1. Introduction
Rapid advancements in cloud computing and containerization have made Kubernetes, a leading container orchestration platform, a key component of modern application architectures [
1]. However, the default Kubernetes scheduler (Kube-scheduler) primarily focuses on scheduling homogeneous resources like CPU and memory, with limited support for heterogeneous resources such as GPUs, network I/O, and disk I/O [
2]. This constraint hampers the scheduler’s ability to efficiently manage complex resource demands, particularly in GPU-intensive tasks like deep learning, where the lack of fine-grained control over resource allocation can lead to inefficient utilization or over-allocation, ultimately affecting task scheduling efficiency, training performance, and overall system effectiveness [
3].
Kubernetes offers limited management of network and disk I/O. While the CNI and CSI plugins provide extended support, they do not offer the same level of precision in scheduling as CPU and memory [
4]. In high-throughput or low-latency scenarios, such as video streaming or large-scale databases, network and storage bottlenecks can significantly degrade performance, increasing latency or reducing throughput [
5]. Google Cloud’s Kubernetes Performance Guide identifies network and disk I/O contention as a common issue in production environments, particularly in multi-tenant cloud settings, where insufficient scheduling can lead to performance instability in data-intensive applications [
6].
Recent developments in Kubernetes resource scheduling, fueled by advances in cloud computing and container technologies, have made strides in overcoming these limitations. For example, Du and T. [
7] introduced a distributed machine-learning-based priority scheduling method that improves scheduling efficiency by incorporating factors such as user and task priorities, waiting times, task parallelism, and node affinity. Wang [
8] used deep reinforcement learning to optimize edge task scheduling, achieving a 31% reduction in average response time after deploying 500 random tasks. Chehardoli [
9] proposed a dynamic network-metrics-based scheduling strategy utilizing the Istio service mesh to gather network data, which reduced response times to 37% of their original value and saved 50% of node bandwidth. Zheng and T. [
10] developed an elastic resource scheduling algorithm for container clouds that maximizes resource utilization by optimizing virtual machine configurations and resource allocation. Although these studies have advanced Kubernetes scheduling, most focus on homogeneous resources, leaving the complex interdependencies of heterogeneous resources underexplored, which limits the precision of resource allocation [
11].
Traditional resource scheduling methods often rely on static configurations and fail to dynamically adjust in response to fluctuating resource demands or cluster load. As a result, static approaches can lead to resource wastage or scheduling delays. Lefteris [
12] improved the existing CPU and memory filtering algorithm by incorporating GPU filtering and refining the scheduler’s scoring mechanism for mixed CPU/GPU deployments, reducing resource contention. Shen [
13] developed a multi-agent critic algorithm to optimize edge cloud scheduling using a graph neural network, which increased system throughput by 15.9% and reduced scheduling costs by 38.4%. Pei [
14] introduced a multi-resource interleaving scheme using deep reinforcement learning to improve performance in cloud-edge systems, addressing high-throughput task scheduling needs through a dynamic task scheduling approach. However, these methods still lack a unified framework for managing multidimensional heterogeneous resource scheduling, leading to inefficiencies when coscheduling various resource types [
15,
16].
In conclusion, while existing scheduling algorithms are effective at managing CPU and memory resources, they often struggle to address the complexities associated with heterogeneous resources and adapt dynamically to real-time fluctuations. This leads to suboptimal scheduling and inefficient resource utilization. To overcome these limitations, we propose a dynamic scheduling method for heterogeneous resources in Kubernetes, which simultaneously considers CPU, memory, GPU, network I/O, and disk I/O. By continuously monitoring resource usage across nodes and pods, our approach can predict shifting resource demands in real time, enabling more accurate scheduling and minimizing both resource wastage and node overload.
This paper is organized as follows:
Section 2 provides an overview of the research landscape in this area.
Section 3 presents a detailed discussion of the proposed algorithmic improvements, emphasizing the key advancements.
Section 4 outlines the experimental setup and parameters.
Section 5 offers a brief summary of the algorithms introduced in this study, along with directions for future research.
2. Research Foundation
Kubernetes [
17,
18] is an open-source container orchestration platform designed to automate the deployment, scaling, and management of containerized applications. Its core functionalities include load balancing, resource scheduling, and cluster management, which collectively enable efficient task distribution and resource management in heterogeneous environments. Among these components, the Kube-scheduler plays a critical role in selecting the most appropriate node for a Pod based on predefined policies [
19]. The scheduling process is comprised of two main phases: node filtering and optimal ranking, which together provide both flexibility and precision in resource allocation.
In the scheduling process, Kube-scheduler first filters out the eligible node set, according to the resource requirements of the task
; the filtering method is shown in Equation (
1).
where
N denotes the set of all nodes,
is the task resource demand vector, and
is the node resource availability vector. The selected nodes select the optimal node
, as shown in Equation (
2).
where
is the node score function. The default Kubernetes scheduler struggles to dynamically adapt to heterogeneous resource environments, particularly when faced with varying task requirements and uneven resource loads. Dynamic resource scheduling seeks to optimize resource allocation through real-time monitoring and feedback, with the goal of maximizing system throughput and minimizing task latency.
