1. Introduction
Optimistic investors typically respond positively to market fluctuations, whereas pessimistic investors exhibit adverse reactions [
1,
2]. Extensive studies have confirmed the significant impact of investor sentiment on capital market fluctuations [
3,
4]. A comprehensive understanding of investor sentiment is essential for predicting stock market returns and formulating effective investment strategies [
5].
Early research on investor sentiment frequently relied on survey-based measurements [
6]. For example, in the paper by Hao, the consumer confidence index (CCI) was introduced to determine sentiment levels on specific dates [
7]. Dong et al. used text mining on daily Twitter feeds, employing neural networks and two analysis tools for sentiments [
8]. Some researchers employed principal component analysis (PCA) to formulate a synthetic sentiment gauge [
9]. While the choice of sentiment proxies can vary, PCA remains widely used in sentiment analysis [
10,
11,
12]. The partial least squares (PLS) method improves predictive accuracy by filtering out irrelevant noise [
13]. Later, Huang et al. introduced the sPCA method for predicting Chinese stock market returns [
14]. Recently, the genetic algorithm (GA), which optimizes complex problems by simulating biological evolution, has also been increasingly applied to dimensionality reduction tasks [
15].
Beyond PCA, sPCA, PLS, and GA, numerous other dimensionality reduction methods exist. Since their inception, generative adversarial networks (GANs) have revolutionized artificial intelligence applications through their innovative dual-network architecture, particularly transforming progress in visual data analysis and linguistic pattern recognition [
16]. The research of Kumar et al. implemented generative adversarial networks within a methodological framework designed to elevate the reliability of stock market forecasts and minimize errors in predictive outcomes [
17]. The paper by Nejad and Ebadzadeh proposed an innovative model integrating GANs with feature-matching techniques to predict equity prices, demonstrating enhanced stability during training tests and mitigating mode collapse challenges in generative processes [
18]. Wu et al. developed GAN-driven architectures incorporating the piecewise linear representation methodology to model three distinct trading strategies in financial markets [
19]. Xu et al. designed a self-regulated GAN framework through a methodological integration of adversarial and cooperative neural architectures to forecast fluctuations in equity prices, aiming to enhance predictive robustness in financial modeling [
20]. The research by Yan and Li introduced the SAR-GAN, which integrates a self-attention mechanism with a residual network to forecast leading stocks in prominent industries across various markets [
21]. So, in our paper, we investigate sentiment indicators. In the investor sentiment literature, the term ‘sentiment’ is often denoted by S, and the specific method of generation is labelled on it. For example,
SGAN denotes the investor sentiment indicator generated by a GAN,
SGA denotes the investor sentiment indicator generated by a genetic algorithm,
SPLS denotes indicators generated through partial least squares, and
SPCA denotes indicators generated through principal component analysis. This notation is generally accepted and followed by researchers as the standard way of writing [
14].
Our study specifically aims to address three key research questions. Firstly, can GANs create a more effective investor sentiment indicator compared to traditional dimensionality reduction methods? Moreover, does our proposed SGAN demonstrate superior predictive power for stock market returns in both in-sample and out-of-sample tests? Finally, how robust is the predictive performance of SGAN across different market conditions, economic cycles, and industries?
This study advances prior scholarly discourse and application through the following key dimensions. Firstly, we apply GANs to the field of investor sentiment indicator construction, which is fundamentally different from linear dimensionality reduction methods such as PCA and PLS in the existing literature. GANs are capable of capturing complex nonlinear relationships among sentiment agents through the adversarial learning mechanism of generators and discriminators, a capability that is particularly important in the highly nonlinear financial markets. The existing literature on financial sentiment analysis rarely explores the potential of adversarial neural networks for sentiment quantification; thus, this study fills this methodological gap. Secondly, by comparing with the investor sentiment indicators constructed using the existing methodology, it is verified that the newly constructed sentiment indicator performs better in market forecasting. Moreover, out-of-sample experiments, multi-period analysis, multi-factor testing, and analysis of different industries, periods, and countries are used to demonstrate the strong robustness of SGAN. Last but not least, the findings of our paper enable investors to grasp the tendency of the change in investor sentiments better, which could help to construct more effective investing strategies.
This paper is structured as follows:
Section 2 provides a summary of the data, while
Section 3 outlines the methodology employed.
Section 4 conducts empirical analyses, followed by a robustness check in
Section 5. Finally,
Section 6 concludes this study.
5. Robustness Check
5.1. Multi-Factor Predictive Regression
In the previous section, we observed that the SPLS, SGA, and SGAN showed significant return predictability, with SGAN exhibiting particularly promising results. However, it is possible that certain economic factors within these indices could also predict returns, potentially affecting the robustness of our findings. To address this, our study investigates the macroeconomic variables’ predictive capacity and examines whether investor sentiments retain significant explanatory power for excess market returns after controlling for fundamental economic determinants. In this paper, four economic factors are incorporated into the analysis to examine their predictive capacity and evaluate the four sentiments’ predicting abilities under the control of these factors. The four economic factors include the macroeconomic prosperity consensus index (MPCI), macroeconomic sentiment proximity index (MSPI), macroeconomic sentiment lag index (MSLI), and consumer sentiment index (CSI).
Firstly, we utilize the single-factor regression analysis:
where
represents the kth economic factor raised in
Section 2.
Panel A of
Table 8 provides the estimated results for the four economic factors, in which we find that the MPCI, MSPI, MSLI, and CSI report estimation results with
R2 values of 0.9%, 5.1%, 3.0%, and 0.3%, respectively.
Secondly, we assess whether the predictive capacity of
SPLS,
SGA, and
SGAN remains robust after controlling for macroeconomic variables. For this purpose, predictive regression models are constructed, incorporating both investor sentiment indices and economic factors
:
Panels B and C of
Table 8 report the results of
SPLS and
SGA, respectively. The corresponding coefficients for
SGA and
SPLS are significant, implying that
SGA and
SPLS could still significantly predict excess market returns after adding economic factors. Panel E of
Table 8 shows the poor predictability of
SPCA after adding the four economic factors.
Panel D of
Table 9 presents the regression results for
SGAN, showing that the corresponding slope remains substantial and statistically significant even after accounting for economic factors. By comparing the results in other panels, we find that the R
2 of
SGAN in the tests on forecasting excess market returns is higher than the R
2 of
SPLS and
SGA in similar tests here. These results suggest that
SGAN contains more predictive information about excess market returns than the others.
