1. Introduction
The increasing interest in applications of fractional calculus, together with the difficulty of finding analytical solutions of fractional differential equations (FDEs), naturally forces researchers to study, devise and apply numerical methods to solve a large range of ordinary and partial differential equations with fractional derivatives.
The investigation of computational methods for fractional-order problems is therefore a very active research area in which, each year, a large number of research papers are published.
The task of finding efficient and reliable numerical methods for handling integrals and/or derivatives of fractional order is a challenge in its own right, with difficulties that differ in character but are no less severe than those associated with finding analytical solutions. The specific nature of these operators involves computational challenges which, if not properly addressed, may lead to unreliable or even wrong results.
Unfortunately, the scientific literature is rich with examples of methods that are inappropriate for fractional-order problems. In most cases these are just methods that were devised originally for standard integer-order operators then applied in a naive way to their fractional-order counterparts; without a proper knowledge of the specific features of fractional-order problems, researchers are often unable to understand why unexpected results are obtained.
The main aims of this paper are to identify a few major guidelines that should be followed when devising reliable computational methods for fractional-order problems, and to highlight the main peculiarities that make the solution of differential equations of fractional order a different—but surely more difficult and stimulating—task from the integer-order case. We do not intend merely to criticize weak or wrong methods, but try to explain why certain approaches are unreliable in fractional calculus and, where possible, point the reader towards more suitable approaches.
This paper is mainly addressed at young researchers or scientists without a particular background in the numerical analysis of fractional-order problems but who need to apply computational methods to solve problems of fractional order. We aim to offer in this way a kind of guide to avoid some of the most common mistakes which, unfortunately, are sometimes made in this field.
The paper is organized in the following way. After recalling in
Section 2 some basic definitions and properties, we illustrate in
Section 3 the most common ideas underlying the majority of the methods proposed in the literature: very often the basic ideas are not properly recognized and common methods are claimed to be new. In
Section 4 we discuss why polynomial approximations can be only partially satisfactory for fractional-order problems and why they are unsuitable for devising high-order methods (as has often been proposed). The major problems related to the nonlocality of fractional operators are addressed in
Section 5 and
Section 6 discusses some of the most powerful approaches for the efficient treatment of the memory term. Some remarks related to the numerical treatment of fractional partial differential equations are presented in
Section 7 and some final comments are given in
Section 8.
2. Basic Material and Notations
With the aim of fixing the notation and making available the most common definitions and properties for further reference, we recall here some basic notions concerning fractional calculus.
For
and any
, in the paper we will adopt the usual definitions for the fractional integral of Riemann–Liouville type
for the fractional derivative of Riemann–Liouville type
and for the fractional derivative of Caputo type
with
the smallest integer greater than or equal to
.
We refer to any of the many existing textbooks on this subject (e.g., [
1,
2,
3,
4,
5,
6]) for an exhaustive treatment of the conditions under which the above operators exist and for their main properties. We just recall here the relationship between
and
expressed as
where
is the Taylor polynomial of degree
for the function
f about the point
,
Moreover, we will almost exclusively consider initial value problems of Cauchy type for FDEs with the Caputo derivative, i.e.,
for some assigned initial values
. A few general comments will also be made regarding problems associated with partial differential equations.
3. Novel or Well-Established Methods?
Quite frequently, one sees papers whose promising title claims the presentation of “new methods” or “a family of new methods” for some particular fractional-order operator. Papers of this type immediately capture the attention of readers eager for new and good ideas for numerically solving problems of this type.
But reading the first few pages of such papers can be a source of frustration, since what is claimed to be new is merely an old method applied to a particular (maybe new) problem. Now it is understandable that sometimes an old method is reinvented by a different author, maybe because it can be derived by some different approach or because the author is unaware of the previously published result (perhaps because it was published under an imprecise or misleading title). In fractional calculus, however, a different and quite strange phenomenon has taken hold: well-known and widely used methods are often claimed as “new” just because they are being applied to some specific problem. It seems that some authors are unaware that it is the development of new ideas and new approaches that leads to methods that can be described as new—not the application of known ideas to a particular problem. Even the application of well-established techniques to any of the new operators, obtained by simply replacing the kernel in the integral (
1) with some other function, cannot be considered a truly novel method, especially when the extension to the new operator is straightforward.
Most of the papers announcing “new” methods are instead based on ideas and techniques that were proposed and studied decades ago, and sometimes proper references to the original sources are not even given.
In fact, there are a few basic and powerful methods that are suitable and extremely popular for fractional-order problems, and many proposed “new methods” are simply the application of the ideas behind them. It may therefore be useful to illustrate the main and more popular ideas that are most frequently (re)-proposed in fractional calculus, and to outline a short history of their origin and development.
3.1. Polynomial Interpolation and Product-Integration Rules
Solving differential equations by approximating their solution or their vector field by a polynomial interpolant is a very old and common idea. Some of the classical linear multistep methods for ordinary differential equations (ODEs), specifically those of Adams–Bashforth or Adams–Moulton type, are based on this approach.
