1. Introduction
State estimation is important for virtually all areas of engineering and science. Every discipline which uses the mathematical modeling of its systems needs state estimation; this includes electrical engineering, mechanical engineering, chemical engineering, aerospace engineering, robotics, dynamical systems’ control and many others.
We estimate the system’s state based on the measurement results. In this estimation, we need to take into account that measurements are never absolutely accurate, the measurement results contain inaccuracy (“noise”)—e.g., due to inevitable imperfection of the measuring instruments. Also, our understanding of the system’s dynamics is also usually approximate. In addition to the internal factors (which are described by the system’s state) and the known external factors, there are usually also many other factors that affect the system—and which, from the viewpoint of the model, constitute the noise. The presence of noise affects our ability to predict the system’s behavior and to control the system. It is therefore desirable to minimize the effect of the noise—in particular, to minimize the effect of noise on the state estimation. In engineering, traditionally, techniques for decreasing the effect of noise—i.e., for separating (“filtering”) signal from noise—are known as filtering; because of this, the state estimation problem can be viewed as an important particular case of filtering.
To formulate the state estimation problem in precise terms, we need to have a mathematical model of the actual system, and we need to have a model describing the system’s and measurement uncertainties (noise). To select the best filtering technique, we also need to select a numerical measure for describing the remaining inaccuracy of state estimation. Once this measure is selected, we need, given the measurement results, to find the state estimates for which the selected measure of inaccuracy attains the smallest possible value; see, e.g., [
1]. In other words, from the mathematical viewpoint, estimating a state means solving the corresponding optimization problem.
The quality of the resulting state estimates depends on how well our models— i.e., our assumptions about the system and about the noise—describe the actual system and the actual noise. The most widely used state estimation techniques are stochastic techniques, i.e., techniques based on the assumption that we know the probability distribution of the noise (or, more generally, that we have some information about this distribution). In most techniques, it is assumed that the noise is Gaussian, but other distributions have also been considered. Stochastic techniques have been actively developed for dozens (if not hundreds) of years.
The most widely used stochastic state estimation techniques are the Kalman Filter (KF) techniques [
2] and the Extended Kalman Filter (EKF) techniques [
3,
4]. In most practical applications, the traditional Kalman filters are used, which are based on the assumption that the system is linear (and that the noise is Gaussian). In practice, however, many real-life system are non-linear (and the actual noise distribution is sometimes non-Gaussian).
Because of the ubiquity of non-linear systems, several filtering techniques have been developed for the non-linear case. Many applications use the finite sum approximation techniques such as the Gaussian sum filter (see, e.g., [
5]) or linearization techniques such as EKF (see, e.g., [
6]). These techniques work well for many non-linear systems. Their main limitation is that they assume that both the system noise and the measurement noise are normally distributed. As a result, sometimes, when the actual distributions are non-Gaussian—e.g., when they are multi-modal—these techniques do not perform well.
Another widely used filtering techniques applicable to non-linear systems is the
Unscented Kalman Filter (UKF), first proposed in [
7]. The UKF technique is based on using a special non-linear transformation of the data—called Unscented Tranform (UT)—that, crudely speaking. transforms the actual probability distributions into simpler ones. The main advantage of UKF is that, in contrast to EKF, UKF techniques do not assume that the required nonlinear transformations are smooth (differentiable). As a result, UKF does not involve time-consuming computation of the corresponding derivatives—i.e., Jacobian and Hessian matrices. On the other hand, because of their more general nature, UKF algorithms are more complex and, in general, require more computation time.
Yet another widely filtering technique for nonlinear (and non-Gaussian, and non-stationary) situations is the Particle Filter (PF) technique [
8]. The main idea of this technique is that we simulate each probability distribution by selecting several sample points (called
particles). We start with selecting several states distributed according to the known prior distribution of the system’s state. To each of the selected states, we apply the system’s dynamics—simulating the corresponding system’s noise and measurement noise. The resulting sample of states (and sample of expected measurement results) represent the distributions corresponding to the next moment of time. We can then use the actual observation results obtained at this moment of time to update the distributions. This method works very well in many practical applications. For example, in geodesy, the PF techniques have been successfully used to accurately determine the trajectory on a moving vehicle based on Laser-scanner-based multi-sensor measurements [
9,
10].
While these techniques work well in many practical situations, they all have a common limitation: they assume that we have a reasonably detailed information about the corresponding probability distributions. In practice, often, we do not have that information. Sometimes, some approximate distributions are provided, but the actual frequencies of different noise values are very different from what these approximate distributions predict. This is a frequent situations, e.g., for measuring instruments, when the manufacturer provides us only with an upper bound on the systematic error component (or even on the overall measurement error) without providing any information on the probabilities of different values within the given bounds; see, e.g., [
11].
Such situations are known as situations with Unknown But Bounded uncertainty (UBB). Techniques for state estimation under such uncertainty have been developed since the 1960s; see, e.g., [
12,
13,
14].
In the case of UBB uncertainty, for each noise component, once we know the upper bound
on its absolute value, the only information that we have about the actual noise value is that this value is located in the interval
; we do not know the probabilities of different values from this interval. Once we know the bounds
on each noise value
(
), we can therefore conclude that the tuple
formed by these noise values belongs to the box
methods for processing such information are given, e.g., in [
15,
16,
17].
We may also have some additional information about the relation between different noise values—e.g., the upper bound on the difference between noise values at two consequent moments of time. As a result, in addition to the interval containing each noise value, we may know a bounded close (hence compact) set containing the tuples of possible noise values.
There exist several techniques for dealing with such uncertainty. The most accurate techniques are the ones that use generic polytopes [
18,
19]—since by using polytopes, we can approximate any reasonable compact set with any given accuracy. However, to get an accurate approximation, we need to use a large number of parameters—especially in multi-dimensional case. As a result, in practice, these general methods are only efficient in low-dimensional situations.
