Abstract
This paper deals with the Tikhonov regularization for nonlinear ill-posed operator equations in Hilbert scales with oversmoothing penalties. One focus is on the application of the discrepancy principle for choosing the regularization parameter and its consequences. Numerical case studies are performed in order to complement analytical results concerning the oversmoothing situation. For example, case studies are presented for exact solutions of Hölder type smoothness with a low Hölder exponent. Moreover, the regularization parameter choice using the discrepancy principle, for which rate results are proven in the oversmoothing case in in reference (Hofmann, B.; Mathé, P. Inverse Probl. 2018, 34, 015007) is compared to Hölder type a priori choices. On the other hand, well-known analytical results on the existence and convergence of regularized solutions are summarized and partially augmented. In particular, a sketch for a novel proof to derive Hölder convergence rates in the case of oversmoothing penalties is given, extending ideas from in reference (Hofmann, B.; Plato, R. ETNA. 2020, 93).
1. Introduction
This paper tries to complement the theory and practice of Tikhonov regularization with oversmoothing penalties for the stable approximate solution of nonlinear ill-posed problems in a Hilbert scale setting. Thus, we consider the operator equation
with a nonlinear forward operator , possessing the domain and mapping between the infinite dimensional real Hilbert spaces X and Y. In this context, and denote the norms in X and Y, respectively. Throughout the paper, let be a solution to Equation (1) for a given right-hand side y. We restrict our considerations to problems that are locally ill-posed at . This means that the replacement of the exact right-hand side y by noisy data , obeying the deterministic noise model
with noise level , may lead to significant errors in the solution of Equation (1) measured by the X-norm, even if tends to zero (cf. ([1], Def. 2) for details).
For finding approximate solutions, we apply a Hilbert scale setting, where the densely defined, unbounded and self-adjoint linear operator with domain generates the Hilbert scale. This operator is assumed to be strictly positive such that we have for some
In this sense, we exploit the Hilbert scale generated by B with , , and with corresponding norms .
As approximate solutions to , we use Tikhonov-regularized solutions that are minimizers of the extremal problem
where is the regularization parameter and characterizes the misfit or fidelity term. The penalty functional in the Tikhonov functional is adjusted to the level one of Hilbert scale such that all regularized solutions have the property . A more general form of the penalty functional in the Tikhonov functional would be , where denotes a given smooth reference element. then plays the role of the origin (the point of central interest), which can be very different for nonlinear problems. Without a loss of generality, we set in the sequel which makes the formulas simpler.
In our study, the discrepancy principle named after Morozov (cf. [2]) as the most prominent a posteriori choice of the regularization parameter plays a substantial role. On the one hand, the simplified version
of the discrepancy principle in equation form with a prescribed constant is important for theory (cf. [3]). However, it is well known that there are nonlinear problems, where that version is problematic due to duality gaps that prevent the solvability of Equation (5). For overcoming the remaining weaknesses of the parameter choice expressed in Equation (5), sequential versions of the discrepancy principle can be applied that approximate , and we refer to [4,5,6] for more details. Such an approach is used for performing the numerical case studies in Section 6.
Our focus is on oversmoothing penalties in the Tikhonov functional , where such that . In this case, the regularizing property does not yield any information. This property, however, is the basic tool for obtaining error estimates and convergence assertions for the Tikhonov-regularized solutions in the standard case, where . We refer as an example to Chapter 10 of the monograph [7], which also deals with nonlinear operator equations, but adjusts the penalty functional to level zero. To derive error estimates in the oversmoothing case, the regularizing property must be replaced by inequalities of the form , where is an appropriately chosen auxiliary element.
The seminal paper on Tikhonov regularization in Hilbert scales that includes the oversmoothing case was written by F. Natterer in 1984 (cf. [8]) and was restricted to linear operator equations. Error estimates in the X-norm and convergence rates were proven under two-sided inequalities that characterize the degree of ill-posedness of the problem. We follow this approach and adapt it to the case of nonlinear problems throughout the subsequent sections and assume the inequality chain
and constants . The left-hand inequality in Equation (6) represents a conditional stability estimate and is substantial for obtaining stable regularized solutions, whereas the right-hand inequality in Equation (6) contributes to the determination of the nonlinearity structure of the forward operator F. Convergence and rate results for the Tikhonov regularization expressed in Equation (4) with oversmoothing penalties under the inequality chain expressed in Equation (6) were recently presented in [3,6,9] and complemented by case studies in [10]. The present paper continues this series of articles by addressing open questions with respect to the discrepancy principle for choosing the regularization parameter and its comparison to a priori parameter choices. In this context, one of the examples from [10] is reused for performing new numerical experiments in order to obtain additional assertions that cannot be taken from analytical investigations.
