Upper Bounds and Explicit Formulas for the Ruin Probability in the Risk Model with Stochastic Premiums and a Multi-Layer Dividend Strategy


Abstract
1. Introduction
2. Preliminary Results
3. Exponential Bound for the Ruin Probability
3.1. Exponential Bound
3.2. Exponential Distributions for the Premium and Claim Sizes
3.3. Hyperexponential Distributions for the Premium and Claim Sizes
3.4. Erlang Distributions for the Premium and Claim Sizes
4. Non-Exponential Bound for the Ruin Probability
4.1. Model with a Constant Dividend Strategy
4.2. Model with a Multi-Layer Dividend Strategy
5. Explicit Formulas for the Ruin Probability
5.1. Hyperexponential Distributions for the Premium and Claim Sizes
5.2. Erlang Distributions for the Premium and Claim Sizes
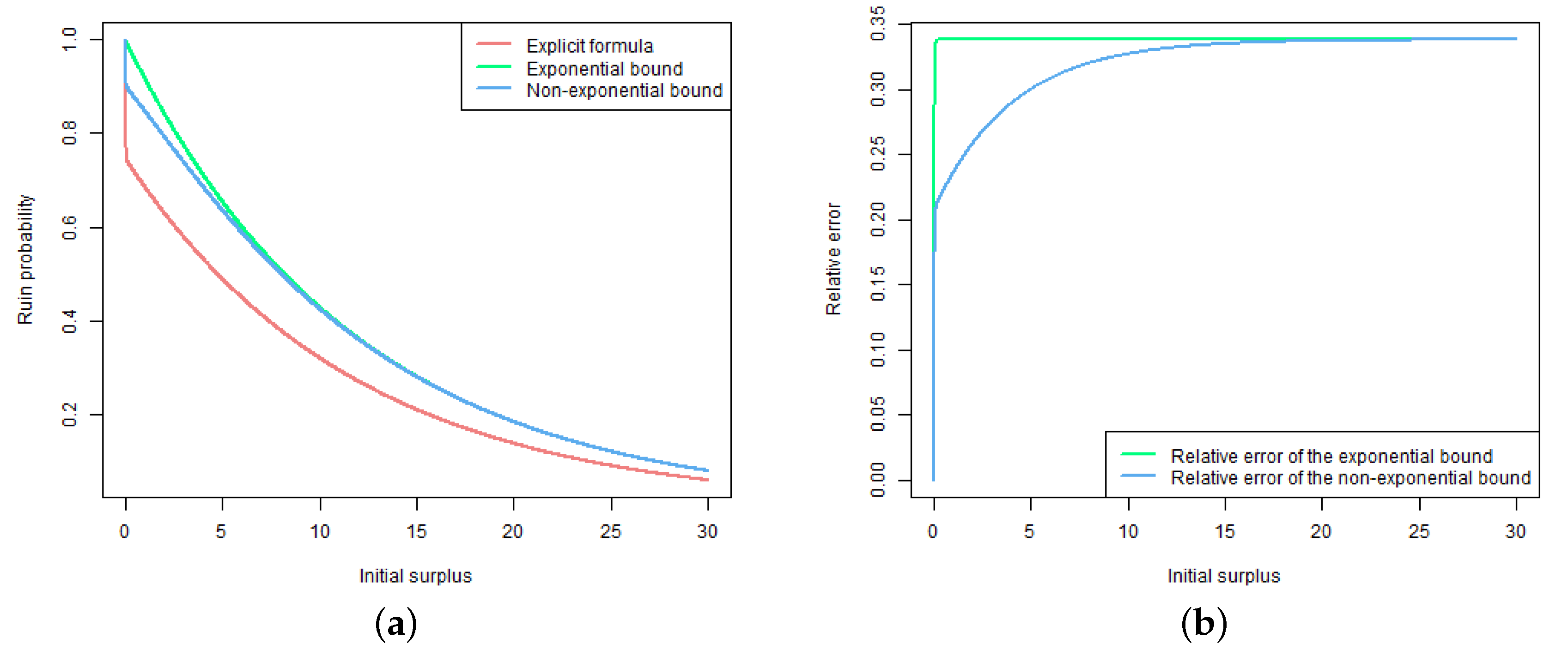
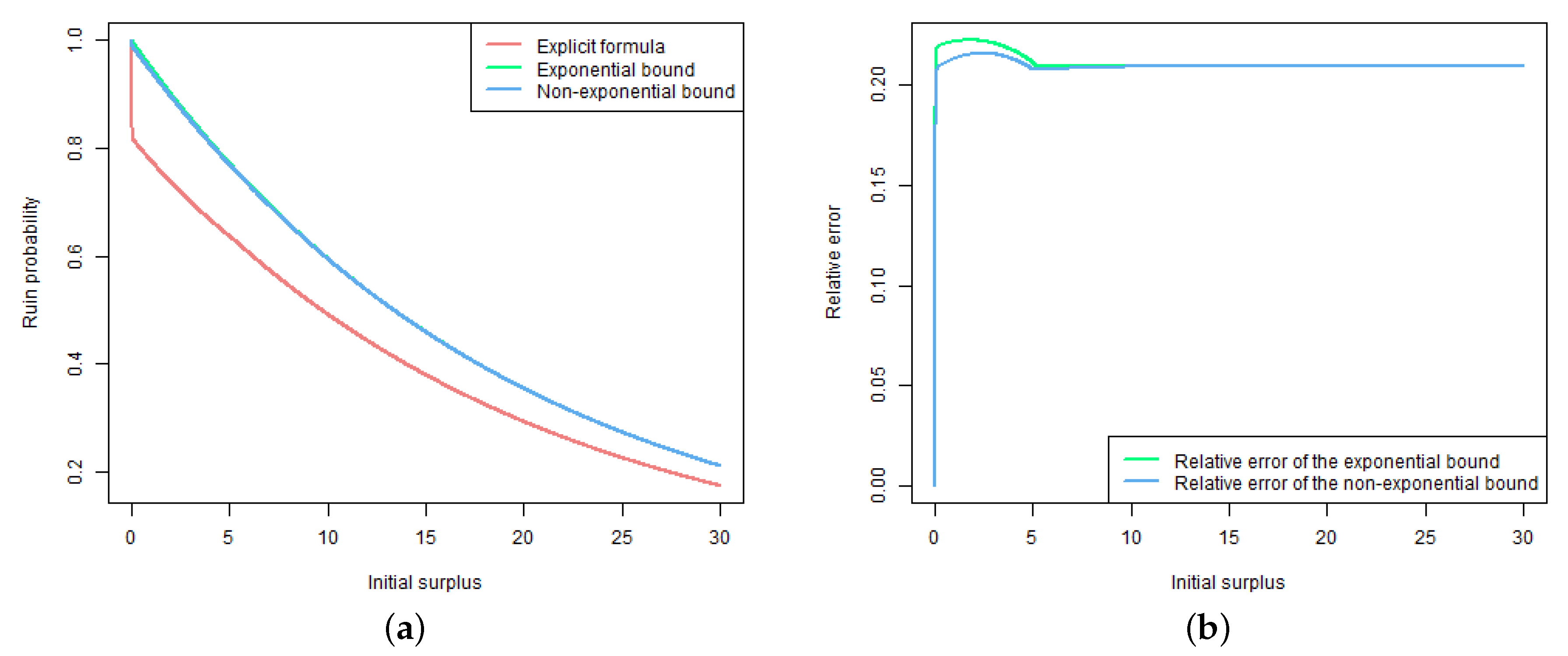
6. Numerical Illustrations
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Grandell, J. Aspects of Risk Theory; Springer: New York, NY, USA, 1991. [Google Scholar]
- Rolski, T.; Schmidli, H.; Schmidt, V.; Teugels, J. Stochastic Processes for Insurance and Finance; John Wiley & Sons: Chichester, UK, 1999. [Google Scholar]
- Asmussen, S.; Albrecher, H. Ruin Probabilities; World Scientific: Singapore, 2010. [Google Scholar]
- Mishura, Y.; Ragulina, O. Ruin Probabilities: Smoothness, Bounds, Supermartingale Approach; ISTE Press—Elsevier: London, UK, 2016. [Google Scholar]
- Schmidli, H. Risk Theory; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Schmidli, H. Stochastic Control in Insurance; Springer: London, UK, 2008. [Google Scholar]
- Gerber, H.U.; Shiu, E.S.W. On the time value of ruin. N. Am. Actuar. J. 1998, 2, 48–72. [Google Scholar] [CrossRef]
- Chadjiconstantinidis, S.; Vrontos, S. On a renewal risk process with dependence under a Farlie–Gumbel– Morgenstern copula. Scand. Actuar. J. 2014, 2014, 125–158. [Google Scholar] [CrossRef]
- Cheng, Y.; Tang, Q. Moments of the surplus before ruin and the deficit of ruin in the Erlang(2) risk process. N. Am. Actuar. J. 2003, 7, 1–12. [Google Scholar] [CrossRef]
- Cossette, H.; Marceau, E.; Marri, F. On the compound Poisson risk model with dependence based on a generalized Farlie–Gumbel–Morgenstern copula. Insur. Math. Econ. 2008, 43, 444–455. [Google Scholar] [CrossRef]
