1. Introduction
A statistical hypothesis is a statement of the population distribution. In order to seek evidence for confirming if the hypothesis is true or false, a sample observation needs to be drawn randomly from the population. The major work of this research is, therefore, via selecting a proper statistical method to analyze the collected data and decide whether the null hypothesis under consideration is effective. In classical statistical testing, the sample observations are generally crisp, and all the corresponding testing methods can be well implemented. However, in a practical world, the data are frequently fuzzy due to imprecise measurement and rough description. For example, a survey test for the starting salary of graduated students per year, owing to people unwilling to tell the precise number, the collected sample data are generally fuzzy, and data, such as “roughly $29,000”, “roughly $32,000”, or “less than $40,000”, are obtained. Therefore, the extension of the notion of hypothesis testing to the fuzzy environment would be useful to apply in such a case.
Hypothesis testing methods have been effective for solving problems of fuzzy data. Bellman and Zadeh [
1] first introduced hypothesis-testing models for application in the fuzzy environment. Casals et al. [
2], Son et al. [
3], Römer and Kandel [
4], Lubiano et al. [
5], and Arefi [
6] extended classical statistical hypothesis testing methods to perform hypothesis testing for fuzzy data. Watanabe and Imaizumi [
7] also fuzzified the statistical hypothesis and then performed fuzzy testing. Delgado et al. [
8] considered a Bayesian testing method for fuzzy data. Arnold [
9] considered statistical tests with a continuously distributed test statistic and determined a test to maximize the degree of satisfaction under particular fuzzy requirements. Saade and Schwarzlander [
10] discussed hypothesis testing for hybrid data, which is composed of fuzzy data and crisp data. Grzegorzewski [
11] presented a corresponding fuzzy testing method by using fuzzy confidence intervals considered by Kruse and Meyer [
12]. Filzmoser and Viertl [
13] considered testing hypotheses with fuzzy data by the fuzzy
p-value. Taheri and Arefi [
14] introduced testing fuzzy parametric hypotheses according to a fuzzy test statistic. Wu [
15] developed a testing rule as well as a step-by-step procedure by fuzzy critical values and fuzzy
p-values when assessing process performance. Parchami et al. [
16] presented a method to test hypotheses by comparing a fuzzy
p-value and a fuzzy significance level when there were problems with fuzzy hypotheses and crisp data. Alizadeh et al. [
17] proposed a hypothesis testing based on a likelihood ratio test for fuzzy hypothesis and fuzzy data. Saeidi et al. [
18] considered the problem of testing a hypothesis on the basis of records in a fuzzy environment. Elsherif et al. [
19] proposed an algorithm for testing a hypothesis when both hypotheses and data are fuzzy based on a fuzzy test statistic. Habiger [
20] developed a framework for the randomized
p-value, mid-
p-value and abstract randomized
p-value, and multiple test function. Icen and Bacanli [
21] presented a hypothesis test method for the mean of an inverse Gaussian distribution. In the presented method, confidence intervals by the help of α-cuts are used to obtain a fuzzy test statistic. Yosefi et al. [
22] presented an approach for testing fuzzy hypotheses based on a likelihood ratio test statistic. Parchami et al. [
23] extended one-way ANOVA to the environment with symmetric triangular and normal fuzzy data. Hesamian and Akbari [
24] presented an approach for intuitionistic fuzzy hypotheses by extending the type-I, type-II, power of test, and
p-value. Parchami et al. [
25] presented a minimax approach to the problem of fuzzy hypotheses while data are crisp. Akbari and Hesamian [
26] suggested a degree-based criterion to compare the fuzzy
p-value and a specific significance level for making the decision to accept the null hypothesis or not. Kahraman et al. [
27] developed interval-valued intuitionistic fuzzy confidence intervals for population mean and differences in means of two populations. Haktanir and Kahraman [
28] developed a Z-fuzzy hypothesis testing method. In the developed method, Z-fuzzy numbers are used to capture the vagueness in the sample data, and a Z-fuzzy number is represented by a restriction function that is usually a triangular or trapezoidal fuzzy number. Parchami [
29] applied two R packages “FPV” and “Fuzz.p.value” for the practical hypothesis-test problem for when data/hypotheses are fuzzy.