The paper is organized as follows: We summarize in Section 2 basic properties of regularized solutions under assumptions that are typical for oversmoothing penalties and in Section 3 assertions concerning the convergence. In Section 4 we show that the error estimates derived in [6] for obtaining low order convergence rates are also applicable to obtain the order optimal Hölder convergence rates under the associated Hölder-type source conditions. Section 5 recalls a nonlinear inverse problem from an exponential growth model and an appropriate Hilbert scale, which can both be used for performing numerical experiments in the subsequent section. In that section (Section 6), the obtained numerical results are presented and interpreted based on a series of tables and figures.
2. Assumptions and Properties of Regularized Solutions
In this section, we formulate the standing assumptions concerning the forward operator F, the Tikhonov functional , and the solution of Equation (1) in order to ensure the existence and stability of regularized solutions for all regularization parameters and noisy data .
Assumption 1.
- (a)
- The operatormapping between the real Hilbert spaces X and Y is weakly sequentially continuous, and its domainwithis a convex and closed subset of X.
- (b)
- The generatorof the Hilbert scale is a densely defined, unbounded, and self-adjoint linear operator that satisfies the inequality expressed in Equation (3).
- (c)
- The solutionof Equation (1) is supposed to be an interior point of the domain.
- (d)
- To characterize the case of oversmoothing penalties, we assume that
- (e)
- There is a number , and there are constants such that the two-sided estimates expressed in Equation (6) hold.
As a specific impact of Item (d) of Assumption 1 on approximate solutions to , we have the following proposition that is of interest for the behavior of regularized solutions in the case of oversmoothing penalties.
Proposition 1.
Let a sequence converge weakly in X to as . We then have .
Proof.
In order to construct a contradiction, let us assume that the sequence (or some of its subsequences) is bounded in , i.e., for all . Thus, a subsequence of converges weakly in X to some element , because bounded sets are weakly pre-compact in the Hilbert space X. Since the operator B is densely defined and self-adjoint, it is closed, i.e., the graph is closed and, due to the convexity of this set, a weakly closed subset of . Hence, the operator B is weakly closed, which implies that and . This, however, contradicts the assumed property and proves the proposition. ☐
Remark 1.
As a consequence of Proposition 1, we have for any sequence of regularized solutions , which is norm-convergent (and thus also weak-convergent) to for as , such that it blows up to infinity with respect to the -norm. In other words, we have the limit condition .
Based on Lemma 1, we can formulate in Proposition 2 the existence of minimizers to the extremal problem expressed in Equation (4).
Lemma 1.
The non-negative penalty functional as part of the Tikhonov functional is a proper convex and a lower, semi-continuous, and stabilizing functional.
Proof.
The obviously convex penalty functional is proper, since it attains finite values for all . It is also a stabilizing functional because, as a consequence of Equation (3), the sub-level sets are weakly sequentially pre-compact subsets in X for all constants . Namely, all such non-empty sub-level sets are bounded in X and hence weakly pre-compact. For showing that the functional is lower semi-continuous, by taking into account Proposition 1 and its proof, it is enough to show that a sequence with for all that converges weakly in X to implies that and that this sequence also converges weakly in to . The lower semi-continuity of the norm functional then yields . Now note that a subsequence bounded in has a subsequence that converges weakly in to some element . Since the operator B is weakly closed, we then have . Since z is uniform for all subsequences, this completes the proof. ☐
Proposition 2.
For all and , there is a regularized solution , solving the extremal problem expressed in Equation (4).
Proof.
Proposition 4.1 from [11], which coincides with our proposition, is immediately applicable, since the Assumptions 3.11 and 3.22 from [11] are satisfied due to Assumption 1 and Lemma 1 above. ☐
In addition to the existence assertion of Proposition 2, we also have, under the assumptions stated above, the stability of regularized solutions, which means that small changes in the data yield only small changes in . For a detailed description of this fact, see Proposition 4.2 from [11] that applies here under Assumption 1.
Remark 2.
From Assumption 1, we have that there are no solutions , satisfying with the operator expressed in Equation (1), because this would contradict, with and , the left-hand inequality of Equation (6). Besides , however, other solutions with may exist. The regularized solutions , for fixed and , need not be uniquely determined, since, though possessing a convex part , the Tikhonov functional is not necessarily convex.
