
A Multi-Scale Fusion Convolutional Network for Time-Series Silicon Prediction in Blast Furnaces



Abstract
1. Introduction
- Inadequate handling of long time delays in BF processes: Despite the success of data-driven methods in silicon content prediction, the inherent long time delays in BF operations—arising from its complex dynamic system and physical reactions with significant lags [26]—have not been sufficiently addressed in many existing models.
- Neglect of historical time-step dependencies: Most data-driven approaches rely on instantaneous input variables for predictions, failing to capture the time delay effects where current silicon content is influenced by inputs from previous time steps. This limits their ability to reflect evolving system states over time [27].
- Suboptimal prediction accuracy under dynamic conditions: Traditional short-term models exhibit reduced effectiveness in rapidly changing process conditions, as they cannot adequately account for time-lagged influences, thereby hindering real-time adjustments for BF operations.
- The Multi-scale Fusion Convolutional Neural Network Model is proposed: An innovative model combining multi-scale feature extraction and deep learning is proposed to tackle the problem of silicon content prediction in the BF ironmaking process. This model effectively captures the complex dynamic characteristics in both long-term and short-term dependencies in the time-series data by fusing information from two different scales;
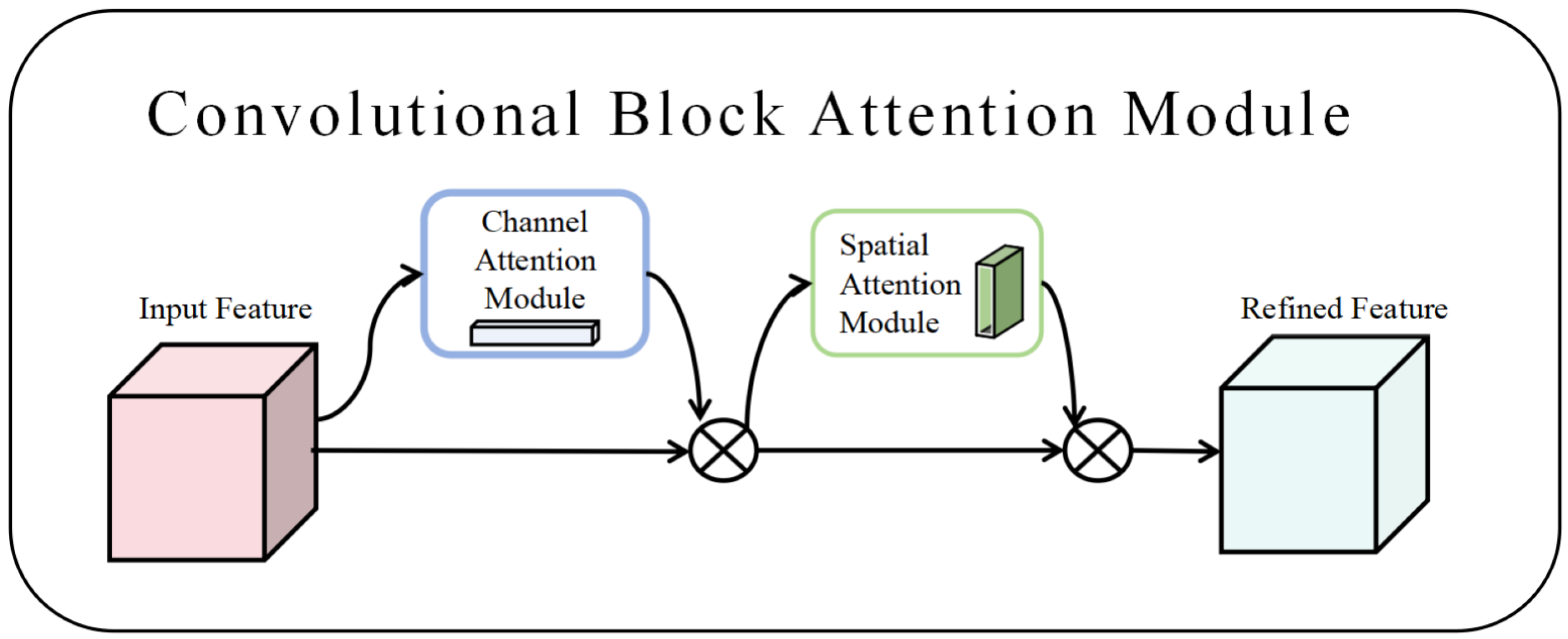
- The CBAM and Multi-Head Self-Attention Mechanism are introduced: During the feature extraction process, the CBAM and Multi-Head Self-Attention Mechanism are leveraged to enhance the model’s feature selection ability when processing BF smelting data. The CBAM helps automatically weight the importance of features, while the MSA further strengthens the model’s capability to capture the complex relationships between time steps in the time series.