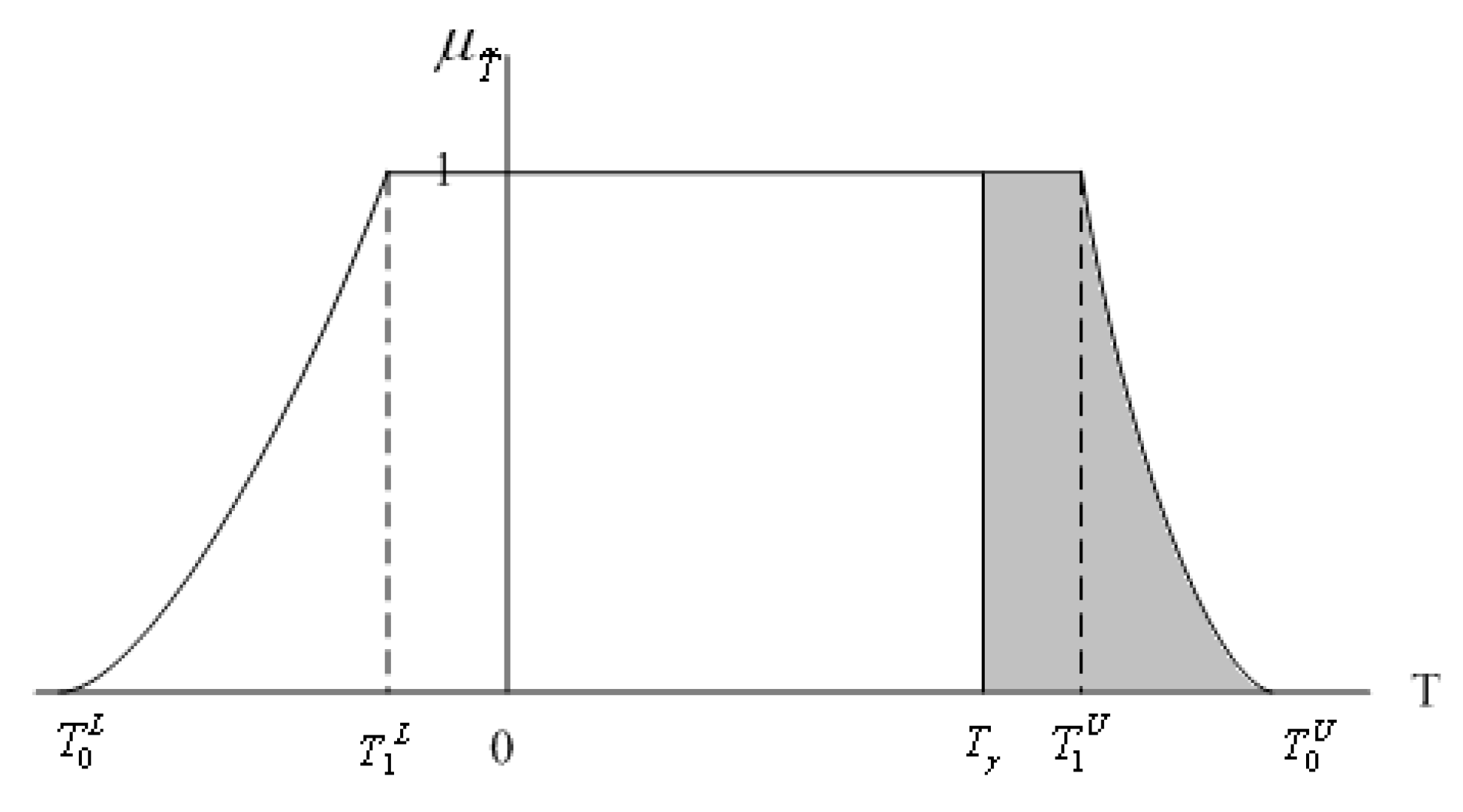
In Theorem 4 of Grzegorzewski [
11], the fuzzy test for
against the alternative
is a function
with the following α-cuts
where
are fuzzy random sample,
is the α-cut of fuzzy confidence interval
for
and
is the α-cut of complement of fuzzy confidence interval
. Grzegorzewski [
11] claims that the membership function of
is
, where
is the membership function value that the parameter value of null hypothesis,
, falling in the fuzzy confidence interval
. For example, we get
= 0.4/0 + 0.6/1 from
Figure 1, and the result may be interpreted as “rather reject
”. Note that, in
Figure 1, Grzegorzewski’s approach uses the information on the right-hand side of the fuzzy confidence interval only. This means the testing method of Grzegorzewski [
11] is simple but may have some spaces to be improved.