- Cossette, H.; Marceau, E.; Marri, F. Analysis of ruin measures for the classical compound Poisson risk model with dependence. Scand. Actuar. J. 2010, 2010, 221–245. [Google Scholar] [CrossRef]
- Gerber, H.U.; Shiu, E.S.W. The time value of ruin in a Sparre Andersen model. N. Am. Actuar. J. 2005, 9, 49–69. [Google Scholar] [CrossRef]
- Navickienė, O.; Sprindys, J.; Šiaulys, J. The Gerber–Shiu discounted penalty function for the bi-seasonal discrete time risk model. Informatica 2018, 29, 733–756. [Google Scholar] [CrossRef]
- Sun, L.-J. The expected discounted penalty at ruin in the Erlang(2) risk process. Stat. Probab. Lett. 2005, 72, 205–217. [Google Scholar] [CrossRef]
- De Finetti, B. Su un’impostazione alternativa dell teoria colletiva del rischio. Trans. XV Int. Congr. Actuar. 1957, 2, 433–443. [Google Scholar]
- Li, S.; Garrido, J. On a class of renewal risk models with a constant dividend barrier. Insur. Math. Econ. 2004, 35, 691–701. [Google Scholar] [CrossRef]
- Lin, X.S.; Pavlova, K.P. The compound Poisson risk model with a threshold dividend strategy. Insur. Math. Econ. 2006, 38, 57–80. [Google Scholar] [CrossRef]
- Landriault, D. Constant dividend barrier in a risk model with interclaim-dependent claim sizes. Insur. Math. Econ. 2008, 42, 31–38. [Google Scholar] [CrossRef]
- Li, B.; Wu, R.; Song, M. A renewal jump-diffusion process with threshold dividend strategy. J. Comput. Appl. Math. 2009, 228, 41–55. [Google Scholar] [CrossRef]
- Chi, Y.; Lin, X.S. On the threshold dividend strategy for a generalized jump-diffusion risk model. Insur. Math. Econ. 2011, 48, 326–337. [Google Scholar] [CrossRef]
- Shi, Y.; Liu, P.; Zhang, C. On the compound Poisson risk model with dependence and a threshold dividend strategy. Stat. Probab. Lett. 2013, 83, 1998–2006. [Google Scholar] [CrossRef]
- Cossette, H.; Marceau, E.; Marri, F. On a compound Poisson risk model with dependence and in the presence of a constant dividend barrier. Appl. Stoch. Models Bus. Ind. 2014, 30, 82–98. [Google Scholar] [CrossRef]
- Wang, W. The perturbed Sparre Andersen model with interest and a threshold dividend strategy. Methodol. Comput. Appl. Probab. 2015, 17, 251–283. [Google Scholar] [CrossRef]
