1. Introduction
Determination of relevant predictors in many fields of human life is important research challenge, including medicine. Research described in this paper is motivated from the fact that from one side, the liver disease causes about 3.5% of all deaths, which is a big number from approximately two million deaths per year worldwide, and that bleeding of varices is most common complication for successful treatment of liver cirrhosis [
1]. On the other side, fact that the development of improved computer solutions for prediction of factors of bleeding, at the beginning of the 21th century, enables significantly more comprehensive, accurate, and fast diagnosis. Namely, the best way to determine esophageal varices is through gastrointestinal endoscopy. Since less than 50% of cirrhotic patients have varices and endoscopy is a nonconforming intervention, this way, a noninvasive methodology for predicting patients with the highest risk of bleeding and then applying endoscopy is the right choice [
2]. In that way, good prediction indirectly reduces mortality of cirrhosis patients caused by bleeding of varices, so that further researches in this area impose itself as a serious challenge [
3].
Basic idea of authors in research proposed in this paper was to apply concept of the classification algorithm, as one of a group of machine learning algorithms, so that a two-class classifier classifies the results into two classes, which is in each classification procedure completely defined with suitable 2 × 2 confusion matrix that content number of a true and false positive classification attempts and true and false negative classification attempts and could be applied in prediction of significant factors for bleeding in liver cirrhosis. Namely, concepts of diagnostic sensitivity and specificities are commonly used in the field of laboratory medicine [
4]. Diagnostic test results are classified as positive or negative, where positive results imply the possibility of illness, whereas negative results indicate higher probability of absence of the illness. However, most of these tests are conducted by the instruments with high but not perfect accuracy, thus introducing certain errors in the diagnosis results and causing false positive and false negative results. Diagnosis sensitivity that is also known as true positive rate represents the possibility to detect ill patients actually, and it is defined as the number of true positive over the total number of ill patients, including the true positive and false negative patients. Hence, proper detection should discover patients with positive results within ill patients. On the other hand, specificity that is also known as a true negative rate represents possibility to detect healthy patients, and it is defined as the number of true negative patients over the total number of healthy patients, including the true negative and false positive ones. Thus, proper determination should also provide negative result for healthy patients. Assuming that determination provides only positive result, then the sensitivity will be 100%, but in that case, healthy patients would be falsely identified as ill [
5]. In theory of statistic, experiments can be used to affirm hypotheses on differences and relationship between two or more groups of variables, and such experiments are called tests, or they can be used to determine influence of variables on dependent variable(s), such multifactor experiments are called valuations, [
6] and such one is applied in the presented case study in this paper. Data mining approach, where belongs classification methodology, has been widely used in different fields of human life, such as economics [
7], justice [
8], medicine [
9], etc. Data mining has also been applied for solving various problems, especially in diagnosis in medicine [
10] and in the field of diagnosis of liver cirrhosis as in [
11]. Bioinformatics and data mining have been the research hot topics in the computational science field [
12,
13,
14,
15,
16]. Data mining is generally a two stage methodology that in the first stage involves the collection and management of a large amounts of data, which in second stage is used to determine patterns and relationships in collected data using machine learning algorithms. [
17,
18,
19,
20].
