1. Introduction
Random walk has attracted mathematicians’ attention both for its analytical properties and for its role in modeling instances ever since it was mentioned by Pearson [
1]. Presently, random walks are universally recognized as the simplest example of a stochastic process and are used as a simplified version of more complex models. For modeling purposes, it is often necessary to introduce suitable boundary conditions, constraining the evolution of the process in specific regions. Typical conditions are absorbing or reflecting boundaries and the involved random walk may be in one or more dimensions. The recurrence of the states of the free or bounded process in one or more dimensions has been the subject of past and recent studies, and results are available for the free random walk [
2] or in the presence of specific boundaries [
3].
The distribution of a simple random walk at Time
has a simple expression while, in the case of the distribution of the random walk constrained by two absorbing boundaries, it involves important calculation efforts [
4].
Classical methods for the study of random walks refer to their Markov property. This happens, for example, when the focus is on recurrence properties in one or more dimensions. Alternatively, some results can be obtained by means of diffusion limits that give good approximations under specific hypotheses [
5,
6,
7,
8] or allow the determination of asymptotic results for problems such as the maximum of a random walk or the first exit time across general boundaries [
9]. However, the presence of boundaries often determines combinatorics problems and discourages the search for closed-form solutions. Furthermore, the switch from unitary jumps to continuous jumps introduces important computational difficulties. There are thousands of papers about random walk, and it is impossible to refer to all of them. We limit ourselves to citing the recent excellent review by Dshalalow and White [
10] that lists many of the most important available results.
In this paper, we focus on a particular constrained random walk: the Lindley process [
11]. In particular, we prove a set of analytical results about it. This process is a discrete-time random walk characterized by continuous jumps with a specified distribution.
Without loss of generality, we define it as
where
are i.i.d. random variables.
Modeling interest for the Lindley process arises in several fields. Historically, it was introduced in [
11] to describe waiting times experienced by customers in a queue over time and it has been extensively studied in recent decades [
12,
13,
14].
This process also arises in a reliability context, in a sequential test framework, through the study of CUSUM tests [
15]. Moreover, the same process appears in problems related to resources management [
16] and in highlighting atypical regions in biological sequences, transferring biological sequence analysis tools to break-point detection for on-line monitoring [
17].
Many contributions concerning properties of the Lindley process are motivated by their important role in applications [
2,
11,
16,
18,
19]. A large part of the papers about the Lindley process concerns its asymptotic behavior. Using the strong law of large numbers, in 1952, Lindley [
11] in the framework of queuing theory showed that the process admits a limit distribution as
n diverges if and only if
, i.e., if the customer’s arrival rate is slower than the service one. Furthermore, when
, the ratio
converges to the modulus of a Gaussian random variable. Lindley also showed that the limit distribution is the solution of an integral equation, and Kendall solved it in the case of exponential arrivals [
14] while Erlang determined its expression when both arrival and service times are exponential [
20]. Simulations were used in [
21] to determine invariant distribution when
are Laplace or Gaussian distributed. The analytical expression of the limit distribution was determined by Stadje [
22] for the case of integer-valued increments. Recent contributions consider recurrence properties in higher dimensions [
3,
23,
24] or the study of the rate of convergence of expected values of functions of the process.
Other contributions make use of stochastic ordering notion [
25] or of continuous-time versions of the Lindley process [
12]. Recently, the use of machine learning techniques has been proposed to learn Lindley recursion (
1) directly from the waiting time data of a G/G/1 queue [
26]. Furthermore, Lakatos and Zbaganu [
25], and Raducan, Lakatos and Zbaganu [
27] introduced a class of computable Lindley processes for which the distribution of the space increments is a mixture of two distributions. To the best of our knowledge, no other analytical expressions are available for a Lindley process.
Concerning the first exit time problem for the Lindley process, it has been considered mainly in the framework of CUSUM methodology to detect the time in which a change in the parameters of the process happens [
15,
28,
29,
30]. In this context, the focus was on the Average Run Length that corresponds to the exit time of the process from a boundary, and in [
31,
32], such distribution and its expected value are determined when the
are exponentially distributed with a shift. Markovich and Razumchick [
33] investigated a problem related to first exit times, i.e., the appearance of clusters of extremes defined as subsequent experiences of high thresholds in a Lindley process.
