1. Introduction
Research on financial market risk plays an important role in understanding the operating mechanism of the financial market, improving the financial theoretical system, evaluating and managing investment risks, etc. Volatility is an indicator that measures the range and frequency of market price changes over a period of time, reflecting the uncertainty of financial asset prices and the risk of asset investment [
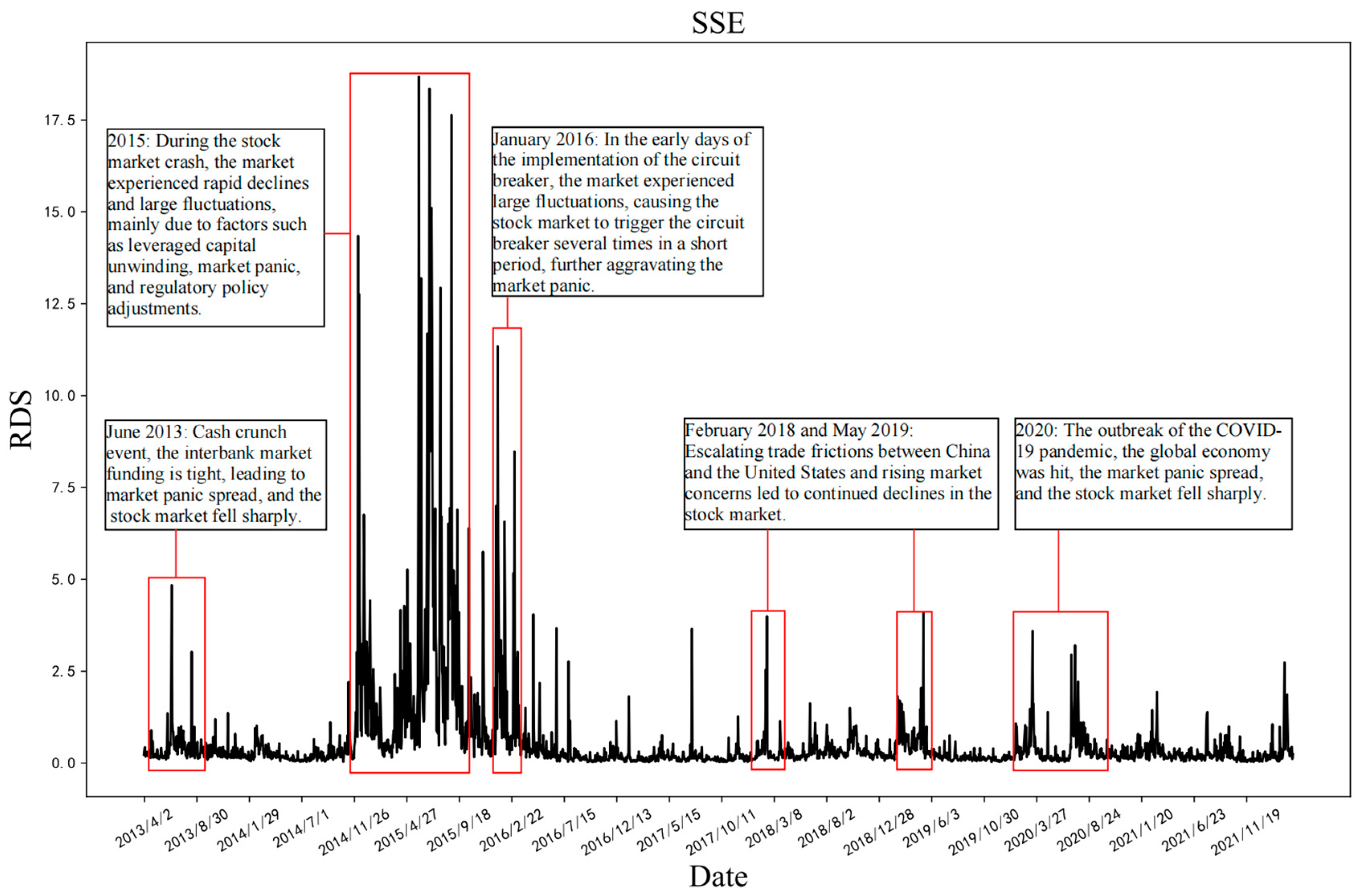
1]. Although volatility is a common risk measure, it measures both the upward and downward movements of asset prices. However, investors generally pay more attention to the potential losses caused by falling asset prices, known as downside risk. Therefore, the research on downside risk, especially the prediction accuracy of the downside risk measurement index, also known as realized downward semi-variance (RDS), is of great significance to help investors reduce extreme losses and assist financial institutions in effectively evaluating risk management strategies.
