1. Introduction
Statistical modeling depends on accurate data to provide reliable results in many contexts. This is especially relevant in the case of medical diagnosis. Since the human factor is introduced in the data collection processes, errors may occur. For example, when modeling a degenerative disease, which should produce non-decreasing outcome data over time, it may happen that some data do not satisfy this condition, mainly due to human factors. Therefore, additional parameters should be included in the statistical approach to correct the bias yielded by the use of error-prone data. Ignoring measurement errors may lead, in many cases, to non-optimal decisions (see, e.g., [
1,
2]). For example, the wrong estimations can be obtained for the sensitivity and specificity of diagnostic tests, which may lead to errors in positive and negative predictive values, implying diagnostic errors. Thus, statistical models should incorporate correction mechanisms for measurement errors to produce proper inference.
In the scientific literature, there are different approaches considering measurement errors in different contexts, depending on the type of observed data. When a measurement error occurs in a categorical variable, it is called misclassification. The work in [
3] proposed statistical models for phenomena with misclassified ordinal responses in the multivariate case. The work in [
4] considered covariates with missing data. The work in [
5] addressed misclassified ordinal response data based on a cross-sectional framework. For misclassified longitudinal data with categorical responses, The works in [
6,
7] considered generalized linear mixed models, whereas [
6,
8,
9] used approaches based on generalized estimating equations.
Multi-state transitional models and hidden Markov models (HMM) are useful for quantifying disease staging. They can be used to examine measurement error and misclassification in longitudinal studies where the outcome is continuous or categorical in both continuous and discrete time settings. For binary misclassifications with non-monotone longitudinal responses, HMM have been considered by several authors ( e.g., [
10,
11]). The works in [
12,
13,
14,
15] addressed the problem of misclassified monotone longitudinal responses. The work in [
16,
17,
18] proposed models for longitudinal data with ordinal responses subject to misclassification in a non-continuous internal process.
HMM with random effects [
19], also called mixed hidden Markov models (MHMM), have been used to cope with misclassification in multilevel data [
20] and longitudinal data [
21]. The model parameters of HMM and MHMM for true monotone responses may be estimated without the use of external information on the misclassification parameters. Recently, the works in [
22,
23] developed approaches based on HMM to model measurement errors in continuous and binary responses, respectively, in the context of non-decreasing processes. In this paper, an HMM is proposed to address measurement errors in the ordinal response in the context of monotone non-decreasing processes. A Bayesian framework is presented with an efficient Markov chain Monte Carlo (MCMC) method that solves the computational problem. The approach is applied to simulated data in order to evaluate its performance and to the problem of grading aortic aneurysms based on misclassified data.
In the proposed approach, the true process by which the disease develops can be modeled continuously, but this level of measurement is transformed into an ordinal scale for practical purposes. Furthermore, considering that the process is non-decreasing, it is assumed that the disease progressively worsens. Aortic aneurysm is an example of the type of disease that can be modeled with this approach, since it is a located and permanent dilation that occurs in the aorta and is caused by a progressive degeneration of its wall. It must be monitored because its natural evolution is growth until breakage. Its diagnosis is based on the diameter of the aorta [
24], but it is staged by severity, according to successive ranges of aortic diameter in an ordinal scale (from Stages 1 to 4). Besides, this disease is prone to measurement errors due to the ultrasound equipment and/or its management.
The rest of the paper is organized as follows.
Section 2 includes the proposed approach considering non-decreasing time processes with measurement error in the ordinal response and the conditional independence assumptions. In
Section 3, a Bayesian analysis is presented.
Section 4 shows the model performance with a simulation-based example, whereas the analysis of the aortic aneurysm data is presented in
Section 5. Finally, the conclusions are presented in
Section 6.
2. The Model
The proposed approach considered a time-dependent process, which was continuous and monotone non-decreasing. It addressed the measurement errors in the ordinal response, and it took into account several conditional independence assumptions. The following subsections describe the approach.
