Abstract
In this paper, we address the challenge of dynamic evolution of user preferences and propose an attribute-sequence-based recommendation model to improve the accuracy and interpretability of recommendation systems. Traditional approaches usually rely on item sequences to model user behavior, but ignore the potential value of attributes shared among different items for preference characterization. To this end, this paper innovatively replaces items in user interaction sequences with attributes, constructs attribute sequences to capture fine-grained preference changes, and reinforces the prioritization of current interests by maintaining the latest state of attributes. Meanwhile, the item–attribute relationship is modeled using LightGCN and a variant of GAT, fusing multi-level features using gated attention mechanism, and introducing rotary encoding to enhance the flexibility of sequence modeling. Experiments on four real datasets (Beauty, Video Games, Men, and Fashion) showed that the model in this paper significantly outperformed the benchmark model in both NDCG@10 and Hit Ratio@10 metrics, with a highest improvement of 6.435% and 3.613%, respectively. The ablation experiments further validated the key role of attribute aggregation and sequence modeling in capturing user preference dynamics. This work provides a new concept for recommender systems that balances fine-grained preference evolution with efficient sequence modeling.
MSC:
68T07
1. Introduction
Recommender systems aim to present users with candidate items that align with their preferences, derived from their historical interactions. Significant efforts have been invested to enhance performance through various approaches. Conventionally, recommendation algorithms concentrate on calculating similarities between users and items [1,2,3], primarily employing collaborative filtering techniques. This method is founded on the assumption that users with similar tastes will likely favor similar items. With the evolution of deep learning, neural-network-based approaches have surpassed traditional methods in terms of their ability to more effectively represent complex user–item relationships. However, user preferences are not static; they evolve over time. The static user embeddings that these models initially learn fail to capture the dynamic nature of user demands. As user preferences change, recommender systems need to adapt to these changes to continue delivering relevant suggestions that resonate with the user’s current preferences. Sequential recommendation systems [4,5,6,7] (SRS) have thrived in the field of recommendation systems over the past few years to solve this problem, primarily because these systems are predominantly based on users’ past behavior and are prevalent in nearly all e-commerce, social media, and streaming platforms. Sequential recommendation systems process a user’s history of interactions into a time-ordered sequence that reflects the evolution of their preferences. Initially, research in this area primarily utilized Markov chains, which posited that each interaction is dependent on the preceding one. More recent approaches, such as those using recurrent neural networks [8] and self-attention mechanisms [9], have shifted focus towards enhancing information propagation within sequences and modeling relationships between items, yielding notable improvements. However, existing approaches often treat items as the fundamental units that reflect user preferences, without considering the attributes of these items, and they fail to explore the underlying reasons behind each interaction. We contend that users consistently focus on specific attributes during their interactions; different users have preferences for varying attributes, and even the same user preferences for attributes can change over time, resulting in a shift in their interaction patterns with items. By identifying the attributes of items that users genuinely care about and directly generating preferences based on these attributes, we can achieve a more granular representation of both items and their attributes, thereby enhancing model performance. Even some of the sequential recommendation models [10] that utilize item attributes for recommendation are inclined to use item attribute information as auxiliary information for learning item changes, and do not delve into the deeper reasons for the changes in the items that users have interacted with. In contrast, we attempt to identify key item attributes as the primary unit for detailed extraction of user preferences. To enhance the accuracy of capturing user preferences, this paper introduces a novel methodology that substitutes items with attributes, thereby constructing an attribute sequence for each item sequence. It is crucial to acknowledge that different items may share identical attributes, indicating that these attribute sequences should represent the progression and evolution of user preferences over time. An effective solution to address this issue is to maintain the most recent state of each attribute within the sequence. This approach not only simplifies representation but also ensures that the most relevant and current user preferences are given priority. By shifting the focus from items to attributes, our method offers a more dynamic insight into user behavior, capturing subtle shifts in preferences that might go unnoticed by conventional item-based sequence recommendation systems. This strategy further enhances the generalization ability and capability of the model to anticipate changes in user interests, thus improving the precision and relevance of recommendations. Additionally, this paper advances the encoding of attention networks by introducing new codes aimed at enhancing experimental metrics and stabilizing the model in the face of data sparsity. The main contributions of the paper are as follows:
- The paper constructs item–attribute interaction graphs to model correlations between attributes and attribute change sequences, to model user preferences for attributes.
- The paper proposes new encoding methods for attention networks, to improve experimental metrics and model stability.
- The paper conducted experiments on four real datasets, and the experimental results show that our proposed model outperformed the state-of-the-art baseline models.
2. Related Work
2.1. Sequential Recommendation
In comparison with traditional recommendation methods, sequential recommendation systems yield more accurate predictions by modeling the dependencies among items within interaction sequences. This capability allows them to capture the dynamic preferences of users. An archetypal solution in early sequential recommendation research involved the use of Markov-Chain-based models [11], which model the transition of information within the sequence to predict the subsequent item. Rendle and colleagues introduced personalized Markov chains that utilize transition matrices constructed from user consumption sequences to capture both long-term and short-term user preferences. However, a significant drawback of Markov-chain-based methods is that the current interaction depends on only one or a few recent interactions, thereby capturing only short-term dependencies, while overlooking long-term relationships. With the advancement of deep learning, Recurrent Neural Networks (RNNs) and its variants, such as Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRUs), have been introduced into sequential recommendation.