Somewhat faster techniques emerge when we limit ourselves to a special class of polytopes called
zonotopes; see, e.g., [
1,
20,
21,
22,
23]. Mathematically, zonotopes are defined as Minkowski sums of intervals (for those who are not familiar with this notion, the definition of Minkowski sum is given in the next section). These methods are more efficient, but still mostly limited to low-dimensional cases.
The only efficient general techniques available in the higher-dimensional cases are techniques based on using ellipsoids; see, e.g., [
24,
25,
26]. If we use ellipsoids, then some problems becomes easy to solve: e.g., if the system is linear and we know the ellipsoid that contains its initial state, then the set of all possible states at the next moment of time is also an ellipsoid, and this ellipsoid can be easily computed. Other problems are not so easy. For example, if we have two different sources of noise and each of them is described by an ellipsoid, then the set of possible values of the overall noise is no longer an ellipsoid—using the term which is explained on the next section, it is the Minkowski sum of the two original ellipsoids. To apply the ellipsoid technique to this situation, we need to enclose this Minkowski sum into an ellipsoid. We want this enclosing ellipsoid to represent the sum as accurately as possible—so, to compute this ellipsoid, we need to solve the corresponding optimization problem (this will also be described in the next section).
The above techniques take care of the situations in which we either know all the corresponding probability distributions or we do not know the probabilities at all—we only know the bounds on the noises. In practice, often, we have the probability information about some noise components, and we only know bounds on other components of the noise. For such situations, we need state estimation techniques that would take both types of uncertainty into account. For the linear case, such techniques have been developed by Benjamin Noack in his PhD dissertation [
27]. In this paper, we extend these techniques to the general nonlinear case.
Following Noack, we use ellipsoids to describe the UBB uncertainty. At this stage of our research, we limit ourselves to the situations when all the probability distributions are Gaussian. Thus, we call our new filtering techniques the Ellipsoidal and Gaussian Kalman Filter (EGKF, for short).
For random uncertainties, the newly proposed method keeps the Kalman filter’s recursive framework, and thus, with respect to this uncertainty, is as efficient as the original KF. Of course, since we also use ellipsoidal uncertainty, we need to solve an optimization problem on each step, as a result of which our method requires somewhat more computation time than the usual KF.
The structure of the paper is as follows.
Section 2 describes the mathematical definitions and results that are used in the following text—including the general definitions and results about the corresponding dynamical systems and filters. In
Section 3, we analyze the corresponding problem, derive the formulas of the resulting EGKF algorithm, and, finally, present this algorithm in a practical ready-to-use form. In
Section 4, we show, on several test cases, how the new method works—and we show that, in most cases, it indeed performs better than EKF. The last section contains conclusions and future work.
2. Mathematical Model
This section contains the mathematical definitions and results that are used in the following text—including the general definitions and results about the corresponding dynamical systems and filters. It also includes the formulation of the problem in precise terms.
2.1. Mathematical Definitions and Results Used in This Paper
The following definitions, theorems and corollaries are required for the derivation of the new filter model EGKF. Proofs of these results can be found, e.g., in [
26].
Definition 1. Let n be a positive integer. By a bounded ellipsoid in with nonempty interior (or simply ellipsoid, for short) we mean a setwhere and S is a positive definite matrix (this will be denoted by ). is called the center of the ellipsoid , and S is called the shape matrix. The shape matrix specifies the size and orientation of the ellipsoid.
Definition 2. Let A and B be sets in the Euclidean space . By the Minkowski sum
of A and B, we mean the set of all possible values obtained by adding elements of A and B: In general, for
K ellipsoids in
their Minkowski sum
is not an ellipsoid anymore; however, it is still a convex set.
In this paper, we will look for the ellipsoid with the smallest trace that contains the Minkowski sum. We selected this criterion since it corresponds to minimizing the mean square error in the probabilistic case. In principle, we could instead minimize the volume of the ellipsoid—which corresponds to minimizing the determinant of the shape matrix, or the largest eigenvalue of the shape matrix . Minimizing the largest eigenvalue makes the ellipsoid more like a ball (in 2D case, more like a circle). Minimizing the volume sometimes leads to oblate ellipsoids, with large uncertainty in some directions.
For minimizing the trace, we will denote the corresponding minimization problem by
:
It is known that the optimal ellipsoid
always exists and is unique [
26].
Theorem 1. The center of the optimal ellipsoid for Problem is given by Theorem 2. Let be the convex set of all vectors for which for all k and . Then, for any , the ellipsoid , with defined by (6) andcontains the Minkowski sum . Corollary 1. (Special case of Theorem 2) When , we have , so the formula for can be rewritten aswhere β can be any positive real number. Proof of Corollary 1. Indeed, for each , we can take and . ☐
Theorem 3. In the family , the minimal-trace ellipsoid containing the Minkowski sum of the ellipsoids is obtained for Corollary 2. (Special case of Theorem 3) When , we have 2.2. Dynamical Systems and Linearization
In this paper, we consider the following general discrete-time nonlinear system:
where:
is a n-dimensional state vector at time ,
is the known input vector,
is a Gaussian system noise with covariance matrix ,
is an UBB perturbation with shape matrix ,
is a Gaussian measurement noise with covariance matrix ,
is an UBB perturbation with shape matrix —all at the time .
To make notations clearer, in this paper, parameters related to the first (system) equation will be denoted by u and parameters related to the second (measurement) equation will be denoted by z.
Similarly to EKF, we start with linearization: namely, we expand the right-hand side of the above equations in Taylor series and keep only linear terms in the corresponding expansion. For the system Equation (
11a), we perform Taylor expansion around the point
and get the following result:
Here, we denoted and , , and denote the corresponding derivatives. Note that, in spite of the fact that our uncertainty model is different from the purely probabilistic model underlying the EKF technique, the resulting formulas are similar to the corresponding EKF formulas–since at this stage, we did not yet use any information about the uncertainty.
For the measurement Equation (11b), a similar Taylor expansion around the natural point
leads to the following formula:
Here, we denoted . Notice that if the measurement equation is linear, then .