3. Convergence of Regularized Solutions in the Case of Oversmoothing Penalties
In this section, we discuss assertions about the X-norm convergence of regularized solutions with the Tikhonov functional introduced in Equation (4). First we recall the following lemma (from [6], Proposition 3.4).
Lemma 2.
Under Assumption 1, we have, for regularized solutions solving the extremal problem expressed in Equation (4), a function satisfying the limit condition and a constant such that the error estimate
is valid for all and for sufficiently small .
From Lemma 2, we directly obtain the following proposition (cf. [6], Theorem 4.1):
Theorem 1.
For any a priori parameter choice and any a posteriori parameter choice , the regularized solutions converge under Assumption 1 to the solution of the operator expressed in Equation (1) for , i.e.,
whenever
Remark 3.
By inspection of the corresponding proofs in [6], it becomes clear that the validity of Lemma 2 and consequently of Theorem 1 is not restricted to the case of oversmoothing penalties, but it holds if Items (a), (b), (c), and (e) of Assumption 1 are fulfilled. This means that the solution can possess arbitrary smoothness.
Example 1.
In this example, we consider with respect to Theorem 1 the a priori parameter choice
for varying exponents . As the following proposition, as a consequence of Theorem 1, indicates, there is a wide range of exponents yielding convergence.
However, the proof of the underlying Theorem 4.1 in [6] shows that the general verification of the basic estimate expressed in Equation (8), developed with a focus on the case of oversmoothing penalties, requires both the left-hand inequality as well as the right-hand inequality in the nonlinearity condition expressed in Equation (6) and, moreover, that is an interior point of . More discussions in that direction can be made if we distinguish the following three -intervals:
- (i):
- (ii):
- with two constants and such thatand
- (iii):
If we have in contrast to Item (d) of Assumption 1, then, for the convergence of regularized solutions to in Case (i), the nonlinearity condition expressed in Equation (6) is not needed at all provided that Items (a) and (b) of Assumption 1 are fulfilled. Also Item (c) is not necessary there. However to derive Equation (9), must be the uniquely determined penalty-minimizing solution to Equation (1) (cf. [11], Sect. 4.1.2 or alternatively [12,13]). Note that, for and parameter choices according to (i), conditions of the type expressed in Equation (6) are only relevant for proving convergence rates.
If regularization parameters are chosen such that Equation (12) is violated as in Cases (ii) and (iii), then even for inequalities from the condition expressed in Equation (6) are important. Precisely, Case (iii) seems to require both inequalities of Equation (6) for deriving convergence of regularized solutions to . The parameter choice according to Case (ii) with represents for the typical conditional stability estimate situation introduced in the seminal paper [14]. There, only the left-hand inequality of condition expressed in Equation (6) is needed for convergence, which then is a consequence of convergence rate results (cf. [15,16,17] and references therein). However, to derive Equation (9), must be the uniquely determined solution to Equation (1). In the oversmoothing case , both inequalities in Equation (6) seem to be indispensable for obtaining convergence; moreover, for all suggested choices of the regularization parameter , the convergence proofs published by now, all using auxiliary elements, are essentially based on the fact that is an interior point of the domain . Determining the conditions under which convergence takes place if is chosen in Equation (11) is an open problem.
Now we turn to convergence assertions, provided that the regularization parameter is selected according to the discrepancy principle expressed in Equation (5) with prescribed constant . The main ideas of the proof are outlined along the lines of [6], Theorem 4.9, where a sequential discrepancy has been considered.
Theorem 2.
Under Assumption 1, let there be, for a sequence of positive noise levels with and all admissible noisy data obeying , regularization parameters , satisfying the discrepancy principle
for a prescribed constant . We then have
and convergence as
Proof.
First, we show that Equation (16) always takes place for oversmoothing penalties with . To find a contradiction, we assume that . Since as a consequence of Item (a) of Assumption 1, we have and thus , which means that and, by Equation (3), are uniformly bounded from above for all . We then have for a subsequence the weak convergences in X as and as . Since the operator B is weakly sequentially closed, we therefore obtain and for F weakly sequentially continuous (cf. Item (a) of Assumption 1) also . Now, by Equation (15), we easily derive that as and consequently . Thus, the left-hand inequality of Equation (6) (cf. Item (e) of Assumption 1) yields , which contradicts the assumption and proves the property expressed in Equation (16) of the regularization parameter choice.
Secondly, we prove the convergence property expressed in Equation (17). From [6], Lemma 3.2, we have that
for some function satisfying the limit condition , for sufficiently small and arbitrary . In combination with , this yields under the condition expressed in Equation (16), implying the estimate
Now Theorem 1 applies. This completes the proof. ☐
Remark 4.