According to whether various factors of the market are included, volatility prediction models are divided into autoregressive models and multiple regression models. The autoregressive model realizes reasonable prediction by capturing the features of volatility itself. Early scholars estimated and predicted volatility under low-frequency data through traditional econometric models, such as the autoregressive conditional heteroskedasticity (ARCH) model [
2], the generalized autoregressive conditional heteroskedasticity (GARCH) model [
3], and stochastic volatility (SV) model [
4]. These models can extract the linear and deterministic information and save the uncertain information in the residual sequence. However, it usually needs to satisfy the assumptions of a linear relationship, stationarity, a normal distribution, etc., so it has obvious shortcomings when dealing with complex nonlinear high-dimensional data. With the continuous improvement of the accessibility of high-frequency data, its rich intraday feature information is gradually mined and utilized, and many scholars consider increasing the modeling frequency down to the day and minute. Andersen and Bollerslev [
5] proposed realized volatility (RV) and provided a method to estimate volatility directly from intraday high-frequency data by calculating the cumulative square daily return under high-frequency data. Thus, the potential unobservability of volatility and the estimation of conditional variance can be effectively solved. Classical RV models include the autoregressive fractionally integrated moving average-RV (ARFIMA-RV) model proposed by Andersen et al. [
6] and the heterogeneous autoregressive-RV (HAR-RV) model proposed by Corsi [
7], which characterized the autocorrelation and long memory characteristics of RV to achieve effective prediction. Izzeldin et al. [
8], Liang et al. [
9], and Korkusuz et al. [
10] forecast multi-market and multi-stock RV based on the HAR model, the HAR-RV-Average model, and the HAR-RV-X framework, respectively.
Although the traditional econometric model can describe the volatility aggregation characteristics and has the advantages of clear statistical principle, strong explanation, clear structure, and stable parameters, the model has strict requirements on assumptions such as data distribution, which makes it difficult to fully capture the nonlinear relationship in the time series, and has high processing cost and limited prediction accuracy. Therefore, machine learning models, which are good at capturing complex nonlinear relationships and extracting high-dimensional data features, are widely used to predict RV in financial markets with non-stationary, nonlinear, aggregated, and jumping characteristics. For example, Fałdziński et al. [
11] applied support vector regression (SVR) to predict the volatility of energy commodity futures contracts such as crude oil and natural gas. Compared with the single machine learning model with outlier sensitivity and weak generalization ability, the ensemble machine learning model achieves a more robust prediction model by combining multiple weak learners. For example, Luong and Dokuchaev [
12] and Demirer et al. [
13] used RF models to forecast the RV of the stock index and crude oil, respectively. However, the ensemble learning model still needs a lot of feature engineering work, and the ability to process high-dimensional complex structure data needs to be improved. Compared to the ensemble learning model, the deep learning model approximates complex nonlinear features infinitely using multi-layer nonlinear transformation and has strong automatic feature learning and generalization ability. Traditional deep learning models, such as long short-term memory (LSTM) and the gated recurrent unit (GRU), have been widely used to predict financial stock market volatility [
14,
15,
16].
The trend and fluctuation of the financial stock market are easily affected by company fundamentals, macroeconomic factors, market sentiment, and other aspects. Multiple regression methods can consider multiple influencing factors at the same time, conduct a comprehensive analysis of the financial market, extract relevant features, and accurately understand market dynamics. Some scholars use multivariate regression models to forecast RV in the stock market. For example, Todorova and Souček [
17] incorporated overnight information flow into the RV prediction of ASX 200 and seven highly liquid Australian stocks. Audrino et al. [
18] made use of a large amount of emotion and search information on the website, combined with emotion classification technology, an attention mechanism, and the high-dimensional predictive regression model, to predict volatility. Kim and Baek [
19] proposed the FAHAR-LSTM model, which incorporated multiple relevant transnational stock market volatility information into the RV prediction of the Asian stock market. Kambouroudis et al. [
20] extended implied volatility (IV), the leverage effect, and overnight returns into the HAR and predicted the RV of 10 international stock indexes. Lei et al. [
21] used the LSTM model to forecast stock RV by taking trading information, on-floor trading sentiment, and unstructured forum text information as input variables. Jiao et al. [
22] took trading information and news text information in the crude oil market as input variables and used the LSTM to forecast the RV of crude oil. Ma et al. [
23] proposed a parallel neural network model of CNN-LSTM and LSTM based on mixing big data, which considered a variety of micro and macro variables and processed mixed frequency data through the RR-MIDAS model. Zhang et al. [
24] introduced transaction information and sentiment indicators into the LSTM model, combined with the jump decomposition method, to predict RV.
There are two shortcomings in the existing literature. First, most of the target variables for prediction focus on RV, which is used as an indicator to measure risk. RV is calculated by the sum of the squares of the intraday high-frequency logarithmic returns, so falls and rises in stock prices have the same effect on RV, but it should be noted that there is significant leverage in the market, and the distribution of returns is asymmetric. Granger [
25] points out that the risk of an investment is mainly related to low or even negative returns. In reality, investors tend to be more sensitive to investment losses, and the left tail of the return distribution constitutes a downside risk, which can better reflect investors’ concern about trading losses. However, RV ignores the effect of leverage on stock market transactions in the calculation process, making it difficult to reflect investors’ concerns about downside risks. Barndorff-Nielsen et al. [
26] proposed the RDS based on the high-frequency negative return rate. Therefore, this paper takes high-frequency RDS, which is more concerned with the market, as the forecast object and fully studies the amplitude and frequency of downward fluctuations of asset prices.
