1. Introduction
The discipline of community ecology investigates variability in the composition of ecological communities and the possible environmental factors that might determine or constrain that composition. Because ecological communities generally contain multiple species, the comparison of composition is inherently multivariate. The general approach to the analysis of this variability involves the calculation of a symmetric matrix of similarities, dissimilarities, or distances between all possible pairs of community sample units, followed by the subsequent analysis of the properties of that matrix. This analysis typically takes one of two forms: partitioning the sample units into sets of similar samples through some form of cluster analysis, or projecting the matrix to lower dimensionality and analyzing the variability as a field, which ecologists refer to as “ordination.” Textbook treatments of these methods are given by Legendre and Legendre [
1] and Kent [
2].
Formal statistical analysis of ecological communities goes back to at least 1954, when David Goodall introduced the use of principal component analysis (PCA) to ecology [
3]. Over the subsequent decades, numerous statistical methods have been adopted or invented to further the aims of community ecology. In particular, various forms of cluster analysis have been employed in ecological analysis. Recent examples include analyses of plants [
4,
5,
6], fish [
7], birds [
8,
9], and mammals [
10]. Examples of comparative analyses of clustering algorithms applied to ecological community data are given by Roberts [
11] and Aho et al. [
12]. Generally, if not without exception, ecological cluster analyses have produced partitions of the sample units, i.e., a family of sets where (1) every set has at least one member, (2) every element belongs to exactly one set, and (3) the union of sets comprises the universe of elements. While there are practical reasons to desire a partition as the outcome of the analysis (e.g., to produce a set of community types for inventory or mapping purposes), the use of partitions presents challenges in statistical analysis of the underlying environmental constraints or determinants of the community type composition.
Given a sample with
N sample units, the number of possible partitions of the data into clusters is given by Bell’s number
where
K is a given number of clusters (
),
N is the number of sample units, and
is the Stirling number of the second kind.
While the population of possible partitions is generally large, sampling at random from that population is difficult due to the peculiarities of the cluster analysis result to be compared to. Even constraining the sample population to the same value of K, it may or may not be desirable to constrain the individual clusters to the distribution of cluster sizes obtained in the original cluster analysis, which is in part an artifact of the particular cluster analysis performed and not necessarily a good result.
Alternatively, it is possible to calculate a covering, as opposed to a partition of the data, i.e., a family of sets such that (1) all sets have at least one member, (2) all elements belong to at least one set, and (3) the union of all sets comprises the universe of sample units. By relaxing the partition constraint that every element belongs to exactly one set, but imposing the constraint that all sets are the same size, we can derive a covering, as opposed to a partition. In this case, the number of possible sets of size
in the covering for
K clusters is
where
is the number of elements of set
. This is a much more favorable population to sample from. We simply sample
sample units without replacement from the set of
N sample units a large number of times and compare the random samples to the the observed sets in the covering.
The specific objectives of this paper are to demonstrate and test the utility of the proposed analysis on a specific ecological data set. The primary hypothesis underlying the test is that ecological community composition is constrained (as opposed to determined) by environmental factors acting upon the individual species that make up the community, and that such factors can be identified by a test designed to identify limiting conditions within sets of similar communities. The concept of maximally similar sets and the specific algorithms for construction and analysis of such sets by permutation employing non-parametric statistics are novel and have not previously been demonstrated in the scientific literature.
2. Materials and Methods
The proposed analysis is demonstrated on a sample of the forest vegetation of the Shoshone National Forest, Wyoming, USA. The vegetation composition varies primarily as a function of environmental variability, but the precise nature of this relationship is unknown. Maximally similar sets analysis as described above is employed to tease out this relationship.
2.1. Data
Sample units were 375 m
circular plots, where the abundance of every vascular plant species was estimated according to an ordinal ten-class scale. Environmental attributes associated with the sample units were either measured in the field or modeled in a geographic information system. Attributes include sample unit elevation, aspect, slope steepness, surficial geology, soil properties, topographic position, and climate attributes modeled from elevation, aspect, slope, surficial geology, topographic position, and geographic location. One hundred fifty sample units were selected at random from a larger study to provide a manageable example data set. Further details about the data are given in
Appendix A.
2.2. Analyses
The sample unit composition data were used to calculate a symmetric, reflexive similarity matrix using the Bray–Curtis index [
13].
where
is the similarity of sample unit
i to sample unit
j,
m is the number of species,
is the abundance of species
q in sample unit
i, and
.
where sample units with no species in common
and identical sample units
.
Maximally similar sets (MSSs) were solved for by setting the desired neighborhood size
and then, iteratively for each sample unit, adding the sample unit most similar to the members of the neighborhood until the desired neighborhood size was achieved. The most similar sample unit to the neighborhood was calculated as
where
is the similarity of sample unit
i to neighborhood
.
The set of resulting neighborhoods was reduced to the set of unique neighborhoods by deleting all neighborhoods that were a permutation of an existing neighborhood. The number of neighborhoods in the similarity relation (S) reflects the topology of the similarity relation and cannot be known a priori. As the size of neighborhoods increases, the number of neighborhoods generally declines.