In the case of non-oversmoothing penalties, the limit condition expressed in Equation (16) represents a canonical situation for regularized solutions, whereas the non-existence of from Equation (5) and the violation of Equation (16) only occur in exceptional cases. For the sequential variant of the discrepancy principle, the exceptional case is discussed in [4] in the context of the exact penalization veto introduced there.
4. An Alternative Approach to Prove Hölder Convergence Rates in the Case of Oversmoothing Penalties for an A Priori Parameter Choice of the Regularization Parameter
In this section, we consider order optimal convergence rate results in the case of oversmoothing penalties for an a priori parameter choice of the regularization parameter . Such results have been proven in the paper [9] under the condition for , which is a Hölder-type source condition. In that paper, the proof is formulated for the penalty with reference element . This proof has been repeated in the appendix of the paper [10] in the simplified version with and penalty term , which is also utilized in the present work.
In the following, we present the sketch of an alternative proof for the order optimal Hölder convergence rates under the Hölder-type source condition for . This alternative approach is based on error estimates that have been verified in [6] for showing convergence of the regularized solutions to and for proving low order (e.g., logarithmic) convergence rates under corresponding low order source conditions. By one novel idea outlined below, the results from [6] can be extended to prove Hölder convergence rates, too.
For the subsequent investigations, we complement Assumption 1 with an assumption that specifies the smoothness of the solution :
Assumption A2.
There are and such that
Theorem 3.
Under Assumptions 1 and 2, we have for the a priori parameter choice
the convergence rate
Proof.
We give only a sketch of a proof for this theorem, presupposing the results of the recent paper [6]. Precisely, we outline only the points, where we amend and complement the results of [6] in order to extend [6], Theorem 5.3, to the case of appropriate power-type functions .
Auxiliary elements , which are for all the uniquely determined minimizers of the artificial Tikhonov functional , represent, in combination with the moment inequality, the essential tool for the proof. By introducing the self-adjoint and positive semi-definite bounded linear operator , we can verify these elements in an explicit manner as
which implies that, for all ,
and
According to [6], Lemma 3.1, we then have the functions and as introduced there, which can be found in our notation from the representations , , and . Under the source condition expressed in Equation (18), which attains the form with some source element , we derive in detail the formulas
and
The asymptotics in Equations (21)–(23) is a consequence of the properties , , which yield by exploiting the moment inequality (cf. [7], Formula (2.49))
for the self-adjoint and positive semi-definite operator G. Here, denotes the operator norm in the space of bounded linear operators mapping in X. In Equation (21), the inequality expressed in Equation (24) is applied with , it is applied with in Equation (22), and it is applied with in Equation (23), taking into account that all three -values are smaller than one. These are the new ideas of the present proof.
Because the function in [6], Formula (3.12), is found by linear combination and maximum-building of the functions , and , we derive here along the lines of Section 3 in [6] and consequently the error estimate
with constants , which is valid for all and a sufficiently small . Such a restriction to a sufficiently small is due to the fact that has to belong to in order to apply the inequality chain expressed in Equation (6), but this is the case for small , since is assumed to be an interior point of . Under the a priori parameter choice expressed in Equation (19), we immediately obtain the convergence rate expressed in Equation (20) from the error estimate expressed in Equation (25). This completes the sketch of the proof of the theorem. ☐
Remark 5.
Obviously, the a priori parameter choice expressed in Equation (19) satisfies the sufficient condition expressed in Equation (10) for the convergence of regularized solutions from Theorem 1. More precisely, taking into account Example 1, the choice expressed in Equation (19) has the form of Equation (11) with , which for yields and belongs to Case (iii), where the quotient tends toward infinity as . We mention that the choice expressed in Equation (19) coincides with the choice in [8] suggested by Natterer, who proved the order optimal convergence rate expressed in Equation (20) for linear ill-posed operator equations. For the nonlinear operator expressed in Equation (1), in [3], the convergence rate expressed in Equation (20) has also been proven for the a posteriori parameter choice from Equation (5). However, by now, there are no analytical results about the -asymptotics of the discrepancy principle as tends toward zero. The numerical experiments in the subsequent sections will provide some hints that the hypothesis does not have to be rejected.