The core objective function in Equation (
3) is derived from related work and serves as a conceptual guideline, not a direct part of our algorithm. It provides a theoretical foundation for balancing task latency and resource efficiency, facilitating comparison with prior research. However, it is not integrated into our design or node scoring/scheduling logic and does not influence our algorithm’s decisions.
where
T is the set of tasks,
represents the resource consumption of task
t,
is the amount of resources allocated by task
t at node
n,
is the scheduling delay of the task, and
and
are the weight coefficients. The default Kubernetes scheduler struggles to dynamically adapt to heterogeneous resource environments, particularly when faced with variable task requirements and uneven resource loads. Dynamic resource scheduling seeks to optimize resource allocation through real-time monitoring and feedback, with the goal of maximizing system throughput and minimizing task latency. The core objective function is formulated as shown in Equation (
3).
The cumulative reward function
R, defined in Equation (
4), serves as a conceptual foundation for reinforcement-learning-based task scheduling. While it suggests the use of a learning-based scheduler, this study does not incorporate reinforcement learning or reward-based optimization. Instead, the function provides a theoretical reference and baseline for related algorithms. It is not part of our proposed method, which focuses on a different scheduling approach, and is included to contextualize our work within the broader research landscape.
where
is the discount factor, and
and
represent the state and action.
3. Research Method
In this section, we provide an overview of the algorithm’s framework and the underlying research principles. The section is structured into three parts: the general algorithm, the dynamic resource weight adjustment strategy, and the enhanced TOPSIS algorithm.
3.1. General Algorithm Framework
This paper introduces a dynamic, multi-dimensional, heterogeneous resource scheduling algorithm based on Kubernetes [
20]. The proposed algorithm integrates a dynamic resource weight adjustment strategy and an enhanced TOPSIS algorithm for real-time node scoring and ranking, thereby enabling precise scheduling of heterogeneous tasks [
21]. The algorithm evaluates the demand and load conditions of various multi-dimensional resources, adjusting the weights of each resource based on real-time data. The enhanced TOPSIS algorithm then assigns comprehensive scores to the available nodes, ensuring that tasks are prioritized and allocated to the most suitable nodes [
22]. Finally, using these node scores, real-time scheduling decisions are made to optimize resource allocation, improving resource utilization and enhancing task execution efficiency.
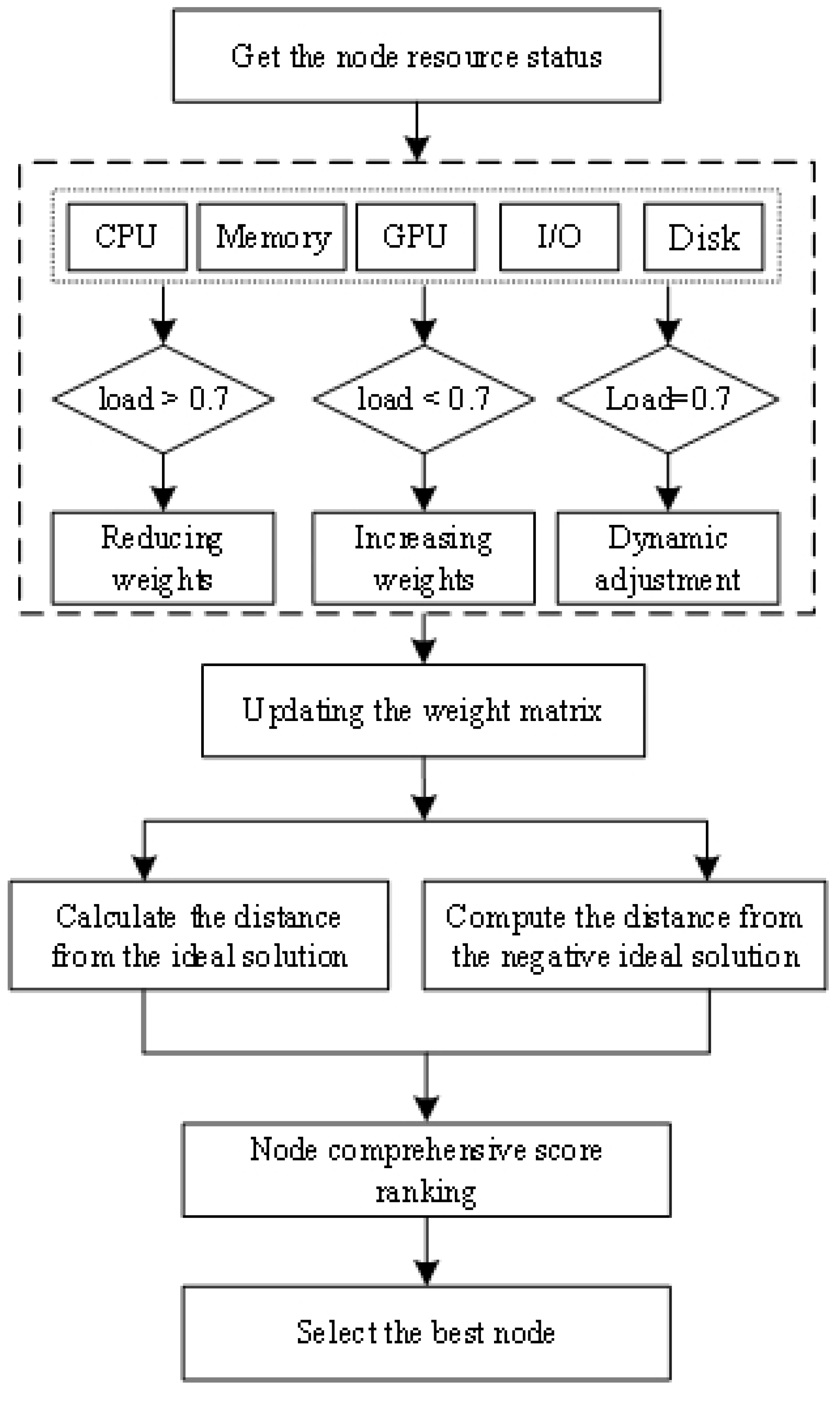
The overall workflow of the proposed algorithm is shown in
Figure 1. It separates the system into three load conditions: load > 0.7, load < 0.7, and load = 0.7. The “load = 0.7” category refers to the case where the load is exactly 0.7. It acts as a boundary between the other two conditions, where the load is either greater than or less than 0.7.
