1. Introduction
The lognormal diffusion process has been widely used as a probabilistic model in several scientific fields in which the variable under consideration exhibits an exponential trend. Originally, the lognormal diffusion process was mainly applied to modeling dynamic variables in the field of economy and finance. Important contributions have been made in this direction by Cox and Ross [
1], Markus and Shaked [
2], and Merton [
3], showing the theoretical and practical importance of the process in that environment. For example, this process is associated with the Black and Scholes model [
4] and appears in later extensions as terminal swap-rate models (Hunt and Kennedy [
5], Lamberton and Lapeyre [
6]).
In 1972, Tintner and Sengupta [
7] introduced a modification of the process by including a linear combination of time functions in the infinitesimal mean of the process. The motivation for this was the introduction of external influences on the interest variable (endogenous variable), influences that could contribute to a better explanation of the phenomenon under study. For this reason, these time functions are known as exogenous factors, whose time behavior is assumed to be known or partially known. By using these time functions we can model situations wherein the observed trend shows deviations from the theoretical shape of the trend during certain time intervals, and can therefore use them to help describe the evolution of the process. Furthermore, a suitable choice of the exogenous factors can contribute to the external control of the process for forecasting purposes. Note that the methodology derived from the inclusion of exogenous factors has been applied to several contexts other than the lognormal process (see, for example, Buonocore et al. [
8]).
The lognormal diffusion process with exogenous factors has been widely studied in relation to some aspects of inference and first-passage times. It has been applied to the modeling of time variables in several fields (see, for example [
9,
10]). On occasion, the endogenous variable itself helps identify the exogenous factors. However, there are situations in which external variables to the process that have an influence on the system are not available, or situations in which their functional expressions are unknown. In such cases, Gutiérrez et al. [
11] suggested approaching the exogenous factors by means of polynomial functions.
The ability to control the endogenous variable using exogenous factors makes this process particularly useful for forecasting purposes. Some of its main features, such as the mean, mode and quantile functions (that can be expressed as parametric functions of the parameters of the process), can be used for prediction purposes. Therefore, the inference of these functions has been the subject of considerable study, both from the perspective of point estimation and of estimation by confidence intervals. With respect to the former, in [
10] a more general study was carried out to obtain maximum likelihood (ML) estimators. In that case, the exact distribution of the estimators was found, and then used to obtain the uniformly minimum variance unbiased (UMVU) estimators. In addition, expressions for the relative efficiency of ML estimators, with respect to UMVU estimators, were obtained. This last study was extended for a class of parametric functions which include the mean and mode functions (together with their conditional versions) as special cases. Concerning estimation by confidence bands, in this paper the authors extended the results obtained by Land [
12] on exact confidence intervals for the mean of a lognormal distribution, thus obtaining confidence bands for the mean and mode functions of the lognormal process with exogenous factors and expressing these functions in a more general form.
In most of the works cited, inference has been approached from the ML point of view, considering discrete sampling of the trajectories. To this end, it is essential to have the exact form of the transition density functions from which the likelihood function associated with the sample is constructed. However, alternatives are available for a range of situations. For example, approximating the transition density function using Euler-type schemes derived from the discretization of the stochastic differential equation that models the behavior of the phenomenon under study (sometimes this approach is known as naive ML approach). Other possible alternatives to ML are those derived, for example, from the use of the concept of estimating functions (Bibby et al. [
13]) and the generalized method of moments (Hansen [
14]). Fuchs in [
15] presents a good review of these and other procedures. The Bayesian approach is also present in the study of diffusion processes, as suggested by Tang and Heron in [
16].
On the other hand, considering particular choices of the time functions that define the exogenous factors has enabled researchers to define diffusion processes associated to alternative expressions of already-known growth curves. Along these lines, we may cite a Gompertz-type process [
17] (applied to the study of rabbit growth), a generalized Von Bertalanffy diffusion process [
18] (with an application to the growth of fish species), a logistic-type process [
19] (applied to the growth of a microorganism culture), and a Richards-type diffusion process [
20]. In [
21], a joint analysis of the procedure for obtaining these processes is shown. More recently, Da Luz-Sant’Ana et al. [
22] have established, following a similar methodology, a Hubbert diffusion process for studying oil production, while Barrera et al. [
23] introduced a process linked to the hyperbolastic type-I curve and applied it in the context of the quantitative polymerase chain reaction (qPCR) technique.
In these last cases, obtaining the ML estimators was a rather laborious task. In fact, the resulting system of equations is exceedingly complex and does not have an explicit solution, and numerical procedures must be employed instead, with the subsequent problem of finding initial solutions (see, for instance [
18,
19,
22]). However, it is impossible to carry out a general study of the system of equations in order to check the conditions of convergence of the chosen numerical method, since it is dependent on sample data. One alternative is then to use stochastic optimization procedures like simulated annealing, variable neighborhood search, and the firefly algorithm [
20,
23,
24]. In any case, the exact distribution of the estimators cannot be obtained. Recently, the asymptotic distribution of the MLestimators and delta method have been used in order to obtain estimation errors, as well as confidence intervals, for the parameters and parametric functions in the context of the Hubbert diffusion model [
25].
The main objective of this paper is to provide a unified view of the estimation problem by means of discrete sampling of trajectories, and to cover all the diffusion processes mentioned above. To this end, we will consider the generic expression of the lognormal diffusion process with exogenous factors. In
Section 2, a brief summary of the main characteristics of the process is presented.
Section 3 and
Section 4 address the problem of estimation by ML by using discrete sampling. In
Section 3, the distribution of the sample is obtained, while in
Section 4 the generic form adopted by the system of likelihood equations is derived in terms of the exogenous factor included in the model.