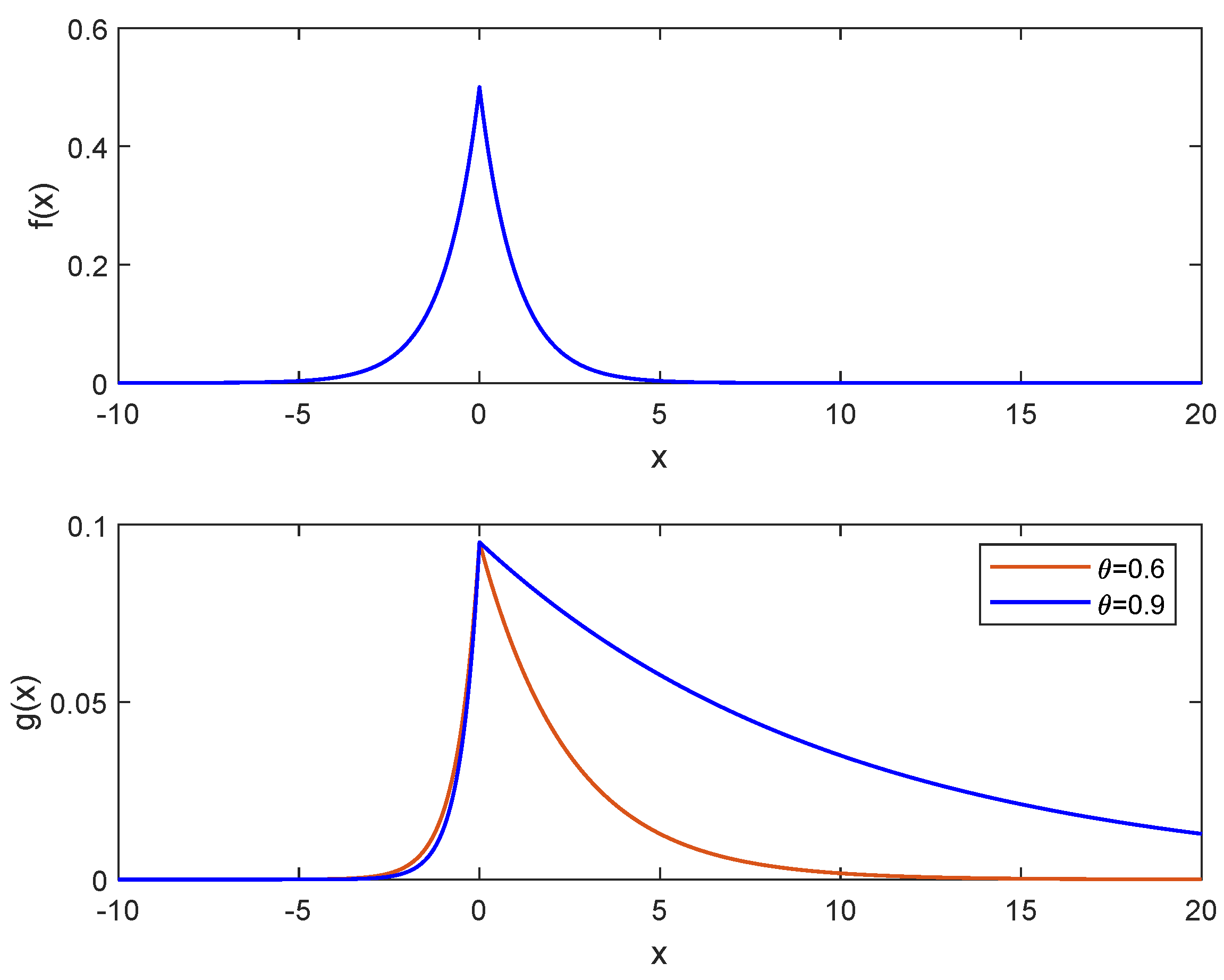
Here, we consider a Lindley process characterized by Laplace-distributed space increments
, i.e.,
Z distributed as a Laplace random variable characterized by parameter
and scale parameter
,
where the mean and the variance are
and
.
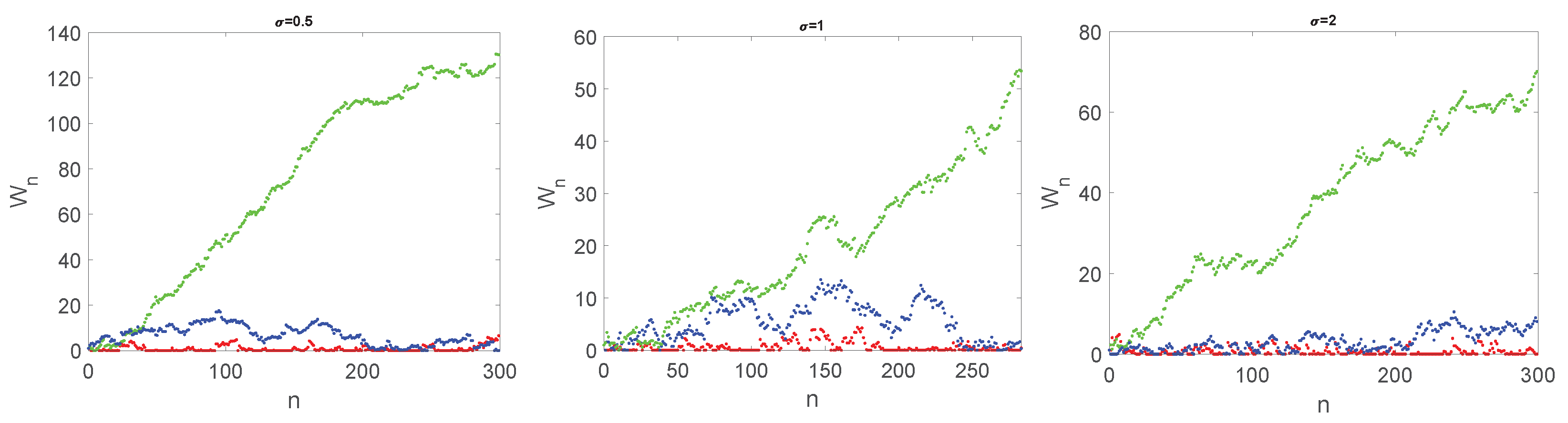
In
Figure 1, three trajectories are plotted of the Lindley process with
,
, and different values of
. The Laplace distribution is often used to model the distribution of financial assets and market fluctuations. It is also used in signal processing and communication theory to model noise and other random processes. Additionally, the Laplace distribution has been used in image processing and speech recognition.
As in the case of the simple random walk, here, the behavior of the random walk dramatically changes according to the sign of
. Indeed, it is well known [
9] that, when
, all the states are transient, and the process has a drift toward infinity. However, in the case
, the process is null recurrent, and when
, the process is positive recurrent and admits limit distribution. Such distribution is the solution of the Lindley integral equation [
11]. Unfortunately, the analytical solution is unknown and numerical methods become necessary.
The recurrence properties imply certainty of the first exit time of the process W from for each , and the study of the first exit time distribution can be performed.
Here, our aim is to derive expressions for the distribution of the process as the time evolves together with its first exit time (FET) from
. Taking advantage of the presence of exponential in the Laplace distribution, we prove recursive closed-form formulae for such distributions, and we show that different formulae hold on different parameters domain. We underline that the special expression of the Laplace distribution allows the use of recursion in various steps of our proofs. This makes hard the extension to other types of distributions. In
Section 2 and
Section 3, we study the distribution of the process and its first exit times from
, respectively. In these sections, we do not present any proofs that we postpone in
Section 4 and
Section 5. Due to the complexity of the derived exact formulae for the studied distributions, we complete our work implementing the software necessary for fast computation of the formulae of interest. This software is open source and can be found in the GitHub repository [
34]. In
Section 6, we illustrate the role of the parameters of the Laplace distribution on the position and FET distribution of the Lindley process. Lastly, in
Section 7, we present an application of our theoretical results in the CUSUM framework. In particular, we discuss a method to detect the change point when the data moves from a symmetric Laplace distribution to an asymmetric one.
