Credit rating is one of the earliest financial risk management tools, adopted by American retailers and mail-order companies as early as the 1950s. Credit rating is a process that uses statistical models to convert relevant data into numerical measures, aimed at assessing the credit risk level of borrowers. This numerical measure is typically used to guide credit decisions, helping financial institutions more accurately evaluate the creditworthiness of borrowers, thereby reducing risk, optimizing the asset–liability structure, and improving profitability.
2.1. Boosting Models
2.1.1. XGBoost Model
XGBoost is an efficient implementation of GBDT and an ensemble learning method. Based on GBDT, the algorithm introduces L1 and L2 regularization terms and supports parallel processing, thereby improving the model’s training speed and reducing the risk of overfitting. The overall approach is to iteratively increase the number of decision trees, gradually approaching the true values.
XGBoost is an additive model that sums over
base learners. The model after
iterations is expressed as Equation (1).
XGBoost adds the loss function and the regularization term to obtain the objective function, which is expressed as Equation (2).
In the equation,
represents the
-th sample in the overall dataset;
denotes the total number of samples used when training the
-th tree;
represents the total number of trees trained; the loss function
indicates the error between the true value and the predicted value of the
-th sample;
is the regularization term, which represents the complexity of the
trees, with smaller values indicating stronger model generalization. By performing a second-order Taylor expansion of the loss function, Equation (3) is obtained.
For computational convenience, define the variables
and
as given in Equations (4) and (5).
The objective function, after simplification, can be approximated by Equation (6).
When the objective function is defined by a decision tree, XGBoost maps a single sample to the leaf node of the tree structure, which leads to Equation (7).
The regularization term in the XGBoost objective function contains a vector composed of the number of leaf nodes of the decision tree and their corresponding weights. The complexity of the decision tree is determined by the number of leaf nodes,
. Therefore, the expression for the tree complexity,
, is given by Equation (8).
In the above equation,
and
are weight parameters that control the number of leaves, and
is the value of the
-th leaf node. By simplifying the loss function into the form of leaf nodes, Equation (9) can be obtained.
The transformation can be performed using Equation (10).
In the equation,
represents the sum of the first-order derivatives of the samples in the
-th leaf node, and
represents the sum of the second-order derivatives of the samples in the
-th leaf node. Therefore, the XGBoost objective function can be further simplified to Equation (11).
Using the formula for finding the extreme values of a quadratic equation, the value of
that minimizes the objective function is given by Equation (12).
The final loss function of the XGBoost model is given by Equation (13).
XGBoost, as a highly optimized gradient boosting framework, employs a sparsity-aware node splitting strategy and an approximate algorithm based on weighted quantile sketch, significantly improving memory efficiency and computational parallelism [
28]. It performs well on both classification and regression tasks, demonstrating strong predictive capabilities across numerous datasets. However, without appropriate regularization measures, it is prone to overfitting. Moreover, as a tree-based algorithm, XGBoost cannot directly process textual data and requires text to be encoded into numerical features before training.
XGBoost uses the Scikit-learn API for parameter tuning. In this manuscript, a grid search approach was employed to identify the optimal combination of model hyperparameters. The hyperparameter distribution ranges of XGBoost are determined based on model initialization configurations and empirical values established in prior research. After parameter optimization, the final parameter settings for the model are as follows: number of subtrees, n_estimators = 200; tree depth, max_depth = 5; minimum sample weight in the child nodes, min_child_weight = 1; training set proportion, subsample = 0.8; learning rate, learning_rate = 0.06.