As shown in
Figure 1, the algorithm evaluates the demand and load of various multi-dimensional resources, adjusting the weight of each resource based on real-time data. Once the weight matrix has been updated, the output is divided into two components to assess the relative proximity of the available nodes to both the ideal and negative ideal solutions. This division is a crucial feature of the modified TOPSIS algorithm, which first calculates the distance to the ideal solution and then to the negative ideal solution.
The distance from the ideal solution path measures how closely each node approaches the best performance across all criteria, while the distance from the negative ideal solution path quantifies how far each node is from the worst-case scenario. By evaluating these distances, the algorithm ranks nodes based on their proximity to both the ideal and negative ideal solutions, ensuring tasks are allocated to the most optimal nodes. The modified TOPSIS algorithm then assigns scores to nodes, prioritizing tasks and making real-time scheduling decisions to optimize resource utilization and improve system performance.
3.2. Dynamic Resource Weight Adjustment Strategy
To achieve accurate task scheduling in heterogeneous environments, it is essential to adjust resource weights based on their real-time status and task demands [
23]. We propose a dynamic weight adjustment strategy that prioritizes resources according to task requirements: for CPU- and memory-intensive tasks, CPU and memory resources are given higher weights; for GPU- and I/O-intensive tasks, GPU resources are prioritized; and for disk-intensive tasks, disk weights are adjusted to optimize storage and I/O performance [
24].
The core of this strategy is the real-time modulation of resource importance, driven by cluster load and task needs [
25]. The system continuously monitors resource usage and updates weights to ensure critical resources are prioritized. These adjustments occur dynamically in response to fluctuations in workload and resource availability, with more frequent updates in fluctuating environments and less frequent updates in stable ones. This adaptive approach enhances resource utilization and minimizes waste, making it effective in diverse settings such as mixed workloads or dynamic cloud environments [
26].
The system considers factors such as task characteristics, node resource status, and current load, dynamically adjusting the resource weights using the following Formula (5).
where
is for dynamically adjusting the weight of the resource,
is the initial weight of the resource dimension,
is the current resource state of the node on
,
is the requirement of task
T on
, and
is an adjustment coefficient that controls the degree of influence of resource state differences on weight adjustment.
To ensure that the weight sum of all resource dimensions is one, the adjusted weights need to be normalized, and the normalized weight calculation
is shown in Equation (
6).
The detailed dynamic resource weight control retuning policy is as follows.
The primary goal of Algorithm 1 is to ensure that resource allocation is closely aligned with the specific requirements of the current task, while still maintaining the load-balancing policy. The dynamic weight modulation based on load thresholds (Lines 3–7) prioritizes the use of underutilized resources and helps prevent the overloading of already stressed resources. However, once these load-balancing adjustments have been made, it is crucial to incorporate the task-specific resource requirements into line 8 to ensure that the most suitable resources are assigned to the task. This design does not override the load-balancing mechanism; instead, it enhances it by better aligning resource allocation with the real-time demands of the tasks. By combining dynamic load adjustment with task-specific resource needs, the algorithm achieves a balance between optimal task allocation and overall cluster load balancing.
| Algorithm 1: Dynamic resource weight adjustment strategy |
| Input: Task type T; Cluster load L |
| Output: The adjusted resource weight W |
| 1. W = {GPU: 1.0, CPU: 1.0, Memory: 1.0, Network: 1.0, Storage: 1.0} |
| 2. for each R in W |
| 3. if L[R] > 0.7 |
| 4. // Decrease weight for heavily utilized resources |
| 5. else if L[R] < 0.3 |
| 6. // Increase weight for underutilized resources |
| 7. end if |
| 8.