Thus, from the original system (11), we get the following linearized system:
These equations describe the change in the (unknown) true state . In practice, we only know the estimates for the state. Following the general idea of Kalman filter, at each moment of time , we will consider:
an a priori estimate of this state—i.e., what we predict based on the information available at the previous moment of time—and
an a posterior estimate—what we get after taking into account the results of measurements performed at this moment of time.
In this paper, we will denote the a priori estimate by and the a posteriori estimate by .
Since we consider the case when the system has both the random and the unknown-but-bounded error components (14), both a priori and a posteriori estimates should have the same form:
where
and
are points,
and
are random variables with Gaussian distribution,
and
are two points within two ellipsoids with shape matrices
and
respectively.
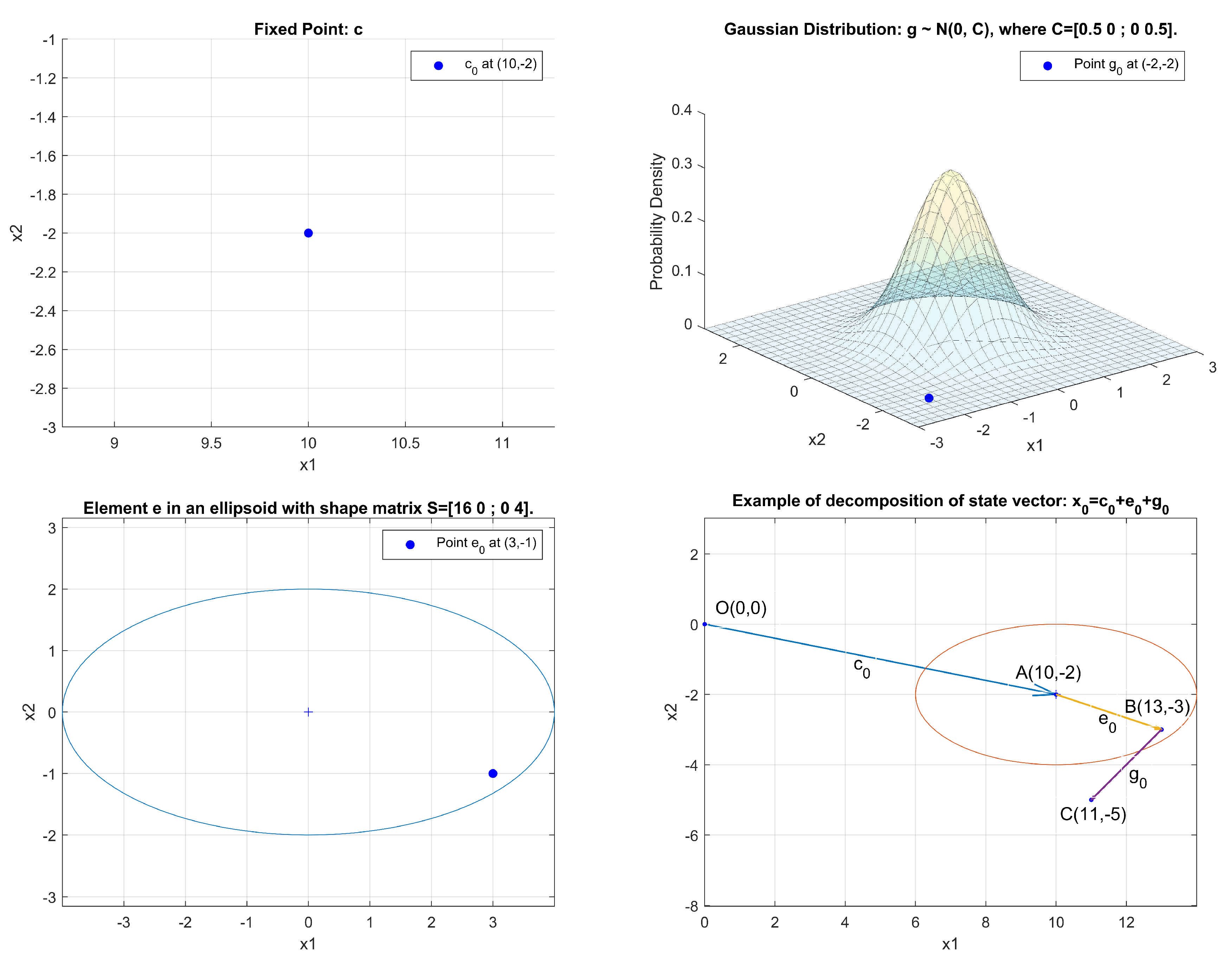
Figure 1 illustrates shows how a state
can be decomposed into the sum of the point estimate
and two perturbations: the UBB noise component
and the Gaussian noise component
.
Our objective is to use the measurement results to generate the a posteriori estimate , i.e., in precise terms, to compute the point estimate and the matrices and .
4. Applications
This section contains the result of two test of applying EGKF to simulated data sets. We also applied EKF to both problems, and compared the root-mean-square error (RMSE) of the two methods.
In the first test, EGKF was applied on a highly nonlinear benchmark problem. To compare the result, we performed 100 simulations.
In the second test, we applied EGKF on a two-dimensional trajectory estimation problem. For this problem, we performed 1000 Monte Carlo runs.
To simulate the UBB uncertainty, we used uniform distributions on the corresponding ellipsoids.
4.1. Example 1: A Highly Nonlinear Benchmark Example
We consider the following example:
where:
is a 1-dimensional scalar,
is the input vector,
is Gaussian noise,
is the unknown but bounded perturbation; in this 1-D case the ellipsoid is simply the interval ,
is Gaussian measurement noise,
is the unknown but bounded perturbation—in this case, the ellipsoid is the interval .
Here:
the initial true state is ,
the initial state estimate is ,
the initial estimate for covariance matrix is ,
the initial estimate for the shape matrix is .
