The proposed framework is shown in
Figure 1 with three major processes, including
data federation,
data linkage, and
knowledge discovery. On the server-side, data from multiple data sources were preprocessed and connected through a VDB in Teiid server (
teiid.io). Different techniques are firstly applied to process raw data, including generating RDF (RDF Generator) from raw data and indexing text-based data. Association rule analysis is applied to support knowledge discovery, such as exploring hidden patterns and co-occurrences of variables from multiple data sources in intuitive ways with visualization. After data exploration, users can explore the user text data in more detail and find relations between users based on their written texts by using RDF and NLP. Afterwards, users can go to the module of Data Search and issue queries across RDF endpoints for general/specific data analytics to confirm the hidden patterns they found at a large scale on all user records (i.e., 1.4M records). On the end-user side, users can explore metadata of all data sources, and further interact with them through SPARQL queries to get data analysis results.
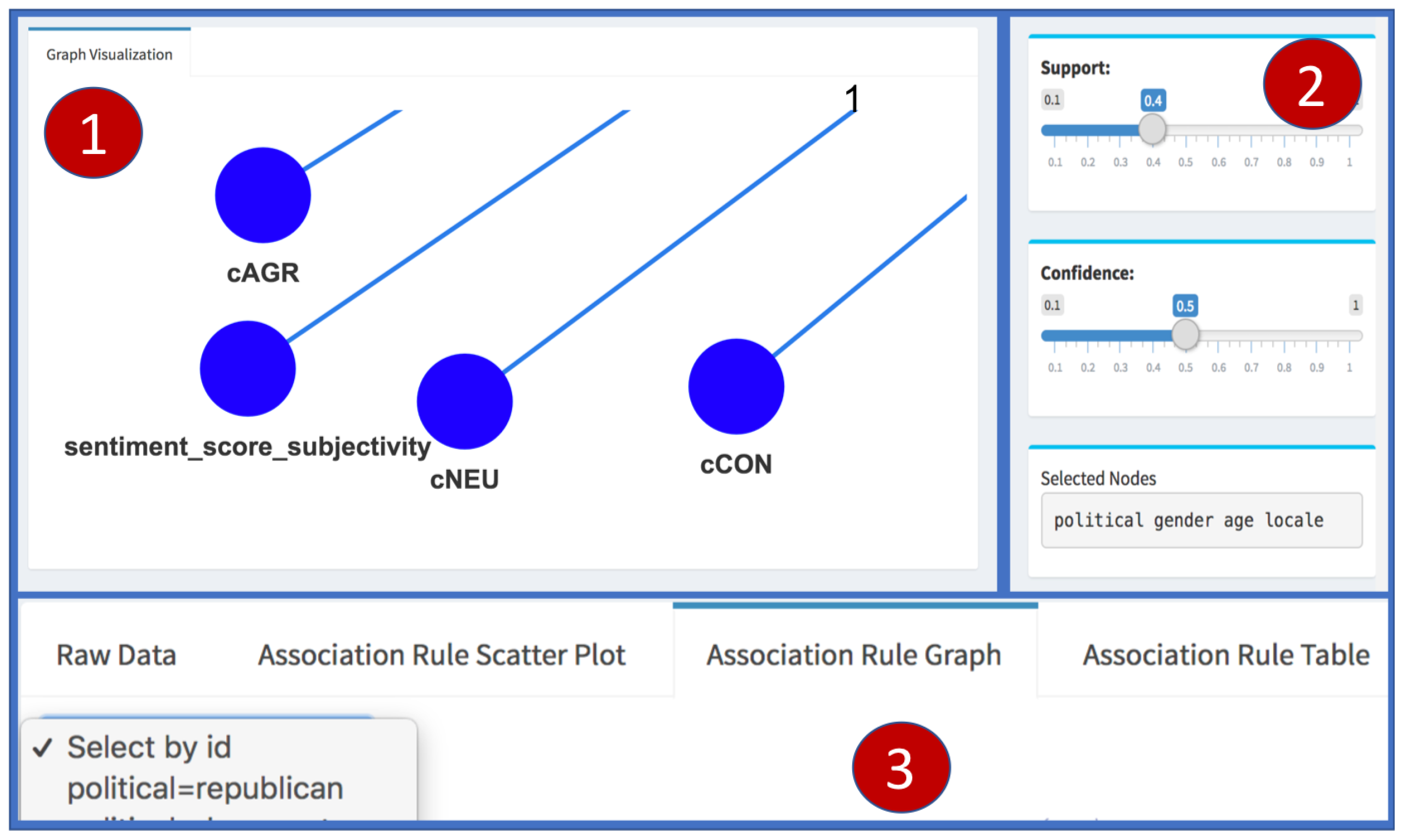
The proposed approach was implemented using R, a language and environment for statistical computing and graphics. The data federation mechanism was built on Teiid. We developed the interactive and user-friendly interfaces using Shiny (
shiny.rstudio.com/) and ArulesViz [
24],
Figure 2 presents the user interface of the system. For RDF storage, we built an RDF Generator to generate RDF files from VDB (Virtual Data Bases) and stored them in Apache Jenna Fuseki (
jena.apache.org). Furthermore, to ensure high-performance data retrieval, we used ElasticSearch and Kibana.