In classical statistical hypothesis testing, the sample data are substituted into a proper test statistic, and the critical value for the test statistic is determined under a given significance level, then the rejection region is determined consequently. When the observed value of the test statistic falls in the rejection region, the null hypothesis should be rejected. Otherwise, the null hypothesis should not be rejected. This is so-called binary decision. Intuitively, when data are fuzzy, the fuzzy testing methods should be developed by fuzzifying the corresponding classical statistical testing methods. Since testing the rejection region is a crisp set, and the observed value of test statistic is fuzzy, we can conduct a reasonable testing approach to determine whether the fuzzy test statistic falls in the rejection region. Moreover, the proposed fuzzy testing method should be able to degenerate to the classical statistical testing method with crisp data. Based on these thoughts, the rest of this paper is organized as follows.
Section 2 presents the method to determine whether the fuzzy test statistic falls into the rejection region.
Section 3 presents the testing of the normal population to illustrate the real-life application of the proposed method.
Section 4 gives examples to compare our proposed approach with the testing methods of Grzegorzewski [
11] and Filzmoser and Viertl [
13]. Conclusions and suggestions are drawn in
Section 5.
2. Fuzzy Test Approach
The fuzzy number can be defined as: given a fuzzy set A of the real line , with the membership function satisfies the following conditions:
- (a)
A is normal, i.e., there exists an element , such that .
- (b)
, .
- (c)
is upper semicontinuous.
- (d)
Support (A) is bounded.
Usually, the α-cut is used to analyze the fuzzy number. That is, the set is used to describe fuzzy number A.
The probability distribution of the object,
, belongs to a distribution family
. Assume that the null hypothesis is
and the alternative hypothesis is
, in which
and
are the subsets of
, and
. The problem of the classical hypothesis testing problem is that in a set of random sample
, the observations can be used to determine to reject
(to accept
) or not to reject
. The classical testing method is to calculate the probability of a specific test statistic
(i.e., the function of observations), to conduct the rejection region
C (a crisp set). If the observations of statistic
fall into
C, then reject the null hypothesis
; otherwise, do not reject the null hypothesis
[
30].
When
are fuzzy random data, based on the definitions of Kwakernaak [
31,
32] and Kruse [
33], they may be treated as a fuzzy perception of the usual random sample
(see [
11]), and
is the population distribution of
. Assume that we are interested in testing
against
, and the observed sample data are fuzzy numbers,
. By substituting these data into a test statistic
, we can obtain a fuzzy number
, which are the observations of fuzzy test statistic
. If each membership function of fuzzy number
,
is known, we can obtain the membership function of fuzzy number
,
, by using Zadeh’s extension principle [
34]. Fuzzy number
is the observations of fuzzy test statistic
. Therefore, if
, then the null hypothesis should be rejected. Otherwise, the null hypothesis should not be rejected. Since
is a fuzzy number, it is not clear whether
falls into the rejection region,
C. To solve this problem, Filzmoser and Viertl [
13] introduce the concept of a fuzzy
p-value. Suppose all α-cuts of
are closed interval
, then each α-cut of
corresponds to a α-cut of fuzzy
p-value, which is defined by
for the left-hand sided testing problem,
for the right-hand sided testing problem, and
for the two-sided testing problem.