Zhang modeled user click sequences using RNNs [12], enhancing prediction accuracy by incorporating sequential dependencies. GRU4Rec [8] was among the first to employ GRUs for modeling entire sessions, achieving more precise recommendations. To effectively capture user sequential behavior and primary intent, NARM [13] incorporated an attention mechanism within an RNN framework. Although these RNN-based methods demonstrated satisfactory performance, they still faced challenges such as difficulties in parallelization and learning long-term dependencies. To address these issues, inspired by the Transformer model [14], SASRec [6] captures inter-item correlations through stacking self-attention layers, eliminating the need for recurrent or convolutional networks. Recently, some researchers have focused on modeling interaction times within sequences. To underline the impact of time intervals on recommendation outcomes, TiSASRec [15] includes relative time intervals and positional information within item embeddings. Chorus [16] designed two distinct normal distribution temporal kernels for “complementary” and “substitute” relationships, to explicitly model the evolution of user preferences over time. GDERec [17] constructs a user project interaction graph and captures the continuous time dynamics of user preferences using regular differential equations.
2.2. Attribute-Aware Recommendation
Attributes are ubiquitously available and provide essential descriptions of items, leading to the development of numerous attribute-based recommendation methods. Early approaches utilized models based on Factorization Machines [2] to model high-order interactions among attributes. Pasricha and McAuley presented TransFM [18], which substitutes the inner product typically used in sequential recommendations with squared Euclidean distance, enhancing the model’s generalizability and transferability among sample features. He and Chua introduced NFM [19], employing neural networks to learn informative feature combinations, thus enhancing the capacity for multi-order interaction among features.
Recent works [20,21] have embedded attribute information into feature vectors and concatenated them for recommendation purposes. Cheng introduced the Wide&Deep model [22], which combines deep neural networks with linear models for recommendation. In this model, the deep component employs a multi-layer perceptron to connect feature embedding vectors for learning feature interactions. Li proposed a Deep Heterogeneous Autoencoder (DHA) [23] model that integrates attribute information into a shared feature space, achieving improved predictive outcomes. Su and colleagues developed a multi-matrix factorization approach, named MMF [24], which leverages common attributes across different items to achieve state-of-the-art prediction accuracy. Lv introduced a Sequential Deep Matching [25] (SDM) model that captures short-term preferences using a multi-head attention mechanism; long-term preferences are captured by categorizing the attributes of all items in a user’s long-term behavior sequence, which are then modeled by an attention mechanism. Zhang proposed FDSA [26], a feature-level deep self-attention network for sequential recommendations that employs distinct self-attention blocks for item-level sequences and feature-level sequences, modeling item transition patterns and feature transition patterns separately. One of the SOTA models CARCA [27] uses a multi-layer multi-head self-attention module to extract user features contained in the user’s historical behavior, and also utilizes a cross-attention module to fuse the target item and the user’s features.
3. Problem Formulation
Let denote the set of n users, and denote the set of m items. The interaction history of user is denoted by in chronological order, where represents the total number of interactions in this sequence of user u. Each item in the interaction sequence is associated with multiple attributes, such as category, brand, and time of interaction. These attributes are collectively represented by , where k denotes the total number of distinct item attributes.
The primary objective of sequential recommendation systems is to accurately predict the next item with which the user u is most likely to engage. This prediction is based upon the historical sequence of item interactions by the user u, and the attributes associated with each item in the sequence. By analyzing the patterns within and considering the characteristics specified in , the system aims to enhance the precision of its recommendation for the subsequent interaction.
4. Proposed Model
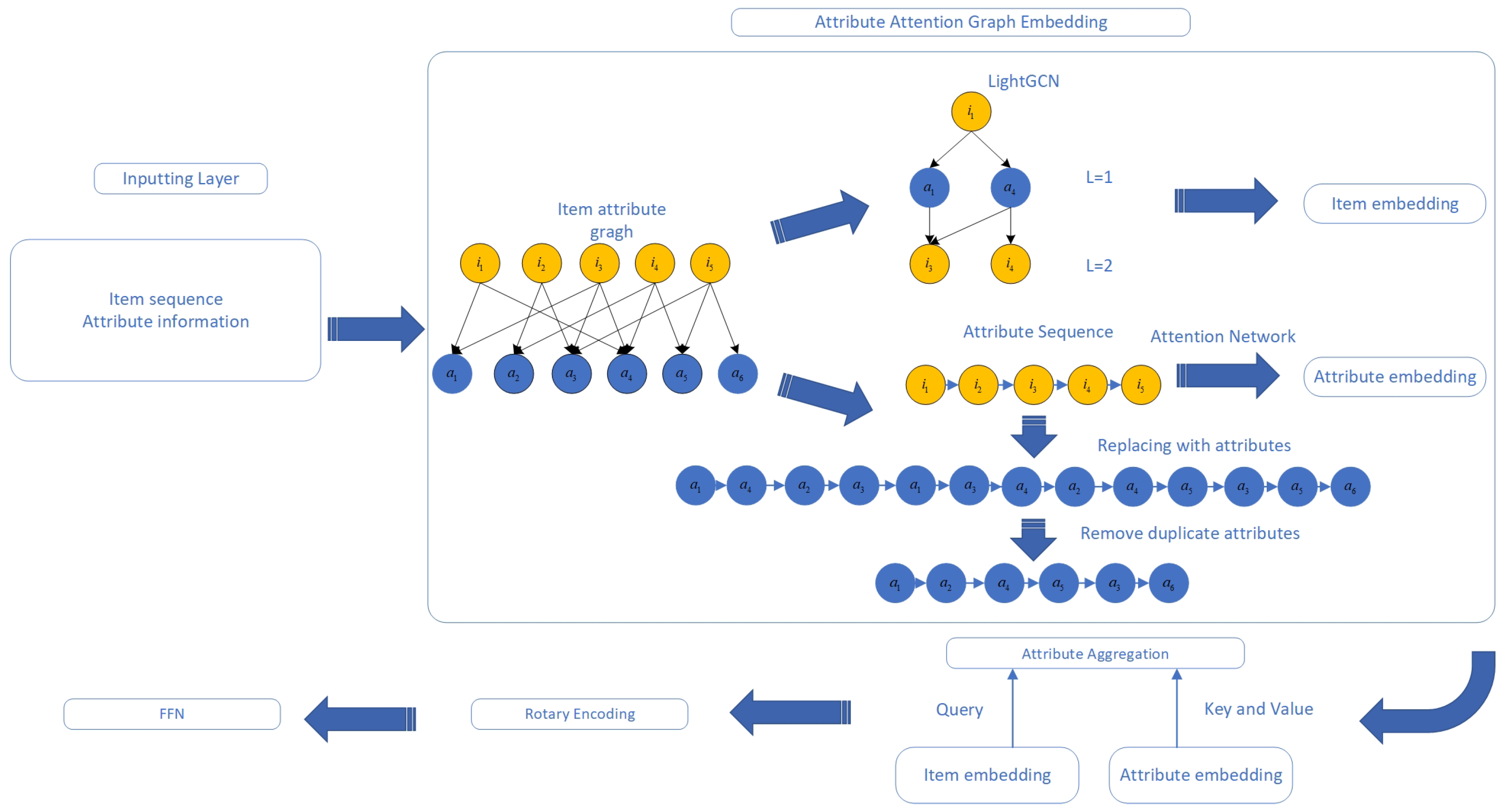