In 1954 the British mathematician Andrew Young proposed [
7,
8] the application of polynomial interpolation to solve Volterra integral equations numerically. This approach turns out to be suitable for FDEs since (
6) can be reformulated as the Volterra integral equation
The approach proposed by Young is to define a grid
on the solution interval
(very often, but not necessarily, equispaced, namely
,
) and to rewrite (
7) in a piecewise way as
then to replace, in each interval
, the vector field
by a polynomial that interpolates to
f on the grid. This approach is particularly simple if one uses polynomials of degree 0 or 1 because then one can determine the approximation solely on the basis of the data at one of the subinterval’s end points (degree 0; the
product rectangle method) or at both end points (degree 1; the
product trapezoidal method); thus, in these cases one need not introduce auxiliary points inside the interval or points outside the interval. Neither of these methods can yield a particularly high order of convergence, but as we shall demonstrate in
Section 4, the analytic properties of typical solutions to fractional differential equations make it very difficult and cumbersome to achieve high-order accuracy irrespective of the technique used. Consequently, and because these techniques have been thoroughly investigated with respect to their convergence properties [
9] and their stability [
10] and are hence very well understood, the product rectangle and product trapezoidal methods are highly popular among users of fractional order models.
Higher-order methods have occasionally been proposed [
11,
12] but—as indicated above and discussed in more detail in
Section 4—they tend to require rather uncommon properties of the exact solutions to the given problems and therefore are used only infrequently. We also have to notice that the effects of the lack of regularity on the convergence properties of product-integration rules have been studied since 1985 for Volterra integral equations [
13] and since 2004 for the specific case of FDEs [
14].
3.2. Approximation of Derivatives: L1 and L2 Schemes
A classical numerical technique for approximating the Caputo differential operator from (
3) is the so-called
L1 scheme. For
, the definition of the Caputo operator becomes
The idea ([
15], Equation (8.2.6)) is to introduce a completely arbitrary (i.e., not necessarily uniformly spaced) mesh
and to replace the factor
in the integrand by the approximation
This produces the approximation formula
with
For smooth functions f (but only under this assumption!) and an equispaced mesh , the convergence order of the L1 method is .
By construction, the L1 method is restricted to the case
. For
, the
L2 method ([
15], §8.2) provides a useful modification. In its construction, one starts from the representation
which is valid for these values of
. Using now a uniform grid
, one replaces the second derivative of
f in the integrand by its central difference approximation,
for
, which yields
where now
A disadvantage of this method is that it requires the evaluation for f at the point which is located outside the interval .
The central difference used in the definition of the L2 method is symmetric with respect to one of the endpoints of the associated subinterval
, not with respect to its mid point. If this is not desired, one may instead use the alternative
on this subinterval. This leads to the
L2C method [
16]
with
Like the L2 method, the L2C method also requires the evaluation of f outside the interval ; one has to compute and . Both the L2 and the L2C method exhibit convergence behavior for if f is sufficiently well behaved; the constants implicitly contained in the -terms seem to be smaller for the L2 method in the case and for the L2C method if .
In the limit case , the L2 method reduces to first-order backward differencing, and the L2C method becomes the centered difference of first order; for the L2 method corresponds to the classical second-order central difference.
3.3. Fractional Linear Multistep Methods
Fractional linear multistep methods (FLMMs) are less frequently used since their coefficients are, in general, not known explicitly but it is necessary to devise some algorithm for their (technically often difficult) computation. Nevertheless, since these methods allow us to overcome some of the issues associated with other approaches, it is worth giving a short presentation of their properties.
FLMMs were proposed by Lubich in 1986 [
17] and studied in the successive works [
18,
19,
20]. They extend to fractional-order integrals the quadrature rules obtained from standard linear multistep methods (LMMs) for ODEs.
Let us consider a classical
k-step LMM of order
with first and second characteristic polynomials
and
, namely
FLMMs generalizing LMMs (
9) for solving FDEs (
7) are expressed as
where the convolution weights
are obtained from the power series expansion of
, namely
and the
are some starting weights that are introduced to deal with the lack of regularity of the solution at the origin; they are obtained by solving, at each step
n, the algebraic linear systems
with
and
the cardinality of
.
The intriguing property of FLMMs is that, unlike product-integration rules, they are able to preserve the same convergence order p of the underlying LMMs if the LMM satisfies certain properties: it is required that has no zeros in the closed unit disc except for , and for . Thus, high-order FLMMs are possible without requiring the imposition of artificial smoothness assumptions as is required for methods based on polynomial interpolation.
But the price to be paid for this advantage may be not negligible: the convolution weights
are not known explicitly and must be computed by some (possibly sophisticated) method (a discussion for the general case is available in [
17,
18,
19,
20] while algorithms for FLMMs of trapezoidal type are presented in [
21]). Moreover, high-order methods may require the solution of large or very large systems (
11) depending on the equation order
and the convergence order
p of the method; in some cases these systems are so ill-conditioned as to affect the accuracy of the method, a problem addressed in depth in [
22].