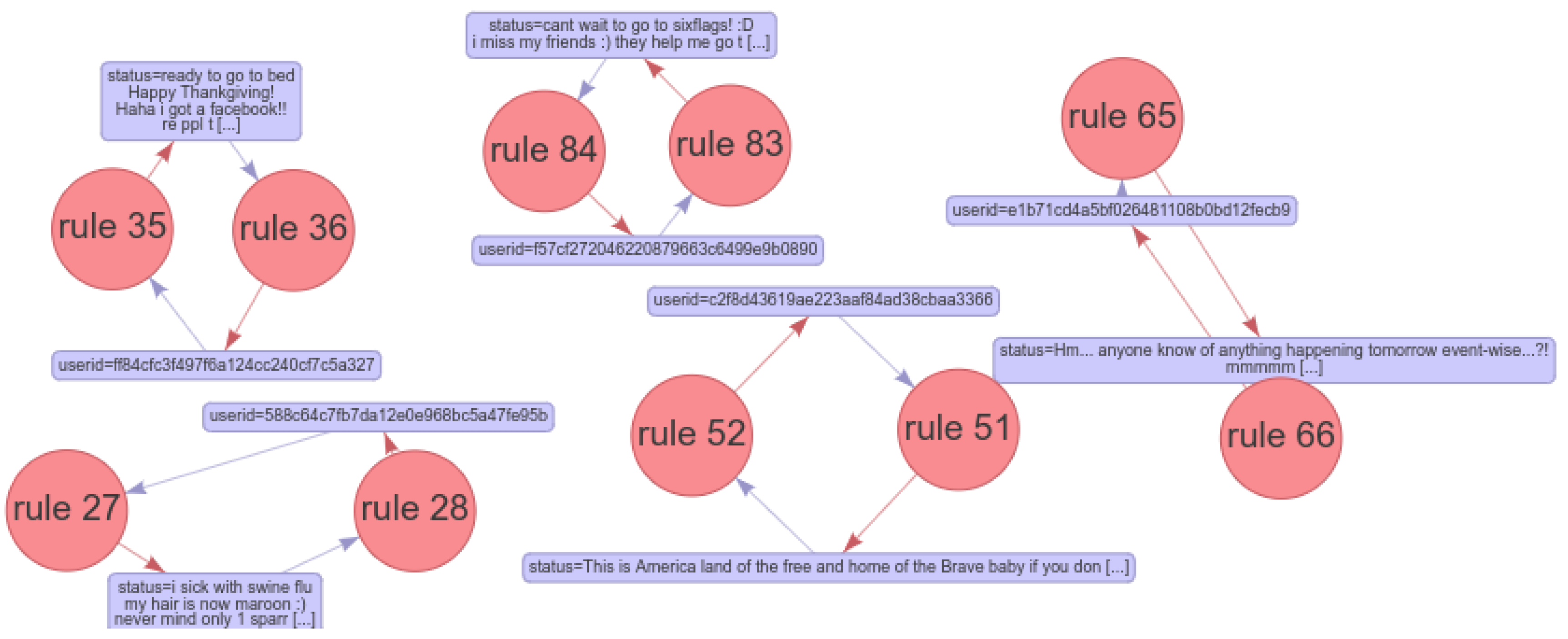
Data Linkage. It is a method of linking information from different sources into a single population that enables the construction of a chronological sequence of information. In this context, we applied semantic Web technologies (e.g., RDF, SPARQL) for data linkage, and our RDF Generator converts raw data to a unified RDF format as shown in
Figure 1. Since we have multiple data sources federated in different locations and formats, the RDF Generator automatically maps required variables based on user queries, to return related records for further data analysis. Afterwards, we applied the inverted indexing schema from ElasticSearch (
www.elastic.co) (ES) for data indexing.