It is known that esophagus bleeding is not only the most frequent but also the most severe complication in cirrhotic patients that directly threatens patient’s life [
21,
22,
23,
24]. Because of this fact, the main objective of this paper is to analyze as many factors as possible, which cause this bleeding, and specifically in this study, we have determined 29 factors, which belong to different types of data, from clinical and biochemical view, obtained via endoscopic and ultrasound data to the color Doppler data. In this way, we aimed to be as comprehensive as possible and determine and rank these factors as risk indicators of varices bleeding. Consequently, due to high mortality ratio caused by bleeding of varices, considering the bleeding risk assessment is crucial for proper therapy admission. The case study, we included 96 cirrhotic patients from the Clinical Center of Nis, Serbia. This mentioned study studied risks of initial varices in cirrhosis patients, as well as risks of early and late bleeding reoccurrence. As the main result of this study, authors proposed model which predicts the assessment of the significance of the individual parameters for variceal bleeding and survival probability of cirrhotic patients, which is in addition to the above adequate therapy very important and for determination of patient priority on the liver transplant waiting lists. Namely, in literature and practice connected with the problem of bleeding in liver cirrhosis, we can find research gap between request that for considering this problem, it is necessary to include more different types of parameters and, e.g., uncomfortable endoscopy, which, in turn, may be cost ineffective because less than 50% of a cirrhosis patients are with varices, from the medical standpoint from one side [
25]. From the other mathematical side, we have the research gap between the need to include as many factors as possible in the consideration of bleeding problems in liver cirrhosis, which, in turn, cause the undesirable occurrence of noise in the data and, consequently, the need to reduce their number provided that the accuracy of the prediction is maintained [
26]. Due to this fact, it is becoming more common request for using more noninvasive factors as possible, which is commonly solved using data mining technique. We can find more articles that deals with using different techniques of data mining for determination of risk indicators in different complications in disease liver cirrhosis [
27,
28,
29] and risk for variceal bleeding as in [
30,
31]. Because two main methodologies of data mining approach are used in this paper, data mining classification technique with feature selection and logistic regression for prediction of variceal bleeding in cirrhotic patients, it is necessary to present the state of the art closely observed on the subject methodology, which solves the considered problem. This enabled authors to produce one new ensemble data mining model whose validity is proven by the results obtained in the case study. In literature, we find few papers that deals with machine learning approaches, which studied general complications in liver cirrhosis disease as, e.g., in [
32,
33], also on prediction of esophageal varices [
34,
35,
36,
37,
38], and we found different forms of their integration but we did not find integration that we propose in this paper.
Authors as the subject of the paper set the answer to the research question, i.e., proof of the hypothesis, that it is possible to integrate classification method with attribute reduction also and regression into one ensemble method, which has better characteristics than each of them individually applied. To confirm the hypothesis and answer the research question, the authors used the results obtained with application of their novel proposed model in the case study described in previous paragraph of this section.
The remaining of this paper is organized as follows. After
Section 1 Introduction, which after short explanation of motivation for authors to work on this paper, describes in four paragraphs the concept, objectives and existing research gap, contribution, and the organization of the paper and gives author’s review of world literature which deal with bleeding problems in liver cirrhosis as well as with application of classification and logistic regression in prediction models, the other sections continues. Next,
Section 2 Materials and Methods is part of paper that presents the background, which enables solving of the considered problem to be solved in this paper, introducing the methodology adopted in the proposed solution. In
Section 3 Results are presented results obtained with proposed new methodology at concrete case study performed in the Clinical Center of Nis, Serbia. In
Section 4 Discussion, authors discuss possibilities of theirs proposed approach and especially to clinical interpretation of the results, and in the end of this paper are conclusion remarks in
Section 5 Conclusions.
3. Results
The study from Benedeto-Stojanov and other coauthors in [
36] involved 96 subjects, 76 (79.2%) male and 20 (20.8%) female participants. There were 55 patients without bleeding, of which 44 (80.0%) were male and 11 (20.0%) were female. The group of 41 patients with bleeding included 32 (78.0%) male and 9 (22.0%) female participants. The average age of all patients was (56.99 ± 11.46) years. The youngest and oldest patients were 14 and 80 years old, respectively.
The data used in the study were obtained by the Clinical Center of Nis, Serbia. The original feature vector of patient data consisted of 29 features that were predictive variables. As the thirtieth variable, there was a two-case class variable result (yes/no), which was considered as a dependent variable. All predictive variables and dependent variable are shown in
Table 2, where it can be seen that they were of numerical data type.
In the case study, five classification algorithms were implemented, i.e., Naive Bayes, J48, Decision Trees, HyperPipes, Ada LogitBoost, and PART for designing prediction modes. Method of training set was applied in model for proposed classification algorithms where the authors chose the most famous from different groups of classifiers. This method was chosen and training set mode combined with test as well as 10-cross validation were not used because of a small number of instances in the case study.
The performance indicators of five classification algorithms are given in
Table 3, where it can be seen that the LogitBoost classifier achieved the most accurate prediction results among all the models.
As presented in
Table 3, the LogitBoost classifier achieved the F1 measure of 97.9%, accuracy of 98.0% (0.980), and the ROC of 0.999.
In
Table 4,
CCI denotes the number of correctly classified inputs, and
ICI denotes the number of incorrectly classified inputs.
