Aggregating a Plankton Food Web: Mathematical versus Biological Approaches



Abstract
1. Introduction
2. Materials and Methods
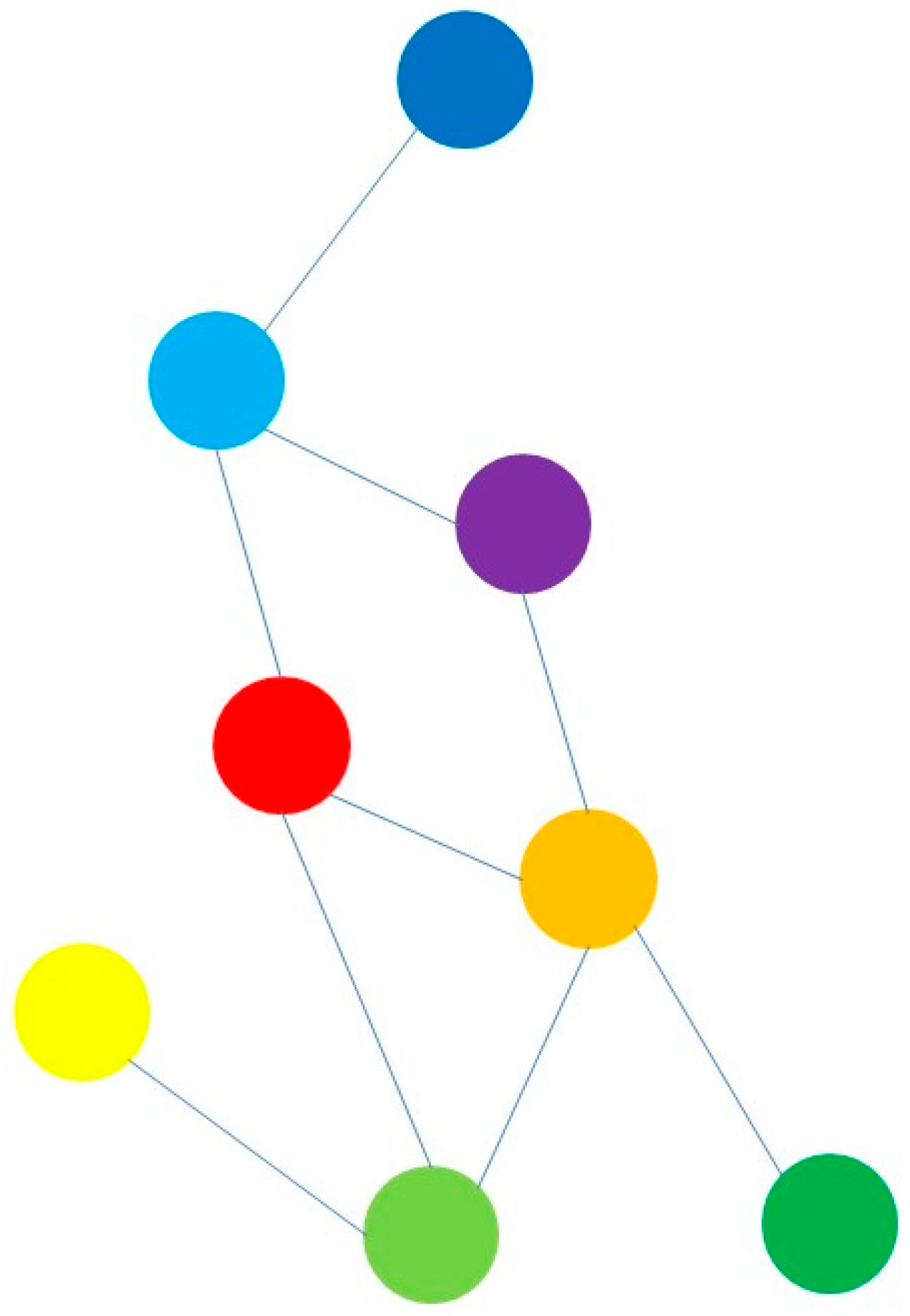
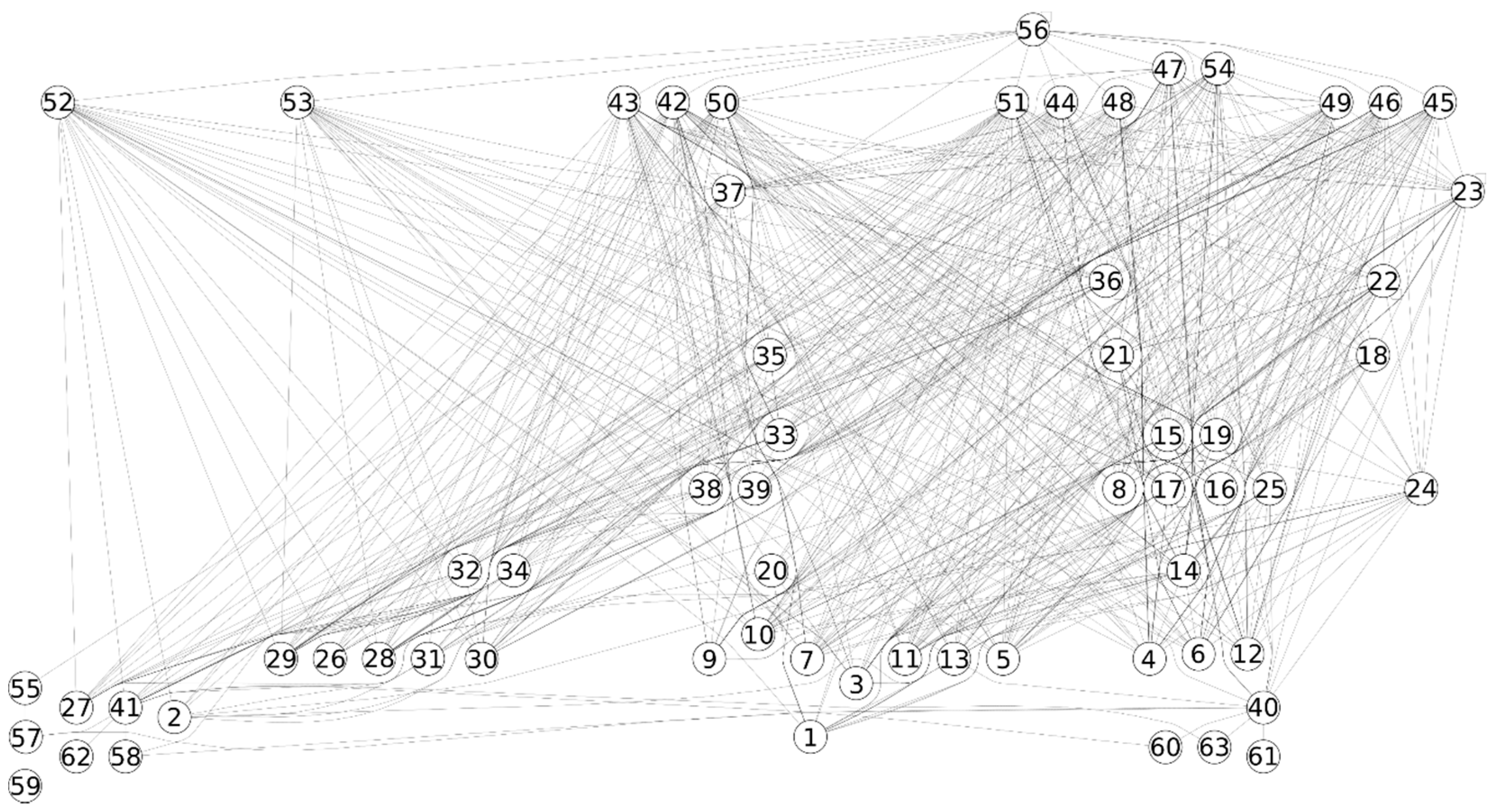
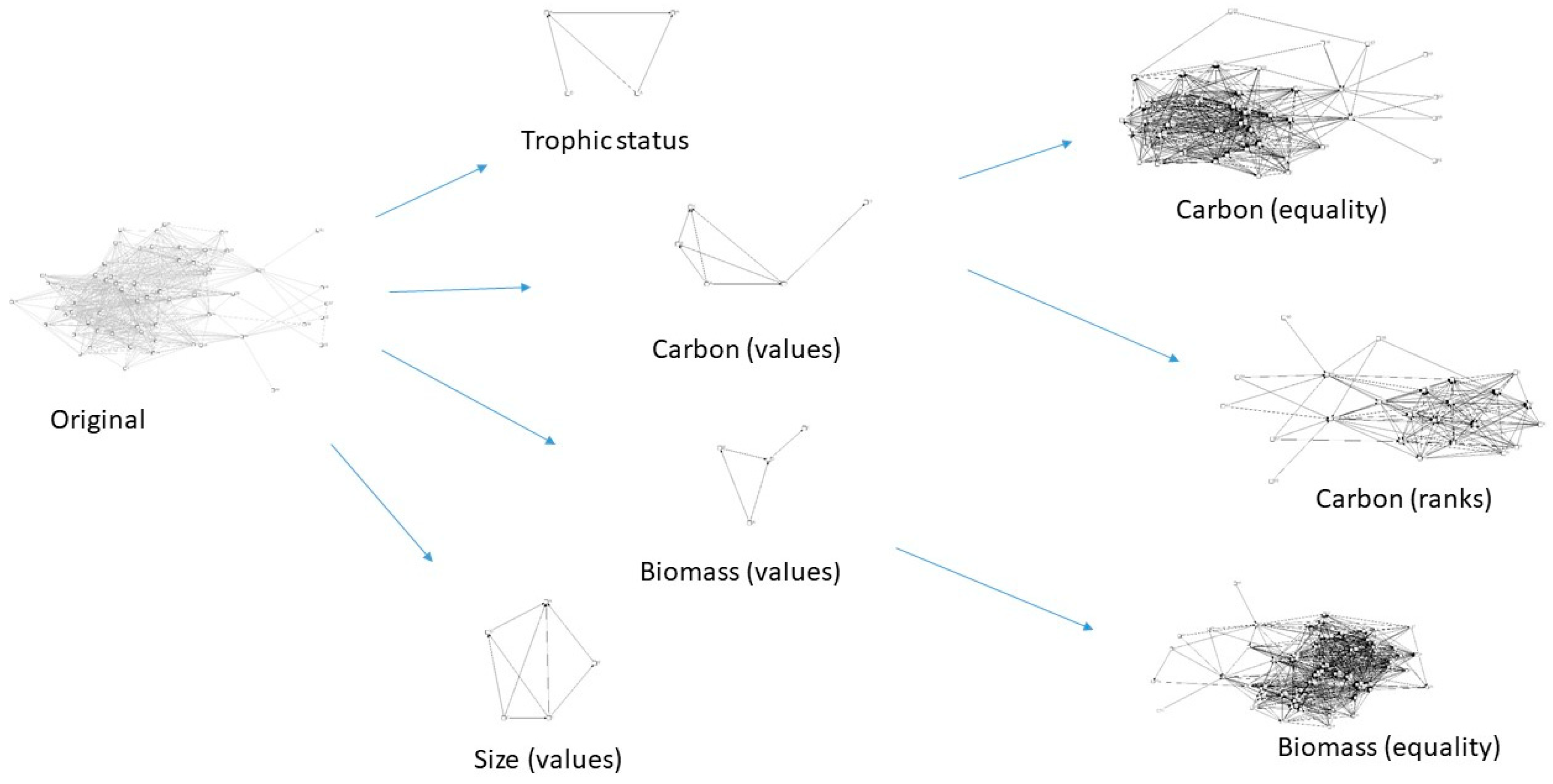
2.1. Data
2.2. Methods
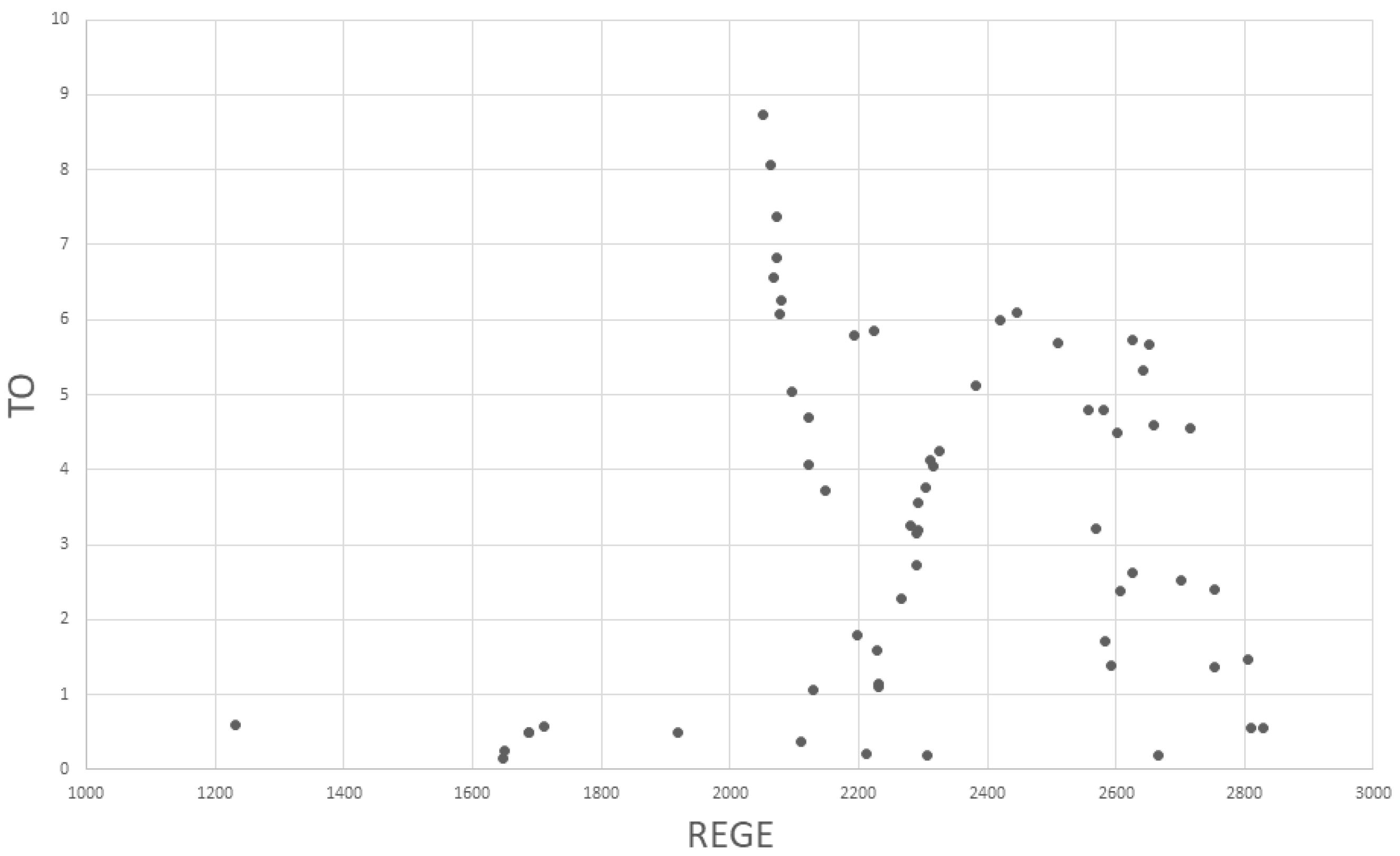
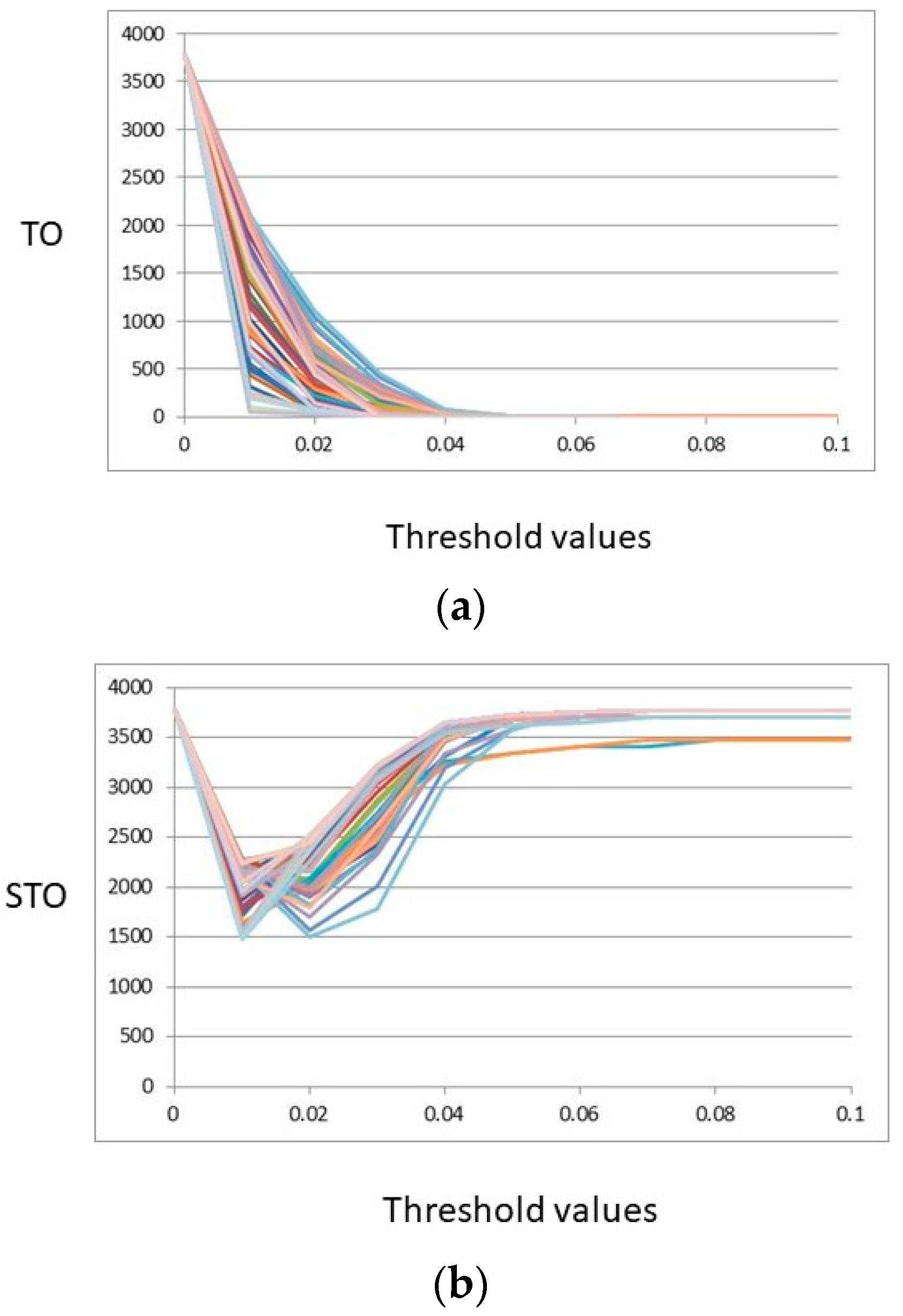
2.2.1. Topological Overlap (TO, STO)
2.2.2. Regular Equivalence (REGE)
- At iteration 0, all node pairs are perfectly equivalent (i.e., R(0)ij = 1).
- At iteration t + 1, the extent of regular equivalence between i and j, R(t + 1)ij, is determined as follows.
- (a)
- For outgoing links only, for each neighbor k of i (i.e., species i and its predator k), we determine which neighbor m of j (i.e., species j and its predator m) that is most equivalent to k according to R(t) (i.e., the largest R(t)km); and then we define a quantity Xi,k,j which takes the value of R(t)km. Likewise, from the perspective of j, we determine the value of Xj,m,i.
- (b)
- For incoming links only, for each neighbor h of i (i.e., species i and its prey h), we determine which neighbor n of j is most equivalent to h according to R(t) (i.e., the largest R(t)hn); and we then define a quantity Yi,h,j which takes the value of R(t)hn. Similarly, from the perspective of j, one determines the value of Yj,n,i.
- (c)
- The extent of regular equivalence between i and j at iteration t + 1 is defined as:where the denominator is the maximum possible value of the numerator if i and j are perfectly equivalent. R(t + 1)ij is bounded between 0 and 1, with 1 indicating i and j are perfectly equivalent.