2. Distribution of
Let us consider the Lindley process (
1) with Laplace-distributed jumps (
2). In the following, we will use the distribution of the process at Time
that we denote as
and, with an abuse of notation, we indicate with
the corresponding probability density function, since the derivative is the distributional derivative because the
are mixed random variables.
In the following we make use of Dirac delta function
with the agreement that, for each
Since , the density for . Moreover, if the sum .
Lemma 1. The probability distribution function of for iswhile, for is The corresponding probability density function iswhere is the Dirac delta function. Remark 1. Using the Markov property of the process W, the one-step transition probability density function, for , is Notation 1. In the forthcoming, when not necessary, we will skip the dependence on the initial position of the process: , .
To determine the distribution of , computations change according to the sign of . Theorem 1 gives the distribution for . When is negative two different cases arise when (Theorem 2) and (Theorem 3).
Theorem 1. For a Lindley process characterized by Laplace increments with location parameter , the probability density function of the position is given bywhere and , , with , are The coefficients , and verify the following recursive relations for , where is the Kronecker delta and The initial values for the recursion of (10) are Remark 2. Observe that the coefficients , for each admissible k. This prevents the terms in (10e) and (11b) to explode.
The following corollary may be useful for computational purposes.
Corollary 1. The constant coefficients , can also be obtained as Remark 3. Observe that the density (7) refers to a mixed random variable.
Theorem 2. For a Lindley process characterized by Laplace increments with location parameter , the probability density function of the position is given bywhereand , are If , the coefficients , verify the recursive relations for and where The values of coefficients for arewhereand The initial conditions for the recursion of the coefficients are If , we have for each n and the coefficients , verify the following recursive relations for .with initial conditions given by (21c), (21d) and (21e).
Theorem 3. For a Lindley process characterized by Laplace increments with location parameter , the probability density function of the position is given bywhereand . The coefficients and verify the following recursive relations for The initial values for the recursion are 3. First Exit Time of
Let
be the first exit time (FET) of the Lindley process (
1) from the domain
for fixed
and let
indicate the probability that the FET is equal to
n,
, given that the process starts in
.
In order to determine the distribution of N, computations change according to the sign of and its order with respect to h. Theorem 4 gives the distribution for while Corollary 2 considers the case . For , Theorem 5 gives the distribution for while Corollary 3 considers the case and Theorem 6 refers to .
Theorem 4. For a Lindley process characterized by Laplace increments with location parameter , the probability distribution of the FET through h is given bywhere and Here and we partition the interval in The coefficients , and are defined by the following recursive relations for and Here, is the index of the interval (28) that contains , and When , the partition reduces to a single interval , and we obtain a compact closed-form solution.
Corollary 2. For a Lindley process characterized by Laplace increments with location parameter and , the probability distribution of the FET through h is given bywhere Theorem 5. For a Lindley process characterized by Laplace increments with location parameter , the probability distribution of the FET through h is given bywhere and, for , Here we partition the interval as The coefficients , and are defined by the recursive relations, for and where is the interval that contains . For the coefficients are defined by the recursive relationswhere The coefficients for the base case of the recursion are given by When in the previous theorem, we observe that the partition is formed of a single interval . This simplifies a lot of the computations, and we obtain the following:
Corollary 3. For a Lindley process characterized by Laplace increments with location parameter , and , the probability distribution of the FET through h is given bywhere for and the initial values are Theorem 6. For a Lindley process characterized by Laplace increments with location parameter , the probability distribution of the FET through h is given by The coefficients satisfy the following recursive relations for with initial conditions Remark 4. In Theorems 4 and 5, when μ is not small, the value of i such that is small. Hence, the sums include very few terms since and coincide with i soon.
Remark 5. Please note that from Corollary 3, we easily observe the exponential decay of the tails of the FET probability function. Since larger values of μ facilitate the crossing of the boundary, this tail result holds for any choice of μ.
6. Sensitivity Analysis
Here, we apply the theorems presented in
Section 2 to investigate the shapes of the distribution of
for finite times, emphasizing the variety of behaviors as the parameters change.