5.2. Economic Significance Analysis
5.2.1. Predictability over Business Cycle
The predictability of investor sentiment has been shown to vary across different time periods [
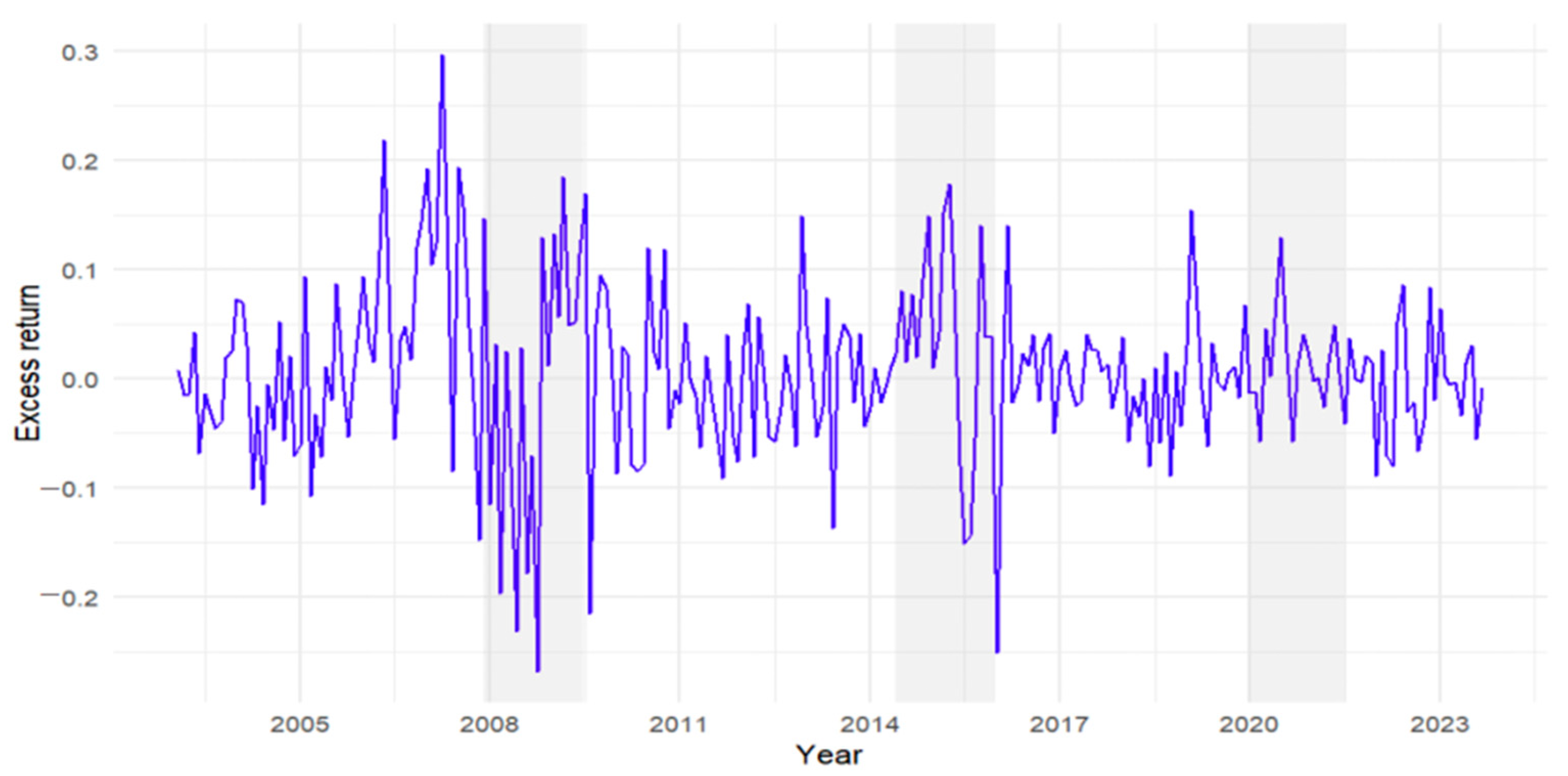
37]. Consequently, we perform the robustness check to evaluate whether the principal findings maintain statistical and economic significance in varying periods. The global financial market experienced a significant shock in 2008, known as the subprime mortgage crisis. The full sample is divided at the onset in December 2007. Similarly, the 2015 to 2016 Chinese stock market turbulence had a profound impact on investor confidence in future market conditions.
We run the regression model in
Section 4.1 for
SPCA,
SPLS,
SGA, and
SGAN again over the four time periods. The temporal analysis employs systematically segmented intervals to evaluate sentiment predictability under distinct market regimes. For the 2008 financial crisis, the sample is stratified into pre-crisis (February 2003–December 2007) and post-crisis (January 2008–September 2023) phases. Similarly, China’s 2015 equity market correction is analyzed through pre-turbulence (February 2003–June 2015) and post-turbulence (July 2015–September 2023) windows.
Table 9 presents the comparative predictive efficacy of sentiment metrics across these temporally stratified intervals, revealing structural variations in forecasting capacity during crisis versus noncrisis market states.
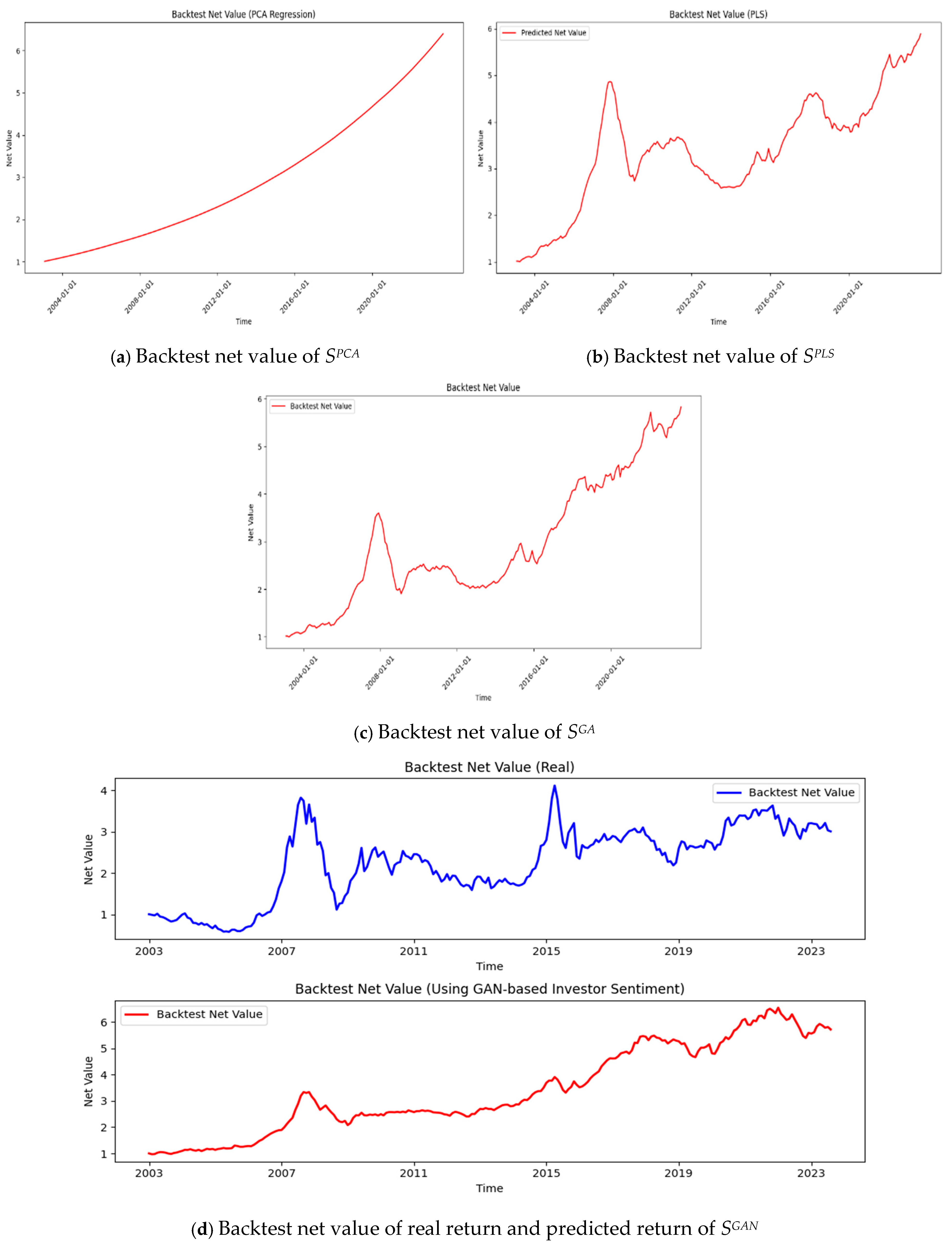
Table 10 provides a comparative analysis of different predictors. For example, before the subprime crisis,
SPLS exhibited significant positive predictive power, but after the crisis, its predictive ability turned negative, and its explanatory power decreased substantially, indicating that the market’s reliance on this variable weakened in the face of the crisis.