2.1.2. LightBGM Model
LightGBM is an efficient gradient boosting framework developed by Microsoft Corporation, specifically designed for the fast processing of large-scale datasets. This framework is based on the GBDT algorithm and has been significantly optimized to address the performance bottlenecks of traditional GBDT when handling massive amounts of data. Specifically, LightGBM introduces innovative techniques such as the histogram-based decision tree algorithm, gradient-based one-side sampling, and exclusive feature bundling, which greatly enhance model training efficiency while maintaining high predictive accuracy. Its unique feature parallelism and data parallelism strategies allow the framework to perform excellently when processing high-dimensional sparse data, making it particularly suitable for large-scale machine learning tasks. Additionally, LightGBM supports various machine learning tasks, including multi-class classification, ranking, and regression, and has gained widespread application and recognition in both industry and academia.
The histogram algorithm is a computational method that optimizes decision tree training efficiency through feature discretization. Its core principle is to divide continuous feature values into several discrete intervals and quickly determine the optimal feature split points based on bucketed statistical information. Specifically, the algorithm first performs bucketing on each continuous feature, dividing the value range into intervals. Then, it traverses all samples, counting the sum of gradients, the sum of second-order derivatives, and the number of samples within each bucket, forming global or local statistical histograms. During decision tree node splitting, the algorithm does not need to traverse all original data points but directly uses the statistical differences between adjacent buckets in the histogram, such as information gain or mean squared error, to evaluate the quality of potential split points. This mechanism significantly reduces computational overhead, compresses memory usage through bucketing, and simultaneously introduces a certain regularization effect.
The core idea of gradient-based one-side sampling is to reduce the computational cost while preserving model accuracy through a gradient-sensitive data sampling strategy. Specifically, gradient-based one-side sampling is based on the following observation: during the gradient boosting process, samples with larger absolute gradients contribute more significantly to information gain, while low-gradient samples have a smaller impact on model updates. LightGBM achieves efficient sampling through the following steps.
Gradient sorting and sampling: The absolute gradients of all samples in the current model are sorted, retaining the top of high-information samples with the largest absolute gradients, while randomly selecting of the remaining low-gradient samples.
Weight compensation: To eliminate sampling bias, the gradient values of the randomly selected low-gradient samples are weight-compensated, i.e., their gradients are multiplied by a scaling factor when calculating information gain, in order to maintain the unbiasedness of the statistics.
The exclusive feature bundling algorithm aims to significantly improve model training efficiency through feature dimensionality reduction. Its core principle is based on the observation that many features in real-world scenarios are mutually exclusive, and these features can be combined into a single composite feature without resulting in loss. The basic idea of the algorithm is to group features with certain correlations into exclusive feature bundles and replace the original features with these bundled feature sets. These bundles are mutually exclusive, i.e., any given sample can belong to only one bundle, thereby reducing the model’s complexity and the amount of feature computation required. The specific implementation process is as follows.
Step 1: Compute the pairwise correlations among all features and perform clustering based on feature similarity to group highly correlated features into the same package.
Step 2: For each feature package, select a representative feature, calculate the inter-feature correlation coefficients or mutual information, and determine the optimal threshold for fusing features within that package.
Step 3: Compare each feature package against the others and conduct a final selection by computing a score for each package, retaining the package with the highest score.
Step 4: Generate new features based on the selected feature packages, replacing the original features with these packages.
LightGBM exhibits significant advantages in efficiency and scalability by employing histogram-based algorithms and leaf-wise growth strategies, which substantially reduce memory consumption and computational costs while maintaining competitive accuracy. Its support for parallel computing, categorical feature handling, and gradient-based sampling further enhance performance in large-scale datasets. However, the algorithm’s potential overfitting on noisy datasets, and precision loss from feature discretization, represent notable limitations [
29]. These characteristics necessitate careful regularization and parameter optimization in practical implementations.
LightGBM uses the Scikit-learn API for parameter tuning. In this manuscript, a grid search approach was employed to identify the optimal combination of model hyperparameters. The hyperparameter distribution ranges of LightBGM are determined based on model initialization configurations and empirical values established in prior research. After parameter optimization, the final parameter settings for the model are as follows: number of subtrees, n_estimators = 200; tree depth, max_depth = 8; minimum sample weight in the child nodes, min_child_weight = 8.5; number of leaves, num_leaves = 235; learning rate, learning_rate = 0.06; L1 regularization coefficient, reg_alpha = 0.5; L2 regularization coefficient, reg_lambda = 5.72.