Section 5 deals with obtaining the asymptotic distribution of the estimators, after calculating the Fisher information matrix, for which the results of
Section 3 are fundamental. Finally, and as an application of the previous developments,
Section 6 deals with the particular case of the Gompertz-type process introduced in [
17].
2. The Lognormal Diffusion Process With Exogenous Factors
Let be a real interval (), an open set, and a continuous, bounded and differentiable function on I depending on .
The univariate lognormal diffusion process with exogenous factors is a diffusion process
, taking values on
, with infinitesimal moments
and with a lognormal or degenerate initial distribution. This process is the solution to the stochastic differential equation
where
is a standard Wiener process independent on
,
, being this solution
with
An explanation of the main features of the process can be found in [
21], where the authors carried out a detailed theoretical analysis. As regards the distribution of the process, if
is distributed according to a lognormal distribution
, or
is a degenerate variable (
), all the finite-dimensional distributions of the process are lognormal. Concretely,
and
, vector
has a
n-dimensional lognormal distribution
, where the components of vector
and matrix
are
and
respectively. The transition probability density function can be obtained from the distribution of
,
, being
that is,
follows a lognormal distribution
From the previous distributions, one can obtain the characteristics most commonly employed for practical fitting and forecasting purposes. These characteristics can be expressed jointly as
with
and where
.
Table 1 includes some of these characteristics (the
th moment, and the mode and quantile functions as well as their conditional versions) according to the values of
,
and
y.
3. Joint Distribution of Sample-Paths of the Process
Let us consider a discrete sampling of the process, based on d sample paths, at times , with = , . Denote by the vector containing the random variables of the sample, where includes the variables of the i-th sample-path, that is , .
From Equation (
2), and if the distribution of
is assumed lognormal
, the probability density function of
is
where
and
Now, we consider vector
, built from
by means of the following change of variables:
Taking into account this change of variables, the density of
becomes
with
,
. Here,
represents the
d-dimensional vector whose components are all equal to one, while
is a vector of dimension
n with components
,
.
From Equation (
5) it is deduced that:
and are independents,
the distribution of is lognormal ,
is distributed as an n-variate normal distribution ,
being and the identity matrices of order d and n, respectively.
4. Maximum Likelihood Estimation of the Parameters of the Process
Consider a discrete sample of the process in the sense described in the previous section, including the transformation of it given by Equation (
4). Denote by
and suppose that
and
are functionally independent. Then, for a fixed value
of the sample, the log-likelihood function is
where
Taking into account Equation (
6), and since
and
are functionally independent, the ML estimation of
is obtained from the system of equations (Given a function
,
. Notation
indicates that the result is a row vector).
resulting in
On the other hand, by denoting
we have
Thus, the ML estimation of
is obtained as the solution of the following system of
equations:
In the case where
is a linear function in
, it is possible to determine an explicit solution for this system of equations (see [
10,
26]). In other cases, the existence of a closed-form solution can not be guaranteed, and it is therefore necessary to use numerical procedures for its resolution. The fact that these methods require initial solutions has motivated the construction of
ad hoc procedures which depend on the process derived according to the function
considered (see [
18,
19,
22]). However, it is impossible to carry out a general study of the system of equations in order to check the conditions of convergence of the chosen numerical method, since the system is dependent on sample data and this may lead to unforeseeable behavior. One alternative would be using stochastic optimization procedures like simulated annealing, variable neighborhood search and the firefly algorithm. These algorithms are often more appropriate than classical numerical methods since they impose fewer restrictions on the space of solutions and on the analytical properties of the function to be optimized. Some examples of the application of these procedures in the context of diffusion processes can be seen in [
19,
21,
23,
25].
5. Distribution of the ML Estimators of the Parameters and Related Parametric Functions
In this section we will discuss some aspects related to the distribution of the estimators of the parameters of the model, and their repercussions in the corresponding distributions of parametric functions, which can be of interest for several applications.
With regard to the distribution of the estimators of
, it is immediate to verify that
If
is linear, it is then possible to calculate exact distributions associated with the estimators of
, which allows us to establish confidence regions for the parameters as well as UMVU estimators and confidence intervals for linear combinations of
and
(see [
10,
26]). However, in the non-linear case, the fact that an explicit expression for the estimators of
is not always readily available precludes obtaining, in general, exact distributions for them. In that case, asymptotic distributions can be used instead. In fact, on the basis of the properties of the ML estimators, it is known that
is asymptotically distributed as a normal distribution with mean
and covariance matrix
, where
is the Fisher’s information matrix associated with the full sample (in this case, ignoring the data of the initial distribution).
First we calculate the associated Hessian matrix: (we have adopted the usual expression for the Hessian matrix of
using vectorial notation, that is
).
where
and
Taking into account the distribution of the sample (see
Section 3), we have
so, the Fisher’s information matrix is given by
from where it is concluded that
. In addition, and by applying the delta method, for a
parametric function
(
) it is verified that
where
represents the vector of partial derivatives of
with respect to
.
The elements in the diagonal of matrix
provide asymptotic variances for the estimations of the parameters, while the delta method provides the asymptotic covariance matrix for
(and consequently the elements of the diagonal are the asymptotic variances for the estimation of each parametric function of
). For example, if we consider
, that is the general expression for the main characteristics of the process given by Equation (
3), then
6. Application: The Gompertz-Type Diffusion Process
In this section we focus on the Gompertz-type diffusion process introduced in [
17] with the aim of obtaining a continuous stochastic model associated with the Gompertz curve whose limit value depends on the initial value. Concretely
To this end, the non-homogeneous lognormal diffusion process with infinitesimal moments
was considered.
In order to apply the general scheme developed in the preceding sections, we consider the following reparameterization
, which leads to expressing the Gompertz curve as
whereas the infinitesimal moments (
10) are written in the form of Equation (
1), with
.