SGAN reflects the dramatic shift in market mood, showing a sharp drop in sentiment that corresponded with the market’s steep decline. The recovery seen later is captured by the rebound in sentiment, demonstrating
SGAN’s ability to predict the market’s reaction to global financial events and policy interventions.
A similar pattern is observed in the period surrounding the Chinese stock market turbulence. SGAN exhibited greater robustness, as its predictive ability remained stable and even improved after the turbulence, with a significant increase in explanatory power. These results indicate that SGAN demonstrates a high degree of robustness during both crises, effectively responding to external shocks, whereas SPLS and SGA show greater variability in their predictive performances across different stages.
5.2.2. Predictability During Bull Market, Bear Markets, and Turning Points
As a measure of market sentiment, the indicator exhibits strong indicative power in bull–bear market transitions. Specifically:
- (1)
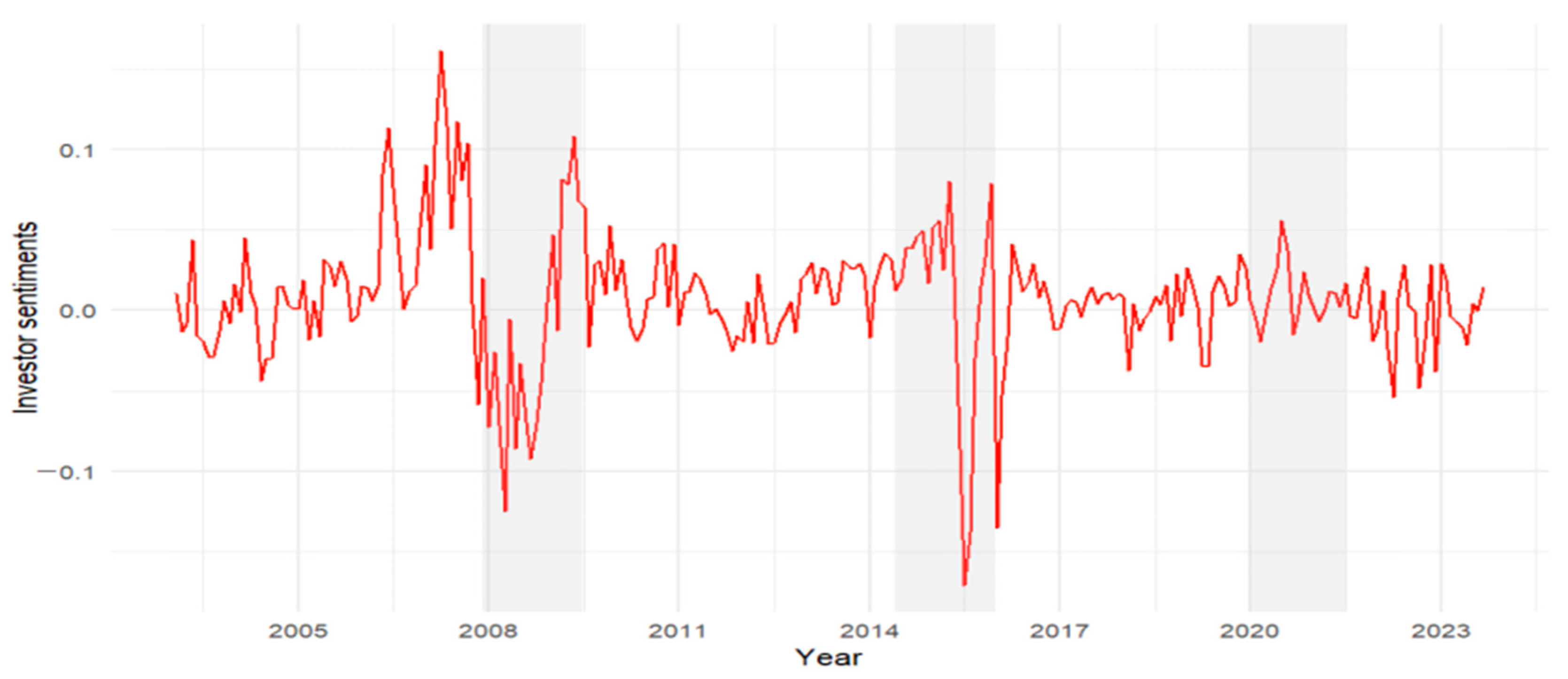
Bull Market: At the early stage of a bull market, SGAN exhibits a gradual upward trend, indicating a steady improvement in investor sentiment. As the market reaches its late phase, SGAN experiences a sharp surge, suggesting potential overheating and speculative bubbles.
- (2)
Bear Market: In the initial phase of a bear market, SGAN declines rapidly, reflecting a significant deterioration in investor confidence. Towards the end of the bear cycle, SGAN remains at a low level but gradually recovers as signs of market stabilization emerge. A notable example is the 2008 global financial crisis, where SGAN plummeted to a trough before gradually rebounding with the onset of economic recovery in 2009.
- (3)
Turning Points: SGAN tends to lead market return fluctuations at critical turning points, meaning that when it reaches an extreme high or low, a market trend reversal often follows. This characteristic makes SGAN a valuable reference for investment strategies. For instance, a downturn from a high SGAN level may signal rising market risks, prompting a more cautious approach, whereas an upward shift from a low SGAN level may indicate a favorable entry point for investors.
5.2.3. Predictability During Bear Markets
In the Chinese stock market, bear markets are usually triggered by a range of economic, political, and market factors [
36]. In the past few years, the Chinese stock market has experienced several notable bear markets, particularly in 2015, 2018, and 2021 to 2023 [
38]. Market behavior during these bear markets provides an important opportunity to test the validity of investor sentiment indicators [
39].