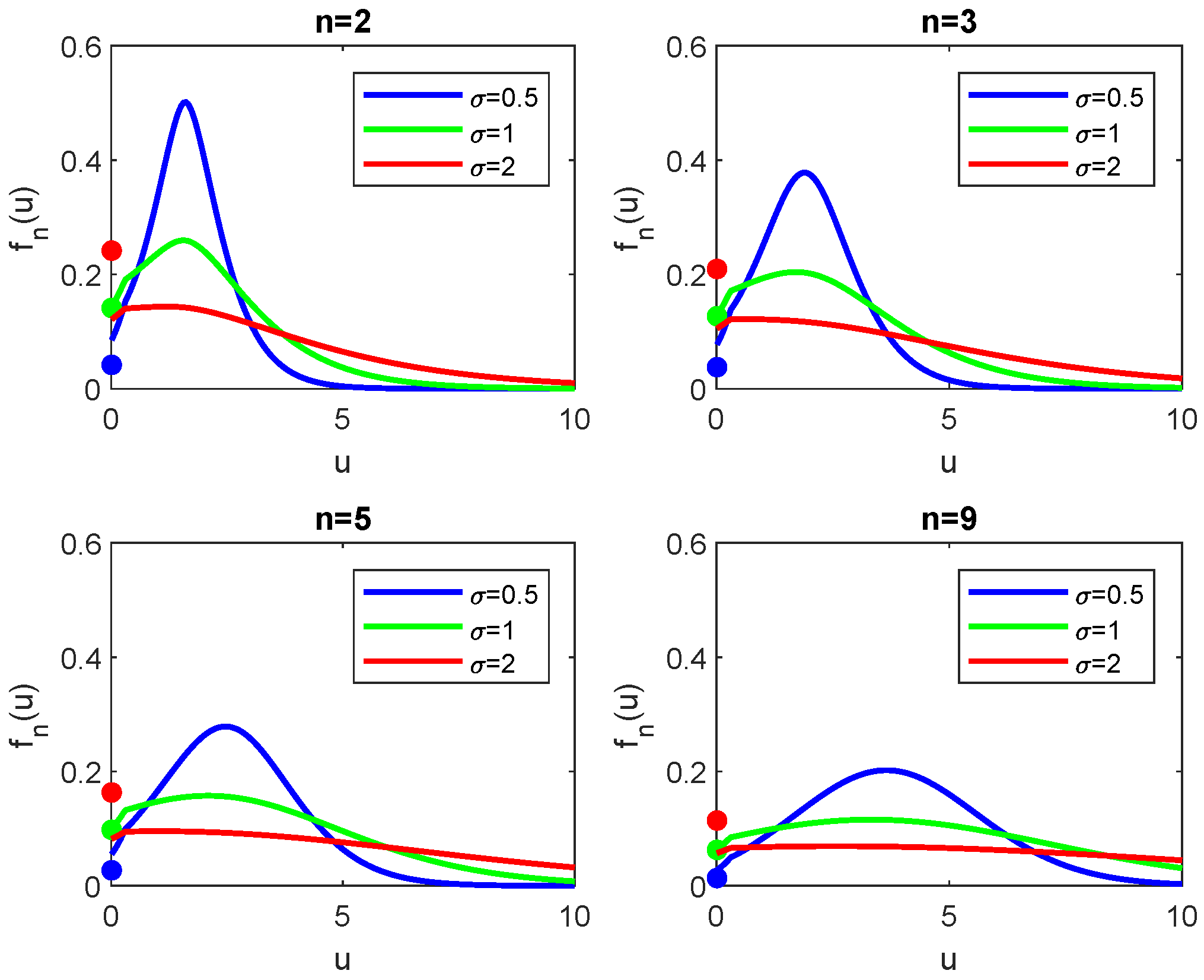
In
Figure 2, the density functions of the Lindley process with
and starting position
for different values of
n and
is shown. We can see that as
n increases, the density flattens out, the variance increases, and the maximum of the density moves toward higher values. As
increases, the density flattens out but keeps the position of the maximum. The discrete part of the distribution, represented by a colored dot on the
y-axis decreases as
n increases. Note also that only when
we observe the continuity between the continuous and discrete part of the density; this is due to Corollary 1.
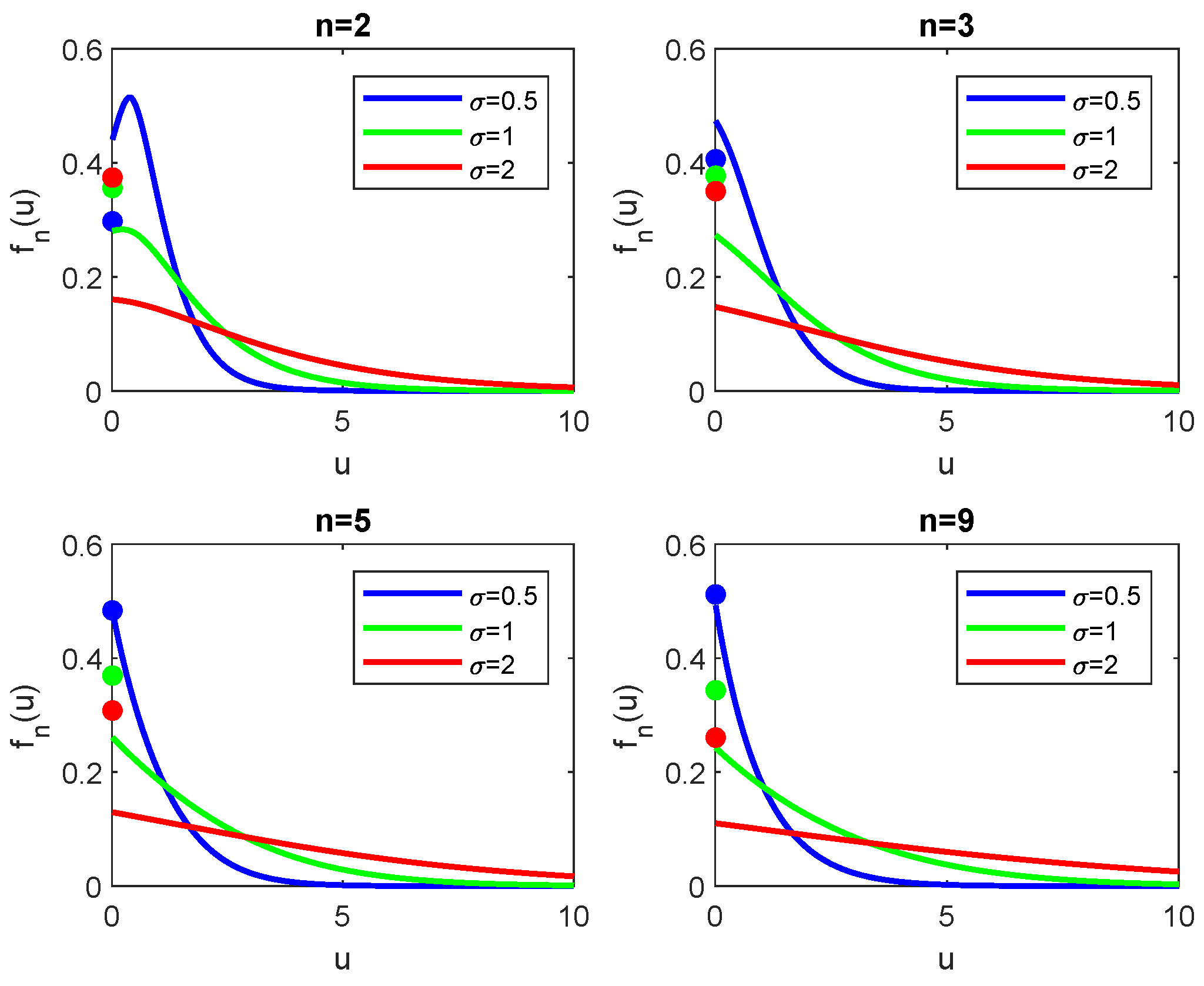
A different behavior appears when the shift term
is negative. In
Figure 3 the density functions of the Lindley process with the same parameters of
Figure 2 and
is shown. We can see that, as
n increases, the density converges to a stationary distribution, as expected from the theory. The interesting remark is that such convergence appears for reasonable small values of
n. Please note that the convergence to the steady-state distribution is faster for larger values of
. Furthermore, as
increases, the density flattens out, and the variance of
increases, as expected since we increased the variability of the process.