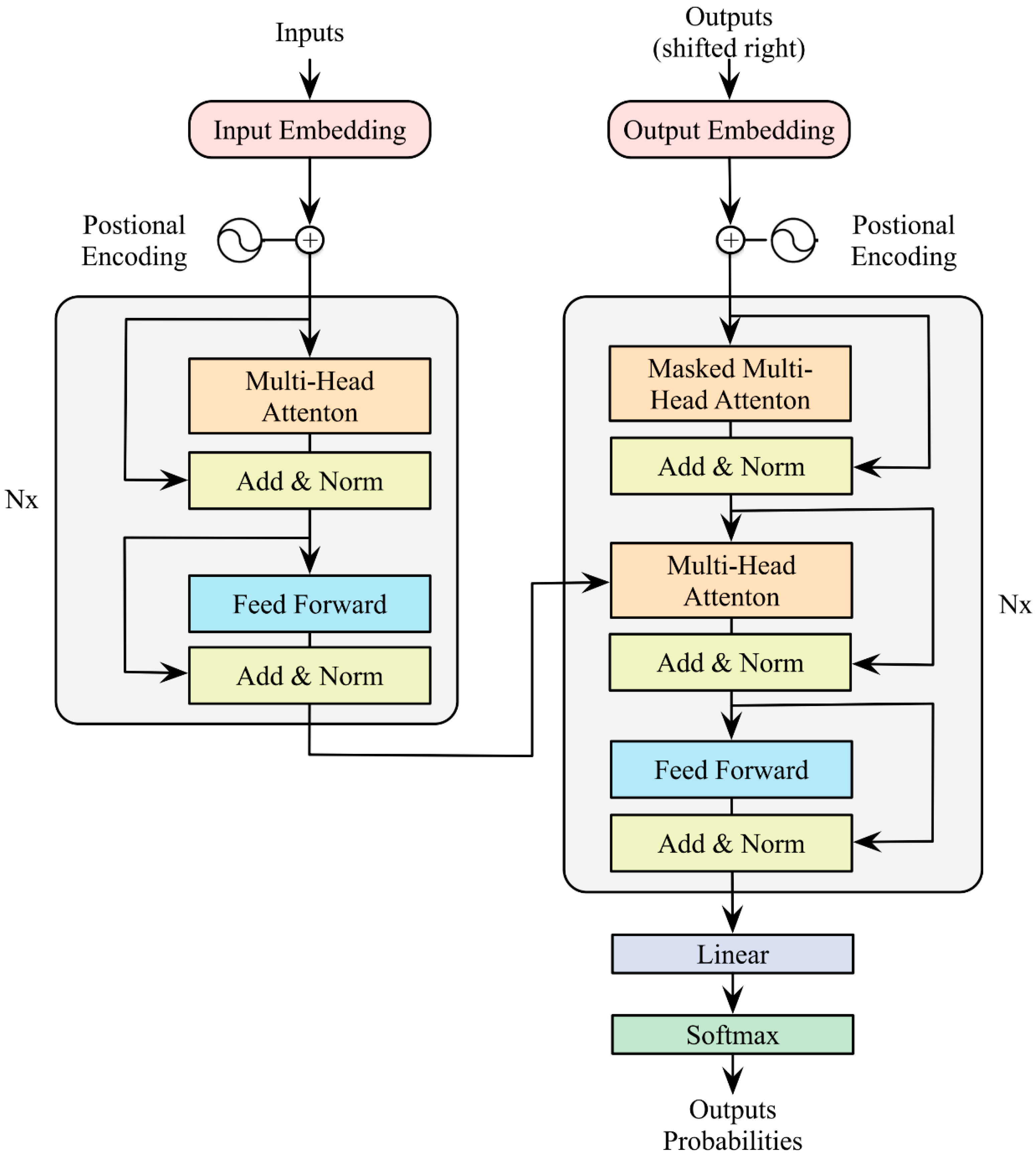
In addition, from the perspective of volatility prediction models, most studies use traditional deep learning models (RNN, LSTM, and GRU) to predict volatility. According to the descriptive statistical analysis below, it can be found that RDS has a strong long-term autocorrelation, but the traditional deep learning model cannot capture global information and deal with long-distance dependencies in long sequences. Therefore, this paper adopts a new deep learning model called Transformer, which abandons the cyclic structure of recurrent neural networks (RNNs) and uses self-attention mechanisms and parallel computation to process sequential data. The model is not only good at capturing global information and long-term dependencies but is also able to capture ultra-short-term feature changes, which is suitable for RDS data with long-term autocorrelations and short-term aggregation jumps.