An overview of our proposed framework is shown in Figure 1. It consists of four main components: (1) Inputting layer: inputting item sequences, as well as item attribute information. (2) Attribute Attention Graph Embedding, which includes the generation of attribute sequences for the graph convolutional network of items, as well as the attention network of attribute sequences. (3) Attribute Aggregation: aggregation of items and attribute embeddings directly extracted at different granularities through the attention mechanism. The item-level embeddings are used as a query to aggregate multi-class embeddings into a single representation. (4) Rotary Encoding: rotationally transforming the fused embeddings to capture the relative positional relationships in the sequence. (5) FFN: outputting scores and making recommendations.
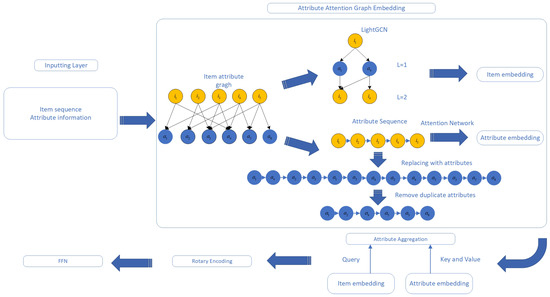
Figure 1.
Overview of the proposed framework.
Next, we describe each component in detail.
4.1. Attribute Attention Graph Embedding
In an effort to more precisely capture user interests, this paper suggests a novel approach where items are replaced by their attributes, facilitating the construction of an attribute sequence for every item sequence. It is important to recognize that different items might possess the same attributes, indicating that these attribute sequences ought to reflect the progression and evolution of user interests over time.
An intuitive method to address this is to maintain the most recent version of each attribute within the sequence. Doing so not only simplifies the representation but also ensures that the most relevant and recent user preferences are prioritized. By focusing on attributes rather than items, our approach allows for a more dynamic understanding of user behavior, capturing subtle shifts in preferences that might not be immediately apparent through traditional item-based tracking. Additionally, this strategy enhances the model’s ability to adapt to and predict changes in user interests, thereby improving the accuracy and relevancy of our recommendations.
First, based on the attribute information of each item, an item–attribute graph can be constructed as follows:
where denotes the node set, including all items and their attributes, denotes the edge set and contains the attribute . Then, we use GNN to model the connectivity of attribute graphs with multi-hop aggregation. Here, we adopt LightGCN [28], a classic GNN-based CF method, to model the item–attribute relationships:
where represent the corresponding embeddings of the item i and the attribute a in the l-th layer, respectively; L is the number of aggregation layers; d is the dimension of embeddings; represents all the items that have the attributes a; and represents all the attributes of the item i.
In addition, we construct a sequence of attribute changes based on the user’s sequence of item interactions, using certain mapping rules to reflect the user’s preference for attributes over time. The attribute change sequence construction rule is as follows: replace each item of the item sequence with the attribute it has, to form an attribute sequence in which only the last of the duplicated attributes is retained, and all the rest of the duplicated attributes are deleted to form a new attribute sequence. This sequence is the generated attribute change sequence [29].
Specifically, based on the previously defined item–attribute graph, we can we can determine the exact location of each attribute in the item sequence:
where the function denotes the original position of item . The corresponding attribute sequence is obtained by sorting the locations and filtering out attributes with fewer connections, where is a hyperparameter that denotes the maximum length of the attribute sequence.
Based on the obtained attribute changing sequence, in order to build a bridge between the interests extracted from the attributes and the items to be predicted, we deploy attribute-based aggregation using a variant of GAT. Considering an attribute in the sequence of attributes , we use all the attributes in the sequence to update the features for , and each attribute in the sequence is computed with the to compute the normalized attention value and aggregated:
where denotes the embedding of .
4.2. Attribute Aggregation
We have now derived the augmented embeddings for both items and attributes, along with the sequence of changes in these items and attributes. These embeddings are designed to represent user preferences at two levels: basic embeddings at the item level, and more detailed, fine-grained embeddings at the attribute level. Each type of embedding captures different facets of user preferences. By employing an attention mechanism, we aggregate these multiple embeddings into a final item representation. Specifically, this involves calculating the similarity between the item-level embeddings and the various attribute-level embeddings. Based on these similarity scores, we compute a weighted sum of the attribute-level interests to form the final representation. In this attention mechanism, the item-level embeddings serve as the query, while the attribute-level interests are used as both keys and values:
where and are the final embeddings formed by the item and attribute aggregated embeddings through the fully connected layer, respectively.