The LogitBoost classifier achieved a relatively good performance on classification tasks, due to the boosting algorithm [
65]. Boosting process is based on the principle that finding many rough rules of thumb can be much easier than finding a single, highly accurate prediction rule. This classifier is a general method for accuracy improvement of learning algorithms. In the WEKA [
66], LogitBoost classifier is implemented as class which performs additive logistic regression, which performed classification using a regression scheme as a base learner, and also can handle multiclass problems.
Feature selection is normally realized by searching the space of attribute subsets and evaluating each attribute. This is achieved by combining attribute subset evaluator with a search method. In this paper, five filter feature subset evaluation methods with a rank search or greedy search method were conducted to determine the best feature sets, and they are listed as follows:
- (1)
Chi-square attribute evaluation (CH),
- (2)
Gain-ratio attribute evaluation (GR),
- (3)
Information-gain attribute evaluation (IG),
- (4)
Relief attribute evaluation (RF) and
- (5)
Symmetrical uncertainty attribute evaluation (SU).
The feature ranks obtained by the above five methods on the training data are presented in
Table 5.
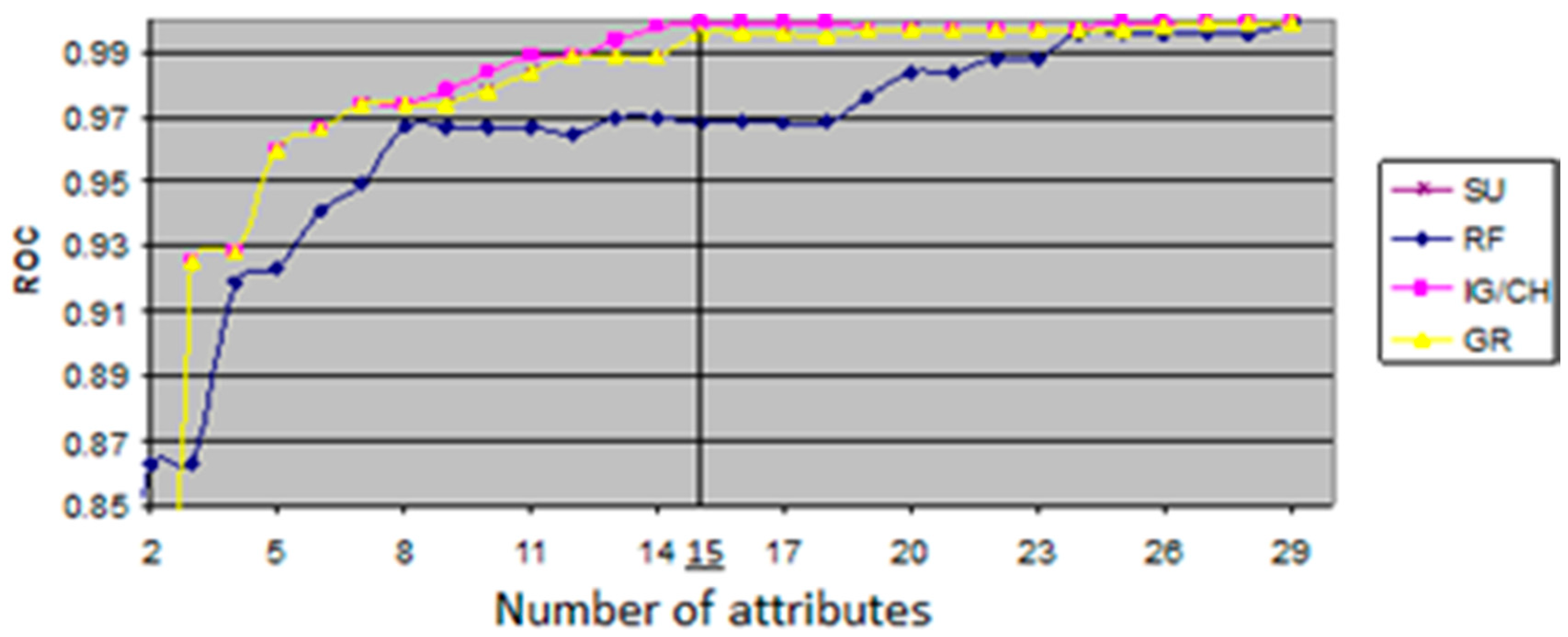
The ROC value shows relationship between sensitivity, which represents measure of the proportion of positives that are correctly identified TP, and specificity, which represents measure of the proportion of negative that are correctly identified, both in executed process of classification. The evaluation measures with variations of ROC values were generated from an open source data mining tool, WEKA, that offers a comprehensive set of state-of-the-art machine learning algorithms as well as set of autonomous feature selection and ranking methods. The generated evaluation measures are shown in
Figure 2, where the
x-axis represents the number of features, and the
y-axis represents the ROC value of each feature subset generated by five filter classifiers. The maximum ROC value of all the algorithms and the corresponding cardinalities that are illustrated in
Figure 2 are given numerically in
Table 5. This is quite useful for finding an optimal size of the feature subsets with the highest ROC values. As given in
Table 5, the highest ROC values were achieved by CH and IG classifiers. Although the CH and IG resulted in the ROC value of 0.999, the IG/CH could attain the maximum ROC value when the number of attributes reached the value of 15. Thus, it was concluded that IG has an optimal dimensionality in the dataset of patients.