Given the significance level
for all
and
, the decision of Filzmoser and Viertl [
13] is made according to (1) if
, then reject
and accept
; (2) if
, then accept
and reject
; (3) if
then both
and
are neither accepted nor rejected. Note that we cannot make a certain decision in the third case. In this paper, we define the possibility of
and propose another testing approach, so that the total information of a membership function of test statistic can be used, and a fuzzy decision can be made in any case.
Assuming that a fuzzy set
A of the real line
, the membership function of
A is
, and Zadeh [
35] defines that the probability of fuzzy set A is
where
P is the probability measure of
Y on real axis
. Based on Equation (2), we can define:
Definition 1. The possibility of the value of the fuzzy test statistic,, falling in the rejection region. C is the ratio of probability ofto the probability ofin C, i.e.,= 0, indicates that the possibility of rejectingis zero, then we should not reject.= 1, indicates that the possibility of rejectingis 100%, then we should reject. If 0 << 1, this indicates that the possibility of rejectingis, then we should rejectwith degree of conviction. Hence, a fuzzy decision rule is formulated. If a decision maker needs a crisp answer to know whethershould be rejected or not, the manager can use a random mechanism to transfer the fuzzy decision rule to the binary decision rule. For example, the manager can randomly draw a random numberin [0, 1]. If, thenis rejected. If, thenis not to be rejected. Consequently, we have a decision rule that is analogous to that of a classical random test. When data reduce to crisp, the membership function of
is
Then, the denominator of Equation (3) is zero, which means that Equation (3) is meaningless. However, since is crisp, the possibility of is also crisp. That is, if , then ; if , then . This is identical to the classical testing method.
3. Fuzzy Testing of Hypotheses with Fuzzy Data
Suppose the sample data are fuzzy numbers
. According to
Section 2, by substituting these sample data into test statistic
, the value
of a fuzzy test statistic
becomes a fuzzy number. If every membership function of fuzzy number
,
is known, we can obtain the membership function of fuzzy number
,
, by using Zadeh’s extension principle [
34].
Represent the
α-cuts of
as
where
X is the crisp universal set on which
is defined. It is very difficult to deduce the exact membership function
of
because the function relationship may be nonlinear. The approximately membership function
can be derived by the approaches of Liu and Kao [
36]. Let
then
is the α-cuts of
.
When all fuzzy data reduce to crisp values, Equation (5a,b) become identical and
reduce to
in the classical model. Using Zadeh’s extension principle [
34], the membership function
may be constructed as
where
L(
t) and
R(
t) are the left and right shape functions of
, respectively.
Suppose
against
is to be tested and the rejection region is
.
Figure 2 describes one of the relationships between the membership function
and rejection region. The probability of the fuzzy test statistic
, based on Equations (2) and (6), is defined as,
where
f(
t) denotes the probability density function of test statistic
T. In
Figure 2, based on Equations (3), (6), and (7), the possibility
can be defined as,
The right-sided test involves five different types, as shown in
Figure 3, where the crisp set
represents the rejection region. Based on Equations (2), (3), (6), and (7), the possibility
in
Figure 3 are shown in
Table 1.
Similarly, the possibility
can be calculated for the left-sided test and two-sided test.
Figure 4 shows the five different types of the left-sided test, where the rejection region is
. The definition of possibility
is shown in
Table 2.
The two-sided test involves fifteen different types of membership functions of
, as shown in
Figure 5,
Figure 6 and
Figure 7, where the crisp set
is the rejection region. The definition of possibility
is shown in
Table 3.
