



Task-Oriented Local Feature Rectification Network for Few-Shot Image Classification


Abstract
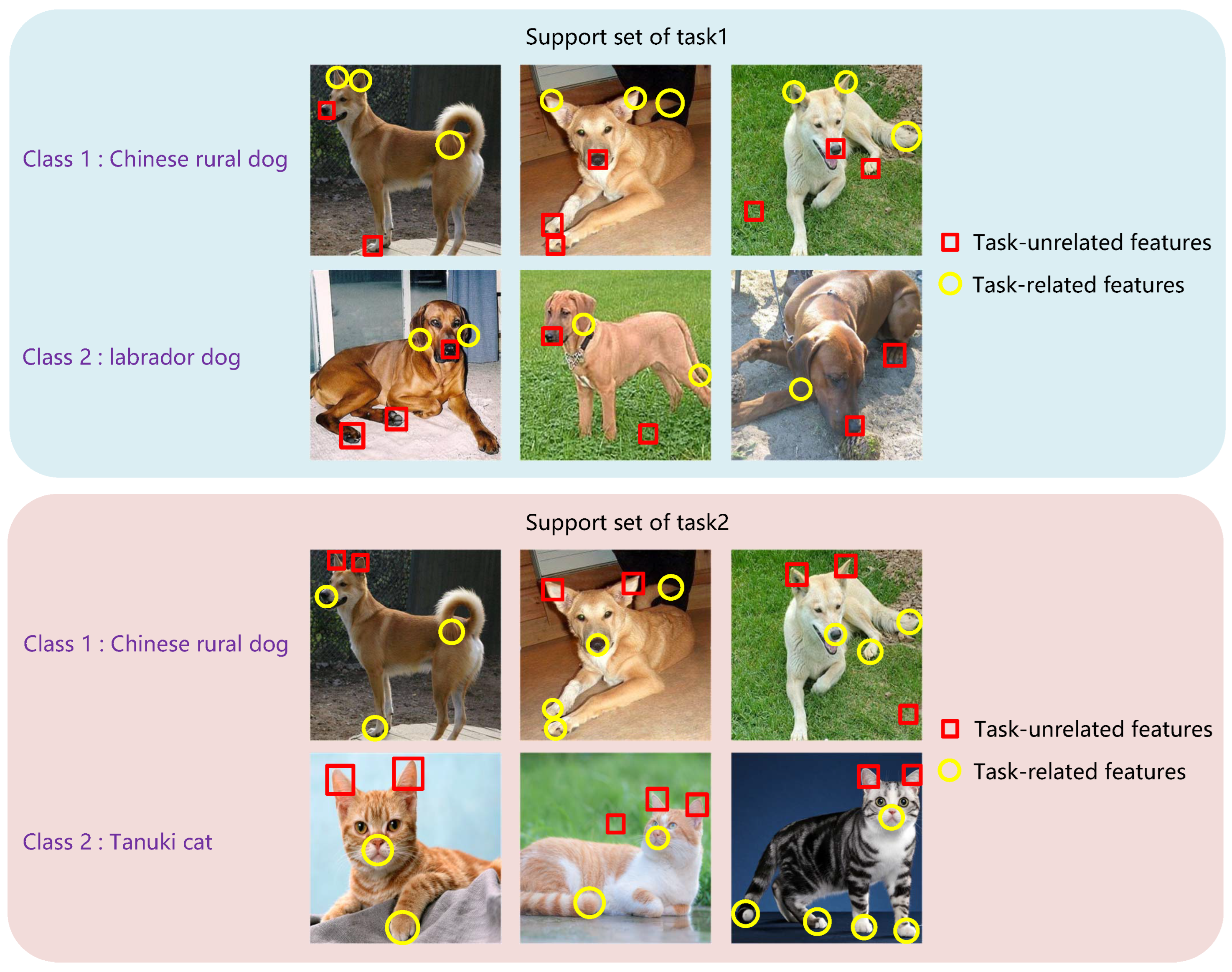
1. Introduction
- We separately design the SRM and the QRM to rectify the local features in a task-oriented form. Thus, the model can focus on the features closely related to the corresponding category while suppressing the influence of irrelevant features.
- We use a similarity rectification network to rectify the similarity tensors in order to obtain more accurate feature similarities for the computation of query local feature weight.
- We conduct extensive experiments on multiple datasets, and demonstrate that our method can effectively rectify the local features, resulting in a significant improvement over related methods.