3.1. Association Rules Extraction and Classification
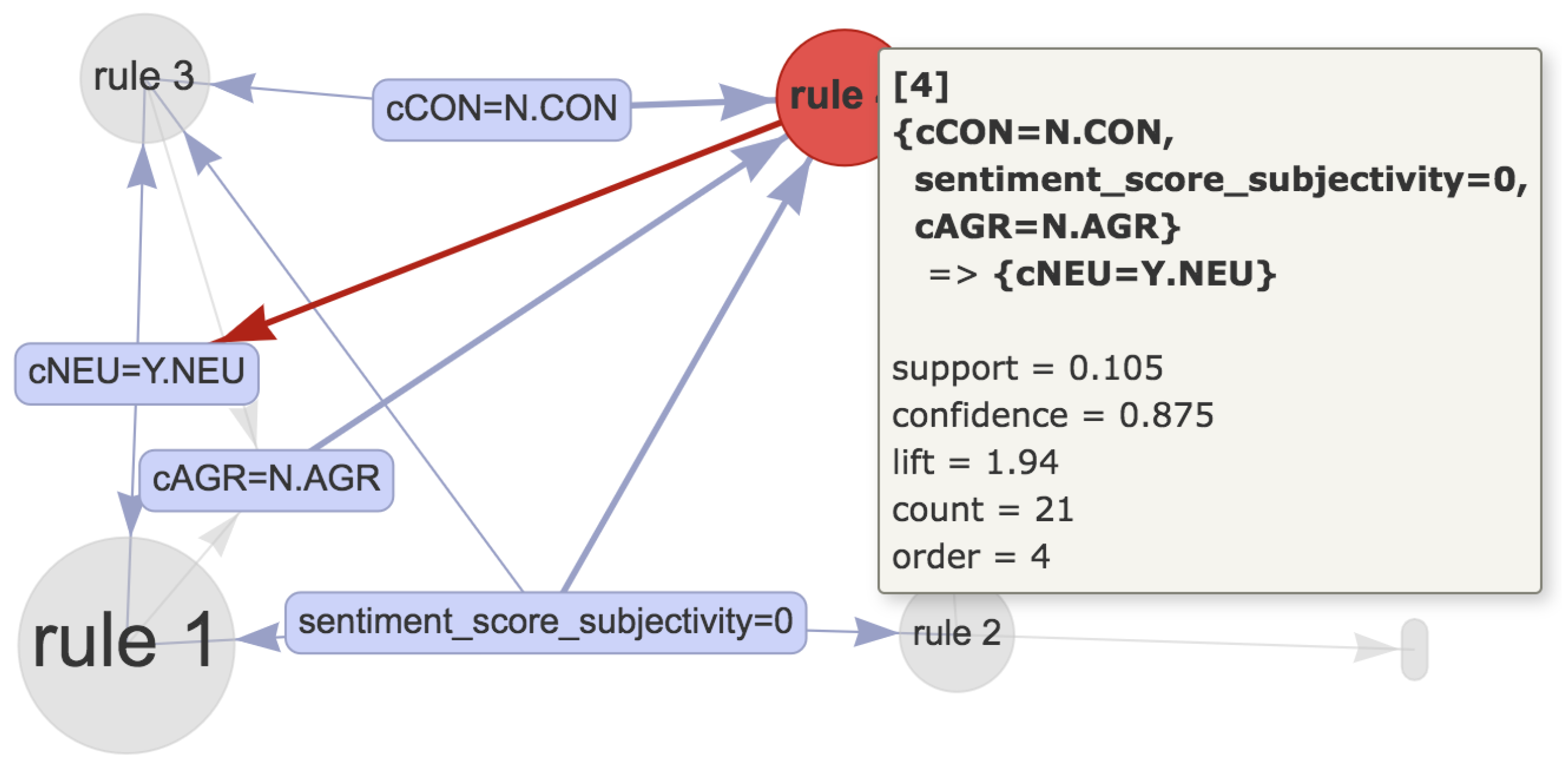
Association rules extraction. After understanding the data sources, users are enabled to use data mining algorithms to extract patterns and correlations over data variables. We took the association rules [
25] technique as an example to show how data mining techniques discover the relationship between variables in federated data. The Apriori algorithm [
25] was applied to extract association rules among variables over the federated data and to generate association rules. For example, the variables age (e.g., 31–40), gender (e.g., female), and relation status (e.g., married), can present an association rule graph with another variable “personality”(e.g., neuroticism, low-score agreeableness, etc.).