- Ragulina, O. The risk model with stochastic premiums, dependence and a threshold dividend strategy. Mod. Stoch. Theory Appl. 2017, 4, 315–351. [Google Scholar] [CrossRef][Green Version]
- Albrecher, H.; Hartinger, J. A risk model with multilayer dividend strategy. N. Am. Actuar. J. 2007, 11, 43–64. [Google Scholar] [CrossRef]
- Badescu, A.; Drekic, S.; Landriault, D. On the analysis of a multi-threshold Markovian risk model. Scand. Actuar. J. 2007, 2007, 248–260. [Google Scholar] [CrossRef]
- Lin, X.S.; Sendova, K.P. The compound Poisson risk model with multiple thresholds. Insur. Math. Econ. 2008, 42, 617–627. [Google Scholar] [CrossRef]
- Badescu, A.; Landriault, D. Recursive calculation of the dividend moments in a multi-threshold risk model. N. Am. Actuar. J. 2008, 12, 74–88. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, Z. Gerber–Shiu discounted penalty function in a Sparre Andersen model with multi-layer dividend strategy. Insur. Math. Econ. 2008, 42, 984–991. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, Z. The perturbed compound Poisson risk model with multi-layer dividend strategy. Stat. Probab. Lett. 2009, 79, 70–78. [Google Scholar] [CrossRef]
- Mitric, I.-R.; Sendova, K.P.; Tsai, C.C.-L. On a multi-threshold compound Poisson process perturbed by diffusion. Stat. Probab. Lett. 2010, 80, 366–375. [Google Scholar] [CrossRef]
- Deng, C.; Zhou, J.; Deng, Y. The Gerber–Shiu discounted penalty function in a delayed renewal risk model with multi-layer dividend strategy. Stat. Probab. Lett. 2012, 82, 1648–1656. [Google Scholar] [CrossRef]
- Jiang, W.; Yang, Z.; Li, X. The discounted penalty function with multi-layer dividend strategy in the phase-type risk model. Stat. Probab. Lett. 2012, 82, 1358–1366. [Google Scholar] [CrossRef]
- Zhou, Z.; Xiao, H.; Deng, Y. Markov-dependent risk model with multi-layer dividend strategy. Appl. Math. Comput. 2015, 252, 273–286. [Google Scholar] [CrossRef]
- Xie, J.-H.; Zou, W. On the expected discounted penalty function for a risk model with dependence under a multi-layer dividend strategy. Comm. Stat. Theory Methods 2017, 46, 1898–1915. [Google Scholar] [CrossRef]
- Ragulina, O. The risk model with stochastic premiums and a multi-layer dividend strategy. Mod. Stoch. Theory Appl. 2019, 6, 285–309. [Google Scholar] [CrossRef]