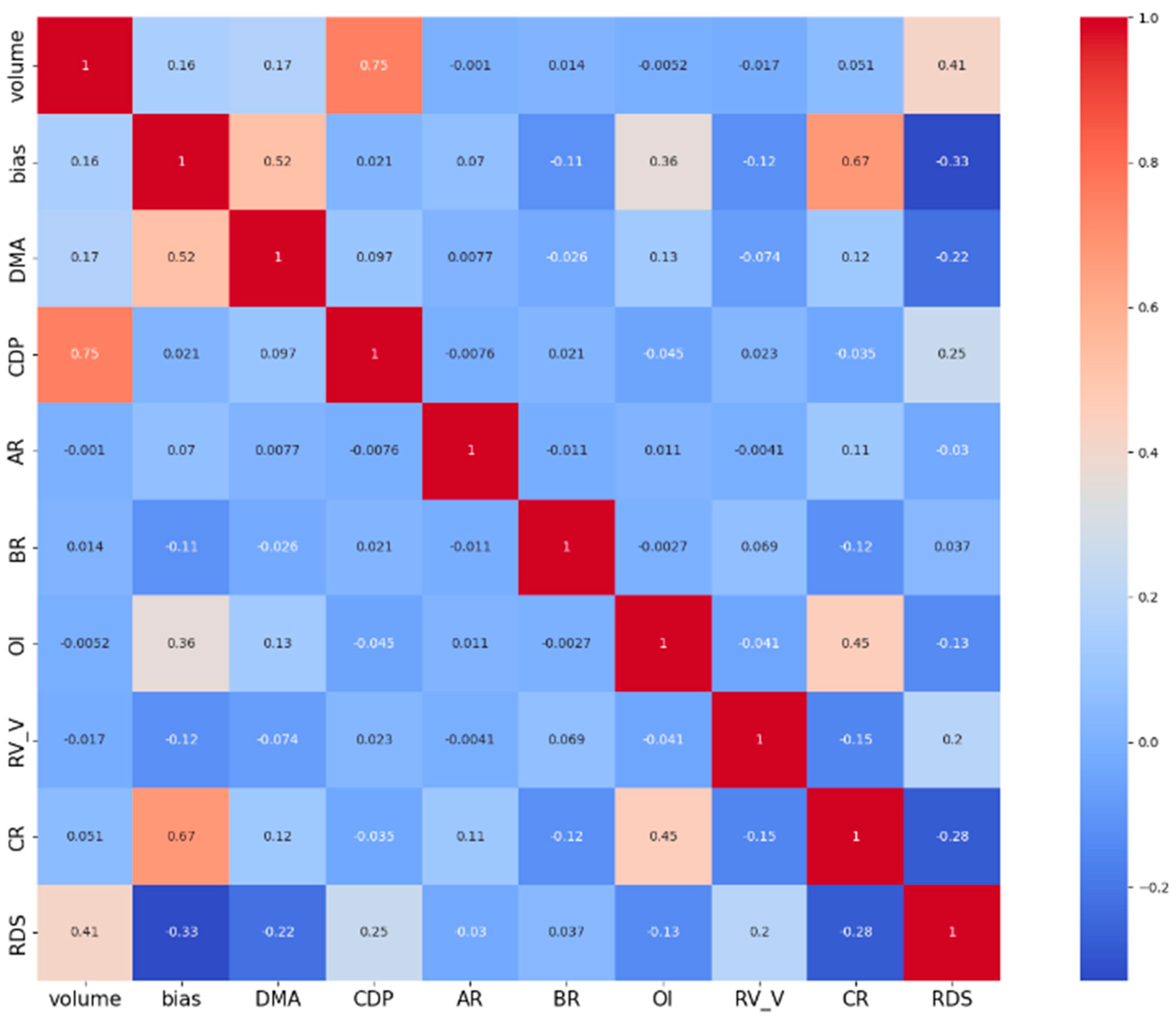
To sum up, compared with the existing literature, this study is more in line with the downside risk indicator RDS of investors’ risk preference. Multiple factor variables related to RDS, including market trading information, floor trading sentiment, the volatility of trading indicators, etc., are selected to study the correlation between various influencing factors and RDS. Secondly, the downside risk measure RDS is predicted and analyzed using a multivariable Transformer prediction model that is good at capturing global information and short-term characteristics. Finally, various evaluation criteria and the DM test are used to analyze the sensitivity of scroll window size, prediction step size, and prediction model performance. The robustness of the model under structural fracture, the influence of the emotion index on model prediction, and the RDS prediction results under the stacked-ML-DL framework are discussed.
The marginal contribution of this paper mainly includes the following three points:
- (1)
Predict objects: Compared with the existing literature, the research objective of this paper focuses on downside risk measurement, also known as RDS prediction based on high-frequency data. The downside risk is consistent with investors’ risk preference, which describes the potential loss of the portfolio. The study of downside risk measurement RDS is conducive to further distinguishing the impact of different price changes on market risk and traders’ behavior and more accurately capturing the negative volatility characteristics of assets, thus helping traders avoid possible major losses when the market falls and optimize the investment portfolio to achieve more robust investment returns.
- (2)
Prediction model: In this paper, combined with multiple market influencing factors such as trading volume, trading volume volatility, overnight information, turnover rate, and moving average, Transformer is used to forecast RDS. Compared to traditional deep learning LSTM and GRU models, the Transformer model uses a self-attention mechanism to simultaneously process global data, which is better able to capture long-distance dependencies when processing the long series data. In addition, the model abandons serialization processing and makes full use of the advantages of parallel computing to effectively improve the model’s training and operation efficiency. By inputting a variety of relevant variables into the Transformer model, its high computation and strong long-range capture capability can be used to improve the prediction accuracy and efficiency of RDS. In addition, the predictive effects of the ML and DL stack models are discussed and compared with the single Transformer model.
- (3)
Sensitivity analysis: In this paper, a variety of evaluation criteria and improvement ratios are used to explore the impact of the size of each model’s rolling window on the prediction accuracy under one-step prediction. In addition, by studying the evaluation criteria results of each model under different prediction lengths, the robustness of each model is analyzed and tested. Combined with evaluation criteria and the DM test, the results of one-step prediction and multi-step prediction among different models are compared, and the accuracy and robustness of the Transformer model in RDS prediction are comprehensively tested through event shock and emotion factor analysis.