2.1.3. CatBoost Model
CatBoost is an ensemble learning algorithm that is designed to efficiently handle categorical features and reduce the risk of overfitting. Through innovative feature encoding strategies, an ordered gradient boosting mechanism, and a symmetric tree structure design, CatBoost significantly improves model performance and training efficiency in heterogeneous data scenarios. It has now become one of the benchmark tools in high-dimensional sparse data fields such as financial risk control and recommendation systems.
CatBoost proposes an innovative categorical feature encoding framework that combines adaptive target statistics with Bayesian prior regularization to achieve automated high-precision mapping of categorical variables to numerical variables. Compared to traditional methods that rely on manual encoding, this framework constructs categorical features based on Equation (14).
is the smoothing coefficient, is the global target mean, and is the indicator function. This equation effectively alleviates the overfitting issue in low-frequency categories caused by insufficient samples in Greedy Target-based Statistics by introducing a Dirichlet prior distribution.
In the GBDT framework, the autocorrelation of training data can lead to Gradient Estimation Bias, which in turn causes the Prediction Shift problem. To obtain an unbiased gradient estimate, CatBoost trains a separate model for each sample using data that excludes the sample itself. This model is then used to estimate the gradient for the sample, and the estimated gradient is employed to train the base learner to obtain the final model. However, the implementation of this approach in the context of ranking-based boosting requires training different models, which significantly increases memory consumption and computational complexity, rendering it impractical for real-world applications. To address this, CatBoost introduces further optimizations during the tree construction phase through two boosting modes: Ordered and Plain, enhancing the efficiency of the Ordered Boosting algorithm.
CatBoost and LightGBM are both gradient boosting algorithms and offer greater flexibility compared to random forest. However, CatBoost demonstrates superior performance in handling categorical variables [
30]. While both algorithms are suitable for large-scale and high-dimensional datasets, CatBoost excels in dealing with categorical features and missing values, whereas LightGBM offers advantages in terms of speed and accuracy.
CatBoost uses the Scikit-learn API for parameter tuning. In this manuscript, a grid search approach was employed to identify the optimal combination of model hyperparameters. The hyperparameter distribution ranges of CatBoost are determined based on model initialization configurations and empirical values established in prior research. After parameter optimization, the final parameter settings for the model are as follows: number of iterations, iterations = 300; tree depth, max_depth = 5; maximum size for One Hot encoding, one_hot_max_size = 1; learning rate, learning_rate = 0.04; L2 regularization coefficient, l2_leaf_reg = 3.
2.2. TabNet Model
The TabNet model, proposed by Google Cloud AI in 2021, is the first self-supervised deep learning model for tabular data. The model fully incorporates the advantages of existing tree models and DNN models, integrating the ideas of both to achieve excellent model performance and interpretability. TabNet can directly input raw tabular features without any feature preprocessing, which is not possible with tree models. Additionally, it is trained using gradient descent to achieve end-to-end learning. Therefore, this manuscript chooses to use TabNet as the initial model for training.