Classification based on association rules (CBA) [
26]. Classification is one of the main techniques of data mining and machine learning. The idea is to utilize frequent patterns and relationships between objects and class labels in training data set to build a classifier. For classification based association rules in myPersonality dataset, there is a pre-determined target (i.e., the class such as democrat, republican, etc.). The rule classification is done by focusing on the right-hand-side (RHS) subset as a restricted class attribute; we refer to this subset of rules as the class association rules. Let
D be the dataset, and
a set of items, and
Y be the set of class labels. A class association rule set (
CARs) is a subset of association rules with classes specified as their consequences. The rule
has support value of
s in
D if
s of the cases in
D contain
X and are labeled with class
y. The CBA algorithm consists of two parts, a rule generator, which is based on the Apriori algorithm [
25], and a classifier builder (called CBA-CB) using
CARs generated by rule generator. To build a classifier, let
and
D a training dataset, the idea is to choose a set of high precedence rules (
has a higher precedence than
if
or
) in
R to cover
D (see the illustration section for case study).
3.2. Mining Semantic Association Rules
Linked data is mostly presented in the RDF triples (SPO). However, these data are incomplete in reality; it requires promising techniques to explore and extract new facts, especially from text data. Association rule mining is a promising approach to generate such new relations, as we show in this paper. We proposed an approach (
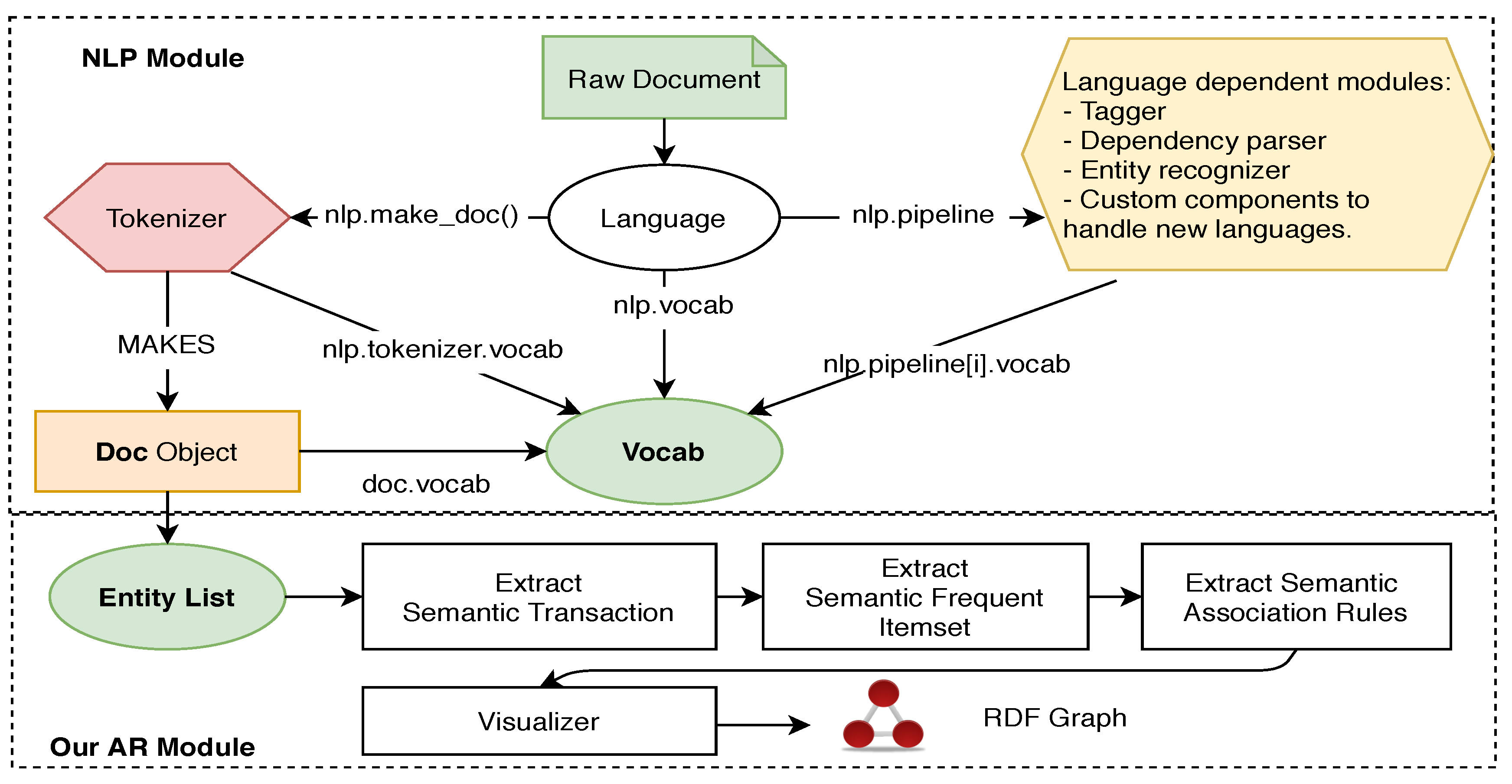
Figure 3) based on association rules mining by using NLP techniques to generate new relations from text data that can be used to enrich knowledge bases and knowledge graph representation, particularly myPersonality knowledge base.
As shown in
Figure 3, the given data (i.e., FB Status Updates—FB Posts) is processed by the NLP pipeline empowered by SpaCy NER module (
spacy.io), hereafter, the NLP module. The reason we chose SpaCy are: (1) it supports multiple languages; and (2) it allows us to customize and train the NLP models to adapt new datasets. Moreover, two peer-reviewed papers [
27,
28] confirmed that SpaCy offers the fastest syntactic parser and reasonable accuracy, as shown in
Table 1. Besides,
Table 2 presents a comparison between different NLP libraries in terms of features.
More about the NLP module in