One of the simplest methods in this family is obtained from the backward Euler method, whose generating function is
. Its convolution weights are hence the coefficients in the asymptotic expansion of
, i.e., they are the coefficients in the binomial series
and no starting weights are necessary since the convergence order is
and hence
is the empty set. One recognizes easily that the so-called Grünwald-Letnikov scheme is obtained in this case. Although this scheme was discovered in the nineteenth century in independent works of Grünwald and Letnikov, its interpretation as an FLMM may facilitate its analysis.
4. Classical Approximations Will Not Give High-Order Methods
Solutions of fractional-derivative problems typically exhibit weak singularities. This topic is discussed at length in the survey chapter [
23] and it is known since earlier works on Volterra integral equations [
24,
25]. This singularity is a consequence of the weakly singular behavior of the kernels of integral and fractional derivatives and its importance, from a physical perspective, is related to the natural emergence of completely monotone (CM) relaxation functions in models whose dynamics is governed by these operators [
26,
27]; CM relaxation behaviors are indeed typical of viscoelastic systems with strongly dissipative energies [
28].
In the present section we shall examine the effects of the singular behavior on numerical methods, in the context of initial value problems such as (
6).
To grasp quickly the main ideas, we focus on a very simple particular case of (
6): the problem
where
and, for the moment, we do not prescribe the initial condition at
. The general solution of (
12) is
This solution lies in but not in . This implies that standard techniques for integer-derivative problems, which require that (or a higher degree of regularity), cannot be used here without some modification. In particular one cannot perform a Taylor series expansion of the solution around because does not exist.
What about the initial condition? If we prescribe a condition of the form
we get
in (
13), but the solution is still not in
. One might hope that a Neumann-type condition of the form
would control or eliminate the singularity in the solution, but a consideration of (
13) shows that it is impossible to enforce such a condition; that is, the problem
on
with
has no solution. This seems surprising until we recall a basic property of the Caputo derivative from ([
1], Lemma 3.11): if
for some positive integer
m and
, then
. Hence, if in (
12) one has
, then taking the limit as
in (
12) we get
, which is impossible. That is, any solution
y of (
12) cannot lie in
.
One can present this finding in another way: for the problem
on
with
, if the solution
, then one must have
. This result is a special case of ([
1], Theorem 6.26).
Remark 1. For the problem on with , if one wants more smoothness of the solution y on the closed interval , then one must impose further conditions on the data: by ([1], Theorem 6.27), for each positive integer m, one has if and only if . Conditions such as (and the even stronger conditions listed in Remark 1) impose an artificial restriction on the data f that should be avoided. Thus we continue by looking carefully at the consequence of dealing with a solution of limited smoothness.
Returning to (
12) and imposing the initial condition
, the unique solution of the problem is given by (
13), where
b is now fixed. Most numerical methods for integer-derivative initial value problems are based on the premise that on any small mesh interval
, the unknown solution can be approximated to a high degree of accuracy by a polynomial of suitable degree. But is this true of the function (
13)? We now investigate this question.
Consider the interval
, where
. This is the mesh interval where the solution (
13) is worst behaved.
Lemma 1. Let . Consider the approximation of by a linear polynomial on the interval . Suppose this approximation is uniformly accurate on for some fixed . Then one must have .
Proof. Our hypothesis is that
for all
and some constant
C that is independent of
h and
t. Consider the values
and
in this inequality: we get
The first equation gives . Hence the other equations give and . Eliminate by multiplying the first equation by 2 then subtracting from the other equation; this yields . But this cannot be true unless , since the left-hand side is simply a multiple of because . □
Lemma 1 says that the approximation of on by any linear polynomial is at best . But the order of approximation of on is also achieved by the constant polynomial 0. That is: using a linear polynomial to approximate on does not give an essentially better result than using a constant polynomial. In a similar way one can show that using polynomials of higher degree does not improve the situation: the order of approximation of on is still only . This is a warning that when solving typical fractional-derivative problems, high-degree polynomials may be no better than low-degree polynomials, unlike the classical integer-derivative situation.
One can generalize Lemma 1 to any
with
not an integer, obtaining the same result via the same argument. Furthermore, our investigation of the simple problem (
12) can be readily generalised to the much more general problem (
6); see ([
1], Section 6.4).
Implications for the Construction of Difference Schemes
The discussion earlier in
Section 4 implies that, to construct higher-order difference schemes for typical solutions of problems such as (
12) and (
6), one must use non-classical schemes, since the classical schemes are constructed under the assumption that approximations by higher-order polynomials gives greater accuracy. The same idea is developed at length in [
29], one of whose results we now present.
Note: although [
29] discusses only boundary value problems, an inspection reveals that its arguments and results are also valid (mutatis mutandis) for initial value problems such as (
6) when
, i.e., when the problem (
6) is linear.