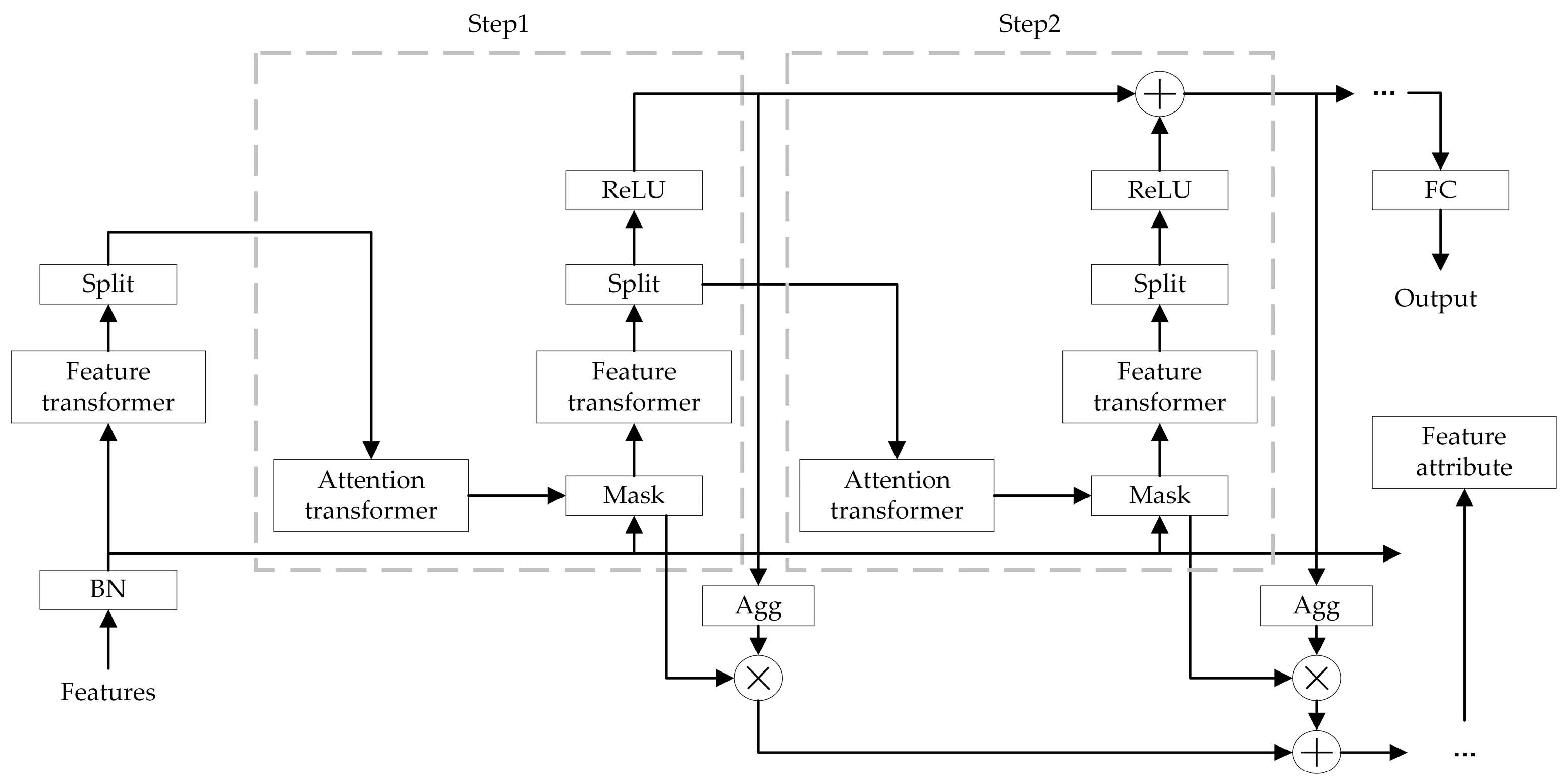
The core principle of TabNet is based on a collaborative mechanism of multi-step feature selection and information aggregation. The model generates sparse feature masks at each decision step using attention transformers, dynamically selecting important subsets of features, and encodes the selected features into higher-order representations using feature transformers. These representations are progressively merged through residual connections to form global feature interaction information. Finally, the model outputs the decision results through a Softmax function. A significant advantage of TabNet is its interpretability, as the feature selection process provides a clear weight distribution, making it easier to understand the model’s decision-making basis. Furthermore, its computational complexity is low, making it suitable for large-scale tabular data scenarios. The TabNet network structure is shown in
Figure 1.