2. Related Work
2.1. Data Augmentation-Based Methods
2.2. Meta-Learning-Based Methods
2.3. Metric Learning-Based Methods
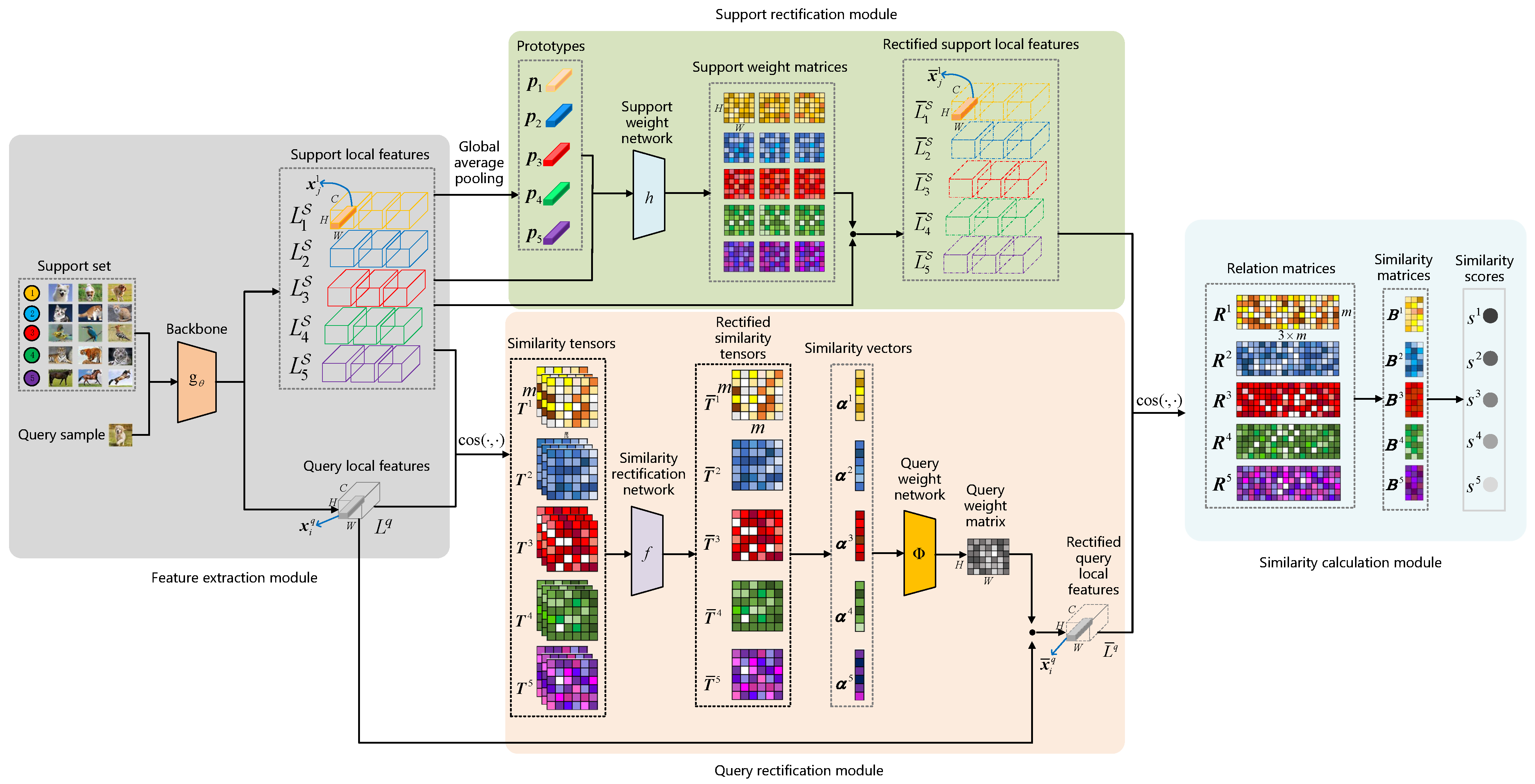
3. Task-Oriented Local Feature Rectification Network
3.1. Problem Description
3.2. The Proposed TLFRNet Framework
3.3. Feature Extraction Module
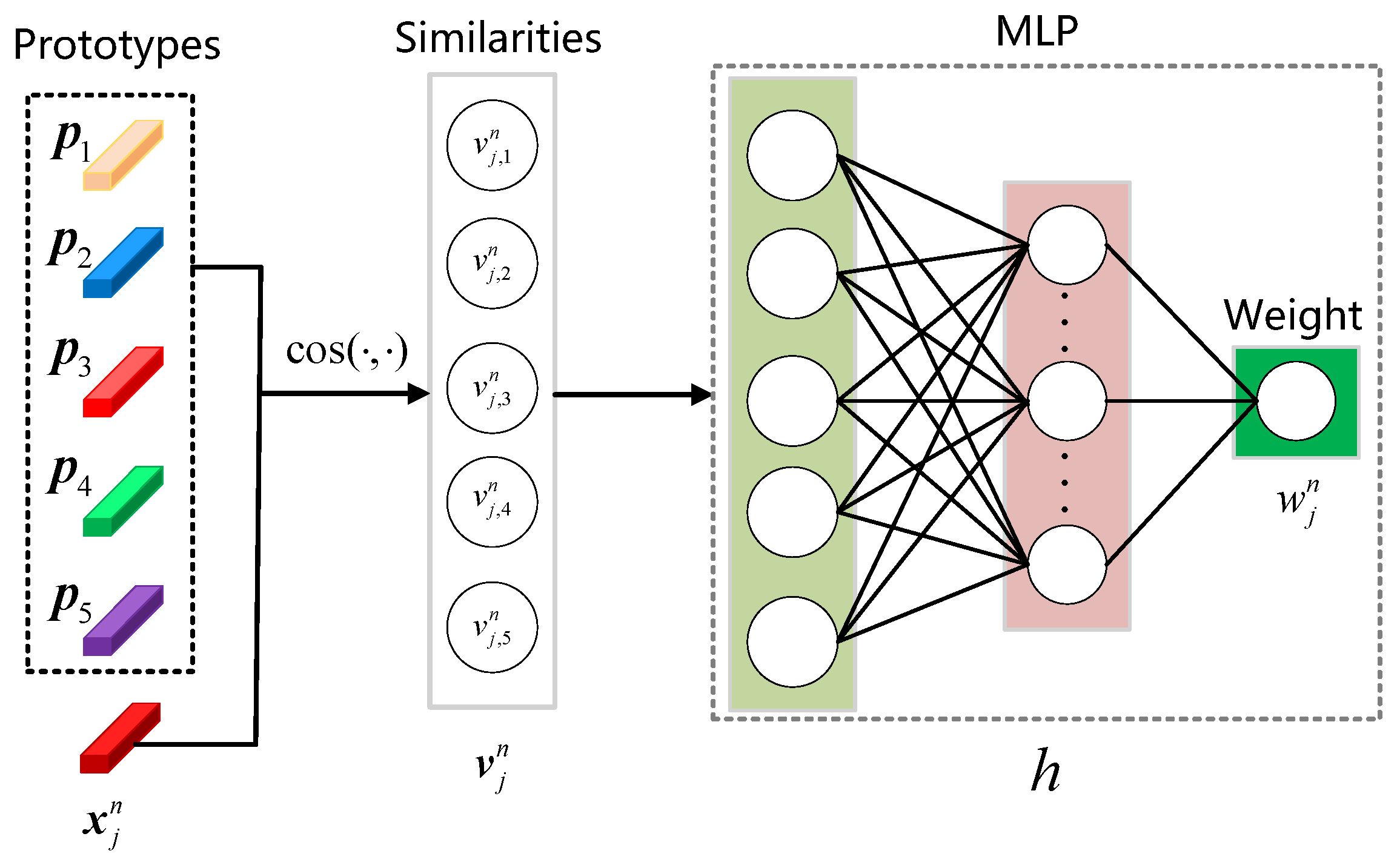
3.4. Support Rectification Module
3.5. Query Rectification Module
3.6. Similarity Calculation Module
4. Performance Evaluation
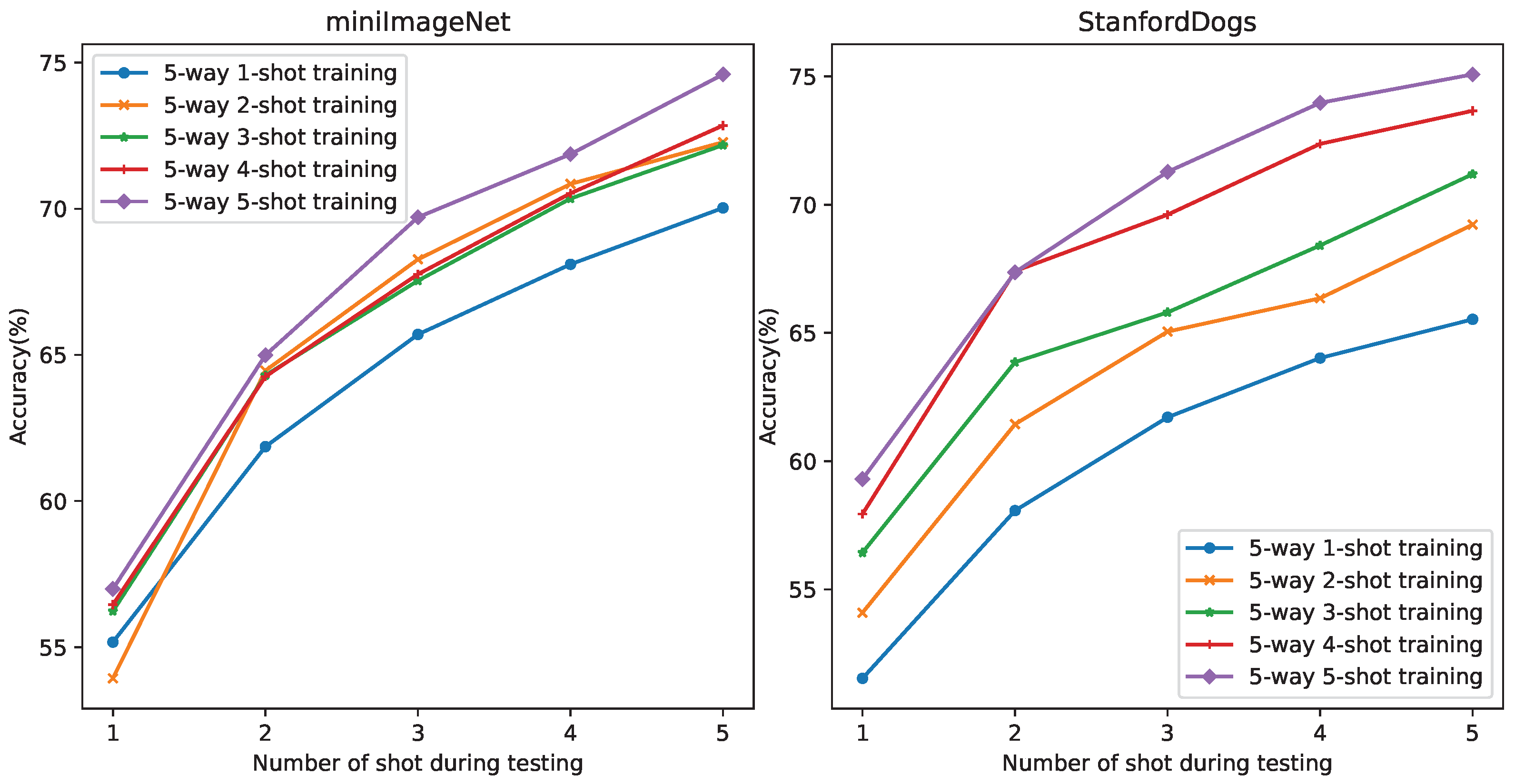
4.1. Experimental Settings
4.2. Experimental Results on miniImageNet and tieredImagenet
4.3. Experiments on Three Fine-Grained Datasets
4.4. Comparison with Other Feature Extraction Networks
4.5. Ablation Experiments
4.6. Computational Complexity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lin, Z.; Wang, Y.; Zhang, J.; Chu, X. Dynamicdet: A unified dynamic architecture for object detection. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 6282–6291. [Google Scholar]
- Nirkin, Y.; Wolf, L.; Hassner, T. Hyperseg: Patch-wise hypernetwork for real-time semantic segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4061–4070. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Luo, X.; Wu, H.; Zhang, J.; Gao, L.; Xu, J.; Song, J. A closer look at few-shot classification again. In Proceedings of the International Conference on Machine Learning (ICML), Honolulu, HI, USA, 23–29 July 2023; pp. 23103–23123. [Google Scholar]
- Zhou, F.; Wang, P.; Zhang, L.; Wei, W.; Zhang, Y. Revisiting prototypical network for cross domain few-shot learning. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 20061–20070. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical Networks for Few-shot Learning. In Proceedings of the Thirty-First Annual Conference on Neural Information Processing Systems, NeurIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 4077–4087. [Google Scholar]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7260–7268. [Google Scholar]