The numerical method is therefore applied to determine the approximate values of . As an illustration, we consider some fuzzy testing problems for the normal population with fuzzy data.
3.1. Fuzzy Test of Mean with Known Population Variance
3.1.1. Single Normal Population with Known Population Variance
The mean of a normal population in classical tests generally assumes that the observations are crisp. Suppose that the population variance is known; the test statistic for the null hypothesis about the population mean,
, is calculated as,
for a normal population, where
,
n, and
are the sample mean, sample size, and the standard deviation of the population, respectively.
When measured imprecisely, the test statistic using fuzzy data becomes
The exact membership function of a fuzzy test statistic
can be derived, since the functional relationship between
and
is linear. When all the observations
are trapezoidal fuzzy numbers, the α-cuts of
can be represented as
. Let
then
is the
α-cuts of
. Equations (11a) and (11b) are a pair of linear functions with bound constraints. The membership function,
, is constructed as,
where
and
.
is also a trapezoidal fuzzy number defined as
, since the function relationship between
and
is linear. The trapezoidal membership function
is shown in
Figure 8.
Figure 9 shows the right-sided test for
under fuzzy data. The probability associated with
, based on Equations (2), (3), and (12), is defined as
where
is the probability density function of a standard normal distribution
Z. In
Figure 9, the possibility
is defined as
.
3.1.2. Two Normal Populations with Known Population Variances
This approach can also be applied in a testing hypothesis concerning the difference between two normal population means. Assume the two population variances are known. The classical test statistic of
is calculated as,
for two independent normal populations. Without loss of generality, assume all data (
and
) are trapezoidal fuzzy numbers for two independent normal populations with fuzzy data. Equation (14) for calculating the test statistic using fuzzy data becomes,
Similar to the aforementioned concept, the exact membership function
of
can be derived. The
α-cuts of
and
are represented as,
where
and
are the membership functions of
and
, respectively. Let
where
,
,
and
. When all data are crisp values, Equation (16a,b) become identical and reduce to Equation (14).
3.2. Fuzzy Test of Mean with Unknown Population Variance
3.2.1. Single Normal Population with Unknown Population Variance
The same concept can be applied to cases of an unknown population variance for tests of the mean for a normal population. In the classical statistical test procedure, suppose
and
S represent the mean and the standard deviation of the sample, respectively. If the null hypothesis
is true, then the test statistic
has a t distribution with
degrees of freedom when the population is normal.
When the observations are fuzzy, a natural test statistic is obtained by substituting
for
, in Equation (17), and the fuzzy test statistic becomes,
From Equation (18), the function relationship between
and
is nonlinear. Deducing the exact membership function
is nearly impossible since Equation (18) includes quadratic terms of the fuzzy observations. The lower and upper bounds of α-cuts of fuzzy observations,
and
, are calculated. Let
then
is the α-cuts of
.
is a pair of nonlinear functions with bounded constraints. We can obtain the membership function of fuzzy number
,
, by using Zadeh’s extension principle [
34]. When all fuzzy data reduce to crisp values, Equations (19a) and (19b) become identical and reduce to Equation (17) in the classical model.
3.2.2. Two Normal Populations with Unknown but Equal Population Variances
When the two normal population variances are unknown but equal, the test statistic for the null hypothesis about the difference between the two population means,
, is determined to be
has a t distribution with
degrees of freedom, where
represents the pooled sample variance, which is defined as
When the observations are fuzzy, a natural test statistic substitutes
for
, which is defined as,
Accordingly, Equation (20), for calculating the test statistic when using fuzzy data, becomes,
From Equation (21), the test statistic is also a fuzzy number. Let
then
is the α-cuts of
. When all fuzzy data reduce to crisp values, Equations (22a) and (22b) become identical and reduce to Equation (20) in the classical model. The construction of the membership function
and the fuzzy test procedure are the same as those for a single normal population with unknown population variance.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}