2. Preliminaries
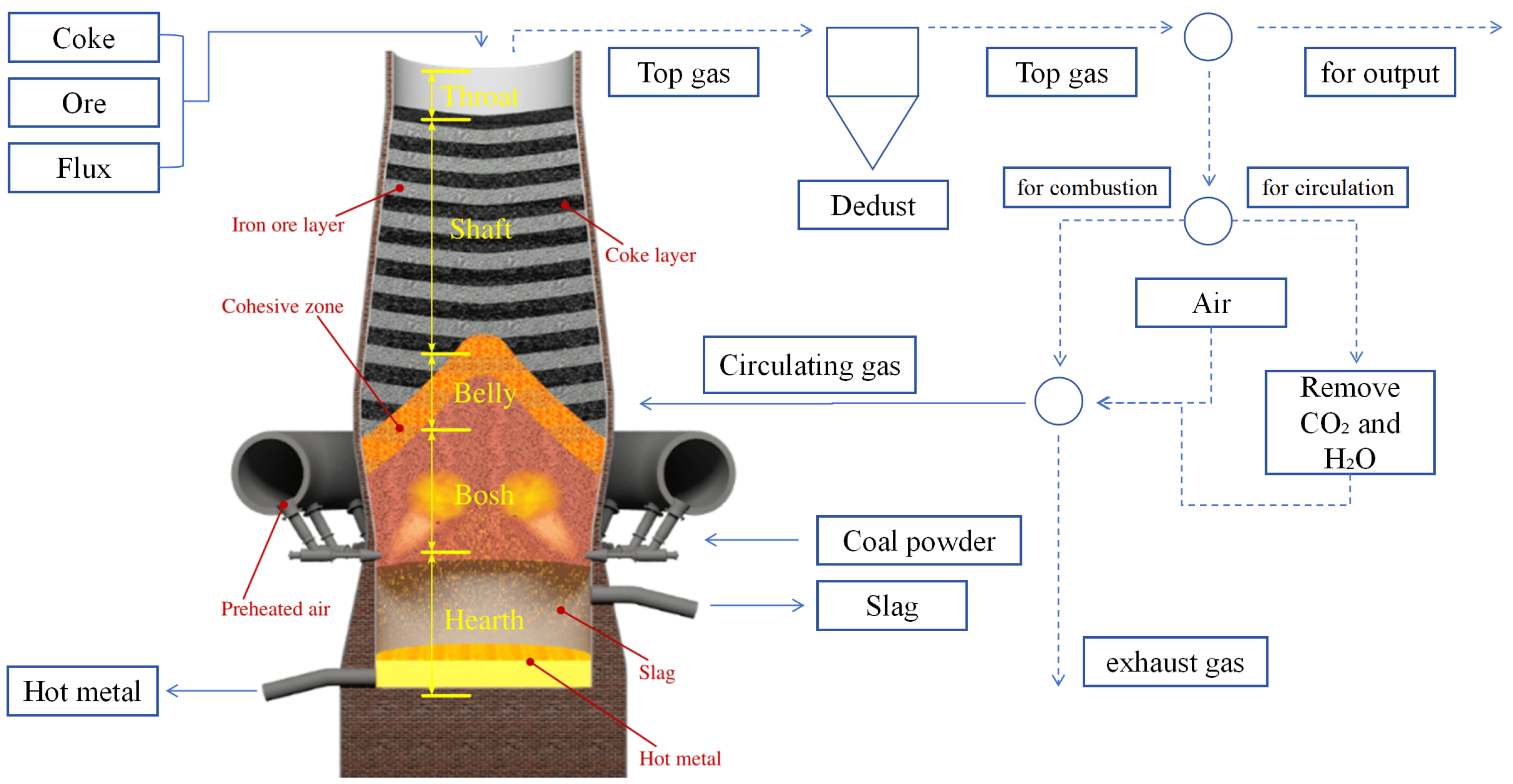
2.1. Challenges of Blast Furnace Data and Traditional Methods
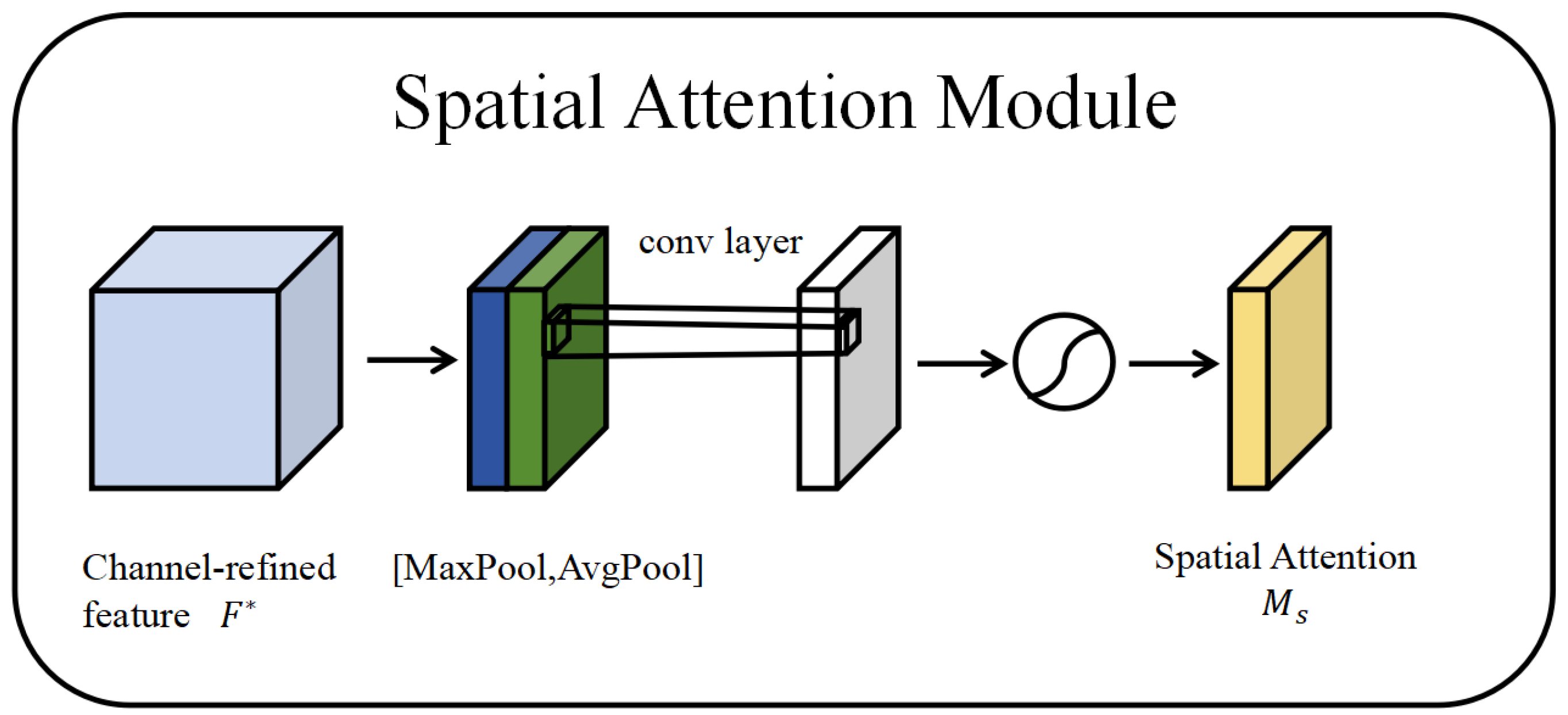
2.2. Convolutional Block Attention Module
2.3. Self-Attention Mechanism
3. Methodology
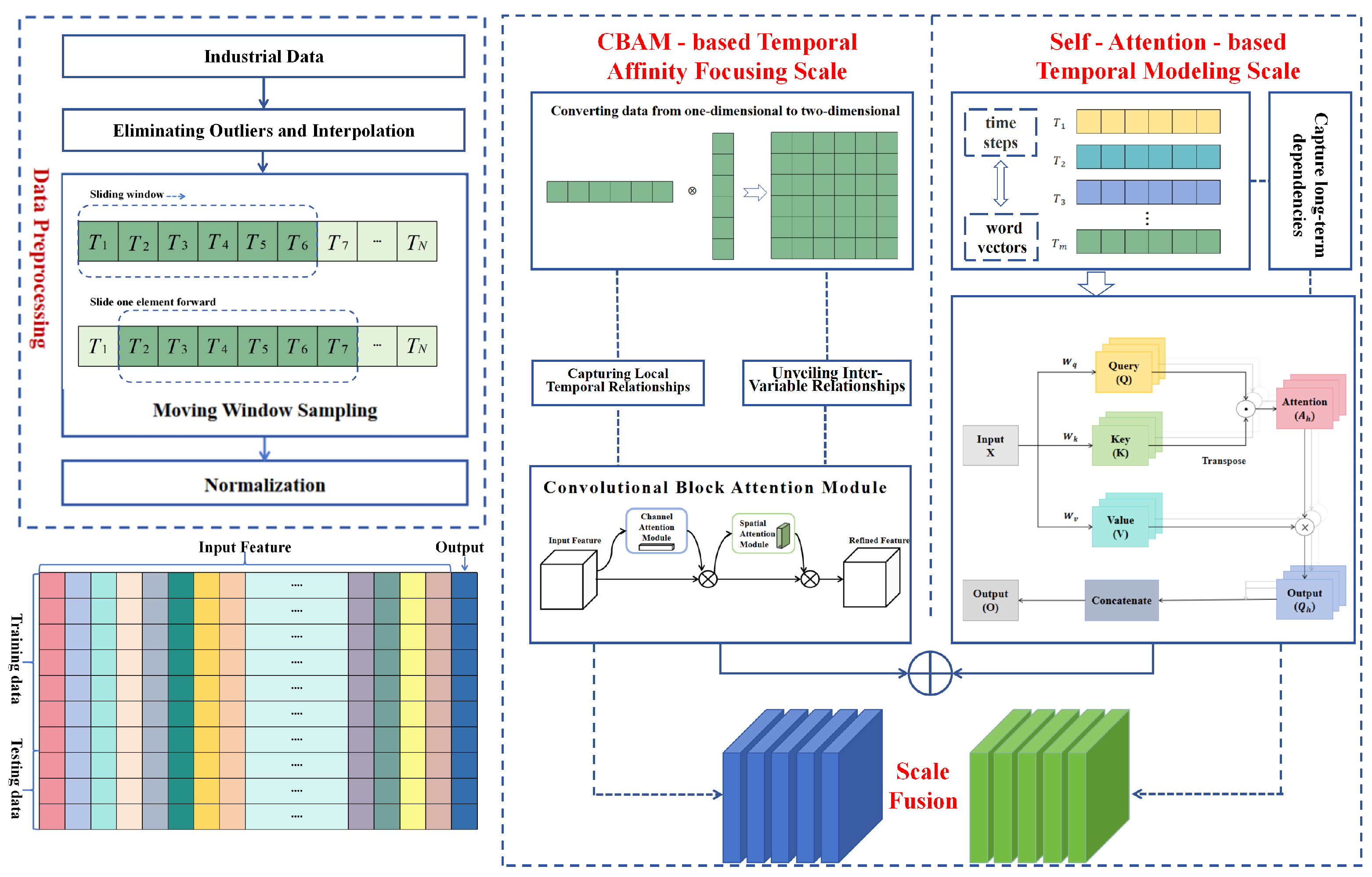
3.1. Overall Framework of MSF-CNN
- CBAM-based Temporal Affinity Focusing Scale: By introducing the CBAM, this scale focuses on critical features within local temporal windows, capturing local temporal dependencies. The CBAM module employs both the channel and SAM to selectively focus on the most important features, thereby enhancing the modeling capability of local time series data.
- Self-Attention-based Temporal Modeling Scale: Building on this, the self-attention mechanism is used to model global temporal dependencies. Unlike traditional RNN/LSTM/GRU methods, self-attention allows the model to freely capture dependencies across long time spans on a global scale. By calculating the relationships between time steps, the self-attention mechanism effectively mitigates the gradient vanishing problem and can comprehensively capture complex interactions between variables.
3.2. CBAM-Based Temporal Affinity Focusing Scale
3.2.1. Temporal Feature Enhancement via Outer Product Operation
3.2.2. Attention Mechanism Optimization in Time Series Processing
3.3. Self-Attention-Based Temporal Modeling Scale
3.4. Fusion of Local and Global Temporal Scales
4. Experimental Results and Discussion