- Zhang, C.; Cai, Y.; Lin, G.; Shen, C. Deepemd: Few-shot image classification with differentiable earth mover’s distance and structured classifiers. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12203–12213. [Google Scholar]
- Huang, H.; Wu, Z.; Li, W.; Huo, J.; Gao, Y. Local descriptor-based multi-prototype network for few-shot learning. Pattern Recognit. 2021, 116, 107935. [Google Scholar] [CrossRef]
- Liu, Y.; Zheng, T.; Song, J.; Cai, D.; He, X. Dmn4: Few-shot learning via discriminative mutual nearest neighbor neural network. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence (AAAI), Virtual, 22 February–1 March 2022; Volume 36, pp. 1828–1836. [Google Scholar]
- Qi, H.; Brown, M.; Lowe, D.G. Low-shot learning with imprinted weights. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5822–5830. [Google Scholar]
- Schwartz, E.; Karlinsky, L.; Shtok, J.; Harary, S.; Marder, M.; Kumar, A.; Feris, R.; Giryes, R.; Bronstein, A. Delta-encoder: An effective sample synthesis method for few-shot object recognition. In Proceedings of the Conference on Neural Information Processing Systems (NeurIPS), Montréal, QC, Canada, 3–8 December 2018; pp. 2850–2860. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Li, Z.; Zhou, F.; Chen, F.; Li, H. Meta-sgd: Learning to learn quickly for few-shot learning. arXiv 2017, arXiv:1707.09835. [Google Scholar]
- Zhang, B.; Luo, C.; Yu, D.; Li, X.; Lin, H.; Ye, Y.; Zhang, B. Metadiff: Meta-learning with conditional diffusion for few-shot learning. In Proceedings of the 39th Annual AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 16687–16695. [Google Scholar]
- Zhu, H.; Koniusz, P. Transductive few-shot learning with prototype-based label propagation by iterative graph refinement. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 23996–24006. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015. [Google Scholar]
