Estimation and Prediction of Record Values Using Pivotal Quantities and Copulas



Abstract
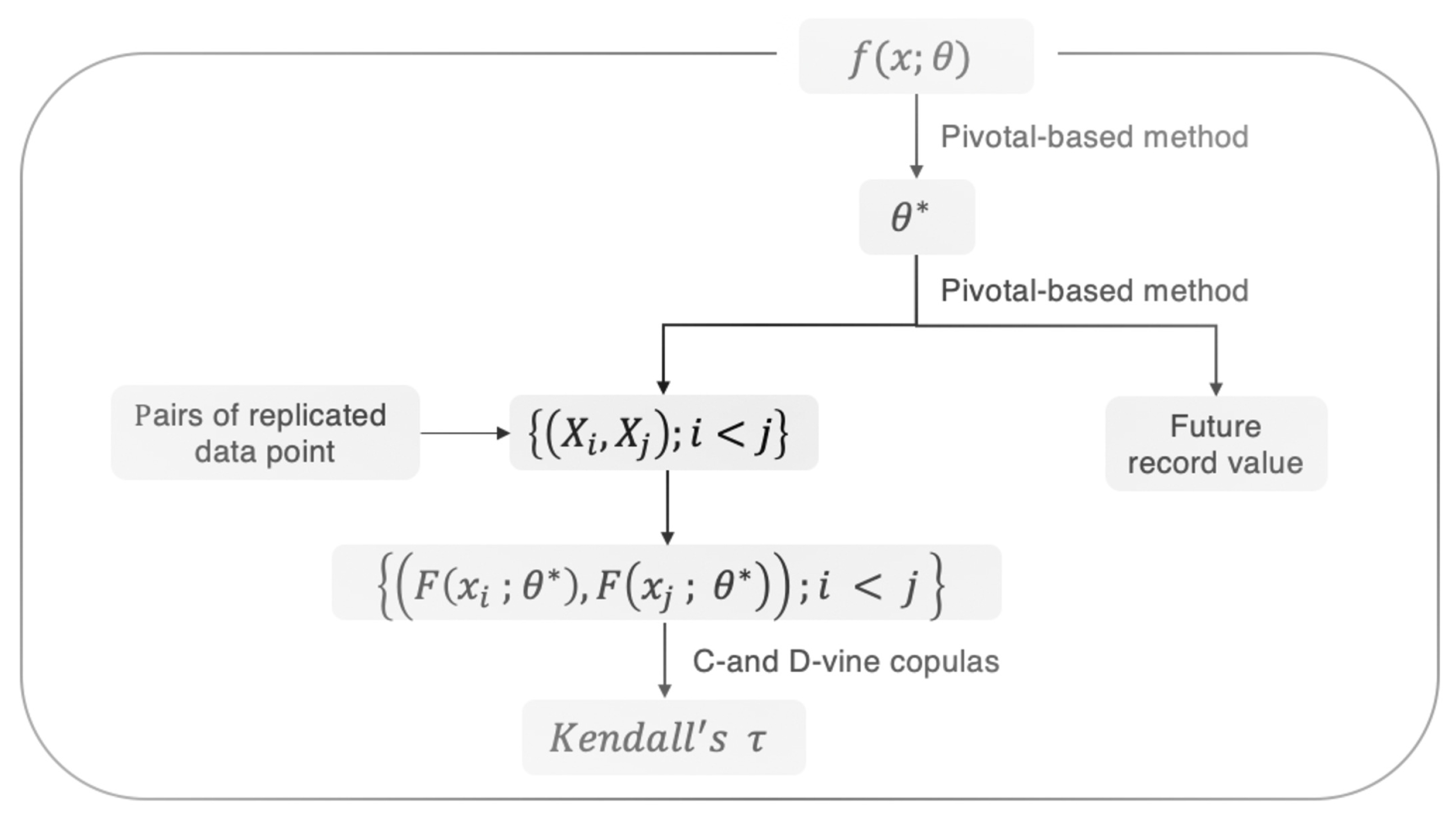
1. Introduction
2. Methods
2.1. C- and D-Vine Copulas
2.2. Pivotal-Based Approach
- (a)
- has a distribution with degrees of freedom;
- (b)
- has a F distribution with and 2 degrees of freedom;
- (c)
- has a distribution with degrees of freedom.
