1. Introduction
Many disciplines such as Marketing, Tourism, Engineering, Health Economics or Medical Care address the problem of choosing the optimal choice from a set of alternatives which can be assessed regarding multiple criteria through several ordered qualitative scales (
OQSs). Likewise, in the framework of decision-making problems, some situations require that experts express their assessments taking into account their knowledge or experience by means of specific OQSs formed by linguistic terms (see Delgado et al. [
1], Herrera and Herrera-Viedma [
2], Herrera et al. [
3] and de Andrés et al. [
4], among others).
The concept of linguistic term was introduced by Zadeh [
5,
6,
7] when he defined the concept of linguistic variable as those variables whose values are words or terms from natural or artificial languages. For example, “ugly”, “fair” and “beautiful” could be linguistic terms for a linguistic variable Aesthetics, as these are not numerical values.
The use of linguistic assessments coming from of different OQSs is not infrequent. For instance, the Statistical office of the European Union (Eurostat) uses different OQSs in the EU Statistics on Income and Living Conditions (EU-SILC). In its questionnaires we can easily find OQSs formed by different linguistic terms. For instance, in the question Q19 (HS140), Eurostat uses the following 3-term OQS: {“a heavy burden”, “somewhat a burden”, “not burden at all”} for asking households about the financial burden of total housing cost and in the question Q26 (HS120), a 5-term OQS: {“with great difficulty”, “with difficulty”, “with some difficulty”, “fairly easily”, “easily”, “’very easily”} for analyzing the households’ difficulties to make ends meet. On the other hand, in clinical diagnosis is also needed to aggregate ordinal information from different OQSs. The Hospital Anxiety and Depression Scale (HADS) developed by Zigmond and Snaith [
8] also uses different scales for measuring depression severity in primary care. Some of these scales are: {“very seldom”, “not often”, “sometimes”, “often”}, {“not at all”, “not often”, “usually", “definitely”}, or {“only occasionally”, “from time to time, but not too often”, “a lot of the time”, “a great deal of the time”}.
OQSs formed by linguistic terms are appropriate tools for collecting the agents’ opinions and judgments in situation of vagueness and imprecision. People are more comfortable using words rather than numbers to describe probabilities. In this sense, authors such as Zimmer [
9,
10] and Windschitl and Wells [
11] point out that words are more natural than numbers, since verbal expressions of uncertainty are easily understood and, besides, they emerged long before the development of probability. On the other hand, agents’ opinions and judgments are generally imprecise, and therefore it would be misleading to represent them by precise numerical values (see Beyth-Marom [
12], Wallsten et al. [
13] and Teigen [
14], among others).
A common practice when dealing with OQSs is to start by converting the qualitative information into numbers by assigning numerical values to each linguistic term of the scale. However, if done prematurely and arbitrarily, numerical codifications can produce negative effects. The first is concerned with the validity of translating an OQS into a numerical form. That practice introduces properties that were not present in the original linguistic scale and imposes more informative content on the qualitative scale. For example, when the numerical codifications are equidistant, it is possible to assume that there are the same differences between terms of scales. On the other hand, ordinal scales establish an ordered relationship between the objects being measured. In these scales, numerical codifications do not provide information on the magnitude of the differences between the terms; they only indicate different levels of the attribute or characteristics. Thus, in the ordinal scales, the numerical values obtained from measures of location and dispersion, such as arithmetic mean or variance are not meaningful, and they can lead to misinterpretation of results (see Merbitz et al. [
15], Blair and Lacy [
16], Franceschini [
17], Bashkansky and Gadrich [
18] and Gadrich et al. [
19], among others).
In Franceschini et al. [
20], it is shown that the arithmetic mean can distort the result obtained from ordinal data. To illustrate this issue, the authors consider the results of the visual control for a sample of 30 corks. The corks are assessed by the following 5-term OQS: {“reject”, “poor quality”, “medium quality”, “good quality”, “excellent quality”}. Initially, they assume that the scale is equally spaced and assign the numerical codification 1, 2, 3, 4, 5 to the corresponding linguistic terms. Considering this numerical codification, the arithmetic mean of the sample (3.7) indicates that the mean of the sample would be between “medium quality” and “good quality”. Afterwards, they consider different proximities between the terms of the scale and suggest a new numerical codification 1, 3, 9, 27, 81. In this case, the new arithmetic mean (32.9) provides a different result: the mean of the sample would be between “good quality” and “excellent quality”. Likewise, Stevens [
21] pointed out that means and standard deviations ought not to be used with ordinal scales, since these statistics imply a knowing more than the relative rank-order data. In particular, the use of means and standard deviations computed on an ordinal scale is not reasonable when the consecutive intervals on the scale are unequal in size.
