1. Introduction
Backward stochastic differential equations (BSDEs) play a pivotal role in stochastic control theory and have found extensive applications in finance (see [
1,
2,
3,
4]). The linear quadratic (LQ) optimal control problem for BSDEs with deterministic coefficients was first investigated by Lim and Zhou [
5]. They derived a complete solution to such backward stochastic linear quadratic (BSLQ) problems by employing forward equations, limit procedures, and completing squares techniques. Following this foundational work, numerous extensions have been developed, including BSLQ problems under partial information [
6], BSLQ problems with asymmetric information [
7], mean-field backward LQ optimal control problems [
8], BSLQ problems with stochastic coefficients [
9], BSLQ problems with random jumps [
10], the turnpike property of BSLQ problems [
11], BSLQ problems with indefinite weighting matrices in the cost functional [
12], among others.
In the aforementioned literature, no constraints were considered for BSLQ optimal control. However, in practical applications, constraints on states or controls are often inevitable. Examples include the portfolio selection problem with variance investment under the restriction of no short selling of stocks [
13] and the welfare pension problem [
14]. Therefore, studying BSLQ optimal control with state or control constraints is of significant importance. Examples of such constraints include mixed-control-state integral quadratic inequality constraints [
15,
16], conic control constraints over an infinite time horizon [
17,
18], state switching, stochastic coefficients, conic control constraints over finite [
19] and infinite time domains [
20], mixed pointwise state-control linear inequality constraints [
21,
22], and terminal state expected inequality constraints [
23], to name just a few.
Based on the ideas from the aforementioned literature, and as a companion to [
24], which addresses a forward stochastic LQ optimal control problem with a terminal state expected equality constraint, this paper investigates a backward stochastic optimal control problem with an initial state expected equality constraint (CBSLQ for short):
Let
, and consider the underlying filtered probability space
. On this space, a one-dimensional standard Wiener process W is defined. Here,
is the natural filtration generated by W (augmented by all the P-null sets). The expectation operator is denoted by
. The controlled backward linear stochastic differential equation is
with the state
depending on a terminal condition
and a control
u, and the quadratic cost function is
Here, the terminal datum ; the control u; the coefficients , , , , , ; and the operator are subject to appropriate assumptions and will be defined later.
Clearly, the completion of squares method [
24] is not applicable for solving our CBSLQ problem. However, the maximum principle [
8] combined with Lagrange duality theory [
24] provides an effective approach. Our main contributions are as follows: (1) the CBSLQ problem is proposed for the first time; (2) under the uniform convexity of the cost function, an equivalent unconstrained parameterized BSLQ problem is explicitly solved, whose optimal control is feedback based and determined by an adjoint SDE, a Riccati-type ODE, a BSDE, and an equality; (3) the surjectivity of the linear constraint is established with an illustrative example, and the equivalence between the CBSLQ problem and the dual problem of the equivalent BSLQ problem is ensured, thereby obtaining the optimal control for the CBSLQ problem.
The remainder of this paper is organized as follows.
Section 2 introduces basic notations and assumptions.
Section 3 establishes the equivalence between the (CBSLQ) problem and its dual problem under a surjectivity condition. In
Section 4, an explicit solution to the optimal control of the unconstrained problem is derived by using the maximum principle.
Section 5 provides several equivalent characterizations of the surjectivity condition. A financial application of the (CBSLQ) problem to portfolio management is presented in
Section 6. Concluding remarks are given in
Section 7.
2. Preliminaries
Let
be the Euclidean space of all
real matrices (and simply write it as
when
), on which, for any two elements
M and
N, the inner product
is the trace of the matrix
with the transpose ⊤ of matrices and induces the norm of
M as
. Denote as
the space of all symmetric
real matrices. If
is positive definite (positive semi-definite), we write it as
. The same symbols
and
shall be used to denote the inner product and the induced norm, respectively, in possibly different Hillbert spaces
without confusion. Given a measure space
, for a measurable function
, its essential supremum is defined as
. Some spaces of random vectors or random processes are introduced by us as follows.
To make our problem CBSLQ solvable, we introduce some assumptions below.