// Adjust weight based on task needs for resource R |
| 9. end for |
| 10. = sum(W.values()) // Calculate the total weight of all resources |
| 11. For each R in W |
| 12. W[R]/ = // Normalize weights based on the total weight |
| 13. end for |
3.3. Improved TOPSIS Algorithm
To effectively address the multi-dimensional heterogeneous resource scheduling problem, task scheduling must consider not only the availability of resources but also the performance of each node across various resource dimensions [
27]. To this end, we propose an enhanced TOPSIS algorithm, termed Dynamic TOPSIS (D-TOPSIS), which performs comprehensive node scoring and ranking to enable precise resource scheduling. The algorithm evaluates the relative proximity of each node to the ideal solution by simultaneously factoring in resource availability and task requirements [
28]. Based on this evaluation, a scheduling priority is assigned to each node. The specific steps of the D-TOPSIS algorithm are outlined as follows.
According to the resource status of each node in the different resource dimensions, decision Matrix
is constructed, as shown in Equation (
7). There are
m nodes and
n resource dimensions. The decision matrix is
.
where
denotes the performance index of the
i node in the
j resource dimension. Since the units of different resource dimensions vary, the decision matrix must be normalized to ensure comparability across dimensions and eliminate dimensional effects. The normalization formula is given in Equation (
8).
where
is the normalized decision matrix element and represents the normalized value of node
i in resource dimension
j. As per the dynamic resource weight adjustment strategy outlined in the previous section, the resource weights will be dynamically updated based on the current conditions during the scheduling process. Consequently, the weight of each resource dimension will vary at different time points. The formula for calculating the weighted normalized value
is shown in Equation (
9).
where
is the weight
j of the resource dimension. Using the weighted normalized decision matrix, the performance of each node across all resource dimensions can be evaluated. The ideal and negative ideal solutions correspond to the best and worst node performances in each resource dimension. The definitions of ideal solutions
and negative ideal solutions
are given in Equation (
10).
Here,
and
represent the maximum and minimum values for each resource dimension among all nodes. The performance of a node can be quantified by calculating the Euclidean distance between each node and both the ideal and negative ideal solutions, as expressed in Equation (
11).
where
and
are the distances of nodes to ideal and negative ideal solutions. Then, the distance is used to calculate the relative proximity of each node
, which is the ratio of the distance from the node to the ideal solution and the total distance from the ideal solution and the negative ideal solution. The calculation formula is shown in Equation (
12).
where
is the proximity of a node
i, where a value closer to one indicates that the node is better, and a value closer to zero indicates that the node is worse. Finally, the nodes are ranked based on their relative proximity, with nodes exhibiting higher proximity prioritized as scheduling targets. The task is then scheduled to the node with the highest score. The steps of the improved TOPSIS algorithm are outlined below (Algorithm 2).
The D-TOPSIS algorithm enhances the traditional TOPSIS method to address resource scheduling challenges in heterogeneous environments, focusing on dynamic decision-making and adaptability to fluctuating resource demands. It introduces nonlinear normalization to preserve resource data diversity, ensuring accurate evaluations in variable environments. Dynamic weight adjustment adapts the importance of resource types based on real-time data, overcoming static weights. Real-time node scoring and ranking enable dynamic assessment and optimal task–node assignment.
| Algorithm 2: The modified TOPSIS algorithm. |
| Input: Resource matrix R |
| Output: Best node |
| 1. For each node i in R: |
| 2. |
| 3. end for |
| 4. |
| 5. |
| 6. for iter = 1 to MaxIter |
| 7. |
| 8. |
| 9. |
| 10. break |
| 11. end for |
| 12. for i = 1 to n |
| 13. |
| 14. |
| 15. |
| 16. end for |
| 17. |
| 18. |
While these improvements enhance scheduling accuracy, they also introduce computational overhead due to dynamic weight adjustments and real-time scoring. To address this, we utilize parallel computing, enabling simultaneous processing of node evaluations and weight adjustments across multiple cores or systems, thereby reducing computation time. Approximation techniques strike a balance between speed and accuracy, allowing for the efficient handling of large datasets. Incremental computation ensures that only the affected parts of the schedule are updated, minimizing unnecessary recalculations, while hardware acceleration supports optimal performance under heavy loads. In conclusion, despite the computational overhead, these optimizations ensure that D-TOPSIS maintains real-time performance, making it well-suited for scheduling in dynamic, heterogeneous environments.
4. Experimental Results and Analysis
In this section, the key findings of this study are presented. For simplicity, this section is divided into three. This section includes the experimental environment, the measurement indicator, and the analysis of results.
4.1. Experimental Environment
The experiment aimed to assess the effectiveness of the proposed dynamic multi-dimensional heterogeneous resource scheduling algorithm within a Kubernetes cluster environment. The cluster was deployed on Ubuntu 20.04 LTS (Linux Kernel 5.15), with Kubernetes v1.27 as the orchestration platform and Docker v24.0 as the container runtime. The experimental setup was designed to replicate a real-world multi-dimensional heterogeneous resource environment, utilizing both physical and virtual nodes. The specific configuration parameters for the system are provided in
Table 1 and
Table 2.
4.2. Measurement Indicator
In dynamic, multi-dimensional, and heterogeneous resource scheduling based on Kubernetes, selecting appropriate performance metrics is crucial. This study utilized indicators such as task completion time, resource utilization, load balancing, and throughput to evaluate the effectiveness of the scheduling algorithms in terms of resource efficiency, system performance, and task completion effectiveness.