- Albrecher, H.; Constantinescu, C.; Loisel, S. Explicit ruin formulas for models with dependence among risks. Insur. Math. Econ. 2011, 48, 265–270. [Google Scholar] [CrossRef]
- Constantinescu, C.; Samorodnitsky, G.; Zhu, W. Ruin probabilities in classical risk models with gamma claims. Scand. Actuar. J. 2018, 2018, 555–575. [Google Scholar] [CrossRef]
- Dufresne, F.; Gerber, H.U. Three methods to calculate the probability of ruin. ASTIN Bull. 1989, 19, 71–90. [Google Scholar] [CrossRef]
- Gómez-Déniz, E.; Sarabia, J.M.; Calderín-Ojeda, E. Ruin probability functions and severity of ruin as a statistical decision problem. Risks 2019, 7, 68. [Google Scholar] [CrossRef]
- Ramsay, C.M. A solution to the ruin problem for Pareto distributions. Insur. Math. Econ. 2003, 33, 109–116. [Google Scholar] [CrossRef]
- Mishura, Y.S.; Ragulina, O.Y.; Stroev, O.M. Analytic property of infinite-horizon survival probability in a risk model with additional funds. Theory Probab. Math. Stat. 2015, 91, 131–143. [Google Scholar] [CrossRef]
- Thorin, O. The ruin problem in case the tail of the claim distribution is completely monotone. Scand. Actuar. J. 1973, 1973, 100–119. [Google Scholar] [CrossRef]
- Navickienė, O.; Sprindys, J.; Šiaulys, J. Ruin probability for the bi-seasonal discrete time risk model with dependent claims. Mod. Stoch. Theory Appl. 2019, 6, 133–144. [Google Scholar] [CrossRef]
- Grigutis, A.; Šiaulys, J. Ultimate time survival probability in three-risk discrete time risk model. Mathematics 2020, 8, 147. [Google Scholar] [CrossRef]
- Gerber, H.U. Martingales in risk theory. Z. Mitt. Ver. Schweiz. 1973, 73, 205–216. [Google Scholar]
- Boikov, A.V. The Cramér–Lundberg model with stochastic premium process. Theory Probab. Appl. 2003, 47, 489–493. [Google Scholar] [CrossRef]
- Yang, H.; Zhang, L. Martingale method for ruin probability in an autoregressive model with constant interest rate. Probab. Eng. Inf. Sci. 2003, 17, 183–198. [Google Scholar] [CrossRef][Green Version]
- Grandell, J.; Schmidli, H. Ruin probabilities in a diffusion enviroment. J. Appl. Probab. 2011, 48A, 39–50. [Google Scholar] [CrossRef]
- Mishura, Y.; Ragulina, O.; Stroev, O. Practical approaches to the estimation of the ruin probability in a risk model with additional funds. Mod. Stoch. Theory Appl. 2014, 1, 167–180. [Google Scholar] [CrossRef]