Let be fixed, with not an integer. Consider the problem on with . Assume that the mesh on is equispaced with diameter h, i.e., for . Suppose that the difference scheme used to solve at each point for is . It is reasonable to assume that for all i and j since we are approximating a derivative of order (one can check that almost all schemes proposed for this problem have this property).
We have the following variant of ([
29], Theorem 3.3).
Theorem 1. Assume that our scheme achieves order of convergence p for some when for all . Then for each fixed positive integer i, the coefficients of the scheme must satisfy the following relationship: Proof. Fix
. This implies that
. Choose for simplicity
Then the true solution of our initial value problem is
. Fix a positive integer
i. Then
Hence, using the hypothesis that our scheme achieves order of convergence
p and
,
since
. □
Theorem 1 implies that schemes that fail to satisfy (
14) cannot achieve an order of convergence greater than
at each mesh point. (This is consistent with the approximation theory result of Lemma 1.) For example, in the case
, it follows from Theorem 1 that the well-known L1 scheme is at best
accurate.
Remark 2. To avoid the consequences of results such as Theorem 1, one can impose data restrictions such as . This is discussed in ([29], Section 5), where theoretical and experimental results show an improvement in the accuracy of standard difference schemes, but only for a restricted class of problems. 5. Failed Approaches to Treat Non-Locality
Non-locality is one of the major features of fractional-order operators. Indeed, fractional integrals and derivatives are often introduced as a mathematical formalism with the primary purpose of encompassing hereditary effects in the modeling of real-life phenomena when theoretical or experimental observations suggest that the effects of external actions do not propagate instantaneously but depend on the history of the system.
On the one hand, non-locality is a very attractive feature that has driven most of the interest and success of the fractional calculus; on the other hand, non-locality introduces severe computational difficulties that researchers try to overcome in different ways.
Unfortunately, some attempts to treat non-locality are unreliable and lead to wrong results. This is the case of the naive implementation of the “finite memory principle” consisting in simply neglecting a large amount of the history solution; since on the basis of this technique it is however possible to devise more sophisticated and accurate approaches, we postpone its discussion to
Section 6.
We have also to mention methods based on some kind of fractional Taylor expansion of the solution, such as
where the coefficients
are determined by some suitable numerical technique.
When solving integer-order differential equations, it is possible to use Taylor expansions to approximate the solution at a given point and hence reformulate the same expansion by moving the origin to the new point , thus generating a step-by-step method in which the approximation at is evaluated on the basis of the approximation at (or at additional previous points).
With fractional-order equations, instead, the above expansion holds only with respect to the point
(the initial or starting point of the fractional differential operator) and it is not possible to generate a step-by-step method. Expansions of this type are therefore able to provide an accurate approximation only locally, i.e., very close to the starting point
; consequently, as discussed in [
30], methods based on these expansions are usually unsuitable for FDEs.
Another failed approach is based on an attempt to exploit the difference between
and
in the integral formulation (
7): rewrite the solution at
as some increment of the solution at
, i.e.,
then approximate the increment
by replacing the vector field
in both integrals of (
15b) by its (first-order) interpolating polynomial at the grid points
and
. Methods of this kind read as
with
a known function obtained by standard interpolation techniques. Approaches of this kind are called
two-step Adams–Bashforth methods and attract researchers since they apparently transform the non-local problem into a local one (and thus, a difficult problem into a much easier one); in (
15b)
is still a non-local term but these methods are strangely becoming quite popular despite the fact that, as discussed in [
31], they are usually unreliable because in most cases they attempt to approximate the (implicitly) non-local contribution
by some purely local term.
Using interpolation at the points
and
to approximate
over the much larger intervals
and
is completely inappropriate. It is well known that polynomial interpolation may offer accurate approximations within the interval of the data points, in this case in
; but outside this interval (where an extrapolation is made instead of an interpolation), the approximation becomes more and more inaccurate as the integration intervals
and
in (
15b) become larger and larger, i.e., as the integration proceeds and
n increases.
The consequence is that completely untrustworthy results must be expected from methods based on this idea.
Note that the fundamental flaw of this approach is not the decomposition (15) but the local (and hence inappropriate) way (
16) in which the history is handled. Indeed, it is possible to construct technically correct and efficient algorithms on the basis of (15), for example if one treats the increment term (
15b) by a numerical method that is cheaper in computational cost than the method used for the local term [
32].
6. Some Approaches for the Efficient, and Reliable, Treatment of the Memory Term
The non-locality of the fractional-order operator means that it is necessary to treat the memory term in an efficient way. This term is commonly identified to be the source of a computational complexity which, especially in problems of large size, requires adequate strategies in order to keep the computational cost at a reasonable level, and indeed this observation has led to many investigations of (more or less successful) approaches to reduce the computational cost. It should be noted however that the high number of arithmetic operations is not the only potential difficulty that the memory term introduces. There is another more fundamental issue, which seems to have attracted much less attention: the history of the process not only needs to be taken into account in the computation but, in order to be properly handled, also needs to be stored in the computer’s memory. While the required amount of memory is usually easily available in algorithms for solving ordinary differential equations, the memory demand may be too high for efficient handling in the case of, e.g., time-fractional partial differential equations where finite element techniques are used to discretize the spatial derivatives.