Figure 4 shows the density function of the Lindley process with
, starting position
for different values of
n and
. We notice that if
is positive, the increase of
determines a very similar shape of the density but shifted while, if
is negative, as
decreases, the density concentrates more and more in zero. Another interesting feature concerns the mass in
. For positive
, it decreases as
increases. Indeed, the trajectories move quickly away from zero. However, for negative
, we observe the opposite behavior due to the fact that the trajectories are pushed towards zero, and it becomes increasingly difficult to leave zero. Recall that
implies the existence of the steady-state distribution. We underline that such distribution is attained faster as
decreases.
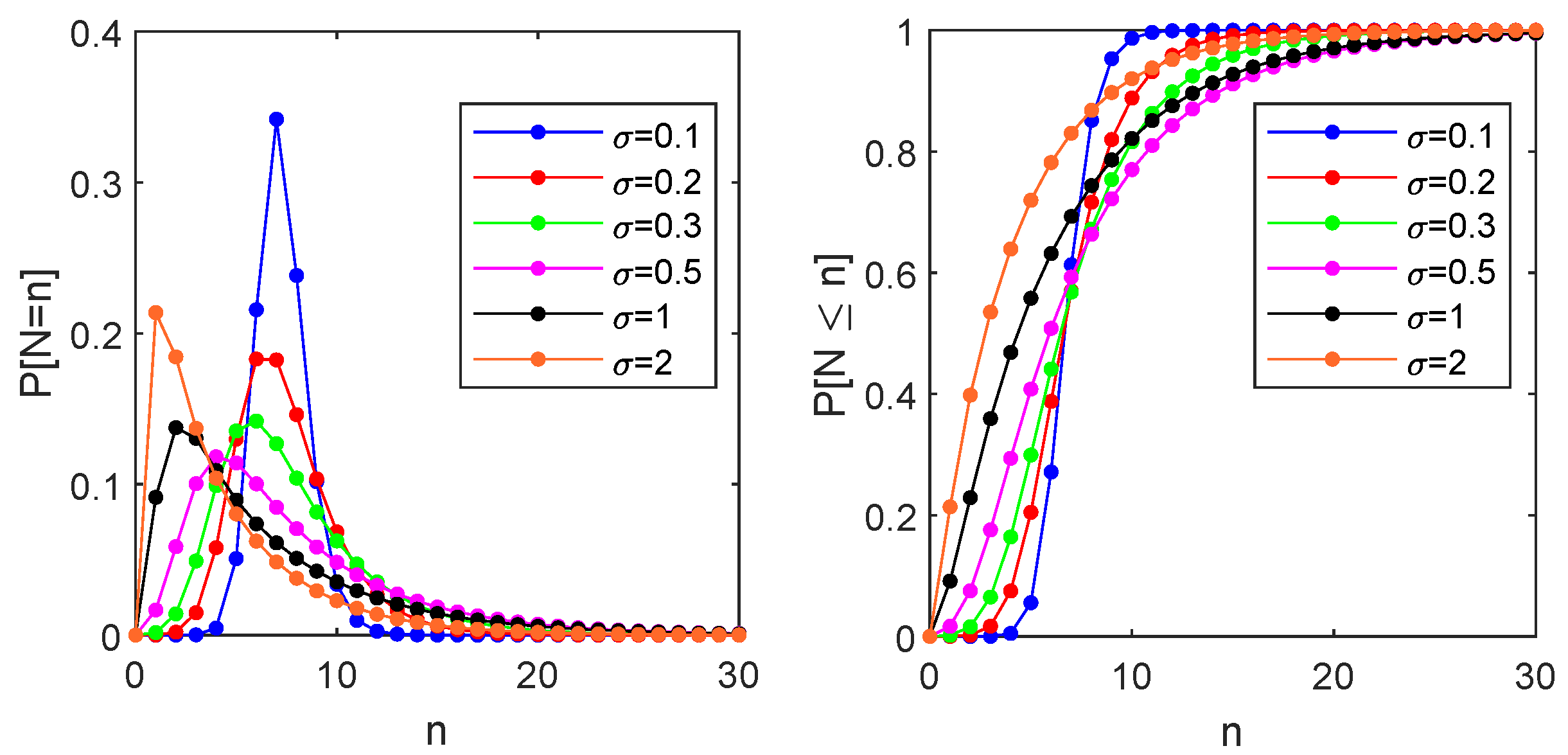
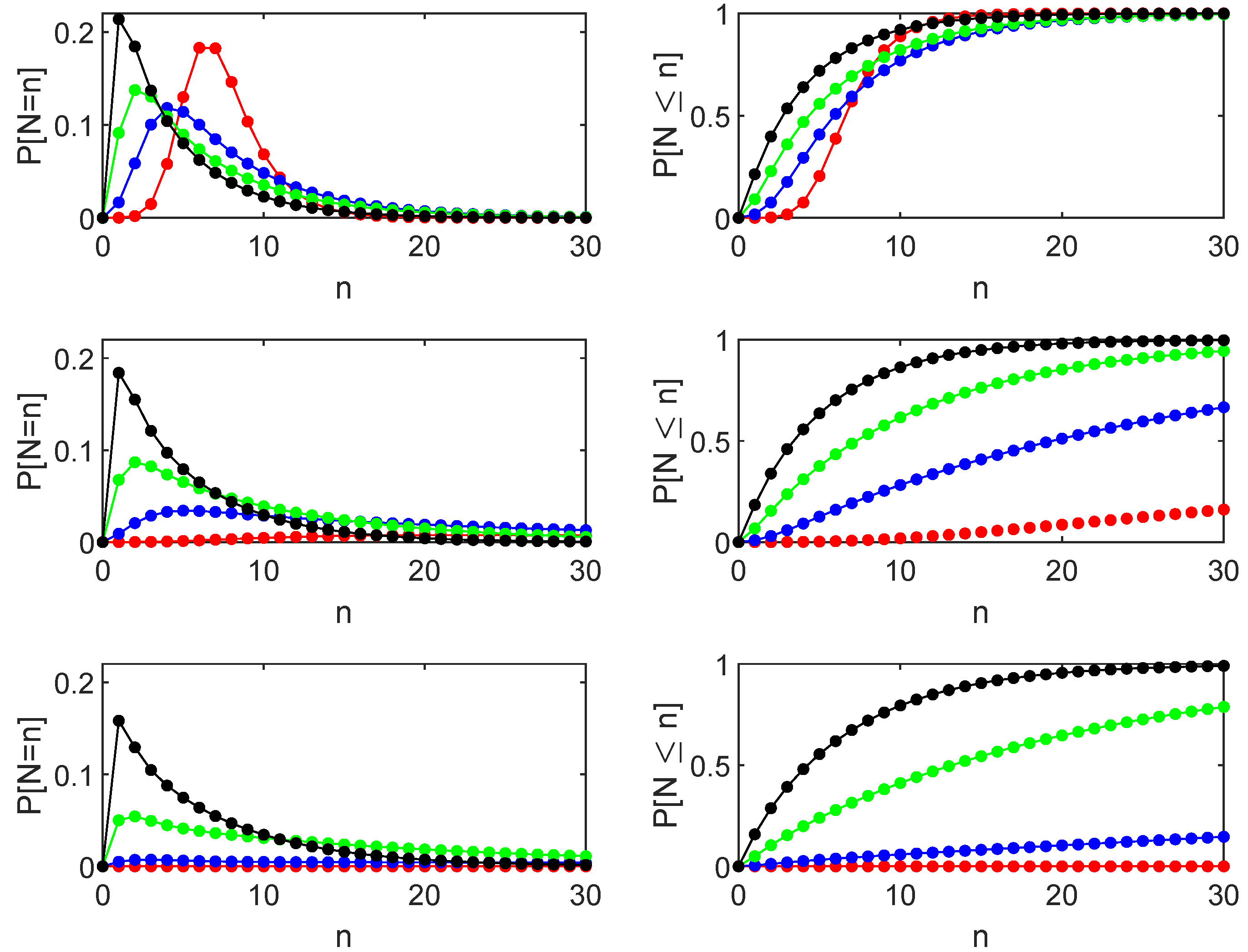
As far as the FET
are concerned, in
Figure 5, we illustrate the behavior of the probability distribution function
and of its cumulative with starting position
, boundary
,
and for different values of
. We see a different behavior for small or large values of the dispersion parameter
. Indeed, when
,
has a maximum whose ordinate decreases as
increases while it increases when
. This behavior has an immediate interpretation by observing that almost deterministic crossings determine a high peak when
is small; as far as
increases, the variability of the increments facilitates the crossing that also happens for smaller times, and the probabilistic mass starts to increase sooner.
In
Figure 6, we investigate how this behavior evolves when
decreases. In particular, we compare the shapes for different values of
. Observe that the abscissa of the maximum of the distribution decreases as
increases. Concerning the corresponding ordinate, we observe different behaviors depending on the sign of the parameter
. Indeed, for positive
, we have the features already noted in
Figure 5. These features are no longer observed when
because here, the deterministic crossing is no longer possible, and crossings are determined only by the noise.
7. An Application: CUSUM with Laplace-Distributed Scores