The top ranking features in
Table 5 that were obtained by CH and IG classifiers were used for further predictive analysis as significant predictors of bleeding, and they were as follows: (A15)—Red color signs, (A14)—large esophageal varices, (A17)—congestive gastropathy, (A7)—international normalized ratio, (A23)—collateral circulation, (A24)—flow speed in portal vein, (A9)—ascites, (A8)—creatinine, (A6)—prothrombin time, (A29)—MELD score, (A2)—age, (A5)—albumin, (A11)—platelet count/spleen diameter ratio, (A3)—etiology, and (A25)—flow speed in lienal vein.
This study analyzes risks of initial bleeding of varices in cirrhotic patients, and the risks of early and late bleeding reoccurrence. The obtained results are important for further treatment and prevention of bleeding from esophageal varices, the most common and life-threatening complications of cirrhosis. Coauthors in this manuscript, Randjelovic and Bogdanovic, still used the univariate logistic regression analysis to demonstrate the most significant predictors of bleeding. Results of this analysis obtained using same input data are given in
Table 6 [
67].
After conducting the experiment with the real medical data, important predictors of bleeding were determined by performing logistic regression analysis.
Univariate logistic regression analysis indicated the most significant predictors of bleeding in cirrhotic patients: the value of the Child–Pugh/Spleen Diameter ratio, platelet count, as well as the expression of large esophageal varices, red color signs, gastric varices, and congestive gastropathy collateral circulation. Approximate values were calculated relative risk (odds ratio—OR), and their 95% confidence intervals. The statistical significance was estimated by calculating the OR Wald (Wald) values.
The increase in the value of Child–Pugh/Spleen Diameter ratio for one unit resulted in the reduction in the risk of bleeding by 0.2% (from 0.1% to 0.3%, p < 0.05), while the increase in platelet count to 1 × 109/L yielded to the decrease in risk of bleeding by 0.8% (from 0.1% to 1.5%, p < 0.05). Expression of the following factors indicating an increased risk of bleeding: large esophageal varices 24.589 (7.368–82.060, p < 0.001), red color signs 194.997 (35.893–1059.356, p < 0.001), gastric varices 4.110 (1.187–14.235, p < 0.05), congestive gastropathy 10.153 (3.479–29.633, p < 0.001), and collateral circulation 1.562 (1.002–2.434, p < 0.05).
Following performed univariate logistic regression analysis, it is enabled that previously acquired set of 15 attributes with attribute rank given in columns one (CH) and three (IG) of
Table 5 can be calibrated using results for OR given in column three (OR) in
Table 6. The calibration process is showed in
Table 7. It was carried out so that the mentioned set of 15 attributes from
Table 5, which is given in the first row of
Table 7 using extracting those of the 15 attributes for which OR > 1 in
Table 6 is given in the second row of
Table 7 and using extracting those of the 15 attributes for which OR < 1 in
Table 6 is given in the third row of
Table 7.
According to the results in
Table 6, the independent (predictive) variables were A1–A29 attributed to number
p smaller than 0.05, which significantly influenced on dependent, binary variable A30—bleeding.
According to the results in
Table 7, we have 15 significant predictors given in first row. On the one hand, in second row, we have 12 predictors from this 15 with OR greater than one and characteristic when the predictive variable, bleeding, increased, and the risk that binary variable would acquire value Yes also increased.