Assumption 1. The coefficients of the state equation are all deterministic and satisfy the following: Assumption 2. The weighting coefficients in the cost functional are all deterministic and satisfy the following: Assumption 3. Our admissible control set issuch that the mapping is surjective, that is, We say a functional
is called strongly convex [
25] if there exists a constant
,
Lemma 1. Suppose that Assumptions 1 and 2 hold. Then, the cost functional J is strongly convex and continuous on . In addition, if Assumption 3 holds, CBSLQ is uniquely solvable on .
Proof of Lemma 1. By the Assumptions 1 and 2, for each controller (2), there exists a unique solution , and , which is continuous. We need to prove its strong convexity:
Let
Then, by (A1), such solutions as
,
, and
to the systems (2) controlled by
and
, respectively, exist uniquely. Moreover,
In addition, it is easy to check that
Then by Assumption 2,
which means
J is strongly convex on
□
By Assumption 3,
is nonempty. It is also a closed convex subset of
, since the control system (2) is linear and the initial state constraint is a linear equality constraint. Then, by the standard existence theory of convex optimization (see, for instance, [
26], Theorem 2.31), CBSLQ is uniquely solvable.
3. Lagrangian Duality
Inspired by the ideas in [
24], the Lagrangian dual method can be applied to solve the problem
.
Lemma 2. For , we definewhere satisfies (2), and J is the same as the definition (3). If Assumptions 1 and 2 hold, then given , the following unconstrained backward stochastic linear quadratic problem with parameter λ (for short, BSLQu) is uniquely solvable: Proof of Lemma 2. Note first that the mapping is well defined by Lemma 1.
Moreover, given
, there is for
, and
with
,
Then, by Assumption 2, we have
which means that
M is strongly convex with respect to control
u on
. Again, by Theorem 2.31 in [
26], the problem BSLQu is uniquely solvable. □
Clearly, under the Assumptions 1 and 2, by (4)
Therefore, the original CBSLQ is equivalent to
Now, we define the dual problem of CBSLQ:
In what follows, we prove the strong duality between CBSLQ and its dual problem (6)
Theorem 1. Assume Assumptions 1–3 and let be the unique optimal solution to CBSLQ. Then, the following two assertions hold true.
(i) The strong duality between CBSLQ and unconstrained problem (6) holds true, i.e., (ii) Let be the solution to the dual problem (6); then, is a , i.e., Proof of Theorem 1. Clearly,
is a convex set. In the following, we will prove that
is also a convex set. Let
; then, there exist
such that
By Lemma 1, J is convex. Then, for any
,
From (2), obviously, there is a unique solution
satisfying
such that
satisfy the linearity in (2). Thus,
Therefore,
Therefore,
is also a convex set.
By the optimality of
, we deduce that
. Then, by the separation theorem,
,
such that
Then, we have
,
, and
We claim that
. If
, then
Then, by Assumption 3,
. This contradicts
. Therefore,
.
Letting
, we have
Since
it holds that
This implies that
Since there is
This proves (i).
The following proves the assertion (ii). Let
in
be the unique optimal solution (which exists by (i)); then, we have
By the optimality of
and
,
Thus,
is a saddle point of
M. Then, it follows that
□
4. Maximum Principle
The effient method for the solving backward stochastic linear quadratic problem in [
8] can be used to solve our BSLQu.
Lemma 3. Suppose that Assumptions 1 and 2 hold. If is the optimal triple of BSLQu with parameter λ, thenwhere the process is the solution to the following SDE Proof of Lemma 3. Let
be the optimal control of BSLQu (4); then, for any
and
,
where
is a solution to (2) with the terminal state
. Then, we get
Moreover, with the help of Equation (8) and by applying It
’s formula to
, the following result is given
Therefore,
Next, set
Then,
is continuously differentiable with perturbed parameters
, and we obtain
We directly claim that (7) holds, since
v is arbitrary.