The within-MSS variability of interval- or ratio-scaled sample unit attributes was determined by calculating the range of the attribute within each MSS. That set of
K ranges was then compared to the set of ranges of an equal number of sets of equal size drawn at random without replacement from the set of sample units. The ranges of the MSS were compared to the ranges of the randomly drawn sets in a Wilcoxon rank-sum test with continuity correction to generate the Wilcoxon statistic
W. The within-MSS variability for categorical variables was determined by calculating the entropy of the tabulated values of the variable for each of the
K MSSs and comparing it with the entropy of
K sets of the same size sampled at random without replacement from the set of sample units. The entropy for set
k was calculated as
where
is the number of sample units in category
c for categorical variable
C. As for the interval-valued attributes, the observed and random entropies were then tested with a Wilcoxon rank sum test with continuity correction to generate the Wilcoxon statistic
W. This process was repeated 1000 times for each attribute to generate 1000
W statistics for each attribute, and the effect size of each attribute was estimated by comparing the distribution of
W values in a boxplot.
3. Results
The analysis generated neighborhoods of sample units of size 5, 10, 15, and 20, where each neighborhood consisted of sample units with maximally similar composition. Distributions of Wilcoxon’s W were produced for each candidate explanatory variable for all neighborhoods of all sizes. The number of neighborhoods generated and the effect size analysis of the variables is presented below.
3.1. Similarity Relation and Maximally Similar Sets
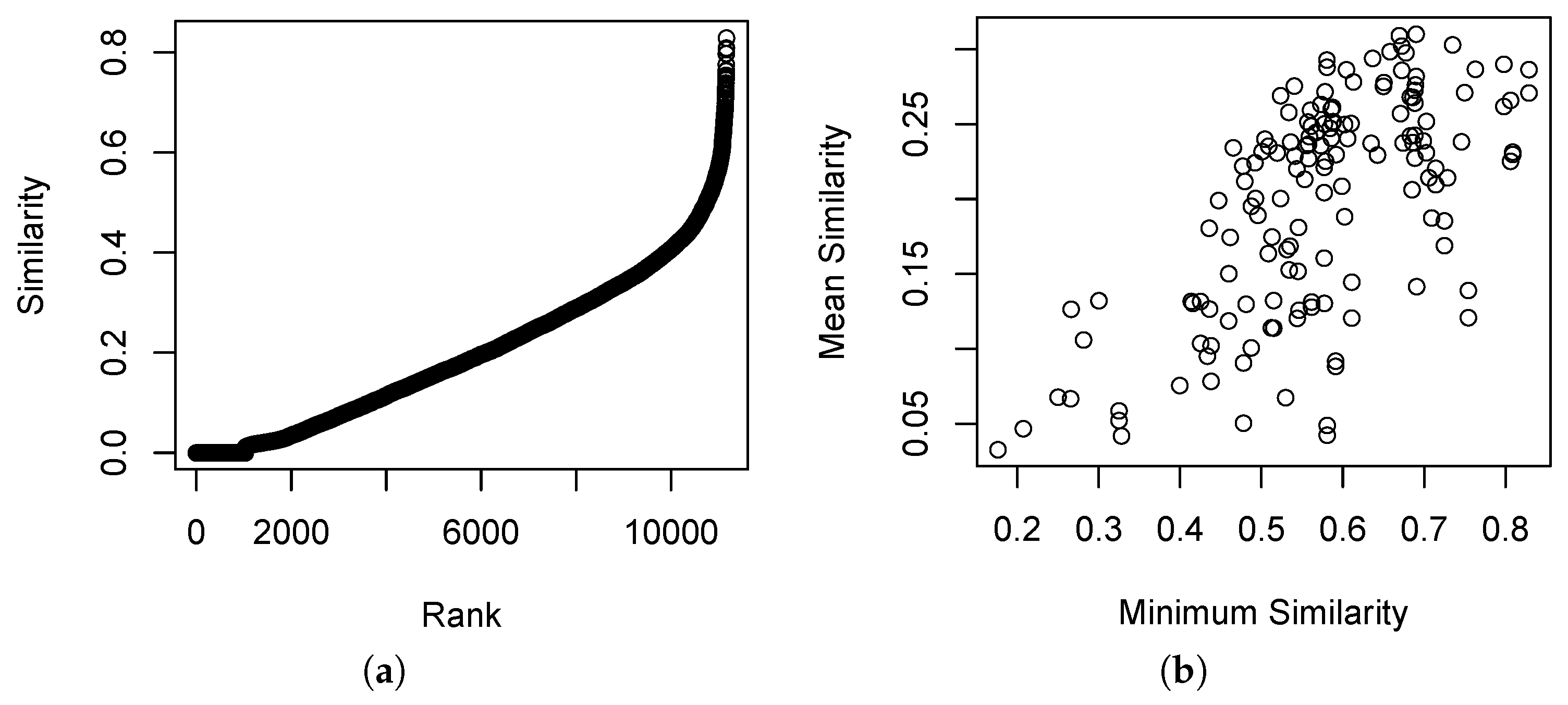
The distribution of similarities in the Bray–Curtis similarity relation is shown in
Figure 1.