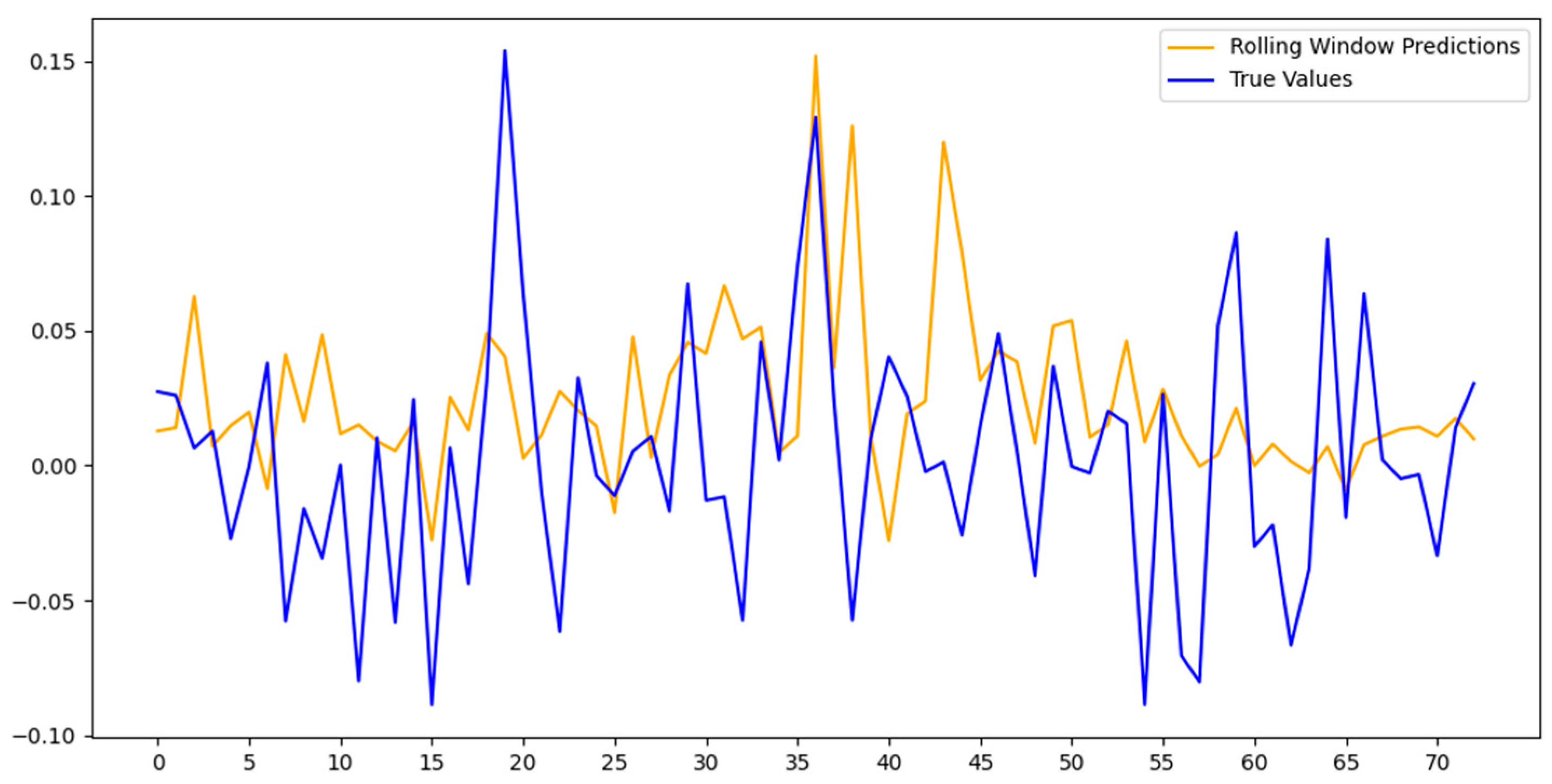
As can be seen in
Table 11,
SGAN has demonstrated strong forecasting ability during different bear market periods. During the crash between June 2015 and February 2016, the predictive performance of
SGAN is impressive and significant, with an R² of 68.4%, demonstrating the model’s high ability to explain excess market returns. In contrast,
SPCA has no predictive power in almost all the time periods.
SPLS performs relatively weakly, especially during the same period, with an R² of 61.3% and a negative coefficient, suggesting that its forecasts are not as good during this period. The performance of
SGA is relatively robust, with the significant coefficient and high R², but still not as good as that of
SGAN. In addition, during the other periods of the bear market, in 2018 and from 2021 to 2023,
SGAN still maintains a high R² value of 71.8% and 47.2%, respectively, showing its robustness and consistency across market cycles. Overall,
SGAN performs well in all bear market periods analyzed, proving its strong predictive ability as a sentiment indicator in extreme market conditions.
5.2.4. Which Market Behaviors (e.g., Speculation, Market Bubbles) Influence SGAN Dynamics?
As an investor sentiment index, SGAN captures various behavioral patterns in financial markets. It demonstrates notable sensitivity to specific market conditions, particularly in the following scenarios:
- (1)
Speculation: Empirical evidence suggests that one of SGAN’s key sentiment factors is market trading activity (TURN), which tends to increase during periods of heightened speculative behavior. For instance, in bullish markets, retail investors typically engage in higher trading volumes, leading to a surge in overall market sentiment, which is subsequently reflected in SGAN’s upward movement.
- (2)
Market Bubbles: SGAN is also effective in identifying market bubble formations. During major bull runs, such as those in 2007 and 2015 of the Chinese A-share market, SGAN recorded significant increases, signaling extreme investor optimism. Notably, before a bubble bursts, SGAN often exhibits an early downward trend.
- (3)
Flight to safety: During periods of heightened market uncertainty, such as the 2008 global financial crisis and the 2020 COVID-19 pandemic, SGAN experienced a pronounced decline, reflecting deteriorating investor sentiment and a shift towards safer assets. This trend aligns with the movement of the VIX index (volatility index), reinforcing SGAN’s ability to capture risk aversion behavior under financial distress.
5.2.5. How Do SGAN’s Core Sentiment Factors Relate to Investor Behavior?
The key sentiment factors extracted by SGAN using deep learning techniques exhibit strong associations with investor behavior in financial markets. These relationships are particularly evident in the following aspects:
- (1)
Market Participation:
- ①
Key Factors: TURN (trading volume), NIA (number of new accounts).
- ②
Trading volume and the number of newly opened accounts serve as indicators of investor enthusiasm. When market sentiment strengthens, these metrics tend to rise, and SGAN correspondingly reflects this upward trend.
- (2)
Speculative Trading
- ①
Key Factors: IPOR (IPO first-day return), IPON (number of IPOs).
- ②
A heightened preference for high-risk assets is often accompanied by an increase in IPO first-day returns and the number of IPOs. SGAN captures this dynamic, signaling periods of intensified speculative activity.