From the above result, we see that if
u happens to be an optimal control of BSLQu, then the following FBSDE admits an adapted solution
:
and the following stationarity condition holds:
□
We call (8), together with the stationarity condition (11), the optimality system for the optimal control of CBSLQ. Note that the four-step scheme introduced in [
27,
28] for general FBSDEs has provided an efficient skill to solve this special FBSDE (10).
In fact, due to the linearity of BSLQu, there is also a linear relation between and , as shown in the following lemma.
Lemma 4. In the FBSDE (10), there is, for ,where the matrix-valued function P satisfies the Riccati-type ODEand the process pair satisfies the BSDE Proof of Lemma 4. Assume that
where
is absolutely continuous, and a process pair
satisfies the following BSDE
for some adapted process
.
Applying It
’s formula to Equation (14) together with (15) and (10), we have
Then, we can suppose that
and
Now, from (17) we have
where
I is the
identity matrix. Then, substituting it into (16) gives
From the above equation, one can take
Comparing the terminal values on both sides of Equations (10) and (15), one has
. Then, there are two equations, the ODE (13) and the BSDE (15). According to Assumptions 1 and 2 and Proposition 4.1 in [
5], each of the two equations has a unique solution. Thus, Equation (12) follows. □
Moreover, we can obtain the optimal cost function of the BSLQ as in the following lemma.
Lemma 5. Suppose that Assumptions 1 and 2 hold. Then, the cost function for the optimal triple iswhere and are defined in Lemma 4. Proof of Lemma 5. Note that, according to the formula (4),
On one hand, according to the three equalities (11), (12), and (18), we have
On the other hand, by applying
’s formula to
, we have
Then, combining (19) with (20), we get
Since it can be obtained from (11) and (12) that
we obtain
Substituting the above expression into (21) gives the result immediately. □
According to the above lemma, we can construct an optimization problem
which can be solved easily.
Lemma 6. Suppose Assumptions 1 and 2 hold. Then, for the optimization problem (22), there is a unique optimal satisfying the following linear algebraic equations Proof of Lemma 6. First, we prove that
. According to Assumption 3, the matrix
N is full rank, and
is a positive definite matrix. Therefore,
is also a positive definite matrix, i.e.,
. Obviously, the dual function
d on
defined by the Lagrange multiplier method is concave and differentiable. Then, its optimal solution
satisfies the first-order optimality conditions, that is
Since , the matrix is invertible. Therefore, there exists a unique that satisfies the above equation. □
Now, we can state our main theorem about our original problem, the CBSLQ, whose proof is similar to that of Theorem 3.2 in [
24] based on Lagrangian duality theory. We provide the details in the next section for readers’ convenience.
Theorem 2. Suppose Assumptions 1–3 hold. Then, the optimal control of CBSLQ iswherewith and respectively determined by the ODEand the BSDE Proof of Theorem 2. It follows from Lemma 1, Lemma 2, Lemma 3, and Lemma 6, and Theorem 1 in
Section 3. □
5. The Characterization of Condition (Assumption 3)
In this section, we will investigate the equivalent characterizations of condition (Assumption 3). The basic idea is from the fundamental controllability argumentation for deterministic controlled linear systems (see, for instance, [
29]). In order to characterize the condition (Assumption 3), let us consider a special CSBLQ with Assumption 1 holding true:
Define the Lagrangian functional for (23) by
for
and
.
Then, by Lemma 3.1 and Lemma 3.2, for a given
, for the problem
there is a unique optimal control
satisfying, for
,
with the process
being the solution to an adjoint equation
By applying
’ s formula together with the Equations (26) and (25), we have
We have the following result.
Lemma 7. If is the optimal solution tothenis the optimal solution to (23), where is the solution to (26) with initial datum . Proof of Lemma 7. Since
is the optimal solution, for any
,
Let
be the solution to the controlled system (2) with terminal datum
and control
defined by (28). Then, by (28) and (29) and
’ formula,
Due to the arbitrariness of
, we obtain
This proves that the control
defined by (28) is a feasible control.
Next, we prove the optimality of
. Replacing
by
in (30), we obtain
Note that for any
with the corresponding state
such that
by
’s formula,
Combining (31) with (32), we obtain
This proves the optimality of
. □
The following theorem gives a necessary and sufficient condition for being a surjection.