To overcome these issues, several methods have been proposed in the literature for managing linguistic information. For instance, those based on fuzzy techniques (see Herrera and Martínez [
22], Herrera et al. [
23], Wang [
24], Liu and Jin [
25] and Xiao et al. [
26], among others), computing with words (see Zadeh [
5,
6,
7,
27], Li et al. [
28], and Herrera et al. [
29], among others) or dominance criteria and cumulative distribution functions (see Franceschini et al. [
20,
30] and Bashkansky-Gadrich [
18]). However, the above procedures present some limitations. They do not consider how agents perceive the proximities between the linguistic terms of OQSs and, besides, some of them imply a direct conversion into cardinal values.
In general, OQSs are devised as balanced (they are formed by a fixed neutral central linguistic term and the rest of the terms are symmetrically distributed) and uniform (all the proximities between consecutive linguistic terms are considered identical). Nevertheless, in some cases the nature and the semantics of linguistic terms can be such that agents appreciate different proximities between the terms of the scale, i.e., they perceive the OQS as non-uniform. For instance, the OQS used in the HADS can be understood as non-uniform if agents perceive that “usually” is closer to “definitely” than to “not often”.
In the context of OQSs that are not uniformly and symmetrically distributed, Herrera et al. [
23] developed a methodology to deal with unbalanced linguistic information. Their methodology is based on the concept of linguistic hierarchy and on the 2-tuple fuzzy linguistic representation model. This succeeds in allowing non-uniform scales in the 2-tuple fuzzy linguistic representation model, which is still equivalent to work with numerical values, as pointed out by García-Lapresta [
31], requiring a qualitative to cardinal transformation at the outset.
In this paper, to deal with non-uniform OQSs in a way that postpones as much as possible the need to use numbers, we use ordinal proximity measures, introduced by García-Lapresta and Pérez-Román [
32]. The concept of ordinal proximity measure takes into account psychological proximities between linguistic terms in a purely ordinal way by means of ordinal degrees. It is important to mention that these ordinal degrees are only abstract objects that represent different degrees of proximity. Likewise, we use the notion of metrizable ordinal proximity measure, which behaves as if the ordinal comparisons between the terms of the OQS were managed through a linear metric (see García-Lapresta et al. [
33]). These concepts were recently implemented in some decision-making procedures where alternatives are always assessed through the same OQS. García-Lapresta and Pérez-Román [
34] introduce a voting system that ranks the alternatives taking into account the medians of the ordinal degrees of proximity between the obtained individual assessments and the highest linguistic term of the scale. Later, García-Lapresta and González del Pozo [
35] presented an ordinal multi-criteria decision-making (MCDM) procedure under uncertainty, extending the previous procedure to a multi-criteria setting, in which agents are allowed to assign two consecutive terms of the OQS to each alternative when they hesitate.
The aim of this paper is to propose a new MCDM procedure for managing ordinal information coming from several OQSs. This new procedure allows that each criterion uses a different OQS to evaluate the alternatives, thus making it more widely applicable. These OQSs can be considered to be non-uniform and can even be formed with a different number of linguistic terms for different criteria. The MCDM procedure yields a ranking of the alternatives based on an intuitive principle of compensation between advantages and disadvantages of each alternative in comparison with its opponents. To respect the ordinal information coming from the OQSs, the MCDM procedure follows an ordinal approach by means of the concept of ordinal proximity measure that avoid assigning arbitrary numerical codifications to the linguistic terms of the scales. In the proposed procedure, we also provide and analyze a homogenization process for managing the ordinal degrees of proximity from different OQSs.
The rest of this paper is organized as follows.
Section 2 briefly introduces ordinal proximity measures.
Section 3 presents a new MCDM procedure for ranking a set of alternatives assessed through a specific OQS for each criterion.