5. Model Problem and Appropriate Hilbert Scale
In the following, we introduce an example for a nonlinear inverse operator expressed in Equation (1) together with an appropriate Hilbert scale, for which we will investigate the analytic results from the previous section numerically, following up on [10]. The well-known scale of Hilbert-type Sobolev spaces with integer values of consists of functions whose p-th derivative is still in . For positive indices p, the spaces can be defined by using an interpolation argument, and for general real parameters of the norms of can be defined by using the Fourier transform of the function x as
(cf. [18]). The Sobolev scales do not constitute a Hilbert scale in the strict sense, but for each there is an operator such that is a Hilbert scale (see [19]). In order to form a full Hilbert scale for arbitrary real values of p, boundary values conditions need to be imposed.
Hilbert scale.
To generate a full Hilbert scale , we exploit the simple integration operator
of Volterra-type mapping in and set
Using the Riemann-Liouville fractional integral operator and its adjoint for , we receive
(cf. [20,21,22,23]); hence, by [20], Lemma 8, the explicit structure
Further boundary conditions have to be incorporated for higher Sobolev indices p.
Model problem.
The exponential growth model of this example was discussed in early literature (cf., e.g., [24], Section 3.1). More details and properties can be found in [25] and in the appendix of [3]. To identify the time dependent growth rate of a population, we use observations of the time-dependent size of the population with initial size , where the O.D.E. initial value problem
is assumed to hold. For simplicity, we set and consider the space setting . Thus, we derive the nonlinear forward operator mapping in the real Hilbert space as
with full domain and with the Fréchet derivative
It can be shown that there is some constant such that for all the inequality
is valid. This in turn guarantees that a tangential cone condition
holds with some in for a sufficiently small r > 0 (cf. [3], Example A.2), where denotes a closed ball around with radius r. According to the construction of the Hilbert scale generated by the operator B in Equation (28), and due to as a consequence of Equation (30), we receive from [3], Proposition A.4 that the inequality chain expressed in Equation (6) holds with a = 1 in this example.
6. Numerical Case Studies
In this section, numerical evidence for the behavior of the regularized solutions of the model problem introduced in Section 5 is provided. In Section 6.1, numerical experiments with a focus on the discrepancy principle are conducted using exact solutions for low order Hölder-type smoothness with , while the focus of the recent paper [10] was on results for and larger values p. The essential point of Section 6.2 is the comparison of results obtained by the discrepancy principle with those calculated by a priori choices expressed in Equation (11) of the regularization parameter .
6.1. Case Studies for Exact Solutions with Low Order Hölder Smoothness
In our first series of experiments, we investigated the interplay between the value , the decay rates of the regularization parameter with respect to the noise level for different values p as tends toward zero, and the corresponding rates of the error of regularized solutions . Therefore, we turn to exact solutions of the form with . These functions do not belong to the Sobolev space with fractional order p if (see for example [26], p. 422). This allows us to study the behavior of the regularized solutions for exact solutions with low order Hölder-type solution smoothness. For the numerical simulations, we therefore assume that is at least approximately the smoothness of the exact solution .
To confirm our theoretical findings, we solve Equation (4) after discretization using the trapezoidal rule for the integral, the MATLAB®-function fmincon. We would also like to point out the difficulties associated with the numerical treatment of functions of this particular type. Obviously the pole occurring at zero is source force for the low smoothness of the exact solution and needs to be captured accordingly. After multiple different approaches, equidistant discretization with the first discretization point very close to zero was proven to be very successful. Typically, a discretization level is used. To the simulated data , we added random noise for which we prescribe the relative error such that ; i.e., we have Equation (2) with . To obtain the norm in the penalty, we set and additionally enforce the boundary condition . The regularization parameter in these series of experiments is chosen as using, with some prescribed multiplier , the discrepancy principle
which approximates from Equation (5). Unless otherwise noted, C = 1.3 was used. From the case studies in [10], we can conjecture, but have no stringent proof, that the -rate of the discrepancy principle does not systematically deviate from the a priori rate expressed in Equation (19), which for attains the form
This -rate already occurred in Natterer’s paper [8] for linear problems, and occurs in the case of oversmoothing penalties. We should in our numerical experiments be able to observe the order optimal convergence rate, which is for
This convergence rate was proven for the a priori parameter choice expressed in Equation (19) as well as for the discrepancy principle expressed in Equation (5) in [9] and [3], respectively.
As the exact solutions are known, we can compute the regularization errors . Interpreting these errors as a function of justifies a regression for the convergence rates according to
The -rates are then computed in a similar fashion using
Both exponents and and the corresponding multipliers and , all obtained by using a least squares regression based on samples for varying , are displayed for different values in Table 1. As we know, the convergence rate expressed in Equation (35), we can estimate the smoothness p by the the formula . The far right column of Table 1 displays the quotient estimating the exponent in Equation (34), which can be compared with the -values in the second to right column obtained by regression from a data sample. By comparing the far right column and the second to right column of Table 1, we can state that the asymptotics of as seems to be approximately the same as for the optimal a priori parameter choice expressed in Equation (34). Such observation was already made for larger values p in [10] for the same model problem.