TabNet is an overall summation model, where the original feature vector
is input into the Batch Normalization layer for normalization. The data then pass through the Feature Transformer layer for feature computation. The specific structure of the Feature Transformer is shown in
Figure 2.
To improve model parameter utilization and stability, the Feature Transformer layer integrates parameter-sharing layers and parameter-independent layers. The former computes feature commonality, while the latter computes feature specificity. The Feature Transformer layer combines two parameter-sharing layers and two parameter-independent layers. Each layer consists of a fully connected layer, a BN layer, and a gated linear unit layer, concatenated together. Residual connections between layers are achieved by multiplying by , ensuring that the network does not experience drastic changes during training, thereby enhancing the model’s robustness.
After the data are output from the Feature Transformer layer, they are transformed into features and input into the Splitting module. In the Splitting module, the features are divided into two parts: one part undergoes the current computation, and the other part is input into the next layer for Mask computation. After passing through the Split module, the data enter the Attention Transformer layer, whose internal structure is shown in
Figure 3.
The Sparsemax layer is a sparse version of Softmax, enhancing the feature selection ability of Softmax. Unlike Softmax’s smooth transformation, Sparsemax projects the vector onto a simplex to achieve sparsity, with the calculation formula given by
. This approach helps eliminate the impact of less relevant features. The feature selection process of TabNet primarily involves learning a Mask at each step to achieve feature selection for the current decision step. The selection of features is achieved through the Attention Transformer at that decision step, and the formula for learning the Mask in the Attention Transformer is provided in Equation (15).
Here, represents the step, is the feature vector after the Split operation in the previous step, represents the FC + BN layer, and is the prior scale term from the previous step, with the specific expression given by , which indicates the degree of usage of a feature in the previous step. The model uses the prior scale term to control the feature usage across steps. Additionally, is the sparse regularization weight, which imposes a constraint on the feature sparsity during the feature selection phase. When , each feature can only be used once; when , each feature can participate in subsequent steps of training. The selected features are obtained by multiplying element-wise with the feature elements, which achieves feature selection for the current decision step.
These processed features are then fed into the Feature transformer of the current decision step, subsequently initiating a new cycle of decision step iterations. The masked features are processed by the Feature Transformer, where the transformed features are partitioned into two components: one serves as input for the current decision step, while the other propagates to the subsequent decision step. The Feature Transformer consists of two distinct modules. The front module employs shared parameters trained across all decision steps to capture feature commonalities, thereby reducing parameter updates and enhancing robustness. In contrast, the latter module utilizes step-specific parameters that are independently trained for each decision step to extract step-unique feature representations. This design enables differentiated feature processing capabilities across steps while leveraging shared feature inputs. Specifically, shared layers first compute generic feature transformations, followed by step-specific layers tailored to individual decision contexts. Additionally, residual connections with a scaling factor of are incorporated to mitigate variance fluctuations during training, ensuring stability.
Notably, the Mask layer selectively filters features without modifying retained ones, preserving their original representations. The Mask matrix obtained from the feature masking layer has dimensions of
. Based on the property
of Sparsemax, the attention weight allocation for each batch sample in a given step corresponds to the current step. Furthermore, the attention weights output by the feature transformation layer vary across different samples, which demonstrates the powerful instance-wise feature selection capability of this neural network architecture. To enhance the model’s sparse feature selection ability, a regularization term is introduced, with its mathematical formulation provided in Equation (16).
represents the number of steps, is the batch size, and is the feature dimension. is a small decimal value that is primarily used to stabilize the overall value. This regularization term computes the average entropy, aiming to make the distribution of as close as possible to 0 or 1. reflects the sparsity of ; the smaller is, the sparser becomes. Finally, will be added to the total loss function.