On the other hand, in third row we have 3 predictors from this 15 with OR smaller than one and characteristic when the predictive variable increased, and the risk that binary variable would acquire value Yes decreased.
4. Discussion
In the machine learning and statistics, dimensionality reduction is the process of reducing the number of random variables under a certain consideration and can be divided into feature selection and attribute importance determination.
Feature selection approaches [
68,
69,
70] try to find a subset of the original variables. In this work, two strategies, namely, filter (Chi-square, information gain, gain ratio, relief and symmetrical uncertainty) and wrapper (search guided by the accuracy) approaches are combined. The performance of classification algorithm is commonly examined by evaluating the classification accuracy.
In this study, the ROC curves are used to evaluate the classification accuracy. By analyzing the experimental results presented in
Table 3, it can be observed that the LogitBoost classification technique achieved better result than the other techniques using training mode of valuation applied classification algorithms.
The results of the comparative application of different classifiers conducted in described case study on feature subsets generated by the five different feature selection procedures are shown in
Table 5. The LogitBoost classification algorithm is trained using decision stumps (one node decision trees) as weak learners. The IG attribute evaluation can be used to filter features, thus reducing the dimensionality of the feature space [
71].
The experimental results presented on
Table 8 show that IG feature selection significantly improves the all observed performance of the LogitBoost classification technique in spite of the fact that decision tree has inherited ability to focus on relevant features while ignoring the irrelevant ones (refer to