- (3)
Market Uncertainty
- ①
Key Factor: EPU (economic policy uncertainty index).
- ②
During times of rising uncertainty—such as policy shifts or geopolitical tensions—investor sentiment tends to weaken. This is reflected in a decline in SGAN, indicating a more cautious market outlook.
5.3. Predictability of SGAN in the American Stock Market
In order to briefly examine the dimensionality reduction effect of the GANs on various investor sentiment proxies in different market environments, we selected the five most representative sentiment proxies in the U.S. stock market for dimensionality reduction analysis. These five indicators are dividend premium (PDND), closed-end fund discount (CEFD), number of IPOs (NIPO), first-day returns on IPOs (RIPO), and equity share in new issues (S). They are all from the New York University Stern School of Business, while excess market returns (Rm) data are from the Tuck School of Business at Dartmouth. The period selected for this test is from November 2003 to November 2023.
Based on the similar methodology in
Section 4.1, our empirical analysis shows that investor sentiment has a significant positive impact on stock market returns.
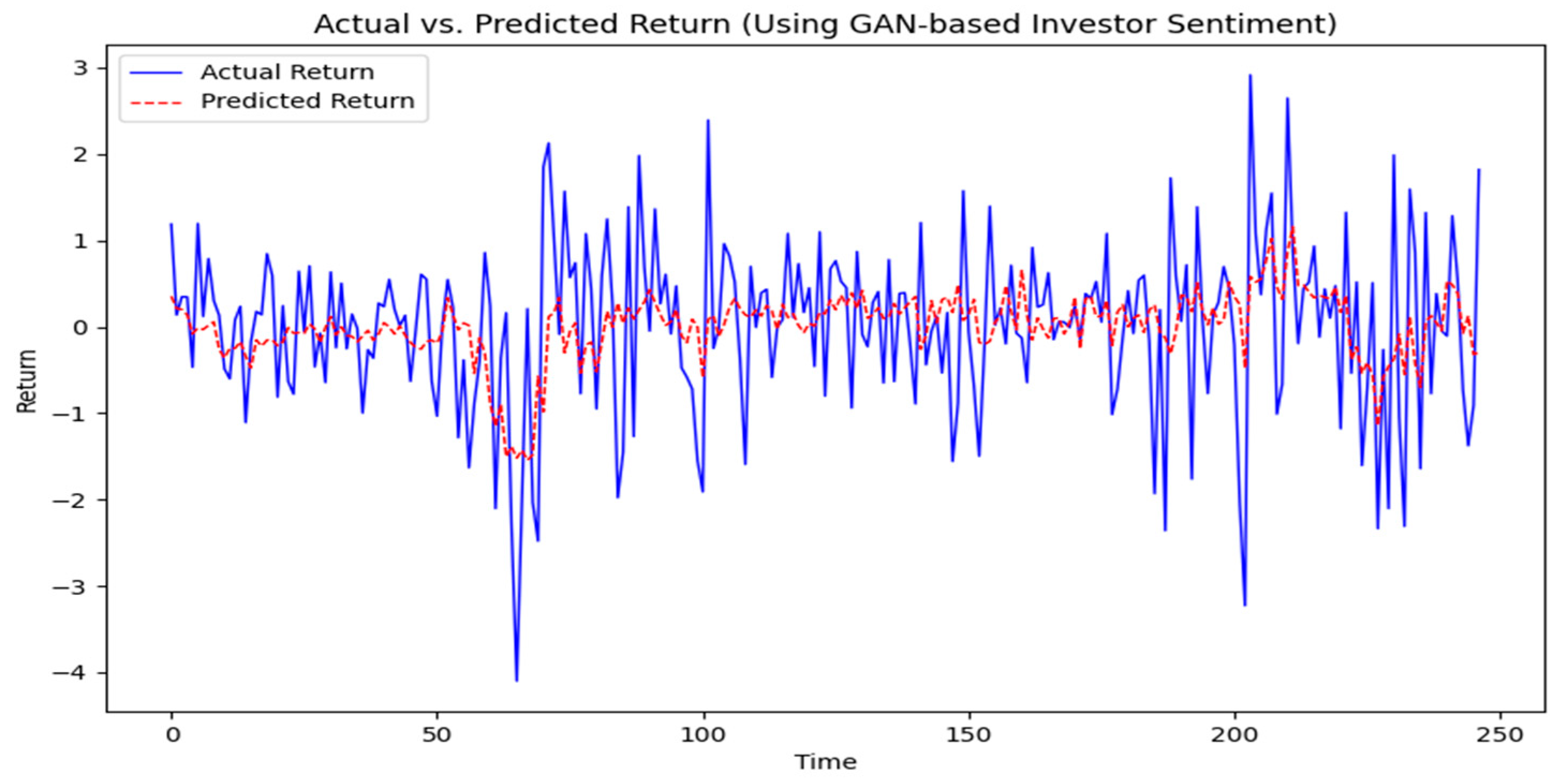
Figure 13 compares the predicted returns with actual returns. As can be seen from the figure, the overall trend of actual returns is closer to that of predicted returns, suggesting that the model has demonstrated some validity in capturing the overall direction and trend of market returns. In addition, the F-statistic of the regression analysis and its corresponding
p-value indicate that the overall model is highly significant, which further validates that the downgraded sentiment proxies are still effective in capturing the dynamic relationship of market returns. Moreover, we use the Diebold–Mariano test to assess the statistically significant differences in the forecasting models. The results show that
SGAN has a significantly superior forecasting accuracy with the DM statistic of 2.87, and the
p-value is less than 0.01. It confirms the robustness of our model’s predictive ability in different market environments. This formal statistical test provides an objective basis for this model. In other words, the investor sentiment extracted by the GAN method still represents excellent explanatory ability in the prediction of U.S. market returns.