This discrete-time dynamical system is a known benchmark in the nonlinear estimation theory; see, e.g., [
6,
8,
29]. A high degree of nonlinearity in both process and measurement equations makes state estimation problem for this system very difficult.
We use this example to show that the new EGKF method behaves better than the traditional first order EKF when UBB uncertainties are taken into account.
We used a simulation length of 50 time steps. Following recommendations from the previous section, we selected the weight parameter .
We repeated our simulation 100 times.
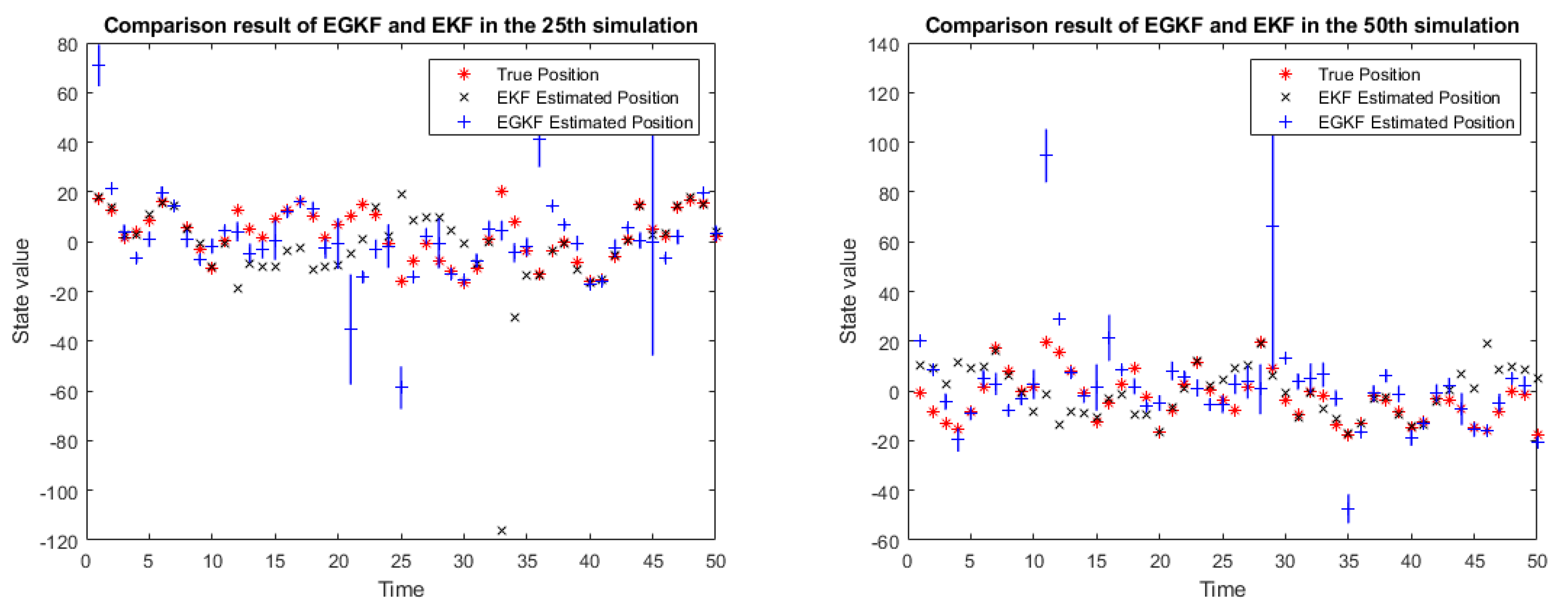
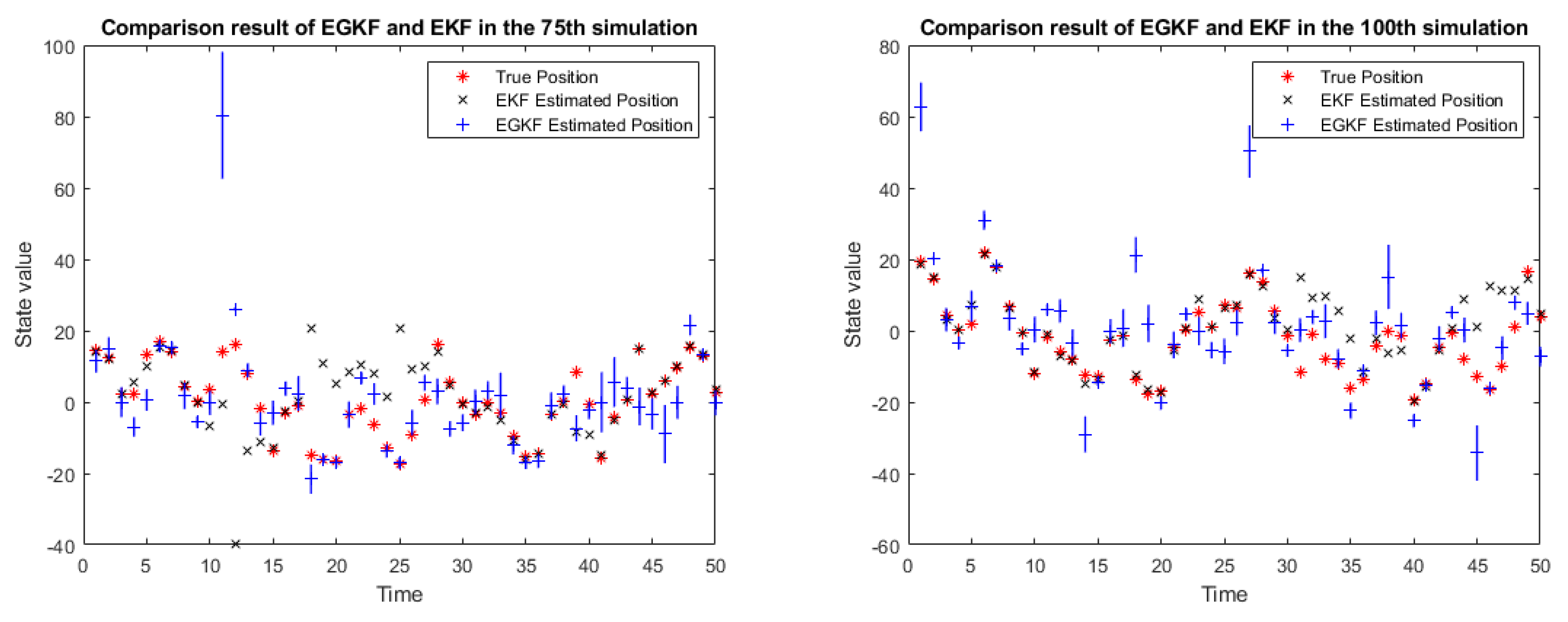
Figure 2 shows the results of applying both EGKF and EKF for several of the 100 runs, namely, for runs 25, 50, 75, and 100.