4.1. Experimental Settings
- :
- :
- :
- :
- :
4.2. Model Performance Optimization
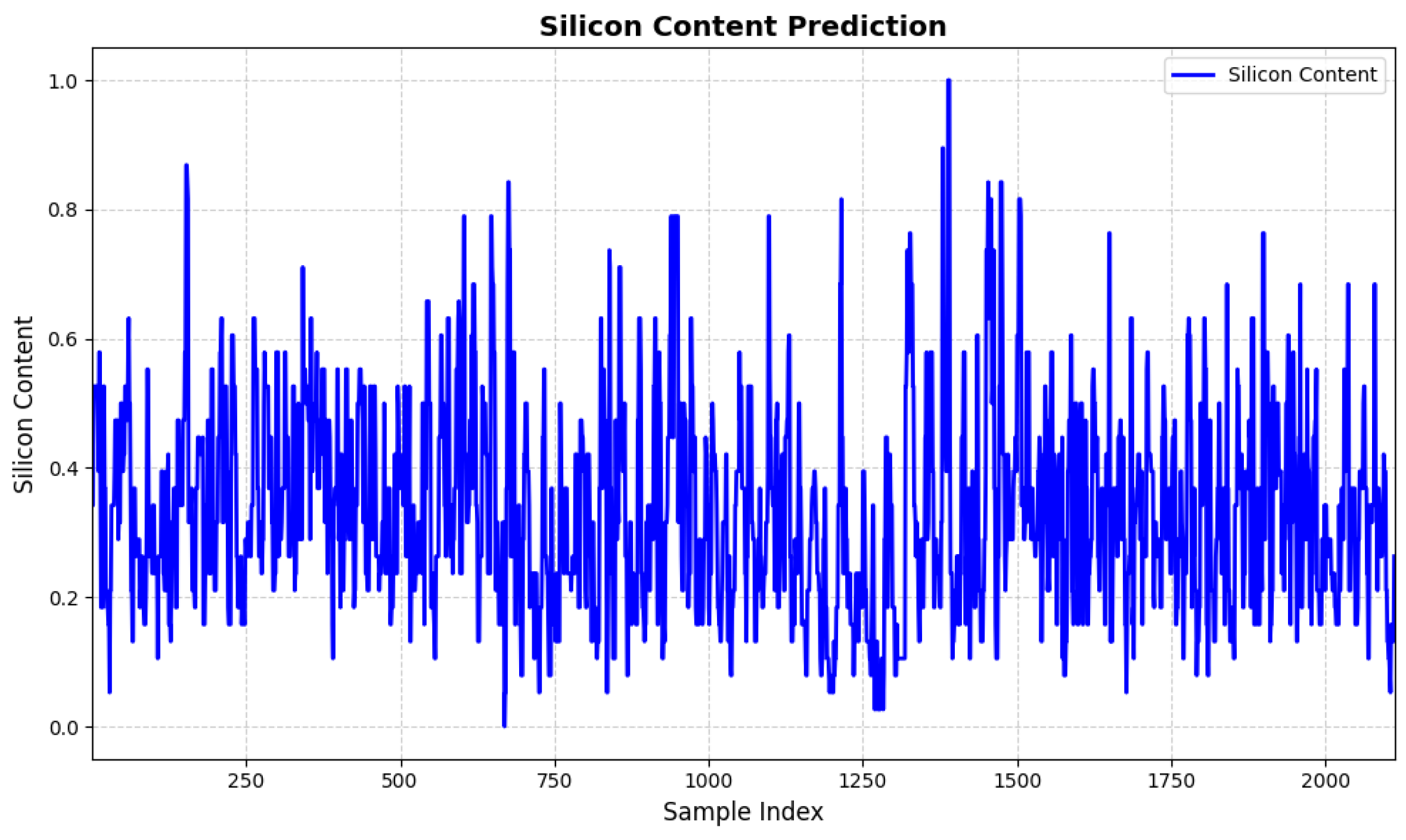
4.3. Experimental Results
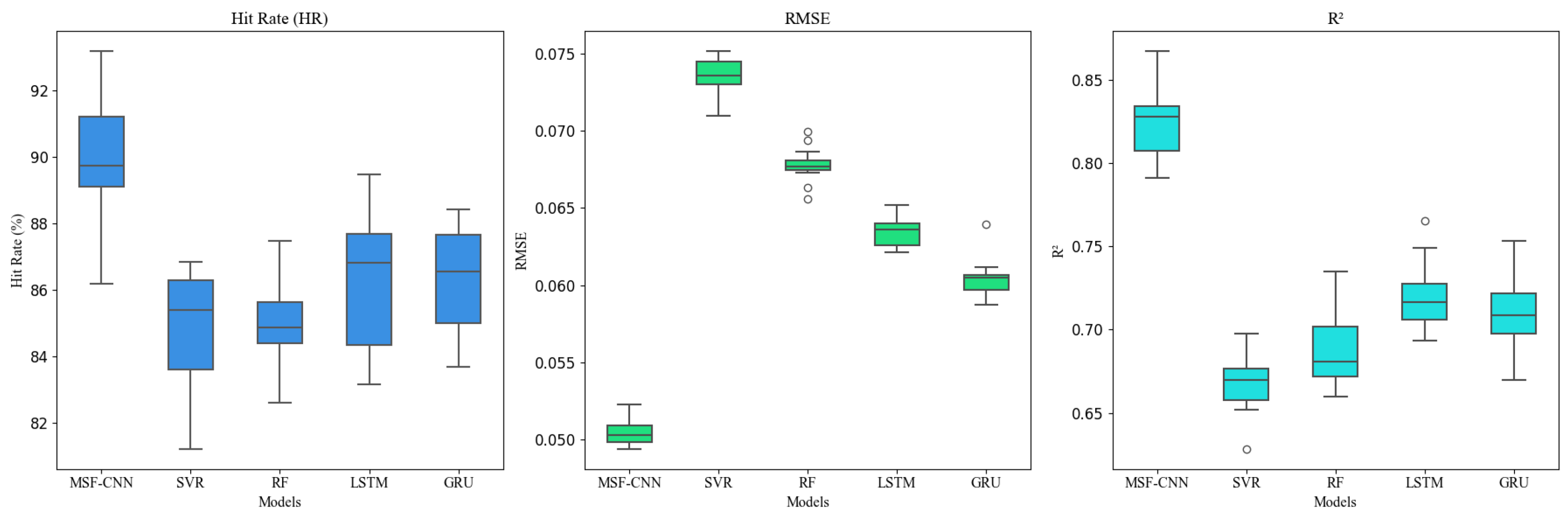
4.3.1. Comparison with Baseline Models
4.3.2. Ablation Study
4.4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Saxén, H.; Gao, C.; Gao, Z. Data-Driven Time Discrete Models for Dynamic Prediction of the Hot Metal Silicon Content in the Blast Furnace—A Review. IEEE Trans. Ind. Inform. 2013, 9, 2213–2225. [Google Scholar] [CrossRef]
- Wang, X.; Hu, T.; Tang, L. A Multiobjective Evolutionary Nonlinear Ensemble Learning with Evolutionary Feature Selection for Silicon Prediction in Blast Furnace. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 2080–2093. [Google Scholar] [CrossRef] [PubMed]
- Dong, X.F.; Yu, A.B.; Burgess, J.M.; Pinson, D.; Chew, S.; Zulli, P. Modelling of Multiphase Flow in Ironmaking Blast Furnace. Ind. Eng. Chem. Res. 2009, 48, 214–226. [Google Scholar] [CrossRef]
- Kuang, S.; Li, Z.; Yu, A. Review on Modeling and Simulation of Blast Furnace. Steel Res. Int. 2018, 89, 1700071. [Google Scholar] [CrossRef]
- Gupta, S.; French, D.; Sakurovs, R.; Grigore, M.; Sun, H.; Cham, T.; Hilding, T.; Hallin, M.; Lindblom, B.; Sahajwalla, V. Minerals and Iron-Making Reactions in Blast Furnaces. Prog. Energy Combust. Sci. 2008, 34, 155–197. [Google Scholar] [CrossRef]
