
A Comparative Analysis of Three Data Fusion Methods and Construction of the Fusion Method Selection Paradigm


Abstract
1. Introduction
2. Description of the Problem and Related Concepts
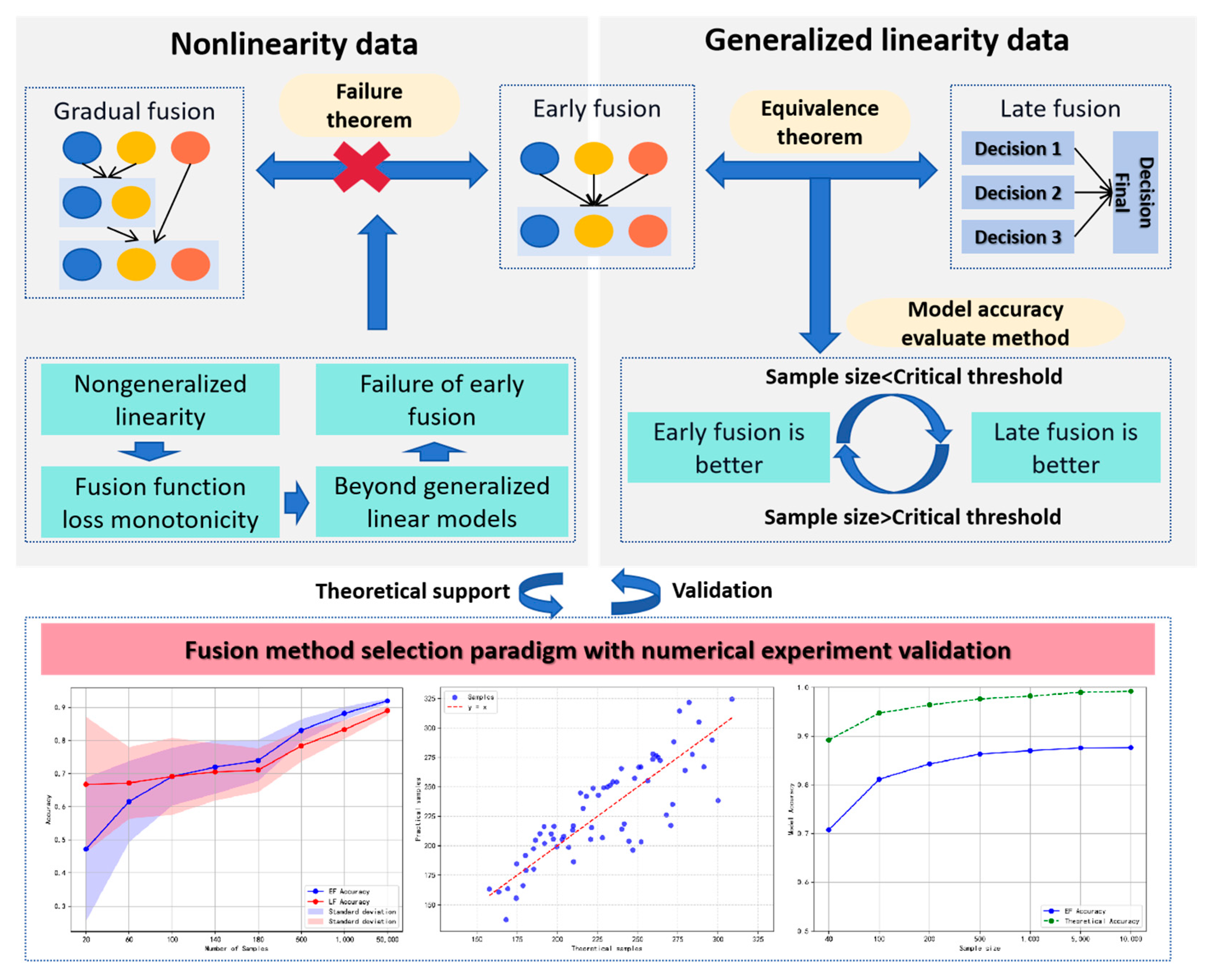
3. Comparative Analysis and Construction of the Fusion Method Selection Paradigm
3.1. Comparative Analysis of Early Fusion and Late Fusion
3.2. Comparative Analysis of Early Fusion and Gradual Fusion
3.3. Construction of the Fusion Method Selection Paradigm
- (a)
- Samples are randomly drawn from the population with a predetermined sample size range of . For each sampled set, the signal-to-noise ratio is calculated simultaneously.