Figure 1a shows relatively few cases of
, and relatively few cases of
.
Figure 1b shows that the mean similarity and minimum similarity are somewhat correlated, and that most sample units have at least one other sample unit with
. This is a typical result for vegetation data where the composition of the sample units is quite diverse but where sampling is adequate to span the range of variability.
MSSs were calculated for neighborhood sizes of 5, 10, 15, and 20 members.
Table 1 gives the sizes of the resulting families of neighborhoods.
Setting
resulted in 90 MSSs, and this result is used in subsequent analyses. Given
and
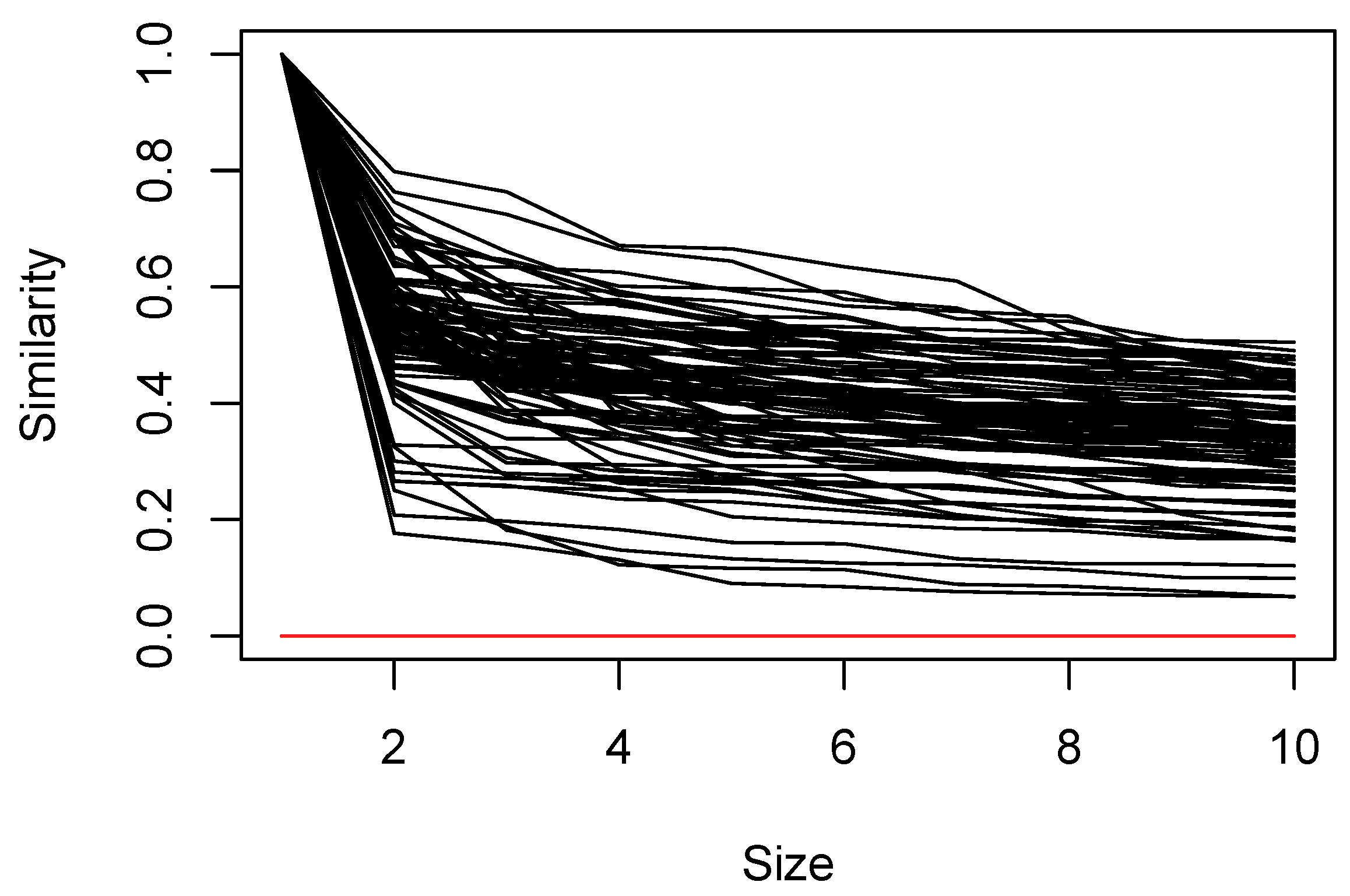
, on average, sample units belonged to six neighborhoods. In many cases, the similarity of the second element joining the set is low, but the monotonic decline in the similarity of subsequent elements is relatively gentle (
Figure 2); the lowest similarity of any member of a set ranges from 0.067 to 0.50 with a median of 0.35.