In the above figure:
the red stars denote the true state,
the black crosses represent the EKF estimates of the state,
the blue lines represent the UBB ellipsoids estimated by EGKF (in this 1D case they are intervals),
the blue plus signs mark the centers of the output ellipsoids.
One can see that the centers of the ellipsoids are, in general, different given from the EKF estimates.
For each of the two methods and for each of the 100 iterations, at each moment of time, we can calculate the difference between the actual state and the corresponding estimate. (As estimates corresponding to EGKF, we took the centers of the corresponding a posterior ellipsoids.)
Based on 50 moments of time, we get a vector consisting of 50 such actual-state-vs.-estimated-state differences. To compare the vectors corresponding to two different methods, we calculated the
norms of these vectors—this is equivalent to comparing the root-mean-square estimation errors. The resulting values are presented in
Table 1 for simulations 1, 11, …, 91.
In most cases, the EGKF leads to a smaller mean squared estimation error. Over all 100 simulations:
the average norm of the EGKF estimates is 148.70, while
for the extended Kalman filter, the average norm is much higher: it is equal to 192.29.
Thus, we conclude that, on average, the new EGKF algorithm performs much better than EKF.
We got a similar conclusion when, instead of comparing the norms, we compared:
the norms—which correspond to comparing mean absolute values of the estimation errors, and
the norms—which correspond to comparing the largest estimation errors.
4.2. Example 2: Two-Dimensional Trajectory Estimation
In the second test, we used 1000-times Monte Carlo simulations to compare the performance of EGKF and EKF on a 2D trajectory estimation problem from [
10].
In this problem, a vehicle moves on a plane, following a curved trajectory. The state vector