Denoting
and
, one has
and
so, from Equation (
8), and by taking into account of Equation (
7), the following system of equations appears
where
After some algebra, one obtains
On the other hand, and since
The solution of this equation provides the estimation of , whereas those of the other parameters are given by and .
As regards the asymptotic distribution of
, it is a trivariate normal distribution with mean
and covariance matrix given by
, being
with
This distribution can be used to obtain the asymptotic standard errors for the estimation of the parameters as well as for some parametric functions of interest (see the last comment of the previous section). In particular, we focus on the inflection time and the corresponding expected value of the process at this instant, conditioned on . Another important parametric function in this context is the upper bound that determines the carrying capacity of the system modeled by the process. Concretely:
Upper bound, conditioned on , .
Inflection time, .
Value of the process at the time of inflection, conditioned on , .
On the other hand, when using the model for predictive purposes some of the parametric functions of
Table 1 can be used. In particular, the conditioned mean function adopts the expression
Note that this curve is of the type of Equation (
11). For this reason, this function is useful for forecasting purposes. In this case, it is of interest to provide not only the value of the function at each time instant, but also the standard error of the prediction and a confidence interval determining a range of values that includes, with a given confidence level, the true real value of the forecast.
Application to Real Data
The following example is based on a study developed in [
27] on some aspects related to the growth of a population of rabbits.
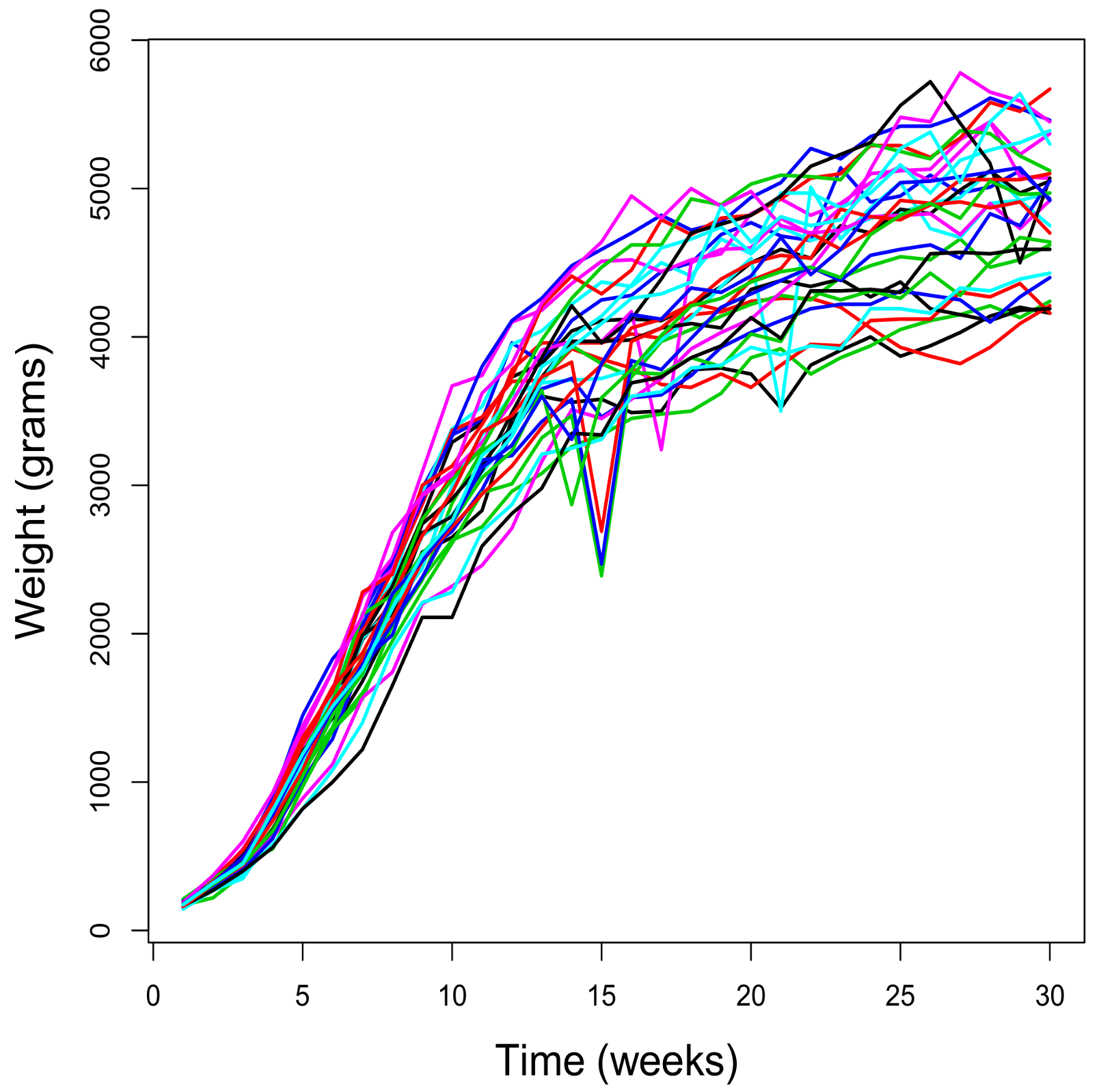
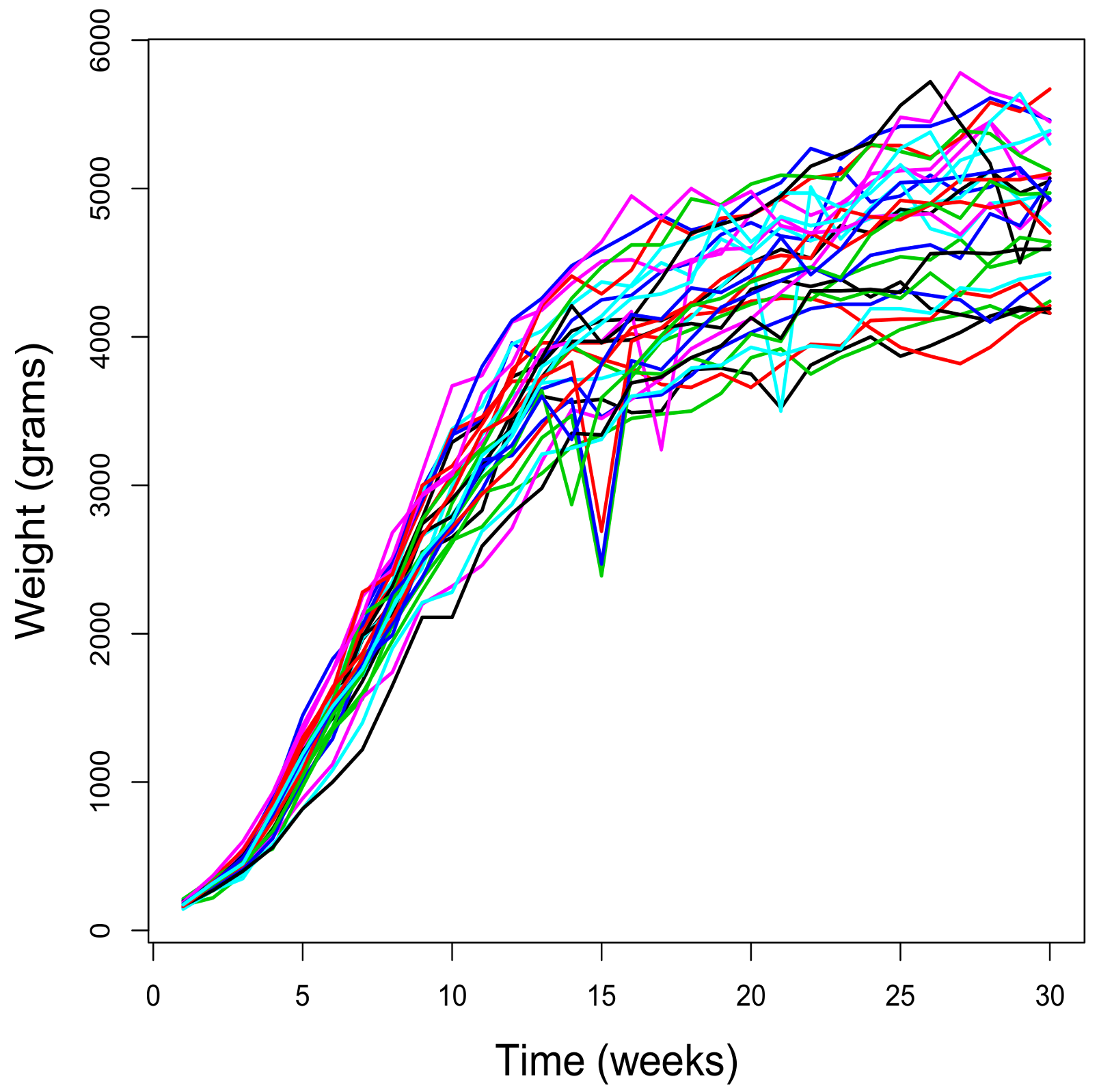
Figure 1 shows the weight (in grams) of 29 rabbits over 30 weeks. The sample paths begin at different initial values, thus showing a sigmoidal behavior, and their bounds are dependent on the initial values. These two aspects suggest that using the Gompertz-type model proposed above would be appropriate.
This data set has been used in various papers to illustrate some aspects of the Gompertz-type process, such as the estimation of the parameters and the study of some time variables that may be of interest in the analysis of growth phenomena of this nature. As regards the estimation of the parameters, in [
17] the authors designed an iterative method for solving the likelihood system of equations, while in [
24] the maximization of the likelihood function was directly addressed by simulated annealing. In addition, in [
28] two time variables of interest for this type of data were analyzed: concretely the inflection time and the time instant in which the process reaches a certain percentage of total growth. Both cases were modeled as first-passage time problems.