- (b)
- Generalized linear models are employed to construct both early fusion and late fusion models. The models are trained on the sampled datasets, and their predictive accuracy is systematically recorded. Concurrently, the theoretical accuracy under the given sample conditions is computed using Equations (21) and (22).
- (c)
- A comparative analysis is conducted between the empirical model’s accuracy and the theoretical accuracy. If the maximum deviation between the model’s accuracy and the theoretical accuracy for either early or late fusion does not exceed 20%, the task can be appropriately addressed using the corresponding generalized linear fusion approach. Conversely, if the deviation exceeds this threshold, the relationship between features and labels is deemed nonlinear, suggesting that generalized linear fusion methods (either early or late fusion) are insufficient. At a 95% confidence level, more sophisticated fusion strategies, such as progressive fusion, should be considered to capture the underlying complexity of the data.
4. Numerical Experiment Validation
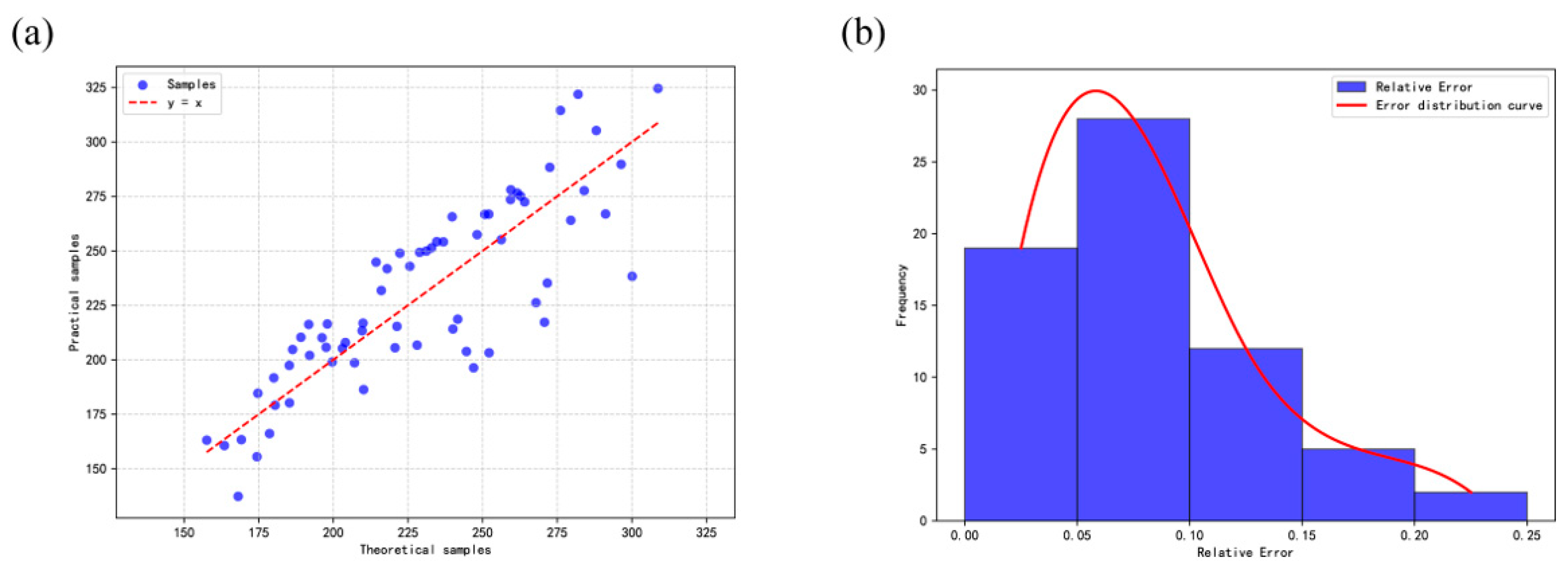
4.1. Example of Early Fusion and Late Fusion Equivalence
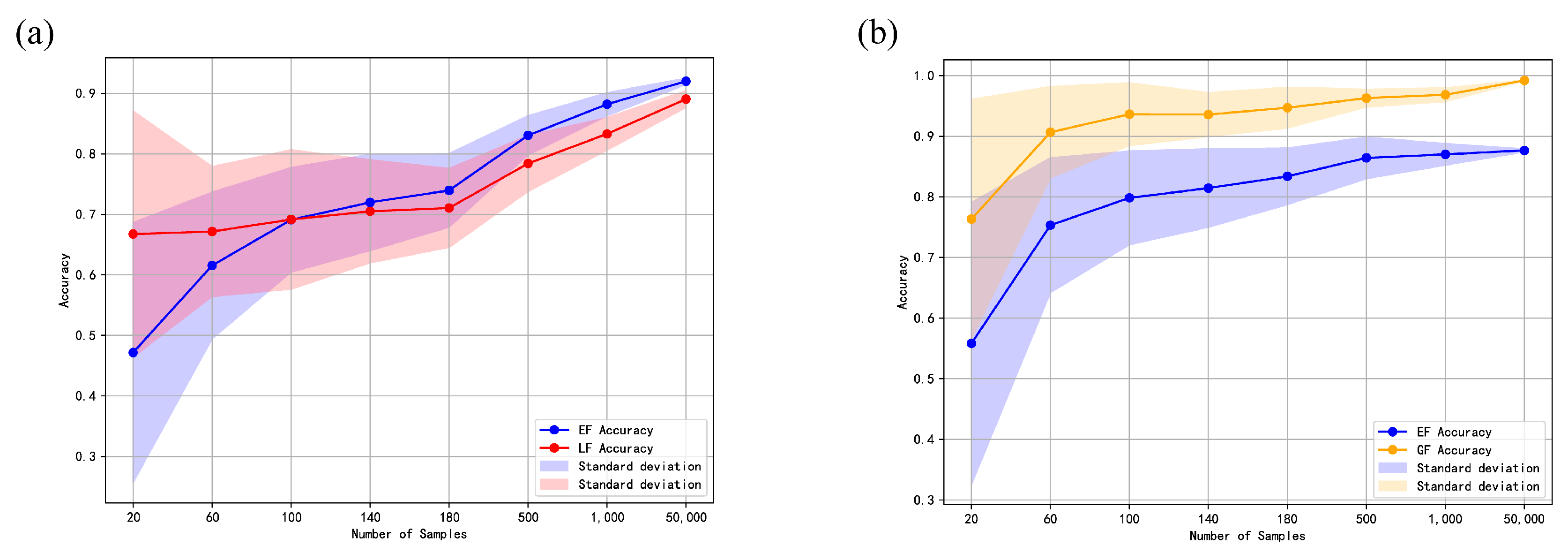
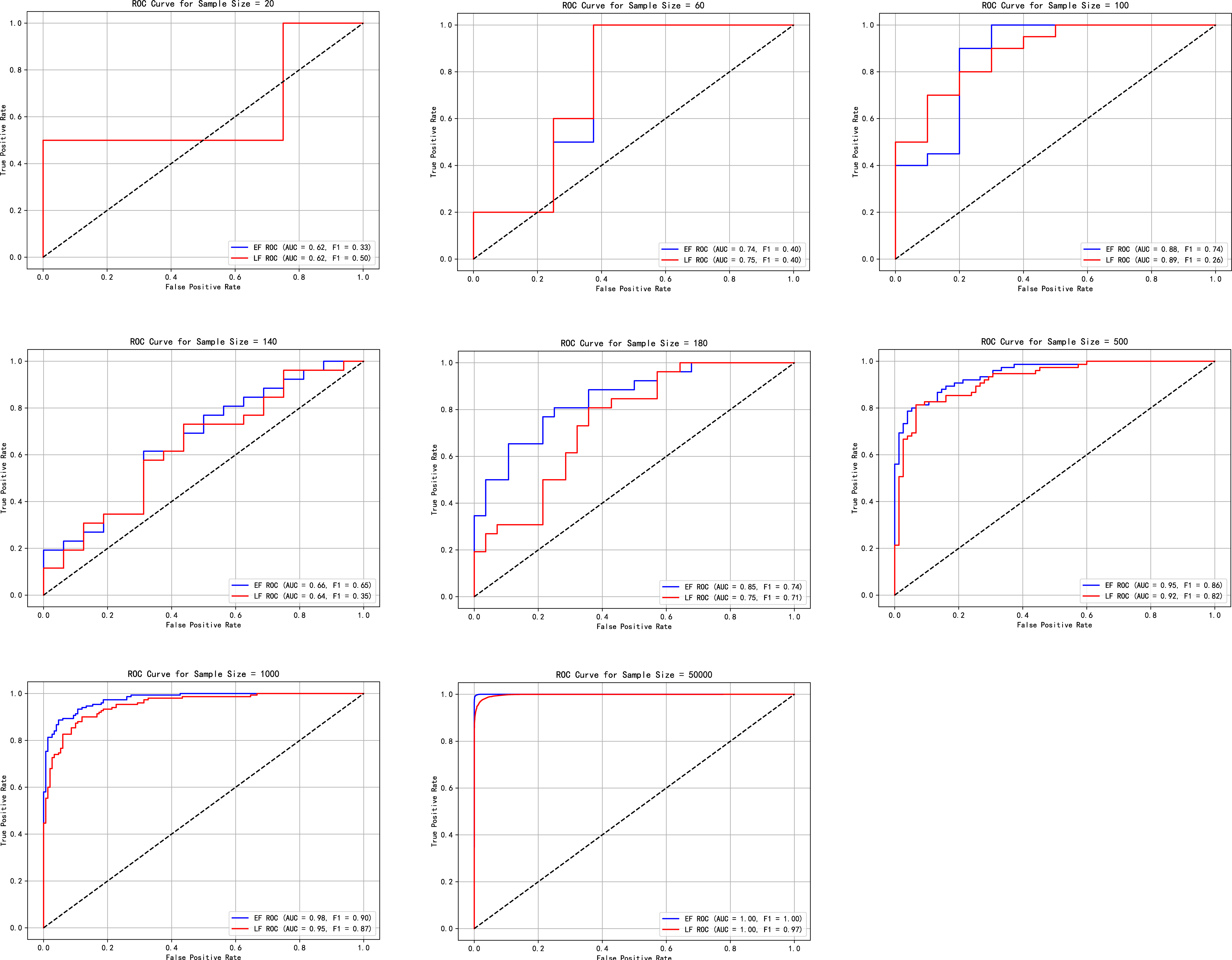
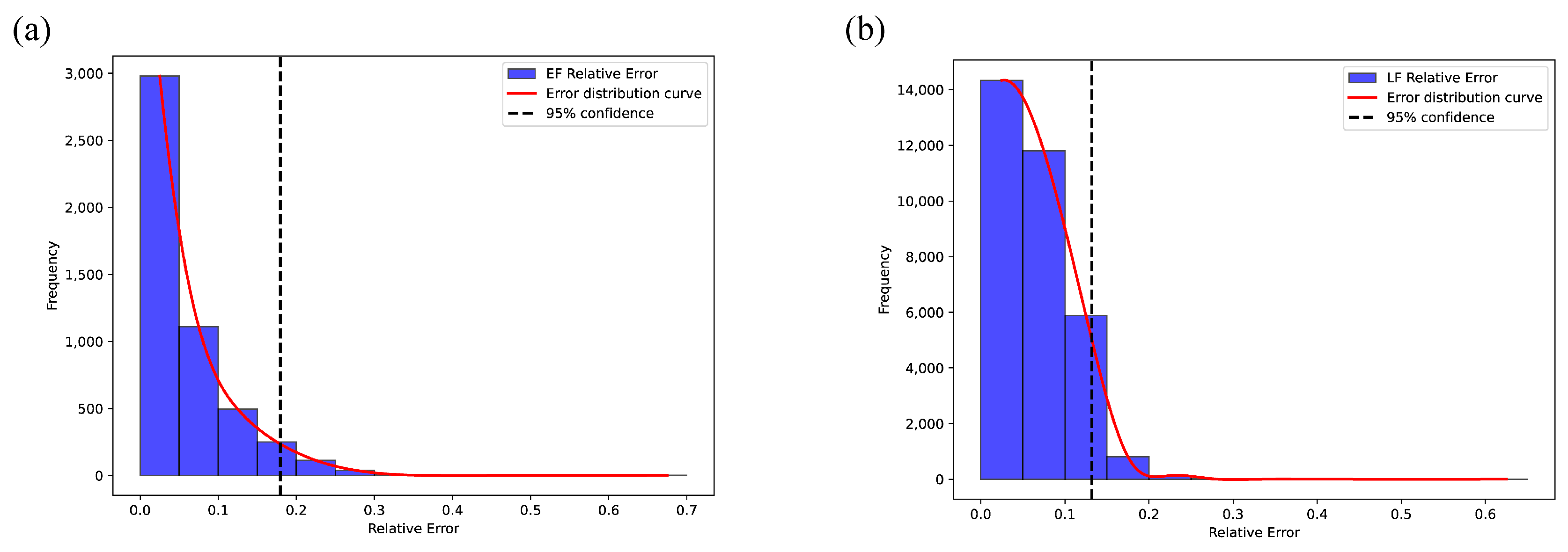
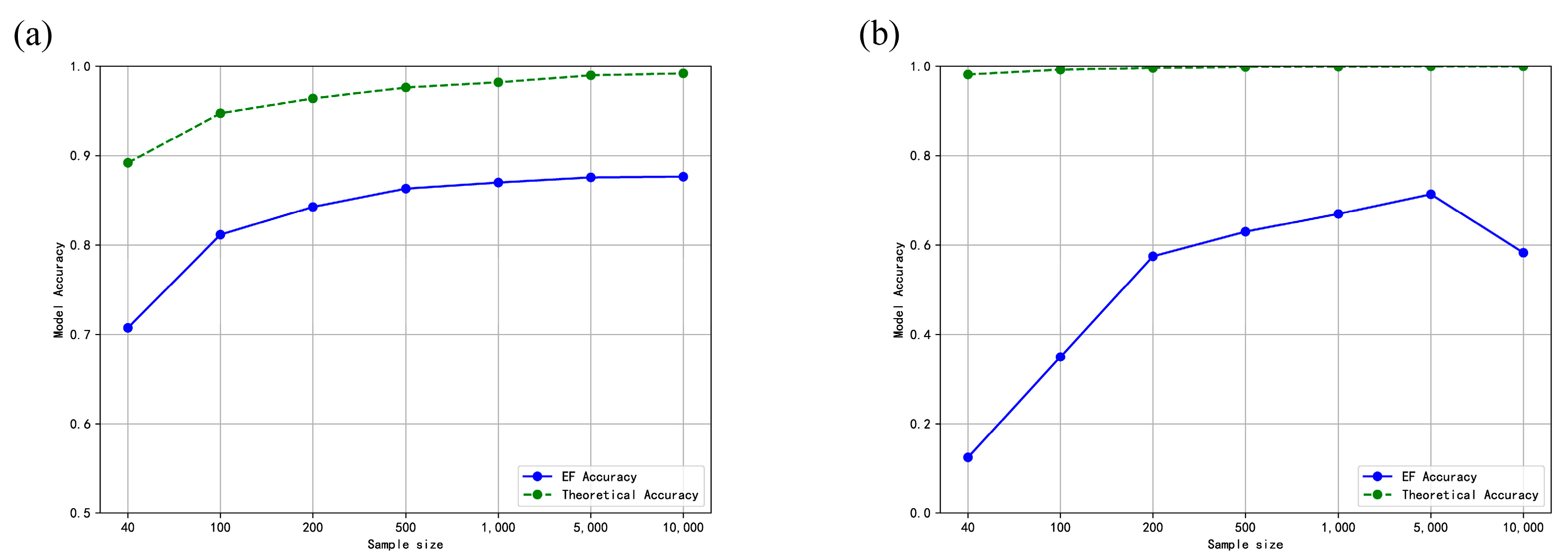