Section 4 includes an example that illustrates how the proposed procedure works and we introduce a stochastic analysis to assess the robustness of the conclusions obtained. Likewise, we also include a comparison of our procedure with the methods SMAA-O (see Lahdelma [
36]) and ZAPROS III (see Larichev [
37]) that belongs to the family of verbal decision-making analysis. Finally,
Section 5 presents some concluding remarks.
2. Preliminaries
Let us consider an OQS , with , arranged in ascending order, .
We now recall the concept of ordinal proximity measure, introduced by García-Lapresta and Pérez-Román [
32]. An ordinal proximity measure is a mapping that assigns an ordinal degree of proximity to each pair of linguistic terms of an OQS
. These ordinal degrees of proximity belong to a linear order
, with
, being
and
the maximum and the minimum degrees of proximity, respectively. The elements of
are not numbers and they only represent different degrees of proximity.
Definition 1 ([
32])
. An ordinal proximity measure (OPM) on with values in Δ
is a mapping , where represents the degree of proximity between and , satisfying the following conditions:- 1.
Exhaustiveness: For every , there exist such that .
- 2.
Symmetry: , for all .
- 3.
Maximum proximity: , for all .
- 4.
Monotonicity: and , for all such that .
Every OPM can be represented by a
symmetric matrix with coefficients in
, where the elements in the main diagonal are
,
:
This matrix is called proximity matrix associated with .
A prominent class of OPMs, introduced by García-Lapresta et al. [
33], is the one of metrizable OPMs which is based on linear metrics on OQSs.
Definition 2 ([
33])
. A linear metric on is a mapping satisfying the following conditions for all :- 1.
Positiveness: .
- 2.
Identity of indiscernibles: .
- 3.
Symmetry: .
- 4.
Linearity: whenever .
Definition 3 ([
33])
. An OPM is metrizable if there exists a linear metric such that , for all . Consequently, an OPM is metrizable if the ordinal comparisons between linguistic terms were made as if the agent had in mind a linear metric.
For
there are three OPMs and all of them are metrizable. However, when
the complexity of constructing OPMs increases. In these cases, we can apply an algorithm that generates metrizable OPMs (see García-Lapresta et al. [
33]). To do that, the algorithm is based on appropriate sequences of questions whose answers lead to metrizable OPMs. For
there are 51 OPMs, but only 25 of them are metrizable.
3. The MCDM Procedure
In this section, we present an MCDM procedure for ranking a set of alternatives
, with
that are assessed by a group of agents
, with
, regarding a set of different criteria
. MCDM authors have proposed many methods for determining criteria weights (see, for instance, Solymosi and Dombi [
38], Borcherding et al. [
39], Diakoulaki et al. [
40], Marichal and Roubens [
41], Figueira and Roy [
42], and Kao [
43], among others). To focus on the main ideas in this contribution, we assume that the weights are exogenously given and they are collected in a weighting vector
, with
. This is a common situation for evaluation panels and competition juries in which the weights are given in the regulations. Nevertheless, the procedure can easily be adapted to the case in which each agent uses different weights.
Agents assess the alternatives through a specific OQS for each criterion , , equipped with a metrizable OPM , where . To focus on the main ideas in this contribution, we assume that all agents use the same scale and the same OPMs (one for each criterion). Again, this assumption can easily be dropped. Assuming the agents have the same OPMs means that they need to agree on the ordinal proximity levels before making their assessments of the alternatives, which is an essential step to ensure they attach the same meaning to the possible grades in the scale.
The proposed procedure is related to the Copeland rule (see Copeland [
44]) and to the net flow method used in PROMETHEE II (see Brans [
45], Brans and Vincke [
46], Bouyssou [
47] and Brans and De Smet [
48]). The Copeland rule is a voting system that ranks order the alternatives taking into account the number of pairwise victories minus the number of pairwise defeats. The method PROMETHEE II generates a ranking considering positive and negative flows for each alternative according to the given criteria weights. The positive flow shows how much an alternative dominates over the others (the higher the positive flow, the better the alternative). The negative flow shows the dominance of all the other alternatives over the considered one (the smaller the negative flow, the better the alternative).