- Lee, S.; Moon, W.; Seong, H.S.; Heo, J.P. Task-Oriented Channel Attention for Fine-Grained Few-Shot Classification. arXiv 2023, arXiv:2308.00093. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Yang, L.; Gao, F. More attentional local descriptors for few-shot learning. In Proceedings of the 29th International Conference on Artificial Neural Networks, ICANN, Bratislava, Slovakia, 15–18 September 2020; pp. 419–430. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Kavukcuoglu, K.; Wierstra, D. Matching Networks for One Shot Learning. In Proceedings of the Annual Conference on Neural Information Processing Systems, NeurIPS, Barcelona, Spain, 5–10 December 2016; pp. 3630–3638. [Google Scholar]
- Sung, F.; Yang, Y.; Zhang, L.; Xiang, T.; Torr, P.H.; Hospedales, T.M. Learning to compare: Relation network for few-shot learning. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1199–1208. [Google Scholar]
- Pan, M.H.; Xin, H.Y.; Shen, H.B. Semantic-based implicit feature transform for few-shot classification. Int. J. Comput. Vis. 2024, 132, 5014–5029. [Google Scholar] [CrossRef]
- Li, P.; Song, Q.; Chen, L.; Zhang, L. Local feature semantic alignment network for few-shot image classification. Multimed. Tools Appl. 2024, 83, 69489–69509. [Google Scholar] [CrossRef]
- Wah, C.; Branson, S.; Welinder, P.; Perona, P.; Belongie, S. The Caltech-UCSD Birds-200-2011 Dataset; Technical Report CNS-TR-2011-001; California Institute of Technology: Pasadena, CA, USA, 2011. [Google Scholar]
- Khosla, A.; Jayadevaprakash, N.; Yao, B.; Li, F.F. Novel dataset for fine-grained image categorization: Stanford dogs. In Proceedings of the CVPR Workshop on Fine-Grained Visual Categorization (FGVC), Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3d object representations for fine-grained categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, NSW, Australia, 2–8 December 2013; pp. 554–561. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zheng, Z.; Feng, X.; Yu, H.; Li, X.; Gao, M. BDLA: Bi-directional local alignment for few-shot learning. Appl. Intell 2023, 53, 769–785. [Google Scholar] [CrossRef]