- Zhou, P.; Li, W.; Wang, H.; Li, M.; Chai, T. Robust Online Sequential RVFLNs for Data Modeling of Dynamic Time-Varying Systems with Application of an Ironmaking Blast Furnace. IEEE Trans. Cybern. 2020, 50, 4783–4795. [Google Scholar] [CrossRef]
- Saxén, H.; Pettersson, F. Nonlinear Prediction of the Hot Metal Silicon Content in the Blast Furnace. ISIJ Int. 2007, 47, 1732–1737. [Google Scholar] [CrossRef]
- Jian, L.; Gao, C. Binary Coding SVMs for the Multiclass Problem of Blast Furnace System. IEEE Trans. Ind. Electron. 2013, 60, 3846–3856. [Google Scholar] [CrossRef]
- Zhou, P.; Wang, C.; Li, M.; Wang, H.; Wu, Y.; Chai, T. Modeling error PDF optimization based wavelet neural network modeling of dynamic system and its application in blast furnace ironmaking. Neurocomputing 2018, 285, 167–175. [Google Scholar] [CrossRef]
- Li, J.; Yang, C.; Li, Y.; Xie, S. A Context-Aware Enhanced GRU Network with Feature-Temporal Attention for Prediction of Silicon Content in Hot Metal. IEEE Trans. Ind. Inform. 2022, 18, 6631–6641. [Google Scholar] [CrossRef]
- Guo, R.; Liu, H.; Xie, G.; Zhang, Y.; Liu, D. A Self-Interpretable Soft Sensor Based on Deep Learning and Multiple Attention Mechanism: From Data Selection to Sensor Modeling. IEEE Trans. Ind. Inform. 2023, 19, 6859–6871. [Google Scholar] [CrossRef]
- Guo, R.; Chen, Q.; Tong, S.; Liu, H. Knowledge-Aided Generative Adversarial Network: A Transfer Gradient-Less Adversarial Attack for Deep Learning-Based Soft Sensors. In Proceedings of the 14th Asian Control Conference (ASCC), Dalian, China, 5–8 July2024; pp. 1254–1259. [Google Scholar]