4.2.1. Task Completion Time
Task completion time refers to the duration from the initiation of a task to its completion. In cluster scheduling, minimizing task completion time is a key objective of optimal scheduling. The calculation formula for task completion time is provided in Equation (
13).
where
is the task completion time and
n is the number of tasks. The shorter the
, the more efficient is scheduling.
4.2.2. Resource Utilization
Resource utilization measures the degree to which each resource in the cluster is being utilized. A higher resource utilization rate signifies more efficient resource usage, which in turn enhances task scheduling performance. The formula for calculating resource utilization is provided in Equation (
14).
where
is resource utilization. USE refers to the actual usage of the
i node and
refers to the total amount of resources.
4.2.3. Load Balancing
Load balancing refers to the scheduling algorithm’s ability to distribute workloads evenly across different nodes, preventing some nodes from becoming overloaded, while others remain underutilized. Ideally, the workload should be distributed uniformly across all nodes. The load balancing expression is given in Equation (
15).
where
L denotes the load of the
i node, and
and
are the maximum and minimum load of all nodes.
4.2.4. Throughput
Throughput
refers to the number of tasks a system can complete per unit of time, serving as a key metric for evaluating system efficiency. The calculation formula is provided in Equation (
16).
where
denotes the number of completed tasks,
denotes the time when the last request started,
denotes the time when the last request ended, and
denotes the time when the first request started.
4.3. Analysis of Experimental Results
4.3.1. Task Response Time Testing and Analysis
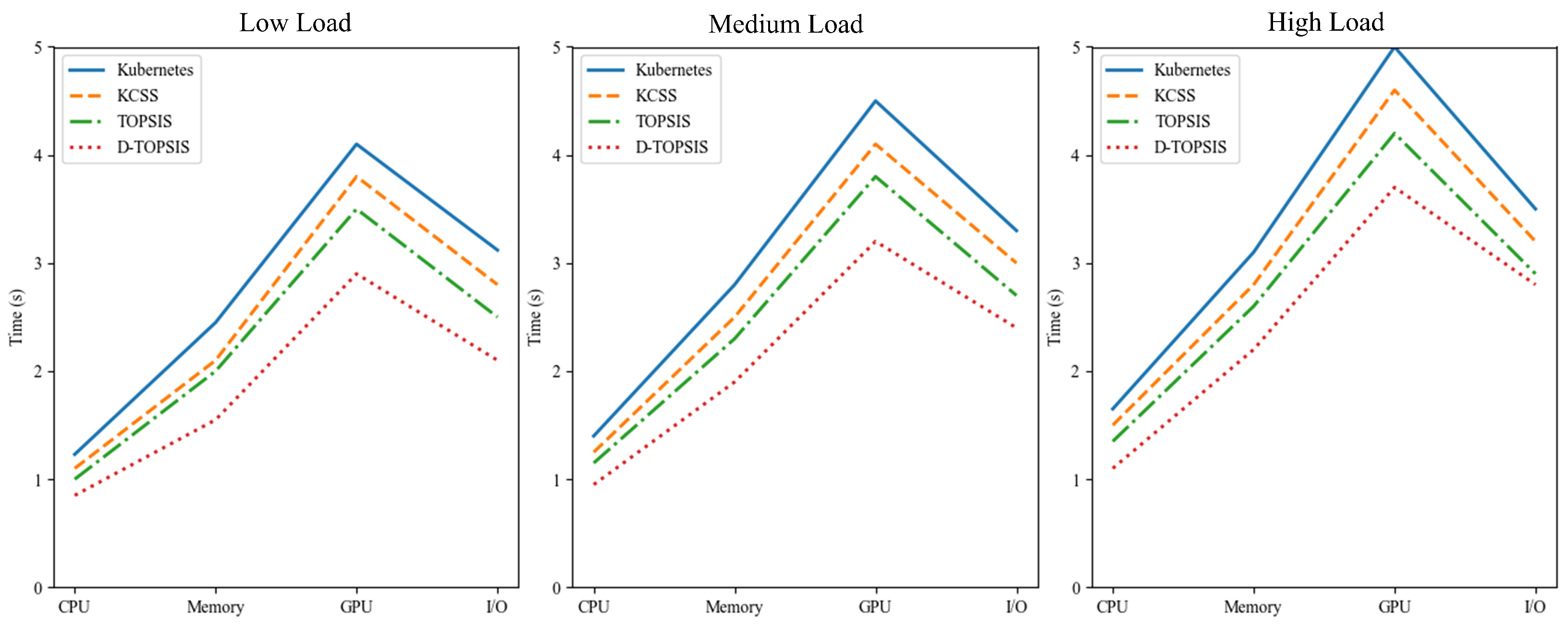
The experimental results are shown in
Table 3, which illustrate that the D-TOPSIS algorithm outperformed the Kubernetes default scheduler, KCSS algorithm, and traditional TOPSIS algorithm across various load conditions, particularly in terms of task response time. Under low-load conditions, the D-TOPSIS algorithm achieved a reduction in task response time by 31% to 36%, highlighting its ability to optimize resource allocation and reduce delays. However, when the system was under high-load conditions, the task response time improvements were slightly smaller due to increased resource contention and the more complex nature of scheduling under heavy loads. Nevertheless, the D-TOPSIS algorithm continued to reduce task response times compared to other methods, demonstrating its robustness and adaptability, even in demanding environments.