contains positions and velocities of the vehicle, in x-direction and y-direction, respectively. After linearization, we get the following equation:
Here:
is the state vector at time ;
the transition matrix
has the form:
is Gaussian noise with covariance matrix ,
is the unknown but bounded uncertainty, which is bounded by an ellipsoid with shape matrix .
In total, in each of the 1000 simulations, we observed 500 epochs with time step s. In our formulas, as units of time, distance, and angle, we chose second, meter and degree, respectively.
In this experiment, two observation stations located at points
and
performed the measurements. Each station measured the distance to the vehicle and the direction to the vehicle, as described by the following equation:
Here:
represents random uncertainty; it is Gaussian with covariance matrix ,
represents the unknown but bounded uncertainty; it is bounded by an ellipsoid with shape matrix .
The initial state estimate, and initial estimates for the covariance matrix and for the shape matrix are:
,
,
.
The initial covariance matrices in process equation and measurement equation are:
The initial shape matrices of UBB uncertainties in process equation and measurement equation are:
As in the first example, we select the value of the weighting parameter.
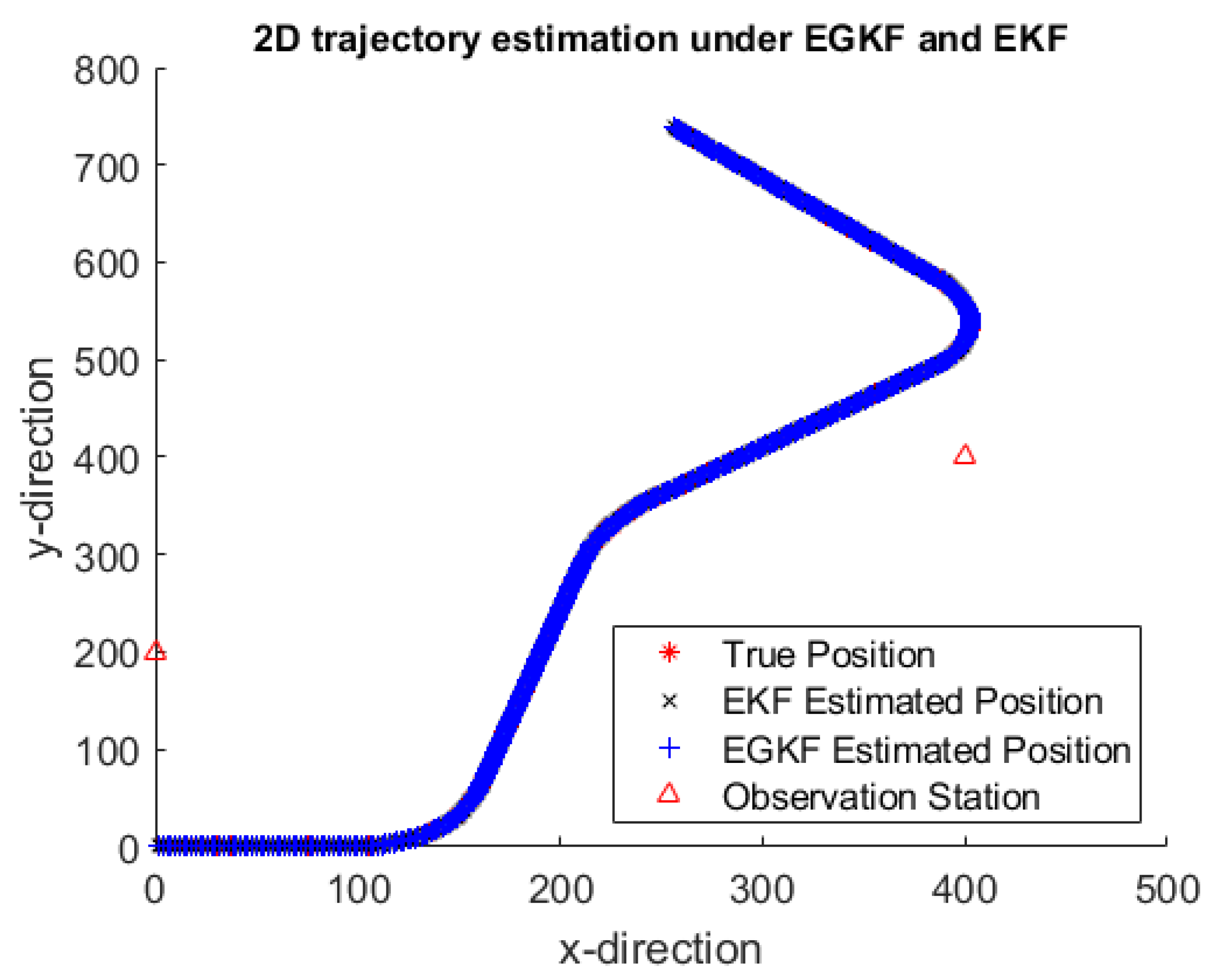
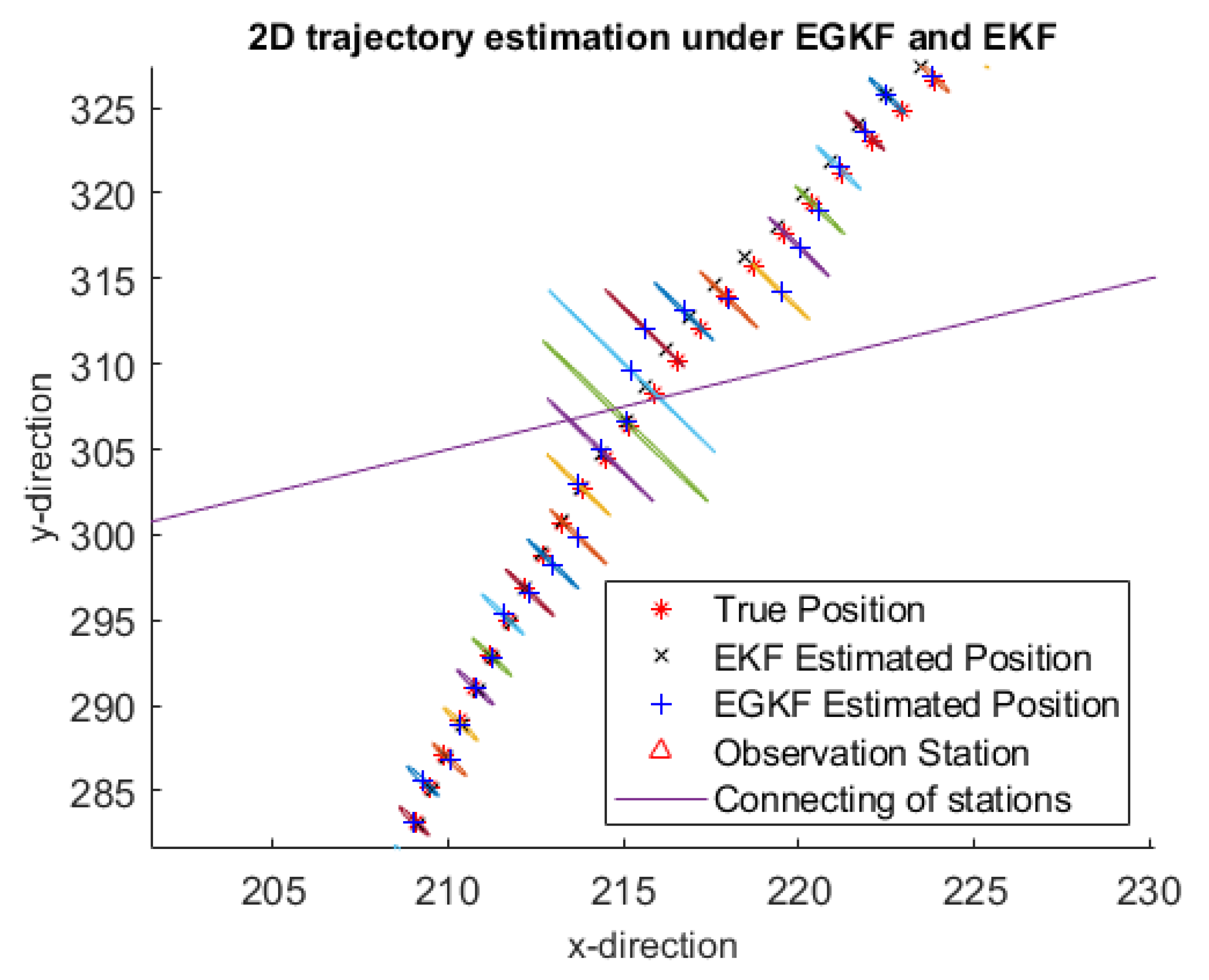
Figure 3 shows an example of trajectory estimates by using EGKF and EKF obtained on one of the 100 iterations—namely, on the 5th iteration. To see it clearer,
Figure 4 shows a more detailed information for several portions of the trajectory.
Here:
the red stars mark the true positions,
black crosses mark the EKF estimates,
the blue plus signs are the centers of the ellipsoids computed by EGKF.
The two observation stations are marked by red triangles; they are connected by a straight line.