A problem in reliability theory concerns the change detection of a machinery’s performance. A widely used technique for this aim is known as CUSUM [
15,
36,
37]. In this context, given the observation of a sequence of independent random variables
, with a probability density function that changes at an unknown Time
m:
the method aims to recognize the unknown Time
m in which such sequence changes its distribution.
In his pioneering paper [
15], Page proposes the CUSUM procedure as a series of Sequential Probability Ratio Tests (SPRTs) between two simple hypotheses, with thresholds of 0 and
h. The detection of a change is achieved through repeated application of the likelihood ratio test. Page shows that the likelihood ratio test can be written in an iterative form as (
1), where
corresponds to the instantaneous loglikelihood ratio at Time
n
and the stopping time of the test is
Generally, hypothesis tests involve comparing two alternative values of one distribution parameter. Unfortunately, in most cases, closed-form expressions for the distribution of
are not available. In particular, when parameter changes result in a shift from a symmetric to an asymmetric distribution, it cannot be computed in closed form. However, the results from previous sections allow us to study the case where
is the Laplace density function (
2) and
, where
with
and
. In other words, we suppose that up to Time
m, the random variable
follows a Laplace distribution
with mean
while, after Time
m, it switches to a skewed Laplace distribution with mean
(cf.
Figure 7). Please note that this special case where
is the Laplace density function (
2) is relevant in applications [
38]. In this instance, the instantaneous loglikelihood ratio of the
n-th observation is
i.e., it is a linear function of
with slope
and specific intercept (
78) for each slope. The distribution of the loglikelihood ratio is then a rescaled and shifted Laplace random variable
.
Typically, the value of the boundary h is determined using the average time interval between anomalies, estimated by the experimenter. However, this procedure highly depends on such subjective estimation that does not allow the fixing of Type I error rate .