- Step 1.
- Generate from a distribution with two degrees of freedom.
- Step 2.
- Compute for .
- Step 3.
- Compute and solve the equation for to obtain .
- Step 4.
- Compute .
- Step 5.
- Repeat times.
2.3. Prediction
- Step 1.
- Generate from Gam.
- Step 2.
- Compute
- Step 3.
- Repeat steps 1 and 2, N times.
3. Simulation Study
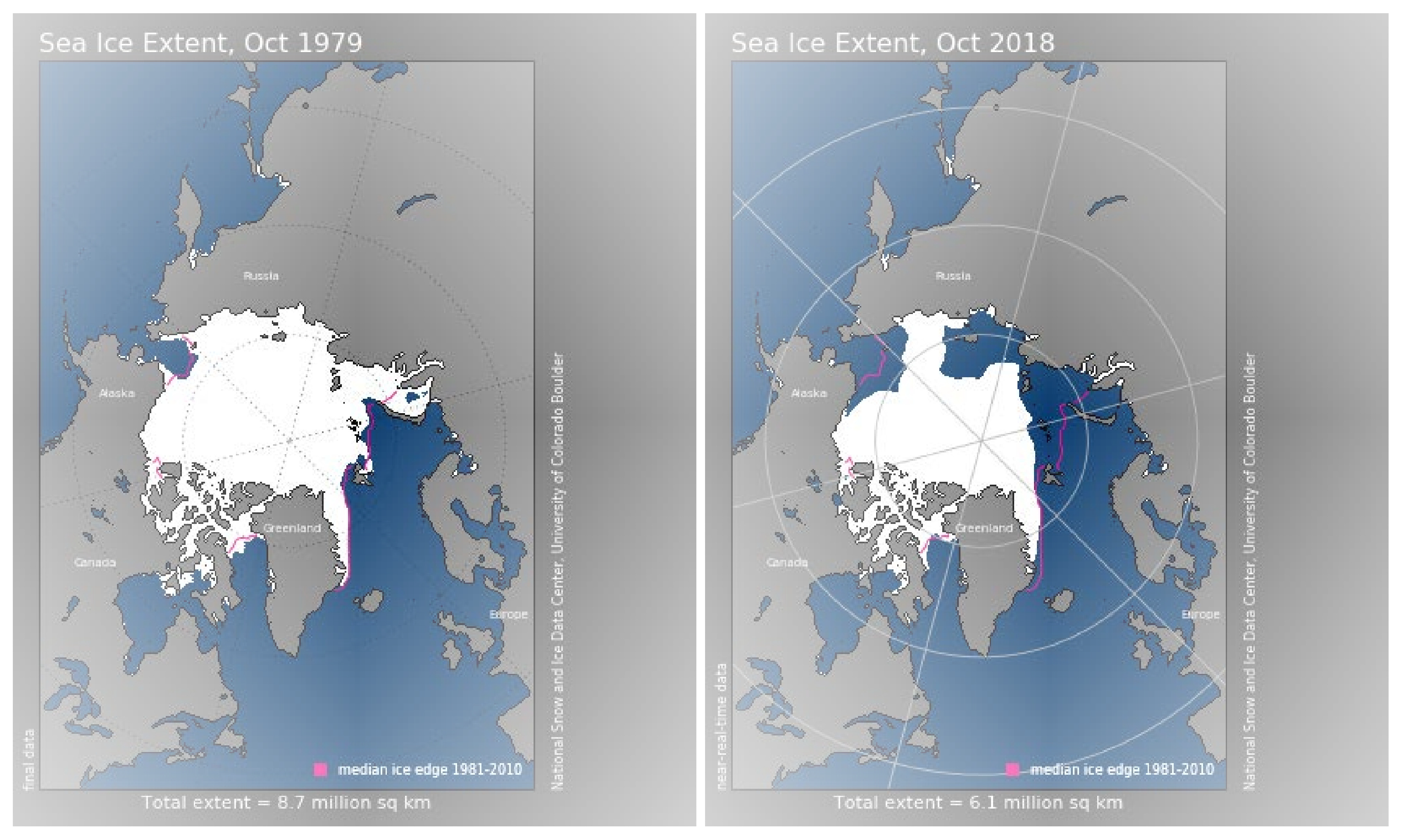
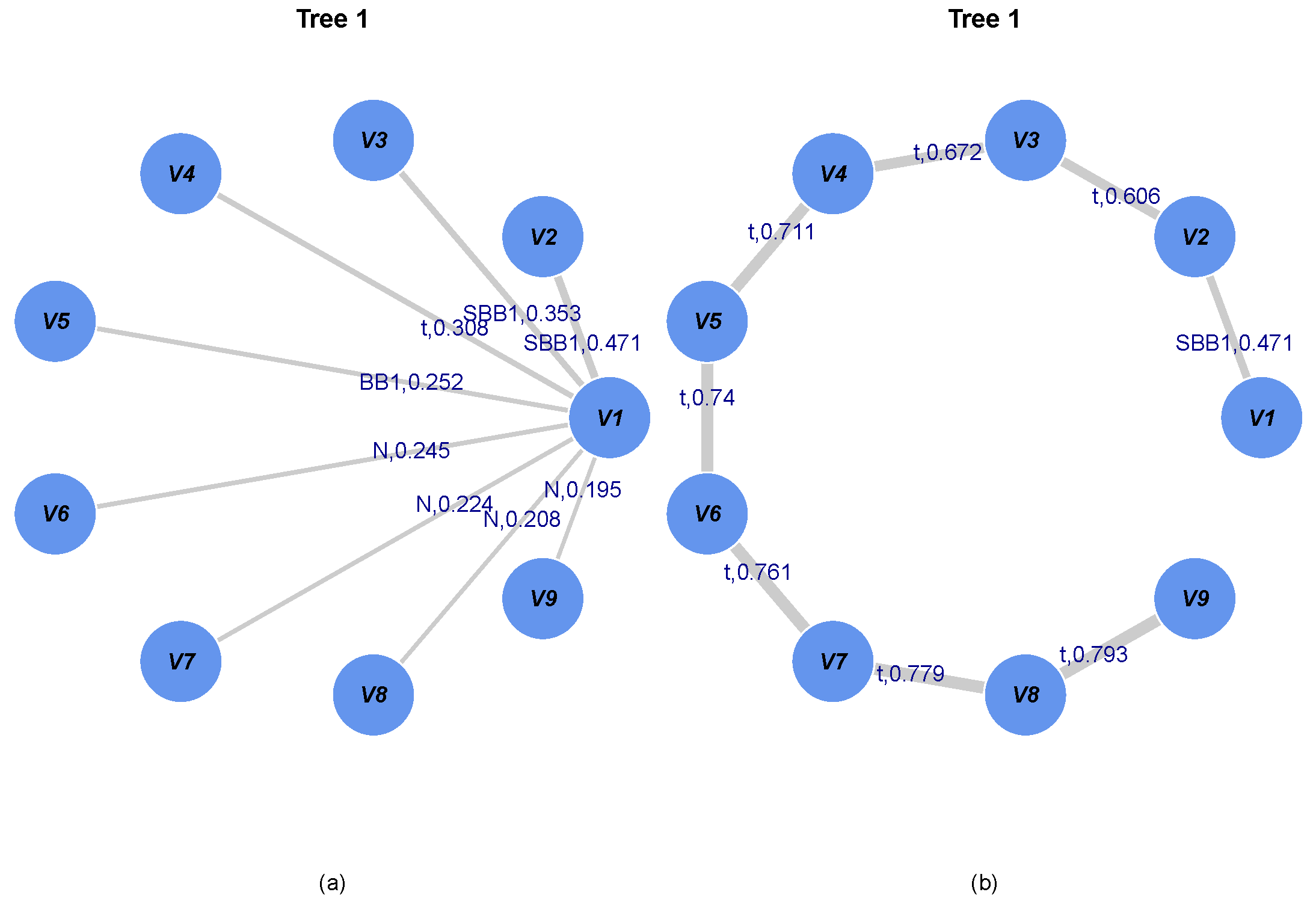
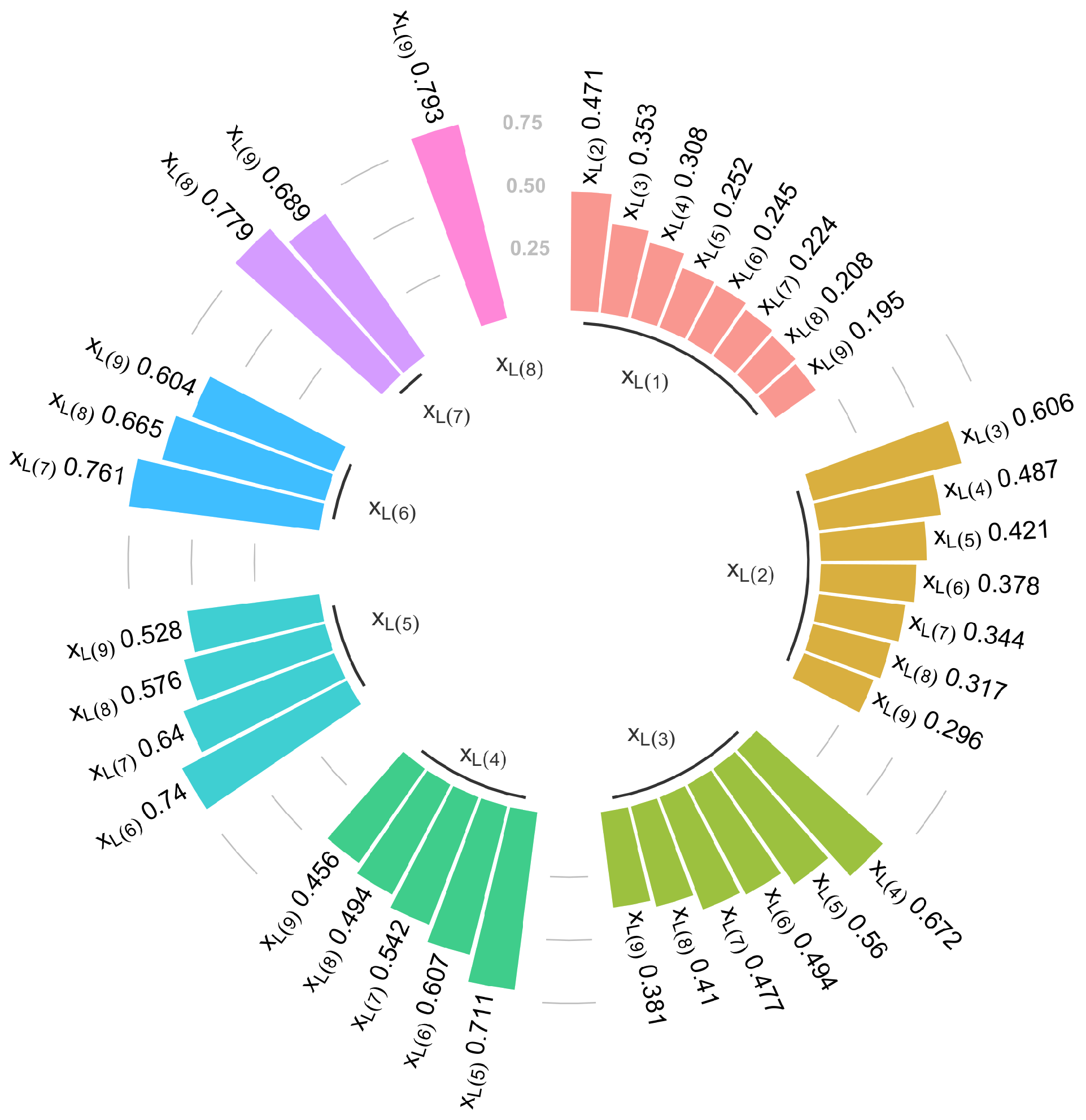
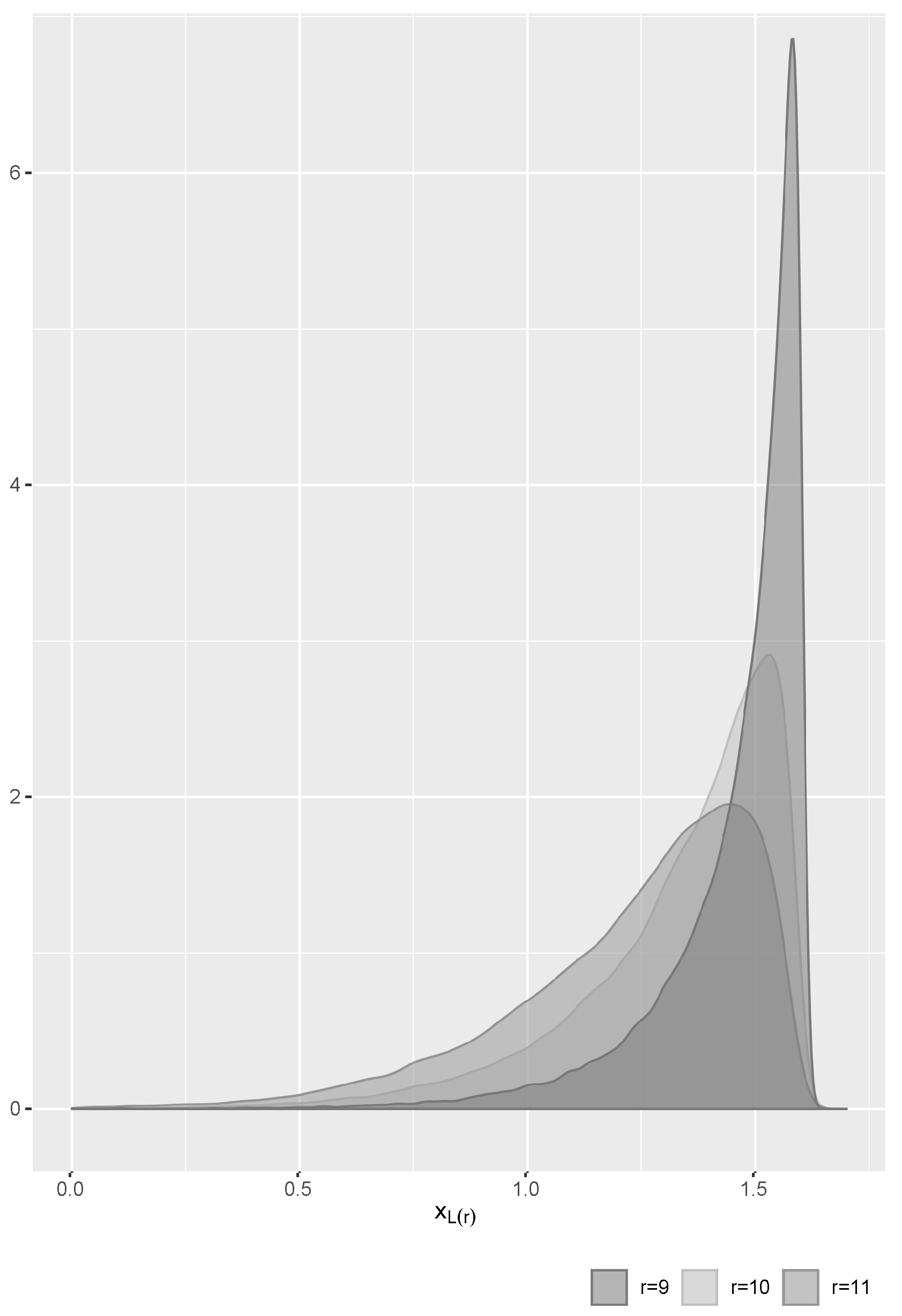
4. Application: Arctic Sea Ice
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Proof
References
- Chandler, K.N. The distribution and frequency of record values. J. R. Stat. Soc. Ser. B 1952, 14, 220–228. [Google Scholar] [CrossRef]
- Balakrishnan, N.; Ahsanullah, M.; Chan, P.S. Relations for single and product moments of record values from Gumbel distribution. Stat. Probab. Lett. 1992, 15, 223–227. [Google Scholar] [CrossRef]
- Coles, S.G.; Tawn, J.A.A. Bayesian analysis of extreme rainfall data. J. R. Stat. Soc. Ser. C 1996, 45, 463–478. [Google Scholar] [CrossRef]
- Wang, B.X.; Yu, K.; Coolen, F.P. Interval estimation for proportional reversed hazard family based on lower record values. Stat. Probab. Lett. 2015, 98, 115–122. [Google Scholar] [CrossRef]