5.4. Theoretical Basis and Mechanism Analysis of SGAN’s Superiority
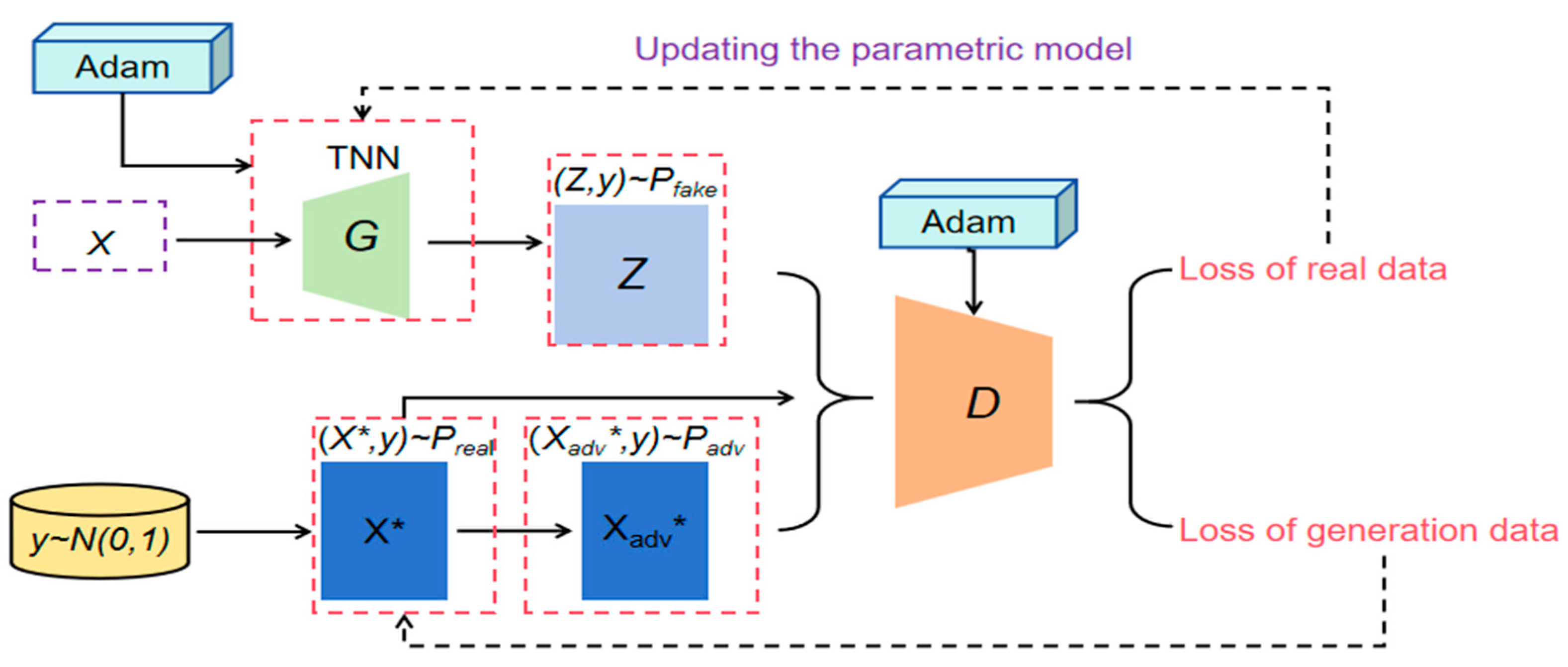
This section explores the intrinsic theoretical basis of the superiority of SGAN over traditional methods. The results of the empirical analyses show that SGAN significantly outperforms methods such as SPCA, SPLS, and SGA in predicting the excess returns of China’s A-share market, and this superiority stems from the following key mechanisms.
Firstly, the nonlinear feature extraction capability of GANs enables
SGAN to effectively capture the complex relationships among sentiment proxy variables. Financial markets are inherently nonlinear systems, and the relationship between investor sentiment and market behavior often exhibits complex nonlinear patterns. Traditional methods such as PCA and PLS are mainly based on linear assumptions, and it is difficult for them to capture this complexity. GANs, on the other hand, are able to automatically learn the nonlinear dependencies between sentiment agents through multilayer neural networks and adversarial training without the need to pre-specify the form of the parameters. The feature importance analysis in
Figure 9 confirms the more complex and balanced emotional structure captured by
SGAN.
Secondly, the adversarial training mechanism provides powerful noise filtering capabilities. Financial market data typically contain a large amount of noise that may interfere with the extraction of sentiment signals. The discriminator of SGAN effectively filters out extraneous noise by constantly challenging the generator and forcing it to extract the most informative sentiment factors. This mechanism is particularly important during periods of high market volatility, explaining why SGAN performed stably during the 2008 financial crisis and the 2015 market turmoil.