3.2. Analysis of Environmental Constraints
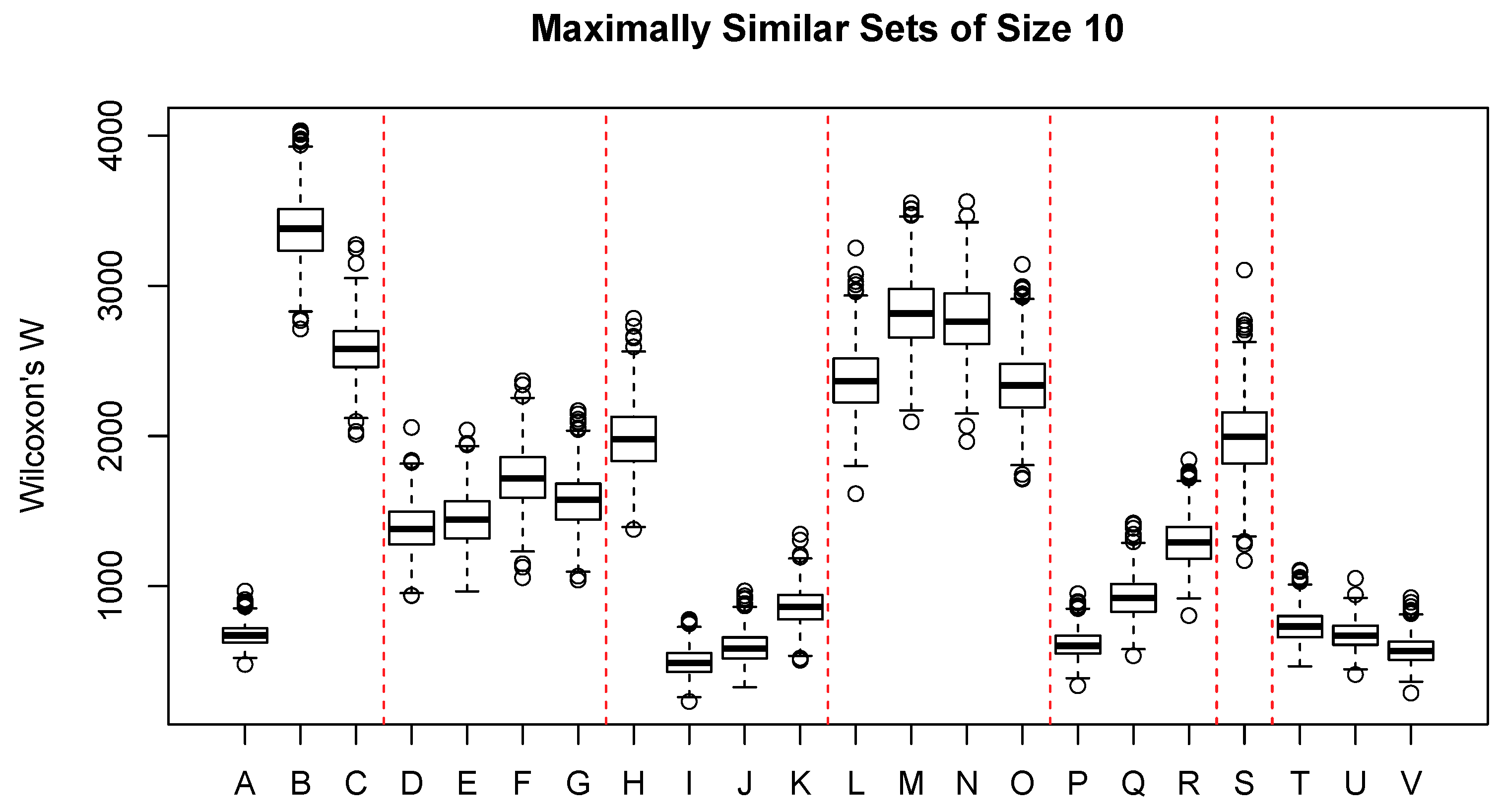
Figure 3 shows the distribution of Wilcoxon’s
W for a broad range of interval- or ratio-scaled environmental attributes, mostly related to topography and climate. Boxes A–C represent commonly observed plot-level observations: elevation (m), aspect value
, and slope steepness in percent. Elevation shows quite a strong constraint, where sample units with similar vegetation composition must occur within a relatively narrow band of elevation; aspect and slope show very little constraint. Boxes D–G are seasonal precipitation and show moderate constraint on similarity. Boxes H–K show seasonal temperature and, except for winter temperature (H), show quite a significant constraint; spring temperature has the strongest constraint of any attribute, and summer temperature ranks third in effect size. Boxes L–O show direct solar radiation (heat load) and exhibit little direct constraint. Boxes P–R show seasonal potential evapotranspiration (PET); spring PET ranks fourth in effect size, and summer and autumn PET rank ninth and tenth, respectively. Boxes T–V show annual climatic summaries: the mean annual temperature, the number of frost free days, and the growing degree days (sum of temperature > 5
C). All three variables show strong constraint; growing degree days ranks second in effect size, the number of frost free days ranks fifth, and the mean annual temperature ranks seventh.