Figure 3, starting from the Language object, it coordinates other components, including the Tokenizer, an NLP pipeline (Tagger, TextCategorizer, Entity Recognizer, etc.). This module takes the central data which is a text corpus (raw data) and returns an annotated document. The Doc object owns the sequence of tokens and all their annotations, while the Vocab object owns a set of look-up tables that make common information available across documents. By centralizing strings and lexical attributes, SpaCy avoids storing multiple copies of this data. This is another reason why we chose to use SpaCy to save the memory of the whole system. The final list of extracted entities and their types are stored in the Doc object. After the NLP Module, the Entity List was achieved based on multiple FB Posts. Then, it is sent to the AR module, which includes (1) Semantic Transaction Extractor, (2) Semantic Frequent Itemset Extractor, (3) Semantic Association Rules Extractor, then finally, (4) the Visualizer for displaying the RDF graph. The extraction of semantic association rules from the FB Posts is important for different research topics such as personality prediction, emotional and sentiment analysis etc [
29].
To the former reason, the NLP Module allows our system to support other languages to apply our proposed approach. The myPersonality dataset contains FB Posts of users in many different countries [
30]. And up to date, SpaCy has supported ten languages, such as English, German, French, etc. Therefore, based on SpaCy, our framework can process and understand multiple languages existing in user text data. To the latter reason, from the fact that user texts usually are very noisy; therefore, the ability to customize the NLP Module is a key factor for us to improve the system in the future. However, to support SpaCy in the R framework, we had to solve some software engineering problems, including how to integrate and run python inside R seamlessly. Finally, we showed that this challenge is possible to solve, which makes our system more robust to adapt to new requirements in the future.
Improve KG by using extracted entities. This approach provides an effective way to describe entities and their relationships. We use extracted entities from texts since they contain huge information from a variety of sources that can be used in semantic search, question answering, pattern mining, and sentiment analysis. In this work, we focus on the myPersonality dataset, especially FB Posts, using NER and data mining algorithms. We apply these techniques for constructing KG, including personality knowledge extraction, sentiment analysis, and community detection. Moreover, We link the extracted entities from FB posts to some external knowledge bases (i.e., DBpedia [
31] and Google knowledge graph).