- Trosten, D.J.; Chakraborty, R.; Løkse, S.; Wickstrøm, K.K.; Jenssen, R.; Kampffmeyer, M.C. Hubs and hyperspheres: Reducing hubness and improving transductive few-shot learning with hyperspherical embeddings. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 7527–7536. [Google Scholar]
- Satorras, V.G.; Estrach, J.B. Few-shot learning with graph neural networks. In Proceedings of the 6th International Conference on Learning Representations (ICLR 2018), Vancouver, BC, Canada, 30 April–3 May 2018; pp. 1–13. [Google Scholar]
- Li, W.; Xu, J.; Huo, J.; Wang, L.; Gao, Y.; Luo, J. Distribution consistency based covariance metric networks for few-shot learning. In Proceedings of the Thirty-Third AAAI Conference on Artificial Intelligence, AAAI, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8642–8649. [Google Scholar]
- Hao, F.; He, F.; Cheng, J.; Wang, L.; Cao, J.; Tao, D. Collect and select: Semantic alignment metric learning for few-shot learning. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8460–8469. [Google Scholar]
- Dong, C.; Li, W.; Huo, J.; Gu, Z.; Gao, Y. Learning task-aware local representations for few-shot learning. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021; pp. 716–722. [Google Scholar]
- Chen, H.; Li, H.; Li, Y.; Chen, C. Multi-scale adaptive task attention network for few-shot learning. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 4765–4771. [Google Scholar]
- Song, Q.; Zhou, S.; Xu, L. Learning More Discriminative Local Descriptors for Few-shot Learning. arXiv 2023, arXiv:2305.08721. [Google Scholar]
- Huang, X.; Choi, S.H. Sapenet: Self-attention based prototype enhancement network for few-shot learning. Pattern Recognit. 2023, 135, 109170. [Google Scholar] [CrossRef]
- Qiao, Q.; Xie, Y.; Zeng, Z.; Li, F. Talds-net: Task-aware adaptive local descriptors selection for few-shot image classification. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 3750–3754. [Google Scholar]
- Wang, M.; Yan, B. LDCA: Local Descriptors with Contextual Augmentation for Few-Shot Learning. arXiv 2024, arXiv:2401.13499. [Google Scholar]