The assessments provided by the agents to the alternatives with respect to the criterion
are collected in a
profile, a matrix of
m rows and
n columns of linguistic terms, where
is the assessment given by the agent
a to the alternative
regarding the criterion
:
3.1. The Procedure
To rank the alternatives, the procedure is divided into the following steps:
Gather the agents’ assessments in the corresponding profiles .
Calculate, for every pair of alternatives , the ordinal degrees of proximity between the assessments given by the agents, , for all and .
Homogenize the ordinal degrees of proximity coming from the metrizable OPMs considered in the different criteria by means of a mapping . Such mapping must satisfy the following conditions for every :
Min-normalization: .
Max-normalization: .
Strict monotonicity: , .
Assign a score to the alternatives, through the mapping
defined as
Following the approaches of the Copeland rule and the PROMETHEE II,
is divided into two parts. The first part of Equation (
1) considers, for the criterion
k and for the agent
a, the victories of the linguistic assessment
over the rest of assessments
(the higher, the better), and the second part the defeats of the linguistic assessment
over the rest of assessments
(the lower, the better).
In Equation (
1),
measures for the criterion
k and for the agent
a, the proximity between the assessments
and
. By means of these ordinal degrees of proximity,
considers the scope of victories and defeats. The mapping
converts the ordinal degrees of proximity to the interval [0,1]. Then, the final score is calculated multiplying the obtained results by the corresponding weights.
Order the alternatives through the weak order ⪰ on
X:
We now enumerate some properties that the proposed procedure satisfies:
Anonymity: All agents are treated equally by the procedure.
Neutrality: All alternatives are treated equally by the procedure.
Monotonicity: If an agent improves the evaluation of an alternative on some criterion, all else remaining equal, then its score increases.
Cancelation: In the uniform case, when two agents a and b increase and decrease at the same time their assessments, in such a way that agent a increases the assessment to and agent b decreases the assessment to , for some alternative and criterion , then does not change.
Definition 4. Given a metrizable OPM , ρ preserves OPM linearity if , for all such that .
Remark 1. If ρ preserves OPM linearity, then one can interpret the proximities between levels as the difference of proximities between such levels and the worst performance as follows: Moreover, this allows rewriting Equation (1) as: Since the rightmost summation is a constant that does not depend on , if preserves OPM linearity then its overall evaluation depends only on Remark 2. The simplest mapping considers that consecutive qualitative levels on a given criterion always represent the same difference, as follows: This mapping preserves OPM linearity if the OPM is uniform, but not in the general case.