2.1. A Continuous Monotone Non-Decreasing Process
N response scores were considered, all of them recorded at time points
,
and
Without loss of generality and for the sake of simplicity, the subjects were assumed to have the same number of time points, which is denoted by
Nevertheless, this is only a notation issue, and a different number of time points could be handled by the approach. Let
be the true response for the
ith subject at time
such as
for all
i. This means that
is a monotone non-decreasing continuous process, representing the true gradual process, which is difficult to score quantitatively, and it is not observable. Therefore, let
be a process that is recorded and subject to measurement error, which will be introduced in
Section 2.2.
Now, consider two vectors of covariates associated with the
ith subject:
which is a non time-varying
L-dimensional vector, and
which is a time-varying
M-dimensional vector at time point
. Moreover,
represents the vector of covariates for the
ith subject. Let
be the linear predictors for the
ith subject at time
, consisting of linear combinations of the covariates
and
i.e.:
where
and
are the
L-dimensional and
M-dimensional vectors of coefficients for the covariates
and
respectively. Then,
is the unknown response vector that is related to a set of the exogenous covariates
and
through the following equations (see [
22]):
where
denotes the indicator function. Since the
’s are unobserved and in order to avoid identifiability problems, the variances of the normal distributions were set to one. Moreover, a first-order Markov chain property for continuous processes was assumed, and the truncation allowed the non-decreasing restriction to be satisfied.