4.3. Rotary Encoding
The final embedding is encoded next, and unlike most methods that use a self-attentive approach, the paper uses rotational coding to encode the fused embedding. Rotational coding [30] focuses on representing positions in a fixed coordinate system or relative to other items in the sequence, utilizing rotational transformations to encode positional information.
The orientation or rotation of the positional embedding can provide valuable information about the relationships between props in the sequence. This approach is particularly suitable for scenarios where the inherent order or arrangement of items is not straightforward, and can benefit from more flexible representations, such as a user searching for multiple items in the same session. These embeddings capture the linear order and rotational relationships in sequences. Rotational positional encoding applies rotations to the query and key-value matrices, which preserves the dot product between vectors.
Absolute or relative positional encoding focuses on representing positions within a fixed coordinate system or relative to other items in a sequence. Conversely, rotational encoding operates differently by utilizing rotational transformations to encode positional information. Rotational positional encoding, often referred to as ‘Rope’, represents a specific technique used within position encoding. The underlying motivation for ‘Rope’ is that the orientation or rotation of positional embeddings can provide valuable information about the relationships between items in a sequence. This approach is particularly beneficial in scenarios where the inherent order or arrangement of items is not straightforward and could benefit from a more flexible representation, such as a user’s search behavior within the same session [31]. These embeddings capture both the linear order and rotational relationships within the sequence. Rotational positional encoding involves rotating the query and key matrices, thereby preserving the dot product between vectors. In a two-dimensional setup, for a given input vector x and a specified angle , the encoding function f is defined as follows:
where denotes the rotation matrix parameterized by the angle, denoted by the sine and cosine, and is the key value or query. More explicitly, for the case of key values K, we have
where and denote the components of in Equation (6) in two-dimensional space.
The encoded embedding is then output to the final item score after a layer of FFN:
where denotes the embedding after rotation encoding in Equation (7).
4.4. Model Optimization
As in previous work [27], we use the Adam optimizer to minimize the binary cross-entropy loss of the CARCA model, while masking filler terms to prevent them from contributing to the loss function. For a given sequence of items, the interaction of user u is . The input list is obtained by deleting the last item of . The positive target list is obtained by moving the list one item to the right. The negative list of targets is obtained by random generation. Then the loss function is
5. Experimental Setup
5.1. Datasets
We chose the Amazon dataset, to assess proficiency in various coding types. For this purpose, we used four different real-world datasets extracted from product reviews on Amazon. Basic statistical information for these four datasets is shown in Table 1.

Table 1.
Dataset statistics.
These datasets are diverse and have been widely used for SRS under leave-behind protocols [4,5,6,32,33,34]. Since there are multiple versions of these datasets, we chose the preprocessed version of CARCA [27].
These datasets contain a variety of product categories and provide a diverse and comprehensive source for training and evaluating recommendation models. They provide the necessary characteristics for each interaction, such as the user id, item id, timestamp, and additional vector context information. The specific information for each dataset is provided below:
The Beauty dataset includes discrete and categorical attributes of all beauty products, including fine-grained categories and brands. There are mainly categorical and discrete features.
The Video Games dataset includes user interactions, reviews, and product details specific to the video games category, such as price, brand, and categorical features. Most of the attributes here are discrete and categorical.
The Men dataset contains a comprehensive collection of men’s clothing items. Attributes are dense vectors of image-based features extracted from the last layer of ResNet50 from the ImageNet dataset.
The Fashion dataset contains six categories of male and female clothing. Dense features are extracted using the same ResNet50 method.
5.2. Baselines
SASRec [6]: A sequence recommendation model that utilizes self-attention networks to capture the relationships between different time steps in the same sequence in a parallelized manner. It then derives the sequence characteristics for each time step through weighted summation.
BERT4Rec [7]: A model that employs a deep bidirectional self-attention mechanism to model user behavior sequences, addressing the limitations of traditional unidirectional models in capturing user behavior patterns.
S3Rec [5]: A model that leverages correlations within the original data to construct self-supervised signals, enhancing data representation through pretraining methods to improve sequence-based recommendations.
CARCA [27]: A recommender system model that that integrates contextual information with item attributes. The model enhances recommendation accuracy by using a cross-attention mechanism to predict user preferences for the next item.
5.3. Evaluation Metrics
To evaluate the performance of our recommendation system, we employed two widely-used Top-K metrics: Hit Ratio (HR@K) and Normalized Discounted Cumulative Gain (NDCG@K). These metrics provided complementary insights into the quality and effectiveness of our recommendations. Hit Ratio@K measures the proportion of recommended items that appear in the top K positions of the list, indicating how well the system identifies relevant items. This metric focuses on the accuracy of the recommendations. NDCG@K evaluates the ranking quality within the top K recommendations, giving higher weight to items ranked closer to the top. This metric emphasizes the precision of the ranking order, ensuring that the most relevant items are prioritized. The formulas for these metrics are as follows:
where S denotes the total number of items, denotes whether the i-th demand item is included in the list of items recommended by the model. If it is in the list, its value is 1; otherwise it is 0. denotes the set after sorting the original recall set R according to the scores from largest to smallest, and the sorted set is used to compute the DCG to obtain the IDCG. The NDCG obtained after normalization is a relative value, thus even enabling comparisons to be made between different users.
5.4. Parameter Settings
The parameter settings for the baseline model were initialized according to the optimal values recommended in the original paper. For our model, the number of attention heads and blocks was set to 3, the L2 regularization weight was set to 0.0001, and the other parameter settings for the four datasets are shown in Table 2.
Table 2.
Parameter settings.
