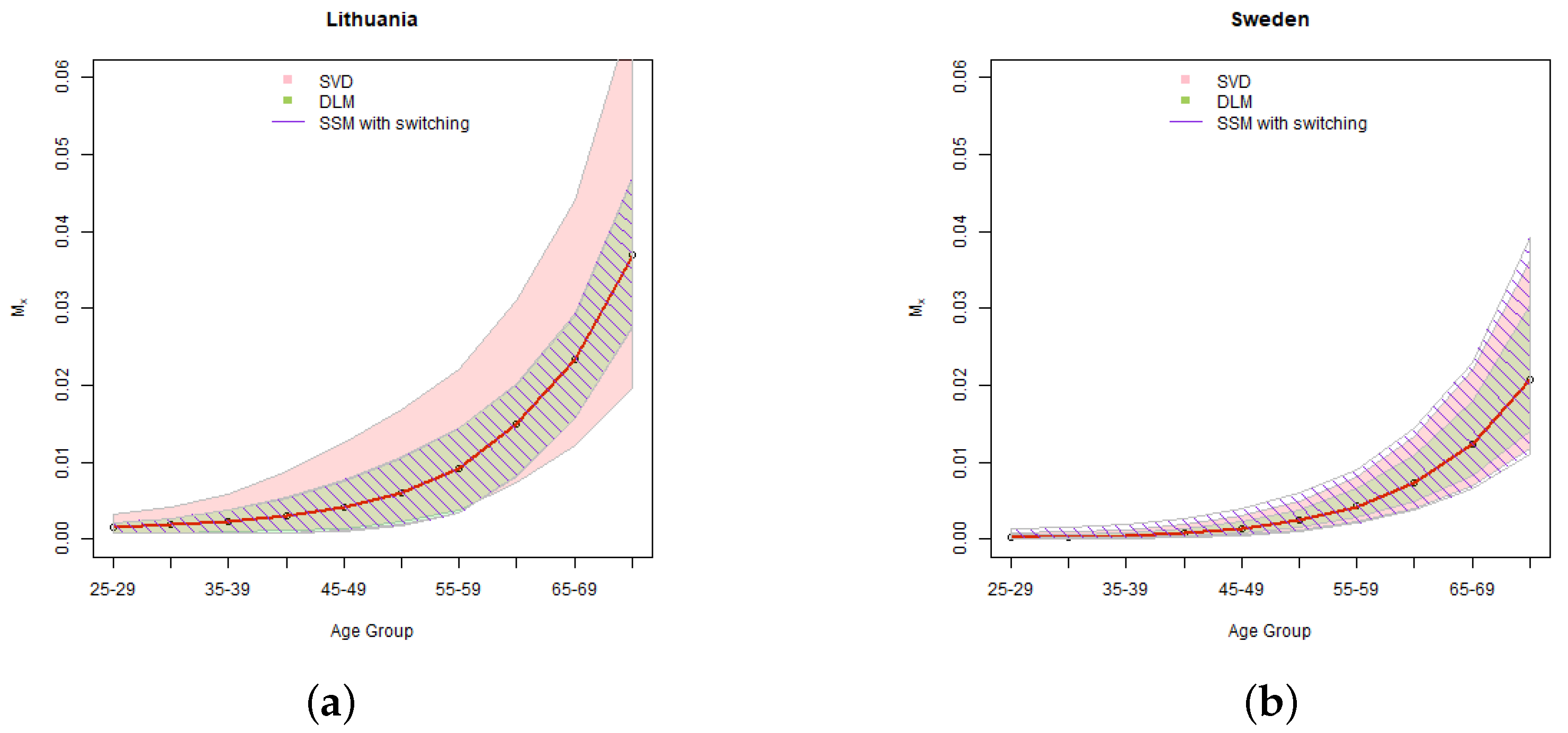
5.2. Uncertainty of Mortality Rates
The results of the simulations of
mortality rates are provided in
Figure 7 for confidence level of 95%, and
Figure 8 for confidence level 99.5%. Considering that in practical applications we usually need a set of mortality rates for each of the future years in the forecasting period, in our illustration we provide the results for 15 year projection, which is in the middle of the total forecasting period.
As we can see in Equation (
7), the variation in
is translated to changes of the mortality rates via the parameter
. The higher
for a certain age group is, the more sensitive are the projected mortality rates of that age group to changes in
, and vice versa. As shown in
Table 3, for Lithuania the highest
are for mid-ages and therefore in the state-space models mid-agers get the widest confidence intervals. The Lithuanian SVD calculations, due to relatively poor fit, have a large residual variance, which dominates in the classical Lee-Carter model simulations and results in very wide simulated mortality rate confidence intervals. Thus, despite we did not manage to achieve with SSMs a significant improvement in the confidence intervals of the parameter
, the width of the simulated confidence intervals of mortality rates are reasonable and comparable to the Swedish result.
In the Swedish case, the results are consistent with the results of simulation of parameter . Due to better fit, at 95% confidence level the confidence intervals of SSMs are narrower than in case of SVD. At 99.5% confidence level, as expected, the heavy tails of SSMs with swithing prevail, resulting in the widest confidence intervals.
6. Discussion
Overall, the use of state-space models enabled us to achieve better fit and to derive more reasonable confidence intervals of the projected mortality rates. The methods developed in the paper can be used in common mortality modelling situations when there is a major change in mortality development trend or major fluctuations in mortality are observed. In particular, in the Swedish case the pandemic effect was well captured by SSM with switching and both DLM and SSM with switching allowed us to take into account the Lithuanian change in mortality trend. However, SSM with switching model developed in this paper proved to capture more prolonged and less sharp fluctuations in the level of mortality less successfully and further research is needed in this area.
The analysis also showed that in case of mortality projections, if we want to achieve high confidence levels, we need to accept wide confidence intervals. Historically, mortality experience was volatile, and we cannot preclude this volatility in the future. The analysis also showed that in some cases Normal approximation of the distribution of residuals, which have true mixture distribution, can unjustifiably narrow the confidence intervals of the projections, especially for high confidence levels. This could have negative implications for insurers, who use high confidence intervals in their risk and capital models as application of too narrowly distributed projections may lead to understatement of the economic capital.
The study demonstrated the advantages of SSM in the mortality modelling, in particular in ensuring higher flexibility and more coherent estimation of parameters. Overall, SSM may be used to flex other parameters of the Lee-Carter model. For example, it is possible to model the variance of residual of parameter
stochastically as in [
12], apply regime-switching to parameter
, or apply state-space Poisson model as in Chapter 9 of [
8] or introduce certain volatility of a drift of time varying index. Considering the recent developments in the area of nonlinear SSMs and sequential Monte Carlo methods the possibilities of their application in mortality studies are very high.
In practice, it also possible to use the Bayesian structure of the model. In this research, we used weakly informative priors to “let data to speak for itself”. However, in practice more informative priors are often used, to use experience from peers, introduce expected developments stemming from business plans, or simply apply the expert judgement. Thus, with SSM we can introduce not only greater flexibility of the model but also of its parameters.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}