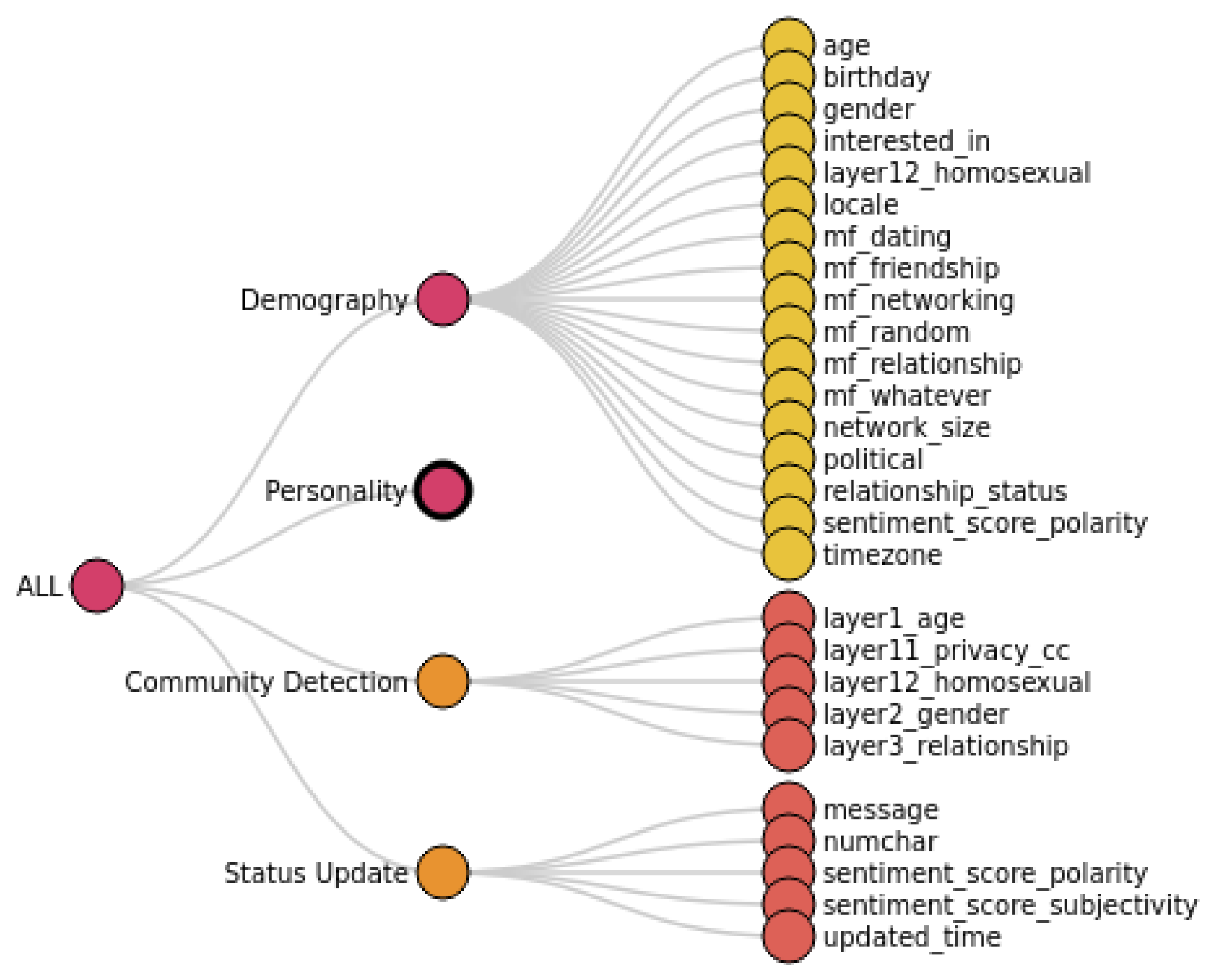
Table 3 presents a non-exhaustive list of extracted entities from text updates to be used in the next step for extracting semantic association rules.