- Mishura, Y.; Perestyuk, M.; Ragulina, O. Ruin probability in a risk model with variable premium intensity and risky investments. Opusc. Math. 2015, 35, 333–352. [Google Scholar] [CrossRef]
- Kievinaitě, D.; Šiaulys, J. Exponential bounds for the tail probability of the supremum of an inhomogeneous random walk. Mod. Stoch. Theory Appl. 2018, 5, 129–143. [Google Scholar] [CrossRef]
- Kizineviě, E.; Šiaulys, J. The exponential estimate of the ultimate ruin probability for the non-homogeneous renewal risk model. Risks 2018, 6, 20. [Google Scholar] [CrossRef]
- Andrulytė, I.M.; Bernackaitė, E.; Kievinaitė, D.; Šiaulys, J. A Lundberg-type inequality for an inhomogeneous renewal risk model. Mod. Stoch. Theory Appl. 2015, 2, 173–184. [Google Scholar] [CrossRef][Green Version]
- Yang, H. Non-exponential bounds for ruin probability with interest effect included. Scand. Actuar. J. 1999, 1999, 66–79. [Google Scholar] [CrossRef]
- Embrechts, P.; Villasenor, J.A. Ruin estimates for large claims. Insur. Math. Econ. 1988, 7, 269–274. [Google Scholar] [CrossRef]
- De Vylder, F.; Goovaerts, M. Bounds for classical ruin probabilities. Insur. Math. Econ. 1984, 3, 121–131. [Google Scholar] [CrossRef]
- Sundt, B.; Teugels, J. Ruin estimates under interest force. Insur. Math. Econ. 1995, 16, 7–22. [Google Scholar] [CrossRef]
- Cai, J.; Garrido, J. Two-sided bounds for ruin probabilities when the adjustment coefficient does not exist. Scand. Actuar. J. 1999, 1999, 80–92. [Google Scholar] [CrossRef]
- Kalashnikov, V. Bounds for ruin probabilities in the presence of large claims and their comparison. N. Am. Actuar. J. 1999, 3, 116–128. [Google Scholar] [CrossRef]
- Konstantinides, D.; Tang, Q.; Tsitsiashvili, G. Estimates for the ruin probability in the classical risk model with constant interest force in the presence of heavy tails. Insur. Math. Econ. 2002, 31, 447–460. [Google Scholar] [CrossRef]
- Ragulina, O. Simple approximations for the ruin probability in the risk model with stochastic premiums and a constant dividend strategy. Mod. Stoch. Theory Appl. 2020, 7, 245–265. [Google Scholar] [CrossRef]
- Mordecki, E. Ruin probabilities for Lévy processes with mixed-exponential negative jumps. Theory Probab. Appl. 2003, 48, 170–176. [Google Scholar] [CrossRef]