2.2. Addressing Measurement Errors in Ordinal Response
The response variables are latent variables assumed to be prone to measurement errors. Let be the non-error-free ordinal response for subject i at time where takes one of J categories. Thus, denotes the observed score, which may have been measured with error, and with either non-decreasing or decreasing patterns.
Let
denote the probability that the
ith subject at time
is classified in the
jth category for
For ordered response categories, the ordinal model can be defined by cutpoints
considering that
where
is a cumulative distribution function (cdf) (see [
25]). Let
be the vector of unknown cutpoints with
and
In order to avoid parameter identifiability problems, the intercept term is excluded from the linear predictor
, or it is included, but with only
unknown cutpoints
where
.
Now, based on the data augmentation framework for the ordinal regression model proposed by [
25,
26], let
be the non error-free continuous response for subject
i at time
having
as the cdf. These variables
are related to
by:
Measurement error is here assumed to occur on the latent continuous variable
, which has a normal distribution conditional on
(see [
1] and [
2]), i.e.:
Note that in the case that there is information about who examined each subject i at each time then a different variance parameter could be used to estimate the degree of error made by each examiner. Moreover, different cutpoints could be considered for each time point.
2.3. Conditional Independence Assumptions
The proposed full model is an inhomogeneous hidden Markov model with a continuous state-space that is comprised of Equations (
1)–(
5).
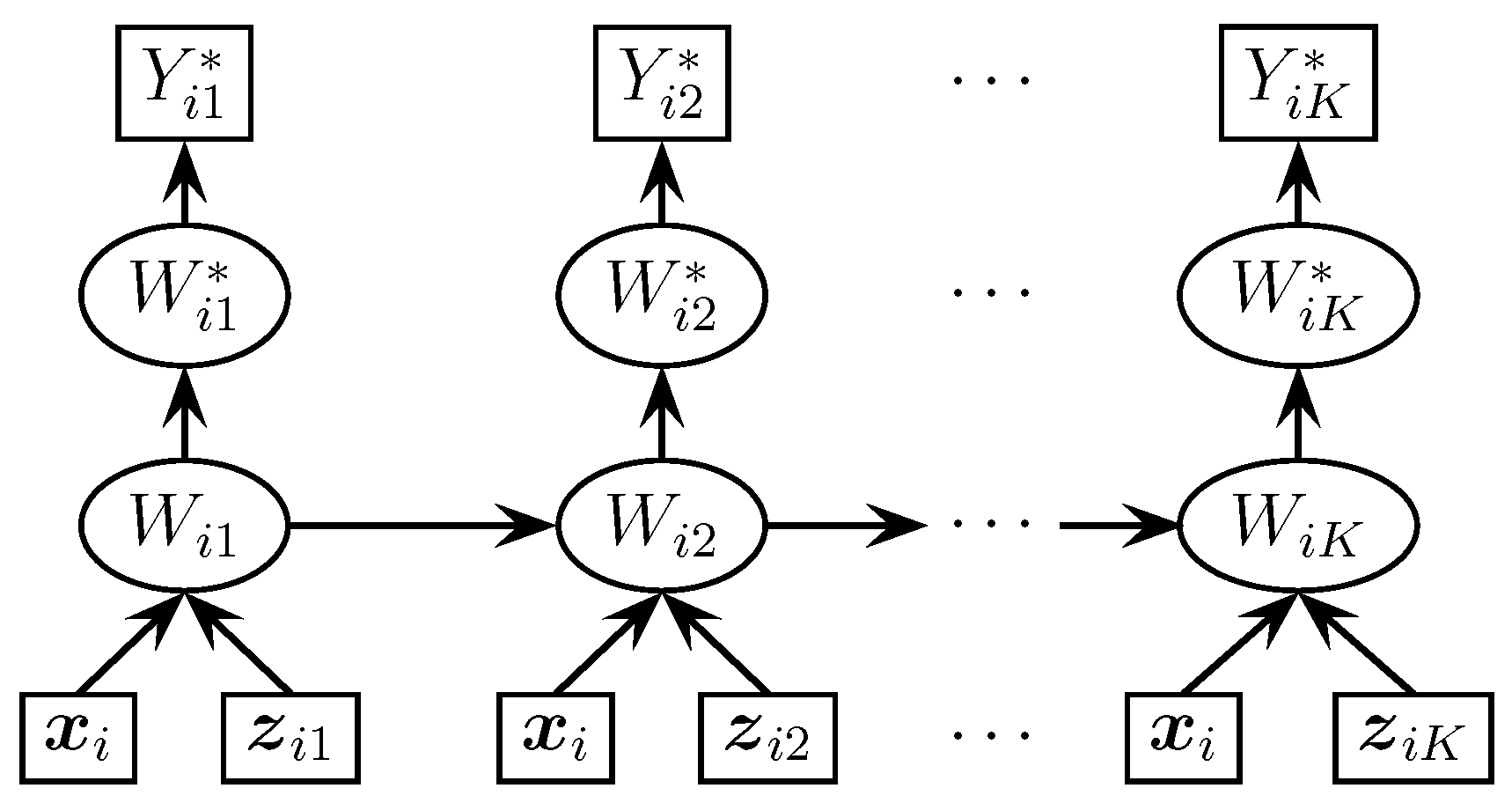
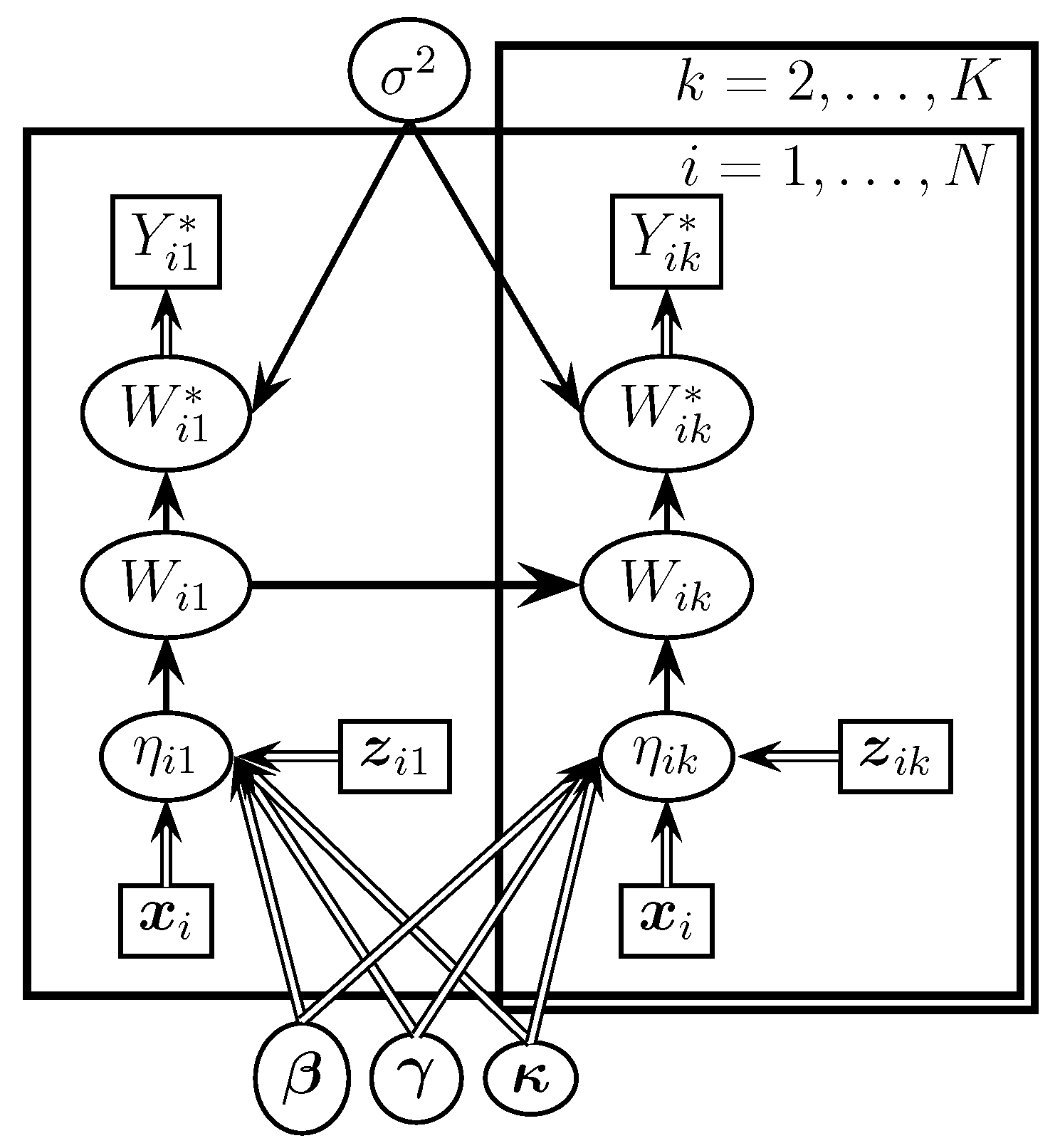
Figure 1 displays the probabilistic graphical representation showing the dependencies among the variables in the proposed model. The usual convention of graphical models is followed.
The process is characterized by the following conditional independence assumptions (see also [
27]):
i.e., the observed ordinal response vectors for each subject are independent given the true unobserved continuous responses and the variance of the measurement error.
, i.e., the distribution of the observed ordinal response vector for a subject only depends on his/her true unobserved continuous response vector and the variance of the measurement error.
i.e., the observed ordinal response for a subject at one time point is independent of the one for the same subject at any other point of time, given the subject’s true unobserved continuous response vector and the measurement error variance.
i.e., the distribution of the observed ordinal response in the kth examination only depends on the subject’s true unobserved continuous response at the same examination and variance of the measurement error.
These conditional independence assumptions lead to distributions that are free of other model parameters. In particular, they are independent of parameters
, and
and they are also independent of the observed variables
and
Note that these assumptions are a natural extension of the usual conditional independence assumptions of the HMM proposed by [
28].