The research content of this paper is to construct a Transformer multivariable model to predict the RDS and analyze the empirical results. The remainder of this article is structured as follows:
Section 2 defines RDS and introduces the Transformer model and prediction evaluation methods. In
Section 3, multivariate rolling prediction is carried out by combining nine forecasting variables, demonstrating the empirical results of various multivariate forecasting models, and using a variety of evaluation criteria, the DM test, and other methods to analyze the sensitivity of the rolling window length, prediction length, and prediction model to give the optimal model.
Section 4 discusses the robustness of the model under event shock and the influence and effect of adding an emotion index on the RDS prediction models.
Section 5 explores the forecasting performance of the stacked-ML-DL hybrid forecasting framework and provides empirical analysis.
Section 6 summarizes the content of the paper and provides its limitations and future extension.
5. Discussion
Based on the above analysis of the forecasting effect of the single model, this section discusses the forecasting effect of an advanced stacked hybrid model and its advantages [
29]. The main idea of the stacked model is as follows: The first layer of the model will train multiple base models (including machine learning, deep learning, etc.) to initially predict the target variables. The second layer of the model uses the prediction results of the base model as input features to train simple models (such as linear regression). This layer in the model learns the assigned weight of each base model, integrates the prediction results of each base model, and uses the model output as the final prediction result to complete the hybrid model’s prediction. According to the previous analysis of prediction results, the Transformer model with the best overall prediction effect of a single model is compared with two stacked hybrid models (stacked-ML and stacked-ML-DL). Stacked-ML includes submodels for SVR, RF, XGBoost, and Ridge, while stacked-ML-DL includes submodels for SVR, RF, XGBoost, Ridge, LSTM, GRU, and Transformer. Using linear regression as a meta model, the predicted value of each model is taken as the feature; the real value is taken as the target, and the linear regression model is trained to learn the weight. Taking SSE as an example, the one-step prediction evaluation results of RDS under different rolling windows are shown in
Table 10.
As shown in
Table 10, stacked-ML-DL has the best prediction effect on the whole. From the point of view of the setting of the rolling window, it is consistent with the conclusion of the single prediction model. When the window size is 20, the overall prediction error of each index is the lowest. From the perspective of the prediction model, the stacked model can effectively adapt to changes in historical data distribution, control model complexity, reduce overfitting, and improve model prediction accuracy through the complementarity between multiple base models and the adjustment of base model weights by the second-layer model according to data changes. Taking SSE as an example, when selecting the rolling window as 20, the error evaluation criteria RMSE, MAE, MAPE, SMAPE, MBE, and SD of the stacked-ML-DL model are 0.2810, 0.1795, 0.8997, 0.5657, −0.0087, and 0.2808, respectively. The advantage of the stacked model is that by combining the prediction results of multiple models, using the sensitivity of different models to different aspects of the data, reducing the possible bias and variance of the single model, and capturing the complex pattern of the data to improve the overall prediction accuracy. Stacked models can be adapted to various types and lengths of data without strong dependence on a particular model or algorithm. Moreover, through regularization of the second layer model, the stacked model can effectively reduce the overfitting risk when the base model is relatively complex, and the second layer model can provide the contribution degree or weight of each base model, improving the explainability of the model.
6. Conclusions and Extension
The downside risk refers to the risk that the asset value is lower than the expected target, which describes the extent of losses that investors may face. Its importance lies in that it is consistent with investors’ sensitivity to losses, which helps investors better evaluate potential losses and achieve more stable investment returns. In this paper, RDS is used to measure the downside risk, and multiple predictive indicators, as well as traditional econometric models, machine learning models, traditional deep learning models, and Transformer, are combined to predict RDS. Furthermore, the sensitivity analysis of the rolling window length, prediction length, and prediction model is carried out using various evaluation criteria, the DM test, etc.