Under low-load conditions, the D-TOPSIS algorithm achieved a reduction in task response time by 31% to 36%, underscoring its effectiveness in optimizing resource allocation and minimizing delays. However, under high-load conditions, the improvements in task response time were slightly less pronounced due to increased resource contention and the more complex nature of scheduling in such environments. Despite this, the D-TOPSIS algorithm continued to outperform other methods, highlighting its robustness and adaptability even under demanding, high-load scenarios.
The task response times of the different algorithms under varying load conditions are shown in
Figure 2. The horizontal axis represents the resource requirements for various task types, while the vertical axis displays the corresponding response times. As illustrated in the figure, the D-TOPSIS algorithm consistently outperformed the other algorithms in terms of response time, particularly for CPU-bound tasks, where it demonstrated superior efficiency in allocating CPU resources. As the memory requirements increased, D-TOPSIS maintained the lowest response time, further showcasing its ability to handle memory-intensive tasks effectively. For GPU-intensive tasks, D-TOPSIS achieved the shortest response time, reflecting its adeptness in dynamically adjusting GPU resource weights. Additionally, the algorithm also exhibited the lowest response time for I/O-bound tasks. These results collectively demonstrate that D-TOPSIS achieved consistently lower response times across all resource dimensions, validating the efficacy of its dynamic resource weight adjustment strategy in optimizing task scheduling.
4.3.2. System Throughput Testing and Analysis
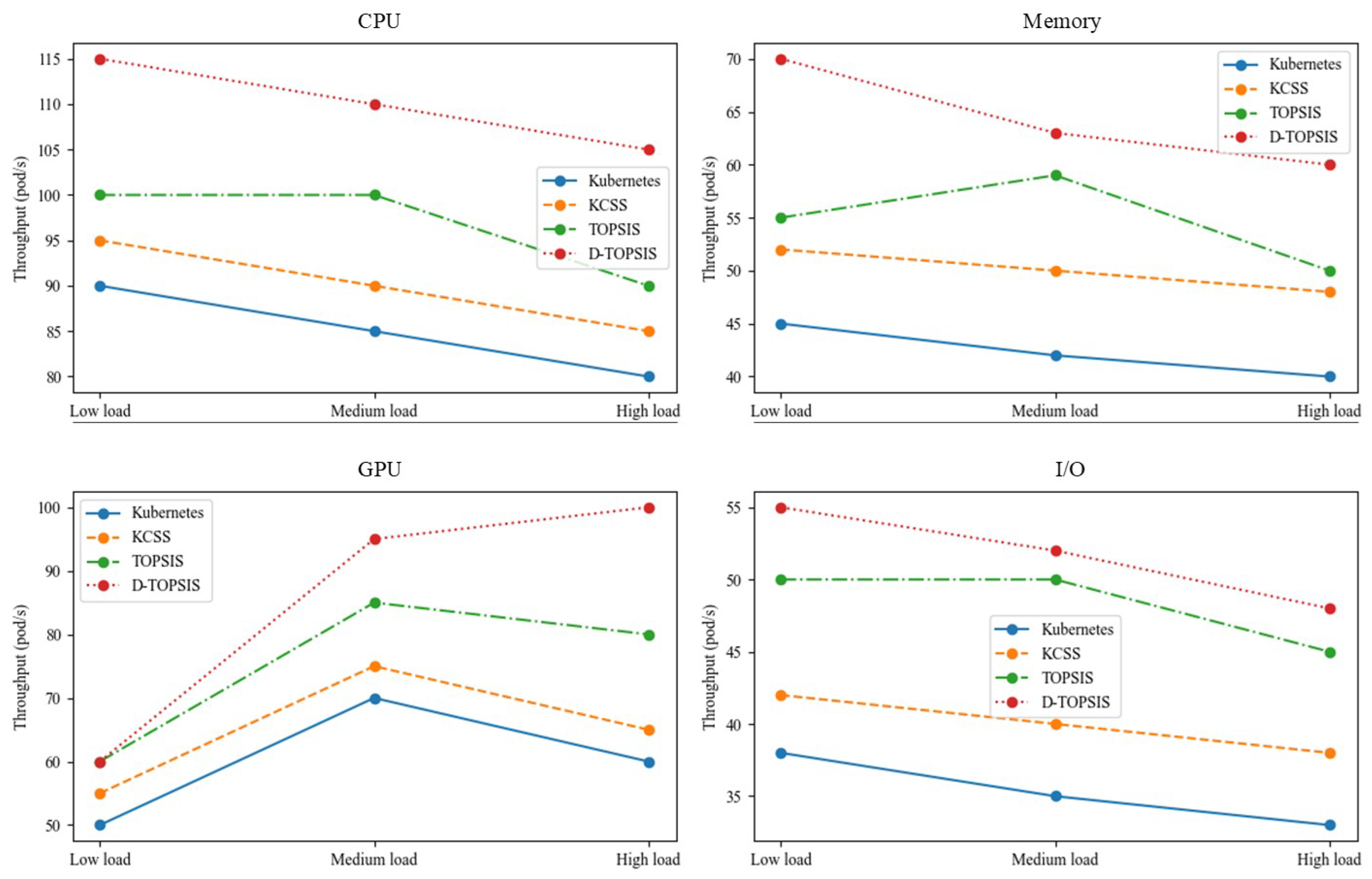
Throughput performance is shown in
Table 4, further supporting the effectiveness of the D-TOPSIS algorithm in high-load scenarios. The results indicate that D-TOPSIS consistently outperformed the other scheduling methods across all load conditions, including high load. Notably, under high-load conditions involving GPU-intensive tasks, D-TOPSIS achieved a 53.8% improvement in throughput over the KCSS algorithm, with throughput increasing from 65% to 100%. This demonstrates that our dynamic scheduling approach can effectively mitigate resource bottlenecks, even when the system faces heavy demand, ensuring optimal utilization of resources. Additionally, in memory-intensive and I/O-bound tasks, D-TOPSIS maintained high throughput, further emphasizing its capability to handle high-load scenarios efficiently.