- Seo, J.I.; Kim, Y. Statistical inference on Gumbel distribution using record values. J. Korean Stat. Soc. 2016, 45, 342–357. [Google Scholar] [CrossRef]
- Seo, J.I.; Kim, Y. Objective Bayesian analysis based on upper record values from two-parameter Rayleigh distribution with partial information. J. Appl. Stat. 2017, 44, 2222–2237. [Google Scholar] [CrossRef]
- Seo, J.I.; Kim, Y. Objective Bayesian entropy inference for two-parameter logistic distribution using upper record values. Entropy 2017, 19, 208. [Google Scholar] [CrossRef]
- Imani, M.; Braga-Neto, U.M. Finite-horizon LQR controller for partially-observed Boolean dynamical systems. Automatica 2018, 95, 172–179. [Google Scholar] [CrossRef]
- Imani, M.; Dougherty, E.R.; Braga-Neto, U. Boolean Kalman filter and smoother under model uncertainty. Automatica 2020, 111, 108609. [Google Scholar] [CrossRef]
- Sklar, M. Fonctions de répartition á n dimensions et leurs marges. Publ. Inst. Stat. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Tsung, F.; Zhang, K.; Cheng, L.; Song, Z. Statistical transfer learning: A review and some extensions to statistical process control. Qual. Eng. 2018, 30, 115–128. [Google Scholar] [CrossRef]