4. Simulation Example
A procedure was implemented to generate one hundred datasets. A set of measurements for
subjects at
time points was simulated. The covariates
and
were generated from uniform distributions,
and
for
, and
and they were vectors of dimension
and
respectively, for subject
i at time point
Linear predictors of Equation (
1) were computed by using
and
The true responses
were generated by Equations (
2) and (3). Now, considering the conditional independence assumptions and
categories, the responses subject to measurement error
were generated by Equation (
4), by using the cutpoints
, and two values for the standard deviation parameter of the measurement error were considered, assuming two different values for the measurement errors that were committed,
(for the first half of the subjects) and
(for the other subjects), defined by the latent continuous variable subject to measurement error
in (
5).
Using the simulation-based procedure previously described, one-hundred datasets with 100 subjects each were generated.
Table 1 shows the average transition rates between stages.
In order to assess the model generalization performance, a cross-validation was considered, splitting datasets into training (75% of the subjects) and testing subsets. Using the training data, the model parameters were estimated, and using the testing data, the classification errors were computed. This was performed for all simulated datasets, and then, the results were averaged.
For the prior distributions, the following were considered:
and
Now, in order to obtain the convergence of the MCMC algorithm, twenty-thousand iterations were considered, with a burn-in of 5000. For each chain, a thinning period of 10 generated values was considered, resulting in a reduced chain of length 2000. The convergence analysis was performed by using the
BOA package [
31].
After applying the MCMC algorithm with the previous specifications, the posterior distribution was estimated.
Table 2 presents the means and standard deviations of the posterior estimates of the regression coefficients and variance parameters based on the 100 generated datasets.
Note that the estimation of the parameters was reasonably well recovered, showing small biases. Moreover, models with measurement errors usually required external information on the parameters to correct the error, which could be given via informative prior distributions. The proposed vague informative prior distributions provided good results, since the model managed to capture the measurement errors of the response variable properly.
In order to measure the goodness-of-fit of the approach, the mean absolute error (MAE) and root mean squared error (RMSE) were considered.
Table 3 shows the means and the standard deviations (between brackets) of the goodness-of-fit criteria obtained with the specified cross-validation scheme. The results showed greater errors between the observed responses and the estimated ones (
,
) than those between the non-decreasing generated responses and the estimated values (
,
).
Note that the parameters of the model could be estimated without using external information about the measurement error parameters, i.e., the approach was able to obtain information from data in order to estimate the parameters related to measurement errors.
5. Aortic Aneurysm Progression
An aortic aneurysm is an abnormal bulge that occurs in the wall of the aorta, which is greater than 1.5 times its normal size [
24]. Aortic aneurysms can occur anywhere in the aorta and may be tube-shaped or rounded. If an aneurysm grows large, it can burst and cause dangerous bleeding or even death. Therefore, once it has been detected, it is very important to perform a proper tracking.
The following analysis as based on longitudinal measurements of the grades of aortic aneurysms, measured by ultrasound examination of the aorta diameter. The dataset
aneur is available in the
R package
msm [
32]. In this dataset, the disease is staged by severity, according to successive ranges of aortic diameter. The data frame contains 4337 rows. Each row corresponds to an ultrasound scan from one of 838 men over 65 years of age. The variables are the following:
ptnum, patient identification number;
age, recipient age at examination (years);
diam, aortic diameter;
stage, stage of aneurysm. The stages represent successive degrees of aneurysm severity, as indicated by the aortic diameter: Stage 1, aneurysm free, less than 30 mm; Stage 2, mild aneurysm, 30–44 mm; Stage 3, moderate aneurysm, 45–54 mm; Stage 4, severe aneurysm, 55 mm and above. These are the stages that are often used to determine the time to the next screen.
The data used in this paper were from 207 men who had more than one screen, specifically, who had a stage greater than 1. The remaining subjects appeared in Stage 1 at the initial screen and were not offered an additional screen, and no longitudinal study could be performed.
Table 4 shows the relative frequencies of the transitions between observed stages at consecutive pairs of times. The measures were subject to error. It can be observed that the data presented decreasing transitions, i.e., decreasing patterns, which were not possible since the disease has a degenerative nature. The measurement errors could be due to the ultrasonography scanners or the screening process.