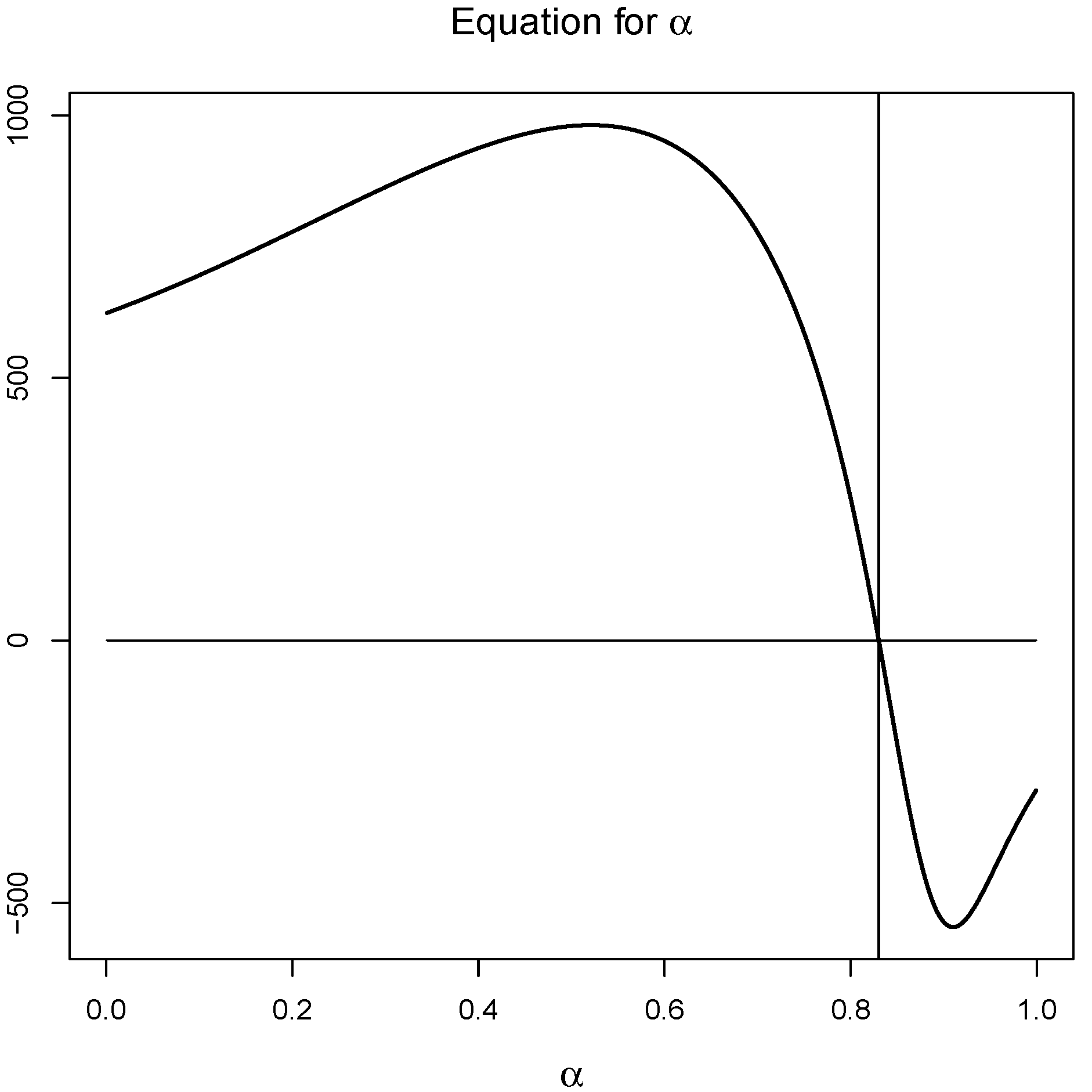
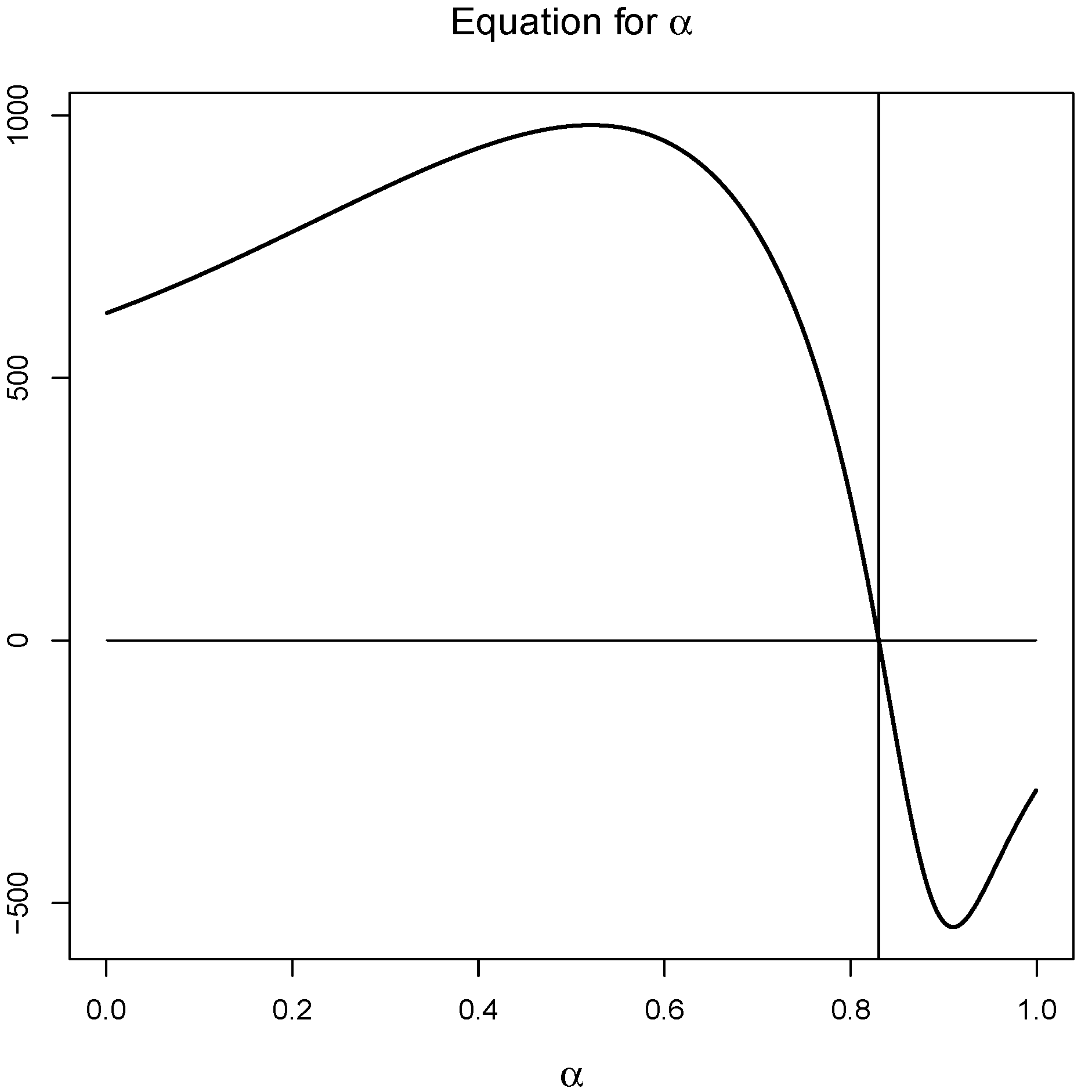
In this paper the estimation of the parameters has been carried out from the resolution of Equation (
12) by means of the bisection method (see
Figure 2) and then by using expressions
and
.