6. Experimental Results
Table 3 summarizes the recommendation performance of the baseline approach and our proposed model on the four datasets. It is clear that the model outperformed the other baseline methods on most datasets, because it is able to understand user preferences in a fine-grained way from the correlation and change trends of attributes. The better performance for the Beauty dataset demonstrates the advantage of utilizing more attribute information propagation in sequential recommendation. The model achieved an NDCG@10 of 0.419 (highest improvement of 6.435% over CARCA) on the Beauty dataset and a Hit Ratio@10 of 0.803 (highest improvement of 3.613% over CARCA) on the Video Games dataset.
Table 3.
Performance comparison.
Our model significantly outperformed all baseline models, except CARCA, across all datasets, highlighting the importance of leveraging item attributes to learn user preferences. Compared to the more advanced S3Rec model, our model achieved improvements of 6.285% in NDCG@10 and 4.967% in Hit Ratio@10 on the Video Games dataset, which had the fewest item attributes. This improvement is attributed to the ability to incorporate item attribute information when representing item sequences.
A rather counterintuitive result was that our proposed model slightly underperformed CARCA on one of the metrics for the Men and Fashion datasets, both of which contained more attributes than the Video Games dataset. This was mainly due to the fact that the item attributes in these two datasets are image-based features, and the refinement process of converting item features into attribute features in our model led to some information loss, negatively impacting performance. On the other hand, this also explains why our model performed better on the Game and Beauty datasets, as these datasets predominantly feature categorical attributes, being more effective at extracting fine-grained attribute-level features.
6.1. Ablation Study
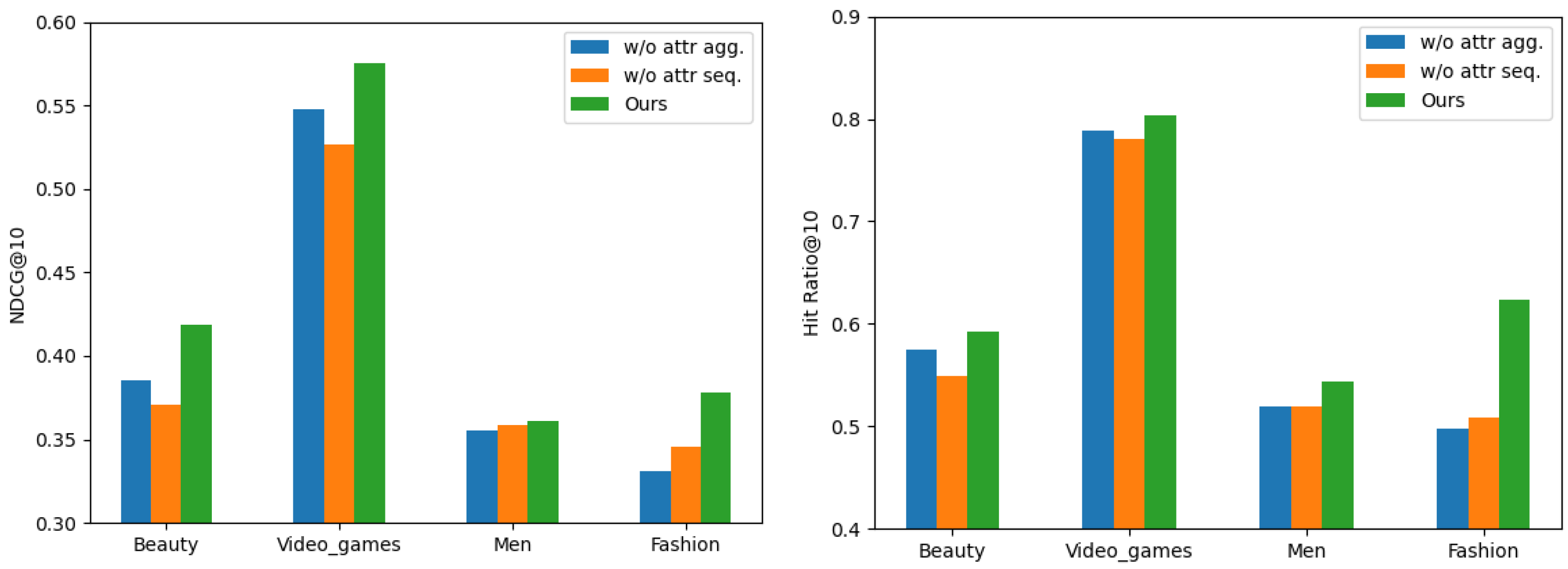
We performed ablation experiments on each of the two components of the model: the item–attribute graph aggregation, and attribute sequence aggregation. Table 4 and Figure 2 shows the experimental results, where w/o attr agg and w/o attr seq represent the variants where the model removed item–attribute graph aggregation and removed attribute sequence aggregation, respectively.
Table 4.
Ablation study, effect of item–attribute graph aggregation and attribute sequence.
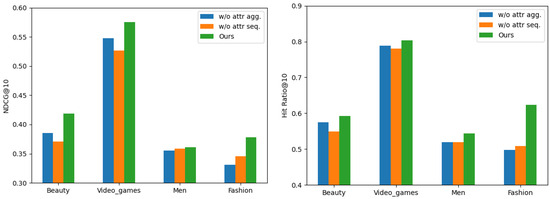
Figure 2.
Impact of item–attribute graph aggregation and attribute sequence aggregation.
We can see that in the absence of an attribute sequence graph, the model suffered the greatest performance loss on the first two datasets. On the latter two datasets, the experimental results of removing the two model components differed negligibly, which suggests that fine-grained information extracted from attributes is essential for user preference representation. Removing attribute sequences (w/o attr seq) resulted in a larger performance loss compared to removing attribute aggregation. For example, on the Video Games dataset, the NDCG@10 dropped from 0.575 to 0.527, and the Hit Ratio@10 dropped from 0.803 to 0.781. This suggests that fine-grained attribute-level information is crucial for user preference representation, and the attribute aggregation mechanism plays a key role in integrating this information into the model. In most cases, our model w/o attr agg achieved a better performance than our model w/o attr seq, proving that directly utilizing attributes for feature extraction, without learning how they change with user preferences, is not sufficient. Compared to the other two compared models, our model utilizes both item-level features and attribute-level fine-grained multiple feature representations, which ensures that it captures detailed user preferences. However, the model failed to capture changes in user preferences when extracting different features from a sequence of attributes, without adding relative positional encoding to each attribute, which led to a performance degradation.