Theorem 3. Suppose that Assumptions 1 and 2 hold. Then, is a surjection if and only if there is such that ,where is the solution to (26) with initial datum . Proof of Theorem 3. We first prove the sufficiency.
For arbitrarily , let be the dual function defined in (27) with b replaced by . If there is such that (33) holds, then is coercive. Since the convexity and continuity of are obvious, the dual problem (27) with b replaced by has a solution Then, by Lemma 7, the control defined by (28) with replaced by is a minimal norm control such that . By the arbitrariness of , the mapping is surjective.
Next, we prove the necessity.
Suppose by contradiction that
is surjective but the inequality (33) does not hold. Then, there is a sequence
such that
, and
Without loss of generality, assume that
converges to some
with
. Then,
Therefore, Since is surjective, for any , there is u such that .
Let
; then,
By the arbitrariness of , we have , contradicting . This completes the proof. □
6. An Illustrative Example
Here is a simple practical application problem to support our theory. This example demonstrates the practical value of the theoretical results in
Section 3,
Section 4 and
Section 5. We consider a backward portfolio management problem with a constraint expectation of initial state
under the following backward stochastic linear equation in terms of
controlled by
u:
Here,
is the investment strategy adjustment variable at time
(such as the adjustment of the capital allocation proportion), which is adapted to the known noise of standard Brownian motion
W and constrained by the expected value of the initial investment portfolio
b;
represents the value of the investment portfolio; and
is the market fluctuation factor (such as the fluctuation of the market index). Among the other parameters,
represents the expected growth rate of the investment portfolio itself, and
represents the impact coefficient of the investment strategy adjustment on the value of the investment portfolio.
Then, according the discussions in the above sections, there is a corresponding Riccati ODE in terms of
P,
an ODE in terms of
,
and an ODE in terms of
,
Clearly, we have explicit solutions, respectively, for
,
Then, we can solve the dual problem
whose unique optimal solution is
Therefore, the optimal control has the explicit representation
Table 1 shows optimization results under different parameter combinations.
Economic Explanation:
(i) Time Effect: As the investment horizon T increases, the optimal control intensity decays at a faster rate (exponential term ), which aligns with the practical understanding that long-term investments should reduce trading frequency.