The throughput performance of each algorithm under varying load conditions was analyzed in detail. As illustrated in
Figure 3, the D-TOPSIS algorithm consistently outperformed all other algorithms in terms of throughput across the different load scenarios and task types. This highlights its superior capability in dynamic resource scheduling. Under low-load conditions, the D-TOPSIS algorithm effectively optimized resource utilization, leading to a significant increase in throughput.
As the system load increased, the D-TOPSIS algorithm maintained a high throughput by dynamically adjusting resource allocation to meet the changing demands. In contrast, the other algorithms struggled to sustain optimal throughput, particularly under medium- and high-load conditions, due to less efficient resource allocation strategies. These findings emphasize the D-TOPSIS algorithm’s robustness and adaptability, demonstrating its effectiveness in optimizing throughput across a wide range of workloads and environments.
The D-TOPSIS algorithm showed impressive results not only under low-load conditions but also in high-load scenarios. While the improvements in task response time and throughput were somewhat smaller under heavy loads due to increased resource contention, the D-TOPSIS algorithm still outperformed the other advanced scheduling methods in terms of both task scheduling efficiency and resource utilization. These results highlight the scalability and robustness of our approach, making it well-suited for dynamic cloud environments that experience fluctuating load conditions.
The proposed D-TOPSIS algorithm consistently outperformed the Kubernetes default scheduler, the KCSS algorithm, and the traditional TOPSIS algorithm in terms of throughput across all test scenarios. Under low-load conditions with memory-intensive tasks, D-TOPSIS achieved a throughput increase of 45% to 70% (a 55.6% improvement) compared to Kubernetes. Similarly, in GPU-intensive tasks under high-load conditions, D-TOPSIS demonstrated a 53.8% improvement in throughput over the KCSS algorithm, with throughput rising from 65% to 100%.
These results emphasize the algorithm’s robustness and scalability, demonstrating that as the system load increases—whether in terms of task volume or resource demand—D-TOPSIS effectively handles larger task volumes and greater resource requirements. Even in resource-intensive scenarios, the dynamic scheduling approach mitigates bottlenecks, ensuring efficient performance and consistent throughput. This confirms that the D-TOPSIS algorithm is capable of scaling with increased numbers of tasks and resources, significantly enhancing the system’s task processing capacity without substantial performance degradation.
4.3.3. Resource Utilization Testing and Analysis
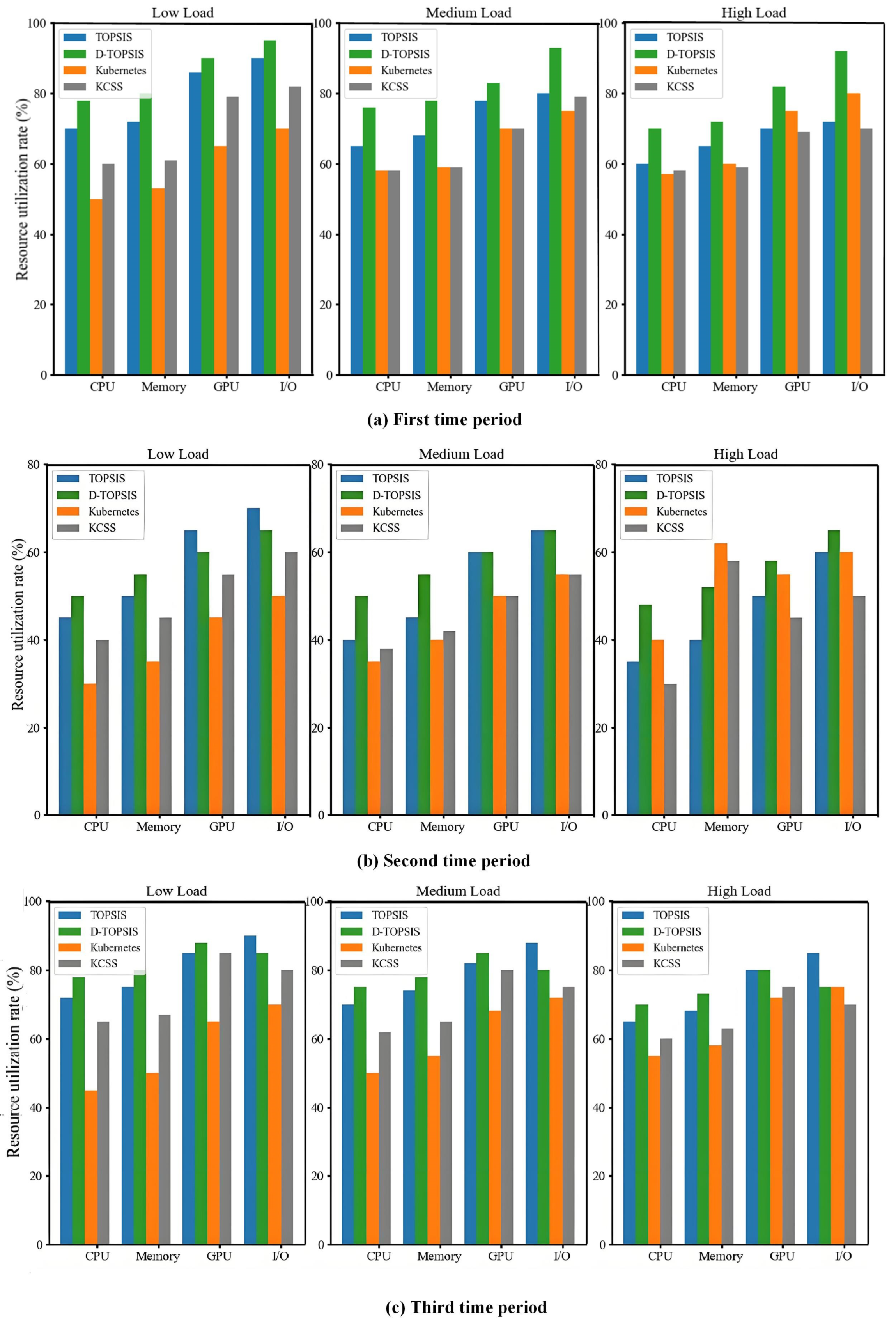
The resource utilization of various scheduling algorithms was assessed over three 30-min intervals, with data collected at the start (0 min), midpoint (15 min), and end (30 min) of each interval. As shown as in the