- Rocher, L.; Hendrickx, J.M.; De Montjoye, Y.A. Estimating the success of re-identifications in incomplete datasets using generative models. Nat. Commun. 2019, 10, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Joe, H. Families of m-variate distributions with given margins and m(m−1)/2 bivariate dependence parameters. Lect. Notes Monogr. Ser. 1996, 28, 120–141. [Google Scholar]
- Aas, K.; Czado, C.; Frigessi, A.; Bakken, H. Pair-copula constructions of multiple dependence. Insur. Math. Econ. 2009, 44, 182–198. [Google Scholar] [CrossRef]
- Berg, D.; Aas, K. Models for construction of multivariate dependence: A comparison study. Eur. J. Financ. 2009, 15, 639–659. [Google Scholar]
- Fischer, M.; Köck, C.; Schlüter, S.; Weigert, F. An empirical analysis of multivariate copula models. Quant. Financ. 2009, 9, 839–854. [Google Scholar] [CrossRef]
- Nelsen, R.B. An Introduction to Copulas, 2nd ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Ahsanullah, M. Record Statistics; Nova Science Publishers, Inc.: New York, NY, USA, 1995. [Google Scholar]
- Arnold, B.C.; Balakrishnan, N.; Nagaraja, H.N. Records; Wiley: New York, NY, USA, 1998. [Google Scholar]