- We repeat procedure 2 after a predefined number of iterations and let matrix S be the final R(t + 1) matrix.
2.2.3. Trait-Based Similarity Measures
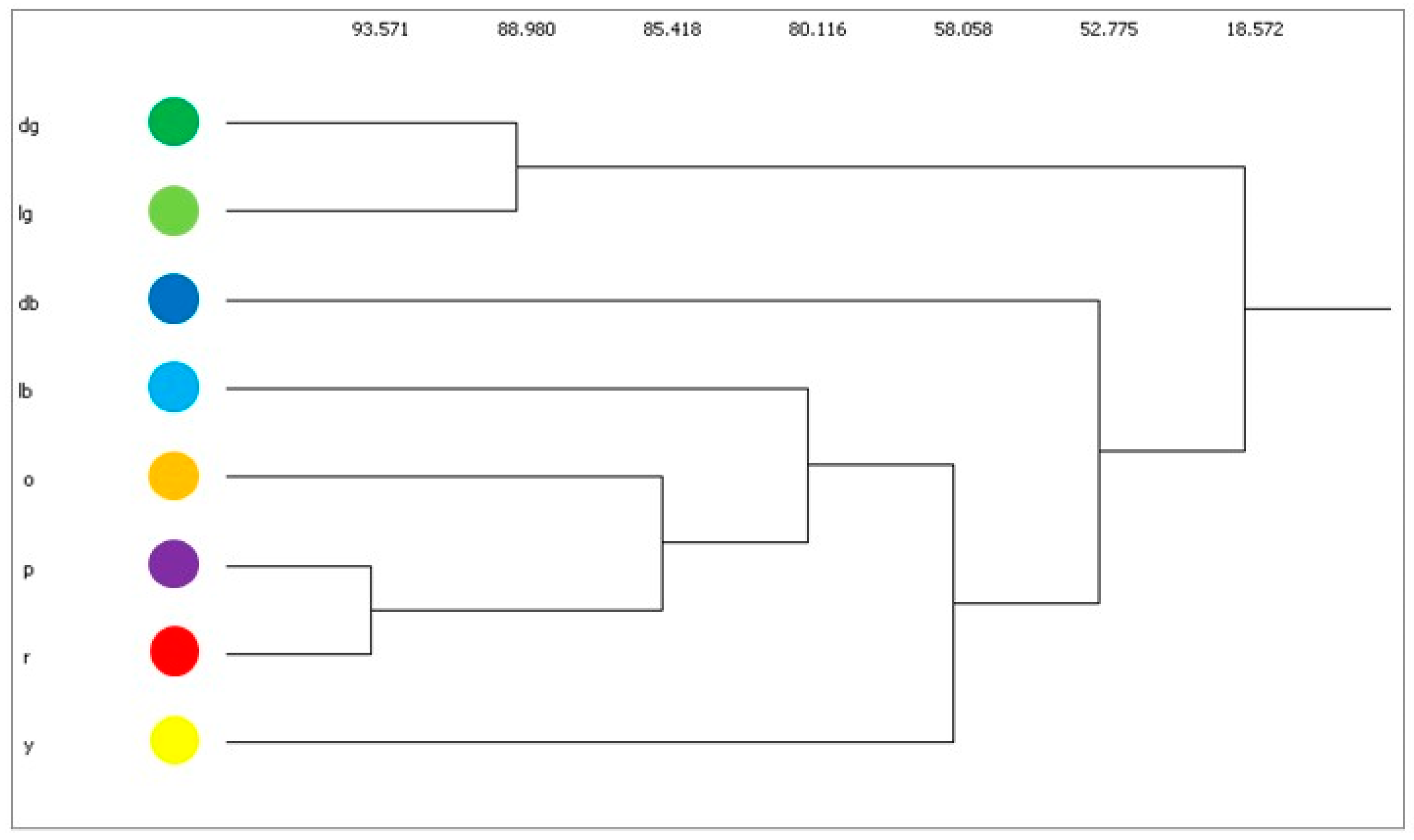
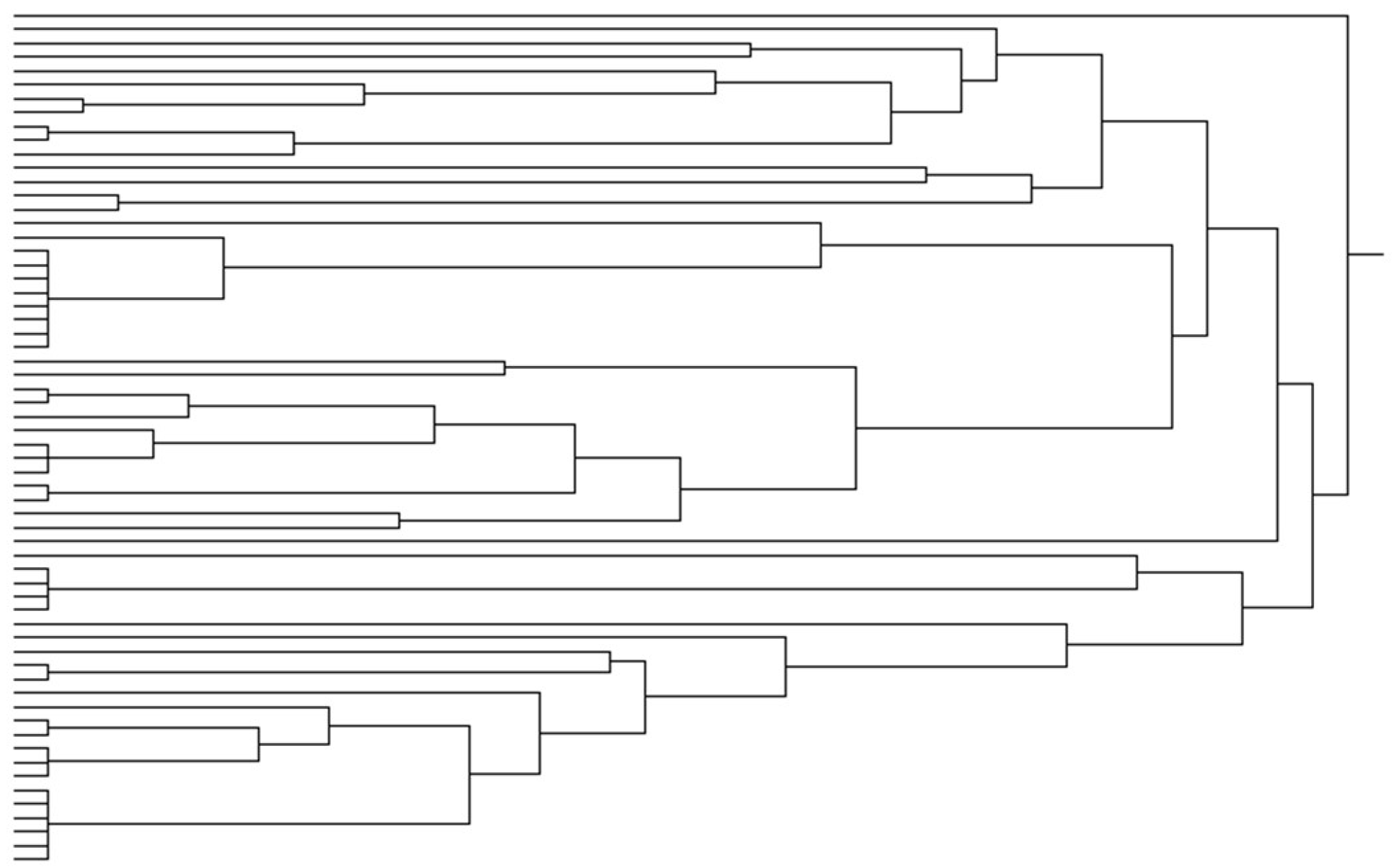
3. Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Martinez, N.D. Artifacts or attributes? Effects of resolution on the Little Rock Lake food web. Ecol. Monogr. 1991, 61, 367–392. [Google Scholar] [CrossRef]
- Thompson, R.M.; Brose, U.; Dunne, J.A.; Hall, R.O.; Hladyz, S.; Kitching, R.L.; Martinez, N.D.; Rantala, H.; Romanuk, T.N.; Stouffer, D.B.; et al. Food webs: Reconciling the structure and function of biodiversity. Trends Ecol. Evol. 2012, 27, 689–697. [Google Scholar] [CrossRef] [PubMed]
- Power, M.E.; Tilman, D.; Estes, J.A.; Menge, B.A.; Bond, W.J.; Mills, L.S.; Daily, G.; Castilla, J.C.; Lubchenco, J.; Paine, R.T. Challenges in the quest for keystones. BioScience 1996, 46, 609–620. [Google Scholar] [CrossRef]
- Lawton, J.H.; Brown, V.K. Redundancy in ecosystems. In Biodiversity and Ecosystem Function; Schulze, E.D., Mooney, H.A., Eds.; Springer: Berlin, Germany, 1994; pp. 255–270. [Google Scholar]
- Cohen, J.E. Food Webs and Niche Space; Princeton University Press: Princeton, NJ, USA, 1978. [Google Scholar]
- Luczkovich, J.J.; Borgatti, S.P.; Johnson, J.C.; Everett, M.G. Defining and measuring trophic role similarity in food webs using regular equivalence. J. Theor. Biol. 2003, 220, 303–321. [Google Scholar] [CrossRef] [PubMed]
- Cirtwill, A.R.; Dalla Riva, G.V.; Gaiarsa, M.P.; Bimler, M.D.; Cagua, E.F.; Coux, C.; Dehling, D.M. A review of species role concepts in food webs. Food Webs 2018. [Google Scholar] [CrossRef]
- Hall, S.J.; Raffaelli, D. Food-web patterns: Lessons from a species-rich web. J. Anim. Ecol. 1991, 60, 823–841. [Google Scholar] [CrossRef]
- Goldwasser, L.; Roughgarden, J. Construction and analysis of a large caribbean food web. Ecology 1993, 74, 1216–1233. [Google Scholar] [CrossRef]
- Hirata, H.; Ulanowicz, R.E. Information theoretical analysis of the aggregation and hierarchical structure of ecological networks. J. Theor. Biol. 1985, 116, 321–341. [Google Scholar] [CrossRef]
- Pahl-Wostl, C. The possible effects of aggregation on the quantitative interpretation of flow patterns in ecological networks. Math. Biosci. 1992, 112, 177–183. [Google Scholar] [CrossRef]
- Solow, A.R.; Beet, A.R. On lumping species in food webs. Ecology 1998, 79, 2013–2018. [Google Scholar] [CrossRef]