Most finite-difference methods for FDEs require at each time step the evaluation of some convolution sum of the form
where
is a term which mainly depends on the initial conditions or other known information.
A naive straightforward evaluation of (
17) has a computational cost proportional to
and, when integration with a small-step size or on a large integration interval is required, the value of
N can be extremely large and leads to prohibitive computational costs.
For this reason different approaches for a fast, efficient and reliable treatment of the memory term in non-local problems have been devised. We provide here a short description of some of the most interesting methods of this type. The influence of these approaches on the memory requirements will be addressed as well.
6.1. Nested Mesh Techniques
Several different concepts can be subsumed under the heading of so-called
nested meshes. The general idea is based on the observation that the convolution sum in Equation (
17) stems from a discretization of a fractional integral or differential operator that uses all the previous grid points as nodes. One can then ask whether it is really neccessary to use all these nodes or whether one could save effort by including only a subset of them by using a second, less fine mesh—i.e., a mesh nested inside the original one.
6.1.1. The Finite Memory Principle
The simplest idea in this class is the
finite memory principle ([
5], §7.3). It is based on defining a constant
, the so-called memory length, and replacing (for
) the memory integral term that extends over the interval
by the integral over
with the same integrand function. Technically speaking, this amounts to “forgetting” the entire history of the process that is more than
units of time in the past, so the memory has a finite and fixed length
instead of the variable length
that may, in a long running process, be very much longer. From an algorithmic point of view, the finite memory method truncates the convolution sum in Equation (
17) to a sum where
j runs from
to
n for some fixed
. This has a number of significant advantages:
The computational complexity of the nth time step is reduced from to . Therefore, the combined total complexity of the overall method with N time steps is reduced from to .
At no point in time does one need to access the part of the process history that is more than time steps in the past. Therefore, all those previous time steps can be removed from the active memory, and the memory requirement also decreases from to .
Unfortunately, this idea also has severe drawbacks. Specifically, it has been shown in [
33] that the convergence order of the underlying discretization technique is lost completely. In other words, one cannot prove that the algorithm converges as the (maximal) step size goes to 0. Therefore, the method is not recommended for practical use.
6.1.2. Logarithmic Memory
To overcome the shortcomings of the finite memory principle, two related but not identical methods, both of which are also based on the nested mesh concept, have been developed in [
33,
34]. The common idea of both these approaches is the way in which the distant part of the memory is treated. Rather than ignoring it completely as the finite memory principle does, they do sample it, but on a coarser mesh; indeed the fundamental principle is to introduce not just one coarsening level, but to use, say, the step size
h on the most recent part of the memory, step size
(with some parameter
) on the adjacent region,