- Wang, B.X.; Yu, K.; Jones, M.C. Inference under progressively Type II right-censored sampling for certain lifetime distributions. Technometrics 2010, 52, 453–460. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Equal-Tails | Shortest | Equal-Tails | Shortest | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Classical | MCMC | Classical | MCMC | Classical | MCMC | Classical | MCMC | MCMC | |||
| 0.5 | 6 | 0.948(3.094) | 0.948(3.093) | 0.950(2.600) | 0.949(2.565) | 0.951(2.623) | 0.950(2.603) | 0.952(2.214) | 0.950(2.194) | 0.950(2.942) | 0.942(2.440) |
| 8 | 0.949(2.456) | 0.948(2.455) | 0.950(1.957) | 0.949(1.923) | 0.951(2.172) | 0.949(2.150) | 0.951(1.740) | 0.949(1.712) | 0.954(2.791) | 0.946(2.344) | |
| 10 | 0.948(2.123) | 0.948(2.120) | 0.950(1.618) | 0.949(1.604) | 0.950(1.925) | 0.947(1.905) | 0.952(1.475) | 0.950(1.454) | 0.952(2.731) | 0.947(2.268) | |
| 12 | 0.948(1.915) | 0.948(1.919) | 0.948(1.405) | 0.948(1.401) | 0.951(1.765) | 0.948(1.760) | 0.949(1.301) | 0.948(1.297) | 0.950(2.580) | 0.944(2.174) | |
| 0.8 | 6 | 0.948(3.094) | 0.948(3.093) | 0.950(2.600) | 0.949(2.565) | 0.951(2.623) | 0.950(2.603) | 0.952(2.214) | 0.950(2.194) | 0.950(3.517) | 0.942(3.006) |
| 8 | 0.949(2.456) | 0.948(2.455) | 0.951(1.957) | 0.949(1.923) | 0.951(2.172) | 0.949(2.150) | 0.951(1.740) | 0.949(1.712) | 0.953(3.406) | 0.944(2.942) | |