In TabNet, the feature vector
at the
-th step is transformed by the feature transformer layer to produce
. The final output of the TabNet model is the sum of the results from all steps. Meanwhile,
has no contribution to the overall model output. The contribution of feature
at the
step is expressed as Equation (17).
A larger value of
indicates a higher contribution of the feature to the model’s feature selection process. Consequently,
can serve as the weight of feature
at the
-th step, enabling weighted masking for the corresponding step. The weight parameters within the Mask explicitly reflect feature importance, thereby allowing the definition of feature-wise importance in the feature vector
as formalized in Equation (18).
After normalization, it is given by Equation (19).
After the feature extraction of all steps is completed, TabNet transforms the outputs of the feature transformer layers of each step using the ReLU activation function. When passing through a specific FC layer followed by ReLU activation, the threshold-based decision mechanism ensures that only one element in the output vector remains positive while all others are zero. This mimics the conditional splits in decision trees. Subsequently, the results from all conditional judgments are aggregated, and the summation is processed through a Softmax layer to generate the final output. Notably, the output requires ReLU activation before integrating multi-step intermediate results. The ultimate output is derived by summing these activated values across multiple steps and projecting them through a final FC mapping layer. The results from all steps are then summed and passed through a fully connected layer to obtain the final output, which represents the predicted class of TabNet.
The feature importance layer serves to capture the global importance of the model’s input features. The model first sums the input vector of a step to obtain a scalar, which reflects the importance of that step for the final result. By multiplying with the Mask matrix, the importance of each feature in that step is reflected. The results of all steps are summed to determine the global importance of the model’s input features.
2.3. Stacking Ensemble Learning
In the field of ensemble learning, the primary methods are Bagging, Boosting and Stacking. These techniques aim to improve model performance by combining multiple base learners. Stacking can integrate heterogeneous base models, such as decision trees, neural networks, and linear models, by employing a meta-model to learn the complementary relationships among them. In contrast, Bagging and Boosting typically rely on homogeneous base models, often utilizing a single type of decision tree. This heterogeneity in Stacking enables the capture of more complex feature interactions within the data. Moreover, in the context of TabNet, Bagging’s effectiveness in reducing variance is limited, and Boosting’s sequential adjustment of sample weights may disrupt TabNet’s attention-based feature selection mechanism, potentially leading to unstable training [
31]. Therefore, this manuscript adopts the Stacking ensemble learning approach for model integration.
Stacking, also known as stacked generalization, is a method that involves training multiple heterogeneous learners on the original data, then combining the predictions of the base learners to create a new training set, which is subsequently used to train a new learner [
32]. The motivation behind this approach is that if a base learner erroneously learns a particular region of the feature space, the meta-learner can appropriately correct this error by combining the learning behaviors of the other base learners. Stacking employs a layered approach that typically involves at least two levels [
33]. The first level consists of multiple base learners that operate in parallel to process the original data. The second level comprises a meta-learner, which integrates the predictions from the base learners in the first level to make the final decision. This strategy can be viewed as a combination of parallel and sequential processing, effectively leveraging the strengths of different models. The basic structure of this method is shown in
Figure 4.