on the next region, etc. The main difference between the two approaches of [
33,
34] then lies in the way in which the transition points from one mesh size to the next are chosen.
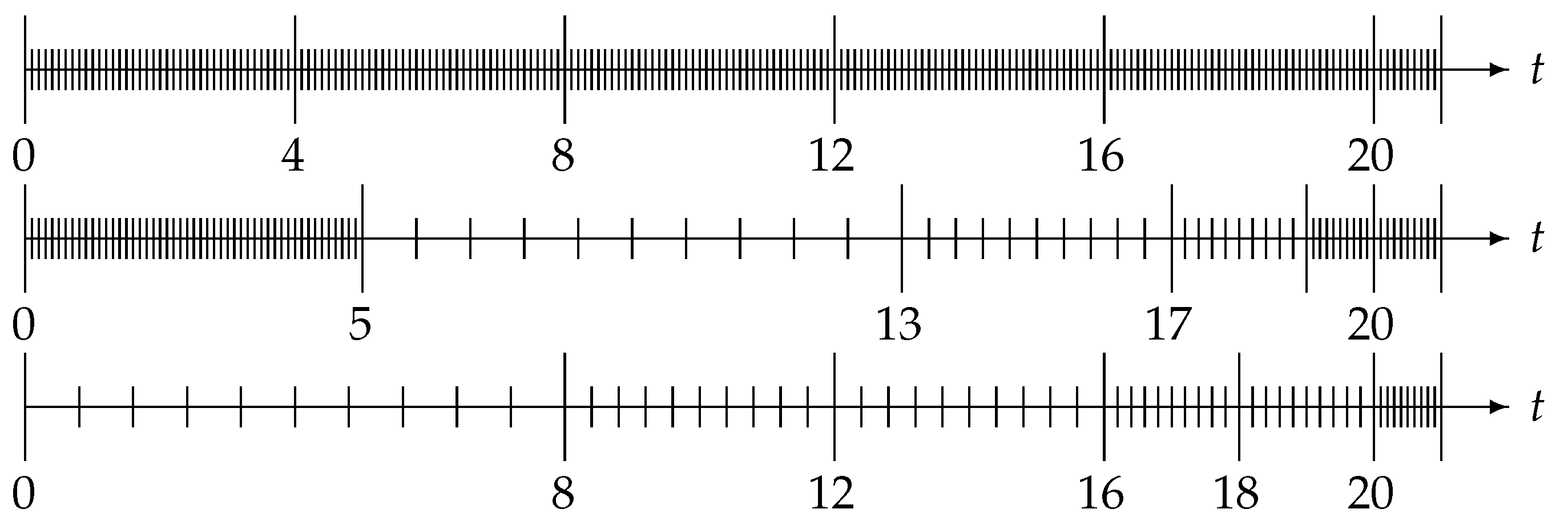
Specifically, as indicated in
Figure 1, the method of Ford and Simpson [
33] starts at the current time and fills subintervals of prescribed lengths from right to left with appropriately speced mesh points. This will lead to a reduction of the computational cost to
while retaining the convergence order of the underlying scheme [
33]. However, as indicated in
Figure 1, it is common that the left end point of the leftmost coarsely subdivided interval does not match the initial point. In this case, one can either fill the remaining subinterval at the left end of the full interval with a fine mesh (which increases the computational cost but also reduces the error) or simply ignore the contribution from this subinterval (which reduces the computational complexity but slightly increases the error; however, since the memory length still grows with the number of steps, this does not imply the complete loss of accuracy observed in the finite memory principle). In either case, grid points from the fine mesh that are not currently used in the nested mesh may become active again in future steps. Therefore, all previous grid points need to be kept in memory, so the required amount of memory space remains at
.
In contrast, the approach of Diethelm and Freed [
34] starts to fill the basic interval from left to right, i.e., it begins with the subinterval with the coarsest mesh and then moves to the finer-mesh regions. The final result is also a method with an
computational cost, and with the same convergence order as the Ford-Simpson method; but its selection strategy for grid points implies that points that are inactive in the current step will never become active again in future steps, and consequently the history data for these inactive points can be eliminated from the main memory. This reduces the memory requirements to only
.
6.2. A Method Based on the Fast Fourier Transform Algorithm
An effective approach for the fast evaluation of the convolution sums in (
17) was proposed in [
35,
36]. The main idea is to split each of these sums in a way that enables the exploitation of the fast Fourier transform (FFT) algorithm. To provide a concise description, let us introduce the notations
where
or
according to the formula used in (
17). Thus the numerical methods described by (
17) can be recast as
The algorithm described in [
35,
36] is based on splitting
into one or more partial sums of type
and just one final convolution sum
of a maximum (fixed) length
r. Thus, the computation is simply initialized as
and the following
r values of
are split into the two terms
Similarly, for the computation of the next
values,
is split according to
and the further
summations are split according to
and this process is continued until all terms
, for
, are evaluated.
Note that in the above splittings the length of each sum is always some multiple of r with a power of 2 as multiplying factor (i.e., the possible length of is r, , , and so on).
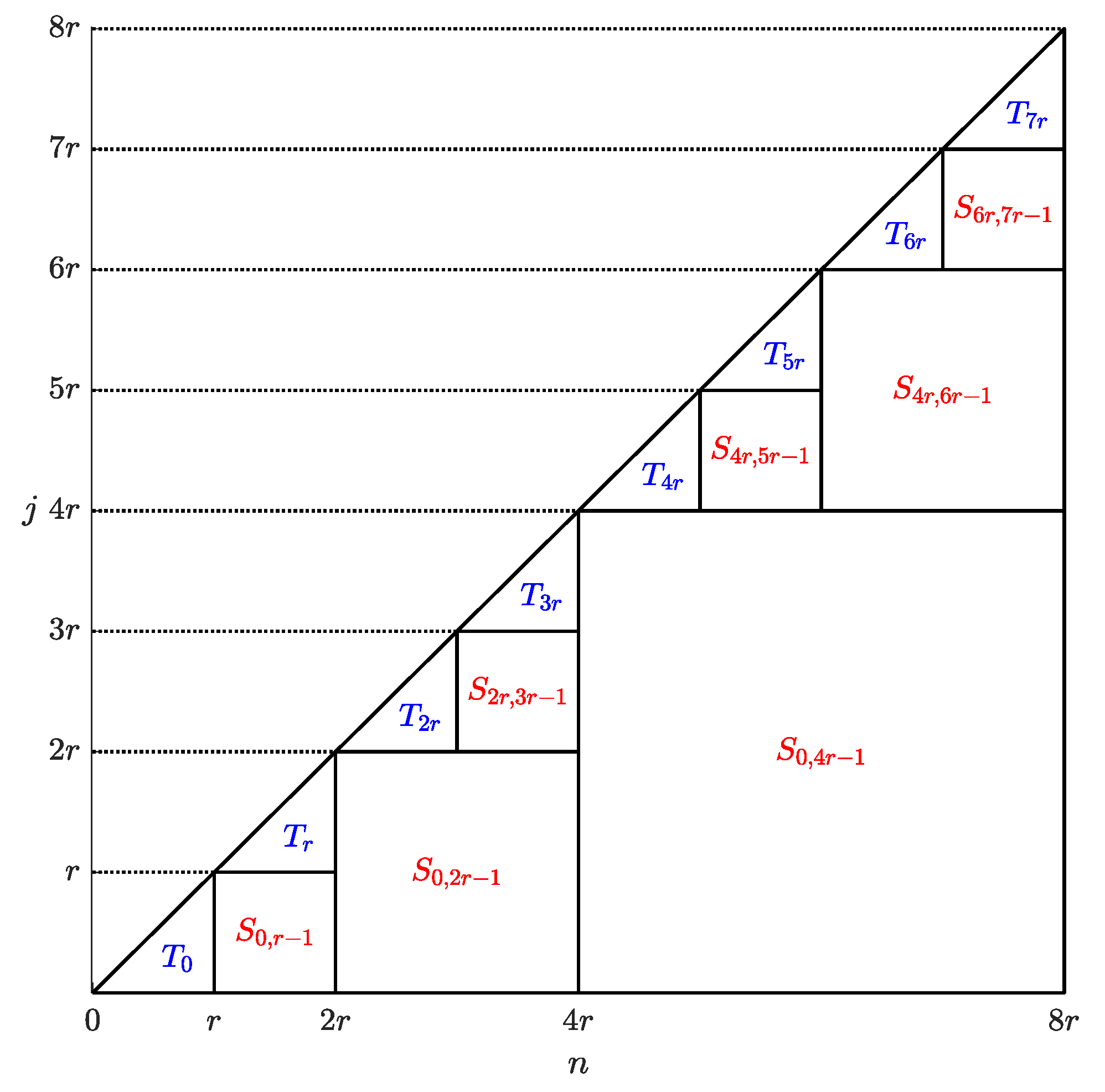
For clarity, the diagram in
Figure 2 illustrates the way in which the computation on the main triangle
is split into partial sums identified by the (red-labeled) squares
and final blocks denoted by the (blue-labeled) triangles
.
Each of the final blocks
,
, is computed by direct summation requiring
floating-point operations. The evaluation of the partial sums