- Huang, H.; Zhang, J.; Zhang, J.; Xu, J.; Wu, Q. Low-Rank Pairwise Alignment Bilinear Network For Few-Shot Fine-Grained Image Classification. IEEE Trans. Multimed. 2021, 23, 1666–1680. [Google Scholar] [CrossRef]
- Wu, J.; Chang, D.; Sain, A.; Li, X.; Ma, Z.; Cao, J.; Guo, J.; Song, Y.Z. Bi-directional feature reconstruction network for fine-grained few-shot image classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 2821–2829. [Google Scholar]
- Yan, B. Feature Aligning Few shot Learning Method Using Local Descriptors Weighted Rules. arXiv 2024, arXiv:2408.14192. [Google Scholar]
- Mishra, N.; Rohaninejad, M.; Chen, X.; Abbeel, P. A simple neural attentive meta-learner. arXiv 2017, arXiv:1707.03141. [Google Scholar]
- Gidaris, S.; Komodakis, N. Dynamic few-shot visual learning without forgetting. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4367–4375. [Google Scholar]
- He, J.; Zhang, X.; Lei, S.; Alhamadani, A.; Chen, F.; Xiao, B.; Lu, C.T. Clur: Uncertainty estimation for few-shot text classification with contrastive learning. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Minin, SIGKDD, Long Beach, CA, USA, 6–10 August 2023; pp. 698–710. [Google Scholar]
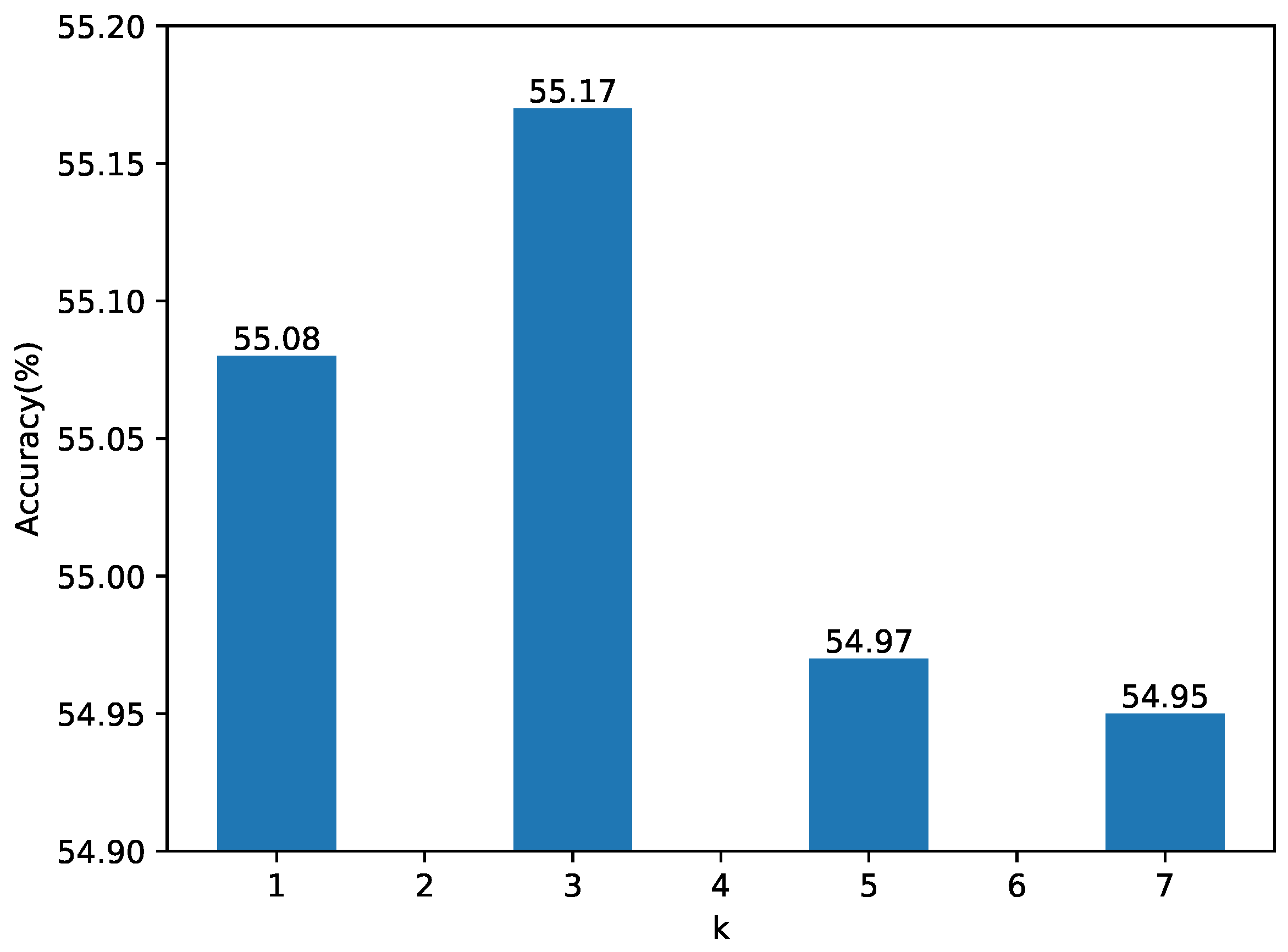

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | miniImageNet | tieredImagenet | ||
|---|---|---|---|---|
| 5-Way 1-Shot | 5-Way 5-Shot | 5-Way 1-Shot | 5-Way 5-Shot | |
| MAML † [15] | 48.70 ± 1.84 | 63.11 ± 0.92 | 51.67 ± 1.81 | 70.30 ± 0.08 |
| Meta-Learner LSTM * [14] | 43.44 ± 0.77 | 60.60 ± 0.71 | — | — |
| Matching Net * [22] | 43.56 ± 0.84 | 55.31 ± 0.73 | — | — |
| Prototypical Net * [6] | 49.42 ± 0.78 | 68.20 ± 0.66 | 48.58 ± 0.00 | 69.57 ± 0.00 |
| Relation Net * [23] | 50.44 ± 0.82 | 65.32 ± 0.70 | 54.48 ± 0.00 | 71.31 ± 0.00 |
| GNN * [32] | 50.33 ± 0.36 | 66.41 ± 0.63 | — | — |
| CovaMNet * [33] | 51.19 ± 0.76 | 67.65 ± 0.63 | 54.98 ± 0.90 | 71.51 ± 0.75 |
| SAML * [34] | 52.22 ± 0.00 | 66.49 ± 0.00 | — | — |