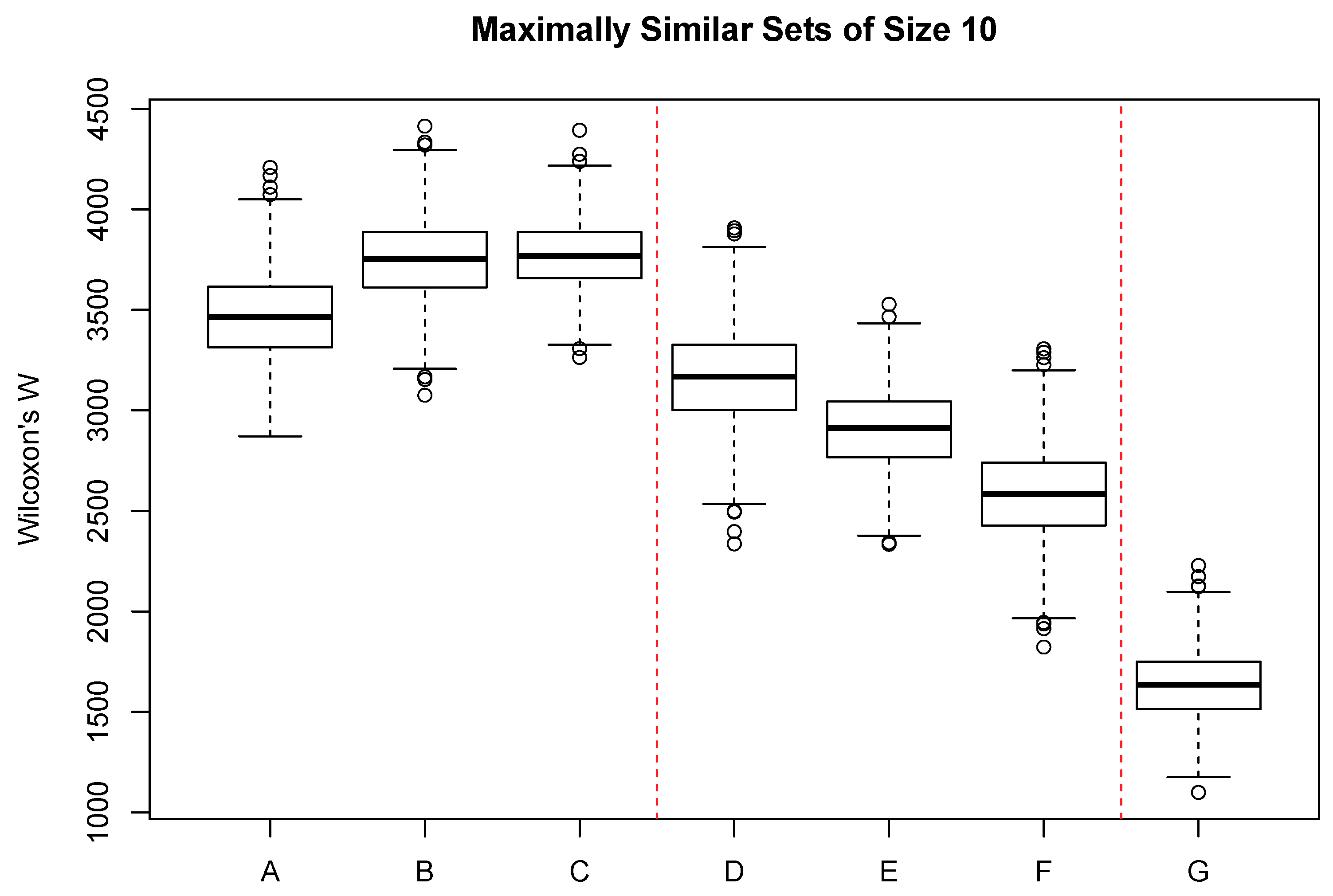
Figure 4 shows the the distribution of Wilcoxon’s
W for a range of categorical variables, mostly related to soil properties and geology. Boxes A–C show the constraints associated with typically observed soil properties. Of the three, soil depth (classified into four categories) shows the greatest constraint. Boxes D–F show the effect size of soil classifications commonly employed in the United States. Soil short family (D) was classified into 58 classes with many singletons and one class with 21 sample units. Soil subgroup was classified into 16 classes with a few singletons and one class with 50 sample units. Soil great group (F) showed the greatest constraint of the three and was classified into seven classes with two singletons and the maximum of 63 sample units/class.
Surficial geology was classified into 23 classes, with several singletons and a maximum or 30 sample units/class, and showed the greatest constraint of any of the categorical attributes. Sample units with similar vegetation are likely to occur on a narrow range of surficial geology types. In general, among the interval-scaled attributes, the greatest constraint was demonstrated by variables associated with sample unit temperatures, either directly or indirectly. Spring potential evapotranspiration also ranked in the top five but is also a function of temperature. Surprisingly, precipitation generally showed little effect, with seasonal precipitation ranking 11–14. Solar radiation showed very little effect, suggesting that the same level of radiation can occur in sites of quite different vegetation composition if the temperature of the units is different. Among the categorical variables only surficial geology showed a substantial constraint, exhibiting values similar to seasonal precipitation among the interval-scale variables.