6.2. Hyperparameter Analysis
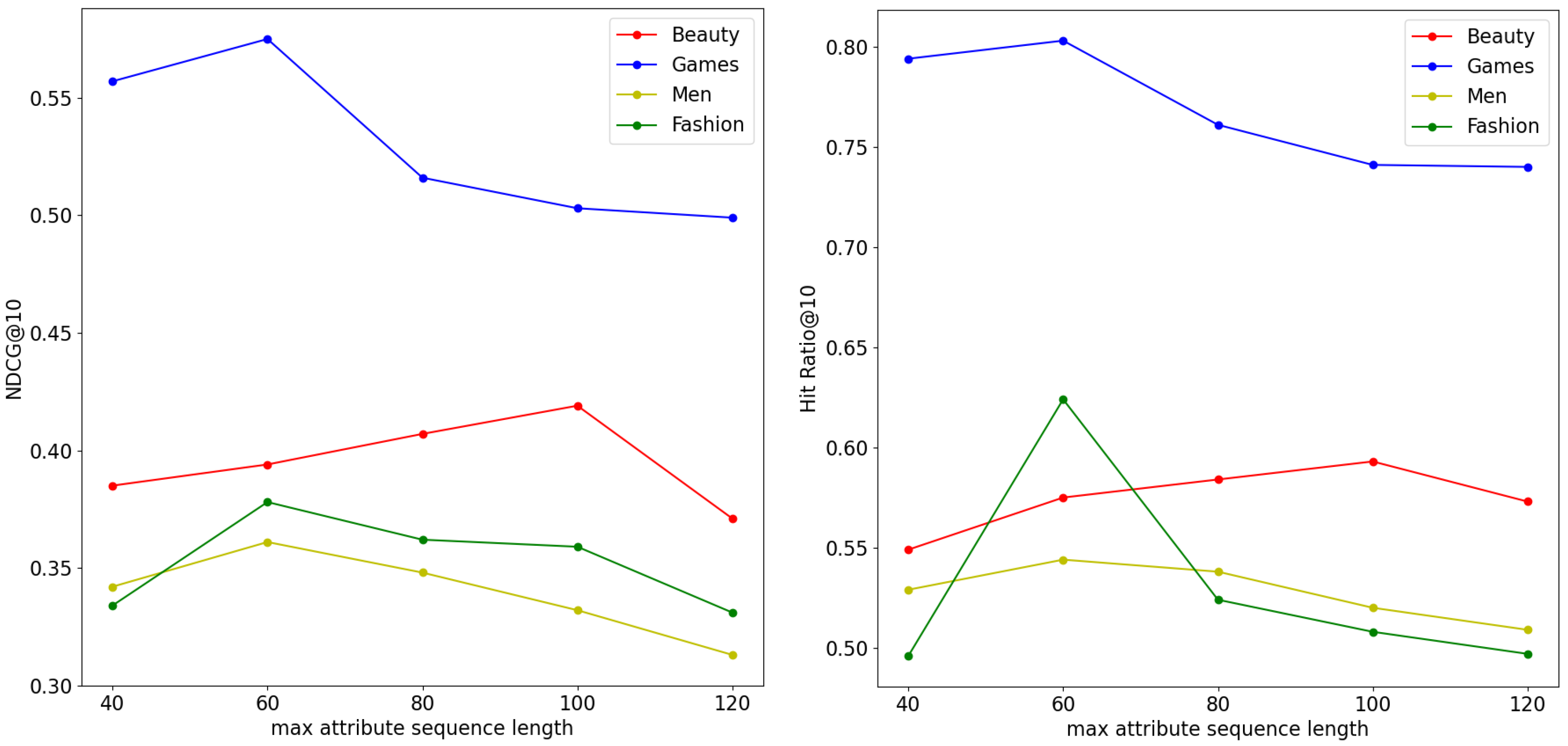
Figure 3 reflect the performance of the model under different settings of the maximum attribute sequence length , which we set at 40, 60, 80, 100, and 120 to explore its impact. Under our attribute sequence construction method, when was small, the attribute sequence retained only the first La attributes that had the largest item neighbors, which represented the attributes most likely to be preferred by the user. When was too large, the attributes of the nearest items dominated the user preference extraction. And when , the model achieved the best results on the Men and Fashion datasets, while on the Beauty and Video Games datasets, the best performance was achieved with a of 100 and 80, respectively, which may have been due to the fact that these two datasets have longer sequences and therefore require more attributes to reflect user preferences.
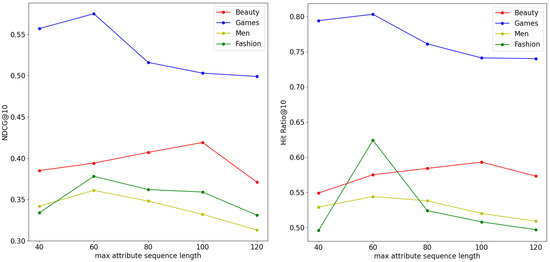
Figure 3.
Impact of maximum attribute sequence length.