- Bao, Z. The expected discounted penalty at ruin in the risk process with random income. Appl. Math. Comput. 2006, 179, 559–566. [Google Scholar] [CrossRef]
- Lewis, A.; Mordecki, E. Wiener-Hopf factorization for Lévy processes having positive jumps with rational transforms. J. Appl. Probab. 2008, 45, 118–134. [Google Scholar] [CrossRef][Green Version]
- Yang, H.; Zhang, Z. On a class of renewal risk model with random income. Appl. Stoch. Models Bus. Ind. 2009, 25, 678–695. [Google Scholar] [CrossRef]
- Labbé, C.; Sendova, K.P. The expected discounted penalty function under a risk model with stochastic income. Appl. Math. Comput. 2009, 215, 1852–1867. [Google Scholar] [CrossRef]
- Zhang, Z.; Yang, H. A generalized penalty function in the Sparre Andersen risk model with two-sided jumps. Stat. Probab. Lett. 2010, 80, 597–607. [Google Scholar] [CrossRef]
- Zhao, X.; Yin, C. The Gerber–Shiu expected discounted penalty function for Lévy insurance risk processes. Acta Math. Appl. Sin. 2010, 26, 575–586. [Google Scholar] [CrossRef]
- Zhao, Y.; Yin, C. The expected discounted penalty function under a renewal risk model with stochastic income. Appl. Math. Comput. 2012, 218, 6144–6154. [Google Scholar] [CrossRef]
- Xie, J.; Zou, W. On a risk model with random incomes and dependence between claim sizes and claim intervals. Indag. Math. 2013, 24, 557–580. [Google Scholar] [CrossRef]
- Wang, Y.; Yu, W.; Huang, Y. Estimating the Gerber–Shiu function in a compound Poisson risk model with stochastic premium income. Discret. Dyn. Nat. Soc. 2019, 2019, 5071268. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| x | |||||
|---|---|---|---|---|---|
| 0.2 | 0.734604 | 0.983187 | 0.3384 | 0.891300 | 0.2133 |
| 0.3 | 0.728359 | 0.974886 | 0.3385 | 0.886006 | 0.2164 |
| 0.7 | 0.704072 | 0.942380 | 0.3385 | 0.864594 | 0.2280 |
| 1 | 0.686390 | 0.918713 | 0.3385 | 0.848330 | 0.2359 |
| 2 | 0.630595 | 0.844034 | 0.3385 | 0.793602 | 0.2585 |
| 3 | 0.579336 | 0.775425 | 0.3385 | 0.739289 | 0.2761 |
| 5 | 0.488980 | 0.654485 | 0.3385 | 0.635932 | 0.3005 |
| 7 | 0.412715 | 0.552408 | 0.3385 | 0.542882 | 0.3154 |
| 10 | 0.320030 | 0.428351 | 0.3385 | 0.424847 | 0.3275 |
| 15 | 0.209455 | 0.280349 | 0.3385 | 0.279687 | 0.3353 |
| 20 | 0.137085 | 0.183485 | 0.3385 | 0.183359 | 0.3376 |