4. Discussion
In general, the method worked well at identifying primary ecological constraints of community composition in the data examined. However, there are several methodological considerations to consider in applying the method to a given data set.
4.1. Constraint vs. Determinant
Throughout the results, I have repeatedly specified “constraint” as opposed to “determinant” in interpreting the results. The composition of ecological communities (forest vegetation in this case) is determined by a complex set of processes. While species have individual responses to specific environmental attributes, the form of integration of those individual responses into the overall species response is generally unknown. Often, environmental attributes can be partly compensatory, and the relationships are generally not linear or independent. Notably, a suitable habitat is necessary but not sufficient, so that species may be absent from a community for reasons unrelated to the environment at that location. Accordingly, the relationship between environment and community composition is a relation, as opposed to a function.
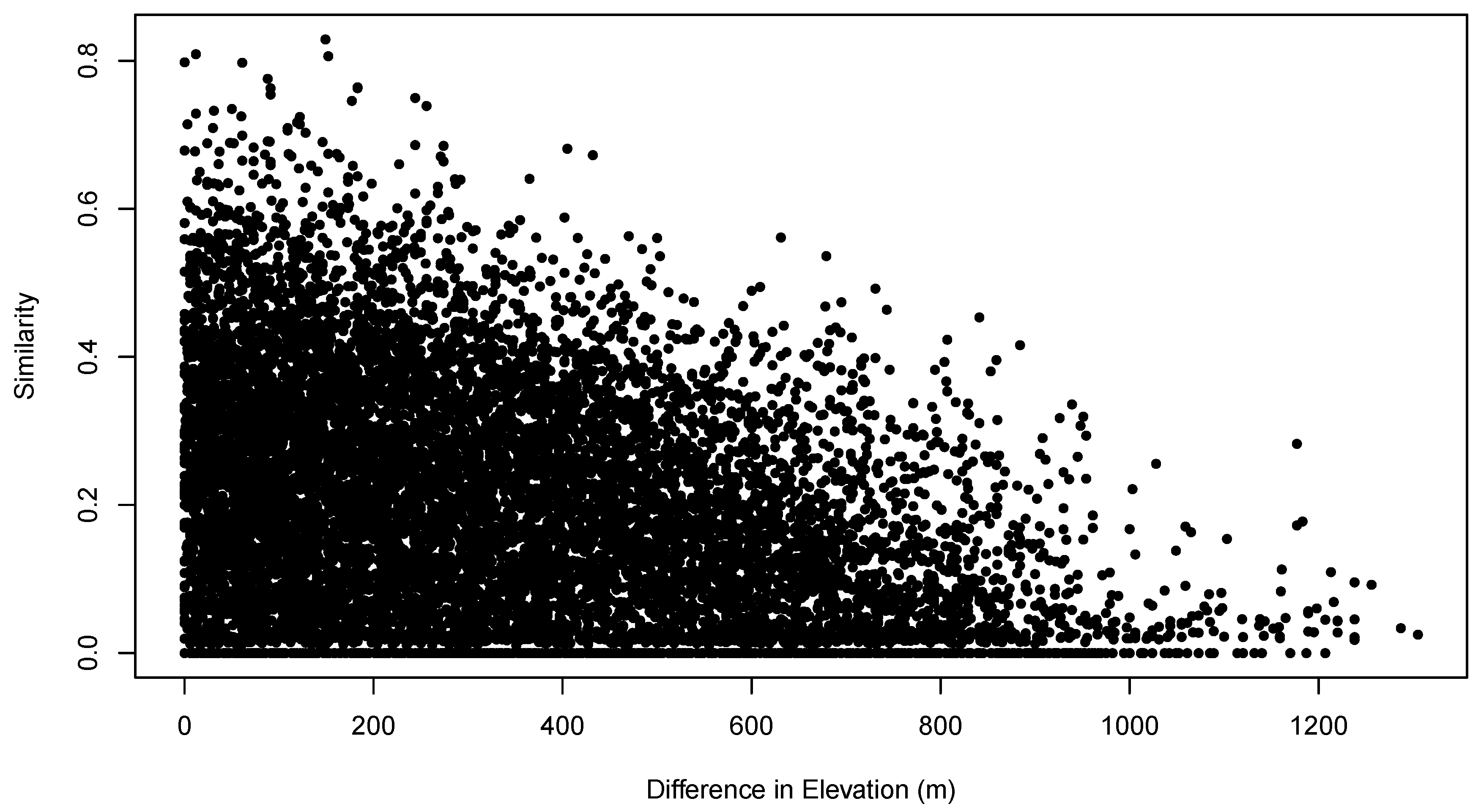
Figure 5 shows the relationship between the pair-wise compositional similarities and the pair-wise differences in sample unit elevation. The plot shows the classical triangular distribution characteristic of these relationships. As the difference in elevation between sample units increases, it becomes increasingly difficult to compensate for that difference, and maximum possible sample unit similarity declines. However, even at zero or small differences in elevation, compositional similarity can be zero or low. Given the triangular distribution of the similarity/environment relation, the MSS analysis proposed here looks for boundary conditions, i.e., “how different can values of an environmental attribute be while still allowing similar community composition?” While it may appear that such relations are suitable for analysis by logistic quantile regression [
14], it is important to note that the points on the figure are not independent of each other and that in fact every point is associated with
other points because they pertain to the same sample unit.