- Jordán, F.; Osváth, G. The sensitivity of food web topology to temporal data aggregation. Ecol. Model. 2009, 220, 3141–3146. [Google Scholar] [CrossRef]
- Patonai, K.; Jordán, F. Aggregation of incomplete food web data may help to suggest sampling strategies. Ecol. Model. 2017, 352, 77–89. [Google Scholar] [CrossRef]
- Scotti, M.; Hartvig, M.; Winemiller, K.O.; Li, Y.; Jauker, F.; Jordán, F.; Dormann, C.F. Trait-based and process-oriented modeling in ecological network dynamics. In Adaptive Food Webs; Moore, J.C., de Ruiter, P.C., McCann, K.S., Wolters, V., Eds.; Cambridge University Press: Cambridge, UK, 2017; pp. 228–256. [Google Scholar]
- Sommer, U.; Charalampous, E.; Scotti, M.; Moustaka-Gouni, M. Big fish eat small fish: Implications for food chain length? Comm. Ecol. 2018, 19, 107–115. [Google Scholar] [CrossRef]
- Bond, W.J. Keystone species. In Biodiversity and Ecosystem Function; Schulze, E.D., Mooney, H.A., Eds.; Springer: Berlin, Germany, 1994. [Google Scholar]
- Daily, G.C.; Ehrlich, P.R.; Haddad, N.M. Double keystone bird in a keystone species complex. Proc. Natl. Acad. Sci. USA 1993, 90, 592–594. [Google Scholar] [CrossRef] [PubMed]
- Ortiz, M.; Hermosillo-Nuñez, B.; González, J.; Rodríguez-Zaragoza, F.; Gómez, I.; Jordán, F. Quantifying keystone species complexes: Ecosystem-based conservation management in the King George Island (Antarctic Peninsula). Ecol. Indic. 2017, 81, 453–460. [Google Scholar] [CrossRef]
- d’Alcalà, M.R.; Conversano, F.; Corato, F.; Licandro, P.; Mangoni, O.; Marino, D.; Mazzocchi, M.G.; Modigh, M.; Montresor, M.; Nardella, M.; et al. Seasonal patterns in plankton communities in a pluriannual time series at a coastal Mediterranean site (Gulf of Naples): An attempt to discern recurrences and trends. Sci. Mar. 2004, 68, 65–83. [Google Scholar]
- D’Alelio, D.; Libralato, S.; Wyatt, T.; Ribera d’Alcalà, M. Ecological-network models link diversity, structure and function in the plankton food-web. Sci. Rep. 2016, 6, 21806. [Google Scholar] [CrossRef]
- D’Alelio, D.; Montresor, M.; Mazzocchi, M.G.; Margiotta, F.; Sarno, D.; Ribeira d’Alcalà, M. Plankton food-webs: To what extent can they be simplified? Adv. Oceanogr. Limnol. 2016, 7. [Google Scholar] [CrossRef]
- Müller, C.B.; Adriaanse, I.C.T.; Belshaw, R.; Godfray, H.C.J. The structure of an aphid–parasitoid community. J. Anim. Ecol. 1999, 68, 346–370. [Google Scholar] [CrossRef]
- Jordán, F.; Liu, W.-C.; van Veen, F.J.F. Quantifying the importance of species and their interactions in a host-parasitoid community. Commun. Ecol. 2003, 4, 79–88. [Google Scholar] [CrossRef]