4.2. Comparative Experimental Analysis of Early Fusion and Late Fusion Models
| Algorithm 1 Data Generation Algorithm of Late Fusion Mode |
| Random , |
| For i in Sample numbers: |
| Random , , |
| Calculate |
| Calculate |
| If : |
| Else: |
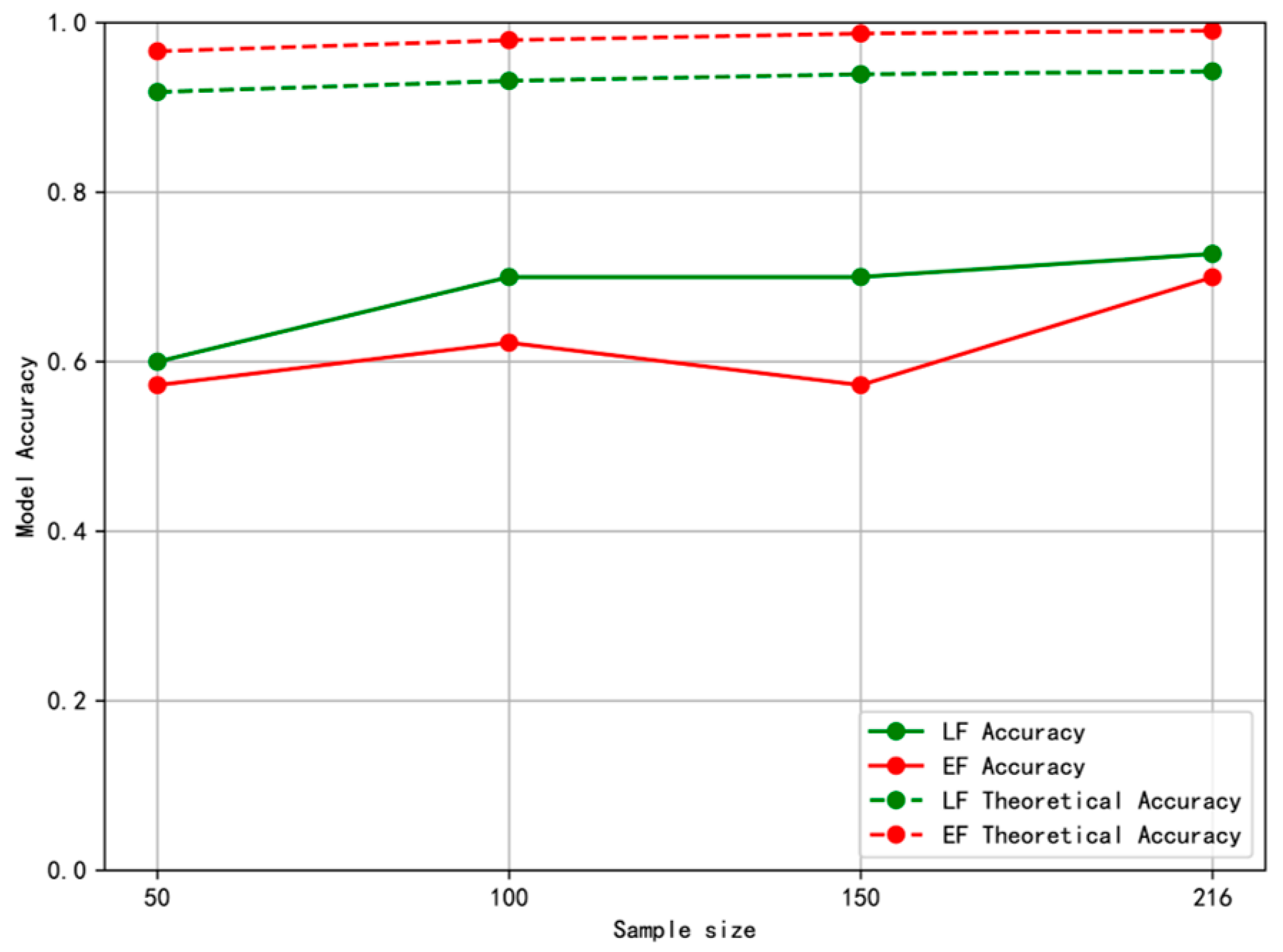
4.3. Comparative Experimental Analysis of Early Fusion and Gradual Fusion Models
| Algorithm 2 Data Generation Algorithm of Gradual Fusion Mode |
| For i in Sample numbers: |
| Random , , , , . , |
| Calculate and |
| Calculate |
| If : |
| Else: |
4.4. Effect Verification of the Approximate Equation and Method Selection Paradigm
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| EF | Early fusion |
| IF | Intermediate fusion |
| LF | Late fusion |
| GF | Gradual fusion |
Appendix A
Appendix B
References
- White, F.E. Data fusion lexicon. JDL. Tech. Panel C 1991, 3, 19. [Google Scholar]
- Durrant-Whyte, H.F. Sensor models and multisensor integration. Int. J. Robot. Res. 1988, 7, 97–113. [Google Scholar] [CrossRef]
- Dasarathy, B.V. Sensor fusion potential exploitation-innovative architectures and illustrative applications. Proc. IEEE 1997, 85, 24–38. [Google Scholar]
- Lipkova, J.; Chen, R.J.; Chen, B.; Lu, M.Y.; Barbieri, M.; Shao, D.; Vaidya, A.J.; Chen, C.; Zhuang, L.; Williamson, D.F.; et al. Artificial intelligence for multimodal data integration in oncology. Cancer Cell 2022, 40, 1095–1110. [Google Scholar]