- Waller, M.; Saxén, H. On the Development of Predictive Models with Applications to a Metallurgical Process. Ind. Eng. Chem. Res. 2000, 39, 982–988. [Google Scholar] [CrossRef]
- Bhattacharya, T. Prediction of Silicon Content in Blast Furnace Hot Metal Using Partial Least Squares (PLS). ISIJ Int. 2005, 45, 1943–1945. [Google Scholar] [CrossRef]
- Saxén, H.; Östermark, R. State realization with exogenous variables—A test on blast furnace data. Eur. J. Oper. Res. 1996, 89, 34–52. [Google Scholar] [CrossRef]
- Östermark, R.; Saxén, H. VARMAX-modelling of blast furnace process variables. Eur. J. Oper. Res. 1996, 90, 85–101. [Google Scholar] [CrossRef]
- Zeng, J.-S.; Gao, C.-H. Improvement of identification of blast furnace ironmaking process by outlier detection and missing value imputation. J. Process Control 2009, 19, 1519–1528. [Google Scholar] [CrossRef]
- Nurkkala, A.; Pettersson, F.; Saxén, H. Nonlinear Modeling Method Applied to Prediction of Hot Metal Silicon in the Ironmaking Blast Furnace. Ind. Eng. Chem. Res. 2011, 50, 9236–9248. [Google Scholar] [CrossRef]
- Cardoso, W.; di Felice, R. Prediction of silicon content in the hot metal using Bayesian networks and probabilistic reasoning. Int. J. Adv. Intell. Inform. 2021, 7, 268–281. [Google Scholar] [CrossRef]
- Zhou, H.; Yang, C.; Liu, W.; Zhuang, T. A Sliding-Window T-S Fuzzy Neural Network Model for Prediction of Silicon Content in Hot Metal. IFAC Pap. 2017, 50, 14988–14991. [Google Scholar] [CrossRef]