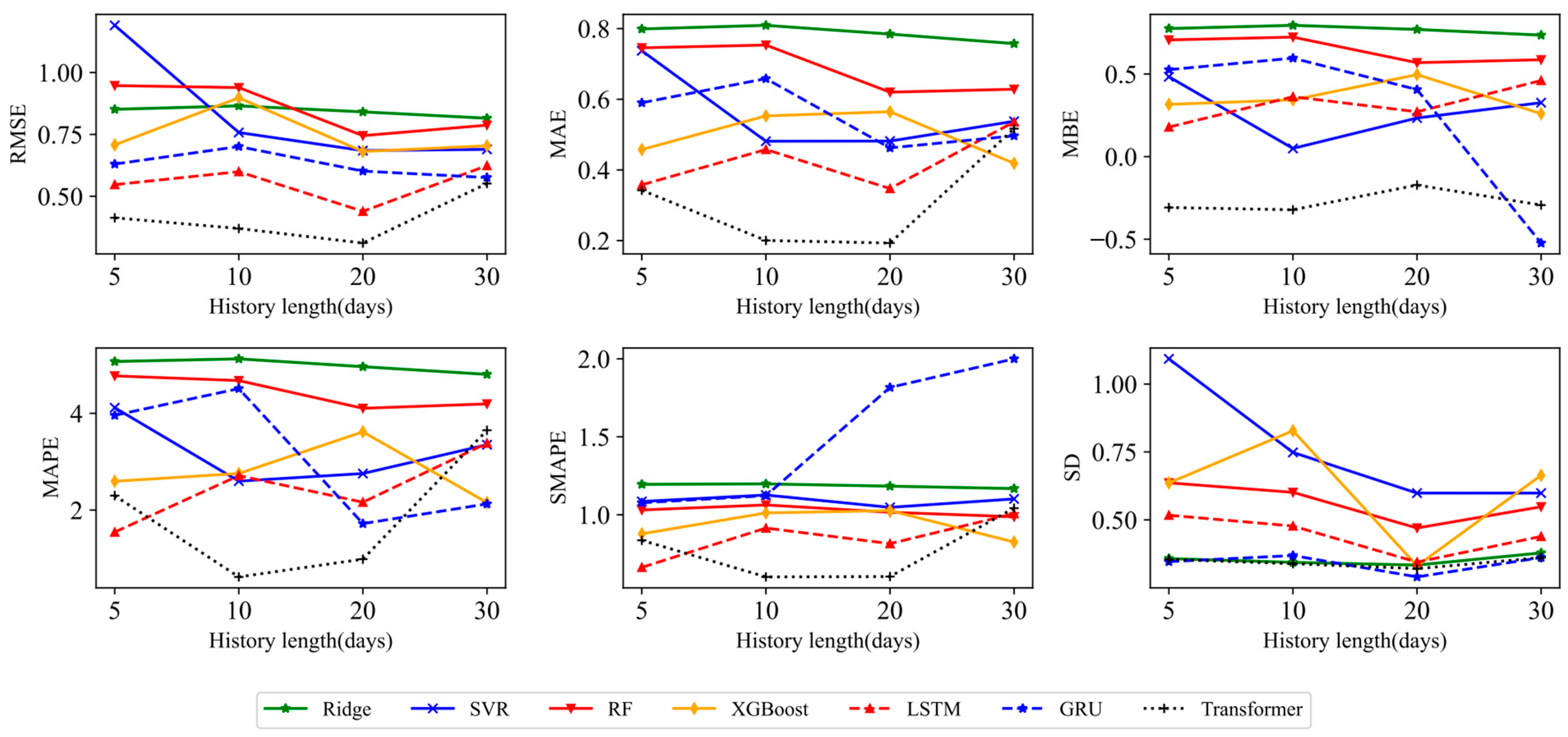
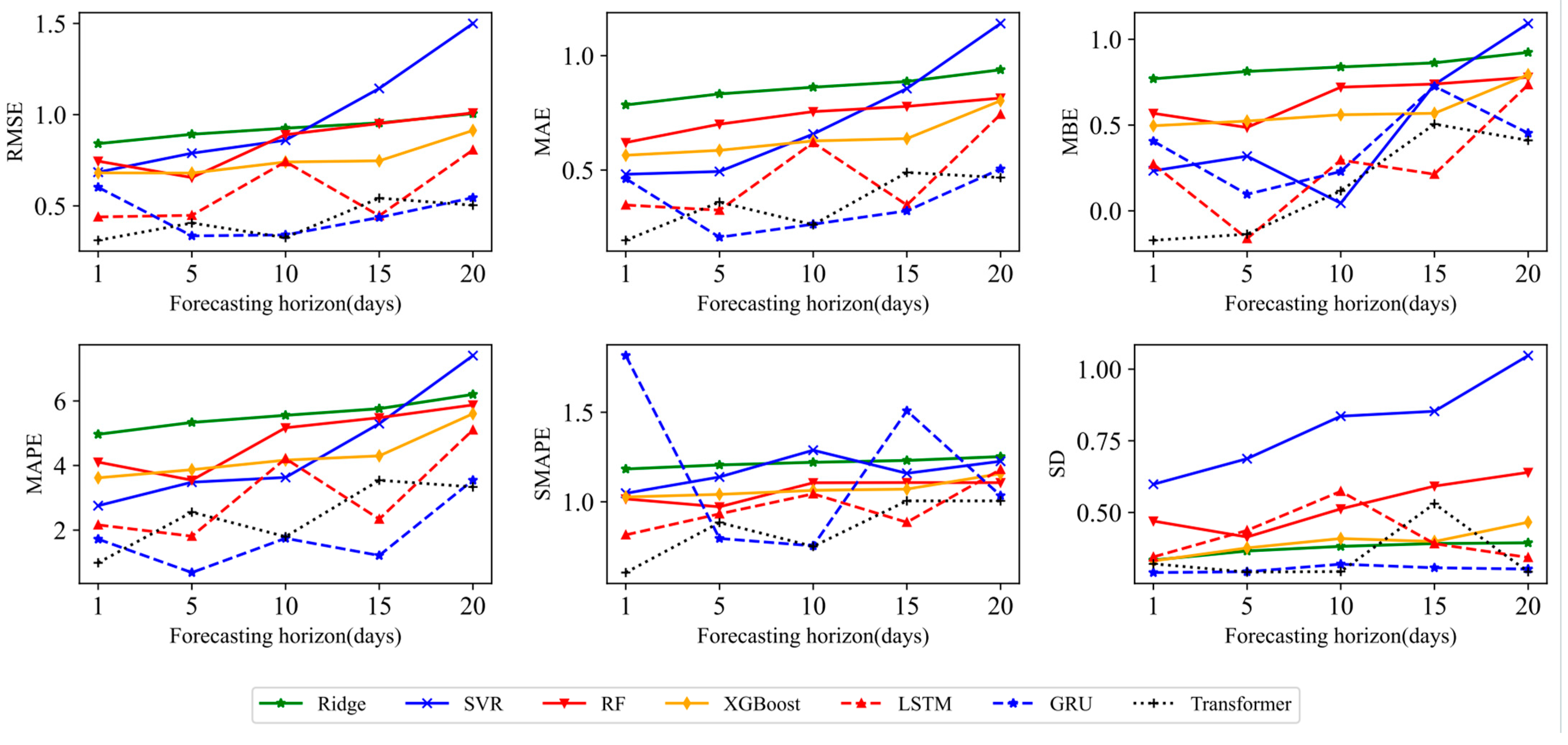
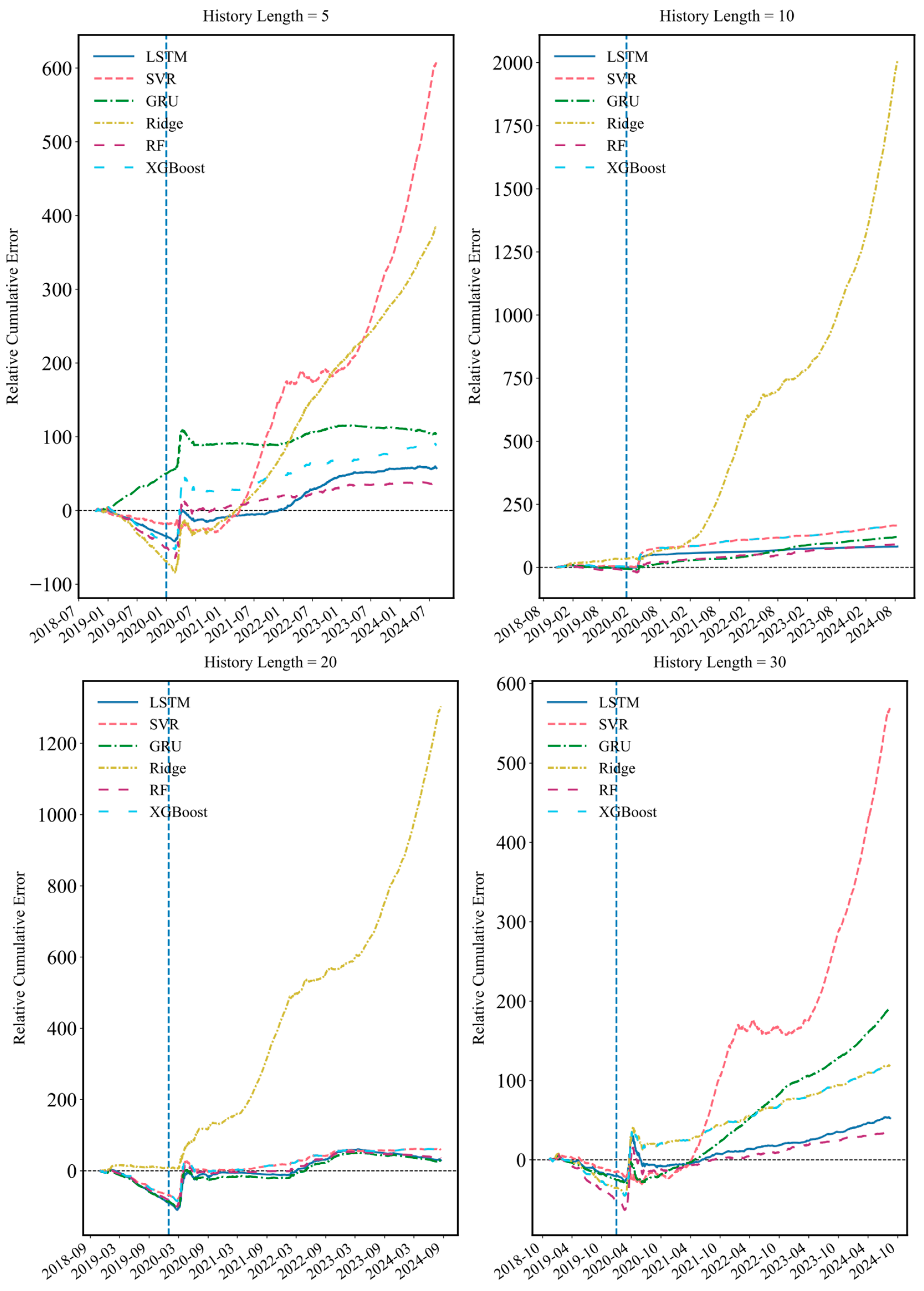
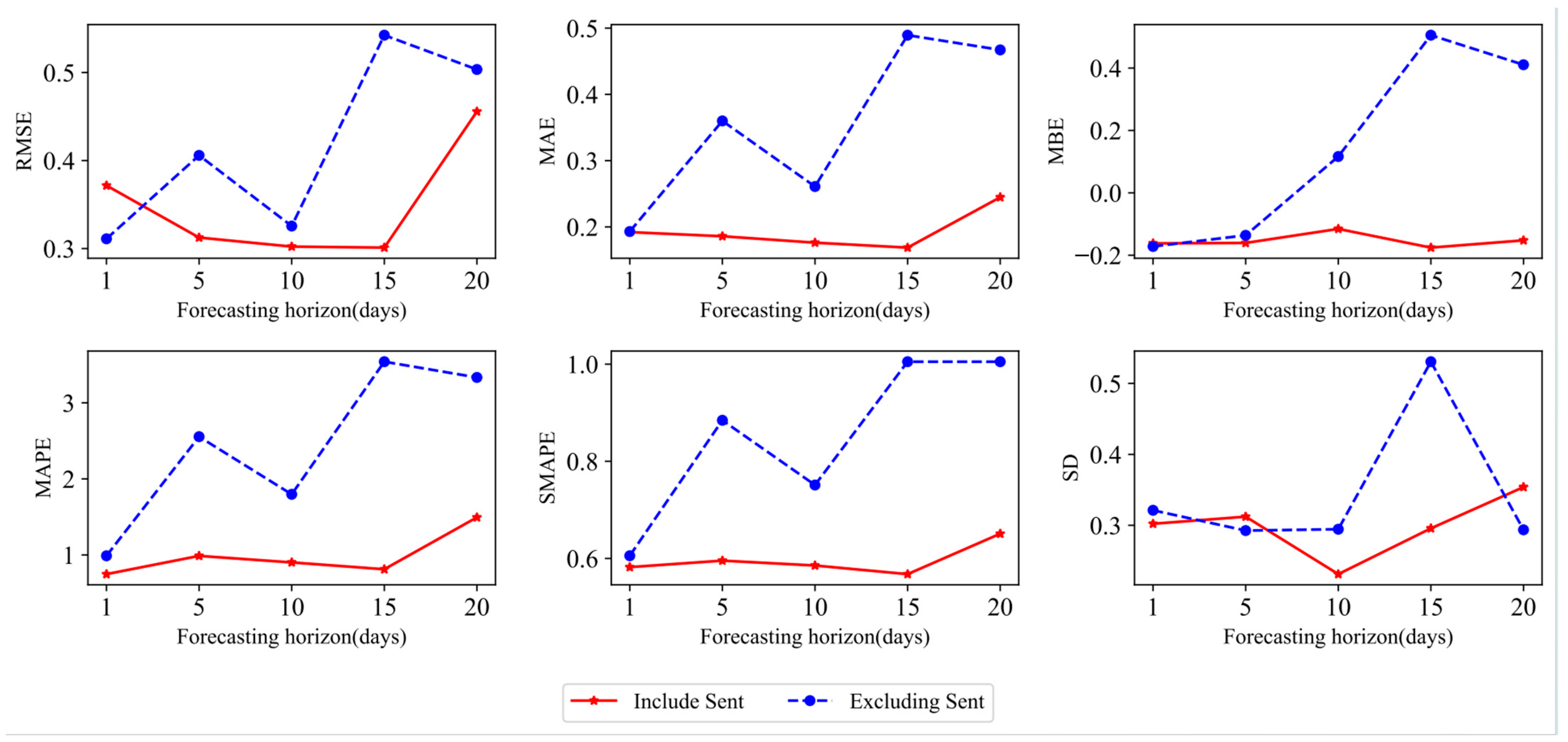
This paper mainly draws the following three conclusions. First, the degree of use of historical information will affect the prediction effect of various models. In this paper, the rolling window sizes of 5, 10, 20, and 30 are used for empirical analysis to verify the prediction advantage when the window size is set to 20, which provides strong data support for selecting the optimal historical data length. Second, the Transformer model has the best prediction accuracy in one-step prediction. RMSE, MAE, MAPE, SMAPE, MBE, and SD are used to evaluate the prediction effect of the seven models. Compared with each model, the average improvement ratios of the Transformer model under SSE are 0.5223, 0.2003, 0.6233, and 0.6033, 37.57%, and 18.70%, respectively. In particular, the Transformer model is compared with the traditional deep learning model, and the improvement ratio of each evaluation criterion