- Stahlschmidt, S.R.; Ulfenborg, B.; Synnergren, J. Multimodal deep learning for biomedical data fusion: A review. Brief. Bioinform. 2022, 23, bbab569. [Google Scholar] [CrossRef]
- Zhao, F.; Zhang, C.; Geng, B. Deep Multimodal Data Fusion. ACM Comput. Surv. 2024, 56, 216. [Google Scholar]
- Mohsen, F.; Ali, H.; El Hajj, N.; Shah, Z. Artificial intelligence-based methods for fusion of electronic health records and imaging data. Sci. Rep. 2022, 12, 17981. [Google Scholar]
- Qi, P.; Chiaro, D.; Piccialli, F. FL-FD: Federated learning-based fall detection with multimodal data fusion. Inf. Fusion 2023, 99, 101890. [Google Scholar] [CrossRef]
- Mervitz, J.; de Villiers, J.; Jacobs, J.; Kloppers, M. Comparison of early and late fusion techniques for movie trailer genre labelling. In Proceedings of the 2020 IEEE 23rd International Conference on Information Fusion (FUSION), Rustenburg, South Africa, 6–9 July 2020; pp. 1–8. [Google Scholar]
- Yao, W.; Moumtzidou, A.; Dumitru, C.O.; Andreadis, S.; Gialampoukidis, I.; Vrochidis, S.; Datcu, M. Early and late fusion of multiple modalities in Sentinel imagery and social media retrieval. In Pattern Recognition. ICPR International Workshops and Challenges; Springer: Cham, Switzerland, 2021; pp. 591–606. [Google Scholar] [CrossRef]