- Song, J.; Xing, X.; Pang, Z.; Lv, M. Prediction of Silicon Content in the Hot Metal of a Blast Furnace Based on FPA-BP Model. Metals 2023, 13, 918. [Google Scholar] [CrossRef]
- Zhang, C.; Lim, P.; Qin, A.K.; Tan, K.C. Multiobjective deep belief networks ensemble for remaining useful life estimation in prognostics. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2306–2318. [Google Scholar] [CrossRef] [PubMed]
- Bui, L.T.; Vu, V.T.; Dinh, T.T.H. A novel evolutionary multi-objective ensemble learning approach for forecasting currency exchange rates. Data Knowl. Eng. 2018, 114, 40–66. [Google Scholar] [CrossRef]
- Zhang, H.; Zhou, A.; Zhang, H. An evolutionary forest for regression. IEEE Trans. Evol. Comput. 2022, 26, 735–749. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, G.; Wang, X. Silicon Content Prediction in Blast Furnace Ironmaking Process Based on Closed-loop Multiobjective Evolutionary Ensemble Learning. IEEE Trans. Instrum. Meas. 2025, 74, 2516715. [Google Scholar] [CrossRef]
- Liu, C.; Tan, J.; Li, J.; Li, Y.; Wang, H. Temporal Hypergraph Attention Network for Silicon Content Prediction in Blast Furnace. IEEE Trans. Instrum. Meas. 2022, 71, 2521413. [Google Scholar] [CrossRef]
- Yan, D.; Yang, C.; Sun, S.; Lou, S.; Kong, L.; Zhang, Y. One-Sided Relational Autoencoder with Seasonal-Trend Decomposition to Extract Process Correlations for Molten Iron Quality Prediction. IEEE Trans. Instrum. Meas. 2024, 73, 1002413. [Google Scholar] [CrossRef]