Here, we propose an alternative algorithm based on the previous section’s results that allows the creation of a test involving the Type I error rate
. We fix
, and we consider a sequence of SPRTs: in each step
, we determine the boundary value
such that
In this way, for the k-th SPRT test, we determine a constant boundary that holds up to Time k.
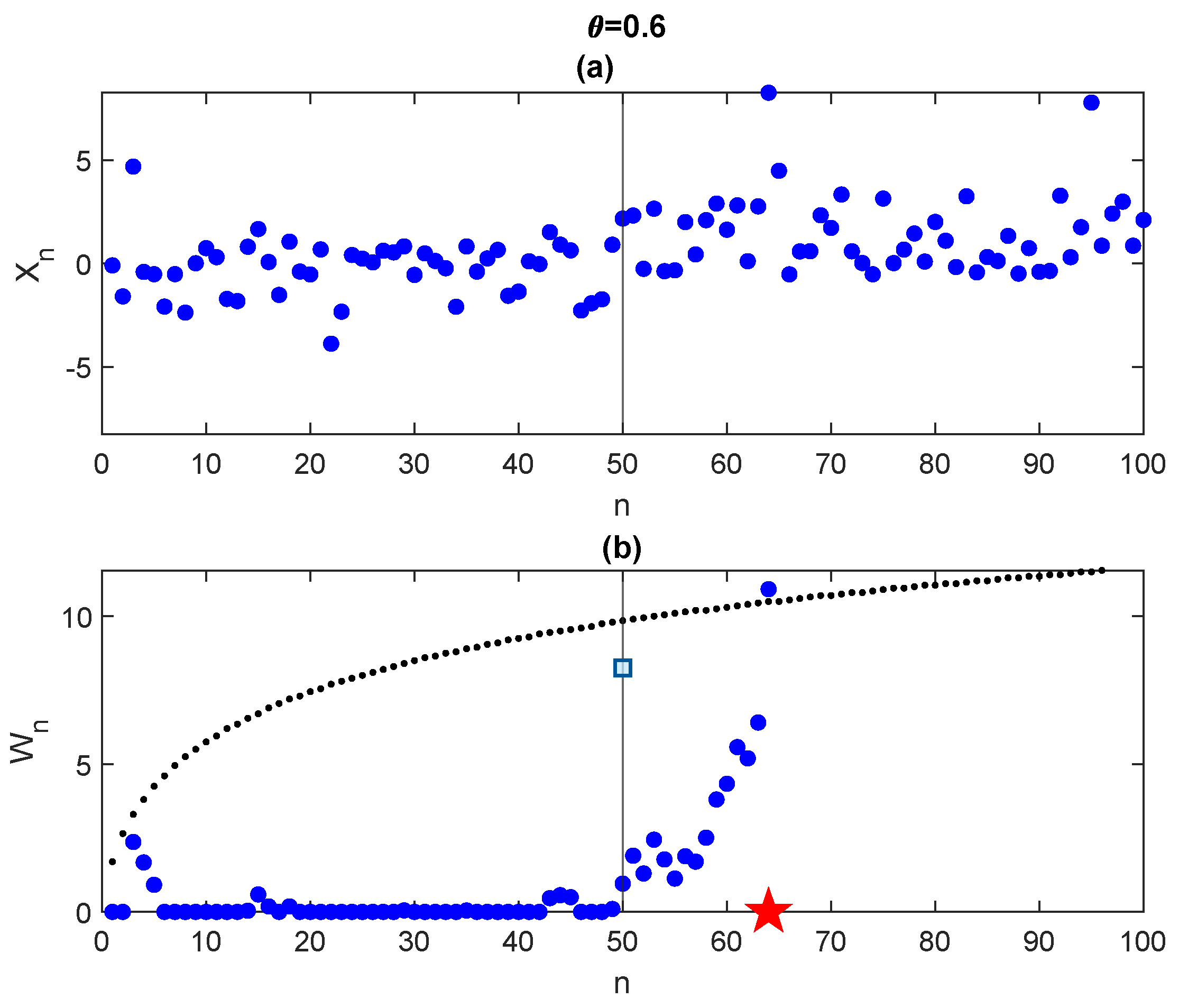
In
Figure 8, we simulate data from Laplace distribution with parameters
,
,
and time change
, i.e., for
the parameter
is null and for
we select
. Applying the CUSUM algorithm with the boundary evaluated through (
80) we obtain a detection time = 64 (red star in the figure). Looking at the trajectory
, it is very hard to detect a change time but the test works properly, though with a slight delay in detection.