- Pandeya, Y.R.; Lee, J. Deep learning-based late fusion of multimodal information for emotion classification of music video. Multimed. Tools Appl. 2021, 80, 2887–2905. [Google Scholar]
- Pawłowski, M.; Wróblewska, A.; Sysko-Romańczuk, S. Effective techniques for multimodal data fusion: A comparative analysis. Sensors 2023, 23, 2381. [Google Scholar] [CrossRef]
- Trinh, M.; Shahbaba, R.; Stark, C.; Ren, Y. Alzheimer’s disease detection using data fusion with a deep supervised encoder. Front. Dement. 2024, 3, 1332928. [Google Scholar]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.-P. Efficient low-rank multimodal fusion with modality-specific factors. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.-P. Tensor Fusion Network for Multimodal Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017; pp. 1103–1114. [Google Scholar]
- Boulahia, S.Y.; Amamra, A.; Madi, M.R.; Daikh, S. Early, intermediate and late fusion strategies for robust deep learning-based multimodal action recognition. Mach. Vis. Appl. 2021, 32, 121. [Google Scholar]
- Koca, M.B.; Sevilgen, F.E. Comparative Analysis of Fusion Techniques for Integrating Single-cell Multiomics Datasets. In Proceedings of the 2024 32nd Signal Processing and Communications Applications Conference, Mersin, Turkey, 15–18 May 2024; pp. 1–4. [Google Scholar]