(ii) Risk Budgeting: The exponential decay characteristic of indicates that the system allocates a decreasing risk budget over time, providing a quantitative tool for dynamic risk control.
(iii) Constraint Effectiveness: By setting the initial expectation
b, investors can precisely control the statistical properties of the portfolio value (see
Table 1).
(iv) Computational Superiority: The explicit solution avoids iterative numerical optimization, providing a real-time strategy generation method for high-frequency trading scenarios.
(v) Scalability: The model parameters (0.03 growth rate, 0.2 control coefficient) can be extended to time-varying functions, adapting to complex market environments.
The expected value equality constraint of
indicates that the expected value of the initial investment portfolio is b. It is an initial reference point set by the investor and is used to measure whether the starting point of the investment portfolio meets the expectations. The variance of the investment portfolio value reflects the extent to which it deviates from the expected path due to factors such as market fluctuations and uncertainties in investment strategies. The larger the variance, the higher the uncertainty of the investment portfolio value is while the greater the investment risk is. Generally, investors hope to minimize this variance under a given expected return level. This leads to solving the following stochastic LQ problem with initial state constraint:
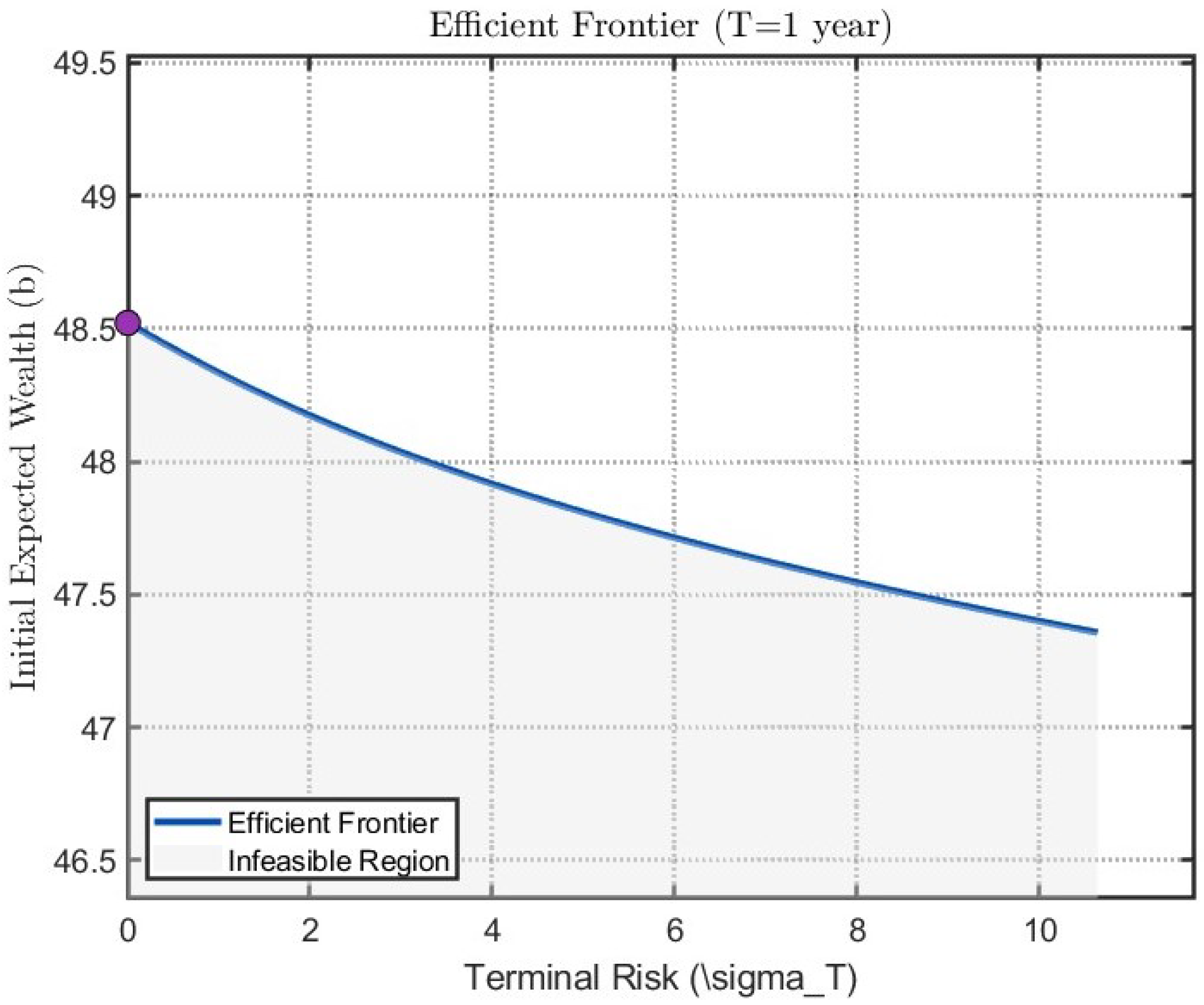
We show in
Figure 1 the efficient frontier of the above portfolio management problem for
and
. The efficient frontier graph illustrates the trade-off relationship between the initial expected return b and terminal risk (standard deviation), exhibiting a characteristic convex decreasing curve (consistent with high-risk-high-return theory), which validates the core theoretical proposition of the model: precise risk-return management can be achieved through backward stochastic control. The purple point on the graph represents the maximum return point, while the shaded area denotes the infeasible region where no strategy can simultaneously deliver higher returns and lower risk.
This example visually confirms three key values of the model through the efficient frontier: (1) the initial constraint b enables precise control of the investment starting point; (2) dynamic strategies can generate Pareto-optimal paths; (3) parameters (e.g., the 0.2 adjustment coefficient) possess clear economic significance. In practical applications, this framework provides quantitative tools for structured product design and dynamic pension fund allocation.



{kind=link}