| 30 | 0.058721 | 0.078596 | 0.3385 | 0.078591 | 0.3384 |
| 50 | 0.010774 | 0.014421 | 0.3385 | 0.014421 | 0.3385 |
| 70 | 0.001977 | 0.002646 | 0.3385 | 0.002646 | 0.3385 |
| x | |||||
|---|---|---|---|---|---|
| 0.2 | 0.811439 | 0.989681 | 0.2197 | 0.981379 | 0.2094 |
| 0.3 | 0.807002 | 0.984561 | 0.2200 | 0.976501 | 0.2100 |
| 0.7 | 0.789746 | 0.964347 | 0.2211 | 0.957182 | 0.2120 |
| 1 | 0.777184 | 0.949459 | 0.2217 | 0.942892 | 0.2132 |
| 2 | 0.737542 | 0.901472 | 0.2223 | 0.896528 | 0.2156 |
| 3 | 0.701123 | 0.855910 | 0.2208 | 0.852140 | 0.2154 |
| 5 | 0.636926 | 0.771579 | 0.2114 | 0.769284 | 0.2078 |
| 7 | 0.575029 | 0.695557 | 0.2096 | 0.694802 | 0.2083 |
| 10 | 0.492173 | 0.595334 | 0.2096 | 0.595056 | 0.2090 |
| 15 | 0.379750 | 0.459347 | 0.2096 | 0.459295 | 0.2095 |
| 20 | 0.293007 | 0.354423 | 0.2096 | 0.354413 | 0.2096 |
| 30 | 0.174437 | 0.211000 | 0.2096 | 0.211000 | 0.2096 |
| 50 | 0.061825 | 0.074783 | 0.2096 | 0.074783 | 0.2096 |
| 70 | 0.021912 | 0.026505 | 0.2096 | 0.026505 | 0.2096 |
| x | |||||
|---|---|---|---|---|---|
| 0.2 | 0.774117 | 0.989681 | 0.2785 | 0.982463 | 0.2691 |
| 0.3 | 0.764011 | 0.984561 | 0.2887 | 0.977524 | 0.2795 |
| 0.7 | 0.738996 | 0.964347 | 0.3050 | 0.958183 | 0.2966 |
| 1 | 0.721066 | 0.949459 | 0.3167 | 0.943881 | 0.3090 |
| 2 | 0.663275 | 0.901472 | 0.3591 | 0.897475 | 0.3531 |
| 3 | 0.608405 | 0.855910 | 0.4068 | 0.853047 | 0.4021 |
| 5 | 0.506845 | 0.771579 | 0.5223 | 0.770109 | 0.5194 |
| 7 | 0.426750 | 0.695557 | 0.6299 | 0.694055 | 0.6264 |
| 10 | 0.330912 | 0.595334 | 0.7991 | 0.594414 | 0.7963 |
| 15 | 0.216577 | 0.459347 | 1.1209 | 0.458798 | 1.1184 |
| 20 | 0.141747 | 0.354423 | 1.5004 | 0.354029 | 1.4976 |
| 30 | 0.060717 | 0.210100 | 2.4751 | 0.210771 | 2.4714 |
| 50 | 0.011141 | 0.074783 | 5.7126 | 0.074702 | 5.7054 |
| 70 | 0.002044 | 0.026505 | 11.9662 | 0.026476 | 11.9522 |
| x | |||||
|---|---|---|---|---|---|
| 0.2 | 0.734553 | 0.984403 | 0.3401 | 0.894135 | 0.2173 |
| 0.3 | 0.728314 | 0.976697 | 0.3410 | 0.889691 | 0.2216 |
| 0.7 | 0.704311 | 0.946468 | 0.3438 | 0.871147 | 0.2369 |
| 1 | 0.687044 | 0.924412 | 0.3455 | 0.856609 | 0.2468 |
| 2 | 0.633290 | 0.854538 | 0.3494 | 0.806126 | 0.2729 |
| 3 | 0.584412 | 0.789946 | 0.3517 | 0.754893 | 0.2917 |
| 5 | 0.498441 | 0.675039 | 0.3543 | 0.656260 | 0.3166 |