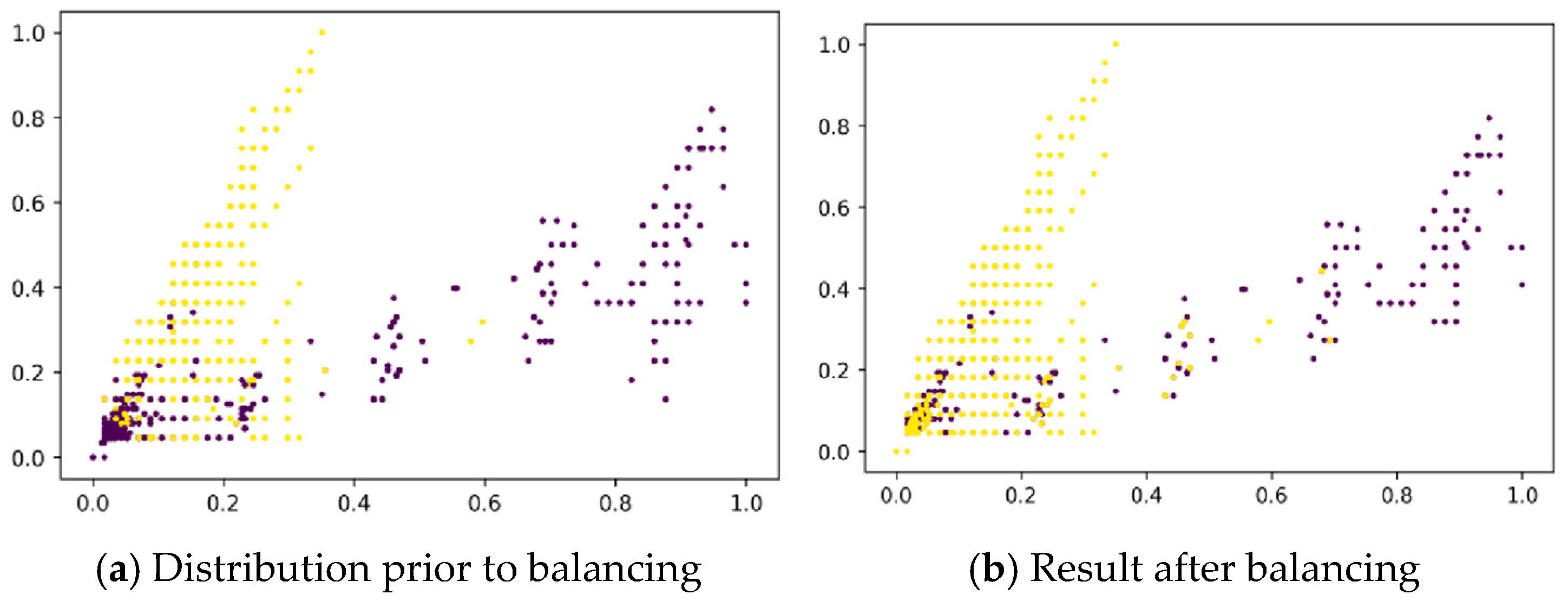
Although Stacking significantly improves model performance by integrating multiple base learners, its traditional implementation carries a risk of overfitting. Specifically, base learners are typically trained on the entire training set, and then the same dataset is used to generate meta-features. This data leakage can lead to overfitting of the meta-learner to the training set, thus reducing the model’s generalization ability. To address this issue, CV (cross-validation) is widely employed in practice. Under the CV framework, the training set is divided into multiple mutually exclusive subsets, with base learners generating predictions on each fold’s validation set, and the meta-features are constructed by concatenating these predictions. This mechanism not only effectively avoids data leakage but also ensures the statistical unbiasedness of the meta-features through stratified sampling. Moreover, by comparing the model’s performance across different cross-validation folds, one can assess its variability on independent datasets, which aids in detecting overfitting. If a model exhibits strong performance on the training set but underperforms on the test set, this typically indicates overfitting.
Assuming five-fold cross-validation, the working principle of Stacking is as follows.
Step 1: Divide the training set into five parts, with each one representing a fold.
Step 2: Use four folds as the training set and the one remaining fold as the validation set, applying multiple base models to train on the training set.
Step 3: For each base model , make predictions on the validation set with the trained model, obtaining the prediction results for that fold, and predictions on the test set.
Step 4: Repeat Step 2–3 until all folds have been used as the validation set.
Step 5: Concatenate the prediction results of all folds on the validation set to form the overall , which is used as the new training set, while the average of all test set predictions gives .
Step 6: Merge the obtained from each base model to generate a new training set (Train2), and merge to generate a new test set (Test 2).
Step 7: Train the second-level model and make predictions on Test 2 to obtain the final prediction values.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}