Thirdly,
SGAN’s adaptive feature weight assignment mechanism makes it highly sensitive to changes in the market environment. Unlike the static weights used by
SPCA and
SPLS,
SGAN is able to dynamically adjust feature weights according to the market environment. This feature is particularly critical for capturing rapid changes in investor sentiment, such as at bull–bear transition points, where
SGAN can quickly adjust the weights of liquidity indicators such as TURN and RV to more accurately predict market turns. This explains why
SGAN significantly outperforms other indicators during bear markets, as shown in
Table 10.
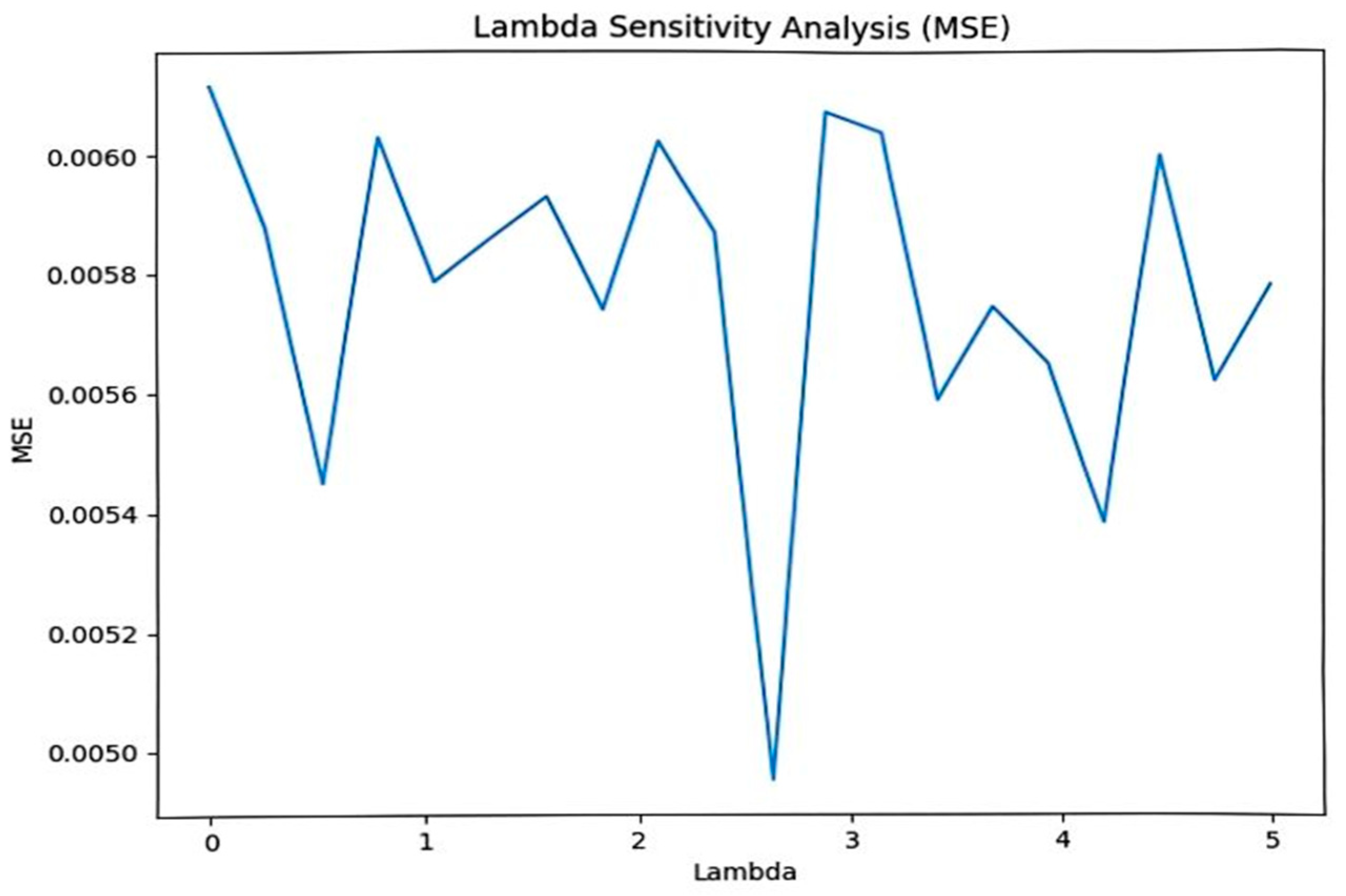
Finally, the integrated loss function we designed ensures that
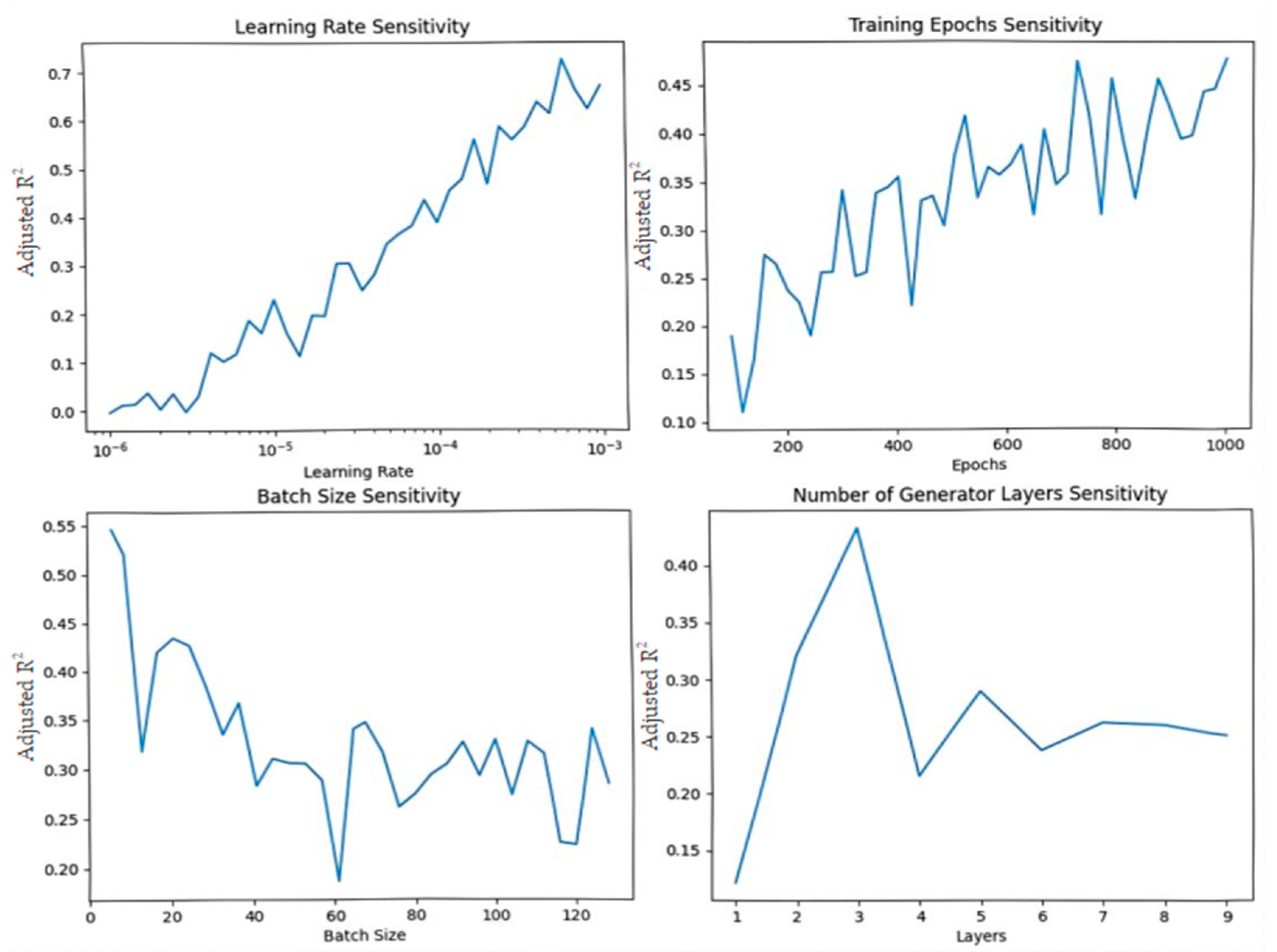
SGAN maintains economic explanatory power while preserving statistical significance. The λ-sensitivity analysis in
Figure 5 shows that this balance is critical to model performance. In addition, the model collapse prevention strategy we employ enhances the generalization ability of
SGAN to maintain stable performance under different market conditions.
In summary, the theoretical basis of SGAN’s superiority lies in its ability to capture complex nonlinear sentiment structures, filter market noise, dynamically adapt to changes in market environments, and strike a balance between statistical significance and economic explanatory power through the unique architecture of GANs. These properties make SGAN promising for a wide range of applications in asset pricing and market forecasting.