Prior information was not available for the model parameters; therefore, vague information distributions were considered. Specifically,
and
A total of 50,000 iterations were performed with 20,000 burn-in iterations with a thinning factor of 10. The BOA package [
31] was used to assess the chain convergence. The JAGS code under the R platform was run on a computer with a 2.5GHz Intel Core i7 processor and 16GB 1600 MHz DDR3 RAM memory. The computation time was 3.92 min.
The proposed approach provided information about the progression process through the regression parameter
and about the degree of error made through the standard deviation parameter
Table 5 presents a summary of the estimated posterior values of the regression coefficients associated with the time, the cutpoints of the ordinal categories, and the variances of the measurement errors. This summary includes their corresponding means, medians, standard deviations, and
and
quantiles.
Considering the estimations obtained from the model for all the subjects, the relative frequencies of transitions between stages of the aortic diameter are presented in
Table 6. It can be observed how decreasing patterns did not appear, and only one stage at a time could be increased.
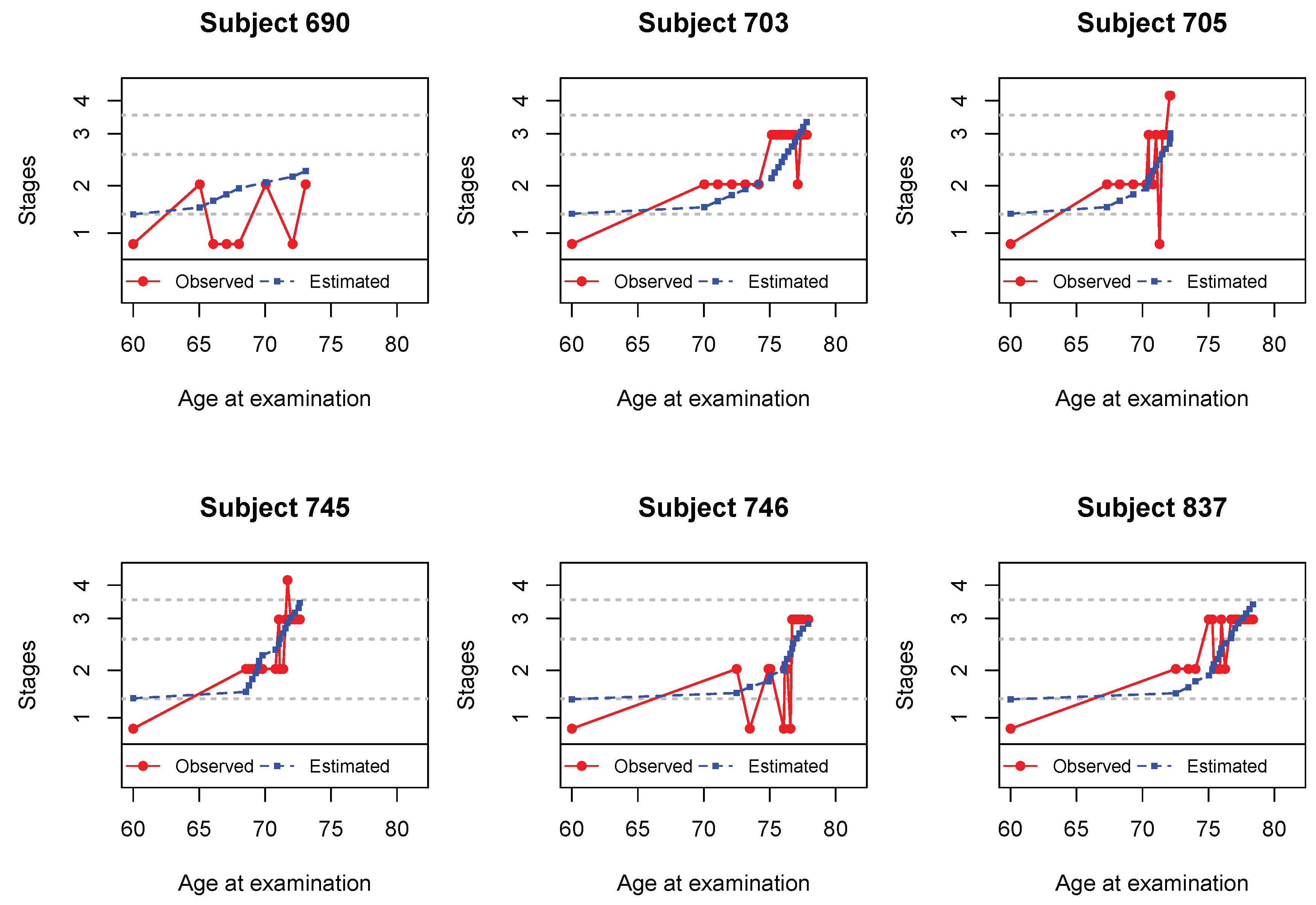
Figure 3 shows the observed and estimated trajectories for six subjects with measurement errors. The estimated dots represent the mean of the estimated true responses with non-decreasing patterns
The corrections performed seem to be in agreement with the dynamic progression of the disease. The observed and estimated stages for these subjects are presented in
Table 7.
A cross-validation scheme was considered to assess the model generalization performance. The 207 subjects were randomly divided into a training set with
(155 subjects) and a testing set with
(52 subjects). The approach was applied to the training set of subjects, and the model parameters were estimated, then applied to the subjects in the testing set, so that the estimated measurements and stages could be calculated. This was repeated 100 times, and the results were averaged.
Table 8 shows the relative frequencies of transitions under this cross-validation scheme.
This cross-validation allowed predicting the fit of the proposed model to hypothetical test data. These predictions only showed non-decreasing patterns, i.e.: subjects in Stage 1 remained in Stage 1 or went to Stage 2; subjects in Stage 2 remained in Stage 2 or went to Stage 3; subjects in Stage 3 remained in Stage 3 or went to Stage 4; and finally, subjects in Stage 4 remained in Stage 4. It can also be observed that from one time to another, no more than one stage was increased. Both non-decreasing patterns and increasing one stage at a time were compatible with the degenerative nature of this disease.