| DN4 * [7] | 51.24 ± 0.74 | 71.02 ± 0.64 | 56.86 ± 0.00 | 72.16 ± 0.00 |
| LMPNet * [9] | 49.87 ± 0.20 | 68.81 ± 0.16 | 47.50 ± 0.11 | 72.65 ± 0.20 |
| ATL-Net * [35] | 54.30 ± 0.76 | 73.22 ± 0.63 | — | — |
| DeepEMD † [8] | 52.15 ± 0.28 | 65.52 ± 0.72 | 50.89 ± 0.00 | 66.129 ± 0.00 |
| MATANet * [36] | 53.63 ± 0.83 | 72.67 ± 0.76 | — | — |
| DLDA * [37] | 53.20 ± 0.82 | 71.76 ± 0.47 | — | — |
| MADN4 * [21] | 53.20 ± 0.52 | 71.66 ± 0.47 | — | — |
| SANet * [25] | 52.59 ± 0.79 | 71.46 ± 0.65 | 57.01 ± 0.62 | 73.04 ± 0.58 |
| DMN4 * [10] | 55.77 ± 0.84 | 74.22 ± 0.64 | 56.99 ± 0.90 | 74.13 ± 0.73 |
| LDCA (k = 1) * [40] | 53.03 ± 0.63 | 74.02 ± 0.49 | — | — |
| TALDS-Net * [39] | 56.78 ± 0.37 | 74.63 ± 0.13 | 57.54 ± 0.71 | 75.79 ± 0.43 |
| TLFRNet (ours) | 55.17 ± 0.63 | 74.60 ± 0.48 | 58.26 ± 0.43 | 74.61 ± 0.41 |
| Model | Stanford Dogs | Stanford Cars | CUB-200 | |||
|---|---|---|---|---|---|---|
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | 1-Shot | 5-Shot | |
| Matching Nets † [22] | 35.80 ± 0.99 | 47.50 ± 1.03 | 34.80 ± 0.98 | 44.70 ± 1.03 | 45.30 ± 1.03 | 59.50 ± 1.01 |
| DN4 * [7] | 45.41 ± 0.76 | 63.51 ± 0.62 | 59.84 ± 0.80 | 88.65 ± 0.44 | 46.84 ± 0.81 | 74.92 ± 0.64 |
| CovaMNet * [33] | 49.10 ± 0.76 | 63.04 ± 0.65 | 56.65 ± 0.86 | 71.33 ± 0.62 | 60.58 ± 0.69 | 74.24 ± 0.68 |
| Relation Net † [23] | 44.75 ± 0.70 | 58.36 ± 0.66 | 56.02 ± 0.74 | 66.93 ± 0.63 | 59.82 ± 0.77 | 71.83 ± 0.61 |
| GNN † [32] | 46.98 ± 0.98 | 62.27 ± 0.95 | 55.85 ± 0.97 | 71.25 ± 0.89 | 51.83 ± 0.98 | 63.69 ± 0.94 |
| DeepEMD † [8] | 46.73 ± 0.49 | 65.74 ± 0.63 | 61.63 ± 0.27 | 72.95 ± 0.38 | 64.08 ± 0.50 | 80.55 ± 0.71 |
| DLDA * [37] | 49.08 ± 0.83 | 70.16 ± 0.67 | 60.04 ± 0.83 | 89.62 ± 0.42 | 54.53 ± 0.85 | 75.85 ± 0.68 |
| LMPNet * [9] | 51.17 ± 0.22 | 64.06 ± 0.18 | 62.52 ± 0.12 | 78.44 ± 0.16 | 53.50 ± 0.24 | 66.60 ± 0.19 |
| SAPENet * [38] | — | — | — | — | 70.38 ± 0.23 | 84.47 ± 0.14 |
| SANet * [25] | 50.97 ± 0.91 | 64.70 ± 0.90 | 63.11 ± 0.87 | 78.90 ± 0.67 | 64.28 ± 0.89 | 76.94 ± 0.71 |