3.2. Linear Programming Formulation
A linear program can be solved to obtain a
mapping that preserves OPM linearity. The following formulation does so by maximizing the minimum difference between consecutive levels, i.e.,
This can be formulated as a linear program by introducing an auxiliary variable .
To simplify notation, let denote . The main decision variables are the variables corresponding to the consecutive levels, , ,…, , plus the auxiliary variable .
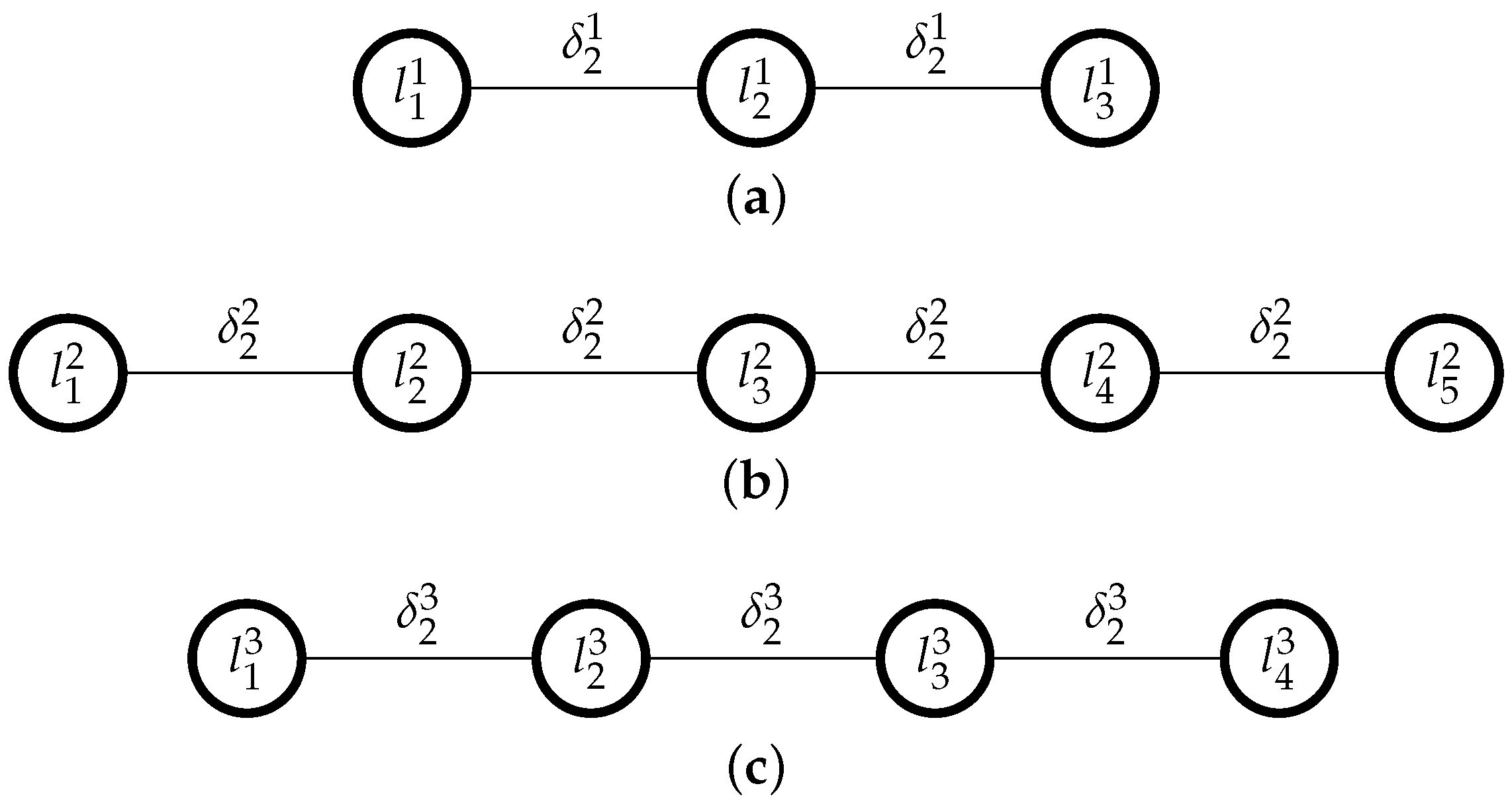
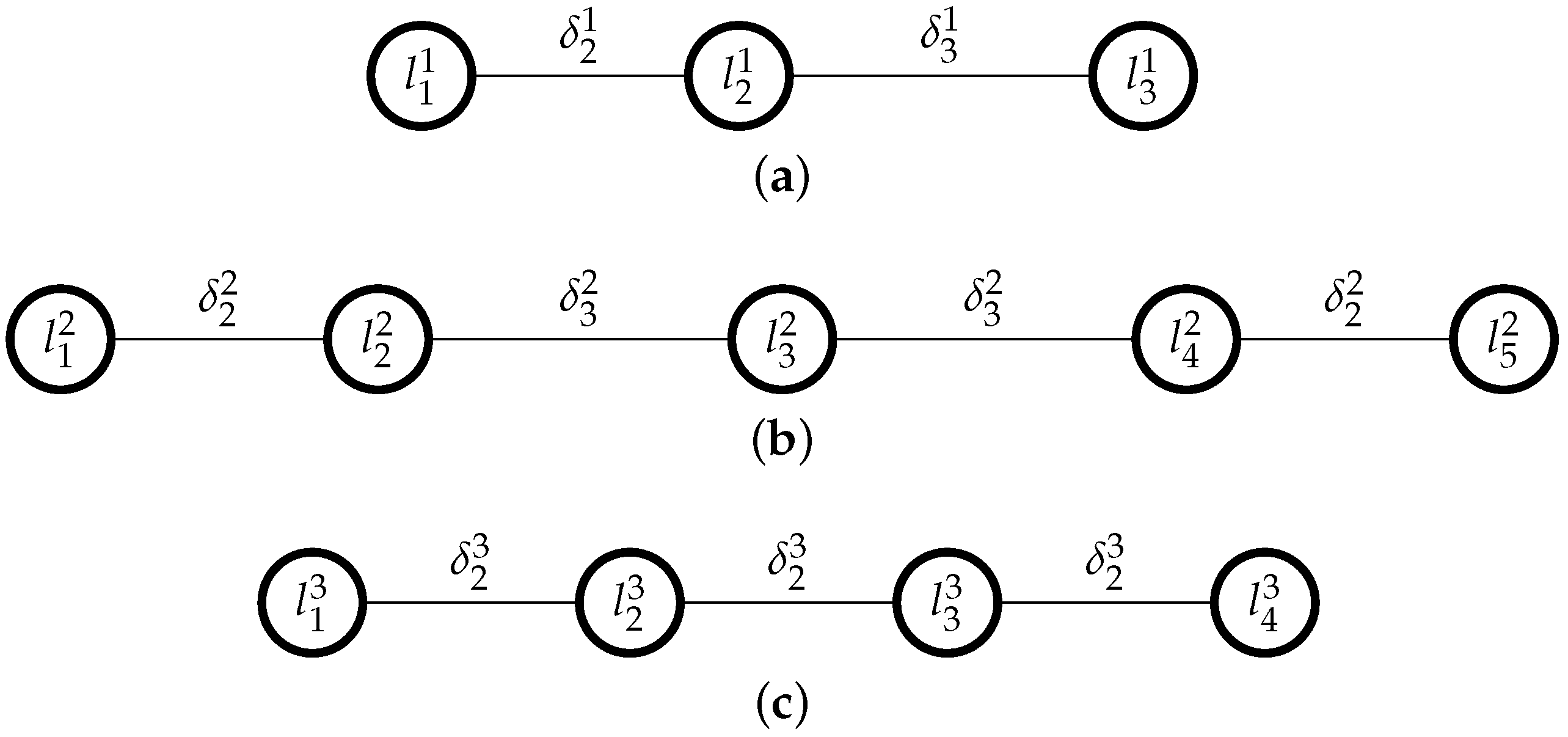
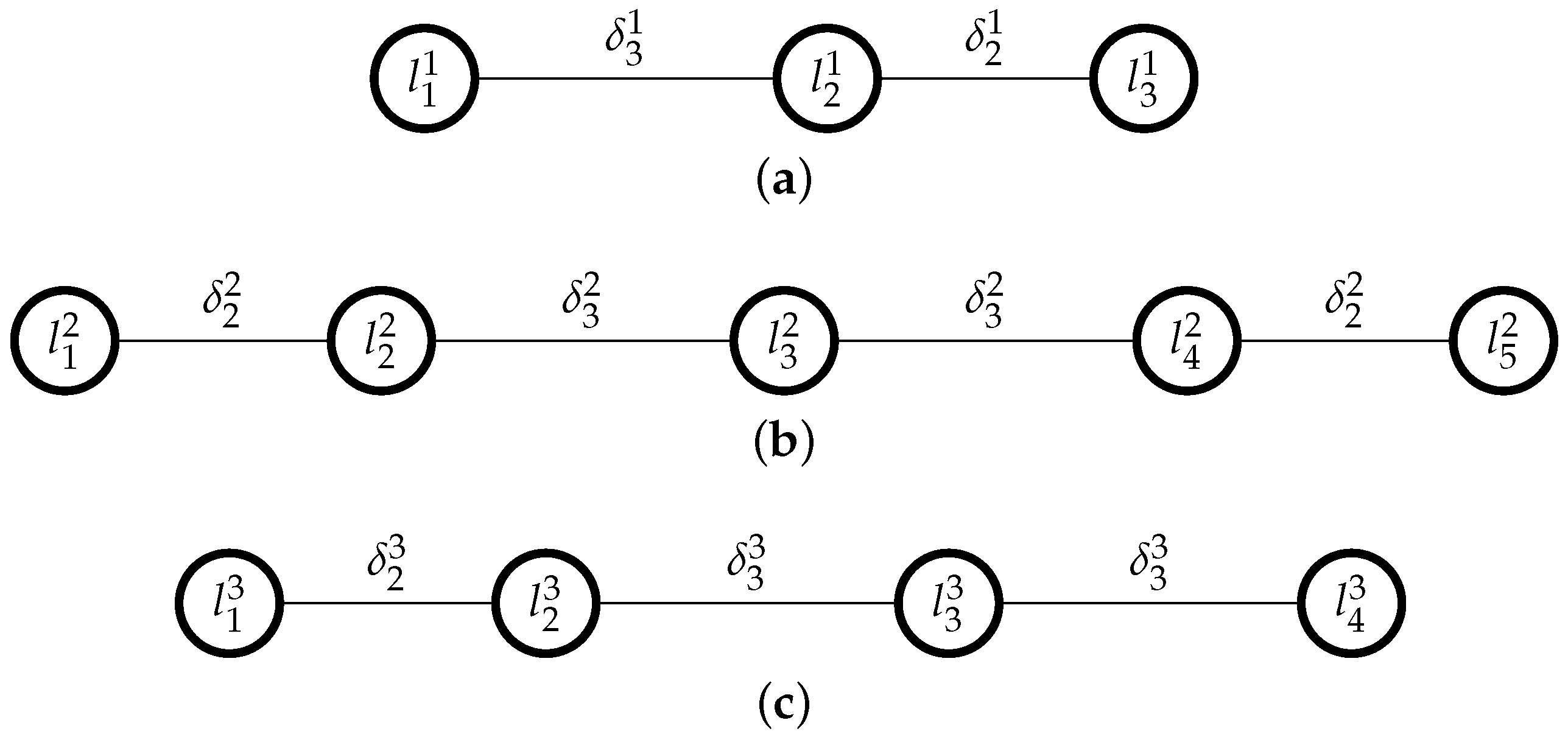
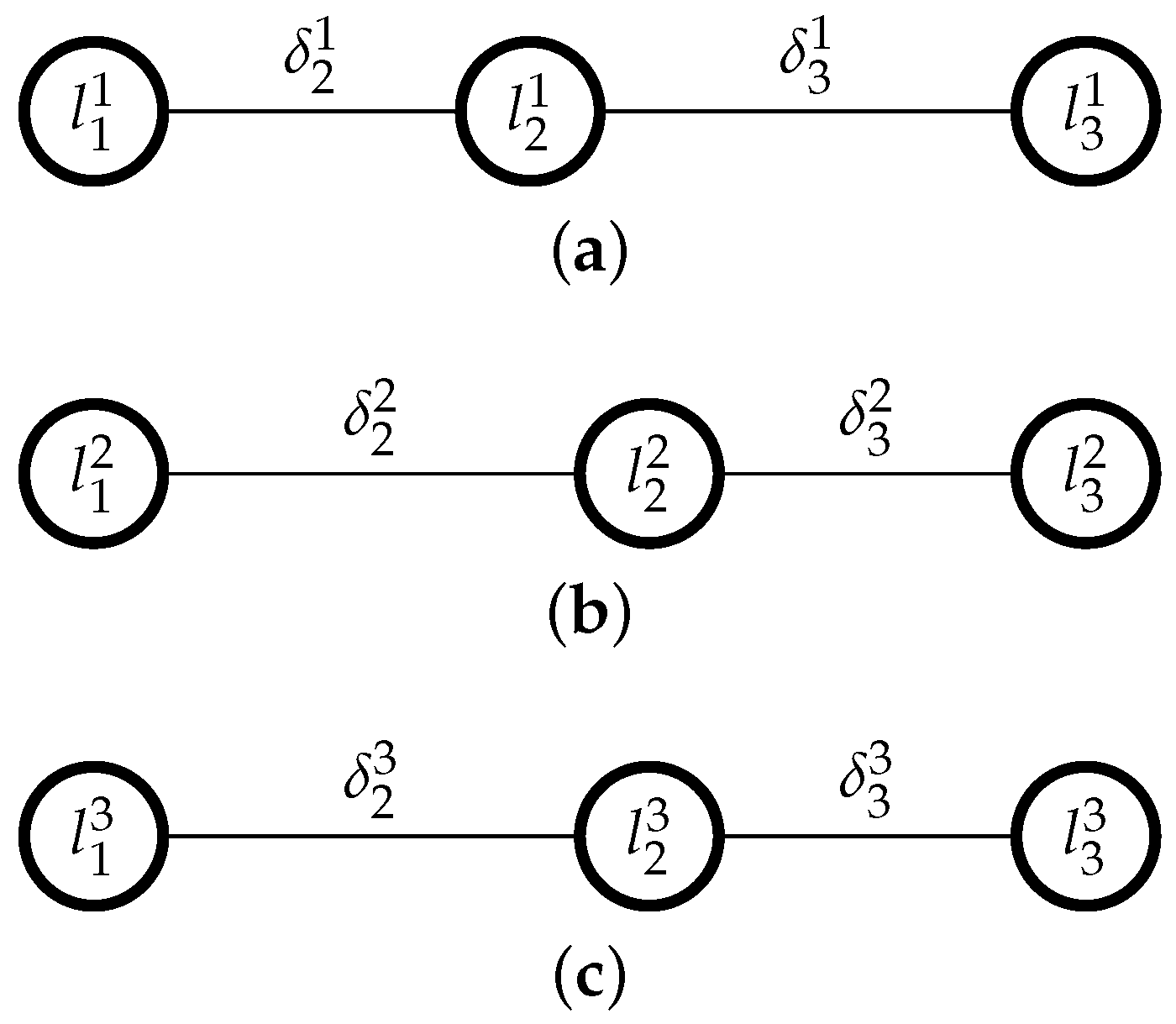
In this linear program, the first group of constraints, [C1], indicates that every subset of three consecutive levels , , must be such that ; a second group of constraints, [C2], indicates that every subset of four consecutive levels , , , must be such that , and so on, until constraint [C3]. These constraints together ensure linearity. For instance, if a scale has 5 linguistic terms , then these linearity constraints would be: , , ([C1]), , ([C2]), and ([C3]).
Then, constraints [C4-C6] are needed to ensure the monotonicity of the mapping. Constraint [C4] can be used to reduce the number of variables in the linear program. Finally, constraint [C7] requires the mapping to be positive.