Figure 1 illustrates results from Table 1 for characterizing with varying different smoothness levels of the solution. Since we have an oversmoothing penalty for all such , the -values lie between 2 and (cf. the -interval (iii) in Example 1). Additionally, the border lines for and are displayed taking into account that [6] guarantees convergence of the regularized solution to the exact solution as for a priori choices in the sense of Equation (19) whenever . It becomes evident that the -rates resulting from the discrepancy principle also lie between those bounds.
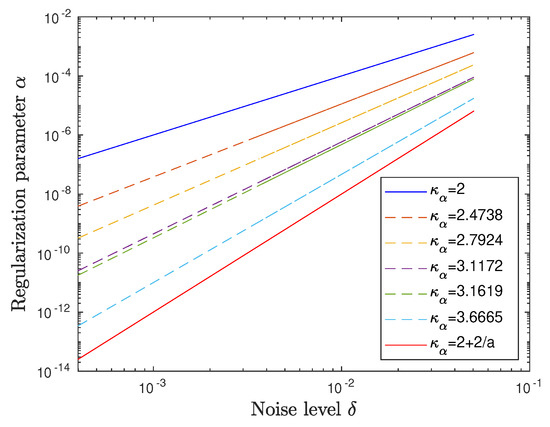
Figure 1.
Regression lines for decay rates of for and different values from Table 1 on a double-logarithmic scale.
Figure 2 and Figure 3 give some more insight into the situation for the special case , which approximately corresponds with the smoothness . In Figure 2 (left), the realized errors are visualized for a discrete set of noise levels and compared with the associated regression line in a double-logarithmic scale. It becomes evident that the approximation using Hölder rates is highly accurate. The right image of Figure 2 visualizes the behavior of for various noise levels on a logarithmic scale. The tendency that as seems to be convincing. Figure 3 (left) displays the realized -values for this particular situation together with the best approximating regression line according to Equation (37). We see again a very good fit for this type of approximation. The right subfigure shows the exact and regularized solution for . The excellent fit of the regularized solution confirms our confidence in the numerical implementation, especially considering the problems associated with this type of exact solution.
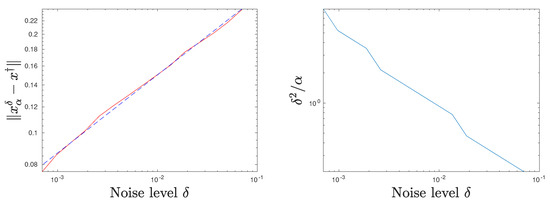
Figure 2.
Approximation error in red and approximate rate in blue/dashed (left) and (right), both depending on various on a log-log scale.
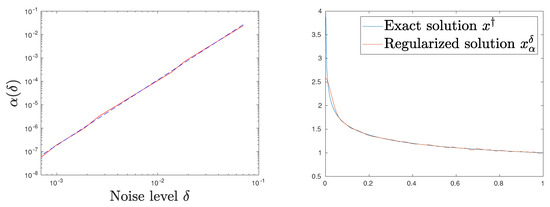
Figure 3.
in red for various and best approximating regression line in blue/dashed on a log-log scale (left). Regularized (red) compared with exact solution (blue) for (right).
6.2. A Comparison with Results from A Priori Parameter Choices
The question of whether the a posteriori choices using the discrepancy principle or appropriate a priori choices according to Equation (19) yield better results is of interest. The influence of the constant when using a priori choice according to Equation (37) remains especially unclear. To numerically investigate this, we remain in the setting of Section 6.1; i.e., we consider as an exact solution. Figure 4 illuminates this situation for . The error is plotted for various constants , where we use . The error curve shows a clear minimum, which is connected with smaller values compared with those obtained by exploiting the discrepancy principle with and . It is completely unclear how to find suitable multipliers in practice, whereas the discrepancy principle can always be applied as a robust parameter choice rule for practical applications.