| MADN4 * [21] | 50.42 ± 0.27 | 70.75 ± 0.47 | 62.89 ± 0.50 | 89.25 ± 0.34 | 57.11 ± 0.70 | 77.83 ± 0.40 |
| FAFD-LDWR * [43] | 55.72 ± 0.72 | 72.76 ± 0.48 | 56.95 ± 0.66 | 81.91 ± 0.34 | 65.45 ± 0.67 | 79.63 ± 0.33 |
| TLFRNet (ours) | 51.53 ± 0.65 | 75.08 ± 0.49 | 61.90 ± 0.65 | 88.99 ± 0.34 | 71.46 ± 0.66 | 85.89 ± 0.42 |
| Model | Embedding | 5-Way 1-Shot | 5-Way 5-Shot |
|---|---|---|---|
| DN4 * [7] | ResNet12 | 54.37 ± 0.36 | 74.44 ± 0.29 |
| SNAIL * [44] | ResNet12 | 55.71 ± 0.99 | 68.88 ± 0.92 |
| Dynamic-Net * [45] | ResNet12 | 55.45 ± 0.89 | 70.13 ± 0.68 |
| SANet * [25] | ResNet12 | 54.75 ± 0.83 | 73.80 ± 0.62 |
| MATANet * [36] | ResNet12 | 60.13 ± 0.81 | 75.42 ± 0.72 |
| TLFRNet (ours) | ResNet12 | 60.75 ± 0.65 | 75.83 ± 0.48 |
| Model | miniImageNet | Stanford Dogs | Stanford Cars | CUB-200 | ||||
|---|---|---|---|---|---|---|---|---|
| 1-Shot | 5-Shot | 1-Shot | 5-Shot | 1-Shot | 5-Shot | 1-Shot | 5-Shot | |
| TLFRNet with SRM w/o QRM | 54.24 | 73.56 | 50.59 | 70.08 | 60.44 | 86.35 | 70.34 | 84.73 |
| TLFRNet with QRM w/o SRM | 54.37 | 73.74 | 49.95 | 72.51 | 59.88 | 86.34 | 71.02 | 81.56 |
| TLFRNet w/o SRN | 52.78 | 73.42 | 51.01 | 73.36 | 61.34 | 86.05 | 69.52 | 84.26 |
| TLFRNet | 55.17 | 74.60 | 51.53 | 75.08 | 61.90 | 88.99 | 71.46 | 85.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, P.; Zhu, X. Task-Oriented Local Feature Rectification Network for Few-Shot Image Classification. Mathematics 2025, 13, 1519. https://doi.org/10.3390/math13091519
Li P, Zhu X. Task-Oriented Local Feature Rectification Network for Few-Shot Image Classification. Mathematics. 2025; 13(9):1519. https://doi.org/10.3390/math13091519
Chicago/Turabian StyleLi, Ping, and Xiang Zhu. 2025. "Task-Oriented Local Feature Rectification Network for Few-Shot Image Classification" Mathematics 13, no. 9: 1519. https://doi.org/10.3390/math13091519
APA StyleLi, P., & Zhu, X. (2025). Task-Oriented Local Feature Rectification Network for Few-Shot Image Classification. Mathematics, 13(9), 1519. https://doi.org/10.3390/math13091519