4.2. Neighborhood Size
The calculation of maximally similar sets was conducted at sizes of 5, 10, 15, and 20. Specific results were only shown for sets of size 10. Across the range of neighborhood sizes examined, the results were quite similar (Spearman rank correlations for the effect size of the candidate explanatory variables were in the range
). In a sense, this is quite reassuring and demonstrates low sensitivity of the analysis to this parameter. Nonetheless, neighborhood size does matter in the analysis. The algorithm looks for boundary conditions within the neighborhoods. The number of pair-wise differences in a neighborhood (and thus statistical power) scales as
. Accordingly, small neighborhoods may by chance not exhibit any sample unit pairs at the limit for a given environmental attribute, and thus larger neighborhoods are preferred. However, as neighborhood size increases, the number of neighborhoods generally declines, and the power of the test thus declines as well, although modestly. In the data analyzed here, the number of neighborhoods declined from 102 to 71, as neighborhood size increased from 5 to 20. In addition, as neighborhood size increases, the similarity to the neighborhood of late-joining sample units declines, so quite large pair-wise differences in environment may be obtained. At the extreme, if the neighborhoods are too large, sample plots will be added to neighborhoods that have no similarity to other members of the neighborhood and thus contribute no information. The optimal neighborhood size is thus a function of the size of the data set and the distribution of similarities in the similarity relation, and generally cannot be known
a priori.
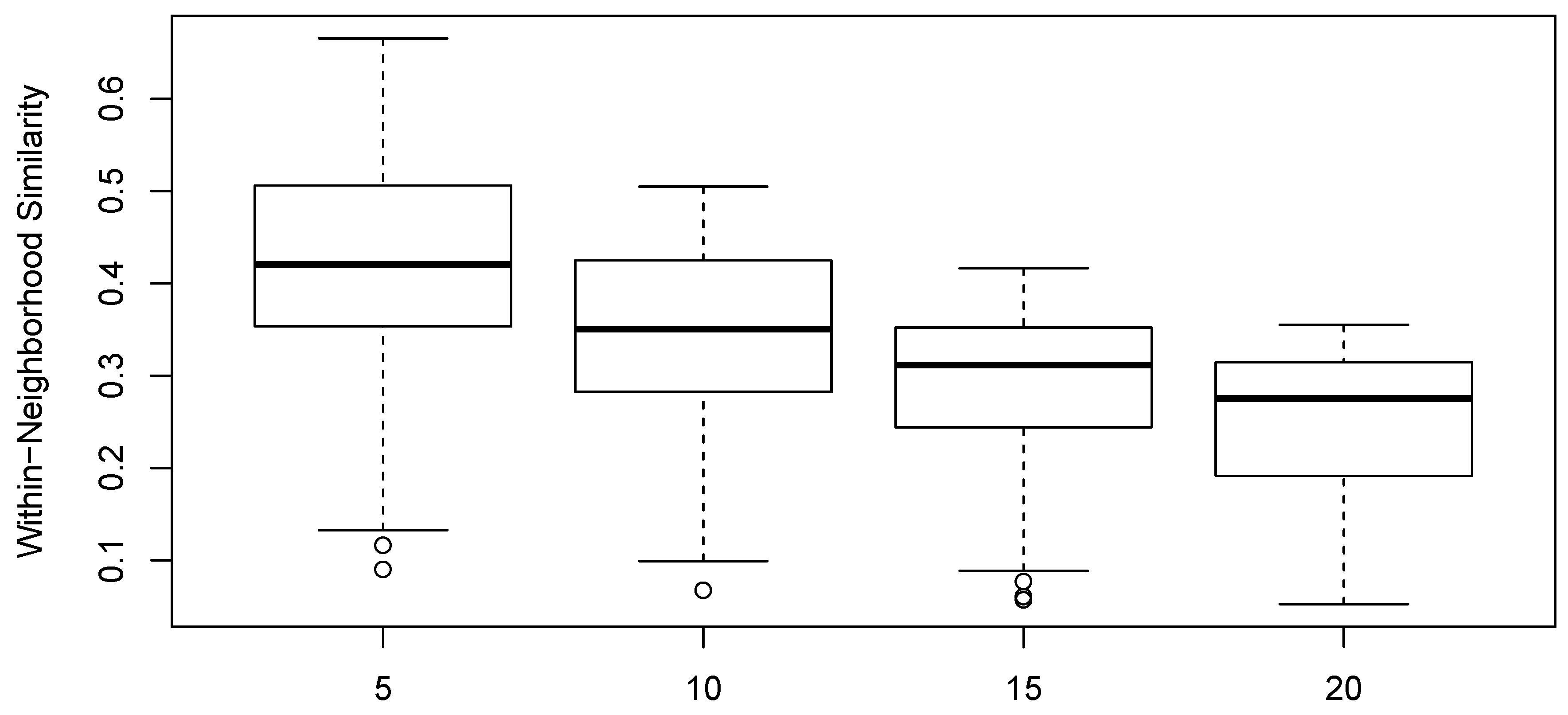
Figure 6 shows the distribution of element-to-neighborhood similarities as a function of neighborhood size for the data analyzed.