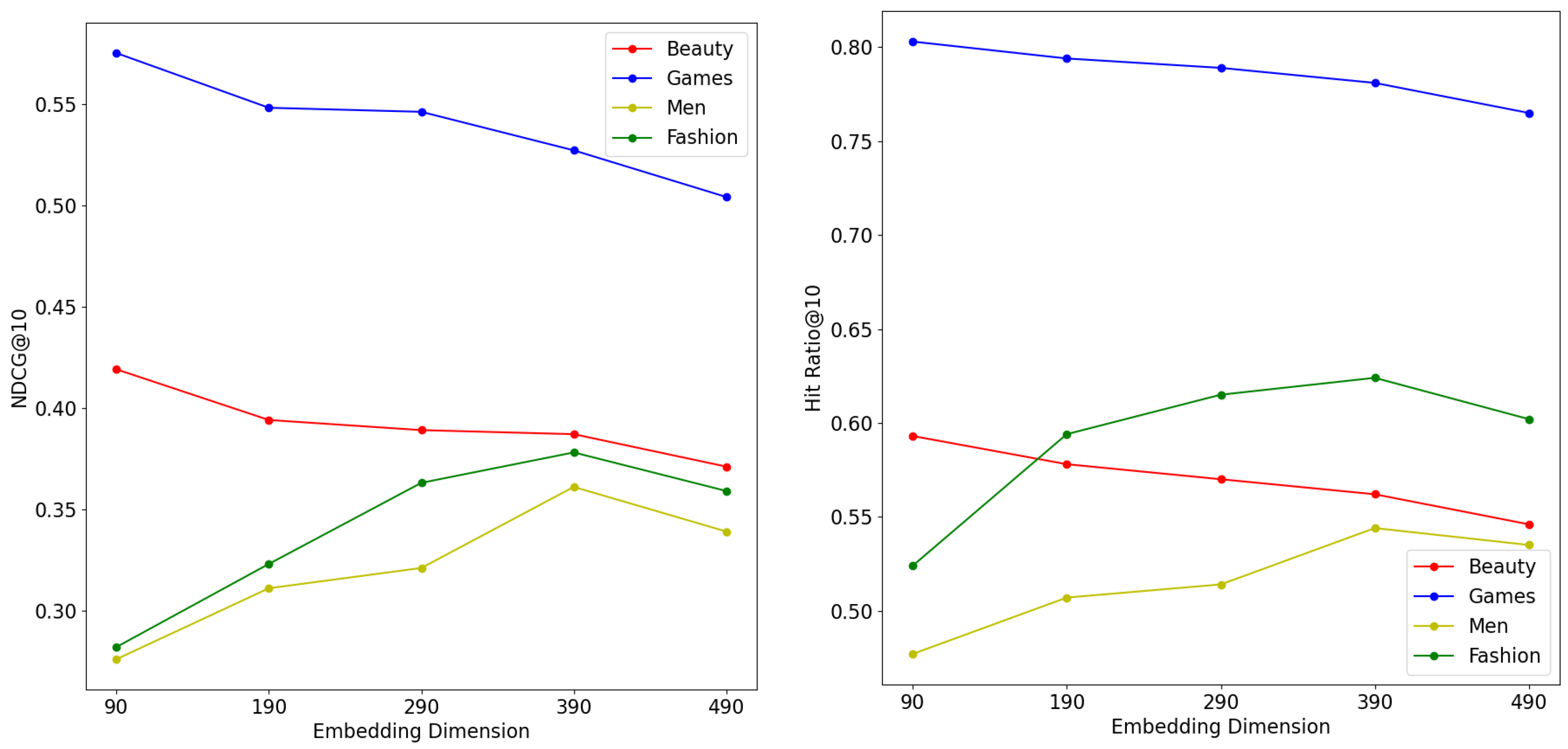
We further investigated the effect of the initial embedding dimensions of items and attributes on the experimental results. With the remaining hyperparameters fixed, we set the value range of the embedding dimension d at . From Figure 4, we can see that the model obtained the best performance on the Beauty dataset and Video games dataset when , and that when d was large, the high dimensionality extraction of item features led to the model’s inability to learn the sequence prediction task efficiently, which resulted in a lower recommendation performance on the Beauty dataset and Video games dataset. The Men and Fashion datasets, on the other hand, required a higher embedding dimension to achieve the best performance, due to having more features.
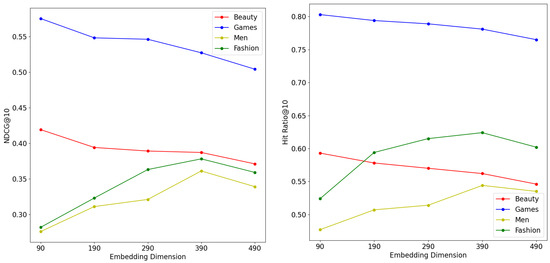
Figure 4.
Impact of embedding dimension.
7. Conclusions
In this paper, we proposed a method based on a graph neural network for constructing item attribute maps, to compute the sequence construction of attribute changes, in order to quickly determine which attributes are valuable for modeling user preferences. An attention mechanism was also introduced to integrate item-level and sequence-level information, and the effect of item attributes on encoding in the user–item interaction sequence was fused into the recommendation results. Experimental results on four different datasets showed that our proposed model significantly outperformed several state-of-the-art models in the item sequence recommendation task.
Author Contributions
Conceptualization, Y.Q. and W.X.; methodology, Y.Q. and Y.F.; software, Y.Q. and W.X.; validation, Y.Q. and Y.F.; formal analysis, Y.Q.; investigation, Y.Q.; resources, Y.Q.; data curation, Y.Q.; writing—original draft preparation, Y.Q.; writing—review and editing, Y.F., Z.T. and W.X.; supervision, W.X.; project administration, W.X.; funding acquisition, W.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Key R&D Program of China No. 2022YFB3102600, NSFC under grants Nos. 62306322 and 72371245.