- Elman, J.L. Finding Structure in Time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar] [CrossRef]
- Jeon, M.; Choi, H.S.; Lee, J.; Kang, M. Multi-scale prediction for fire detection using convolutional neural network. Fire Technol. 2021, 57, 2533–2551. [Google Scholar] [CrossRef]
- Zhang, M.; Zhou, L.; Jie, J.; Liu, X. A multi-scale prediction model based on empirical mode decomposition and chaos theory for industrial melt index prediction. Chemometrics Intell. Lab. Syst. 2019, 186, 23–32. [Google Scholar] [CrossRef]
- Li, H.; Zhao, W.; Zhang, Y.; Zio, E. Remaining useful life prediction using multi-scale deep convolutional neural network. Appl. Soft. Comput. 2020, 89, 106113. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Tang, L.; Zhang, Q. Multiobjective Ensemble Learning with Multiscale Data for Product Quality Prediction in Iron and Steel Industry. IEEE Trans. Evol. Comput. 2024, 28, 1099–1113. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]


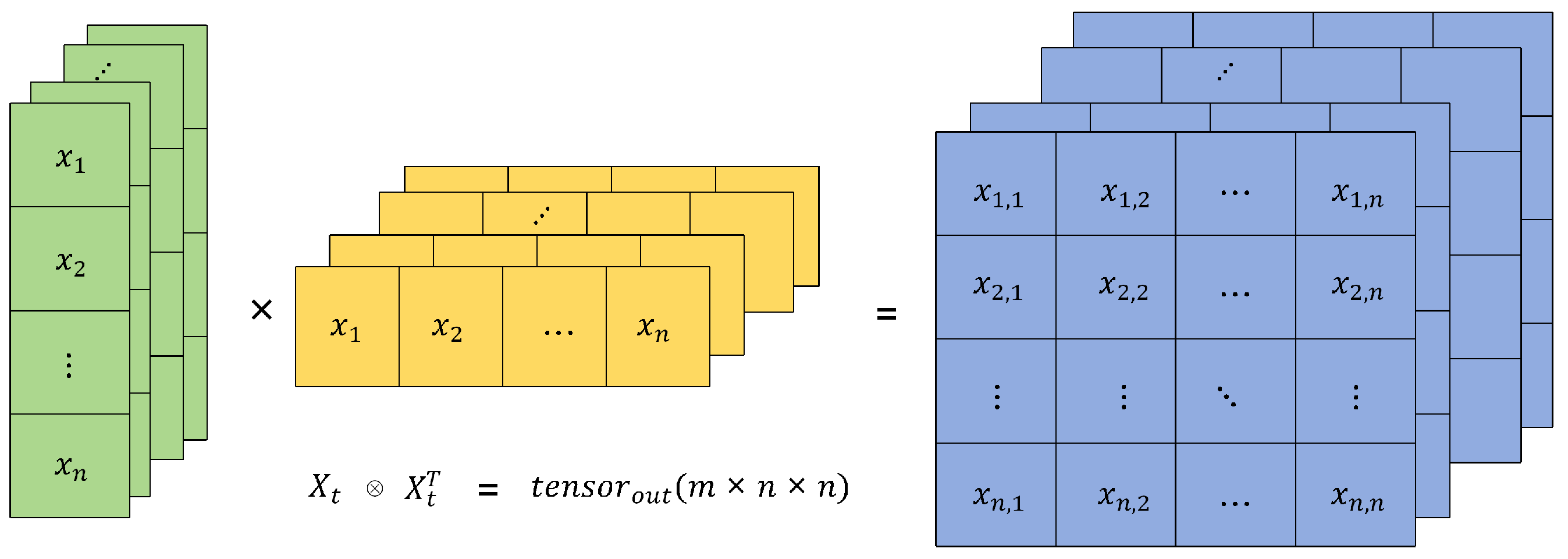




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Feature | Unit |
|---|---|
| Furnace Waist Average Temperature | °C |
| Furnace Waist Temperature Range | °C |
| Top Furnace Pressure | kPa |
| Top Furnace Temperature | °C |
| Top Furnace Gas CO Content | % |
| Top Furnace Gas H2 Content | % |
| Sintered Ore | % |
| Wind flow | |
| Coal Injection Rate | t/h |
| Actual Air Velocity | |
| Oxygen-Enriched Pressure | kPa |
| Oxygen Enrichment Rate | |
| % | |
| % | |
| % | |
| % | |
| C | % |