Section 3).
The authors performed 10-cross validation of the proposed model using Weka software and it confirmed the validity of the proposed model defined by the procedures given in the work with Algorithm 1 and Algorithm 2 as it is given in
Table 9.
As we mentioned in
Section 3 Results, results of univariate regression on same data set [
67] are used for fine calibration in proposed model. In that paper was considered comparison of use of classic and gradual regression in prediction of risk of variceal bleeding in cirrhotic patients.
Table 10 shows results obtained using multivariate gradual regression and recognizes only two factors as significant for risk of variceal bleeding, which are in comparison with results of proposed model evidently a worse result in terms of requested prediction.
The regression calibration is a simple way to improve estimation accuracy of the errors-in-variables model [
72].
It is shown that when variables are small, regression calibration using response variables outperforms the conventional regression calibration.
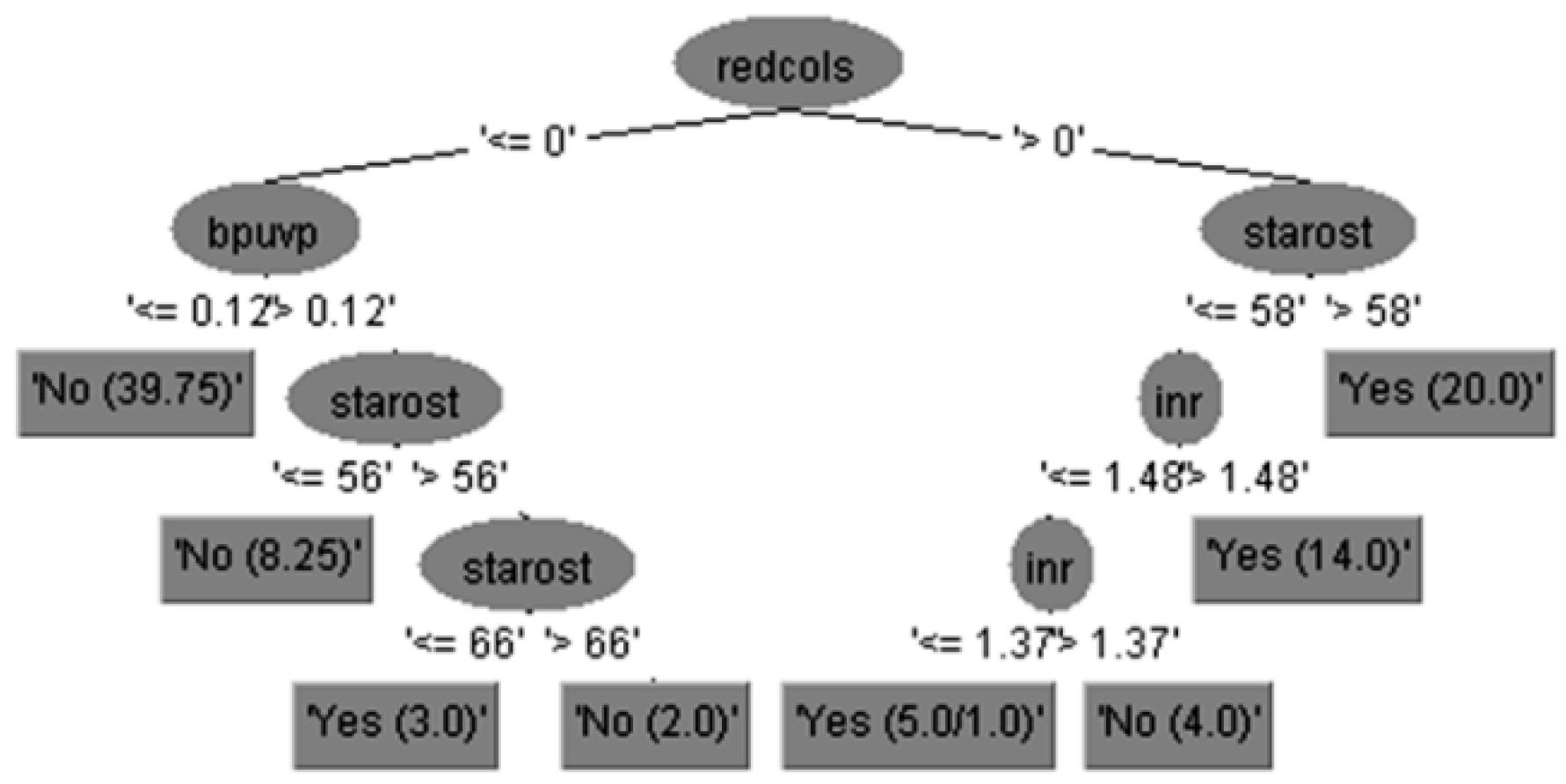
Expert clinical interpretation of obtained results for risk of bleeding prediction in cirrhotic patients could be given using decision tree diagram with feature subset of 15 attributes, which is practically equal to set of 29 attributes in the case without feature selection but more precise and accurate.
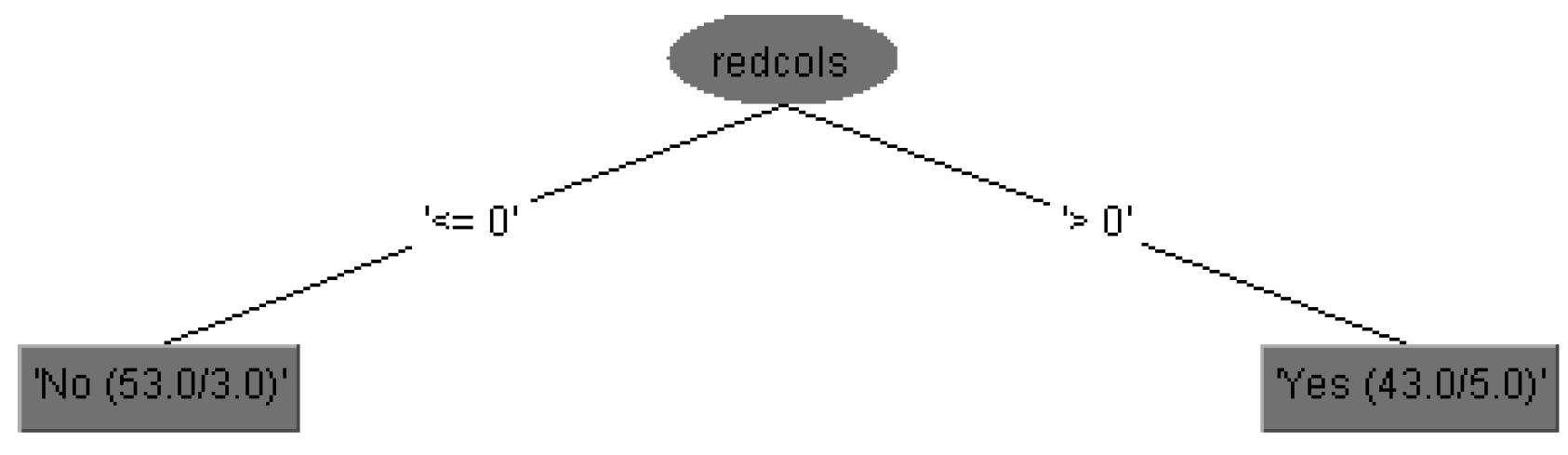
The run information part contains general information about the used scheme, the number of instances, 96 patients, in the case of 15 attributes is shown in
Figure 3, i.e., the case of 29 attributes is shown in
Figure 4, and in both cases as well as the attributes names.