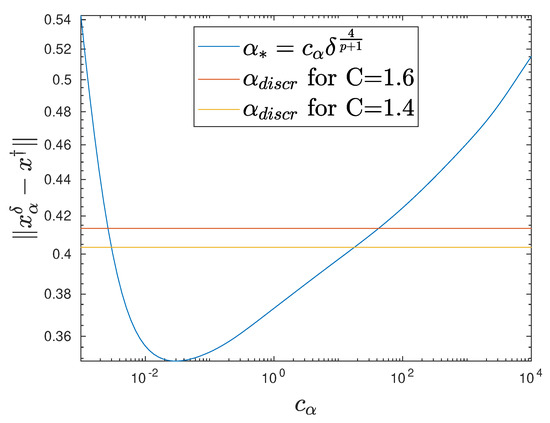
We complete our numerical experiments on a priori choices of the regularization parameter with Table 2 and Figure 5, where we list and illustrate the best regression exponents according to the error norm estimate expressed in Equation (36) for different exponents in the a priori parameter choice expressed in Equation (37). In this case study, we used the exact solution with the higher smoothness . For the a priori parameter choice expressed in Equation (37) with varying exponents , the factor has been fixed. The discretization level was considered.
Table 2.
Error rates by regression for and varying a priori exponents .
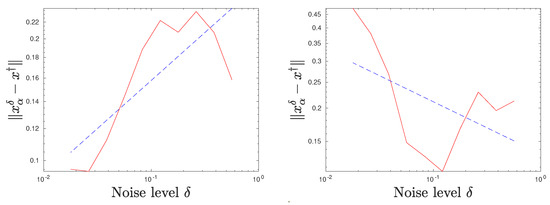
Figure 5.
Regularization error and regression line for different noise levels on a log-log scale. , a priori parameter choice according to Equation (37) with (left) and (right).
As expected, Table 2 indicates that maximal error rates occur if is close to the optimal value . These rates also correspond with the order optimal rates according to Equation (20). For smaller exponents , the error rates are falling, and for large exponents , the convergence seems to degenerate. This is visualized in Figure 5: For , convergence still takes place, whereas for convergence cannot be observed anymore.
Remark 6.
As an alternative a posteriori approach for choosing the regularization parameter , one could also consider the balancing (Lepskiĭ) principle (cf., e.g., [27,28]). In [29], this principle is adapted to the Hilbert scale setting, but not with respect to oversmoothing penalties. In future work, we can discuss this missing facet and perform numerical experiments for the balancing principle in the case of oversmoothing penalties.
Author Contributions
Formal analysis, B.H.; Investigation, B.H. and C.H.; Software, C.H.; Supervision, B.H.; Visualization, C.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Deutsche Forschungsgemeinschaft (grant HO 1454/12-1).
Acknowledgments
The authors thank Daniel Gerth (TU Chemnitz) for fruitful discussions and his kind support during the preparation of this article.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hofmann, B.; Scherzer, O. Factors influencing the ill-posedness of nonlinear problems. Inverse Probl. 1994, 10, 1277–1297. [Google Scholar] [CrossRef]
- Morozov, V.A. Methods for Solving Incorrectly Posed Problems; Springer: New York, NY, USA, 1984. [Google Scholar]
- Hofmann, B.; Mathé, P. Tikhonov regularization with oversmoothing penalty for non-linear ill-posed problems in Hilbert scales. Inverse Probl. 2018, 34, 015007. [Google Scholar] [CrossRef]
- Anzengruber, S.W.; Hofmann, B.; Mathé, P. Regularization properties of the sequential discrepancy principle for Tikhonov regularization in Banach spaces. Appl. Anal. 2014, 93, 1382–1400. [Google Scholar] [CrossRef]
- Anzengruber, S.W.; Ramlau, R. Morozov’s discrepancy principle for Tikhonov-type functionals with nonlinear operators. Inverse Probl. 2010, 26, 025001. [Google Scholar] [CrossRef]
- Hofmann, B.; Plato, R. Convergence results and low order rates for nonlinear Tikhonov regularization with oversmoothing penalty term. Electron. Trans. Numer. Anal. 2020, 93. [Google Scholar]
- Engl, H.W.; Hanke, M.; Neubauer, A. Regularization of Inverse Problems; Volume 375 of Mathematics and Its Applications; Kluwer Academic Publishers Group: Dordrecht, The Netherlands, 1996. [Google Scholar]
- Natterer, F. Error bounds for Tikhonov regularization in Hilbert scales. Appl. Anal. 1984, 18, 29–37. [Google Scholar] [CrossRef]
- Hofmann, B.; Mathé, P. A priori parameter choice in Tikhonov regularization with oversmoothing penalty for non-linear ill-posed problems. In Springer Proceedings in Mathematics & Statistics; Cheng, J., Lu, S., Yamamoto, M., Eds.; Springer: Singapore, Singapore, 2020; pp. 169–176. [Google Scholar]