Table 5, the resource utilization remained relatively low under low-load conditions, increasing with the load. The D-TOPSIS algorithm consistently ensured high resource utilization across CPU, memory, and I/O, whereas both Kubernetes and KCSS exhibited more conservative resource allocation, especially in memory and I/O. During high-load conditions, the resource utilization increased across all algorithms, often reaching or approaching peak values. The benefits of D-TOPSIS were most evident in high-load scenarios, where it optimally utilized CPU, memory, and I/O resources. These findings highlight that D-TOPSIS efficiently allocates resources in high-demand environments, alleviating resource contention and preventing inefficiencies stemming from underutilization.
The resource utilization performance of each scheduling algorithm was evaluated across low, medium, and high load scenarios, as shown in
Figure 4. In the low-load case, D-TOPSIS achieved approximately 95% CPU utilization, significantly outperforming Kubernetes and KCSS. For memory resources, it achieved 90% utilization, while the other algorithms only achieved 68% and 72%, respectively. This highlights D-TOPSIS’s ability to optimize resource usage in low-load conditions, improving overall system performance and efficiency. In the medium-load scenario, D-TOPSIS maintained a high utilization, with memory usage reaching 85%, about 20 percentage points higher than Kubernetes, demonstrating its ability to balance resource allocation effectively, avoiding both underutilization and shortages.
In the high-load case, D-TOPSIS achieved 80% GPU and 75% I/O utilization, compared to only 60% GPU and 55% I/O utilization with Kubernetes. These results emphasize D-TOPSIS’s superior load-balancing capabilities, especially under high-load conditions, where it optimizes resource allocation and maintains system stability. Overall, D-TOPSIS consistently outperformed the other algorithms across varying load conditions, validating its potential for enhancing resource management and performance in dynamic and complex environments.
5. Conclusions
In this paper, we propose a dynamic, multi-dimensional heterogeneous resource scheduling method for Kubernetes that combines a dynamic resource weight adjustment strategy with an enhanced TOPSIS algorithm. This approach overcomes the limitations of traditional scheduling techniques by optimizing task scheduling in real time, reducing resource wastage and delays caused by uneven resource allocation. Experimental results showed that our method outperformed the default Kubernetes scheduler and the KCSS algorithm under low-load conditions, achieving a 31% to 36% reduction in task response time, a 20% to 50% increase in throughput, and a 20% improvement in resource utilization.
Despite these gains, challenges persist in more complex environments with diverse resources, such as specialized hardware accelerators like FPGAs or TPUs. As the cluster size increases, computational overhead may impact scalability and response time. Furthermore, although the load balancing has been improved, certain task types still experience suboptimal distribution, leading to resource underutilization. In future work, we will refine the load balancing strategy to enable more dynamic adjustments based on system load fluctuations. We also plan to improve the scalability and adaptability, allowing the method to handle a wider range of resources and more complex interactions. These efforts will optimize resource utilization and scheduling performance, ensuring efficient operation in large-scale, diverse environments.





{kind=link}
{kind=link}
{kind=link}
{kind=link}