Table 2 contains the estimated values for the parameters and the inflection time, as well as the asymptotic estimation error and 95% confidence intervals by applying the delta method.
As regards the weight value at the inflection time and the upper bound, remember that these values depend on the one observed at the initial instant. Taking into account the range of observed weight values at the initial instant of observation, several values have been considered within this range. For these values, the expected weight of a rabbit at the moment of inflection has been studied, as well as the possible value of the maximum weight (upper bound).
Table 3 contains the estimated values, the asymptotic standard errors, and the 95% confidence intervals.
Function
can be used to provide forecasts of the weight of a rabbit that presents an initial weight
.
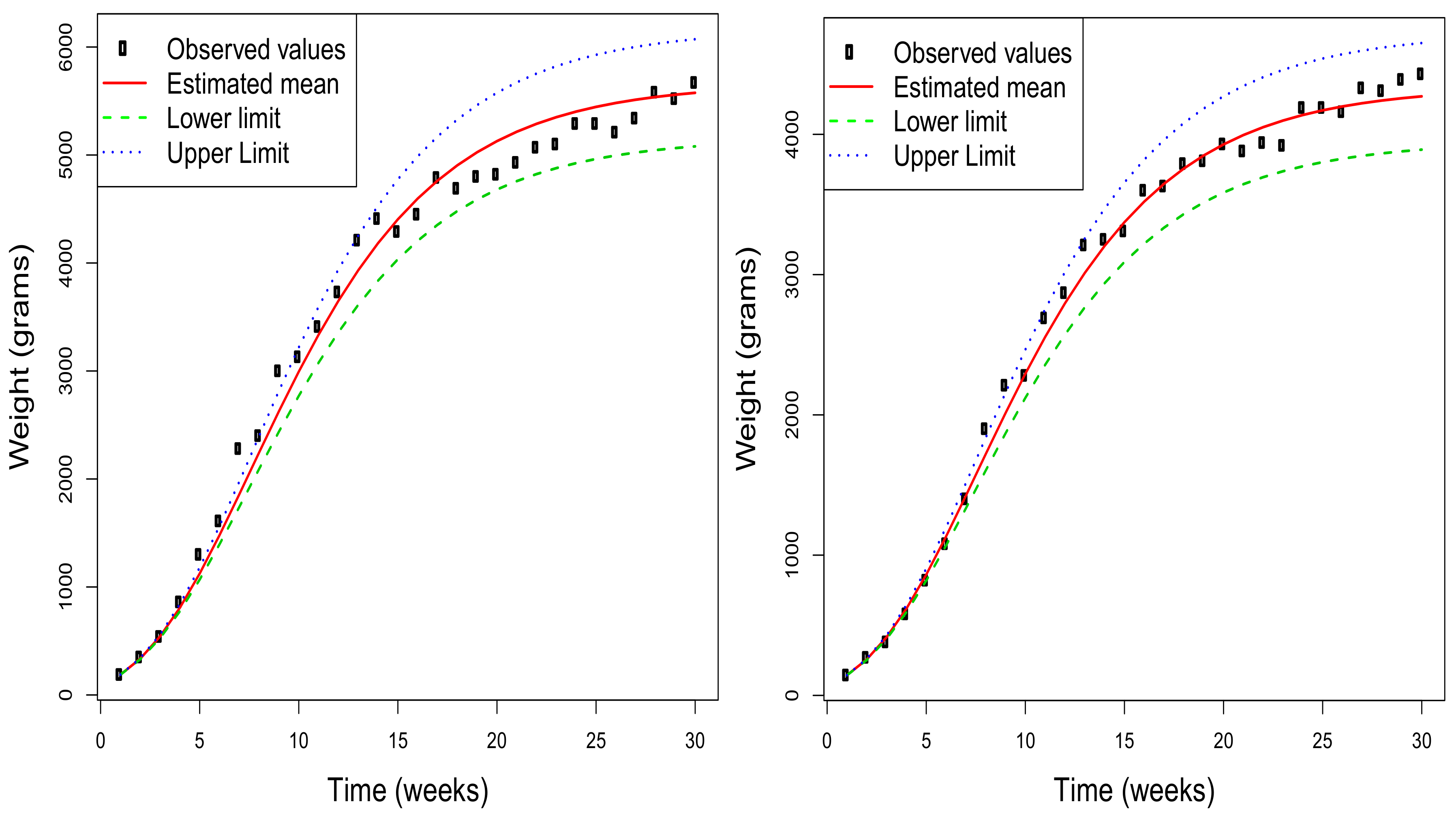
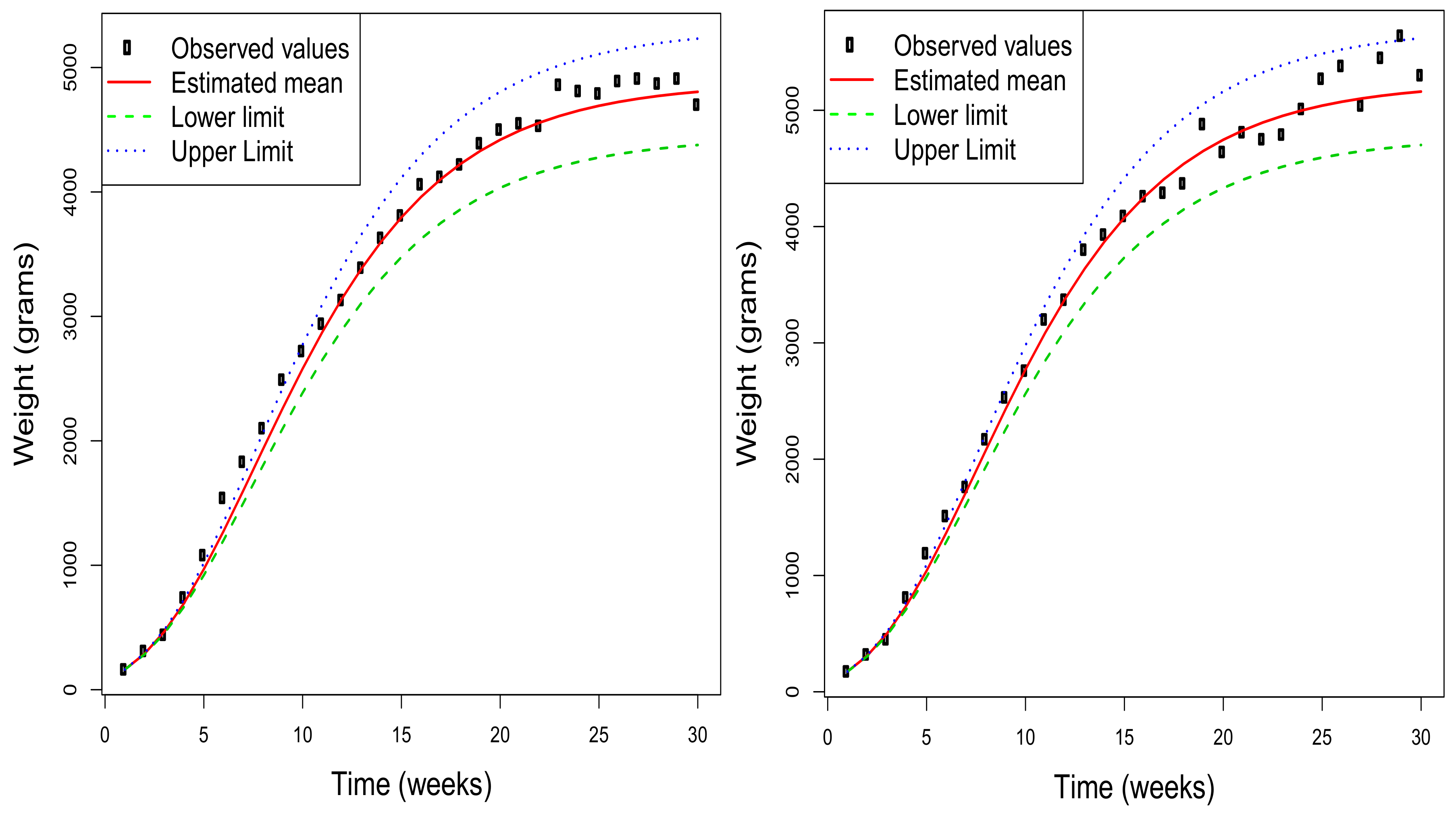
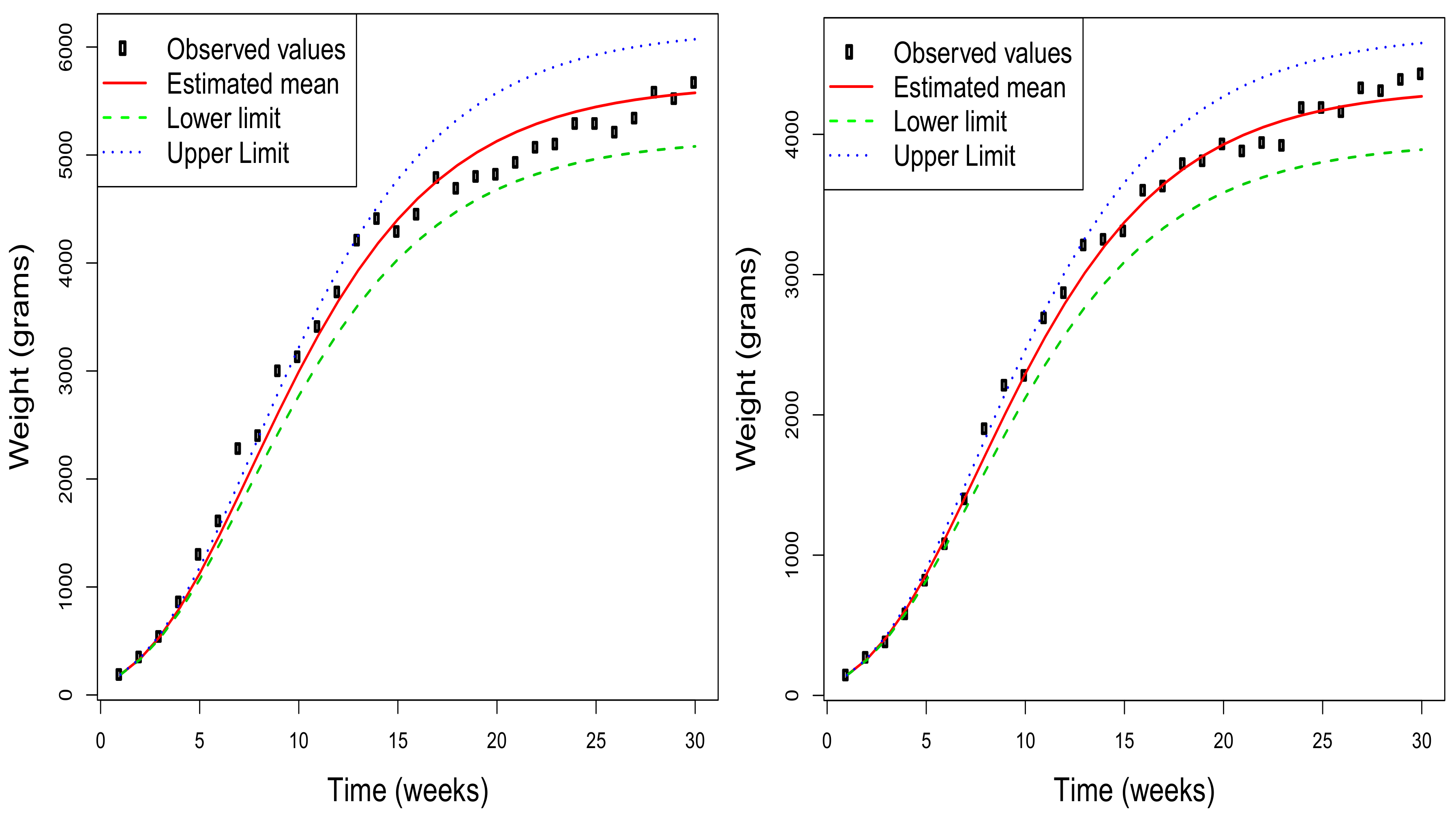
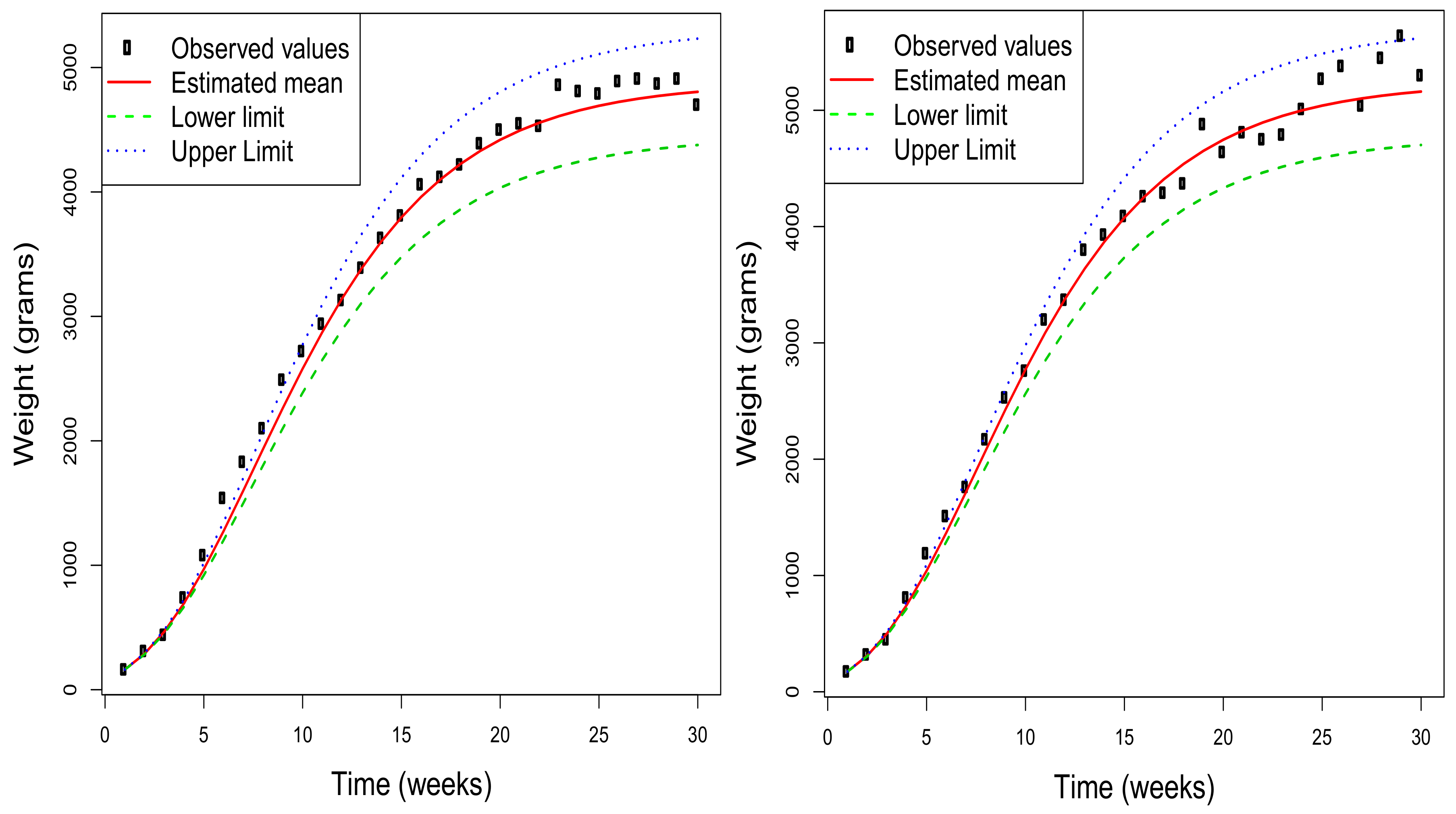
Figure 3 shows, for a selection of four of the rabbits used in the study, the estimated mean function together with the 95% asymptotic confidence intervals obtained for each value of this function. Additionally, the observed values are included to check the quality of the adjustment made by the model under consideration. Obviously, this type of representation can also be obtained by considering any value of
in the range of the initial distribution of the weight. Note that the estimated mean functions for each rabbit depend on the initial value, and so do the corresponding confidence intervals for the mean at each time instant. Therefore, the graphs in the figure are different for each rabbit although the estimation of the parameters is unique.



{kind=link}
{kind=link}
{kind=link}
{kind=link}