The output for predicted variable represented by the decision tree given in
Figure 3 can be interpreted using the If-Then 14 rules in Equation (12), as follows:
Authors contribution is demonstrated in obtained result with application of proposed new ensemble boosting model of data mining, which integrates classification algorithm with attribute reduction and regression method for calibration and which shows that proposed model has a better characteristic than each of individually applied model and authors could not find in existing literature.
The authors confirmed originality of the proposed ensemble model by reviewing the state of the art, generally observed, end especially in the liver disease prediction, which are given in the introduction of the paper and could be confirmed by observation updated state of the art in both disciplines:
- -
in the different machine learning methodologies [
73,
74,
75] and
- -
in the use of differently constructed ensemble methodologies [
76,
77].
Advantage of proposed model is, in fact, that it is evaluated on the case study including big number of different types of considered factors. Finally, one advantage of the proposed model is in the fact that it could be applied worldwide where it will generate prediction that is suitable according the specificity of each locality individual so that the paper is suitable for broad international interest and applications.
In such a way, authors confirmed the hypothesis and answered the research question set in introduction of this paper and thus contributed to the creation of a tool that can successfully and practically serve to solve their perceived research gap.
This described study has several limitations that must be addressed:
First, we collected data only from one medical center (as it is given in [
78] as
Supplementary Material) that reflects its particularities; the sample would be more representative if it is from many different localities, so that results can be generalized. Second, we evaluated small size of only 96 patient’s information, although most of the variables were statistically significant. Third, we have not included all possible factors that could cause bleeding. Finally, we must notice that noninvasive markers may be useful only as a first step to possibly identify varices for cirrhosis patients and in this way to reduce the number of endoscopies.
In further work and research authors plan to test proposed model on the data set obtained in last 10 years in Clinical Center of Nis, Serbia. Authors also intend to include in further research at least two other clinical centers in Serbia or in the Western Balkans that are topologically distant and located in different locations with different features (hilly and lowland coastal locality) where the population has other habits and characteristics and, in this way, to obtain bigger size of cirrhotic patients and more representative sample for proposed model evaluation. Authors plan also to deal with determining more precise type and number in each type of classification algorithms and type and number of classifiers for feature selection used in proposed model. Finally, proposed model can be suggested for prediction and monitoring of risk of bleeding in cirrhotic patients, e.g., by implementing as a software tool.
5. Conclusions
Analysis of significance of factors that are influencing an event is a very complex task. Factors can be independent or dependent, quantitative or qualitative, i.e., deterministic or probabilistic nature, and there can be a complex relationship between them. Due to the importance of determination of risk factors for bleeding problems in cirrhotic patients and the fact that early prediction of varices bleeding in cirrhotic patients in last 20 years help this complication to be reduced, it is clear that it is necessary to develop an accurate algorithm for selection of the most significant factors of the mentioned problem.
Among all techniques of statistics, operation research, and data mining techniques, in this work, statistical univariate regression and data mining technique of classification are aggregated to obtain one boosting method, which has better characteristics than each of them individually. Data mining is used to find a subset of the original set of variables. Also, two strategies, filter (information gain and other) and wrapper (search guided by the accuracy) approaches, are combined. Regression calibration is utilized to improve estimation performance of the errors in variables model. Application of the bleeding risk factors-based univariate regression presented in this paper can help decision-making and higher risk identification of bleeding in cirrhotic patients.
The proposed method uses advantages of data mining decision tree method to make good beginning classification of considered predictors and then univariate regression is utilized for fine calibration of obtained results, resulting in developing a high-accuracy risk prediction model.
It is evident that the proposed ensemble model can be useful and extensible to other hospitals in the world treating this illness, the liver cirrhosis and its consequences as the bleeding of varices studied in this case.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}