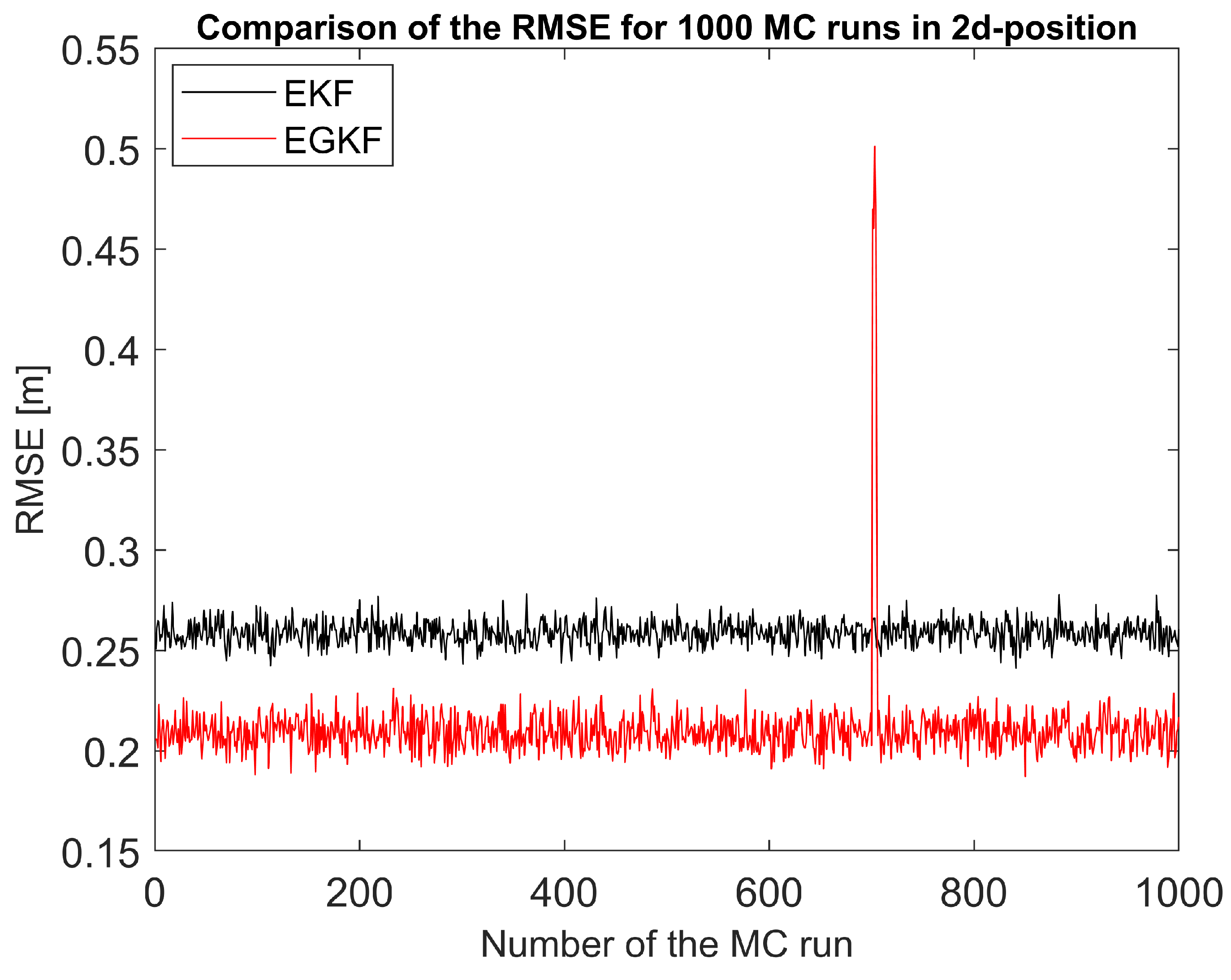
Figure 5 shows the comparison of RMSE estimation errors EGKF and EKF averaged over all 1000 Monte-Carlo runs.
The peak occurred in the figure between [600, 800] is probably caused by the random uncertainty, just like what EKF behaves in nonlinear applications sometimes. In this experiment we introduced new UBB uncertainty but we still kept the influence of random uncertainty (). The new EGKF can provide a better global estimation than EKF but a few exceptions may still happen. This unexpected jump also caused a larger standard deviation value in EGKF.
In almost all simulations (namely, in 997 cases out of 1000), the RMSE of EGKF was significantly smaller than for the EKF. We can therefore conclude that the new EGKF techniques provides better estimation for this nonlinear system than EKF. Detailed statistics of the comparison can be found in
Table 2.