| Model | MSF-CNN | SVR | RF | LSTM | GRU |
|---|---|---|---|---|---|
| RMSE | 5.08 | 7.36 | 6.75 | 6.33 | 6.01 |
| MAE | 0.0522 | 0.0699 | 0.0683 | 0.0622 | 0.0599 |
| HR | 90.02% | 84.74% | 85.53% | 86.37% | 86.71% |
| R2 | 8.30 | 6.68 | 6.91 | 7.11 | 7.07 |
| 0.8203 | 0.7075 | 0.7132 | 0.7543 | 0.7522 |
| Metric | MSF-CNN | NoCBAM-CNN | NoMSA-CNN | Baseline-CNN |
|---|---|---|---|---|
| RMSE | 5.22 | 6.36 | 6.72 | 7.73 |
| MAE | 0.0568 | 0.0677 | 0.0696 | 0.0793 |
| HR | 90.1% | 85.68% | 82.15% | 74.37% |
| R2 | 8.33 | 6.35 | 6.42 | 6.02 |
| 0.8347 | 0.7183 | 0.7241 | 0.7005 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hao, Q.; Liu, W.; Gao, W.; Wang, X. A Multi-Scale Fusion Convolutional Network for Time-Series Silicon Prediction in Blast Furnaces. Mathematics 2025, 13, 1347. https://doi.org/10.3390/math13081347
Hao Q, Liu W, Gao W, Wang X. A Multi-Scale Fusion Convolutional Network for Time-Series Silicon Prediction in Blast Furnaces. Mathematics. 2025; 13(8):1347. https://doi.org/10.3390/math13081347
Chicago/Turabian StyleHao, Qiancheng, Wenjing Liu, Wenze Gao, and Xianpeng Wang. 2025. "A Multi-Scale Fusion Convolutional Network for Time-Series Silicon Prediction in Blast Furnaces" Mathematics 13, no. 8: 1347. https://doi.org/10.3390/math13081347
APA StyleHao, Q., Liu, W., Gao, W., & Wang, X. (2025). A Multi-Scale Fusion Convolutional Network for Time-Series Silicon Prediction in Blast Furnaces. Mathematics, 13(8), 1347. https://doi.org/10.3390/math13081347