can instead be performed by the FFT algorithm (see [
37] for a comprehensive description) which requires a number of floating-point operations proportional to
, with
the length of each partial sum
, since
r is a power of 2.
In the optimal case in which both
r and
N are powers of 2, each partial sum
that must be computed together with its length, number and computational cost is described in
Table 1.
Furthermore,
final blocks
, each of length
r, are also computed in
floating-point operations and hence the total amount of floating point operations is proportional to
which turns out, for sufficiently large
N, to be consistently significantly smaller than the number
required by the direct summation of
.
Although the whole procedure may appear complicated and requires some extra effort in coding, it turns out to be quite efficient since it can be applied to different methods of the form (
17) and does not affect their accuracy. This preservation of accuracy is because the technique does take into account the entire history of the process in the same way as the straightforward approach mentioned above whose computational cost is
. Thus, one does need to keep the entire history data in active memory, but one avoids the requirement of using special meshes. All the Matlab codes for FDEs described in [
10,
21,
38], and freely available on the Mathworks website [
39], make use of this algorithm.
6.3. Kernel Compression Schemes
Although the terminology “
kernel compression scheme” has been introduced only recently for a few specific works [
40,
41,
42], we use it here to describe a collection of methods that were proposed at various times by various authors and are all based on essentially the same principle: approximation of the solution of a non-local FDE by means of (possibly several) local ODEs. We provide here just the main ideas underlying this approach and we will refer the reader to the literature for a more comprehensive coverage of the subject.
Actually, these are standalone methods (usually classified as nonclassical methods [
43]) and not just algorithms improving the efficiency of the treatment of the memory term; for this reason they could have been discussed in
Section 3 along with the other methods for FDEs. But since one of their main achievements (and the motivation for their introduction) is to handle memory and computational issues related to the long and persistent memory of fractional-order problems, we consider it appropriate to discuss them in the present section.
For ease of presentation we consider only
but the extension to any positive
is only a technical matter. The basic idea starts from some integral representation of the kernel of the RL integral (
1), e.g.,
which, thanks to standard quadrature rules, can be approximated by exponential sums
where the error
and the computational complexity related to the number
K of nodes and weights depend on the choice among the many possible quadrature rules. When applying this approximation instead of the exact integral in the integral formulation (
7), the solution of the FDE (
6) is rewritten as
Each of the integrals in (
20) is actually the solution of an initial value problem:
which can be numerically approximated by standard ODE solvers, yielding approximations
on some grid
. If the quadrature rule is chosen so as to make the error
so small that it can be neglected, an approximate solution of the original FDE (
6) can be obtained step-by-step as
where each
depends only on
or on a few other previous values, according to the selected ODE solver.