- Kantarcı, M.G.; Gönen, M. Multimodal Fusion for Effective Recommendations on a User-Anonymous Price Comparison Platform. In Proceedings of the 2024 IEEE Conference on Artificial Intelligence, Singapore, 25–27 June 2024; pp. 947–952. [Google Scholar]
- Xu, R.; Xiang, H.; Xia, X.; Han, X.; Li, J.; Ma, J. Opv2v: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In Proceedings of the 2022 International Conference on Robotics and Automation, Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar]
- Chen, Y.; Bruzzone, L. Self-supervised SAR-optical data fusion of Sentinel-1/-2 images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5406011. [Google Scholar]
- Zhang, P.; Wang, D.; Yu, Z.; Zhang, Y.; Jiang, T.; Li, T. A multi-scale information fusion-based multiple correlations for unsupervised attribute selection. Inform. Fusion 2024, 106, 102276. [Google Scholar]
- Zhang, Q.; Zhang, P.; Li, T. Information fusion for large-scale multi-source data based on the Dempster-Shafer evidence theory. Inform. Fusion 2025, 115, 102754. [Google Scholar] [CrossRef]
- Pereira, L.M.; Salazar, A.; Vergara, L. A comparative analysis of early and late fusion for the multimodal two-class problem. IEEE Access 2023, 11, 84283–84300. [Google Scholar]
- Wu, X.; Zhao, X. Influence analysis of generalized linear model. Math. Stat. Appl. Probab. 1994, 4, 34–44. [Google Scholar]
- Guo, W.; Wang, J.; Wang, S. Deep multimodal representation learning: A survey. IEEE Access 2019, 7, 63373–63394. [Google Scholar] [CrossRef]