- Gerth, D.; Hofmann, B.; Hofmann, C. Case studies and a pitfall for nonlinear variational regularization under conditional stability. In Springer Proceedings in Mathematics & Statistics; Cheng, J., Lu, S., Yamamoto, M., Eds.; Springer: Singapore, Singapore, 2020; pp. 177–203. [Google Scholar]
- Schuster, T.; Kaltenbacher, B.; Hofmann, B.; Kazimierski, K.S. Regularization Methods in Banach Spaces; Volume 10 of Radon Series on Computational and Applied Mathematics; Walter de Gruyter: Berlin, Germany; Boston, MA, USA, 2012. [Google Scholar]
- Scherzer, O.; Grasmair, M.; Grossauer, H.; Haltmeier, M.; Lenzen, F. Variational Methods in Imaging; Volume 167 of Applied Mathematical Sciences; Springer: New York, NY, USA, 2009. [Google Scholar]
- Tikhonov, A.N.; Leonov, A.S.; Yagola, A.G. Nonlinear Ill-Posed Problems; Chapman & Hall: London, UK; New York, NY, USA, 1998; Volume 1. [Google Scholar]
- Cheng, J.; Yamamoto, M. One new strategy for a priori choice of regularizing parameters in Tikhonov’s regularization. Inverse Probl. 2000, 16, L31–L38. [Google Scholar] [CrossRef]
- Egger, H.; Hofmann, B. Tikhonov regularization in Hilbert scales under conditional stability assumptions. Inverse Probl. 2018, 34, 115015. [Google Scholar] [CrossRef]
- Neubauer, A. Tikhonov regularization of nonlinear ill-posed problems in Hilbert scales. Appl. Anal. 1992, 46, 59–72. [Google Scholar] [CrossRef]
- Tautenhahn, U. On a general regularization scheme for nonlinear ill-posed problems II: Regularization in Hilbert scales. Inverse Probl. 1998, 14, 1607–1616. [Google Scholar] [CrossRef]
- Adams, R.A.; Fournier, J.F.J. Sobolev Spaces; Elsevier/Academic Press: Amsterdam, The Netherlands, 2003. [Google Scholar]
- Neubauer, A. When do Sobolev spaces form a Hilbert scale? Proc. Am. Math. Soc. 1988, 103, 557–562. [Google Scholar] [CrossRef]
- Gorenflo, R.; Yamamoto, M. Operator-theoretic treatment of linear Abel integral equations of first kind. Jpn. J. Ind. Appl. Math. 1999, 16, 137–161. [Google Scholar] [CrossRef]
- Gorenflo, R.; Luchko, Y.; Yamamoto, M. Time-fractional diffusion equation in the fractional Sobolev spaces. Fract. Calc. Appl. Anal. 2015, 18, 799–820. [Google Scholar] [CrossRef]
- Hofmann, B.; Kaltenbacher, B.; Resmerita, E. Lavrentiev’s regularization method in Hilbert spaces revisited. Inverse Probl. 2016, 10, 741–764. [Google Scholar] [CrossRef]
- Plato, R.; Hofmann, B.; Mathé, P. Optimal rates for Lavrentiev regularization with adjoint source conditions. Math. Comput. 2018, 87, 785–801. [Google Scholar] [CrossRef]
- Groetsch, C.W. Inverse Problems in the Mathematical Sciences. In Vieweg Mathematics for Scientists and Engineers; Vieweg+Teubner Verlag: Wiesbaden, Germany, 1993. [Google Scholar]
- Hofmann, B. A local stability analysis of nonlinear inverse problems. In Inverse Problems in Engineering—Theory and Practice; The American Society of Mechanical Engineers: New York, NY, USA, 1998; pp. 313–320. [Google Scholar]
- Fleischer, G.; Hofmann, B. On inversion rates for the autoconvolution equation. Inverse Probl. 1996, 12, 419–435. [Google Scholar] [CrossRef]
- Mathé, P. The Lepskiĭ principle revisited. Inverse Probl. 2006, 22, L11–L15. [Google Scholar] [CrossRef]
- Lu, S.; Pereverzev, S.V.; Ramlau, R. An analysis of Tikhonov regularization for nonlinear ill-posed problems under a general smoothness assumption. Inverse Probl. 2007, 23, 217–230. [Google Scholar] [CrossRef]
- Pricop-Jeckstadt, M. Nonlinear Tikhonov regularization in Hilbert scales with balancing principle tuning parameter in statistical inverse problems. Inverse Probl. Sci. Eng. 2019, 27, 205–236. [Google Scholar] [CrossRef]
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).