| 7 | 0.425505 | 0.576846 | 0.3557 | 0.566634 | 0.3317 |
| 10 | 0.335864 | 0.455677 | 0.3567 | 0.451513 | 0.3443 |
| 15 | 0.226613 | 0.307600 | 0.3574 | 0.306636 | 0.3531 |
| 20 | 0.152952 | 0.207642 | 0.3576 | 0.207412 | 0.3561 |
| 30 | 0.069694 | 0.094618 | 0.3576 | 0.094604 | 0.3574 |
| 50 | 0.014471 | 0.019647 | 0.3576 | 0.019647 | 0.3576 |
| 70 | 0.003005 | 0.004079 | 0.3576 | 0.004079 | 0.3576 |
| x | |||||
|---|---|---|---|---|---|
| 0.2 | 0.731189 | 0.976958 | 0.3361 | 0.958695 | 0.3111 |
| 0.3 | 0.724778 | 0.965637 | 0.3323 | 0.948061 | 0.3081 |
| 0.7 | 0.698203 | 0.921649 | 0.3200 | 0.906691 | 0.2986 |
| 1 | 0.677648 | 0.889979 | 0.3133 | 0.876812 | 0.2939 |
| 2 | 0.609064 | 0.792062 | 0.3005 | 0.783729 | 0.2868 |
| 3 | 0.544288 | 0.704918 | 0.2951 | 0.699832 | 0.2858 |
| 5 | 0.432167 | 0.558339 | 0.2920 | 0.556572 | 0.2879 |
| 7 | 0.342451 | 0.442239 | 0.2914 | 0.441661 | 0.2897 |
| 10 | 0.241421 | 0.311742 | 0.2913 | 0.311641 | 0.2909 |
| 15 | 0.134796 | 0.174058 | 0.2913 | 0.174053 | 0.2912 |
| 20 | 0.075262 | 0.097183 | 0.2913 | 0.097183 | 0.2913 |
| 30 | 0.023462 | 0.030296 | 0.2913 | 0.030296 | 0.2913 |
| 50 | 0.002280 | 0.002944 | 0.2913 | 0.002944 | 0.2913 |
| 70 | 0.000222 | 0.000286 | 0.2913 | 0.000286 | 0.2913 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ragulina, O.; Šiaulys, J. Upper Bounds and Explicit Formulas for the Ruin Probability in the Risk Model with Stochastic Premiums and a Multi-Layer Dividend Strategy. Mathematics 2020, 8, 1885. https://doi.org/10.3390/math8111885
Ragulina O, Šiaulys J. Upper Bounds and Explicit Formulas for the Ruin Probability in the Risk Model with Stochastic Premiums and a Multi-Layer Dividend Strategy. Mathematics. 2020; 8(11):1885. https://doi.org/10.3390/math8111885
Chicago/Turabian StyleRagulina, Olena, and Jonas Šiaulys. 2020. "Upper Bounds and Explicit Formulas for the Ruin Probability in the Risk Model with Stochastic Premiums and a Multi-Layer Dividend Strategy" Mathematics 8, no. 11: 1885. https://doi.org/10.3390/math8111885
APA StyleRagulina, O., & Šiaulys, J. (2020). Upper Bounds and Explicit Formulas for the Ruin Probability in the Risk Model with Stochastic Premiums and a Multi-Layer Dividend Strategy. Mathematics, 8(11), 1885. https://doi.org/10.3390/math8111885