- Li, S. Linear Algebra; Higher Education Press: Beijing, China, 2006. [Google Scholar]
- Vapnik, V.N.; Chervonenkis, A.Y. On the uniform convergence of relative frequencies of events to their probabilities. In Measures of Complexity: Festschrift for Alexey Chervonenkis; Springer: Cham, Switzerland, 2015; pp. 11–30. [Google Scholar]
- Sontag, E.D. VC dimension of neural networks. NATO ASI Ser. F Comput. Syst. Sci. 1998, 168, 69–96. [Google Scholar]
- Cherkassky, V.; Dhar, S.; Vovk, V.; Papadopoulos, H.; Gammerman, A. Measures of Complexity: Festschrift for Alexey Chervonenkis; Springer: Cham, Switzerland, 2015; p. 17. [Google Scholar]
- Serebruany, V.L.; Christenson, M.J.; Pescetti, J.; McLean, R.H. Hypoproteinemia in the hemolytic-uremic syndrome of childhood. Pediatr. Nephrol. 1993, 7, 72–73. [Google Scholar]
- Wu, S.; Shang, X.; Guo, M.; Su, L.; Wang, J. Exosomes in the diagnosis of neuropsychiatric diseases: A review. Biology 2024, 13, 387. [Google Scholar] [CrossRef] [PubMed]
- Ying, X. An overview of overfitting and its solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Chabé-Ferret, S. Statistical Tools for Causal Inference. Social Science Knowledge Accumulation Initiative (SKY), 2022.