- Jordán, F.; Liu, W.-C.; Mike, Á. Trophic field overlap: A new approach to quantify keystone species. Ecol. Model. 2009, 220, 2899–2907. [Google Scholar] [CrossRef]
- Lai, S.M.; Liu, W.C.; Jordán, F. A trophic overlap-based measure for species uniqueness in ecological networks. Ecol. Model. 2015, 299, 95–101. [Google Scholar] [CrossRef]
- Lorrain, F.; White, H.C. Structural equivalence of individuals in social networks. J. Math. Sociol. 1971, 1, 49–80. [Google Scholar] [CrossRef]
- Everett, M.G.; Borgatti, S. Role colouring a graph. Math. Soc. Sci. 1991, 21, 183–188. [Google Scholar] [CrossRef]
- Borgatti, S.P.; Everett, M.G.; Freeman, L.C. Ucinet for Windows: Software for Social Network Analysis; Analytic Technologies: Harvard, MA, USA, 2002. [Google Scholar]
- Yodzis, P.; Winemiller, K.O. In search of operational trophospecies in a tropical aquatic food web. Oikos 1999, 87, 327–340. [Google Scholar] [CrossRef]
- Carradec, Q.; Coordinators, T.O.; Pelletier, E.; Da Silva, C.; Alberti, A.; Seeleuthner, Y.; Blanc-Mathieu, R.; Lima-Mendez, G.; Rocha, F.; Tirichine, L.; et al. A global ocean atlas of eukaryotic genes. Nat. Commun. 2018, 9, 373. [Google Scholar] [CrossRef] [PubMed]
- Franks, P.J.S. NPZ models of plankton dynamics: Their construction, coupling to physics, and application. J. Oceanogr. 2002, 58, 379–387. [Google Scholar] [CrossRef]
- Mitra, A.; Castellani, C.; Gentleman, W.C.; Jonasdottir, S.H.; Flynn, K.J.; Bode, A.; Halsband, C.; Kuhn, P.; Licandro, P.; Agersted, M.D.; et al. Bridging the gap between marine biogeochemical and fisheries sciences; configuring the zooplankton link. Progr. Oceanogr. 2014, 129, 176–199. [Google Scholar] [CrossRef]
- Conley, K.R.; Lombard, F.; Sutherland, K.S. Mammoth grazers on the ocean’s minuteness: A review of selective feeding using mucous meshes. Proc. Biol. Soc. 2018, 285, 20180056. [Google Scholar] [CrossRef]
- Flynn, K.J.; Stoecker, D.K.; Mitra, A.; Raven, J.A.; Glibert, P.M.; Hansen, P.J.; Granéli, E.; Burkholder, J.M. Misuse of the phytoplankton–zooplankton dichotomy: The need to assign organisms as mixotrophs within plankton functional types. J. Plankton Res. 2012, 35, 3–11. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A | B | |||||||||||||||||||
| db | dg | lb | lg | o | p | r | y | db | dg | lb | lg | o | p | r | y | sum | rank | |||
| db | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 67 | 0 | 28 | 49 | 50 | 56 | db | 250 | r | 420 | |
| dg | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 18 | 89 | 55 | 49 | 36 | 0 | dg | 247 | o | 412 | ||