| 10 | 0.948(2.123) | 0.948(2.120) | 0.950(1.618) | 0.949(1.604) | 0.950(1.925) | 0.947(1.905) | 0.952(1.475) | 0.950(1.454) | 0.954(3.370) | 0.948(2.887) | |
| 12 | 0.948(1.915) | 0.948(1.919) | 0.948(1.405) | 0.948(1.401) | 0.951(1.765) | 0.948(1.760) | 0.949(1.301) | 0.948(1.297) | 0.950(3.225) | 0.940(2.801) | |
| 1.5 | 6 | 0.948(3.094) | 0.948(3.093) | 0.950(2.600) | 0.949(2.565) | 0.951(2.623) | 0.950(2.603) | 0.952(2.214) | 0.950(2.194) | 0.950(4.561) | 0.940(4.068) |
| 8 | 0.949(2.456) | 0.948(2.455) | 0.951(1.957) | 0.949(1.923) | 0.951(2.172) | 0.949(2.150) | 0.951(1.740) | 0.949(1.712) | 0.953(4.486) | 0.945(4.027) | |
| 10 | 0.948(2.123) | 0.948(2.120) | 0.950(1.618) | 0.949(1.604) | 0.950(1.925) | 0.947(1.905) | 0.952(1.475) | 0.950(1.454) | 0.957(4.482) | 0.943(4.007) | |
| 12 | 0.948(1.915) | 0.948(1.919) | 0.948(1.405) | 0.948(1.401) | 0.951(1.765) | 0.948(1.760) | 0.949(1.301) | 0.948(1.297) | 0.952(4.346) | 0.939(3.939) | |
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 3.95 | 2.66 | 2.47 | 2.32 | 2.19 | 2.17 | 2.05 | 1.60 | 1.29 |
| Equal-tails | Classical | (0.462, 2.672) | (0.631, 2.635) | - |
| MCMC | (0.465, 2.675) | (0.631, 2.619) | (9.747, 77.629) | |
| Shortest | Classical | (0.349, 2.330) | (0.526, 2.333) | - |