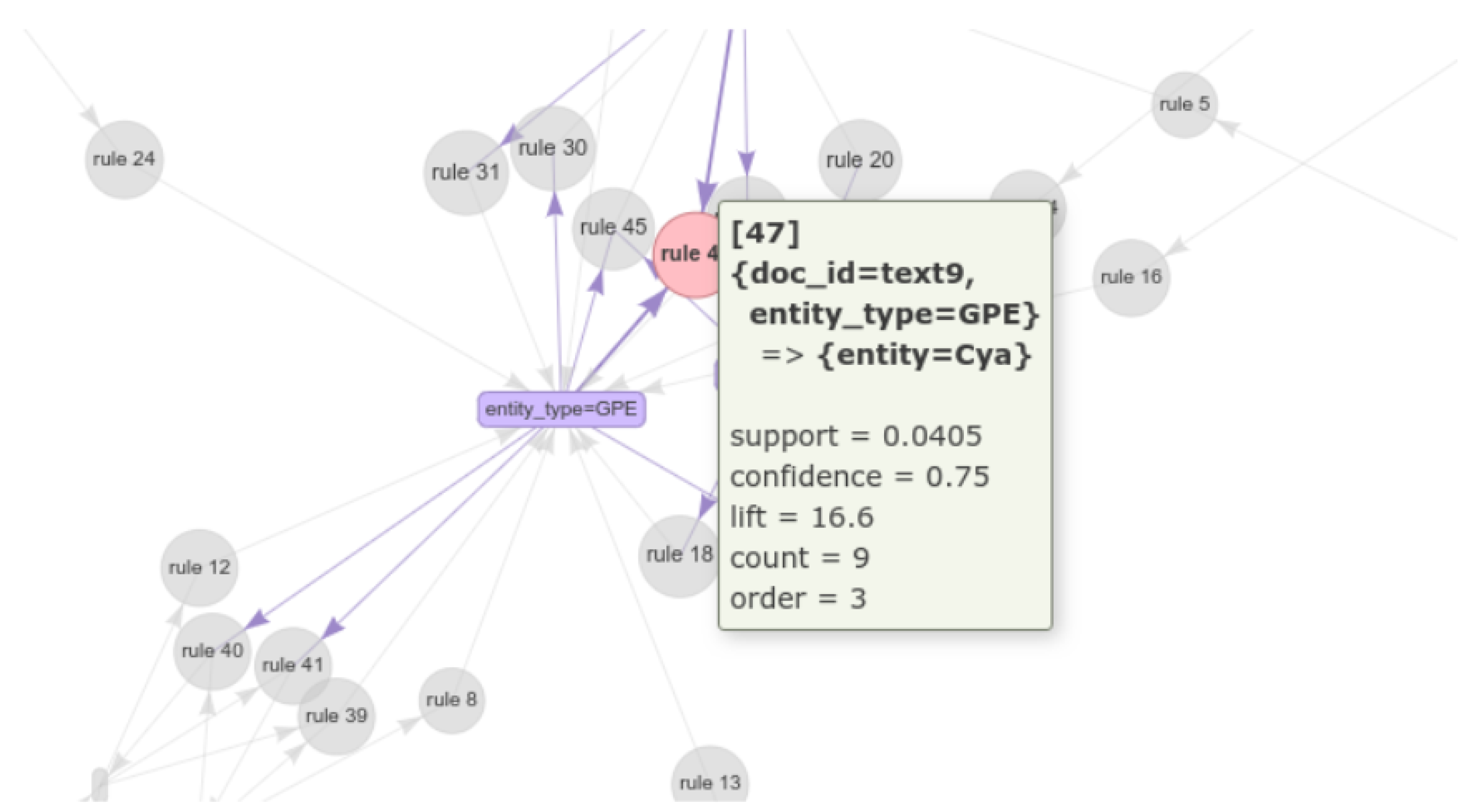
Mining semantic association rules from entities. Users are guided to enhance the analysis by using data mining techniques to explore patterns and correlations between extracted entities. We take the association rules technique as an example to show how data mining techniques discover the relationship between different entities in the FB Posts data. This step lets the user grasp newly discovered hidden relationships between the user’s FB posts that can be used to enrich KG representation.
To extract semantic association rules, semantic transaction
can be generated from the Entity List by using the proposed algorithm 1. The algorithm takes all FB Posts as the input and then generates entities (
Table 3) and semantic transaction list (STL) as the output. It extracts a list of entities
E for each FB post and stores them in
(lines 4–7), for each FB post, we extract a semantic transaction (ST) by generating a new subject and a list of its entities (lines 8–12). When there are no more entities, the algorithm creates a new subject and adds it to the semantic transaction list. The algorithm finally returns the list of ST (Subject, Object). After generating a semantic transaction, we fit the dataset to traditional algorithms such as Apriori [
25] to generate frequent semantic itemset and then generate semantic association rules (lines 13–15). This step requires some thresholds, including minimum support and the minimum confidence to evaluate the extracted rules.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}