| lb | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 39 | 68 | 85 | 83 | 53 | lb | 346 | p | 411 | |||
| lg | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 65 | 61 | 51 | 0 | lg | 305 | lb | 346 | ||||
| o | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 77 | 89 | 58 | o | 412 | lg | 305 | |||||
| p | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 94 | 45 | p | 411 | db | 250 | ||||||
| r | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 67 | r | 420 | dg | 247 | |||||||
| y | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | y | 223 | y | 223 | ||||||||
| C | D | |||||||||||||||||||
| db | dg | lb | lg | o | p | r | y | db | dg | lb | lg | o | p | r | y | sum | rank | |||
| db | 0.17 | 0 | 0.17 | 0 | 0 | 0.08 | 0.06 | 0 | 0 | 2 | 0 | 0 | 2 | 2 | 0 | db | 6 | r | 20 | |
| dg | 0 | 0.13 | 0 | 0.04 | 0.13 | 0.06 | 0.04 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | dg | 0 | o | 14 | ||
| lb | 0.5 | 0 | 0.64 | 0.06 | 0,1 | 0.25 | 0.17 | 0 | 1 | 2 | 3 | 4 | 0 | lb | 12 | lb | 12 | |||
| lg | 0 | 0.13 | 0.06 | 0.26 | 0.17 | 0.06 | 0.21 | 0.5 | 4 | 0 | 4 | 2 | lg | 11 | lg | 11 | ||||
| o | 0 | 0.5 | 0.14 | 0.22 | 0.27 | 0.25 | 0.22 | 0.17 | 1 | 5 | 2 | o | 14 | p | 9 | |||||
| p | 0.17 | 0.13 | 0.17 | 0.04 | 0.13 | 0.15 | 0.1 | 0 | 3 | 0 | p | 9 | db | 6 | ||||||
| r | 0.17 | 0.13 | 0.17 | 0.21 | 0.17 | 0.15 | 0.15 | 0.17 | 2 | r | 20 | y | 6 | |||||||
| y | 0 | 0 | 0 | 0.17 | 0.04 | 0 | 0.06 | 0.17 | y | 6 | dg | 0 |
| Scenarios | cv | bv | sv |
|---|---|---|---|
| A | 49 | 62 | 56 |
| B | 54 | 41 | 52 |
| C | 56 | 29, 56 | 50, 57 |
| D | 52 | 45, 46, 47, 48, 51 | |
| E | others | others | others |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jordán, F.; Endrédi, A.; Liu, W.-c.; D’Alelio, D. Aggregating a Plankton Food Web: Mathematical versus Biological Approaches. Mathematics 2018, 6, 336. https://doi.org/10.3390/math6120336
Jordán F, Endrédi A, Liu W-c, D’Alelio D. Aggregating a Plankton Food Web: Mathematical versus Biological Approaches. Mathematics. 2018; 6(12):336. https://doi.org/10.3390/math6120336
Chicago/Turabian StyleJordán, Ferenc, Anett Endrédi, Wei-chung Liu, and Domenico D’Alelio. 2018. "Aggregating a Plankton Food Web: Mathematical versus Biological Approaches" Mathematics 6, no. 12: 336. https://doi.org/10.3390/math6120336
APA StyleJordán, F., Endrédi, A., Liu, W.-c., & D’Alelio, D. (2018). Aggregating a Plankton Food Web: Mathematical versus Biological Approaches. Mathematics, 6(12), 336. https://doi.org/10.3390/math6120336