Proposition 1. If an OPM is uniform, then Equation (4) is an optimal solution for the above linear program. Proof Given several levels
, a uniform OPM requires
proximity degrees and Equation (
4) yields
,
,
,…,
. In such OPMs,
,
, etc., which by constraint [C4] implies
, etc. Then, constraint [C3] implies
, which means that the solution provided by Equation (
4) is the only one satisfying these constraints.
Moreover,
and
, hence the constraints [C1] are satisfied. Similarly, all other linearity constraints [C2] until [C3] are naturally satisfied. Therefore, Equation (
4) is a feasible solution to the linear program and, since it is the only feasible solution, it is also optimal. □
3.3. Stochastic Analysis
As mentioned before, the
mapping can be obtained by a formula (e.g., Equation (
4), which considers equal differences between any consecutive qualitative levels on a given criterion), or it can result from an optimization process enforcing linearity. However, in general there can be multiple other
mappings preserving linearity. To analyze the results corresponding to the multiple
mappings that preserve linearity it is possible to follow a stochastic approach, inspired by the Stochastic Multi-attribute Acceptability Analysis (SMAA) methods [
36,
49,
50,
51].
In the stochastic analysis, one samples randomly many mappings, and then results are computed for each of these mappings. This allows obtaining statistics about the results, such as:
The rank acceptability indices (for each alternative , for each ranking position p), which is the probability (in terms or relative frequency) that alternative is ranked in position p ().
The pairwise winning indices (for each pair of alternatives ), which is the probability (in terms or relative frequency) that alternative is ranked better than ().
To generate a random
mapping preserving linearity it is sufficient to generate randomly the
values corresponding to the differences in the consecutive levels
,
,…,
. In one extreme case, when the consecutive levels are all different, the number of random numbers to generate is equal to
. In the other extreme case, when the consecutive levels are all equal, no random number needs to be generated. The needed random numbers can be sorted from lowest to highest and assigned in this order to the
, from the lowest to the highest corresponding
. When needed, a hit-and-run approach [
50] can be followed to exclude cases in which the
values obtained by summing the obtained numbers do not respect the ordinal relation between the remaining
. For the cases in which the ordinal relations are respected, the generated random values can be divided by the sum
to normalize this sum to unity.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}