- Liu, Z.; Kang, Q.; Mi, Z.; Yuan, Y.; Sang, T.; Guo, B.; Zheng, Z.; Yin, Z.; Tian, W. Construction of geriatric hypoalbuminemia predicting model for hypoalbuminemia patients with and without pneumonia and explainability analysis. Front. Med. 2024, 11, 1518222. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Parameters | ||||
|---|---|---|---|---|
| 185 | 1511 | 511 | 170 | |
| 95 | 1511 | 111 | 106 | |
| 490 | 4511 | 1511 | 512 | |
| 340 | 4511 | 311 | 320 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Yin, Z.; Mi, Z.; Guo, B.; Zheng, Z. A Comparative Analysis of Three Data Fusion Methods and Construction of the Fusion Method Selection Paradigm. Mathematics 2025, 13, 1218. https://doi.org/10.3390/math13081218
Liu Z, Yin Z, Mi Z, Guo B, Zheng Z. A Comparative Analysis of Three Data Fusion Methods and Construction of the Fusion Method Selection Paradigm. Mathematics. 2025; 13(8):1218. https://doi.org/10.3390/math13081218
Chicago/Turabian StyleLiu, Ziqi, Ziqiao Yin, Zhilong Mi, Binghui Guo, and Zhiming Zheng. 2025. "A Comparative Analysis of Three Data Fusion Methods and Construction of the Fusion Method Selection Paradigm" Mathematics 13, no. 8: 1218. https://doi.org/10.3390/math13081218
APA StyleLiu, Z., Yin, Z., Mi, Z., Guo, B., & Zheng, Z. (2025). A Comparative Analysis of Three Data Fusion Methods and Construction of the Fusion Method Selection Paradigm. Mathematics, 13(8), 1218. https://doi.org/10.3390/math13081218