5.5. Computational Complexity and Limitations of Proposed Approach
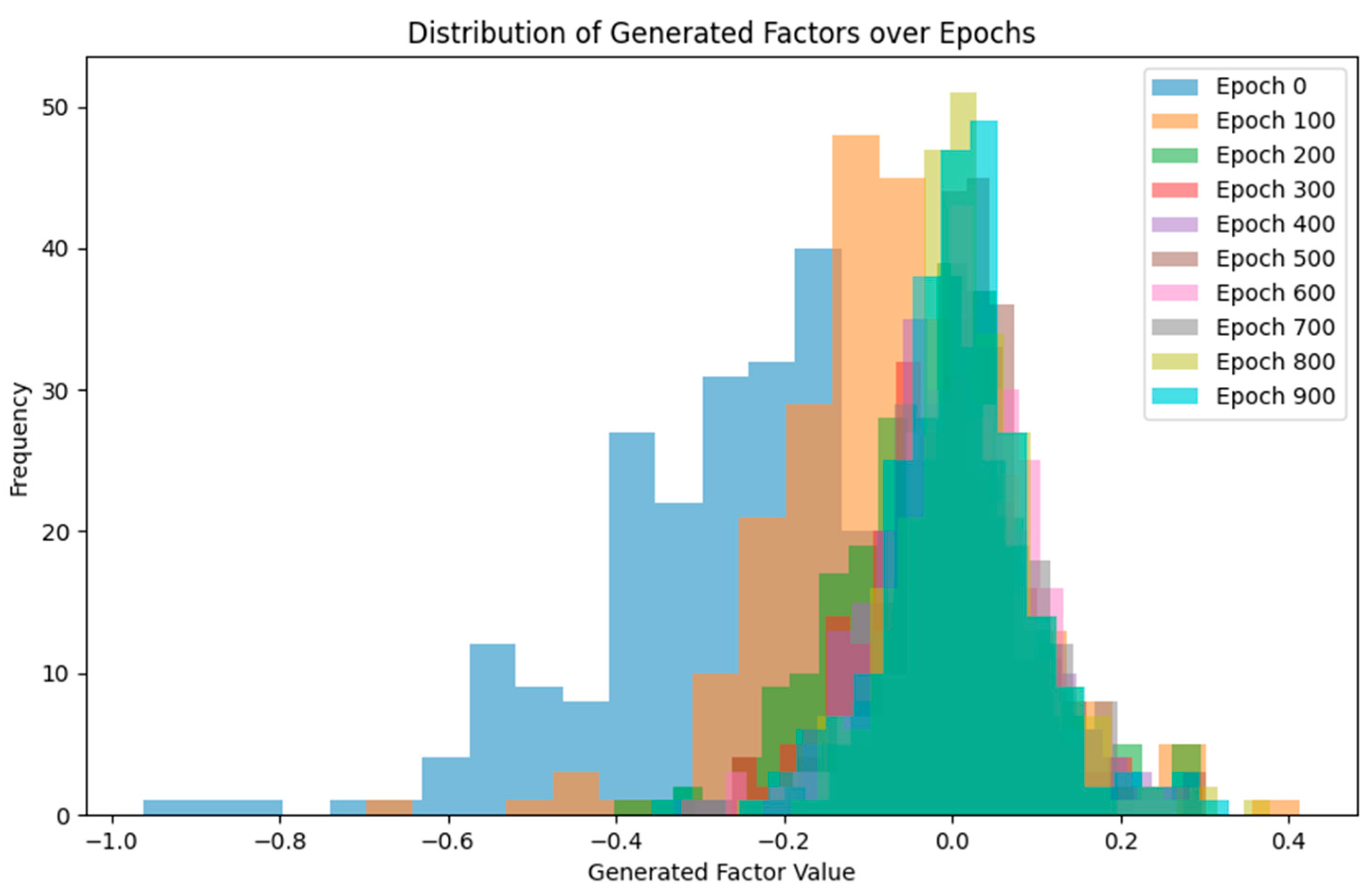
In this test, the GANs need to compute forward propagation and backpropagation once for both the generator and discriminator within each epoch. Assuming that the dimension of our input data is , and we have trained epochs, the total computational complexity of each epoch is , which is the computational complexity of each iteration in the training process. The total training time is 1.53 s. However, the GAN method in this experiment has some limitations. Firstly, the GANs in this study use a single potential dimension to represent investor sentiment. Nevertheless, financial market sentiment is complex, and multiple dimensions may be required to adequately describe investor mood swings and market psychology. If the potential dimension is too small, it may not capture all the useful sentiment signals; if it is too large, it may introduce noise or cause excessive model complexity. Second, for the agents that need to be downgraded in this study, we selected appropriate hyper-parameters to enable effective cooperation between the generator and the discriminator, so that better quality sentiment signals can be extracted. However, if this method is extended without improvement to deal with complex financial data problems, the gaming process between generators and discriminators may lead to unstable training, which makes the extracted correlation signals distorted. Meanwhile, GANs are highly prone to overfitting the training data when dealing with correlated data. Especially in financial data, the market data have strong time dependence and seasonal fluctuations, and overfitting may lead to an inconsistent performance of sentiment signals in different time periods. Finally, financial market sentiment is determined not only by factors such as historical prices and technical indicators, but is also influenced by external factors such as macroeconomics, policies, international events, and so on. The GAN model may not be able to adequately capture the impact of these factors on sentiment, resulting in the extracted sentiment signals failing to reflect the complete market psychology.
Regarding the applicability of SGAN in different trading frequency scenarios, although this study’s analyses are mainly based on monthly data, the method has flexibility and limitations in practical application. For high-frequency trading environments, SGAN faces two main challenges, which are computational latency and the high-frequency nature of emotional agents. The training process of GAN models is relatively time-consuming and is not suitable for real-time re-training in very high-frequency trading with millisecond decision requirements. However, the inference phase of the trained models is very efficient, which means that SGAN can be useful in low- to medium-frequency trading strategies, such as intraday trading and daily or weekly investment decisions. Hybrid strategies can be used in practical applications: for example, the model can be updated weekly using the latest data, while the prediction process can take place in real time. In addition, high-frequency application scenarios require the redesign of sentiment proxies to suit short-term market volatility, which may be an important direction for future research. Overall, SGAN is best suited for low- to medium-frequency trading strategies with daily to monthly time horizons and is able to effectively balance predictive performance and computational efficiency in these scenarios. For portfolio managers, SGAN can be used as an asset allocation decision tool to enable countercyclical investment strategies; market analysts can use it as a leading indicator of market turnaround, which performs particularly well in extreme market environments; and financial economists can use it to delve into the nonlinear relationship between sentiment and asset pricing.
6. Conclusions
Investor sentiment, a key behavioral indicator in the stock market, was constructed using various methods in prior research. This study introduces a novel investor sentiment, SGAN, developed using GANs. Leveraging GANs, we synthesized latent factors from eight sentiment indicators and assessed their predictive abilities for excess returns in the Chinese A-share market. The empirical results demonstrate that GAN-based investor sentiment outperforms traditional sentiment measures derived from PCA, PLS, and GA in both in-sample tests and out-of-sample tests. Meanwhile, SGAN remains statistically significant even after controlling for macroeconomic variables, indicating that it captures market-relevant information beyond economic fundamentals. Additionally, SGAN exhibits strong predictive power across various industries, with the financial sector showing the highest sensitivity to investor sentiment, aligning with prior research findings. Last but not least, its predictive ability remains robust across different economic periods and countries, further affirming its stability.
In summary, this study innovatively applies GANs to investor sentiment modeling, breaking through the limitations of traditional linear downscaling methods and providing a new research paradigm for financial behavior. The unique ability of GANs to capture the nonlinear features of sentiment time series provides a new perspective to understand how market sentiment drives price fluctuations, and this methodological innovation not only improves the prediction accuracy, but also provides a theoretical basis for constructing more effective investment strategies. Moreover, we find that the lagged effects and asymmetric responses of sentiment indicators play a crucial part in the performance of GAN models. GANs are able to capture these lagged sentiment fluctuations efficiently through adversarial training to improve the predictive power of sentiment indicators, and at the same time deal with such asymmetric effects efficiently, so that the sentiment indicators can accurately reflect the way the market responds to different changes in sentiment. This enables GANs to outperform traditional approaches to sentiment analysis, providing more stable and predictive sentiment signals across a wide range of economic conditions, thereby improving the accuracy of the predictions of future market returns. Future research could be directed toward a comprehensive empirical investigation to select additional sentiment proxies and apply a GAN to develop more robust investor sentiment indicators. Additionally, it is of interest to adopt increasingly advanced dimensionality reduction methods to explore a broader range of stock markets.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}