Using all the subjects as training data may have resulted in model overfitting, which is the effect of overtraining a learning algorithm with certain data. Cross-validation provides a better indication of how well a model will perform on unseen data. In this case, the results with cross-validation presented in
Table 8 supported those obtained in
Table 6, since the results were close. In order to quantify this closeness, the average of the differences in the absolute value between the elements in both matrices was considered. This average was 0.0139, which in percentage terms represented 1.39%.
6. Conclusions
An inhomogeneous continuous hidden Markov model was defined, developed, and implemented to address measurement errors in ordinal response and monotonic non-decreasing processes. An efficient MCMC algorithm was derived and tested on a simulation-based experiment and applied to aortic aneurysm data. Although the approach was motivated by the aortic aneurysm progression problem, it is applicable to any monotonic non-decreasing process whose ordinal response variable is subject to measurement errors.
The predominant pathologic feature of abdominal aortic aneurysm is elastin destruction, which leads to an abnormal bulge in the aorta walls. Errors are produced when measuring the diameter of the aorta in the affected area. Some of the measurements show decreasing patterns through time, which are not possible since this disease has a degenerative nature. The proposed approach provided information about the progression process through the regression parameters and about the degree of error made through the standard deviation parameters. The corrections performed seemed to be in agreement with the dynamic progression of the disease.
As a future research line, the approach could be modified to consider other experimental designs such as considering that several examiners recorded the responses or using different ways of measuring. This would imply the inclusion of new parameters in the model, which slightly change the implementation. Moreover, different specifications of the regression parameters or the variance parameters could also be considered to build heterogeneity models. In addition, the proposed model could also be modified to handle monotonic non-increasing responses.








{kind=link}
{kind=link}
{kind=link}