Data Availability Statement
The datasets can be found at https://nijianmo.github.io/amazon/index.html (accessed on 15 October 2024).
Acknowledgments
This work was partially supported by National Key R&D Program of China No. 2022YFB3102600, NSFC under grants Nos. 62306322 and 72371245.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; pp. 263–272. [Google Scholar]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 995–1000. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Wu, L.; Li, S.; Hsieh, C.J.; Sharpnack, J. SSE-PT: Sequential recommendation via personalized transformer. In Proceedings of the 14th ACM Conference on Recommender Systems, Virtual, 22–26 September 2020; pp. 328–337. [Google Scholar]
- Zhou, K.; Wang, H.; Zhao, W.X.; Zhu, Y.; Wang, S.; Zhang, F.; Wang, Z.; Wen, J.R. S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual, 19–23 October 2020; pp. 1893–1902. [Google Scholar]
- Kang, W.C.; McAuley, J. Self-attentive sequential recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 1441–1450. [Google Scholar]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-based recommendations with recurrent neural networks. arXiv 2015, arXiv:1511.06939. [Google Scholar]
- Hidasi, B.; Karatzoglou, A. Recurrent neural networks with top-k gains for session-based recommendations. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 843–852. [Google Scholar]
- Dong, X.; Jin, B.; Zhuo, W.; Li, B.; Xue, T. Improving sequential recommendation with attribute-augmented graph neural networks. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Virtual Event, 11–14 May 2021; pp. 373–385. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing personalized markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Zhang, Y.; Dai, H.; Xu, C.; Feng, J.; Wang, T.; Bian, J.; Wang, B.; Liu, T.Y. Sequential click prediction for sponsored search with recurrent neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Li, J.; Ren, P.; Chen, Z.; Ren, Z.; Lian, T.; Ma, J. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1419–1428. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, J.; Wang, Y.; McAuley, J. Time interval aware self-attention for sequential recommendation. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, TX, USA, 3–7 February 2020; pp. 322–330. [Google Scholar]
- Wang, C.; Zhang, M.; Ma, W.; Liu, Y.; Ma, S. Make it a chorus: Knowledge-and time-aware item modeling for sequential recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 24–25 July 2020; pp. 109–118. [Google Scholar]
- Qin, Y.; Ju, W.; Wu, H.; Luo, X.; Zhang, M. Learning graph ode for continuous-time sequential recommendation. IEEE Trans. Knowl. Data Eng. 2024, 36, 3224–3236. [Google Scholar] [CrossRef]
- Pasricha, R.; McAuley, J. Translation-based factorization machines for sequential recommendation. In Proceedings of the 12th ACM Conference on Recommender Systems, Vancouver, BC, Canada, 2–7 October 2018; pp. 63–71. [Google Scholar]
- He, X.; Chua, T.S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- Shi, S.; Zhang, M.; Liu, Y.; Ma, S. Attention-based adaptive model to unify warm and cold starts recommendation. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 127–136. [Google Scholar]
- Zhou, G.; Zhu, X.; Song, C.; Fan, Y.; Zhu, H.; Ma, X.; Yan, Y.; Jin, J.; Li, H.; Gai, K. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 1059–1068. [Google Scholar]
- Cheng, H.T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & deep learning for recommender systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; pp. 7–10. [Google Scholar]
- Li, T.; Ma, Y.; Xu, J.; Stenger, B.; Liu, C.; Hirate, Y. Deep heterogeneous autoencoders for collaborative filtering. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 1164–1169. [Google Scholar]
- Su, Y.; Erfani, S.M.; Zhang, R. MMF: Attribute interpretable collaborative filtering. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Lv, F.; Jin, T.; Yu, C.; Sun, F.; Lin, Q.; Yang, K.; Ng, W. SDM: Sequential deep matching model for online large-scale recommender system. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2635–2643. [Google Scholar]
- Zhang, T.; Zhao, P.; Liu, Y.; Sheng, V.S.; Xu, J.; Wang, D.; Liu, G.; Zhou, X. Feature-level deeper self-attention network for sequential recommendation. In Proceedings of the IJCAI, Macao, China, 10–16 August 2019; pp. 4320–4326. [Google Scholar]
- Rashed, A.; Elsayed, S.; Schmidt-Thieme, L. Context and attribute-aware sequential recommendation via cross-attention. In Proceedings of the 16th ACM Conference on Recommender Systems, Seattle, WA, USA, 18–23 September 2022; pp. 71–80. [Google Scholar]
- He, X.; Deng, K.; Wang, X.; Li, Y.; Zhang, Y.; Wang, M. Lightgcn: Simplifying and powering graph convolution network for recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 24–25 July 2020; pp. 639–648. [Google Scholar]
- Ding, Q.; Sun, T.; Zhou, M. Attribute-driven Interest Modeling for Sequential Recommendation. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Su, J.; Ahmed, M.; Lu, Y.; Pan, S.; Bo, W.; Liu, Y. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing 2024, 568, 127063. [Google Scholar] [CrossRef]
- Lopez-Avila, A.; Du, J.; Shimary, A.; Li, Z. Positional encoding is not the same as context: A study on positional encoding for Sequential recommendation. arXiv 2024, arXiv:2405.10436. [Google Scholar]
- He, R.; McAuley, J. VBPR: Visual bayesian personalized ranking from implicit feedback. In Proceedings of the AAAI Conference on Artificial Intelligencer, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Hou, M.; Wu, L.; Chen, E.; Li, Z.; Zheng, V.W.; Liu, Q. Explainable fashion recommendation: A semantic attribute region guided approach. arXiv 2019, arXiv:1905.12862. [Google Scholar]
- Steck, H. Embarrassingly shallow autoencoders for sparse data. In Proceedings of the The World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 3251–3257. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).