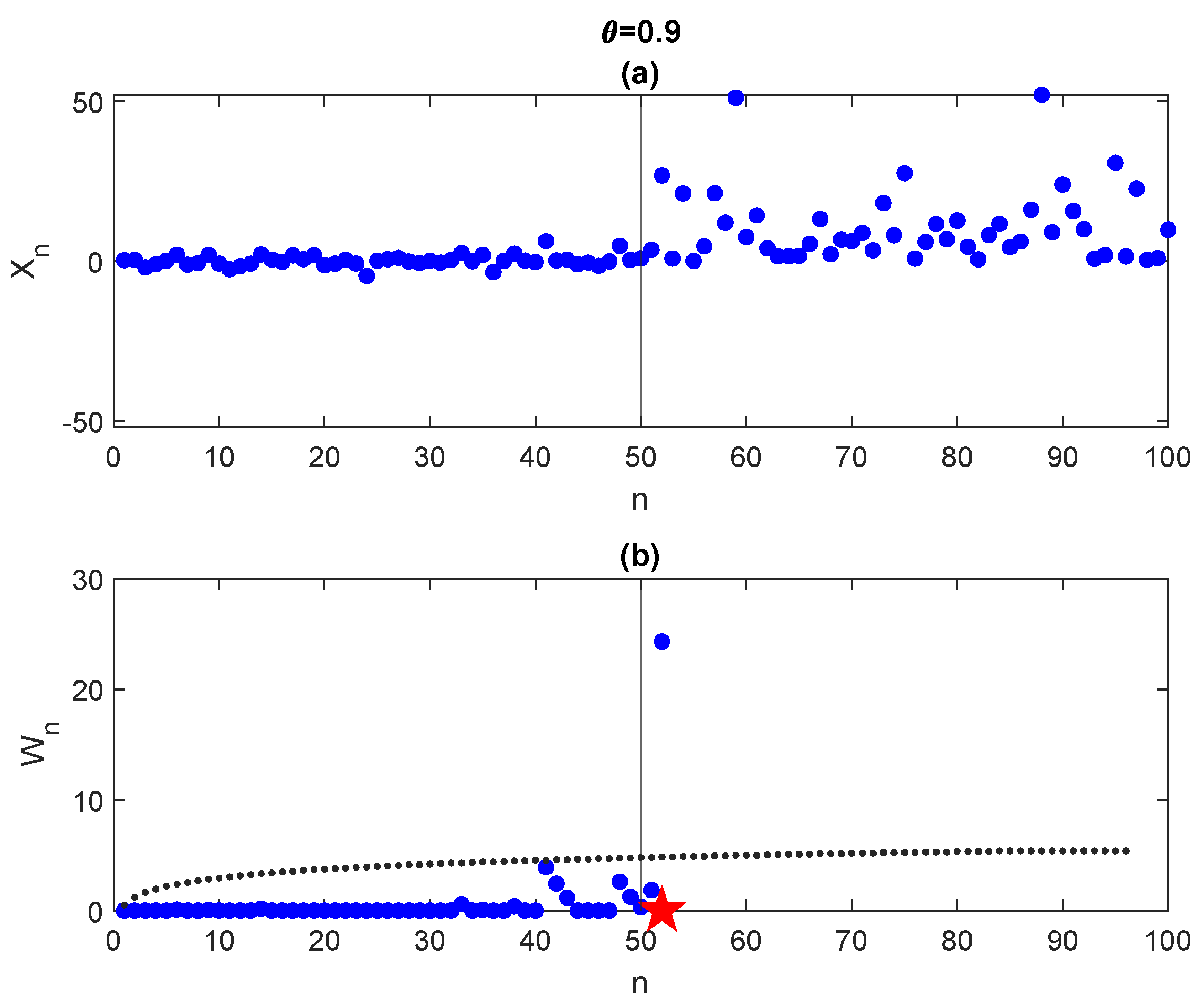
In
Figure 9, we perform the same experiment but with
. Applying the CUSUM algorithm with the corresponding boundary, we obtain a detection time = 52 (red star in the figure). As expected, as
increases, the detection becomes easier and more precise. This is confirmed in
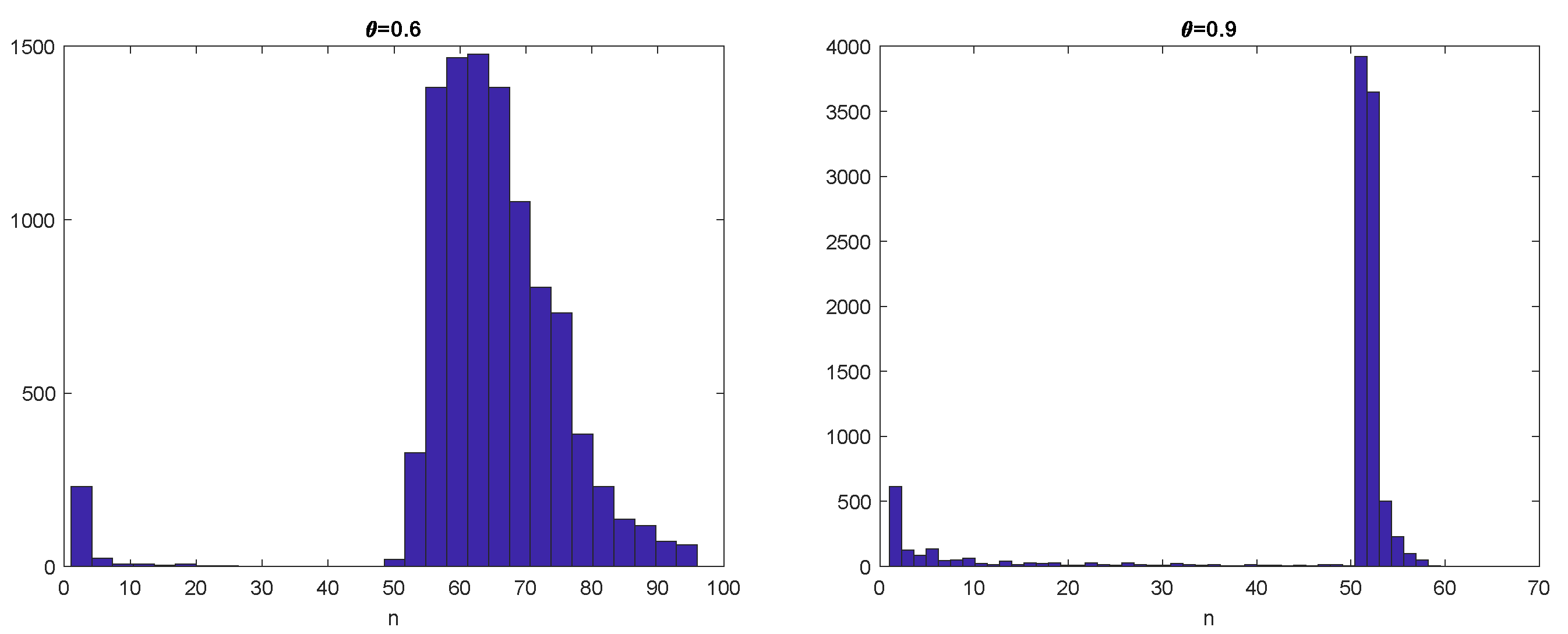
Figure 10 where histograms of the first exit time when
(left) and
(right) are shown for a sample of
trajectories.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}