4.3. Interval-Scaled vs. Categorical Variables
Both interval-valued and categorical variables were analyzed using the Wilcoxon rank sum test, and thus present results on the same scale. However, depending on the number of classes within a categorical variable, it is common to be observed or random sets that have identical entropies and thus generate ties in the calculation of Wilcoxon’s W. As the number of ties goes up, the power of the test declines, and some categorical variables thus have low power. In addition, ideally the distribution of cases by class would be relatively balanced. In the data analyzed here, the distributions were wildly skewed, which again reduces power. Of the categorical variables analyzed, only surficial geology demonstrated a strong constraint. The extent to which the other variables suffered from low power, as opposed to a minimal ecological effect, is difficult to know, but the results obtained do make sense from an ecological perspective.
4.4. Ecological Interpretation
The point of any ecological analysis is to generate insight into the ecological processes and relationships at work. In this case, the signal was clear that the seasonal air temperature at the sample unit locations was the primary constraint on community similarity. Forest plant communities that are similar to each other must occur within a narrow range of temperatures. This makes sense in that plant ecophysiological behavior is a function of temperature. At low temperatures, plants photosynthesize less efficiently and thus gain less carbon for growth or maintenance. At high temperatures, plants suffer from excess sensible heat, and net photosynthesis again declines. Each plant species has an optimal temperature, and plants with similar optima are thus likely to co-occur in sample units with that temperature. Interestingly, the highest ranked variable was specifically the spring temperature (April, May, and June), which may indicate critical timing of the beginning of growth after dormancy in the winter. Summer temperature ranks third in effect size, so temperature throughout the growing season seems quite important. The second strongest constraint is growing degree days, which is the sum of temperatures above 5 C, and again strongly determined by temperature.
Interestingly, solar radiation showed little effect. Solar radiation contributes heat to the sites of the sample units that can be partitioned into latent heat of vaporization (evapotranspiration of water) or sensible heat. Apparently, sites receiving similar radiation budgets but differing in available water differ in the partitioning of heat into latent heat and sensible heat and can thus compensate for differences in radiation.
Surprisingly, precipitation showed relatively little effect, with winter (January, February, and March) precipitation (which comes primarily as snow) showing the largest effect, ranked only at 11th. Water is a necessary resource for plant metabolism and plays a large role in the partitioning of heat into latent heat. However, precipitation does not translate directly into plant-available water and interacts with temperature-controlled evapotranspiration. It is possible to model potential evapotranspiration (the amount of water the atmosphere could evaporate if water was not limiting). In the data analyzed here, the potential evapotranspiration of summer (July, August, and September) and autumn (October, November, and December) ranked eighth and ninth, respectively.
Variability in soils plays a critical role in plant species distribution and community composition, but is notoriously difficult to code as an explanatory variable in statistical analyses. Of the soils variables considered here, surficial geology played the largest role. Surficial geology determines what soil scientists call the soil “parent material” and affects soil water-holding capacity and fertility. Soil parent materials are complex multi-faceted variables that have to be treated as categorical variables in an analysis like this one, which ignores the similarities or differences among types. Nonetheless, soil parent material makes sense as a community composition constraint, as many species are known to have preferences for specific types.
5. Conclusions
Analysis of maximally similar sets operates on a similarity matrix to define neighborhoods in the high-dimensional similarity space defined by the matrix. After forming the neighborhoods, the analysis evaluates within-neighborhood variability in candidate explanatory variables to obtain an estimate of variable effect size. The probability of obtaining results with variability as low as observed is calculated by sampling a large number of sets the same size as the neighborhood and calculating a Wilcoxon siged-rank test of the results. The analysis of maximally similar sets proved to be an effective analysis of variables that exhibit a relational, as opposed to functional, response. The analysis effectively ranked a set of candidate explanatory variables to provide an interpretable ecological analysis. The algorithm is reasonably quick on data sets of this size (the neighorhood analysis with a neighborhood size set at 10 required 0.03 s to run) but would take longer on significantly larger data sets. The analysis provides a more suitable statistical population for sampling than do partition-based cluster analyses, and avoids the artifact characteristic of hierarchical cluster analyses.
The analysis on the example data set of forest vegetation identified sample unit temperature (in multiple forms) as the primary constraint on neighborhood composition, followed by potential evapotranspiration. While the analysis presented here concerned forest vegetation, the analysis is suitable for any multivariate data set, where the relationship among sample units can be described with a similarity matrix, such as that employed in ecology, psychology, and machine learning fields.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