is more than 30%. The Transformer model can maintain a certain degree of accuracy in prediction due to its self-attention mechanism, location coding positioning, and parallel processing capabilities, which make the model efficient in capturing long-distance dependencies in time series prediction. Third, according to the prediction results of various models in the multi-step prediction scenario, it can be found that the Transformer model not only has advantages in prediction accuracy but also shows significant stability in long-term RDS prediction. The DM test is used to compare the advantages and disadvantages of the model, and it is found that all DM test statistics of the Transformer model are positive, which further confirms the superiority and stability of the Transformer model in long-term prediction, and the potential of grasping the long-term dependence relationship of nonlinear and non-stationary complex data. The robustness of the Transformer model and the advantages of the stacked hybrid model are further confirmed in the discussion of robustness under structural fracture, the influence of the emotion index on model prediction, and RDS prediction results under the stacked ML-DL framework.
The research in this paper provides empirical support for the deep learning prediction of RDS. In future volatility research, the architecture and parameters of the Transformer model can be further improved and optimized, such as introducing new attention mechanisms and adjusting the number of attention heads, learning rate, and batch size, to find a better model structure and configuration. In addition, this paper focuses on the model construction and prediction result analysis of the downside risk indicator RDS. In terms of investment decision-making and risk management, future studies may explore the economic impact of prediction models, such as using model prediction results to assist investors in formulating specific trading strategies and helping risk managers optimize investment strategies, to further enhance the application value of prediction models.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}