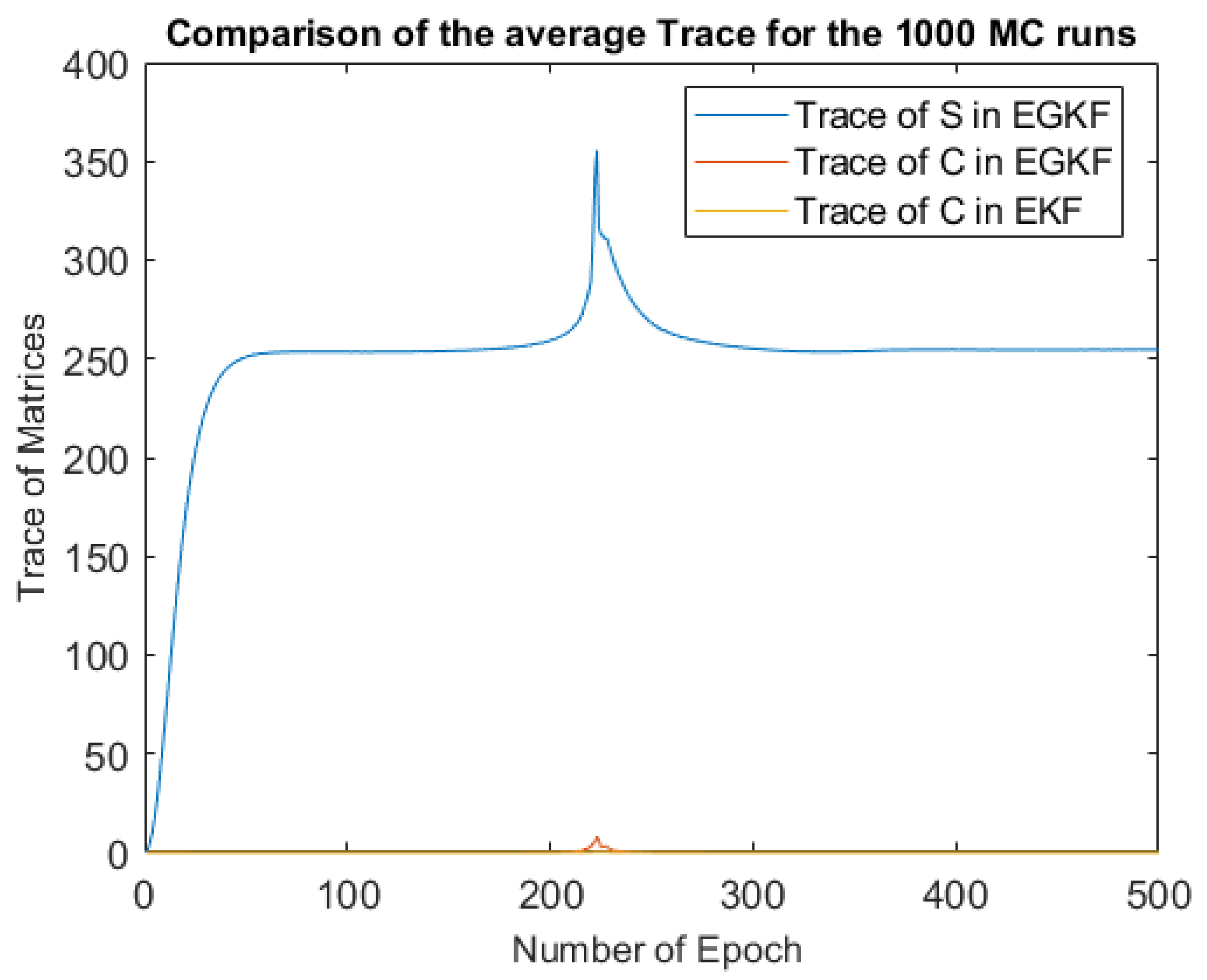
In
Figure 6, we compared the average traces (over all 1000 Monte-Carlo runs) of EGKF UBB shape matrix
, EGKF covariance matrix
and EKF covariance matrix, in every epoch.
Notice that the trace of EGKF shape matrix is much larger than the traces of covariance matrices.
We can also see that the UBB uncertainty grows in the starting part of the trajectory and when the trajectory crosses the straight line connecting the observation stations—this corresponds to . This phenomenon is easy to explain: in this case, both angle measurements measure, in effect, the same quantity, so from the measurements, we get fewer information than in other parts of the trajectory.
The EGKF algorithm has been applied to a data set which is obtained from a real world experiment see, e.g., [
30]. In that experiment, taken from the scope of georeferencing of terrestrial laser scanner, a multi-sensor system has collected the trajectory information of two GNSS antennas. EGKF was applied to estimate the positions and velocities of those two antennas and the results were compared with EKF.
5. Conclusions and Future Work
In this paper, we propose a new method for state estimation in situations when, in addition to the probabilistic uncertainty, we also have unknown-but-bounded errors. Our testing shows that, on average, the new method leads to much more accurate estimates than the standard extended Kalman filter.
While our method has been shown to be successful, there is room for improvement.
First, the efficiency of our method depends on the initial selection of the parameters describing the system uncertainty and the measurement uncertainties. In some practical situations, we have prior information about these uncertainties, but in other practical cases, we do not have this information. Similarly to the usual Kalman filter, our method eventually converges to the correct uncertainty estimate, but this convergence may be somewhat slow. It would be nice to come up with recommendations on how to select the initial uncertainty parameters that would guarantee faster convergence.
Second, in our method, we assumed that measurements are reasonably frequent, so that during the time interval between the two measurements, we can safely ignore terms quadratic in terms of the corresponding changes—and thus consider a linearized system of equations. This is true in many practical situations—e.g., in the example of GNSS-based navigation that we considered in this paper. However, in some practical situations, measurements are rarer, and so, in the interval between the two measurements, we can no longer ignore terms which are quadratic in terms of changes. To cover such situations, it is desirable to extend our technique to second-order Kalman filtering.
Third, in this paper, we followed the usual Kalman filter techniques in assuming that the corresponding probability distributions are Gaussian. As we mentioned in
Section 1, in practice, sometimes distributions are not Gaussian. It is therefore desirable to extend our method to the general non-Gaussian case – e.g., by using ideas of unscented Kalman filtering.
Fourth, in our method, we minimized the mean square estimation error—which, for our method, corresponds to selecting an ellipsoid with the smallest possible trace of the corresponding shape matrix. While in many practical problems, minimizing the mean square error is a reasonable idea, in some problems, it may be more reasonable to minimize, e.g., the largest possible estimation error. In this case, as we have mentioned, instead of minimizing the trace, we should be minimizing the largest eigenvalue of the shape matrix. It is this desirable to extend our method to this—and other—possible criteria.
Fifth, to make computations feasible, we approximated the set of possible states by an ellipsoid. In principle, we can get more accurate estimates if we use families of sets with more parameters for such approximation—e.g., zonotopes or, more generally, generic polytopes. From this viewpoint, it is desirable to come up with efficient algorithms for processing zonotope (and, more generally, polytope) uncertainty.
Finally, it is desirable to analyze (and, if necessary, improve) the stability of our method (and of other state estimation techniques). While stability is very important for practical problems, it is not even clear how to formulate this problem in precise mathematical terms, since the state estimation problems are usually ill-posed—as most inverse problems (see, e.g., [
31])—and thus, strictly speaking, not stable.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}