In practice, a non-local problem (the FDE) with non-vanishing memory is replaced by
K local problems (the ODEs) each demanding a smaller computational effort and the memory storage is restricted to
if a
p-step ODE solver is used for each of the ODEs (
21).
Obviously, the idea sketched above requires several further technical details to work properly. First, an accurate error analysis is needed to ensure that the overall error is below the target accuracy. This is a very delicate task because it involves the investigation of the interaction between the quadrature rule used to approximate the integral in (
20) and the ODE solver applied to the system (
21), which can be a highly nontrivial matter. Moreover, some substantial additional problems must be addressed. For instance,
A-stable methods should generally be preferred when solving the system (
21) since some of the
can be very large and give rise to stiff problems.
A non-negligible issue is that it is not possible to find a quadrature rule approximating (
18) in a uniform manner with respect to all relevant values of
t, i.e. with the same accuracy for any
where
is the first mesh point to the right of the initial point
or for all
(in either case, the singularity at
indeed makes the integral quite difficult to be approximated). To overcome this difficulty, several different approaches have been proposed.
In a series of pioneering works [
44,
45,
46], where a complex contour integral
is chosen to approximate the kernel, the integration interval
is divided into a sequence of subintervals of increasing lengths, and different quadrature rules (on different contours
) are used in each of these intervals. While high accuracy can be obtained, this strategy is quite complicated and requires the use of more expensive complex arithmetic.
In [
40,
41,
42] the integral in (
7) is divided into local and history terms
for a fixed
. This confines the singularity of the kernel to the local term, which can be approximated by standard methods for weakly singular integral equations (e.g., a product-integration rule) with a reduced computational cost and an insignificant memory requirement. The kernel in the history term no longer contains any singularity and can be safely approximated by (
19) which applies now just for
.
To obtain the highest possible accuracy, Gaussian quadrature rules are usually preferred. A rigorous and technical error analysis is necessary to tune parameters in an optimal way. Several implementations of approaches of this kind have been proposed (e.g., see [
47,
48,
49,
50,
51]) but owing to their technical nature, a comparison to decide which method is in general the most convenient is difficult; we just refer to the interesting results presented in [
52].
7. Some Remarks about Fractional Partial Differential Equations
Even though this paper is essentially devoted to the numerical solution of ordinary differential equations of fractional order and the computational treatment of the associated differential and integral operators, a few comments should be made regarding numerical methods for partial fractional differential equations (PDEs).
Remark 3. The issues discussed in Section 4 are relevant to partial differential equations also. Indeed, it is shown in [53] that imposing excessive smoothness requirements on the solutions to a partial differential equation (e.g., for the sake of simplifying the error analysis or for obtaining a higher convergence order) has drastic implications regarding the class of admissible problems; in particular, the choice of the forcing function in a linear initial-boundary value problem will then completely determine the initial condition in the problem. Our second remark regarding partial differential equations deals with a totally different aspect.
Remark 4. Typical algorithms for time-fractional partial differential equations contain separate discretisation techniques with respect to the time variable and the space variable(s). A current trend is to employ a very high order method for the discretisation of the (non-fractional) differential operator with respect to the space variable. While this might seem an attractive approach at first sight, it has a number of disadvantages. Specifically, while this leads to a smaller discretization error in the space variable, it also increases the algorithm’s overall complexity and makes the understanding of its properties more difficult. This complexity would be acceptable if the overall
error could be reduced significantly. But since the overall error comprises not only the error from the space discretisation but also the contribution from the time approximation, it follows that to reduce the overall error, one must force this latter component to be very small also. As indicated above, we cannot expect to achieve a high convergence order in this variable, so the only way to reach this goal is to choose the time step size very small (in comparison with the space mesh size). From Section 6 we conclude that a standard algorithm with a higher-than-linear complexity is likely to lead to prohibitive run times, and even if the time discretisation uses a method with a linear or almost linear complexity, this very small step size requirement will still imply a high overall cost. Therefore, the use of a high-order space discretisation in a time-fractional partial differential equation is usually inadvisable. 8. Concluding Remarks
In this paper we have tried to describe some issues related to the correct use of numerical methods for fractional-order problems. Unlike integer-order ODEs, numerical methods for FDEs are in general not taught in undergraduate courses and, very often, non-specialists are unaware of the peculiarities and major difficulties that arise in the numerical treatment of FDEs and fractional PDEs.
The availability of only a few well-organized textbooks and monographs in this field, together with the presence of many incorrect results in the literature, makes the situation even more difficult.
Some of the ideas collected in this paper were discussed in the lectures of the Training School on “Computational Methods for Fractional-Order Problems”, held in Bari (Italy) during 22–26 July 2019, and promoted by the Cost Action CA15225—Fractional-order systems: analysis, synthesis and their importance for future design.
We believe that the scientific community should make an effort to raise the level of knowledge in this field by promoting specific academic courses at a basic level and/or by organizing training schools.






{kind=link}
{kind=link}