| MCMC | (0.347, 2.321) | (0.507, 2.302) | (6.130, 65.137) | |
| Mean | Median | Equal-Tails | Shortest | |
|---|---|---|---|---|
| 1.457 | 1.516 | (0.987, 1.599) | (1.118, 1.600) | |
| 1.407 | - | (1.071, 1.850) | - | |
| 1.336 | 1.401 | (0.735, 1.583) | (0.876, 1.600) | |
| 1.237 | - | (0.840, 1.821) | - | |
| 1.231 | 1.298 | (0.552, 1.560) | (0.693, 1.591) | |
| 1.087 | - | (0.677, 1.746) | - |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Song, J.J.; Kim, Y.; Seo, J.I. Estimation and Prediction of Record Values Using Pivotal Quantities and Copulas. Mathematics 2020, 8, 1678. https://doi.org/10.3390/math8101678
Lee J, Song JJ, Kim Y, Seo JI. Estimation and Prediction of Record Values Using Pivotal Quantities and Copulas. Mathematics. 2020; 8(10):1678. https://doi.org/10.3390/math8101678
Chicago/Turabian StyleLee, Jeongwook, Joon Jin Song, Yongku Kim, and Jung In Seo. 2020. "Estimation and Prediction of Record Values Using Pivotal Quantities and Copulas" Mathematics 8, no. 10: 1678. https://doi.org/10.3390/math8101678
APA StyleLee, J., Song, J. J., Kim, Y., & Seo, J. I. (2020). Estimation and Prediction of Record Values Using Pivotal Quantities and Copulas. Mathematics, 8(10), 1678. https://doi.org/10.3390/math8101678